基于Spark平台的岩石图像聚类分析
2016-12-16杨艳梅程国建强新建王叙乔
杨艳梅,柳 娜,程国建,强新建,王叙乔
(1.西安石油大学 经济管理学院,陕西 西安 710065;2.长庆油田分公司 低渗透油气田勘探开发国家工程实验室,陕西 西安 710018;3.西安石油大学 计算机学院,陕西 西安 710065;4.长庆油田分公司 第十一采油厂,甘肃 庆阳 745000)
基于Spark平台的岩石图像聚类分析
杨艳梅1,柳 娜2,程国建3,强新建3,王叙乔4
(1.西安石油大学 经济管理学院,陕西 西安 710065;2.长庆油田分公司 低渗透油气田勘探开发国家工程实验室,陕西 西安 710018;3.西安石油大学 计算机学院,陕西 西安 710065;4.长庆油田分公司 第十一采油厂,甘肃 庆阳 745000)
提出了一种基于概率选择的K-means聚类算法,并将其应用到Spark平台进行图像聚类,得到的数据集远小于初始数据集,大大降低了算法的迭代次数,聚类速度非常快。在Spark平台应用改进的K-means算法进行岩石图像处理,对岩石图像进行特征提取,使得岩石图像易于区分,解决了传统的聚类算法无法确定初始中心、聚类数目K的选取不当可能导致聚类失败、算法容易受到噪声和孤立点影响等问题。
岩石图像;聚类分析;Spark平台;K-means
杨艳梅,柳娜,程国建,等.基于Spark平台的岩石图像聚类分析[J].西安石油大学学报(自然科学版),2016,31(6):114-118.
YANG Yanmei,LIU Na,CHENG Guojian,et al.Clustering analysis of rock images based on spark platform[J].Journal of Xi'an Shiyou University (Natural Science Edition),2016,31(6):114-118.
引 言
大数据时代的到来使得信息的种类呈现出复杂多变的局面,由刚开始的纯文本信息发展成为图像、音频、视频及其混杂格式,数据量更是以人们难以想象的速度增长[1]。岩石图像的挖掘对油藏表征及其可视化开辟了新的途径。聚类分析作为图像信息挖掘领域一个重要的研究分支,是对原始图像的海量数据进行合理归类的一种有效方法[2]。
20世纪90年代后期,随着图像处理技术的不断发展,出现了对图像内容进行检索的需求,如对图像的颜色、纹理、布局等进行分析和检索。图像检索技术是基于对图像内容的特征描述,在图像数据库中搜索出具有所描述特征或与所描述的特征有相似之处的图像[3]。而目前图像检索技术所面临的问题之一就是图像的检索时间[4],人们所了解的以往的检索方法是根据用户提供的待查询样本图像,然后按照特定的相似性度量规则,来查询数据库中的所有图像,最终找出最相似的一些查询结果,来返回给用户。有关岩石图像的研究及其工程应用,特别是在油气勘探中的应用可参阅文献[5-14]。对一般自然图像的聚类分析研究已有大量研究论文,但对岩石图像,特别是基于大数据平台Spark的致密砂岩图像研究尚属探索阶段。
本文对Spark平台的岩石图像进行聚类处理,提出了一种基于概率选择的改进的K-means算法,通过此算法得到的数据集远远小于初始数据集,因此会大大提高K-means聚类的速度。基于Spark平台,将改进的K-means算法应用于处理岩石图像中,使用K-means算法对岩石图像进行特征提取,使得岩石图像易于区分。
1 K-means聚类算法的改进
1.1 Spark平台简介
Apache Spark是发源于美国加州大学伯克利分校AMPlab所开源的类HadoopMapReduce的通用并行框架,适用于如机器学习与数据挖掘等一些需要迭代的MapReduce算法[15-16]。为了避免应用程序之间的相互影响,Apache Spark为每个应用程序都设置了相应的运行时环境,含有4种过程[17]:初始化过程、转换过程、调度执行及其终止过程。Spark工作原理如图1所示[18]。
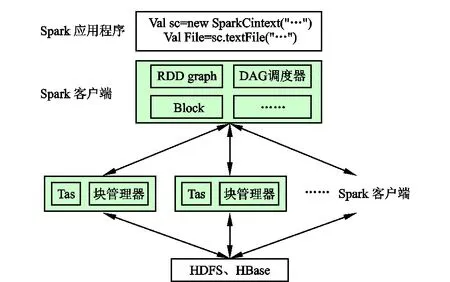
图1 Apache Spark平台的工作原理Fig.1 Working principle of Apache Spark platform
