基于中文分词的电子病历数据挖掘技术
2016-12-07周小茜罗凌云
谢 剑 周小茜 童 凌 罗凌云*
基于中文分词的电子病历数据挖掘技术
谢剑周小茜童凌罗凌云*
(南华大学 计算机科学与技术学院, 湖南 衡阳421001)
电子病历中存在海量非结构化数据,其中隐含的信息对于医学研究与应用均具有重要的意义。文章通过比较各类中文分词器的优劣,结合词典扩充技术,挖掘出真实电子病历中的疾病与药品信息,并对疾病与疾病、疾病与药品进行关联分析,发掘有价值的信息。实验结果表明该方法是行之有效的。
医学数据;电子病历
引 言
众所周知,巨大的医学数据中潜在着很多有价值的信息。这些潜在的信息对辅助病例治疗和医学研究的发展具有很重要的意义。但是从目前的状况来看,多数的医疗机构除了对这些数据做一些简单的录入、修改、查询等操作之外,并没有进行深入的分析,使得这些医学数据中隐含的价值并没有被充分利用。如果不去发掘这些数据中的价值,不管对医学还是对于学术研究来说,都是一种很大的损失。
目前数据挖掘技术正逐渐趋向于成熟[1,2],对于上述的情况,如果能够将数据挖掘技术应用在医学信息挖掘中[3],通过分析海量的医学数据,总结病例就诊过程中接受过的各种治疗所产生的疗效,挖掘出其中隐含的各种有意义的信息[4,5],可以为医务人员对相关病例的医疗计划的制定提供非常有用的帮助,为医学智能辅助系统的设计实现提供支持[6-8]。
1 电子病历
病历是病人在医院就医过程中的全部记录,病历中不仅包含病人的年龄、性别等个人信息,还包含医院的诊断、检查结果、治疗方法记录等等医疗信息。传统的病历都是由人工手写在纸质病历本上,虽然对同一个诊断医生来说书写阅读方便,但随着医疗水平的进步,传统的病历暴露出很多的弊端,如记录信息不完整、遗漏,手写笔迹不工整难以识别等,则当主治医生换成其他人或者病人住院需要转院时,新接手的医生从纸质病历本中得到病人的诊断检查信息可能会存在很大误差或遗漏,造成误诊或者需要重新诊断而浪费大量时间和资源。
现如今,医院都采用电子病历存储病人的信息,与传统病历相比,电子病历具有记录完整、查阅方便、传输快、存储量大等优点。文章所用的病历采用word文档的格式存储,其内容包括:病例特点、拟诊讨论、病例分型、诊疗计划、查房记录。虽然病历文档有一个整体的结构,但其中的详细文本内容还是由医务人员主观录入,是无结构的数据,以下是某个病历中的一次查房记录:
2015-01-24 09:12XX主任查房记录
