基于用户数据的个性化推荐模块的设计与实现
2016-12-06张宇航
张宇航
(华中科技大学 软件学院, 湖北 武汉 430074)
基于用户数据的个性化推荐模块的设计与实现
张宇航
(华中科技大学 软件学院, 湖北 武汉 430074)
面对繁杂的信息海洋,从中获取准确的信息资源、提高信息利用率,是一个需要认真考虑与解决的问题.文章以云端趣码网站数据为基础设计个性化推荐模块,分析用户日常行为数据,得到用户关键字并存入数据字典;完成对其中数据和课程数据的矩阵映射处理,直观地呈现出用户对各种编程语言的偏好度;计算用户和课程关键字之间的余弦相似度距离,得到用户对各具体课程的感兴趣程度,相似度越大感兴趣程度越高;最后系统推荐相似度最高的课程.把云端趣码平台对用户的提问、回答和日志数据的处理,视为用户数据并作为个性化推荐的基础,经测试云端趣码的个性化推荐模块的性能及流程,验证了该模块的可用性和有效性.
用户数据;个性化推荐模块;数据字典;余弦相似度
随着Web2.0技术的快速发展、互联网信息大爆炸时代的到来,每天出现覆盖面广、涉及各个领域、信息冗杂的大量数据,如淘宝数十亿的产品,亚马逊数以百万计的书籍,Facebook数以亿计的照片等[1].信息时代带来便利的同时,也不得不面对海量信息的烦恼,不管浏览要闻还是网站购物及寻找问题答案,从繁多的数据中无法捕捉、难以获取真正的有用信息,反而对信息的利用变得更低.这种信息超载问题,目前常用的解决方法是以搜索引擎为代表的信息检索,典型的如百度、谷歌等,在帮助用户获取有效信息中发挥着重要的作用.但是,用户对信息需求呈现多元化、个性化,搜索引擎提供的信息却呈现大众化,往往无法满足每一个用户的精确需要、解决信息的超载问题.而个性化推荐则根据用户的具体需求、特点、兴趣爱好,通过相似度的合理计算,为使用者生成合适的推荐内容.因此,笔者通过对云端趣码的个性化推荐模块的设计利用来实现用户的个性化推荐,让用户更好更充分地享受高速网络所带来的便利.
1 个性化推荐的技术基础
1.1 信息检索技术
信息检索的一般过程:首先分析检索内容,根据相关数据选择合适的检索关键字,通过语言组织检索语句[2],然后进行信息检索并得到目标结果.早期信息检索一般采用“标准布尔查询”方法,但是,使用这种方式查询会构造一个合适的查询任务推到用户上去,文档查询结果只有匹配与不匹配两种情况,导致布尔查询的实际效率并不高.向量空间模型是通过检索词的加权来提高检索效率,可以根据文献相似度排序从而便于用户选择.
1.2 推荐算法
基于内容的推荐算法 是以用户操作内容为基础的推荐算法,不需要参考用户对内容的认可程度,而是通过机械学习方式,在众多内容的特征事例中找到用户关键字,即用户感兴趣的事物[3].在类似这种推荐过程中,会事先提炼出推荐内容特征即用户感兴趣的点,根据对用户关键资料及相关课题的关键字资料的匹配程度进行个性化推荐.确立用户关键字模型主要取决于推荐模块所采用的方法.该方法需要提供用户的历史操作内容,用户关键字随着用户而改变.如看了《生化危机》第一部,上述算法会推荐《生化危机》后续作品,其推荐内容与之前的操作内容 (共有很多关键词)有很大的关联性.该推荐算法的好处是避免了冷启动,缺点是产生重复的推荐内容.
协同过滤推荐算法 是以用户之前提供的偏好,再结合偏好相近用户的选择来进行个性化推荐的算
法.如图1所示.协同过滤推荐算法用m×n的矩阵表示使用者对某一内容的偏好情况,一般用打分表示用户的喜好程度,数值越高则感兴趣程度越高,0表示与某内容没有过交互[4].算法包括两个步骤:1)预测;2)推荐.预测用户对未购买过内容的可能分数值,推荐则是向用户推荐预测数值最高的内容.
