基于数据关联的分布“对象代理数据库划分方法
2016-11-29王敏彭承晨李蓉蓉彭煜玮
王敏,彭承晨,李蓉蓉,彭煜玮
(武汉大学计算机学院,武汉430072)
基于数据关联的分布“对象代理数据库划分方法
王敏,彭承晨,李蓉蓉,彭煜玮
(武汉大学计算机学院,武汉430072)
对象代理数据库是一种先进的具有复杂信息管理能力的数据库系统,随着数据量的剧增,实现其分布式存储变得十分重要.然而,对象代理数据库中的数据存在着很强的关联性,如果按照传统数据划分方式进行分布式存储,将导致查询效率低下.针对这一问题,本文提出了一种基于关联的高效数据划分方法:首先根据代理层次将关联对象聚集成对象簇,每个簇对应一个存储文件;然后提取对象簇的模式特征和语义特征,通过聚类算法将对象簇集划分为k个子集分配到各存储节点.将本文方法与随机分布式存储方法进行了比较实验,结果证明本文方法在查询效率方面具有明显优势.
分布式;对象代理数据库;关联;数据划分;对象簇
0 引言
对象代理模型[1-2]以面向对象数据库模型为基础,通过定义代理对象来表现对象的多方面本质和动态变化特性.TOTEM(路珈图腾数据库)是基于该模型开发的数据库管理系统,它不仅继承了面向对象数据库的优点,还具有能够有效地支持个性化信息服务、对象动态分类、复杂对象的多表现等功能.目前TOTEM已经在生物信息管理[3-4]、地理信息管理[5]、Web数据管理[6]等诸多领域有着广泛的应用.但应用范围的扩大必然带来存储数据量的增加,使得单机存储无法满足数据存储的需求.在这种情况下,分布式对象代理数据库应运而生.如图1所示,分布式对象代理数据库由应用接口层、TOTEM数据库层、分布式存储层组成.应用接口层为系统的上层应用提供接口;TOTEM数据库层包括连接管理、查询处理、事务处理等3个模块,系统表用于记录对象的相关信息;分布式存储层为本文研究所在的层次,是通过数据分片和数据分布操作实现数据的分布式存储.
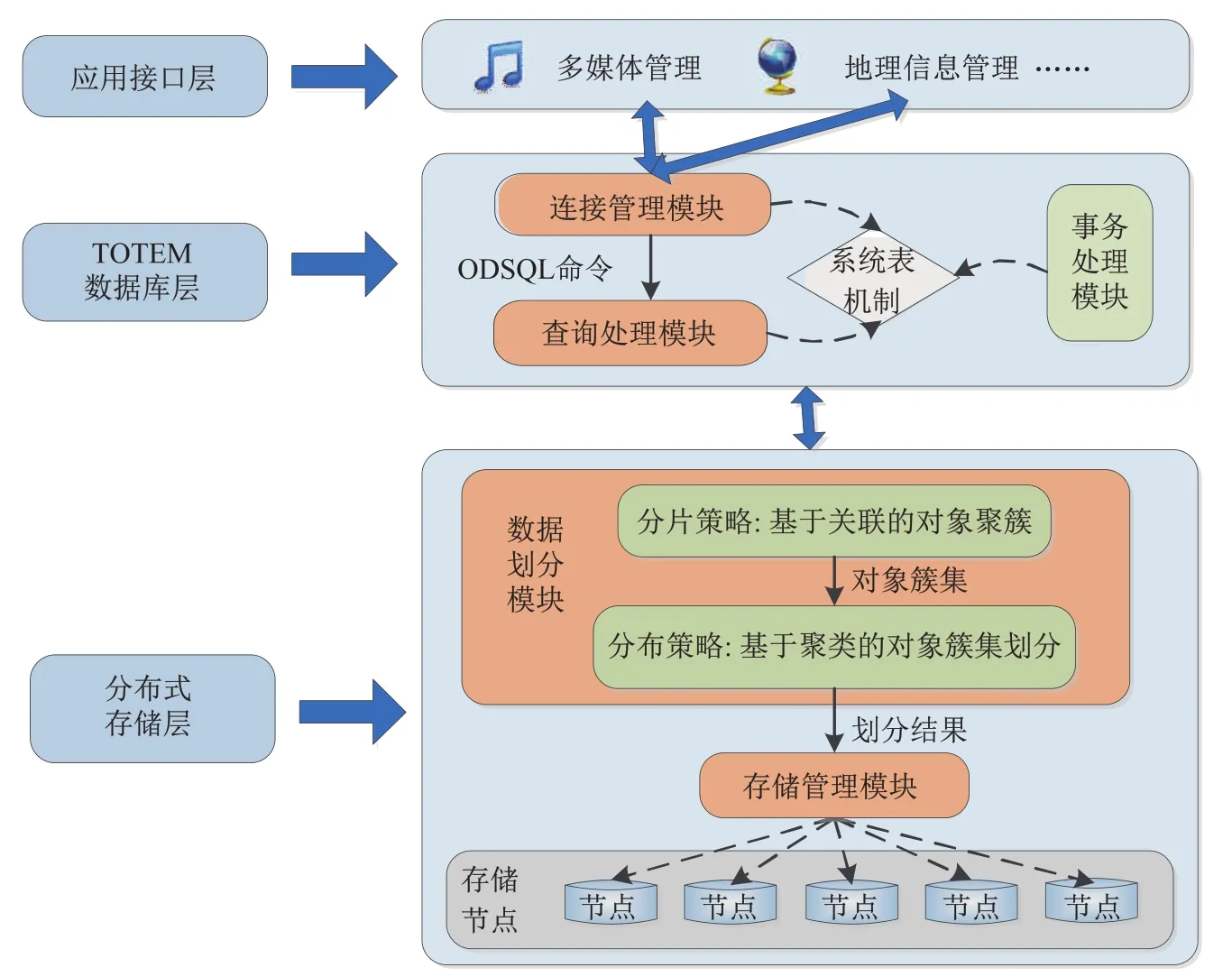
图1 分布式对象代理数据库架构图Fig.1Architecture of distributed object deputy database
在分布式对象代理数据库中,代理关系使得对象之间存在相关性,访问一个对象时往往需要访问与其相关的其他对象,即存在对象级联访问的情况.然而一般的分布式存储系统并不考虑对象的相关性,是将对象随机分配,这样带来的问题是:关联对象可能存储于不同的节点,级联访问时需要从多个节点获取对象,增加了I/O(Input/Output)以及数据传输的开销,这种开销也会随着关联对象的增多而增大.直观而言,如果把数据库中的对象进行划分,将关联的对象存储在相同或尽量少的节点上,读取时把与之相关的对象一起读进内存,B可减少额外的I/O和数据传输,提高对象访问的效率.如考虑2个具有代理关系的对象a和b,如图2(a)所示,它们存储于不同的节点,当对a和b进行级联读取时,需要2次I/O和2个缓冲页面;如果将它们聚集起来存储在同一个节点,如图2(b)所示,读取时同时读进内存缓冲区,则I/O和缓冲区数都减少为原来的一半.然而,对象代理数据库中的数据划分具有一定的挑战性,原因在于传统数据库中的数据划分方法是对单个表进行水平划分或垂直划分,没有考虑到对象间的相关性,因此无法保证关联对象被划分到一起.
