一种深度图的时域下采样编码及重建方法
2016-12-06肖依凡李凤荣
葛 川,刘 琚,2,元 辉,,肖依凡,李凤荣
(1.山东大学信息科学与工程学院,山东济南 250101;2.山东大学苏州研究院,江苏苏州 215123; 3.中国科学院上海微系统与信息技术研究所无线传感网与通信重点实验室,上海 200050)
一种深度图的时域下采样编码及重建方法
葛 川1,刘 琚1,2,元 辉1,3,肖依凡1,李凤荣3
(1.山东大学信息科学与工程学院,山东济南 250101;2.山东大学苏州研究院,江苏苏州 215123; 3.中国科学院上海微系统与信息技术研究所无线传感网与通信重点实验室,上海 200050)
为提高三维视频系统的编码效率,提出了一种针对中间视点的深度时域下采样编码方法.首先确定深度图像的丢弃方式;然后利用基于时间一致性和视点间的相关性,恢复出丢弃的深度图像,并对恢复出的结果进行维纳滤波,进一步提高恢复的深度图的质量.该方法需要向编码端发送维纳滤波器系数和重建深度选择标识符.实验结果表明,在保证同等码率的前提下,解码端重建的虚拟视图的峰值信噪比最大能提升0.229 dB,平均提升0.130 dB,编码性能得到改善.
视频编码;立体图像处理;深度图时域下采样;时间一致性;视点间相关性
随着数字多媒体处理技术以及显示技术的发展,人们对真实视觉体验的需求日益增强,三维视频(3-Dimensional Video,3DV)已成为新的研究热点.相对于传统视频,三维视频可以给观众带来真实三维场景的视觉体验,并广泛应用于各个领域,极大地丰富了现有的媒体内容[1].
在现今的研究和应用中,三维视频的数据格式主要分为多视点视频(Multi-view Video,MV)格式和多视点视频+深度(Multi-view Video+Depth,MVD)格式两种.前者只能提供有限数量视点的三维体验[2],而后者可用于基于深度图像的生成技术[3]合成中间任意视点的虚拟视频,因而MVD数据格式被选作制定三维视频编码标准的数据格式,并被广泛应用.
在三维视频应用中,深度信息有其特定的特点和应用.首先,深度图是单色图且只包含有平滑的纹理区域以及尖锐的边缘区域;然后,与多视点纹理视频相比,深度图对合成的虚拟视图的质量影响较小;接着,与深度图的平滑区域相比,深度图的边缘对于合成虚拟视图的质量的影响较大;最后,深度图的编码目标是为了保证绘制高质量的虚拟视点,而非用于用户的视觉体验[4].因此,利用MVD表征一个立体场景并利用传统的多视点编码标准来进行编码,虽然已经减少了相当大的数据量,但是这并不能为多视点内容提供具有成本效益的压缩率,故研究适应深度图自身特点的编码技术显得至关重要.为了提高深度图编码效率,文献[5-6]中提出了基于虚拟视图质量的率失真优化算法;文献[7]中提出了一种深度图编码解析算法,它不仅可以对简单而平滑的纹理区域进行有效编码,同时能够有效地保护深度图的尖锐的边缘区域.此外,研究人员在文献[8-9]中提出了深度图的下采样编码方法.文献[8]中利用一种空间重建滤波器以及空间的下采样及上采样方法来提高深度图的编码效率;文献[9]中则是提出了一种深度时域下采样的MVD编码方法.
由于深度图与纹理视频对虚拟视点的不同影响,笔者提出对中间视点的深度进行时域下采样编码的方法.该方法考虑到视点内的时间一致性以及视点间的相关性信息,首先分析确定深度时域下采样方式,然后提出一种基于深度信息传播的深度图时域上采样恢复方法.
1 多视点视频编码结构
以高性能视频编码(High Efficiency Video Coding,HEVC)标准的多视点视频编码平台(3D-HEVC)为例,MVD数据包括左视点、中间视点和右视点3个纹理视频以及相应的深度图,如图1所示.左视点作为参考视点(可独立编解码),其他视点则依赖于参考视点进行编码.所有的纹理视频和深度图都是通过分等级B帧的时间预测结构进行预测的.