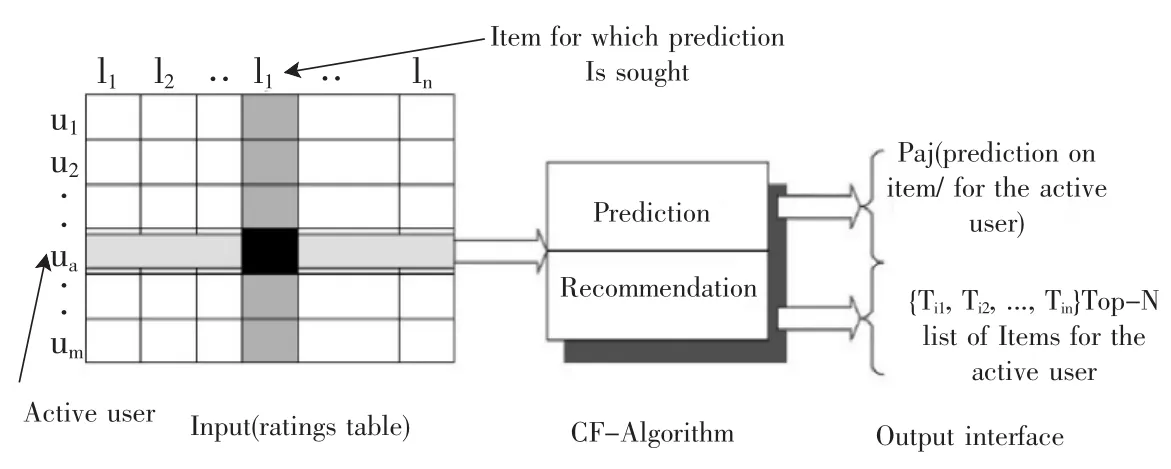
图1 协同过滤算法
推荐算法比较 基于内容的推荐算法方便易用,能较好地解决冷启动推荐系统中存在的问题;不需要用户全部数据,依据用户资料得到的关键字进行推荐,适用于数据繁杂的系统推荐.其缺点是不能为用户贴心地推荐可能感兴趣的内容,只能在已有数据的基础上完成相关推荐,易于重复产生推荐内容.协同过滤算法的优点在于能够推荐诸如音乐、绘画等一些机器无法自动分析的内容,具有创意性,给人耳目一新的感觉;可以对如“品味”等难以用语言描述的概念进行过滤.但是,协同过滤推荐算法对冷启动问题未能有效解决,可拓展性也不高,随着推荐内容的增加性能会变得越来越低下.
2 推荐系统分析与设计
2.1 推荐系统功能需求
本系统是基于云端趣码网站的个性化推荐模块,云端趣码本质上是一个提供课程、问答、可在线编程的网站,可以边学边练在线编译.个性化推荐模块根据用户的日常提问、回答以及学习课程等日志,通过推荐算法分析为用户贴心地推荐可能需要的内容.
输入:用户所写日志,提问以及回答内容.输出:显示推荐内容.
处理过程如图2所示.个性化推荐模块会根据使用者日常提问、回答及日志等原始数据,利用词向量工具拓展用户关键字词,依据关键字词计算出用户可能感兴趣的内容并显示推荐结果.

图2 个性化推荐模块流程
2.2 推荐系统性能
1)时间性能:系统处理能力支持并发数50个;响应速度小于10s.2)系统开放性:基于主流的在线编译网站,具备良好的可移植性、功能和性能的可扩展性.3)界面友好性:系统界面风格一致、操作简洁、指令清楚、操作流清晰、布局大方.4)系统可用性:具有较高的数据准确率和有效性,数据信息具有真实价值,避免冗余或无用数据;较快的响应速度(本地操作2s内,服务器操作5s内);5)系统健壮性:在系统出错时提供相应的处理机制,避免当机或程序崩溃.6)可管理性需求:系统开发严格依据相关文档,严格执行需求控制和跟踪.
2.3 推荐系统设计
云端趣码系统主要由用户模块、课程模块、问答模块、管理员模块、在线编程模块以及个性化推荐模块构成.本系统采用B/S三层架构设计:前端表示层、业务逻辑处理层、数据持久层.前端表示层的主要功能是向用户显示推荐内容,只有少量用户交互操作的界面元素,方便用户使用系统,主要由DIV,CSS控制和ASP.NET控件组件实现.业务逻辑层主要负责用户和管理员对网站操作的所有业务逻辑,主要由ASP.NET和JAVA语言实现.数据持久层主要由SQL和服务器存储来实现业务逻辑层和数据库之间的数据交互,让信息数据在页面流通.
