基于决策树的客户流失模型的建立
2016-12-10林芳
林芳
(集美大学诚毅学院 实验管理中心,福建 厦门 361021)
基于决策树的客户流失模型的建立
林芳
(集美大学诚毅学院 实验管理中心,福建 厦门 361021)
本文对决策树分类方法进行了系统、深入的分析研究.并采用ID3算法对客户提交的友情反馈表进行分析,提取规则,为企业判断客户是否存在流失风险的预测构造系统,在经过处理数据的基础上生成了一系列客户流失预测规则.
客户流失;数据挖掘;决策树
客户在一个网站中一般会经历新鲜期--沉迷期--消退期--离开网站四个阶段.[1]延长用户在网站的停留周期是企业人员需要迫切解决的问题.
数据库中数据的一部分是需要经过一番分析形成知识后才能被决策所利用.通过决策树技术对客户进行分析,针对处于不同的客户生命周期,采取不同的策略,进而提高不同客户的满意程度,建立较高的忠诚度,防止一定客户的流失.
1 分类的概念
数据挖掘中的分类方法是将一个数据集按照某个指定的属性划分,并给出相应的分类规则.对于一个给定的数据集,具有m+1个属性(字段)A1,A2,…,Am的值,计算预测分类属性值.可以按以下两个步骤:[2]
(1)创建分类模型:用分类算法和一个类别已经确定的数据集创建分类模型.
(2)使用模型预测:使用分类模型前必须用一定的方法估计分类模型的准确率.
决策树可看成一个可自动对数据进行分类的树型结构,可解释成一种特殊形式的规则集,其特征是规则的层次组织关系.[3][4]
2 客户流失分析模型的建立
通过实验数据进行预处理,可以选择以下指标变量进行分析:菜品品种(A-丰富,B-单调)、价格(A-太高,B-合理)、菜品味道(A-满意,B-一般,C不满意)、配送时间(A-满意,B-一般,C不满意)、网站设计合理性(A-合理,B-不合理)、服务态度(A-满意,B-不满意).数据集合分为流失(Y)集合和未流失(N)集合
本课题的主要任务是对网上订餐管理系统客户流失进行分析,所以,最终需要的属性为”是否流失”,包含两个值Y (流失),N(未流失),经过对训练集的统计,未流失实例个数为106,流失实例个数为61,所以开始时熵值为:

接下来计算除“是否流失”以外的所有属性的熵.
首先从“菜品品种”属性开始,根据训练集统计出对于“菜品品种”表示丰富的记录有94个,其中“是否流失”=N的有65,“是否流失”=Y的有29;对“菜品品种”表示单调的记录有73,其中“是否流失”=N的有41,“是否流失”=Y的有32.因此它的熵值为

信息增益:
Gain(菜品品种)=(I(s1,s2)-E(菜品品种))*m=(0.947-0.934) /2=0.0065
其中m为改进算法中引入的权重因子.用相同的方法计算出剩余属性的信息增益
Gain(价格)=0.0250 Gain(菜品味道)=0.1100
Gain(网站设计合理性)=0.0001 Gain(服务态度)=0.0145
Gain(配送时间)=0.0143