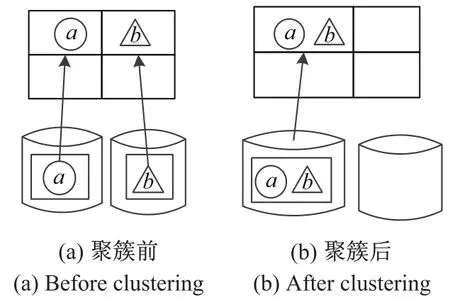
图2 聚簇存储对查询效率的影响Fig.2The influence of clustering storage on the query efficiency
针对这一问题,本文提出了一种基于关联的分布式对象代理数据库数据划分方法.首先,根据代理关系反映的显式关联将对象划分成多个对象簇,同一个簇中的对象之间具有代理关系,不同簇的对象不具有代理关系.对象簇作为分布式存储中的基本单位,为了将对象簇集合理地分配到节点中,本文同时考虑对象簇的模式关联性和语义关联性,采用k-means[7]方法将对象簇集划分为k个子集,每个子集存储在一个节点上.实验证明,本文提出的数据划分方法能够有效地提高分布式对象代理数据库的查询效率.
1 相关工作
单机版对象代理数据库中的对象采用堆文件方式进行存储[8],同一个类的对象存储在一个堆文件中,堆文件在磁盘中采用顺序存储的方式.然而在分布式环境下,这一存储方式会使得具有代理关系的对象存放在多个节点上,查询效率低.目前还没有对象代理数据库分布式存储的相关研究.
分布式数据库系统的设计分为数据划分和数据在节点上的分配[9]这两个步骤.数据划分可分为水平划分和垂直划分[10]:水平划分按元组对关系表进行划分;垂直划分按关系属性对数据表进行划分.目前对分布式关系数据库的数据划分方法已有大量的研究成果: Navathe等人[11]提出了一种两阶段的垂直划分方法,首先根据经验目标函数对关系表划分,然后根据具体的应用环境进行优化.关于面向对象数据库系统的划分方法,也有很多相关的研究工作:Ezeife和Barker[12]为了进行数据的水平划分,将数据库中的类分成4个组,采用一定的方法对每个组中的类进行划分.这些划分方法没有考虑到数据之间的相关性,因此不适合对对象代理数据库中具有代理关系的对象进行划分.
2 问题描述
对象代理数据库中,对象与对象之间、类与类之间的关联性使得数据呈现出代理层次结构.图3给出了代理层次的示例,每个表格代表一个类,其中Media为源类,MTV和Music是从Media派生的代理类,CNMusic是Music的下层代理类.表格中每一行表示一个对象,OID(Object Identifier)[13]为对象标识符,其余列为对象的属性.源对象与代理对象之间使用双向指针(虚线)表示代理关系;实线表示属性的继承关系,如MTV从Media中继承了ID(Identification)和DESC(Descend)属性.类中定义的属性或代理类中扩展的属性称为实属性;代理类中继承自源类的属性称为虚属性,图3中灰色属性均为虚属性.