今随XX主任医师查房,患者诉右下肢浮肿,查体为轻度凹陷性水肿,无畏寒发热及头晕、头痛、视物模糊、恶心、呕吐、胸闷、胸痛、气促等特殊不适,大小便正常。查体:腋表36.7℃,脉搏84次/分,呼吸19次/min,血压110/70mmHg。右下肢有轻度凹陷性水肿。神清,全身皮肤巩膜无黄染,浅表淋巴结未扪及,双肺呼吸音清,未及明显干湿啰音。心率64次/分,律齐,无杂音。韦兵主任医师查房后示:(1)按心胸外科护理常规,予以普食,监测脉搏、血压、心率;(2)完善常规检查:三大常规、肝肾功能、血气、电解质、血糖、肝炎免疫、HIV、梅毒、定血型、胸部CT、头颅CT、腹部彩超、心电图、肺功能、纤支镜等;(3)暂予以“注射用细辛脑”解痉化痰、“苦碟子注射液”改善循环、“注射用香菇多糖”、“消癌平注射液”抗肿瘤、“盐酸氨溴索”、“环磷腺苷葡胺”护心、“阿加曲班注射液”抗动脉闭塞。因患者之前检查结果回报有白细胞数目减少,加用“重组人粒细胞刺激因子”促进粒细胞增加。遵执,继观。
电子病历中潜藏的知识是非常具有研究和实用意义的,例如,发掘出哪个地域处于什么年龄段的病人容易患上什么病;病人在治疗过程中一直出现的症状或发病规律;预测症状的发生等等,如果能挖掘出病历文本中潜在的价值或者规律,有利于辅助医疗诊断系统的构建,给病人带来福音。
2 病历文本分词
目前网络上的中文分词工具很多[9,10],也应用在了很多方面,如搜索引擎、手写输入识别、语音识别分词、微博分词等[11-14],但是在医学文本中,存在许多的医学专用词,如药品名称、疾病名称、组织器官名称等,如果直接将分词工具用来处理病历文本分词,分词正确率和识别率会大大降低,所以有必要采取方法来解决医学专用词的识别。
选取上一节中的病历来进行分词测试。选取这段记录的原因是,该文本中包含人名、医药名称、医学单位、人体体征等词,这些词对各分词工具来说都属于新词,选用这段文本可以用来测试各分词工具对新词识别的正确率。
2.1中文分词器比较
对结巴分词、庖丁分词、斯坦福分词器Stanford Segmenter和中科院分词系统ICTCLAS进行测试[15],对比分词结果可以发现:
(1)结巴分词速度最快,Stanford Segmenter的运行时间最长,因为结巴分词虽然也是基于统计的分词方法,但是结巴分词工具已经在程序中直接写出了训练之后的模型,而斯坦福分词器没有,所以运行之前需要先进行花费时间多的训练。
(2)庖丁分出的词量最多,因为庖丁将文本中相邻之间所有能组合出的词都切分出来,因此庖丁分词工具适合搜索引擎分词而不适合用作文本数据分析前的分词。
(3)结巴分词不能很好的识别出时间,如“2015-01-24”切分成了“2015/ - /01 /- /24 ”。
(4)选取的文本中间存在“注射用细辛脑”、“苦碟子注射液”、“注射用香菇多糖”、“消癌平注射液”、“盐酸氨溴索”、“环磷腺苷葡胺”、“阿加曲班注射液”,共七个药品名称,从测试结果中可以看出,结巴分词、Stanford分词和ICTCLAS分词都没有将这七个词识别出来,对比之下只有庖丁分词的测试结果中完整的切分出了这七个词。而鉴于文本中上述七个词都有双引号包括,为了判断庖丁是否真的能切分出药品名词,将包含上述几个词的句子去掉特殊的双引号之后,庖丁和其它三种分词工具一样,并不能与第一次测试结果一样完整的识别出某一个药品名称。