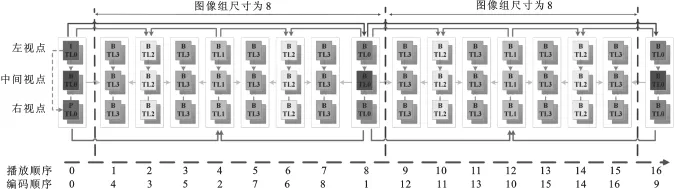
图1 具有4个时域增强层的可分层B帧编码结构,时域层从高到低依次为TL0,TL1,TL2和TL3
在同一视点内部帧间预测时,采用运动补偿预测(Motion-Compensated Prediction,MCP);在视点间预测时,采用视差补偿预测(Disparity-Compensated Prediction,DCP).在分等级B帧结构中,每8帧作为一个图像组(Group Of Pictures,GOP),图像组的第1帧图像称为关键帧.具体的预测方式如下:关键帧处于最高时间层(记为TL0,对应于0层),需要利用最高保真度进行编码.对于一个需要进行运动补偿预测的时域层的帧(假设时域层为TL2),只有更高的时域层的帧(时域层为TL0或TL1)或者是相同时域层的帧(时域层为TL2)才可以被用于作为参考帧.这时,所有的关键帧(时域层为TL0的帧所构成的序列)就是所支持的最低时域分辨率.
2 深度图时域下采样及重建方法
首先对编码结构进行分析从而决定以何种方式对深度图下采样,进而降低深度图编码比特率.接着,被丢弃的深度图将会通过深度信息传播的内插法,并加以维纳滤波后处理进行重建.
2.1深度时域下采样结构
图1中,TL0层的所有帧进行时域独立编码,因而这些帧的保真度通常比其他时域增强层(TL1,TL2和TL3)要高,同时,根据编码顺序可以得出,编码失真是由TL0向TL3逐层传递的.层数越高,此层继承的编码失真越大.基于此,笔者提出的深度时域下采样方法通过舍弃这些中间视点的最低时域层的深度图来实现.即图1中,中间视点的时域增强层TL3的所有深度图均被丢弃,但是其左视点以及右视点的深度图则按原有时间分辨率进行编码.
2.2丢弃的深度图的重建
丢弃的深度图是通过3种不同的深度图预测值非线性融合重建的.3种不同的深度图预测值分别为前向时间一致性深度图预测值,后向时间一致性深度图预测,视点间相关性深度图预测值.3种深度图预测值进行非线性融合,得到高质量的预测结果.
2.2.1前向及后向时间一致性的深度图估计
为了高质量地重建丢弃的深度图像,对于中间视点,时域上顺次两两相邻的深度帧之间,应当首先获得基于像素的前向运动矢量场(Forward Motion Vector Field,FMVF).文中的运动矢量场是基于编码端和解码端解码重建的纹理视频,采用一个改进的光流算法来计算得到的[10].

图2 解码重建图像与标记不可靠区域的二值图像对比
(1)初始像素深度值分配.对于中间视点丢弃的深度图的像素值,首先利用未被丢弃的深度图的像素值以及前项运动矢量场进行初始化分配.在被丢弃的深度图中,由于遮挡或者一些不可靠的前向运动矢量影响而形成的没有深度值分配的像素位置,共同构成了深度不可靠区域.笔者将这些不可靠区域在二值图中用黑色像素点进行标记.解码后的图像与二值图像的对比如图2所示.
(2)针对深度不可靠区域的外推.笔者采用外推法获得不可靠区域像素点的深度值.为了便于描述,将深度可靠点与深度不可靠点构成的区域分别记作θD和φD.对于不可靠区域φD中某一个的深度不可靠点φD,它在中间视点的解码重建的纹理图中对应于点φT.对φDest的深度值估计可通过对其局部窗口内可测点进行加权平均得到,计算方法如下:

其中,ωi是加权因子,N是以φD为中心的局部窗口(大小为W×W,记作ΩD)内的可靠点数,i∈{1,…, N}的数量.同时,可以在中间视点解码重建的纹理图中找到对应的像素点及对应的局部窗口ΩT.加权系数ωi可以通过相对应的解码重建的纹理图的亮度信息获得,计算方法如下:
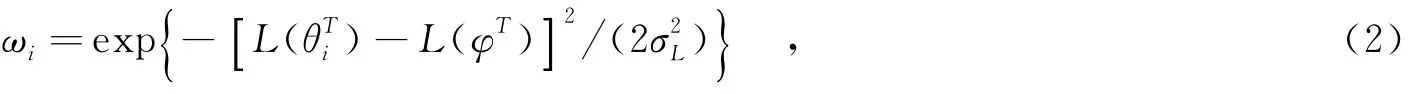
为了获得被舍弃的深度帧的后向时间一致性深度预测算子,必须得到中间视点的连续时间深度图的后向运动矢量场(Backward Motion Vector Field,BMVF).与前向方法类似,可以根据获得的后向运动矢量场产生后向的时空一致性深度预测.