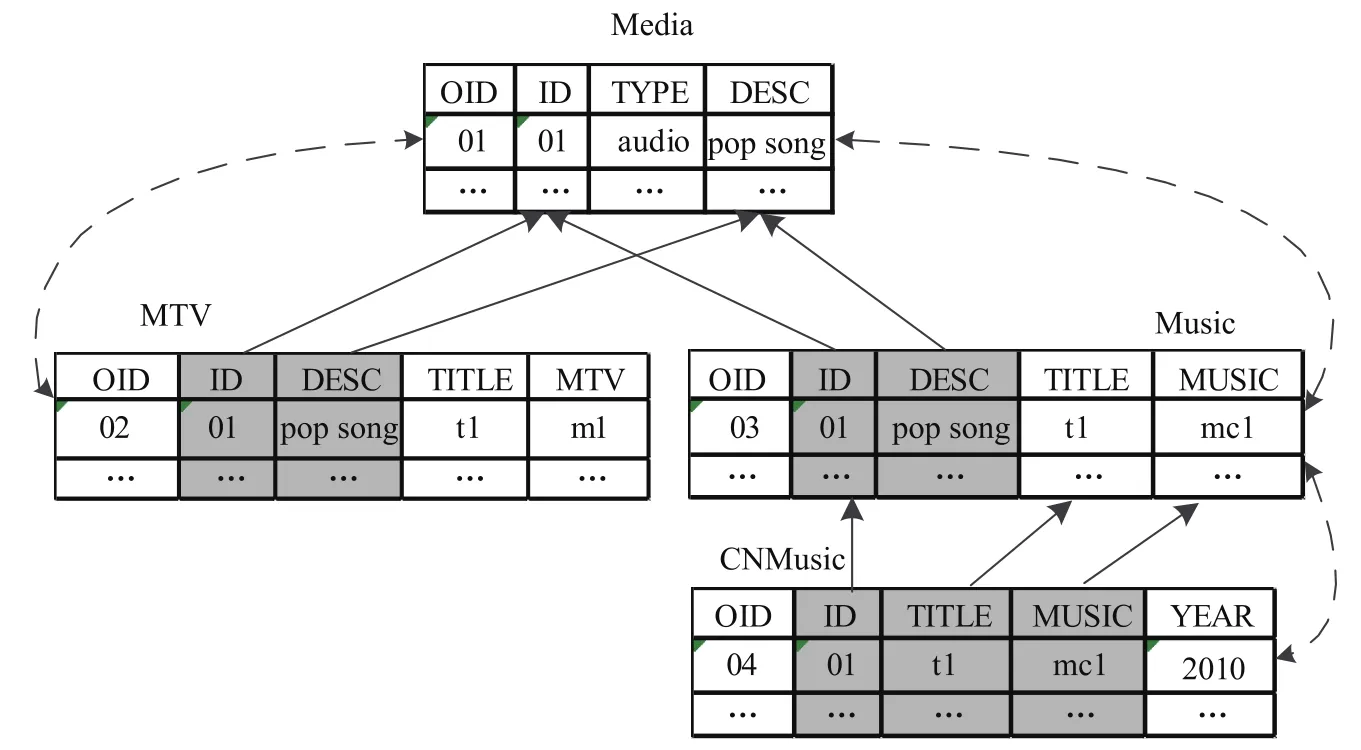
图3 代理层次示例Fig.3The example of deputy layers
定义1级联读取:代理对象的虚属性不占实际的物理存储空间,为了获取虚属性的值,需要读取其源对象中相应的实属性,这种读取方式为级联读取.
定义2跨类查询:利用对象间的代理关系,从一个类的对象出发,可以查询得到与其存在直接或间接代理关系的另一个类的对象,即为跨类查询.
定义3对象簇:对象簇为具有关联关系的对象的集合,在数据库存储和读取时被视为一个整体.
可以看出,代理层次是一个有向图,我们用DH=〈V,E〉表示代理层次,V={〈v1,T1〉,〈v2,T2〉,···,〈vn,Tn〉}为顶点的集合,表示系统共有n个类,其中,类vi={oi1,oi2,···,oimi} (i=1,2,···,n)表示该类由mi个对象组成,Ti∈{Source,Select,Union,Group,Join}(i= 1,2,···,n)为类的类型,Source代表源类,其余4个值代表4种代理类型;E={〈vi,vj,〉|vi,vj∈V}(i=1,2,···,n,j=1,2,···,n)为有向图中的边,表示类之间的代理关系,〈vi,vj〉∈E表示vi是vj的代理类,边的总数目记为f.
本文所解决的问题可描述为:已知代理层次DH和分布式存储节点的数目k,我们希望利用对象之间的关联关系,将数据库中的对象划分为k个互不相交的子集C1,C2,···,Ck,使得对于一组查询Q={q1,q2,···,qt},其查询开销最小,其中,Tc为传输开销,Tr为I/O开销.
3 基于关联的数据划分方法
针对上述问题,本文提出了一种基于关联的数据划分方法,旨在将具有关联关系的对象存储到同一个节点上.该方法有对象聚簇和对象簇集划分两种.