总而言之,虽然这四个分词工具能在自然文本或者说人们经常使用的文本中有不错的分词效果和较高的正确率,但是对于拥有很多专业用语的医学文本处理,如果使用自带的词典,各个分词工具都不能达到比较理想的效果,所以有必要使用分词工具提供的自定义词典功能进行词典扩充。
2.2词典扩充技术
如果把病历中的药品作为数据挖掘感兴趣的知识,例如说,要提取出病人在每个阶段(医生查房记录)接受治疗使用过的药品,则必须在提取信息之前,在对数据预处理的过程中将各药品名词准确的切分出来,而在上述测试中,虽然庖丁切分出了各药品名称,但也仅能切分出双引号括起来的词,事实上,使用各分词工具默认的词典,四个分词工具都不能完成对药品名称的识别,但它们都提供用户自定义词典的功能,因此,我们考虑使用药品名词集对分词词库进行扩充。
但目前网络上并没有包含药品名称的词典可供直接使用或者下载,所以药品词汇的获取只能采用其它的方法,如网页数据爬取。
2.2.1网页数据提取。客户端发出目标URL地址请求,服务器端会返回相应的静态页面,而这个静态页面中就包含了需要的药品词汇。
包含药品最全的莫过于国家食品药品监督局的数据库了,虽然没办法直接提取国家药品监督局的数据库内容,但监督局的网站提供了数据查询服务,药品数据查询结果在浏览器显示内容如图1。
共查询到18955条药品数据,包括国产和进口的药品,而属于不同的药品生产公司但同名的药品只占一条记录,意味着这18955条数据不重名,我们提取这18955条数据中的药品名称来扩充分词词典,而不关心其生产的公司或者来源。
第一步,使用浏览器查看页面源代码,包含数据记录的网页源代码示例如下:
仔细观察源码,各条记录用标签对包围,且可以判定width="241">XXXX所有这样格式的字符串中间包含的XXXX就是要提取的药品名词。文章采用Java来爬取数据,上述的模式对应的Java正则表达式是String PATTERN = "width="241">([^<]+)",其中“()”包围的内容就是药品名称。提取整个页面中的所有药品名称并写入文件。
第二步,上述过程只能提取一个页面的内容,而查询结果有1264个页面,手工翻页提取的话工作量大效率不高,通过查看页面地址,发现地址中有个page字段控制页面,其它的内容都一样,所以建立一个循环每次改变page后面的值之后再发送URL请求就可遍历所有页面。这样就提取出了网站收录的所有药品名称。
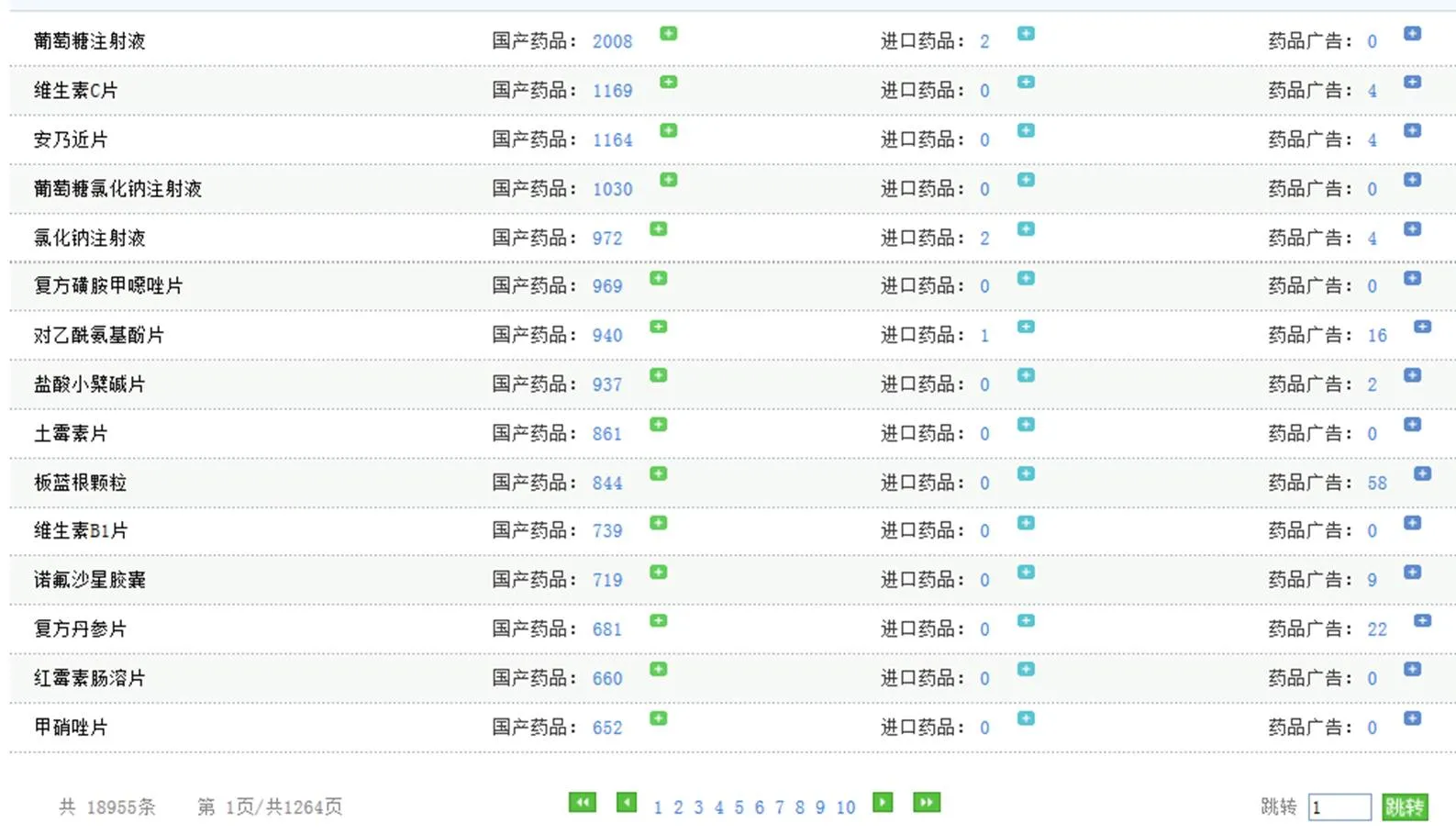
图1.国家食品药品监督局网页内容