2.2.2基于多视点对应性的深度值预测
中间视点的多视点对应性深度图预测值是左视点以及右视点对应时刻的深度图通过三维变换而产生的[4].这种视点间三维变换的本质是坐标变换,即某一视点中的一个像素点可以投影到不同视点图像中坐标中的另一点.
在一个双视点系统(左/右相邻视点与中间视点两个视点)中,一个任意的三维世界坐标系中的点M(坐标值为(X,Y,Z)T),它在相邻视点的投影点为m(其非齐次坐标值为(x,y)T),它在中间视点的投影点为m′(其非齐次坐标值为(x′,y′)T).在假设三维世界坐标系统等同于相邻视点的摄影坐标系统的坐标系时,m可投影到M,关系如下:
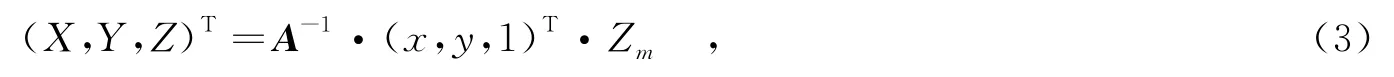
其中,Zm为m的深度值,矩阵A是相邻视点摄像机的3×3内参系数矩阵.M被投影到中间视点中的m′,如下所示:
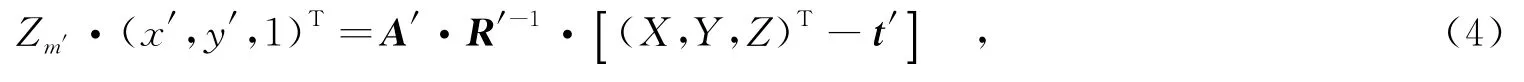
其中,Zm′为m′的深度值,矩阵A′是相邻视点摄像机的3×3内参系数矩阵,R′是中间视点摄像机的3×3内参系数矩阵,t′为中间视点摄像机的3×1的平移向量(tx′,ty′,tz′)T.由式(3)和式(4)推导可得
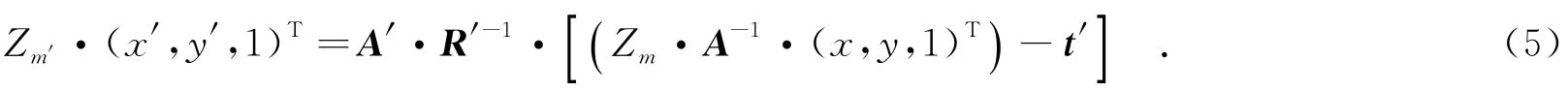
对于一个经过校准的双视点摄像系统,A′与A相同,R′与单位矩阵I相同.同时,由于中间视点摄像机和相邻视点摄像机通常是水平排列的,则Zm与Zm′相等且ty′,tz′分量均为零.内参矩阵A的第1行第1列元素A1,1存储的是摄像机矩阵焦距f,tx′为两个摄像机的基线距离l,则
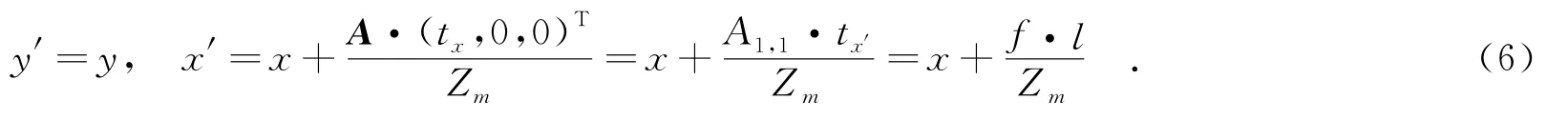
因此,考虑到不同视点间m和m′之间的关系,笔者利用编码系统中传输的摄像机参数及相应的深度图,通过式(6)完成坐标变换,从而形成中间视点的多视点对应性深度图预测值.