3.1 基于代理关系的对象聚簇
对象聚簇是将数据库中的对象进行划分,使得不同类中具有代理关系的对象聚成一个簇,混合存储在同一个文件中.簇文件一般为小文件,因此可保证分布式环境下存储于同一节点.划分依据为代理层次所表示的代理关系,然而代理层次是一个复杂的图结构,直接基于该结构进行聚簇的效率较低.因此在聚簇前,我们将代理层次划分为互不相交的子树,称为代理树,然后根据划分后的代理树集合进行对象的聚簇.代理层次中具有4种类型的代理关系,下面分别讨论代理树生成时每种代理关系的处理方法.
(1)Select代理
Select代理有且只有一个源类,源对象与代理对象之间的关系为一对一或一对零.将Select代理对象与其源对象聚簇存储在一起是最自然的,而且它们的关联存取也是最频繁的.因此在遍历过程中,如果代理类型为Select,则将该代理类与它的源类划分到同一棵代理树中.
(2)Group代理与Join代理
Group代理只有一个源类,源对象与代理对象之间的关系为多对一或多对零.图4(a)所示为Group代理关系,代理对象4对应1组源对象{1,2,3}.如果要将源对象和代理对象进行聚簇存储,第一种策略为冗余存储,即产生多个代理对象的副本,分别与源对象聚簇,这种方式下代理对象4会产生{1,4}、{2,4}、{3,4}3个簇;第二种为非冗余存储,将代理对象与任意一个源对象聚簇,如采用{1,4}、{2}、{3}的形式存储.冗余存储中更新一个代理对象需要更新多个副本,一致性维护开销大;非冗余存储虽然不存在更新问题,但是很难决定代理对象与哪一个源对象聚簇效率最高.因此本文不把Group代理对象与其源对象聚簇,所以在代理树的划分时将Group代理从代理层次中划分出去,形成一个单独的代理树.Join代理关系如图4(b)所示,聚簇存储时也会遇到类似Group代理关系的情况,这里不一一说明,代理树划分时也将其从代理层次中划分出去.
(3)Union代理
图4(c)给出了Union代理关系的示例,与Select代理关系相似,其源对象与代理对象之间只可能存在一对一或一对零的关系.因此在代理树划分的过程中可以将1个Union代理关系分解为2个Select代理关系,如图4(d)所示.
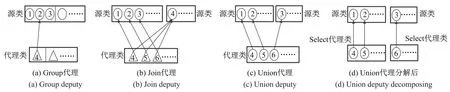
图4 代理关系示例Fig.4The example of deputy relation
综上所述,代理树的根节点为源、Group代理、Join代理,树的成员节点都是Select代理.代理树生成过程为遍历代理层次图,对于每条边,根据其代理类型作相应的处理;依次处理每个子图,直到所有子图都满足代理树的条件为止.
代理树生成算法(Create Deputy Tree,CTD)表示代理树生成的过程,算法涉及的数据结构说明如下:Q为保存代理层次中所有可能的根节点的队列;DTS为保存生成的代理树的集合;Vs为节点集合,保存形成的代理树的所有节点;Es为边集合,保存形成的代理树中的所有边;Qt为保存所有与正在处理的类相关的节点,它们都被初始化为φ.
图5给出了算法CTD执行过程的示例.对于图5(a)中的代理层次图,可以作为代理树根节点的类有v1、v4、v6、v7、v9.首先构造以v1为根节点的代理树:遍历与v1具有直接代理关系的类v2、v3,它们都为Select代理,插入到代理树中,如图5(b)所示;然后考察与v2具有直接代理关系的类,v5作为Select代理被插入到代理树中,而v6为Group代理,将其从代理树中划分出去,得到图5(c)的结果;接着考察与v3具有直接代理关系的类v8,因为它为Union代理,所以进行分解,创建副本v8a并插入到代理树中,形成图5(d),至此以v1为根节点的代理树构造完毕.以同样的方式可生成以v4、v6、v7、v9为根节点的代理树,最终得到图5(e)中所示的5棵代理树.

