H.264中逆量化逆变换的高层次综合实现*
2016-12-03陈新伟孟祥刚李国峰
陈新伟,孟祥刚,高 腾,陈 瑶,梁 科,李国峰
(1.福建省信息处理与智能控制重点实验室,福建 福州350121;2.南开大学 电子信息与光学工程学院,天津 300350)
H.264中逆量化逆变换的高层次综合实现*
陈新伟1,2,孟祥刚2,高 腾2,陈 瑶2,梁 科2,李国峰2
(1.福建省信息处理与智能控制重点实验室,福建 福州350121;2.南开大学 电子信息与光学工程学院,天津 300350)
逆变换与逆量化是H.264解码器中的一个重要环节,由于其算法复杂度较高,利用传统的RTL方法设计其硬件电路需要消耗大量的设计时间并经历复杂的验证过程。提出了采用高层次综合的方法进行高效快速的逆变换逆量化硬件模块设计。测试结果表明,该方法可以较快地得到针对FPGA平台的逆变换逆量化硬件模块,同时可对其设计空间进行有效探索,得到满足不同需求的硬件模块。
H.264解码器;逆量化;逆变换;高层次综合;设计空间探索
0 引言
H.264标准自公布以来,在视频会议、数字电视、视频监控等领域中得到广泛的使用。新一代视频压缩编码标准 H.264/AVC在以往标准的基础上做了很大的改进,从而具有了很高的压缩性能和网络自适应能力[1]。然而高压缩性能是以较高的算法复杂度为代价,尤其是变换与量化部分,其RTL代码设计与在FPGA平台上的实现也变得更为复杂。高层次综合技术相对于传统的RTL级设计能有效地降低硬件的设计复杂度,缩短设计周期。因其在算法硬件模块开发上的高效性,高层次综合工具已被广泛应用于复杂硬件项目开发中。
本文的设计在 H.264标准基础上,采用高层次综合技术,利用 C语言进行算法描述,通过高层次综合过程及其综合优化进行硬件生成,完成符合设计需求的硬件模块。
1 高层次综合技术
高层次综合技术可以将高级编程语言(C/C++等)的算法描述综合成RTL级代码,完成算法级到寄存器传输级的转换。高层次综合工具可以完成各个任务的寄存器分配、任务调度与绑定、状态机生成等功能。基于Vivado_HLS高层次综合的开发流程如图1所示。首先将设计完成的C/C++算法实现代码在 Vivado_HLS中进行编译,检查语法错误并验证代码的功能是否正确;之后,在增加相应优化设置的基础上进行综合;综合完成后进行RTL协同仿真,验证硬件功能正确性及时序需求;如果不能满足设计需求,则可重新更改优化条件进行综合。得到正确的RTL代码后可将其封装成IP核或直接导出RTL代码继续通过Vivado或者ISE等RTL综合工具完成传统 RTL设计流程[2]。
相对于C/C++编程语言标准,Vivado_HLS高层次综合工具支持其大部分语法,但高层次综合工具的输出针对于具体硬件电路的设计[3],因此,需要系统级支持的动态内存分配和二级指针等功能不能通过高层次综合工具进行综合,算法设计中需要避免此类语法和底层函数的应用。

图1 基于Vivado_HLS高层次综合硬件开发流程
2 H.264逆量化逆变换算法概述
变换与量化是根据图像像素之间的相关性来对数据进行压缩,不同量化参数的设置可以改变图像像素的动态取值范围。在H.264标准中对直流系数采用的是哈达玛(Hardmard)变换,对残差系数采用的是离散余弦变换(DCT),并且通过4×4分块的DCT变换降低图像的块效应[4]。量化部分采用的是标量量化,采用移位方法进行数据处理,从而避免除法与浮点数运算。
变换与量化是两个相互独立的过程,但在 H.264中,将两个过程合并在一起进行。其优势在于将DCT中的乘法运算提取出来合并到量化过程中,于是变换部分只进行整数的加法与移位运算,而乘法运算都在量化部分实现,从而减少运算量。因此逆变换逆量化模块实现变换与量化的逆过程。
H.264解码器中的逆变换逆量化实现流程如图2所示,对于含有直流(DC)分量的数据,先对其中的 DC系数进行逆哈达玛变换,然后对 DC系数与交流(AC)系数进行逆量化,然后对DC与AC系数进行重组,对重组后的数据进行逆变换(IDCT)。

图2 H.264逆变换逆量化实现流程
对于AC系数,逆量化方法如式(1)所示:

对于帧内16×16的亮度子块的DC系数,逆量化方法如式(2)所示:

对于色度信号的DC系数,量化方法如式(3):
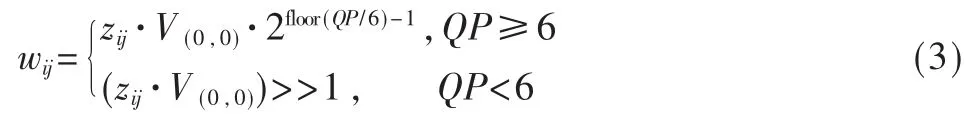
其中,QP表示量化系数,QP的取值直接影响视频压缩比,QP取值越大,视频压缩的压缩比越大,但信噪比会相应降低。
3 基于高层次综合的设计
3.1 算法实现
逆变换逆量化环节在解码器中所占的比重较大,同时该计算模块在解码过程中被频繁调用,而逆量化部分大量的乘法运算需要消耗大量的硬件资源。本设计的目标是在资源消耗量控制在一定限度的前提下提供尽可能高的数据吞吐量。
为了提高数据处理速度,达到硬件实现中对亮度信号(Luma)与色度信号(Chroma)的逆量化逆变换的并行执行。算法实现过程中分别为其设计单独的C函数并采用独立接口。输入数据包括帧内16×16亮度块、帧内4× 4亮度块以及2×2色度块,根据输入的数据类型选择相应的逆量化方法。
对于算法中的逆变换部分,将二维数组的变换转换成两次一维变换:先对数据进行一次行变换,对行变换后的数据进行列变换。H.264逆量化逆变换算法实现伪代码如算法1所示。对其中含有DC分量的数据,先进行逆哈达玛变换,然后再分别对 DC、AC系数进行逆量化;对于不含DC系数的数据则直接进行逆量化。最后对量化后的数据进行IDCT变换,输出相应的数据。
算法 1H.264逆量化逆变换的HLS设计

3.2 高层次综合优化
3.2.1 循环展开
对于C语言算法实现中的循环部分,默认状态下循环体内的操作是顺序执行的。为达到性能要求,在设计中的循环部分插入循环展开综合指示指令(UNROLL),高层次综合工具在综合过程中会将循环展开成并行的结构,在以资源消耗升高为代价的前提下使得单位时间内执行的操作数得到提升[5]。
3.2.2 流水线优化
流水线优化主要针对一系列顺序执行的任务,将其综合成多级流水线结构,从而提高数据吞吐量。对于本文的算法实现,为了实现资源的充分利用并降低整体的计算延迟,在循环展开的基础上,对相应模块的顶层或合适的位置加入了流水线(PIPLINE)优化指令。
3.2.3 数组分割
设计中存在大量的数组运算,默认情况下这些数组在综合中会使用成ROM或BRAM资源,由于ROM或BRAM一次能同时读写的数据个数有限,会造成运算过程中的延时[6]。因此,在以上两种优化的基础上,设计加入数组分割(ARRAY PARTATION)指令,从而指示高层次综合工具将大型数组按输入配置分割成多组小型数组,提升片上数据访问速度,从而更好地配合数据计算的并行执行。
以上优化处理的选择,遵循综合后分析输出结果,进行最直接优化的方法。循环展开目的在于增加循环内数据处理的并行度;流水线优化用以提升并行后数据处理的吞吐量;数组分割目的在于流水线增强后提升数据访问能力。
4 实验结果与分析
本设计所使用的高层次综合平台采用 Xilinx Vivado_HLS 2014.4版本,目标FPGA器件为Virtex-7系列的 xc7vx485tffg1761-2芯片,设置的时钟约束条件为10 ns,算法实现采用C语言,目标输出语言为Verilog。
经过不同优化方案后硬件模块的资源占用与模块执行的时钟延时如图3所示。

