面向高通量事务处理的事务编译技术
2016-11-29王冬慧朱涛钱卫宁
王冬慧,朱涛,钱卫宁
(华东师范大学数据科学与工程研究院,上海200062)
面向高通量事务处理的事务编译技术
王冬慧,朱涛,钱卫宁
(华东师范大学数据科学与工程研究院,上海200062)
针对内存数据库中CPU利用率不高的问题,目前的研究工作集中在利用事务编译技术提升事务的执行效率和改进事务的并发控制以提升数据库的性能.本文主要从以下几个方面对内存数据库的事务编译技术进行了综述.第一,介绍了事务处理的一般流程,分析限制系统性能的因素.第二,分析了当前使用的事务编译技术,包括即时编译技术、操作依赖分析技术和事务切片技术.第三,结合实例分析事务编译是如何提升数据库性能的,介绍典型的内存数据库在事务编译方面的研究工作,如Hekaton、VoltDB等.最后给出了研究展望.
事务编译;并发控制;即时编译技术;操作依赖分析技术;事务切片技术
0 引言
传统的联机事务处理(OLTP)数据库系统的数据存放在磁盘中,主要是因为当时的内存容量不足以保存所有的OLTP数据.文献[1]表明,执行一个事务,只有不到10%的指令是用在处理真正有用的工作,而其他90%的指令都用在了日志、并发控制和缓冲区管理上.因此,传统的磁盘数据库性能的主要瓶颈是磁盘的I/O,很多对事务执行和事务调度的优化都是围绕这一点展开的.例如,设计合理的缓冲区管理策略保证事务访问的数据已经拉取到了内存;设计并发控制协议来并发大量的事务,从而充分利用硬件计算资源.
然而,近年来,随着计算机技术特别是半导体技术的飞速发展,内存的价格不断下跌,而容量却不断上升.1MB内存的价格由1980年的1万美元降低到2010年的0.01美元[2].TB级的主存不再是遥不可及的事了.此外,由于关系型数据库中数据冗余较少,几乎可以将最大的数据库放进内存中[3,20].因此,磁盘I/O已经渐渐的不再是数据库系统性能的主要瓶颈,当前数据库系统的性能主要受限于CPU利用率.确保CPU计算资源的高效利用,提升事务执行的局部性才是当前提升数据库系统性能的主要考虑方向.事务编译的基本理念在于:将大量原本在执行阶段完成的任务提前到编译阶段完成,事务编译能够在此阶段充分挖掘事务逻辑的内在特点,并利用这些特点产生更好的执行策略,减少事务执行阶段的指令开销,极大地改善系统的性能.
本文后续内容组织如下:第1节介绍目前事务处理的一般流程,分析其存在的问题及性能花销;第2节讨论事务编译所用到的技术及其优缺点;第3节介绍事务编译如何改善系统的性能,结合目前事务处理以及存在的问题来展开,分析相关工作是如何优化的,并介绍目前一些系统在事务编译方面的设计以及探索,诸如VoltDB,MemSQL,Hekaton等;最后在第4节总结全文,给出研究展望.
1 事务处理流程与分析
磁盘数据库系统事务处理的主要性能瓶颈是低速的磁盘访问.然而,内存数据库系统天然的避免了这个问题.在新环境下,系统性能的提升主要依赖于对CPU的利用.这导致了传统的事务处理技术存在许多设计的局限性.本节主要从以下两个方面:(1)事务逻辑的执行; (2)事务语义的管理探讨传统技术的设计及其在新环境下的不足之处.
1.1 事务执行
传统数据库,如Oracle、MySQL等,都存在一个SQL解析引擎,将客户端输入的SQL命令序列转换成一个可执行的操作序列[4].如图1所示,主要包括以下3个步骤:(1)词法语法分析.(2)生成逻辑查询.(3)生成物理查询.