算法:算法CTD输入:DH=〈V,E〉输出:代理树集合DTS 1:循环将DH中所有的源类、Group代理、Join代理加入节点队列Q中; 2:while Q非空do//从根节点出发构造代理树3:从Q中取出第一个节点u;初始化Qt、Vs、Es,将u加入Qt中并从Q中删除; 4:While Qt非空do 5:取出Qt中的第一个节点w,将w插入Vs; 6:for each e=<vi,vj,>in E 7:if(vj==w且vi为Select代理) 8:将vi插入Vs、Qt,将e插入Es中并从E中删除; 9:if(vj==w且vi为Group或Join代理) 10:将e从E中删除; 11:if(vj==w且vi为Union代理) 12:从E中删除e,创建vi的Select副本v′i; 13:创建边<v′i,vj>并加入Es中;插入v′i到Vs、Qt中; 14:end for 15:将w从Qt中删除; 16:end while 17:根据Vs、Es生成代理树DT,插入到DTS中; 18:end while
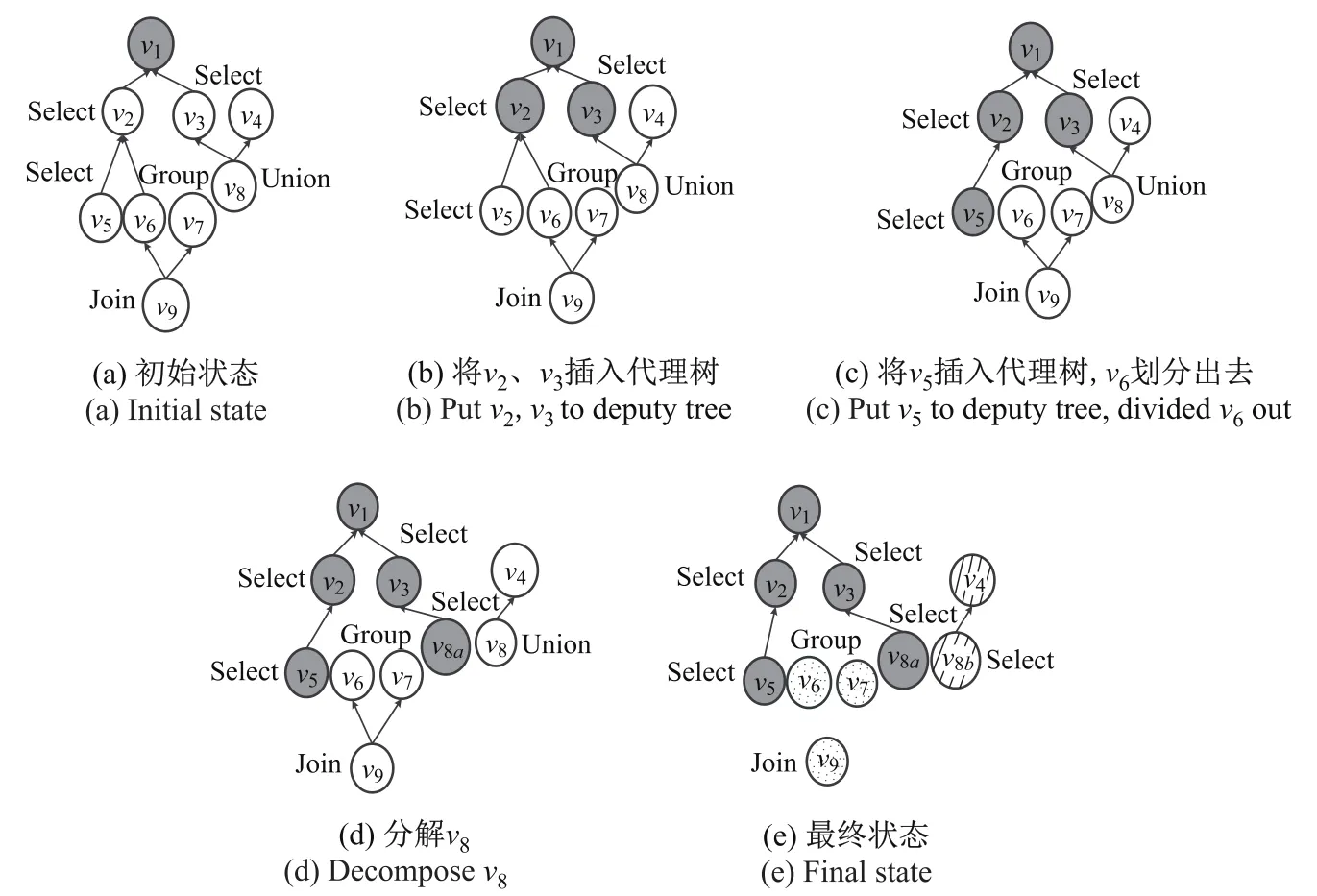
图5 代理树划分过程Fig.5The process of deputy tree partition
算法CTD的时间复杂度为O(n×f),n和f分别为顶点数和边数,算法执行过程中只用到几个集合类型的存储结构,因此空间复杂度为O(1).
通过划分得到代理树后,根据代理树进行对象聚簇.具体方法是:对于代理树根节点中的每个对象,寻找所有与其具有代理关系的对象,形成一个对象簇,记为pi.可以看出,如果代理树根节点存在N个实例对象,将产生N个对象簇.图6为聚簇过程的示例,根据图6(a)中的代理树可将图6(b)中的对象聚成图6(c)所示的2个簇,图中虚线连接起来的2个对象具有代理关系.