2.4 个性化推荐模块设计
个性化推荐模块从用户的提问、回答、日志中收集原始数据.通过收集关键字得到相关用户的关键字词,再根据推荐算法实现个性化推荐.用户通过交互界面提示操作得到相关推荐信息或访问数据.个性化推荐模块主要由3个小模块构成:用户数据处理模块、课程数据处理模块、推荐模块.
用户数据处理模块 用户通过账号登录云端趣码网站进入个性化推荐模块,点击用户数据按钮获得包含
用户提问关键字、用户回答关键字、用户日志关键字的表单.用户数据处理模块主要涉及用户提问、回答、日志等相关数据.在用户查询时,根据其固有的ID在数据库中对提问表、回答表以及日志表进行查询操作,并将得到的数据呈现出来.用户点击表格中的提问ID、回答ID以及日志ID来继续下一步工作.
课程数据处理模块 用户通过账号登录云端趣码网站进入个性化推荐模块.点击课程数据按钮可获得已经录入云端趣码网站的课程名称和关键字的表单;通过课程信息查询得到的课程关键字表并获取自己感兴趣关键字的相关课程;经过表单中的课程信息跳转到相应的课程界面了解相应课程和学习操作.课程关键字主要包含了JAVA、C语言、C++、C#等,涵盖了大部分用户需求的学习内容.
推荐模块 用户通过账号登录云端趣码网站进入个性化推荐模块.点击推荐按钮可获得该个性化推荐模块,通过对用户数据及课程数据的分析得到推荐内容.
2.5 个性化推荐模块的数据库设计
本系统对用户数据(主要包括用户的提问、回答、日志)分析后,采用MySQL作为推荐模块的数据库来存储系统数据,为推荐算法的调用和新加入的用户数据提供存储.数据库设计包括基于用户数据的用户信息表和模块推荐信息.
基于用户数据的用户信息表 用户日常产生的数据主要记忆在提问、回答日志上,它们是推荐环节的信息来源,通过数据采集分析,向用户推荐感兴趣内容的相近信息.用户表、用户问题表、用户回答表、用户日志表、用户关键字表如表1、表2、表3、表4、表5所示.
表1定义用户ID、用户昵称以及用户名和密码;表2定义用户提问ID、内容、日期以及问题标题;表3定义用户回答的ID、内容、日期;表4定义用户日志ID、内容、日期;表5定义用户关键字,Key字段类型为Char,内容为课程名称.
模块推荐信息 本模块依据云端趣码网站上的编译系统及不同语言:C语言、C++、JAVA、C#、VC、SQL等,通过收集和整理日常用户信息得到用户关键字,利用用户课程表得到用户的推荐信息,向用户推荐可能感兴趣的内容.用户课程表设计如表6所示,其中课程ID是课程的唯一识别数据,Ltype是课程语言关键字,通过这一关键属性向用户推荐相关课程.以上字段均根据相关含义分配相应字段.总之,本模块是通过比较用户数据关键字以及课程信息关键字得到相关推荐信息;用户字典是用户关键字集合,课程字典是所有课程关键字集合.