图1 SQL引擎间的调用关系Fig.1Call relationship between SQL engine
主流数据库通常采用迭代器模型封装SQL的执行逻辑,或者称为Volcano模型[5].数据库系统内部实现了大量的物理操作符,对应不同的执行逻辑.查询引擎通过组合不同的物理操作符以实现复杂的查询逻辑.每一个物理操作符有3个方法,这3个方法允许物理操作符结果的使用者一次一个元组的得到这个结果,实现了流水化操作.这3个方法为:open().该方法分配并初始化物理操作符中所用到的各种数据结构等;getnext().该方法返回结果中的下一个元组,通过反复调用该函数以获取全部的元组;close().该方法释放执行当前操作符申请的所有资源.
迭代模型的优点是,接口非常简单,通过组合任意的物理操作符可以表达复杂的执行逻辑.元组根据需求在操作符之间传递,减少了数据物化要求.这种流水化操作节省了磁盘的I/O.
然而,在内存数据库下,迭代模型存在着以下问题,第一,较高的维护开销.在OLTP应用中,实际用于数据访问的指令开销只占很小的一个部分,大量的计算周期耗费在了资源的分配和释放上.第二,高昂的表达式计算.查询执行过程中,需要频繁地进行表达式计算,产生了大量的指令开销.第三,较高的指令缓存缺失.在执行过程中,迭代器需要频繁地在多个物理操作的接口函数间跳转,这会导致CPU的指令缓存频繁缺失.指令缓存的缺失会阻塞CPU的执行,从而降低每周期执行的指令数量.总体而言,采用迭代器描述查询计划一方面增大了完成每次操作需要的指令数量,另一方面降低了CPU每周期执行的指令数量.
1.2 事务管理
并发控制协议是在事务执行过程中调度不同事务的冲突访问,使得多个事务按照合理的顺序操作数据库.然而,磁盘式数据库对并发控制策略的实现都具有较高的维护代价.在事务处理过程中,并发请求的调度产生了较多的指令开销.
经典两阶段锁(two-phase locking,2PL)[4]的实现是采用集中式锁表.在加锁阶段,所有的事务在锁表上申请对应的数据锁.在解锁阶段,事务释放数据锁,并从等待队列中唤醒被阻塞的请求.此外,两阶段锁可能导致死锁的发生,系统需要设计死锁检测策略.集中式的锁表并不适用于内存数据库.一方面,加锁、解锁以及死锁检测都产生了大量的CPU指令.另一方面,集中式锁表存在限制多核性能的问题[20].当多个执行线程共同访问锁表时,共享对象需要使用临界区来同步多核的并发访问,随着物理核心的不断增加,对共享对象的并发访问冲突将持续增加.
在多版本并发控制技术[4]中,调度器为每个数据项的写操作创建一个时间戳作为该数据项的一个版本,当发出读该数据项的请求时,调度度选择一个版本进行读取.多版本需要保证数据项版本的选择能够使得事务可串行化.然而,在并发事务频繁访问某一元素时,所产生的冲突就会较高,系统会因此而出现频繁的回滚操作,导致产生更多的延迟和更多的指令操作,此外,维护多个版本同样会产生大量的指令开销.
有效性确认是一种乐观的并发控制技术[4].该技术在事务完成所有的执行逻辑后,验证所有的读取内容是否发生了更新.若验证通过,则事务会原子性的写入所有的待提交数据;若失败,事务需要被重试.当处理冲突较少的负载是,乐观并发控制策略具有非常好的性能,维护开销极低.然而,当事务间频繁发生冲突时,大量的CPU时间将耗费在事务的重试上,冲突处理的开销将大大增高.当前的许多内存数据库都采用了改进的有效性确认,这是因为事务在内存数据库下执行速度得到了大大的提升,事务与事务之间的发生冲突的频率也随着下降.因此可以采用更加乐观的策略.