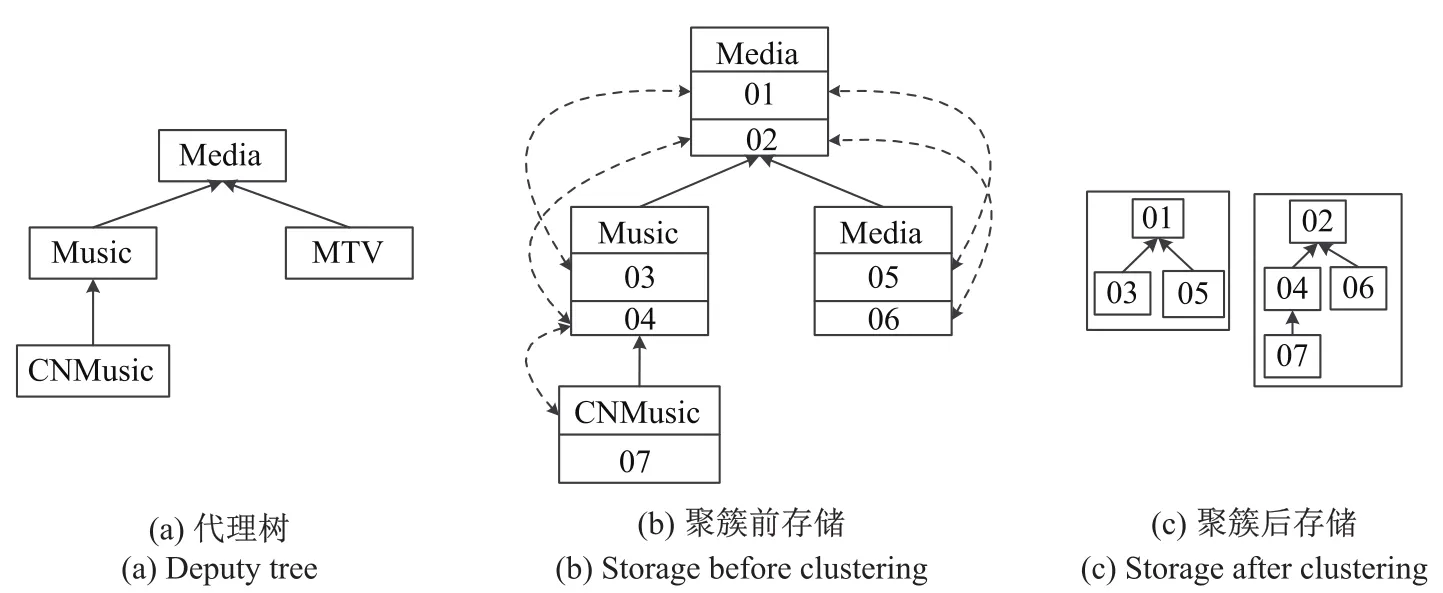
图6 对象聚簇Fig.6Clustering of objects
3.2 对象簇集划分
对象聚簇之后,系统中存在多个对象簇,然而节点的个数远小于对象簇的个数,这就需要考虑如何将大量的对象簇分配到少量的节点中.为了解决这一问题,本文首先提取对象簇的特征,将其表达成特征向量,然后根据对象簇之间的相似性,采用k-means方法将对象簇集划分为k个子集,分别存储于各节点.
3.2.1 特征选择
本文考虑对象簇的两方面特征:模式特征和语义特征.模式特征指对象簇本身所表现的结构特征;而语义特征是指对象簇反映的客观实体的语义.
(1)模式特征
对象簇是具有关联关系的对象集合,它本身具有一定的逻辑结构特征,称为模式特征.我们认为模式上相同或相似的对象簇有很大可能被同时访问,如图6(c)所示的2个对象簇,它们的源对象都属于Media类,代理对象所属类中有2个类是相同的,当我们执行Select*from Media获取Media中的所有对象时,这2个簇就需要被同时访问,而且这种扫描同一类的查询在数据库中很频繁,因此有必要将模式相似的对象存储在同一节点.本文选取簇包含的类集合、簇的代理层次深度作为模式特征,代理层次深度是指簇中代理对象到根源对象的路径的最大长度.图6中2个簇的模式特征分别为({Media,Music,MTV},1)和({Media,Music,MTV,CNMusic},2).
(2)语义特征
语义上具有相似性的对象被同时访问的概率比较大,如2个簇都具有“中文歌”这一语义,它们很有可能被同时访问.因此将语义相似的对象簇存储到同一物理节点可提高查询效率.针对不同的应用领域,对象簇的语义特征有所不同,本文以音乐领域为例,选取歌曲名、歌手名、专辑名、曲风、年代等5种衡量对象簇特征的语义.
3.2.2 基于聚类的划分方法
由于k-means方法可将数据集划分为k个子集,而且时间复杂度接近于线性,具有可伸缩性,因此本文采用该方法进行对象簇集的划分.假设数据集D={p1,p2,···,pl},pi(i=1,2,···,l)代表对象簇,l为对象簇的个数,每个对象簇采用d维特征向量(x1,x2,···,xd)表示.k-means就是一种将D划分为k个子集C1,C2,···,Ck的方法.其基本流程为:首先从l个对象簇中任意选择k个簇作为k个子集的初始中心;对于剩下的其他对象簇,根据它们与这些中心的相似度,分配到与之最相似的中心所代表的子集;分配完所有对象簇后,重新计算每个子集的均值并将此作为新的子集中心;重复上述过程,直到度量函数E开始收敛为止.
本文使用距离度量对象簇之间的相似性,距离越小表示其相似性越大.我们将特征分为3类:集合型;枚举型;数值型.针对不同类型特征,采用不同的距离计算公式.