弹性分布式数据集(Resilient Distributed Datasets,RDD)是Spark的核心技术,在设计时不仅保留了数据流模型框架的优点(诸如本地优化分配、自动容错及可拓展性等),同时也使得用户能够将部分数据集缓存在内存中,这样可大大加速对这部分数据之后的查询和计算过程。
Spark与Hadoop相似,但较Hadoop更优,具体体现在以下方面:
(1)为提高计算时的迭代速度,Spark平台将中间的过渡数据都存放在存储器中。因为Spark中有了RDD的抽象概念,所以Spark更适合于迭代运算较多的DM运算[19]。
(2)由于Spark中有RDD的抽象概念,因此更适用于含有较多迭代过程的机器学习(ML)和数据挖掘(DM)运算。
(3)Spark比Hadoop更加具有通用性。Hadoop只提供2种运算操作:Map和Reduce,而Spark平台能够提供的数据集操作类型有很多。因此,给一些资深的用户提供了方便[20]。各个处理节点之间的通信模型不再是惟一的一种模式。可以说编程模型比Hadoop更灵活。
(4)处理速度高。由于Hadoop优先追求高吞吐量,所以并没有针对低延迟数据访问做一些优化;此外,由于作业的容错性需求,Hadoop要将计算中间结果写回到文件系统中,这就导致了繁琐的I/O操作,大幅降低了短作业的处理速度[21]。
(5)高可用性。Spark比Hadoop提供了更加丰富的Scala、Java、Python API及交互式Shell,并以此来提高可用性。
1.2 K-means算法的改进
在传统的K-means聚类算法中,通常会通过随机采样的方法首先选定k个聚类中心,而经由手动选定的初始中心将直接影响到待聚类数据集的最终聚类效果。如此这般,每个点被选为聚类中心之概率均相同。而在通常情况下,数据点的分布往往不均匀,必须根据不同的概率来选择不同的数据点,将其作为聚类中心,因此本文提出了一种基于概率选择的K-means改进算法。
首先定义代价函数

(1)
数据采样的概率函数为:
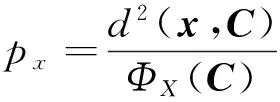
(2)
该函数所要表达的是:某个数据点到其所属聚类中心之距的平方和。最小化代价函数的作用是通过不断迭代,从而判断聚类结果是否达到收敛。将首次代价定义为Φ,将过采样系数定义为λ,采样系数表示在每次迭代中对λ个点进行采样。基于上述概率选择机理的聚类算法如下:
(1)从数据集中随机采样一个点C;
(2)计算该点的初始代价λ;
(3)循环次数为logφ次;
(5)C″←C∪C′;
(6)结束;
(7)按照K-means算法找到数据集C的k个聚类中心。
首先在数据集中随机选择一个点,将其作为初始聚类中心并计算该点的初始代价值φ,随后进行logφ次的迭代。这样做的原因是本文的初始聚类中心是随机选择的,因此无法判断其选择的好坏,根据此值的好坏并基于代价函数可有效地确定本算法的迭代次数。式(1)为每次迭代过程中的采样概率。为
尽可能地使新的聚类中心远离当前的聚类中心,每次迭代时,都会从数据集中采样λ个数据点,距离当前聚类中心越远的数据点有更高的被采样概率。为了更新每个点在下一次被采样的概率,每次迭代完成之后,都会更新ΦX(C)的值。同时可将每次采样的聚类中心合并到上次迭代后的聚类中心数据集当中,直到完成logφ次迭代。此时将会得到一个全新的数据集C,其中包含了λlogφ个数据采样。最后通过传统的K-means聚类算法,再将数据集C划分为k个聚类。
因为基于概率选择的K-means聚类算法对数据进行了适当的预处理,所得到的新数据集C的规模远小于初始数据集X,因此在新数据集上进行聚类处理的速度将会大幅度的提高。同时,传统的K-means算法往往是根据经验设定收敛阈值,这样一来无论是复杂的聚类还是简单的聚类,算法的迭代次数都是确定的,而使用logφ次迭代能够根据代价函数自动调整收敛阈值,这样可有效地降低算法执行所需要的迭代次数,对于海量数据的聚类划分来说更具有时间上的优越性。
2 实验结果与分析
2.1 图像分割测试
利用传统的K-means算法对图像分割,岩石薄片图像的原图如图2所示,进行图像分割后的结果如图3所示。从分割效果看,可以实现岩石图像分割,但是分割后图像目标出现很多不连续点。因此提出了基于概率的改进的K-means算法进行岩石图像的处理,处理结果如图4所示,明显地看出其按颜色分割的特点,连续点也比传统的K-means算法有所改善。