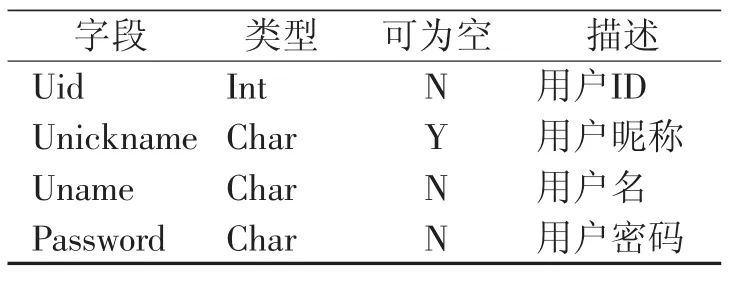
表1 用户表
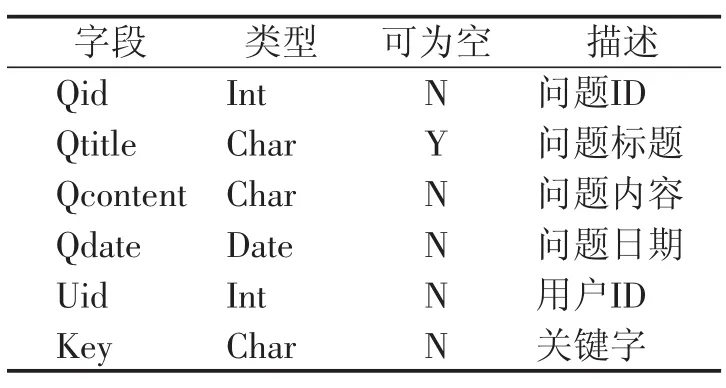
表2 用户问题表
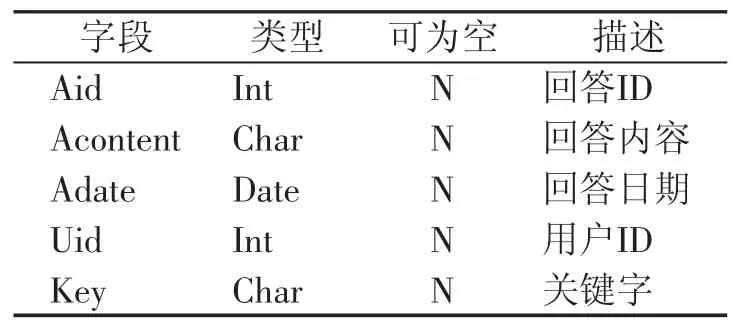
表3 用户回答表
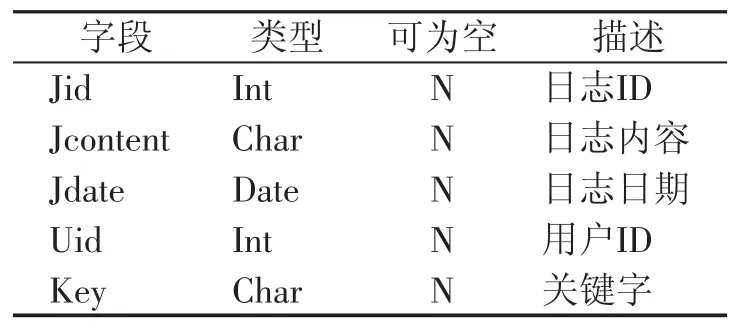
表4 用户日志表
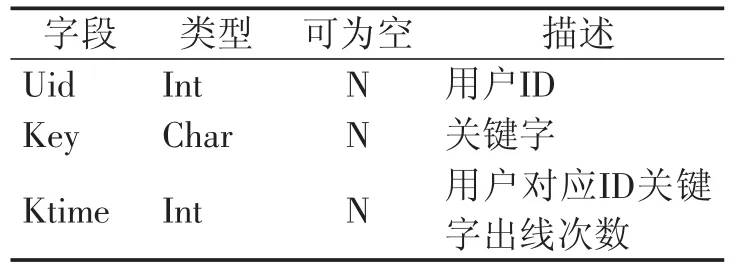
表5 用户关键字表

表6 用户课程表
3 个性化推荐模块的实现
3.1 用户数据处理模块
本模块是云端趣码的个性化推荐模块,处理数据主要有3个方面:用户提问数据;用户回答数据;用户日志.本文采用的用户数据处理方式,主要通过用户ID在数据库中查找其所有提问数据、回答数据及日志数据的关键字得到一个用户关键字词表.
3.2 课程数据处理阶段
本模块是云端趣码的个性化推荐模块,将每个课程关键字即语言类型表示出来,通常用0和1表示课程对应的关键字,是则关键字标为1,其余标为0.该问题用向量表示:a[]={0,0,0,1,0,…,0,0}.
3.3 个性化推荐
通过对用户数据和课程数据的处理,可得到2组关键字数据,算法分为3步:1)为用户构造一个关键字资料;2)为课程构造另一个关键字资料;3)计算用户关键字资料与课程关键字资料的相似度,相似数值越高则用户对该课程越感兴趣,反之则越低.以本模块为例,要向用户推荐可能感兴趣的课程,其影响用户偏好程度的关键字就是语言类型.