2.2.3深度预测值的融合及后处理
前向及后向时间一致性深度图预测值是通过时域一致性产生的,它在重建尖锐的深度过渡区域效果很好,但是它可能在某些深度平滑区域以及物体运动形成的空洞区域表现较差.基于视点间相关性的深度图预测值是通过三维变换得到的,极易受到强遮挡区域以及图像边界的影响,但是它预测平滑的深度区域表现出众.笔者最终对合成的深度图中的每一个16×16的块都在这3种深度预测值中进行选择.为了得到质量更好的中间视点质量,采用原始的中间视点的深度图作为参考,进行选择.因此,需要对每一个16×16的块用2 bit做标识(等于0、1或2),指明采用哪种预测值进行预测,此标识需传输至解码端用作重构解码.
为了进一步提高合成虚拟视图的质量,在深度图的重建过程中采用维纳滤波器[11]来提高重建深度图的质量.首先在编码端通过比较重构深度图与原始深度图来计算维纳滤波器系数;然后将滤波系数传送至三维视频系统解码端,如图3所示.

图3 笔者提出的三维视频系统框图
3 实验结果及分析
实验采用了6个标准视频序列:Book Arrival(1 024×768,16.67,49,6-8-10),Newspaper(1 024×768, 30,49,2-4-6),Kendo(1 024×768,30,49,1-3-5),Balloons(1 024×768,30,49,1-3-5),Lovebird1(1 024× 768,30,49,4-6-8)和Ghost TownFly(1 920×1 080,25,49,1-5-9),括号内分别为分辨率、码率、编码帧数、采用视点.在基于高性能视频编码标准的三维视频C编码平台8.0版本(3D-HTM 8.0)中进行结果验证[12].每个测试序列采用固定的纹理量化参数(Quantization Parameter,QP)进行编码.本实验采用了4对量化参数值对,分别为(32,18),(32,24),(32,30)和(32,36),与3D-HTM 8.0以及采用相同下采样的文献[9]中的方法相比较,来验证笔者所提算法的性能.
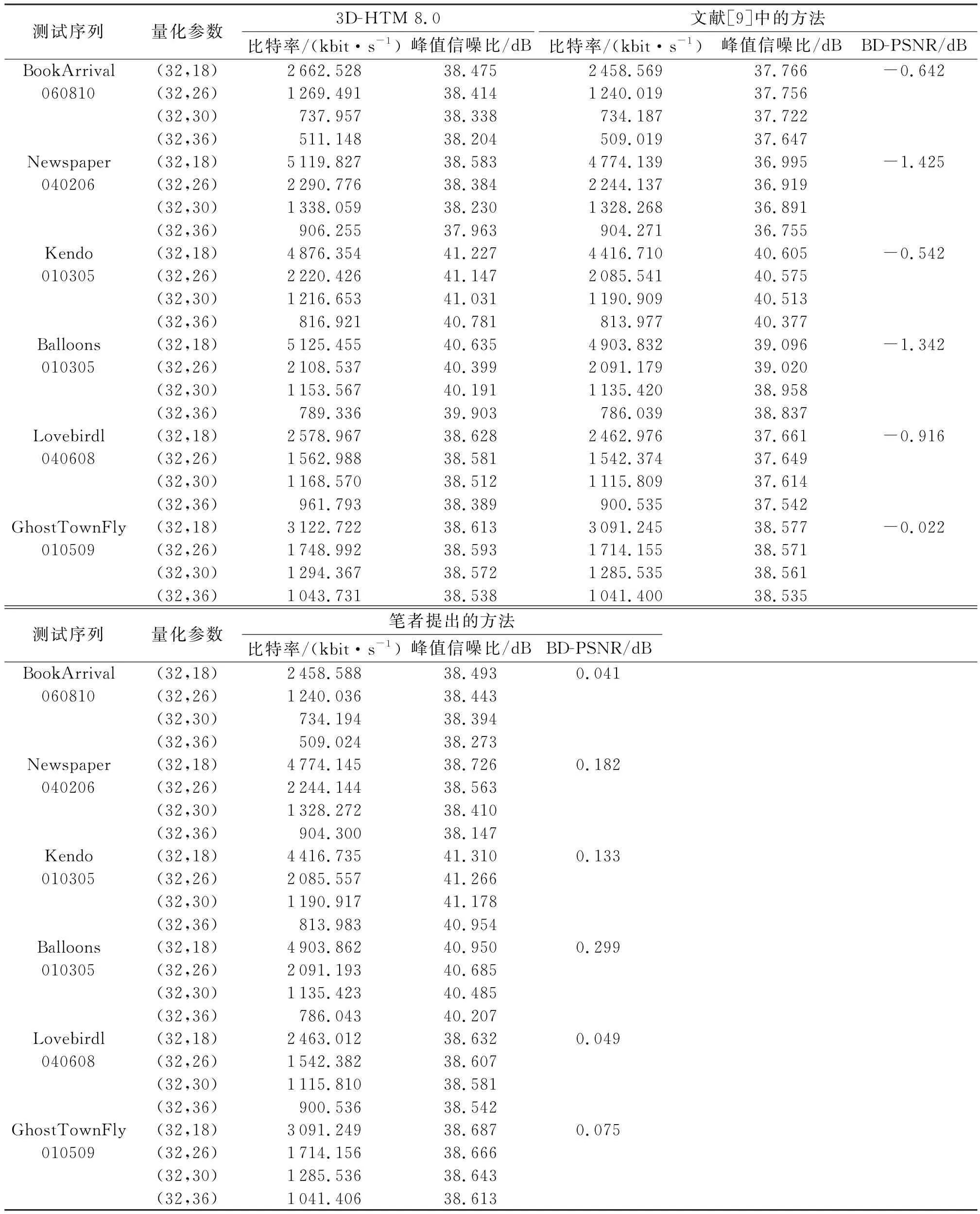
表1 实验结果
视点A表示左视点与中间视点合成得到的虚拟视点,视点B表示由中间视点和右视点合成得到的虚拟视点.采用图4所示比特率-质量曲线来评价所提方法的性能,其中纵坐标表示视点A及视点B的平均峰值信噪比(Peak Signal to Noise Ratio,PSNR),横坐标表示总的编码比特率.从图4可以看出,与3D-HTM 8.0、文献[9]中的方法相比,笔者提出的方法效果最好.