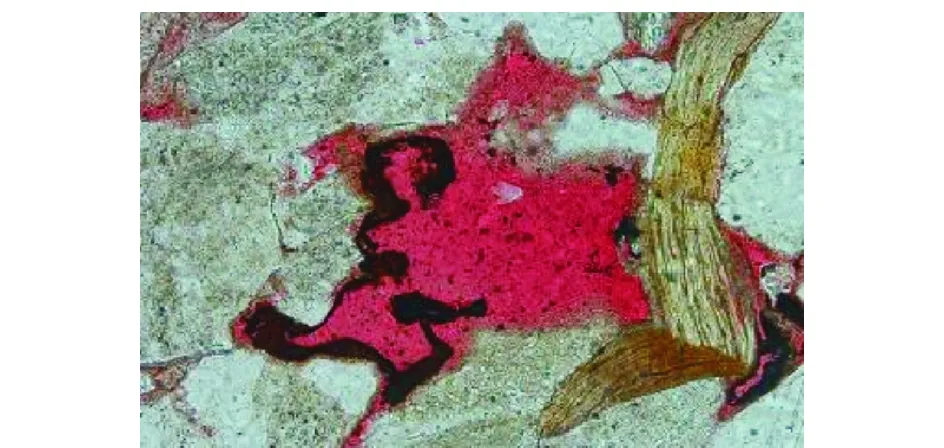
图2 原始岩石图像Fig.2 Original rock image
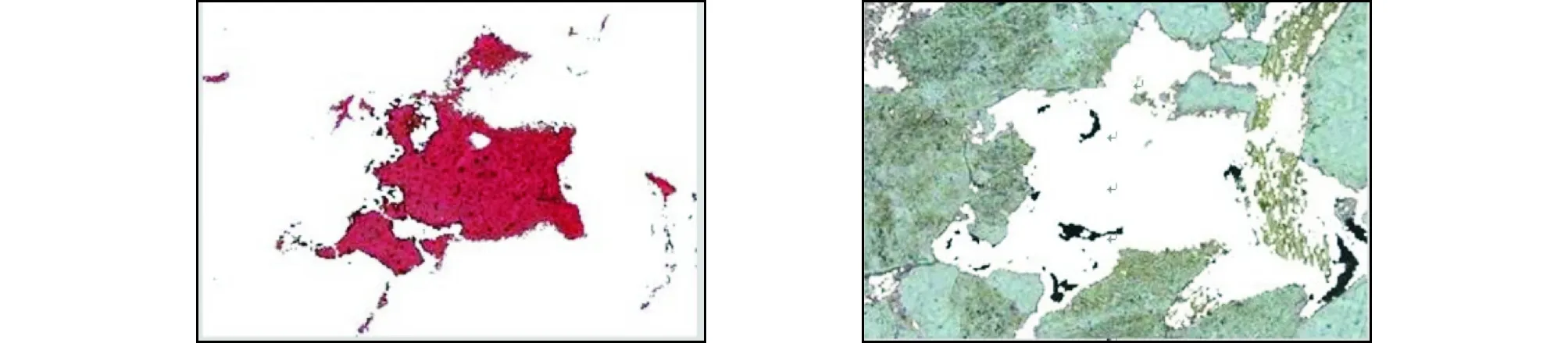
图3 聚类中心随机选择的分割效果(对应2个分割区域)Fig.3 Segmentation effect by random selection of clustering center (corresponding to two segmented regions)

图4 聚类中心概率选择的分割效果(对应2个分割区域)Fig.4 Segmentation effect by probability selection of cluster center (corresponding to two segmentation regions)
2.2 聚类算法有效性测试
使用K-means算法进行聚类分析时需要进行多次迭代运算,迭代次数直接影响算法的收敛速度。为了测试本文算法的有效性,分别比较了传统K-means算法与本文算法将图像分成12块时迭代相同次数所需的时间(见表1),以及不同迭代次数的情况下,使用改进的K-means算法将图像分成不同大小的图像块所需的时间(见表2)。

表1 不同算法不同迭代次数所需时间的对比Tab.1 Time required for different iteration times

表2 相同迭代次数与图像分块条件下所需时间的对比Tab.2 Time required under image blocks and iteration times
本文中改进的K-means算法采用了自适应的初始化聚类中心,从表1可以看出,相同迭代次数下,改进后的算法比传统K-means算法运行时间短很多,迭代3次时,改进的K-means算法将图像分为12块所需要的运行时间几乎是传统K-means算法所需时间的十分之一,算法的速度有了很大的提高;迭代次数增加到15次时,改进的K-means算法所需时间也有所增加,而传统K-means算法所需时间的增加与改进的算法相差不多。从表2可以看出,迭代次数相同时,将图像分为3块和12块所需的时间相差不多,但是将图像分为48块所需的时间比分为3块和12块所需的时间长。
3 结 论
传统K-means算法聚类效果特别依赖于初始聚类中心的选择,一旦初始聚类中心选择的不大合适,算法的执行过程就很容易陷入某个聚类的局部最优值,并且分割效果与聚类数目K的选取有很大的关联性。如果聚类数目K的选取不当可能导致聚类失败,此外,算法容易受到噪声和孤立点的影响,因此论文研究了一种基于概率选择的改进聚类算法,通过改进算法的预处理,将其应用到Spark平台进行图像聚类,得到的数据集远小于初始数据集,且聚类速度非常快,同时也降低了算法执行过程中的迭代次数,因此大大提高了K-means聚类的速度,这对于海量数据的聚类可能效果更为显著。
[1] 吴哲夫,张彤,肖鹰.基于Spark平台的K-means聚类算法改进及并行化实现[J].互联网天地,2016,12(1):44-50. WU Zhefu,ZHANG Tong,XIAO Ying.An improved K-means clustering algorithm based on spark platform and its parallel implementation[J].Internet World,2016,12(1):44-50.
[2] 邱荣财.基于Spark平台的CURE算法并行化设计与应用[D].广州:华南理工大学,2014. QIU Rongcai.Parallelization Design and Application of CURE Algorithm Based on Spark Platform[D].Guangzhou:South China University of Technology,2014.