基于时间戳的并发控制技术[4]在事务开始时为其分配一个全局递增的时间戳.此外,数据记录需要维护一个读取时间戳和写入时间戳,保存最近一次读写该记录的事务.在事务执行过程中,通过判断事务的时间戳和被访问记录的最近读写时间戳来判定是否发生访问冲突.当发生访问冲突时,事务需要回滚并申请一个更新的时间戳重新执行.然而,该策略的维护代价较高.由于数据记录需要维护最后一次读取时间,每个读操作都会造成数据页面的修改,带来了更高的维护代价.此外,当负载中存在较多的访问冲突时,该策略会频繁重试事务,造成较高的调度代价.
确定性执行[5]是一种服务于内存数据库的调度策略.由于磁盘I/O不是内存数据库的瓶颈,因此系统不需要通过并发执行多个事务来提升CPU的利用率.内存数据库可以在事务执行前确定调度策略,并在单线程上串行执行每个请求.该策略能够大大的避免系统在并发控制上耗费的计算资源.在新型的内存数据库VoltDB[12,18],Hyper[22]等中得到了应用.然而,该策略需要集中式的确定事务的调度次序,并且需要通过数据分区的方式提升多核并行能力.前者会导致调度瓶颈.后者会引入分布式事务,由此导致的多核间协调会降低CPU的利用率.
主流磁盘数据库(Orcale,MySQL,PostgreSQL)都采用了多版本并发控制和两阶段锁混合的策略.多版本隔离了只读事务与读写事务之间的冲突,两阶段锁确保了读写事务间的正确调度顺序.然而,这种并发控制策略产生了大量的计算CPU开销.内存数据库(Hekaton等)主要采用了乐观并发控制策略与多版本相结合的管理方式,这主要是得益于乐观并发控制具有更好的多核扩展性以及较小的指令开销.
2 事务编译技术
2.1 即时编译技术
即时编译技术(Just-in-time Compilation,JIT)[6]是一种将中间语言转换成机器码的技术.JIT的具体做法是,当载入一个新类型时,公共语言运行库为该类型分配一个内部数据结构和相应的函数,当该函数被第一次调用时,JIT将其翻译成机器语言,当再次调用这个函数时,则直接从缓存中获取已编译好的机器语言.
目前很多的研究工作[7-9]都用到了这一技术,相比于解释执行SQL请求,JIT转换成机器码的方式能够智能地对代码进行优化与重复利用.对于多次调用的函数,JIT会通过查表或者缓存的策略来取代重复计算,减少指令集大小,加快运行效率.
2.2 操作依赖分析技术
操作依赖(Dependence Theory)是指数据库事务操作之间存在依赖关系,这种关系可能是由于操作间的时序性,或者数据库表间的参照完整度造成的.正是由于这些依赖关系的存在,使得一些操作之间难以并行.操作片段可以通过这些依赖关系来构成拓扑序关系.两个操作可以并行当且仅当这两个操作都不存在拓扑序在他们之前且未执行的操作.操作依赖分析操作之间的依赖关系,给出较好的运算顺序,从而增大并行率,提高效率.
文献[10]提出了这样的操作依赖分析算法:首先将所有的操作按时间排序,p1, p2,···,pn,接着将所有的操作做笛卡尔积,得到序列(p1,p2),(p1,p3),···,(pn-1,pn),并分析每两个操作之间的依赖关系,如存在依赖,则在两操作之间建立一条有向边,表示该操作依赖于另一个操作,由此建立为一个有向无环图.接着遍历该图,所有不依赖其他任何操作的点为第代点,如果存在依赖关系,则该点的代数为它所依赖的点的最大代数+1.最后,可以发现,相同代数的操作点之间不存在依赖关系,是可以并发执行的.如图2所示,每个节点代表一个事务,结点上的数字代表该事务的代数.
解释执行时事务间若发生冲突,事务将被阻塞.操作依赖分析能够在事务预编译阶段挖掘出事务间的依赖关系,从而将相互冲突的事务放在不同的时间片执行,减小了事务因阻塞而等待的时间.然而,在静态分析两个操作之间是否存在冲突时,操作依赖分析算法通常根据其访问的是否是同一个表来判断,而不能具体的分析出操作确切的访问的是哪些数据行,因此,原本可以并行的事务可能被分析为有冲突关系,事务的并行性降低.