图4 三维视频系统框图
表1给出了具体的数值比较结果.其中Bjontegaard峰值信噪比(BD-PSNR)[13]表示在同样编码码率条件下,测试算法与参考算法(3D-HTM8.0)之间的峰值信噪比增益.虽然编码标识位的码率很低,但是笔者将其也算入了码率结果中.从表1可以看出,笔者提出的方法优于文献[9]中的方法;对于Balloons序列,笔者提出方法的BD-PSNR可达0.299 dB;对所有序列而言,BD-PSNR的平均值为0.130 dB.
4 总 结
笔者提出了一种针对中间视点的深度时域下采样编码方法.首先通过分析三维视频编码平台,确定深度图像的丢弃方式,然后提出利用时间一致性和空间一致性方法恢复出丢弃的深度图像,最后采用了维纳滤波的方法以提高恢复的深度图质量.在恢复深度图过程中,首先利用时间一致性得出前向、后向时间一致性深度图预测,利用多视点对应性得出基于多视点对应性的深度预测值,基于原始深度图对3个深度预测值进行融合.笔者提出的方法需要向编码端发送维纳滤波器系数和重建深度选择标识符.实验结果表明,在保证同等码率的前提下,解码端重建的虚拟视图的质量(峰值信噪比)能够得到有效的提升.
[1]GE C,LIU J,YUAN H.Optimizing Rate Allocation between Multiview Videos and Associated Depth Maps with Quantization-based Virtual View Distortion Model and Genetic Algorithm[J].Journal of Electronic Imaging,2014,23 (6):063016.
[2]马祥,霍俊彦,任光亮,等.利用视频和深度图相关性的深度图帧内编码[J].西安电子科技大学学报,2015,42(3): 1-7. MA Xiang,HUO Junyan,REN Guangliang,et al.Depth Map Intra Coding Based on Correlation Between Video and Depth Maps[J].Journal of Xidian University,2015,42(3):1-7.
[3]FEHN C.Depth-image-based Rendering(DIBR),Compression,and Transmission for a New Approach on 3D-TV [C]//Proceedings of SPIE:5291.Bellingham:SPIE,2004:93-104.