[3] 黎光谱.改进K-Means聚类算法在基于Hadoop平台的图像检索系统中的研究与实现[D].厦门:厦门大学,2014. LI Guangpu.Research and Implementation of Improved K-means Clustering Algorithm Based on Hadoop Platform in Image Retrieval System[D].Xiamen:Xiamen University,2014.
[4] 杨传慧.图像聚类及其在图像检索中的应用研究[D].南京:南京师范大学,2013. YANG Chuanhui.Image Clustering and Image Retrieval Application[D].Nanjing:Nanjing Normal University,2013.
[5] SHAINA Kelly,HESHAM El-Sobky.Assessing the utility of FIB-SEM images for shale digital rock physics[J].Advances in Water Resources,2016,95(9):302-316.
[6] SUN Hai,YAO Jun,CAO Yingchang,et al.Characterization of gas transport behaviors in shale gas and tight gas reservoirs by digital rock analysis[J].International Journal of Heat and Mass Transfer,2017,104(1):227-239.
[7] HE Jianhua,DING Wenlong,LI Ang,et al.Quantitative microporosity evaluation using mercury injection and digital image analysis in tight carbonate rocks:a case study from the Ordovician in the Tazhong Palaeouplift,Tarim Basin,NW China[J].Journal of Natural Gas Science and Engineering,2016,34(8):627-644.
[8] JAFAR Qajar,CHRISTOPH H Arns.Characterization of reactive flow-induced evolution of carbonate rocks using digital core analysis part1:assessment of pore-scale mineral dissolution and deposition[J].Journal of Contaminant Hydrology,2016,192(9):60-86.
[9] OLSON L,SAMSON C,MCKINNON S D.3-D laser imaging of drill core for fracture detection and rock quality designation[J].International Journal of Rock Mechanics and Mining Sciences,2015,73(1):156-164.
[10] GAO G,YAO W,XIA K,et al.Investigation of the rate dependence of fracture propagation in rocks using digital image correlation (DIC) method[J].Engineering Fracture Mechanics,2015,138(4):146-155.
[11] SWARUP Chauhan,WOLFRAM Rühaak,FAISAL Khan,et al.Processing of rock core microtomography images:using seven different machine learning algorithms[J].Computers & Geosciences,2016,86(1):120-128.