集合型特征是指特征的值为一个集合,本文中簇包含的类集合与歌名都被作为该类型的特征.对于该类型特征,我们采用Jaccard距离[14].在计算距离之前,需要将歌名转换成词集合的形式,中文可通过分词的方法进行转换,英文则以空格为分隔符进行分割.设x,y为2个集合型属性,其距离计算公式为

枚举型特征的值限定于可列举出的一组值之内,如歌手、专辑、曲风都属于该类型.计算枚举型特征的距离公式为

如果2个属性的值相等,则认为其距离为0,不相等则为1.
数值型特征采用公式

表示的欧氏距离进行度量,簇的代理层次深度、年代为该类型特征.
得到每种类型特征的距离之后,对于2个对象簇pi和pj,pi=(x1,x2,···,xd),pj= (y1,y2,···,yd),它们之间的距离计算公式为

目标函数E被定义为数据集中所有对象的误差平方和,计算公式为

其中,ci为子集Ci的中心.这个目标函数使生成的结果簇尽可能紧凑和独立.
3.3 数据读取与数据更新
由于数据存储方式发生了改变,数据读取的方式也需要做相应的修改.在新的存储方式下,为了获取用户需要的查询结果,在系统表中记录每个对象所属的对象簇和节点.用户提交查询语句后,根据系统表获得对象所在的簇号和节点号,然后从节点中读取对象簇,解析后返回查询结果.
数据库是一个动态变化的系统,当发生数据更新时,需要对生成的对象簇进行维护.对象代理数据库中,插入对象和删除对象都会对对象簇的结构产生影响.
(1)插入对象
对象代理数据库中,插入的对象只能是源对象.根据本文的聚簇方法,每个簇中有且仅有一个源对象,因此当插入源对象时,创建一个新的簇,存储到与之最相似的子集所在的节点中,并在系统表中添加对象与簇的对应关系.
(2)删除对象
如果删除的对象为源对象,将会级联删除与之相关的代理对象,因此删除源对象时会将其所在簇整体删除.删除代理对象时,首先找到其所在簇,然后把对象从簇中删除.
4 实验
本文提出的数据划分方法已在对象代理数据库系统中实现.本节通过实验将本文方法与随机分布式存储方式进行对比,分析二者在数据库查询开销方面的差异.
4.1 实验设计
实验数据:实验数据集是通过元搜索引擎从Web上获得的跨媒体数据,总共包括24万余条数据及相关信息,从这些数据中随机选取2.6万条作为源对象进行实验.代理对象通过源对象派生.数据库模式使用图1所示的代理层次,其中各个类的数据规模如表1所示.

表1 各个类的数据量Tab.1Data size of classes
实验方法:实验对随机存储方法和划分存储方法进行对比.随机存储方法是指对象被随机分配到物理存储节点;划分存储方法是指通过划分,将关联对象存在同一物理节点.为了体现划分过程中模式特征的重要性,实验还对比了有模式特征的划分方法和无模式特征的划分方法之间的差异.
实验环境:实验使用3台PC机模拟12个存储节点,采用TOTEM2.2数据库系统,分布式文件系统为ceph0.8[15].
4.2 实验结果分析
对比实验从3方面进行:一是对单个源类查询的影响;二是对单个代理类查询的影响;三是对跨类查询的影响.每组实验针对100个样本查询,通过平均查询时间衡量方法的性能.
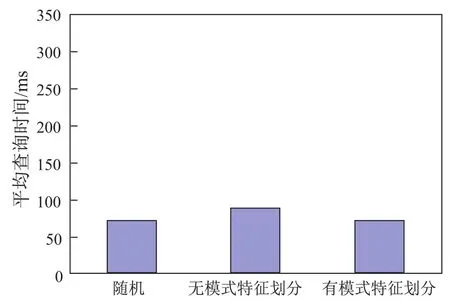
图7 对单个源类查询的影响Fig.7Impact on the query of source class
图7为3种方法在单个源类查询方式下查询效率的差异.由于源类查询不涉及对象的级联读取,因此本文方法对源类查询效率的提升不是很大,如果不考虑模式特征,源类中的对象会被分配到不同节点,查询效率低于有模式特征的划分方法,甚至低于随机分配的方法.图8展示了对跨类查询效率的影响.从图8可以看出,不管是有模式特征的划分还是无模式特征的划分,对查询效率都有很大的提升,而且考虑了模式特征的方法性能更优.