图3 个性化推荐算法流程图
个性化推荐算法流程如图3所示.由于课程关键字代码无法用自然语言描述,因此构造一个映射:首先构造一个1×N维矩阵,N表示本模块中课程语言类型的数量.将该矩阵的所有元素设置为0,可得到一个行向量:X=[0,0,0,..., 0]T,共有N个0.令行向量的第0个单元代表JAVA、第1个单元代表C语言、第2个单元代表C++、第3个单元代表C#、第4、5个单元分别代表VC和SQL.将自然语言描述的课程关键字映射到1×N维矩阵中,映射方式为包含该课程的语言标记为1,其余为0.如JAVA教程在矩阵中的JAVA位置为1,其余为0.例如某课程的0,1矩阵是X=[0,1,...,0]T,由于矩阵的第0个元素代表JAVA,而对应矩阵中第0个元素是0,因此JAVA不是该课程的关键字;同样地,由于C语言对应的矩阵中的第1个元素1,所以C语言是该课程中的关键字.但是仅仅通过对矩阵中0与1的映射,并不能直观的反映用户对具体课程的感兴趣程度,于是设计用户课程表如表7所示.

表7 用户课程表
其中每个用户对应的课程数量可反映出用户对该课程的感兴趣程度,通过分析用户提问和回答中课程信息的出现次数,可以直观地表示用户对该项课程的感兴趣程度.
不妨假设用户ID为x,用a1,a2,a3,.....aN.来表示课程1,课程2一直到课程N的感兴趣程度.利用公式:(∑xi-Avg)/n算出x对这些课程的共同点的喜好程度.Avg是该公式中计算出来的平均值,n是所有涉及到该关键字的课程.通过上述公式计算出的值可用来表示用户x对该关键字的感兴趣程度.结合前面结论可以得到一个用户x对于某种语言的最终感兴趣程度矩阵图.利用余弦相似度公式来计算给定的用户U和课程关键字I之间的距离.余弦相似度的值越大说明U越有可能喜欢I,余弦相似度的具体计算方法:.其中Ua表示用户U对语言a的喜好值 (平均值公式计算出的值);Ia表示课程I是否与语言a相关 (即课程关键字资料矩阵中对应的数值0或者1).最后,模块根据上述计算结果遍历整个关键字数据库,计算用户同每一个课程间的相似度,推荐相似度最高的课程.
4 推荐模块测试
4.1 功能测试用例
单元测试 对软件中最小的可测试单元进行检查和验证[5].单元测试中的单元合理解释:如C语言中的一个函数,或JAVA中的一个类.本模块的单元测试核心是检查模块的子模块设计,通过实验找到有效的功能结果和模块接口定义,发现不符合要求的模块与产生的代码错误信息.
网站启动测试 打开一个浏览器,在网址对话框中输入funchexi9.oicp.net:11298/Coding网址,进入云端趣码的主页面.
用户数据查询测试 1)在客户端浏览器中输入上述云端趣码网址进入该网站.2)用户登录:在登录对话框输入账号密码及验证码.若密码及验证码正确就出现站点管理页,错误则返回登录框.3)点击推荐模块,即可进入个性化推荐模块.4)点击用户数据查询按钮,呈现该用户的提问、回答、以及日志ID和相应关键字.
4.2 性能测试用例与结果
在测试系统并发性能时,当并发用户达到300,绝大部分系统操作响应时间均未超过5秒,系统资源
占用率低于65%[6].在测试系统吞吐量过程中,当系统并发用户增加时,系统请求响应时间会增加,此时系统吞吐率随着用户数的增加而增大;当并发用户超过系统的最大处理能力时,系统吞吐率下降,原因是请求过多会导致服务器阻塞.对于系统性能测试从压力测试与并发处理测试展开,从10个最多递增到100个线程,在系统运行过程中模拟相应数目的并发用户;每个用户循环发送请求50次,测试结果如表8所示.