2.2.2自定义用户词典。根据测试,新词识别效果最好的是中科院分词器ICTCLAS,而且ICTCLAS支持用户在自定义词典中添加词性标注功能,所以选择ICTCLAS分词器来进行病历文档的分词工作。首先采集ICD10提供的比较全的疾病名称以及前文爬取到的药品名称自定义词典。疾病名称采用add_disease做标注,药品名称采用add_nz做词性标注,自定义词典如图2。

图2.自定义词典部分
最后,使用ICTCLAS 2015分词器提供的ICTCLAS-tools.exe工具在脱机状态下导入自定义的词典。
3 病历文本信息分析
对病历文档进行数据挖掘与分析,其大致流程如图3所示。

图3.病历文档分析流程
首先,使用扩充词典后的分词工具对病历文本进行分词操作,得到带有词性标注的文本。其次,进行信息的提取与分析。
3.1信息提取
(1)提取疾病与药品名称。对分词后的文本操作,提取出其中所有以add_disease和add_nz标注的词汇,得到的疾病与药品名称形式如表1:
表1.疾病与药品名称形式

疾病1疾病2...疾病n药品1药品2...药品n 病例1肺结核球肺脓肿甲钴胺注射液甘露醇注射液 病例2冠心病高血压胃窦糜烂苦碟子注射液红花黄色素氯化钠注射用丹参 ... 病例n
(2)将提取出的上述形式的数据存入关系型数据库中,但是对于不同的病例,所患疾病以及对应的治疗药品可能各不相同,而且同一个病例,可能还患有其它的多种疾病,由于这种特殊性,将上述表格拆分为数据库中三个表格,数据库设计如图4所示。

图4.数据库设计
图4中病例表的设计忽略了病例的性别、年龄等其它个人信息。将提取到的信息以如上的形式存入数据库中。到这一步,摒弃了病历文本中的一些次要或者不相关的信息,得到了有结构的关系型数据如图5所示。对于这样的数据,人们可以很方便的使用数据挖掘技术或工具来进行下一步的分析。
图5.提取的疾病表(左)与药品表(右)(部分)
3.2数据挖掘关联分析
使用数据挖掘技术中的关联分析法来分析上节提取出来的数据,关联分析使用支持度和置信度两个度量,支持度用来选取出同时出现多的项集,而置信度则用来度量规则X→Y关联的可信度。通过计算各项关联的置信度和支持度,与预先设定的阈值相比较,判断两个或多个项之间的关联是否成立。例如,对于如下表的例子,疾病用D+数字表示,药物用M+数字表示。
表2.病历数据样例
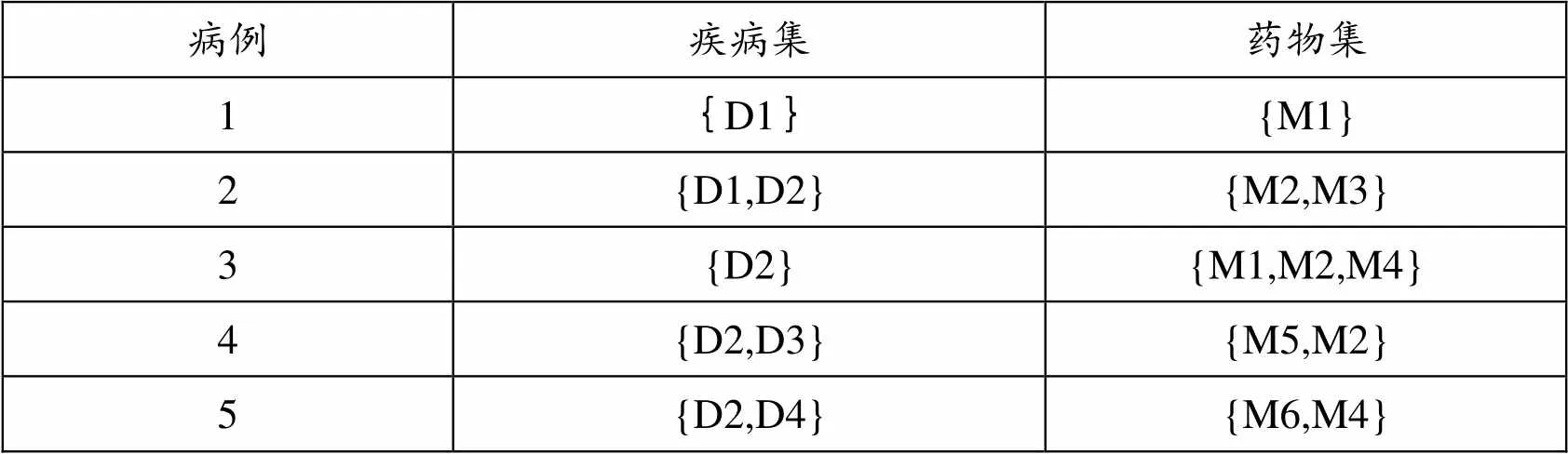
病例疾病集药物集 1{D1}{M1} 2{D1,D2}{M2,M3} 3{D2}{M1,M2,M4} 4{D2,D3}{M5,M2} 5{D2,D4}{M6,M4}
上述共有五个病例,考虑{D2}→{M2}的关联规则,则其支持度为:
S({D2}→{M2}) = {同时包含D2和M2的病例数量}/{所有病例数量}=3/5。置信度为: C({D2}→{M2})={同时包含D2和M2的病例数量}/{包含D2的病例数量}=3/4。预先设定支持度与置信度的最小阈值minSup和minConf,从所有的病例项中,利用算法提取去所有支持度大于或等于minSup的关联规则,再计算这些规则的置信度,如果某条规则的置信度C也大于或等于minConf,则可以认为这条规则是成立的,而这条规则中的疾病和药品相关联,也就是说其中的药品对这些疾病有治疗效果。例如,对于上述的关联规则{D2}→{M2},如果s=3/5>=minSup,c=3/4>=minConf成立,则认为药品M2对疾病D2有治疗效果。
同时,如果使用上述的分析方法,不考虑药品集,只对疾病集进行关联分析,可以得到某些疾病与疾病之间的关联关系,也就是能得出患者患有某种病的同时会患有的并发疾病。采用部分数据进行分析测试过程及结果如图6所示:
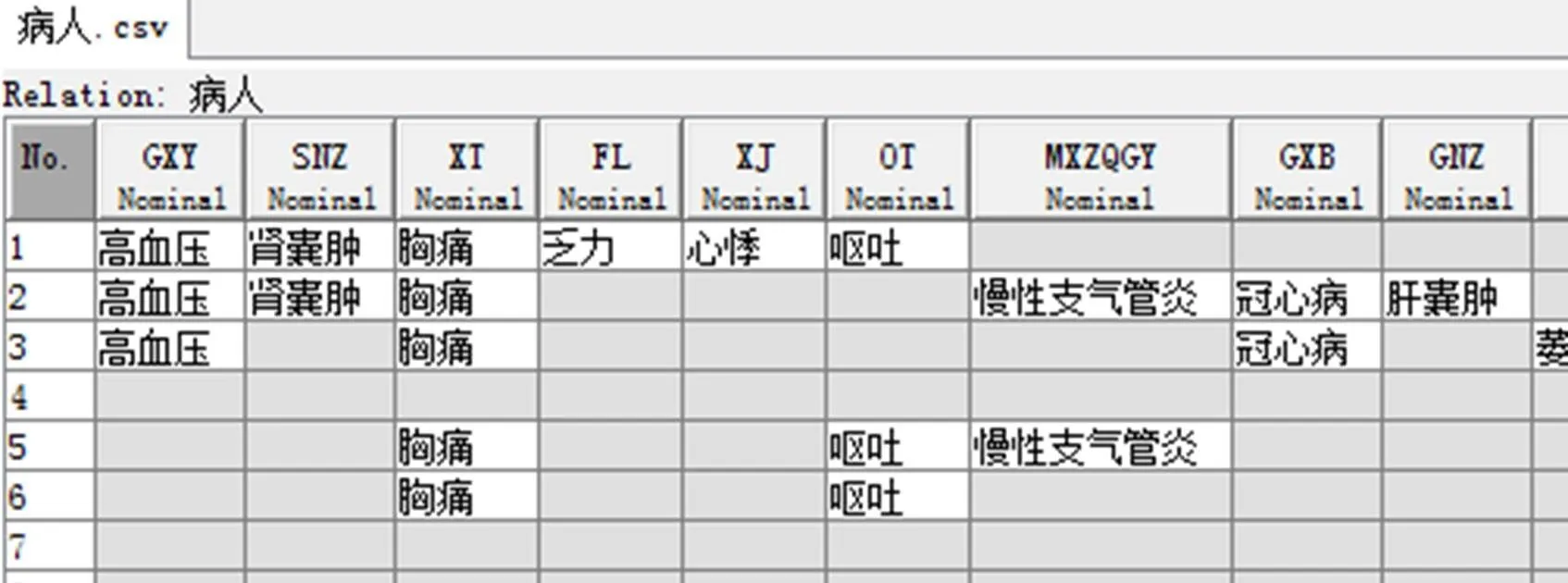
图6.从病历中提取出的部分疾病数据
数据关联分析过程采用weka分析工具,输入的数据格式如图6,每一行表示一个实例,这里表示一个病例,每一列代表一种属性,表示一种疾病,如果病例未患有该疾病,则使用空白格表示。
采用关联规则挖掘的Apriori算法,各步骤如下:
(1)从包含属性值数量为1的候选集中选出支持度大于minSup的候选集L1;
(2)将L1中的候选集两两组合,仍然选取出其中支持度大于minSup的候选集L2;
(3)再将L2中的候选集两两组合,继续选取出其中支持度大于minSup的候选集L3:
(4)不断将上一步产生的候选集中的每一行两两组合,并选取出其中支持度大于最小支持度的属性集合,直至不能产生新的候选集。最终结果如图7所示。

图7.关联规则挖掘的结果
对挖掘出的规则进行分析,如{高血压}→{胸痛},验证发现高血压本身并不会导致患者出现胸痛的症状,而这条规则出现的原因是高血压容易诱发冠心病等心血管疾病,这些诱发疾病则会导致胸痛症状的产生。
基于上述结果,虽然由于无关数据的干扰,产生的规则并不是全部有意义的,如图7中的第2条规则{呕吐}→{胸痛}、第10条{梅毒}→{肝炎}(这两者只是医院对病人采用的常规检查,病人并未患有)等等,但上述结果中出现的高血压、肾囊肿、冠心病、胸痛等的关联规则,在临床现象中确实存在。所以文章使用的挖掘流程和方法对医院的病历文本进行处理分析是确实可行的,能够挖掘出有价值的信息。
4 结 论
文章探讨电子病历中的有效信息挖掘问题。比较了四类中文分词器的优劣,采用词典扩充技术,在其中添加药品名称,挖掘了电子病历中的疾病与药品信息,并进行关联分析,发掘有价值的规则。实验结果表明,该方法对于电子病历的信息挖掘是行之有效的。