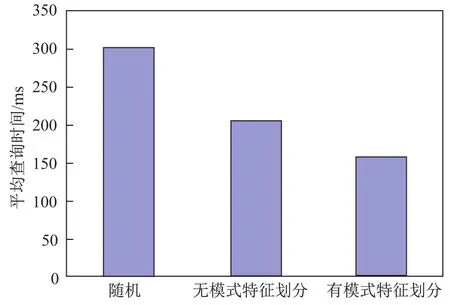
图8 对跨类查询的影响Fig.8Impact on the cross-class query
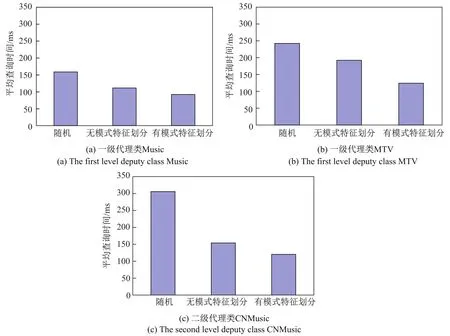
图9 对代理类查询的影响Fig.9Impact on the query of deputy class
图9为3种方法对代理类查询的影响,实验分别比较了3种方法对一级代理类(MTV、Music)查询和二级代理类(CNMusic)查询的影响.从图中可以看出,本文方法对二级代理类查询效率提升的幅度大于一级代理类,这种优势随着代理层次的增加会更明显.对比图9(a)和图9(b),由于MTV中的元组个数多于Music,加入模式特征将属于同一类的簇存入同一节点,可更大地提升查询效率.
综上,对于源类查询、跨类查询和代理类查询,本文方法在查询效率方面均优于随机存储的方法,同时也证明了划分过程中模式特征的重要性.
5 结束语
本文针对分布式对象代理数据库中,对象随机存储而导致的级联读取效率低下这一问题,提出了一种基于关联的数据划分方法,使分布式存储时关联对象存储在同一个节点.实验证明,本文提出的方法能够有效地提高分布式对象代理数据库级联读取的效率,具有良好的性能效果.未来的工作应该进一步研究代理树生成过程中Group代理关系、Join代理关系的处理方法,以及对象簇动态更新过程的优化.
[1]PENG Z Y,KAMBAYASHI Y.Deputy mechanisms for object-oriented database[C]//Proceedings of the 11th International Conference on Data Engineering.1995:333-340.
[2]KAMBAYASHI Y,PENG Z Y.Object deputy model and its applications[C]//Proceedings of the 4th Inernational Conference on Database Systems for Advenced Applications.1995:1-15.
[3]彭智勇,黄泽谦,刘俊.基于对象代理数据库的微生物信息服务系统[J].计算机应用,2010(1):5-9.
[4]PENG Z Y,SHI Y,ZHAI B X.Realization of biological data management by object deputy database system[C]//Transaction on Computational Systems Biology V.Berlin:Springer,2006:49-67.
[5]彭智勇,彭煜玮,翟博譞.一个基于对象代理模型的多表现地信息系统[J].计算机应用,2006(9):2016-2019.
[6]彭智勇.Web数据管理系统:201010140168.4[P].2010-09-15.
[7]MACQUEEN J.Some methods for classification and analysis of multivariate observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability.1967:281-297.
[8]黄泽谦.对象代理数据库聚簇策略与查询优化技术研究[D].武汉:武汉大学,2011.
[9]BAI˜AO F,MATTOSO M,ZAVERUCHA G.A distribution design methodology for object DBMS[J].Distributed and Parallel Databases,2004,16(1):45-90.
[10]ÖZSU M T,VALDURIEZ P.Principles of Distributed Database Systems[M].New York:Springer-Verlag,2002.
[11]NAVATHE S B,RA M.Vertical partitioning for database design:A graphical algorithm[J].ACM Sigmod Record, 1989,18(2):440-450.
[12]EZEIFE C,BARKER K.A comprehensive approach to horizontal class fragmentation in a distributed object based system[J].International Journal of Distributed and Parallel Databases,1995(3):247-272.
[13]施源,彭智勇,庄继峰,等.对象关系数据库中OID回收机制[J].计算机科学,2004,31(10):566-568+581.
[14]SHAMEEM M U S,FERDOUS R.An efficient k-means algorithm integrated with Jaccard distance measure for document clustering[C]//Proceedings of the Asian Himalayas International Conference on Internet.2009:1-6.
[15]WEIL S A.Ceph:Reliable,scalable,and high-performance distributed storage[D].Santa Cruz:University of California Santa Cruz,2007.
(责任编辑:李艺)
Data correlation-based partition approach for distributed deputy database
WANG Min,PENG Cheng-chen,LI Rong-rong,PENG Yu-wei
(Computer School,Wuhan University,Wuhan430072,China)
Object deputy database(ODDB)is an advanced database system with strong ability of complex information processing.With the rapid development of data,distributed storage becomes more and more important to ODDB.However,there exist correlations between objects in ODDB,which makes the traditional data portioning method of distributed storage unsuitable.To solve this problem,we propose a data correlation-based partition approach for ODDB.Firstly,we cluster correlated objects according to the deputy tree,and each object cluster is considered as a heap file in storage.Secondly,on the basis of schema feature and semantic feature,we divide object clusters into k subsets using k-means,each subset is stored on one of the storage nodes.Finally,we compare our method with random distributed storage,the results show that our approach is obviously better in query efficiency.
distributed;object deputy database;correlation;data partition; object cluster
TP311
A
10.3969/j.issn.1000-5641.2016.05.006
1000-5641(2016)05-0045-11
2016-05
国家自然科学基金重点项目(61232002)
王敏,女,硕士研究生,研究方向为数据管理.E-mail:wangmin1992@whu.edu.cn.
李蓉蓉,女,博士,讲师,研究方向为数据抽取与数据管理.E-mail:rrli@whu.edu.cn.