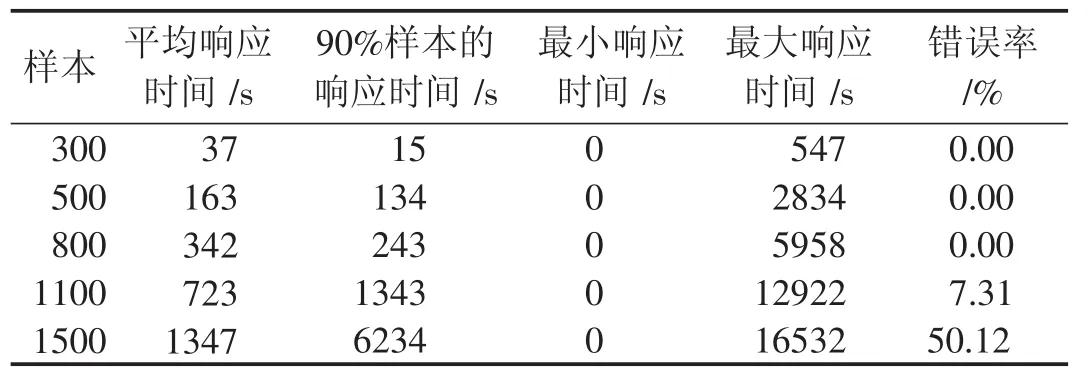
表8 压力测试结果
系统性能取决于两个方面:一是系统设计,业务处理、数据库存储;二是系统的硬件设备部署.它们均可从硬件资源占用和请求应答等方面表现出来[7].本系统采用25个客户端连续访问8个小时,从表8可知用户响应时间、CPU处理时间等信息.在25个用户的高强度测试下,CPU响应系统请求时间在40%左右;每秒钟从硬盘调用页面次数25次左右;硬盘为读写请求提供服务所用时间30%左右.这些性能数据表明系统运行良好,达到预期目的,系统可以进入试运行阶段.
测试结果表明,个性化推荐模块需求分析中所要求的功能均基本实现,系统运行正常,能够为用户提供推荐内容.少数情况下出现页面响应较慢现象,一方面由于网络原因导致,另一方面可能由于与数据库连接配置或安全性配置等问题所致,接下来将一步测试和完善系统性能.
本文以飞速发展的信息时代所产生的信息超载为基点,提出个性化推荐系统方案来解决信息过量化导致的利用率降低的问题,设计的个性化推荐模块以云端趣码网站数据为基础,对用户日常行为数据进行分析,得到用户关键字存入数据字典中,完成对其中数据和课程数据的矩阵映射处理,直观地表现出使用者对每种编程语言的偏好度.由计算用户和课程关键字之间的余弦相似度距离得到用户对每门具体课程的感兴趣程度,从而生成相关推荐内容.通过云端趣码平台对用户提问、用户回答和用户日志数据的处理,作为基于用户数据的个性化推荐基础,经过对云端趣码的个性化推荐模块的性能及流程的测试验证了该模块的可用性和有效性.本研究是对个性化推荐的基础设计与初步运用,对推荐过程和结果的优化完善有待于进一步研究.
[1]孟凡琦.基于查询的论文参考文献个性化推荐系统研究[D].天津:天津大学,2014:1-7.
[2]丁振国,陈 静.基于关联规则的个性化推荐系统[J].计算机集成制造系统,2003,9(10):891-893.
[3]刘建国,周 涛,郭 强,等.个性化推荐系统评价方法综述[J].复杂系统与复杂性科学,2009,6(3):1-10.
[4]刘建国,周 涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[5]胡迎松,韩 苹,陈中新.一个基于Agent的个性化推荐系统[J].计算机应用研究,2006,23(4):78-80.
[6]贾忠涛.基于协同过滤算法的电影个性化推荐系统设计与实现[J].软件导刊,2015(1):86-88.
[7]张锦歌,夏敏捷,樊银亭.基于Android移动图书馆个性化推荐系统设计与实现[J].电脑编程技巧与维护,2014(21):33-34.
Design and Implementation of Personalized Recommendation Model Based on User Data
ZHANG Yuhang
(College of Software,Huazhong University of Science and Technology,Wuhan 430074,China)
Nowadays,with the development of Internet technology,countless information flow is affecting our daily work and life.Consequently,to improve the utilization of information and access information resources which we need has become an urgent problem.With this question,the article implements a personalized recommendation module based on user data.Based on coding the clouds website,the article firstly sets up the database and data dictionary,which analyzes the user’s daily behaviors,and gets the user’s key words in the data dictionary.Then it mapped the user’s interest in the each keyword,calculated the distance between the user and keywords of the course.At last,this system recommended the courses with the highest similarity.By making full use of user’s daily questions and answers,we can obtain the foundation of personalized recommendation.Finally,the article figures out that this system is feasible and effective.
User data;Personalized recommendation;Data dictionary;Cosine similarity
TP317
A
2095-4476(2016)11-0026-05
(责任编辑:陈 丹)
2016-10-08;
2016-10-25
张宇航(1995—),男,湖北襄阳人,华中科技大学软件学院硕士研究生.