图3 不同优化方案下硬件模块资源与时钟延时综合结果
无优化时,FPGA片上各种资源消耗量均为最低,但模块数据处理的时钟延时确最高。因代码的主体以循环为主,为了在速度上得到较大的提升,最直接的方法就是将代码中的循环展开,实现对数据的并行处理。而图3中循环展开部分为对代码中的不同部分进行依次展开并得到综合后的结果。
由于反扫描模块在每个计算支路上都被采用,因此对反扫描进行循环展开有效地降低了模块的时钟延时数量,而没有消耗更多的硬件资源。其原因归结为反扫描部分只采用数据映射,因此其循环展开不消耗过多硬件却使得映射并发的执行。而算法中除了反扫描部分所呈现的映射外,还存在多个循环结构实现的数据映射,对其进行同样展开,结果与上文分析相同。
而对于 luma反量化和 chroma反量化部分,其计算单元主要以乘法为主,因此在进行循环展开后,DSP单元的消耗量有所升高。但两个循环的展开只分别降低了1.1%和0.4%的延时。这是由于这两个部分分别是多个数据通路中某个通路的一个中间单元,因此这两个模块的循环展开只是降低了单个通路上的时钟延迟,但对于顶层模块的总体时钟延迟没有产生足够影响。然而这不代表这两个部分的循环展开优化没有作用,在后面的其他模块展开后,这两个模块的优化会配合其他的优化而对数据通路的并行执行起到明显的作用。
在以上优化的基础上,对每个数据通路上都需要进行的IDCT模块进行循环展开。C代码描述算法中多个计算通路可以调用同一IDCT函数,然而在高层次综合过程中,会将多个函数调用综合为多个重复的相同功能模块。因此在对IDCT模块做循环展开后,时钟延时数量得到了明显降低,而IDCT模块的主体是加减法和移位,因此循环展开后资源的消耗并没有明显增高。由于整个反量化和反变换模块中,主要的计算消耗在于反量化模块中的矩阵乘法,因此对矩阵乘法做循环展开,DSP单元的使用量产生大幅的提升。
对Choma数据反量化模块的循环展开,相对于Luma数据的反量化循环展开,资源消耗增加了57%,相对于Luma数据处理部分的增加更加明显,其原因归结为Chroma数据的位宽较宽。相对于Luma数据反量化单元的展开,时钟延迟方面得到了明显的降低,多条数据通路的循环展开,使得整体模块的计算时钟延迟得到了降低,这一结果与上文对Luma数据反量化单元的循环展开分析结果相吻合。
最后对代码中剩余部分的循环体进行相应的展开操作,对应图中的全展开的数据结果,对整体时钟延时的提升不明显,硬件资源消耗略有升高。
循环的展开提高了数据处理的并行性,但是在硬件设计中数据路径上的并行并不能使硬件处理性能得到最大提升,因此对设计中多处位置插入了流水线的优化,从图中时钟延时曲线可以看出,流水线的加入使得时钟延迟得到成倍的缩减,FF和 LUT的总量变化不大而DSP计算单元成倍增加——这是因为反量化部分的计算主体是乘法为主,而流水线的加入会强制打开循环结构,因此DSP数量急剧上升。
4 结论
本文采用高层次综合硬件设计的方法,实现了H.264标准中反量化反变换部分的硬件部分设计。通过循环展开、流水线、数组分割优化方案的加入,大大降低了计算所需的时间,对硬件模块的设计空间进行了探索。只对硬件模块核心算法进行C语言代码实现,从而得到RTL级硬件模块输出。极大地缩短了硬件设计的周期,提高了生产力。而且本文所呈现的设计思路不仅适用于本文所实现的反量化和反变换,同样适用于其他各种硬件单元的设计。因此在未来的工作中,一方面将会继续完成H.264中其他硬件单元的设计,实现整体H.264标准的硬件实现;另一方面,还会致力于各种复杂算法的高层次综合实现与优化。
[1]FLEMING K,LIN C C,DAVE N,et al.H.264 decoder:A case study in multiple design points[C].MEMOCODE.IEEE,2008:165-174.
[2]樊宗智,周煦林,刘彬.基于高层次综合的 JPEG编码器设计[J].微电子学与计算机,2015,32(6):1-4.
[3]何宾.Xilinx_FPGA权威设计指南-Vivado 2014集成开发环境[M].北京:电子工业出版社,2015,2:348-403.
[4]WANG T C,HUANG Y W,FANG H C,et al.Parallel 4x4 2d transform and inverse transform architecture for mpeg-4 avc/h.264[C].ISCAS,vol.2.IEEE,2003:II-800.
[5]Zhong Guanwen,Vanchinathan Venkataramani,Yun Liang,et al.Design space exploration of multiple loops on FPGAs using high level synthesis[C].2014 32nd IIEEE International Conference on Computer Design,Seoul,South Korea,2104:456-463.
[6]张茉莉,杨海钢,崔秀海,等.基于数组分块的 FPGA高级综合编译优化算法[J].计算机应用研究,2013,30(11):3349-3352.
High level synthesis implementation of inverse quantification and inverse transformation in H.264
Chen Xinwei1,2,Meng Xianggang2,Gao Teng2,Chen Yao2,Liang Ke2,Li Guofeng2
(1.Fujian Provincial Key Laboratory of Information Processing and Intelligent Control,Fuzhou 350121,China;2.College of Information Technology and Optical Engineering,Nankai University,Tianjin 300350,China)
Inverse transformation and inverse quantization is an important process in H.264 decoder,the complexity of the algorithm leads to a long design time and complex verification procedure when designing in conventional way with RTL language.High level synthesis in involved in this paper to illustrate efficient inverse transformation and inverse quantization hardware design.The results show that the design method in this paper could achieve the hardware block for the targeted FPGA platform efficiently and explore the design space of the hardware with different high level synthesis settings at the same time to fulfil the different requirements for different designs.
H.264 decoder;inverse quantification;inverse transform;high level synthesis;design space exploration
TN432
A
10.16157/j.issn.0258-7998.2016.11.005
陈新伟,孟祥刚,高腾,等.H.264中逆量化逆变换的高层次综合实现[J].电子技术应用,2016,42 (11):25-28.
英文引用格式:Chen Xinwei,Meng Xianggang,Gao Teng,et al.High level synthesis implementation of inverse quantification and inverse transformation in H.264[J].Application of Electronic Technique,2016,42(11):25-28.
2016-07-11)
陈新伟(1983-),男,博士,主要研究方向:信号处理、智能控制。
福建省科技厅引导性项目(2015h0031)
孟祥刚(1993-),男,硕士,主要研究方向:数字集成电路设计、高层次综合设计。