[4]YUAN H,KWONG S,GE C,et al.Interview Rate Distortion Analysis-Based Coarse to Fine Bit Allocation Algorithm for 3-D Video Coding[J].IEEE Transactions on Broadcasting,2014,60(4):614-625.
[5]YUAN H,KWONG S,LIU J,et al.A Novel Distortion Model and Lagrangian Multiplier for Depth Maps Coding[J]. IEEE Transactions on Circuits and Systems for Video Technology,2014,24(3):443-451.
[6]YUAN H,LIU J,LI Z,et al.Virtual View Oriented Distortion Criterion for Depth Maps Coding[J].Electronics Letters,2012,48(1):23-25.
[7]GRAZIOSI D B,RODRIGUES N M M,PAGLIARI C L,et al.Compressing Depth Maps using Multiscale Recurrent Pattern Image Coding[J].Electronics Letters,2010,46(5):340-341.
[8]OH K,YEA S,VETRO A,et al.Depth Reconstruction Filter and Down/Up Sampling for Depth Coding in 3-D Video [J].IEEE Signal Processing Letters,2009,16(9):747-750.
[9]EKMEKCIOGLU E,WORRALL S T,KONDOZ A M.A Temporal Subsampling Approach for Multiview Depth Map Compression[J].IEEE Transactions on Circuits and Systems for Video Technology,2009,19(8):1209-1213.
[10]LIU C.Beyond Pixels:Exploring New Representations and Applications for Motion Analysis[D].Cambridge: Massachusetts Institute of Technology,2009.
[11]YUAN H,LIU J,XU H,et al.Coding Distortion Elimination of Virtual View Synthesis for 3D Video System: Theoretical Analyses and Implementation[J].IEEE Transactions on Broadcasting,2012,58(4):558-568.
[12]JOINT COLLABORATIVE TEAM FOR 3DV.3D-HTM Software Platform[EB/OL].[2015-06-13].https://hevc. hhifraunhofer.de/svn/svn_3DVCSoftware/tags/.
[13]BJONTEGAARD G.Calculation of Average PSNR Differences between RD-curves[C]//Processings of 13th Meeting of the ITU-T Video Coding Experts Group.Austin:ACEG,2001:1-4.
(编辑:郭 华)
Temporal subsampling based depth maps coding and the reconstruction method
GE Chuan1,LIU Ju1,2,YUAN Hui1,3,XIAO Yifan1,LI Fengrong3
(1.School of Information Science and Engineering,Shandong Univ.,Jinan 250101,China;2.Suzhou Research Institute of Shandong Univ.,Suzhou 215123,China;3.Key Lab.of Wireless Sensor Network&Communication,Shanghai Institute of Microsystem and Information Technology,Chinese Academy of Sciences,Shanghai 200050,China)
In order to improve the coding efficiency of a three-dimensional video system,a depth temporal subsampling based coding method for the intermediate view is proposed.In this paper,the manner of how to discard depth frames is firstly determined.Then,those discarded depths are reconstructed utilizing temporal consistency and multiview correspondences.Finally,in order to further improve the quality of the reconstructed depth,the wiener filter is implemented on the reconstructed results.Filter coefficients and indicators for selecting the depth predictor should be transmitted to the decoder.Experimental results demonstrate that a maximum 0.229 dB and average 0.130 dB peak signal-to noise ratio(PSNR)gain could be achieved for the virtual view reconstructed by the decoder while maintaining the same coding bit rate,and that the coding efficiency can be improved.
video coding;stereo image processing;depth temporal subsampling;temporal consistency; multiview correspondences
TN919.8
A
1001-2400(2016)04-0160-06
10.3969/j.issn.1001-2400.2016.04.028
2015-06-29 网络出版时间:2015-10-21
国家自然科学基金资助项目(61201211,61571274);教育部博士点基金资助项目(20120131120032,20130131110029);山东省优秀中青年科学家奖励基金资助项目(BS2012DX021);中国科学院无线传感网与通信重点实验室开放课题资助项目(2013002);山东大学青年学者未来计划资助项目(2015WLJH39);苏州市科技计划资助项目(SYG201443)
葛 川(1985-),男,山东大学博士研究生,E-mail:gavinkeh.chuan@gmail.com.
刘 琚(1965-),男,教授,博士,E-mail:juliu@sdu.edu.cn.
网络出版地址:http://www.cnkinet/kcms/detail/61.1076.TN.20151021.1046.056.html