[12] SAFARI Alireza,DOWLATABAD Mojtaba Moradi,HASSANI A,et al.Numerical simulation and X-ray imaging validation of wormhole propagation during acid core-flood experiments in a carbonate gas reservoir[J].Journal of Natural Gas Science and Engineering,2016,30(3):539-547.
[13] HEIKO Andrä,NICOLAS Combaret.Digital rock physics benchmarks:Part I Imaging and segmentation[J].Computers & Geosciences,2013,50(1):25-32.
[14] HEIKO Andrä,NICOLAS Combaret.Digital rock physics benchmarks:part II computing effective properties[J].Computers & Geosciences,2013,50(1):33-43.
[15] ZHOU Y,OUYANG Z,LIU J,et al.A novel K-means image clustering algorithm Based on glowworm swarm optimization[J].Przeglad Elektrotechniczny,2012,88(8):4031-4032.
[16] ZHAO Weizhong,MA Huifang,HE Qing.Parallel K-means clustering based on map reduce[J].Lecture Notes in Computer Science,1990,5931:674-679.
[17] 陈虹君.基于Spark框架的聚类算法研究[J].电脑知识与技术,2015(4):56-57. CHEN Hongjun.Clustering algorithm research based on spark architecture[J].Computer Knowledge & Technology,2015(4):56-57.
[18] 张杰.PyGel:基于DPark的分布式图计算引擎的研究与实现[D].广州:华南理工大学,2013. ZHANG Jie.PyGel:Distributed Graph Computing Engine Research & Implementation Based on DPark[D].Guangzhou:South China University of Technology,2013.
[19] 王诏远,王宏杰,邢焕来,等.基于Spark的蚁群优化算法[J].计算机应用,2015,35(10):2777-2780. WANG Zhaoyuan,WANG Hongjie,XING Huanlai,et al.Ant colony optimization algorithm based on Spark[J].Computer Applications,2015,35(10):2777-2780.
[20] 兰叶芳,邓秀芹,程党性,等.鄂尔多斯盆地三叠系延长组次生孔隙形成机制[J].地质科技情报,2014,33(6):128-136. LAN Yefang,DENG Xiuqin,CHENG Dangxing,et al.Formation mechanisms of secondary porosity in the triassic yanchang formation in the Ordos basin[J].Geological Science and Technology Information,2014,33(6):128-136.
[21] 黄震华,向阳,张波,等.一种进行K-Means聚类的有效方法[J].模式识别与人工智能,2010,23(4):516-521. HUANG Zhenhua,XIANG Yang,ZHANG Bo,et al.An efficient method for K-means clustering[J].Pattern Recognition and Artificial Intelligence,2010,23(4):516-521.
责任编辑:张新宝
Clustering Analysis of Rock Images Based on Spark Platform
YANG Yanmei1,LIU Na2,CHENG Guojian3,QIANG Xinjian3,WANG Xuqiao4
(1.College of Economics and Management,Xi'an Shiyou University,Xi'an 710065,Shaanxi,China;2.National Engineering Laboratory for Exploration and Development of Low Permeability Oil and Gas Field,Changqing Oilfield Company,Xi'an 710018,Shaanxi,China;3.College of Computer Science,Xi'an Shiyou University,Xi'an 710065,Shaanxi,China;4.The 11th Oil Production Plant,Changqing Oilfield Company,Qingyang 745000,Gansu,China)
K-means clustering algorithm based on probability selection is discussed,and it is applied to the Spark platform for the cluster of images.The generated data set is much smaller than the initial data sets,which greatly reduces the iteration times and improves clustering speed.The improved K-means algorithm is applied to the processing of rock images.The feature of the rock image is extracted,which makes the rock image to be very easily distinguished.This method overcomes the shortcomings of the traditional clustering algorithms,such as clustering fails due to the unable determination of initial center and the improper selection of cluster number K,the cluster algorithm is susceptible to noise,isolated points,and so on.
rock image;cluster analysis;Spark platform;K-means
2016-07-15
国家科技重大专项(编号:2016ZX05007G003);陕西省工业科技攻关项目(编号:2015GY104);中国石油天然气股份有限公司重大科技专项(编号:2011EG1301)
杨艳梅 (1968-),女,硕士,高级工程师,主要从事计算机信息处理研究。 E-mail: ymyang@xsyu.edu.cn
10.3969/j.issn.1673-064X.2016.06.018
TE19;TP319
1673-064X(2016)06-0114-05
A