[1]Jiawei Han,Micheline Kamber,Jian Pei.数据挖掘概念与技术[M].北京:机械工业出版社,2012.
[2][土耳其]Ethem Alpaydin.机器学习导论(原书第2版)[M].北京:机械工业出版社,2014.
[3]余辉,吕扬生.数据挖掘在生物医学领域的应用[J].国外医学生物医学工程分册,2003,(2):54-59.
[4]何军,刘红岩,杜小勇.挖掘多关系关联规则[J].软件学报,2007,(11):2752-2765.
[5]何月顺.关联规则挖掘技术的研究及应用[D].南京航空航天大学,2010.
[6]朱凌云,吴宝明,综述,曹长修,审校.医学数据挖掘的技术、方法及应用[J].生物医学工程学杂志,2003,(3):559-562.
[7]胡灵芝.数据挖掘方法及其在医学领域中的应用[J].辽宁中医药大学学报,2010,(7):51-52.
[8]江菊琴.医学数据挖掘综述[J].电脑知识与技术,2011,(15):3495-3497.
[9]孙铁利,刘延吉.中文分词技术的研究现状与困难[J].信息技术,2009,(7):187-189.
[10]龙树全,赵正文,唐华.中文分词算法概述[J].电脑知识与技术,2009,(10):2605-2607
[11]Steven Bird,Ewan Klein,Edward Loper. Natural Language Processing with Python[M].O’Reilly Media,Inc.,2009.
[12]Wang S,Paul M J,Dredze M. Exploring Health Topics in Chinese Social Media: An Analysis of Sina Weibo[C]//Workshops at the Twenty-Eighth AAAI Conference on Artificial Intelligence.2014.
[13]Paul M J,Dredze M.Drug Extraction from the Web:Summarizing Drug Experiences with Multi-Dimensional Topic Models[C]//HLT-NAACL.2013:168-178.
[14]Paul M J,Dredze M. Discovering health topics in social media using topic models[J].PloS one,2014,(8):e103408.
[15]黄翼彪.开源中文分词器的比较研究[D].郑州大学,2013.
(责任编校:何俊华)
TP391
A
1673-2219(2016)10-0054-06