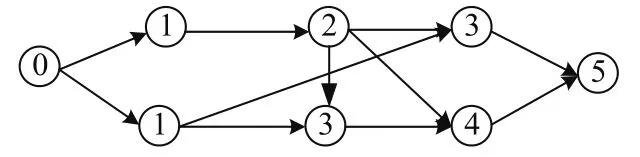
图2 操作依赖分析算法Fig.2Operation dependency analysis algorithm
Calvin[15]在执行前分析事务的读写操作集合确定多个事务之间的是否存在冲突,相互冲突的事务按照时间顺序被放在不同的时间点执行,不存在冲突关系的事务可以多核并行执行,从而在保证事务可串行化的同时减少了事务调度的代价.
2.3 事务分片技术
事务分片技术(Transaction Chopping)[11]是指,系统将事务切割成一些片段来并发执行,以期获得更好的性能.事务分片技术基于如果分片之后的事务片段是可串行化的,那么事务集也是可串行化的的性质.该方法确保了用户在事务执行正确性的前提下获得更高的事务并行度.如何找到事务的最优分片,是事务分片技术最核心的问题.
1.1 对象 2009年6月,选择上海地区5个街道60岁以上2型糖尿病患者73例,其中男30例,女43例,平均年龄69.5岁。文化程度:小学及以下14例,初中14例,高中25例,大专及以上20例。病程5年以上,血糖波动较大的患者。诊断依据,按世界卫生组织制定的糖尿病诊断标准由上海市、区级医院确认的病例。
一个典型的事务分片算法,将事务分片后构造一个图,称为SC图,图的顶点为事务的一个片,边分为两种,一种是S边,表示连接的两个片属于同一个事务,一种是C边,表示连接的两个片之间存在冲突,如修改同一个数据,且这两个片不属于同一个事务.定义SC环为包含至少一条S边和一条C边的简单环.如果事务的SC图中包含SC环,则该事务是不可串行化的.下面是一种寻找最优分片的算法,对于每个事务,首先将其按照存取操作划分为多个片,接着对于该事务的每个片寻找其它与其有冲突的事务,将其连C边,接着寻找C边连通图,将存在同一个连通图中的片合并为一个片,因为将它们切割会产生SC环.寻找完最优分片后将会产生一个无SC环的图,无冲突的片之间可以并行执行.如图3所示,将事务T5按照存取操作分为(a),(b),(c),(d),(e),(f)6个片,接着寻找与其他4个事务的冲突关系,可以看出(b),(d),(f)3个片在同一个连通图中,应合并为一个片.

图3 事务分片算法Fig.3Transaction chopping algorithm
事务分片技术通常与操作依赖分析相结合.如何确定更优的执行顺序,提升事务的并行性是一个重要的课题.此外,限制分片执行顺序还存在很多因素,如分片执行的时间等.
3 事务编译
3.1 编译对事务执行的影响
事务逻辑执行的主要问题在于物理查询计划的表示以及解释执行的方式产生了巨大的指令操作,CPU开销较大.而事务编译能够挖掘事务逻辑的内在特点,改善物理计划的表示以及执行方式,从而提升事务逻辑执行的效率.
文献[7-8]主要介绍了SQL Server的事务处理数据库引擎Hekaton是如何编译事务的. Hekaton将表分为内存优化表和基于磁盘的表,其中内存优化表放在内存中,将存储过程分为本地编译存储过程和解析性存储过程,其中本地编译存储过程是将存储过程转换为机器码,通过执行本地编译存储过程提升事务执行的性能.转换成机器码的过程是:首先使用SQL Server内部翻译机制将原始SQL指令序列转换为MAT(mixed abstract tree);接着由于T-SQL和C语义的差异,将MAT转换为PIT(pure imperative tree);接着生成C语言代码.由于迭代模型自上而下通过调用getnext接口获取子节点的输入元组,调用函数的方式使得代码失去了很好的本地性,产生巨大的指令集.因此,Hekaton大量使用label和goto语句,将其放在一个方法中替代调用函数接口的方式;接着使用编译器将C语言转换成机器码.实验证明,使用本地编译存储过程并且访问内存优化表执行的指令条数减少了94%.