图2-1 初始的决策树的信息图
由此可以看出Gain(菜品味道)最大,即有关菜品味道指数的信息对分类帮助最大,提供最大的信息量.所以应该选择菜品味道作为测试属性.
利用“菜品味道”属性作为本课题决策树根节点,它的属性值作为这个决策树的枝,对其余属性再次计算增益.经过计算,初始的决策树各个子节点的信息如图:
如上图2-1所示,对菜品味道的三个节点要分别继续进行分类.为了预防决策树的创建过程中出现过拟合现象,设定一个停止规则:当信息增益值快趋于0或次小与最小的信息增益之比大于lO时,就要将该分支转换成叶子节点.经过上面的分析“菜品品种”属性和“网络设计合理性”属性的信息增益太小,根据规则可将这2个属性删除,即在以后的计算过程中,不再计算这两个属性的信息增益.
经过一系列的递归运算,得出订餐系统客户流失分析的决策树雏形,如图2-2,
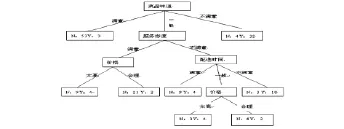
图2-2 客户流失分析决策树雏形
3 模型的改进与剪枝
(1)传统的ID3算法有偏向于选择取值较多的属性的缺点.在改进算法中引入权重因子m,设某个属性A有n种取值,那么m=1/n可作为调整因子.例如菜品品种的属性有丰富和单调两个取值,m则可以取值1/2.在确定好这个调整因子后,原有的信息增益修正为:[5]
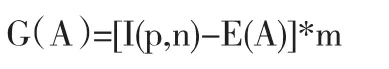
(2)增加了决策树的剪枝处理.在本模型建立过程中,用到两种剪枝方法:第一种,前剪枝,利用提前停止树的构造对决策树进行剪枝,只要停止,节点就变成了树叶,在第一轮计算信息增益时,发现“网络设计是否合理“属性的增益值最小,几乎快接近于0,“菜品品种”属性信息增益与最小的“网络设计是否合理”属性增益比大于10,根据停止规则,在此后的计算过程中,不再对这两个属性进行考虑.
第二种,后剪枝,对于决策树中的每个不是树叶的节点,计算出节点上的子树被剪枝的可能期望的错误率.例如剪去该节点会引起高期望错误率,就要保留该子树;否则就剪掉.该实验模型直接在决策树的生成过程中引入一个停止规则(替代错误率).例如,训练集m,包含训练集n的节点类标签为多数满足n’<=n,则替代错误率为,比较低层的叶节点对替代影响最小,因此会最先被修剪.该实验模型设定的规则为:当分支的替代错误率小于2.5%时,将其转为叶子节点.

其中,n:分支的记录数,n':分支中多数类别的记录数,m:训练集数的记录总数.[6]
例如上图2-2的“菜品味道”属性为满意的N:53 Y:3, n=56,n’=53,m=167

图3-1 最终的决策树
4 模型的验证
通过图3-1的决策树,使用者可以使用遍历路径提取分类规则:
If 菜品味道(满意) then 未流失
If 菜品味道(一般) and 服务态度(满意) then 未流失
我知道,他有好多好多的心事,北方的清军蠢蠢欲动,民间的动乱此起彼伏,明王朝在风雨飘摇中,他眉头紧锁,很少言语,每次来怡香院我都为他沏一壶新茶,知他不爱言语,我也默默地陪坐一旁。可是我知道,他的心里有着一段伤痛,他看起来潇洒不羁,却是情根深种。
If 菜品味道(一般) and 服务态度(不满意) and配送时间(满意) then 未流失
If 菜品味道(一般)and 服务态度(不满意) and配送时间(一般) and 价格(合理)then未流失
If 菜品味道(一般) and 服务态度(不满意) and配送时间(一般) and 价格(太高)then流失
If 菜品味道(一般) and 服务态度(不满意) and配送时间(不满意) then流失
If 菜品味道(不满意) then流失
从数据库里随机抽取的三分之一作为测试集中,按上面客户流失分析模型提取的规则进行测试,如果测试结果在85%-98%之间,则模型符合要求,否则重新创建模型;若正确率低于85%,预测结果错误的可能性太高,若高于98%,则可能出现过匹配现象.
根据验证结果,可知,在所有的83条测试集中,正确的记录数76条,错误的记录7条,得知该实验的决策树模型,准确率达到了91.6%,在85%-98%之间,达到了预计的目标,满足要求.
5 总结
根据客户反馈信息所创建的客户流失分析模型,其正确率为91.6%,可以将该模型推广到一般的分析中,从而为各企业的客户流失提供决策参考.通过该分析模型的建立,企业了解到:本餐厅的菜品味道对客户流失的影响最大,其次是整体的服务态度,配送时间;如果想保有更高的客户持有率,餐厅可以制作不同的菜系来满足不同的客户口味,同时也要提高整体的服务态度.
〔2〕胡小刚.数据挖掘中决策树分类算法的研究.华东师范大学.
〔3〕张运涛,等.数据挖掘原理与技术.电子工业出版社.
〔4〕朱玉全,等.数据挖掘技术.东南大学出版社.
〔5〕苏志同.一种改进的决策树算法及应用[J].微计算机信息,2009(03).
〔6〕范洁,杨岳湘.决策树后剪枝算法的研究.湖南广播电视大学学报.
TP311
A
1673-260X(2016)11-0018-02
2016-06-20