Hekaton减少了迭代模型由于频繁调用接口而产生的指令花销,然而,以迭代器为中心的模型即使使用goto语句,执行的方式仍然是自上而下的方式,指令缓存缺失严重的问题仍然存在[7,9,21].Thomas Neumann[9]提出了一种高效的查询计划编译方式.该方法的主要策略有以下3点:
(1)事务处理以数据为中心而不是以迭代器为中心.处理的数据尽可能的存放在CPU寄存器中,使得访问数据较快.
(3)使用LLVM编译框架将事务编译成机器码,极大地减少了指令集大小.
此外,Thomas Neumann在该论文中还提出了一些优化技术,例如,减少分支预测对指令执行的影响;使用SIMD指令集,指令部件同时访问内存,一次性获得所有需要的数据集,减少访问数据的指令开销.论文的实验基于HyPer内存数据库,使用LLVM编译器将C++代码转换成机器码,实验显示,以数据为中心的查询处理是一种非常有效的查询执行模型, DBMS可以获得更高的效率.
事务编译同样对分布式数据库系统事务执行有着重要的意义.分布式数据库的事务处理能力通常受限于跨节点的事务执行和事务提交.前者在执行阶段需要节点间频繁的交换中间结果,后者在提交阶段需要在节点间进行两阶段提交.事务编译能够在编译阶段分析不同操作之间的联系,产生更优的执行计划.在Oceanbase上执行事务,Mergeserver需要频繁的与Updateserver以及Chunkserver进行网络交互.这些交互一方面大大增加了事务的延迟;另一方面也破坏了任务在多个节点上的连续执行,导致了更高的指令开销.在事务编译阶段,根据事务中每个操作网络节点交互的特点,利用数据缓存,RPC合并以及即时编译等技术大大缩减了事务延迟和执行的指令开销.
3.2 编译对事务管理的影响
事务管理主要利用并发控制技术.主流并发控制技术主要依赖于运行时收集到的信息来隔离多个请求的冲突访问.实际上,给定事务逻辑,在编译阶段就可以挖掘事务访问的数据区域、操作与操作之间冲突的可能性以及依赖关系等,利用这些信息可以改善事务调度的设计,主要有分片并发控制,分片并发控制主要包括两种:①数据分片,每个数据分片单线程调用;②事务分片,通过将事务分片,并行执行分片.
3.2.1 数据分片
VoltDB/H-store[13-14]为了充分利用了大内存和多核CPU优势,提出了采用单线程式的执行引擎依次调度队列中的事务请求.此外,系统将数据分片到多个执行引擎实例上,以提升并行处理能力.单线程式的设计大大简化了事务管理的工作.基于以上设计,在事务编译阶段,系统通过分析分区模式以及事务的执行逻辑,确定各个请求需要访问的分区集合, VoltDB根据事务是否需要访问多个分区上的数据,多个分区之间是否需要协调,将事务分为Single-Sited,One-Shot或者General 3种类型.在运行时,调度器根据事务类型请求路由到正确的分区上执行,针对不同类型的事务采用了特定的执行策略,减少事务执行过程中多个分区的交互.单线程式的事务调度彻底规避了在线式的并发控制技术,大大减少了并发控制引入的指令开销.
DORA[17]是一个面向数据的事务处理引擎.一些系统是将一个线程和一个事务耦合,这样的做法会因为事务频繁地访问数据而造成冲突,导致数据频繁地被上锁和解锁,从而浪费了大量的时间在锁管理上,多核的优势在这个地方产生了瓶颈.而DORA是将一个线程与不相交的数据库子集耦合,一个线程通常只访问一个数据集,避免了锁的开销.为了将每个事务的工作分发给合适的执行线程,DORA在事务编译阶段将事务解释为事务流图,事务流图是指对数据集的操作图,一个操作是事务的一段代码,操作的标识符代表了这个操作访问的数据区域.接着DORA根据操作的标识符找到相应的线程,将操作发放给该线程.不同的操作之间可能存在依赖,DORA的解决方法是在相互依赖的操作中加入一个共享对象RVP, RVP将相互依赖的操作放在不同的阶段执行,从而协调事务的分布式运行.DORA面向数据的设计方式减少了管理锁所耗费的性能,能够充分利用多核处理器的优势.
3.2.2 事务分片
Wang[16]等人提出了并发控制技术IC3来对事务并行进行管理,由于相互冲突的事务必须等待其中一个事务完成,另一个事务才能开始,这样的方式会导致较长时间的阻塞,因此, IC3通过事务分片的方式,将事务切割为很多片段,通过静态分析不同分片间的依赖关系,使得被依赖片段执行完成后,另一个事务的部分片段就可以开始执行,而不必等到被依赖片段所在的事务全部执行完.从而提高了事务处理的并行度.
3.3 事务编译在不同系统中的实践
目前有很多数据库利用事务编译提升了事务处理和事务调度的性能,表1是其中一些系统利用不同的编译技术、事务执行和管理优化方法达到的优化目标.

表1 事务编译在不同系统中的实践Tab.1Application of transaction compilation in different systems
4 总结
传统的磁盘数据库因为大量读写磁盘而产生了巨大的性能消耗,而内存数据库避免了这一问题,其事务执行主要的性能瓶颈在于CPU利用率.本文主要分析了传统事务执行方式和事务管理在内存数据库中的性能花销,介绍主流优化系统如何利用事务编译技术改进事务执行和事务调度.
事务编译的主要优势在于:①更少的指令数量和更高的指令缓存命中率.相对于解释执行,编译执行可以在编译阶段完成大量的工作,并产生更加紧致的执行代码.②更优的事务调度计划.通过分析事务的执行逻辑,系统可以在编译阶段确定部分事务请求之间的调度策略,从而产生更优的调度计划,并减轻在线调度的压力.然而,事务编译同样存在以下局限性:①编译需要更高的计算代价.这导致了编译通常需要离线完成.②编译缺少灵活性.产生的执行计划不能进行微调,单个操作的修改需要整体重新编译.③编译结果占据更多的存储空间.当事务类型过多时,编译产生的执行计划将会占据大量的存储空间.
针对事务编译,未来的研究趋势主要包括以下方面:①数据库特征感知的编译技术.当前的编译围绕在利用JIT将源码转换为机器码.然而,数据库的一些负载特征同样会影响执行计划的运行效果.我们可以引入这些信息来改进编译结果.②高效的编译技术.当前的编译需要较高的计算代价,因此是离线完成.然而,当源码或者数据库Schema发生变化后,执行计划需要完全重新编译.当系统部署的应用较多时,重新编译将产生很大的计算代价.因此需要考虑更加高效的编译方式.
[1]AILAMAKI A G,DEWITT D J,HILL M D,et al.DBMSs on a modern processor:Where does time go?[C]//Proceedings of International Conference on Very Large Data Bases.UK:VLDB.1999:266-277.
[2]哈索,亚历山大·蔡尔.内存数据库管理[M].SAP,译.北京:清华大学出版社,2013.
[3]BERNSTEIN P,BRODIE M,CERI S,et al.The asilomar report on database research[J].Acm Sigmod Record, 1998,27(4):44-113.
[4]GARCIA-MOLINA H,ULLMAN J D,WIDOM J.Database System Implementation[M].USA:Prentice Hall, 2010,132-179.
[5]ALEXANDER T,DANIEL I A.The Case for Determimism in Database Systems[J].VLDB,2010:70-80.
[6]WIKIPEDIA.Just-in-time manufacturing[EB/OL].[2016-06-01].https://en.wikipedia.org/wiki/Just-in-time manufacturing.
[7]DIACONU C,FREEDMAN C,ISMERT E,et al.Hekaton:SQL server’s memory-optimized OLTP engine[J]. SIGMOD,2013:1-13.
[8]DIACONU C,ISMERT E,LARSON P A,et al.Compilation in the microsoft SQL server hekaton engine[J]. IEEE,2014:22-32.
[9]NEUMANN T.Efficiently compiling efficient query plans for modern hardware[J].PVLDB,2011,4(9):539-550.
[10]吴亚鑫,孙静.基于数据库操作的相关性模型及应用[J].计算机工程与设计,2011,32(1):183-187.
[11]SHASHA D,LLIRBAT F,SIMON E,et al.Transaction chopping:Algorithms and performance studies[J].ACM Transactions on Database Systems(TODS),1995,20(3):325-363.
[12]TU S,ZHENG W T,KOHLER E,et al.Speedy transactions in multicore in-memory databases[J].Twentyfourth ACM Symposium on Operating Systems Principles,2013:18-34.
[13]STONEBRAKER M,WEISBERG A.The VoltDB main memory DBMS[J].IEEE DEBull,2013,36(2):21-27.
[14]KALLMAN R,KIMURA H,NATKINS J,et al.H-store:A high-performance,distributed main memory transaction processing system[J].PVLDB,2008,1(2):1496-1499.
[15]THOMSON A,DIAMOND T,WENG S C,et al.Calvin:Fast distributed transactions for partitioned database systems[C]//ACM SIGMOD International Conference on Management of Data.2012:1-12.
[16]WANG Z G,MU S,CUI Y,et al.Scaling multicore databases via constrained parallel execution[C]//ÖICAN F,KOVTRIKE G,MADDEN S.SIGMOD Conference.New York:ACM,2016:1643-1658.[17]PANDIS I,JOHNSON R,HARDAVELLAS N,et al.Data-oriented transaction execution[J].PVLDB,2010,3(1): 928-939.
[18]In-Memory Operational Database,SQL and Scale-Out.VoltDB[EB/OL].[2016-06-03].http://voltdb.com.
[19]Introduction to MemSQL.MemSQL[EB/OL].[2016-06-03].http://www.dbms2.com/2012/06/18/introductionto-memsql/
[20]STONEBRAKER M,MADDEN S,ABADI D J,et al.The end of an architectural era it’s time for a completerewrite[J].VLDB,2007:1150-1160.
[21]HELLERSTEIN J M,STONEBRAKER M,HAMILTON J.Architecture of a database system[J].Foundations and Trends Databases,2007,1(2):141-259.
[22]KEMPER A,NEUMANN T.HyPer:A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots[J].ICDE,2011:195-206.
(责任编辑:张晶)
Compilation techniques for high throughput transaction processing
WANG Dong-hui,ZHU Tao,QIAN Wei-ning
(Institute for Data Science and Engineering,East China Normal University, Shanghai200062,China)
Because of the problem of low utilization of CPU in memory database,the present research work is focused on improving the execution efficiency and concurrency control by transaction compilation technology to improve the performance of database. This article mainly introduces the following aspects of the memory database transaction compilation technology.First,this paper introduces the general process of transaction processing and analyzes the factors that limit the performance of the system.Second, we analyze the compilation techniques,including Just-in-time Compilation,Dependence Theory and Transaction Chopping.Third,we analyze the database and show how to improve the performance combined with the introduction of typical memory database,such as VoltDB,Hekaton and so on.Finally,the research prospects are given.
transaction compilation;concurrency control;just-in-time compilation; dependence theory;transaction chopping
TP391
A
10.3969/j.issn.1000-5641.2016.05.002
1000-5641(2016)05-0010-08
2016-05
国家863计划项目(2015AA015307);国家自然科学基金(61432006)
王冬慧,女,博士研究生,研究方向为分布式数据库.E-mail:zjnuwangdonghui@163.com.
钱卫宁,男,教授,研究方向为可扩展事务处理和海量数据分析与挖掘. E-mail:wnqian@sei.ecnu.edu.cn.
