基于LSM Tree的分布“索引实现
2016-11-29隆飞翁海星高明张召
隆飞,翁海星,高明,张召
(华东师范大学数据科学与工程研究院,上海200062)
基于LSM Tree的分布“索引实现
隆飞,翁海星,高明,张召
(华东师范大学数据科学与工程研究院,上海200062)
近年来Log-Structured-Merge(LSM)Tree在NoSQL系统中得到了广泛地应用.主要是因为LSM Tree架构提出了延迟更新和批量写入的算法,将随机写转换为批量写,减少了磁盘臂的移动开销,从而大大地提升了数据库的写入性能.然而,读性能却也因此受到影响.LSM Tree和B Tree之间的本质区别使得NoSQL系统不适宜直接引用B Tree作为辅助索引结构.本文实现了LSM Tree下的一种分布式辅助索引结构,提出针对这种读写分离架构的索引批量加载策略,并对LSM Tree的查询计划树进行了缓冲优化,避免了重复的查询解析,使得索引读的性能得到了相应的提升.
辅助索引;日志结构合并树;NoSQL
0 引言
近些年,伴随着数据采集设备的快速发展,用户成为产生数据的主体,产生的数据总量往往会达到TB甚至PB级别.集中式数据库在处理这些数据时,代价高昂.因此,水平扩展良好的NoSQL数据库应运而生,并迅速发展起来.大多数NoSQL系统都是基于key-value形式的存储架构,例如HBase[1],LevelDB,Apache Cassandra[2]等.它们都是搭建于廉价的硬件设施之上,往往适用于对数据库的伸缩性,高性能,高可用和低成本有更高要求的应用.
无论是传统的关系型数据库抑或是新型NoSQL数据库,更高的数据查询速度始终是不变的追求.典型的NoSQL系统只支持key上的查询操作,对于value上的查询操作支持都不是很友好,但许多应用需要快速查询value列的某一行,因此它们对于NoSQL上的辅助索引的需求也越来越迫切.为了满足NoSQL数据库对于辅助索引的需求,本文实现了解决大规模数据量的分布式辅助索引功能,设计了针对Log-Structured-Merge(LSM)[3]体系的批量加载策略以解决基线数据上索引的构建任务,通过使用索引列进行查询,能够大大提高对数据表中非主键数据的查询性能.
分布式存储引擎下的索引实现对于NoSQL类系统有着重大的意义,同时它的研究已经成为查询效率研究的热点之一.例如,华为公司实现在HBase上建立辅助索引HIndex[4], Google Spanner[5]中支持高并发跨数据中心情况下满足事务一致性的索引,Chen et al[6]提出了一种云端类DBMS的索引框架,华东师范大学数据工程研究院在阿里的数据库Oceanbase上实现辅助索引[7]等等.
本文的章节安排如下:第1节首先介绍了背景及其研究现状,包括LSM Tree模型和其存储架构;第2节描述了辅助索引的结构,阐述了辅助索引的单点存储方式和分布式存储方式;第3节是介绍了分布式存储架构下辅助索引的实现细节;在第4节,本文做了一些实验来验证辅助索引为查询带来的性能提升,并针对本文对辅助索引所做的一些优化进行了实验验证;第5节作为全文的总结并分析了未来工作.
1 基于LSM-Tree的分布式存储系统架构
LSM模型诞生于1996年.自Google公司的BigTable[8]论文发表之后,LSM模型受到大量的关注.LSM对于数据的变化采用的是延迟和批量写的算法,将内存与磁盘中的数据级联在一起.与传统的B Tree相比,LSM会先将一段时间内的插入操作缓冲在内存,当内存达到阈值时,再将内存中的数据和磁盘上的数据做合并,并顺序写入一个或多个磁盘页.这种顺序写相比于随机写,能够明显地减少磁盘臂的移动,会快很多;因此LSM Tree能够提升数据库的写入性能.比较适合LSM-Tree的应用场景是:insert数据量大,读数据量和update数据量不高且读一般针对最新数据,例如历史库和日志文件.Diff-index[9]论文指出LSM是针对写作了优化的而B Tree对读和写都只做了一些简单的优化.
LSM Tree由许多位于磁盘上的树结构成分和一个驻留在内存当中的成分组成.数据按照主键排序,以SSTable[8](Sorted String Table)的形式存储在磁盘组件中.如图1所描述,分布式LSM架构将数据分为增量数据和基线数据,分别存储在更新服务器和基线服务器上.图中包含一个内存组件和三个磁盘组件.当客户端发起更新请求时,首先会在磁盘上追加一行操作日志,然后,将更新的数据写入到C0 Tree当中.当内存达到存储阈值,LSM Tree会发起合并流程.为了取回数据的实际值,读操作不得不对每个磁盘中的树结构上进行查询.

图1 LSM存储模型Fig.1LSM storing model
在一些大规模数据分析的应用当中,相对于整个数据库,更新数据量往往不是很多.对于这部分数据,可以直接存放在内存当中.如图2所示,在读写分离情况下,内存数据往往存放在一个单独的服务器当中,称为UpdateServer(UPS),对应LSM中的C0组件.基线数据存储在Chunkserver(CS)中.根据应用的规模,可以对CS水平扩展.在CS上实现LSM的不同级别的存储.Rootserver(RS)是整个集群的管理者,管理集群中的所有服务器,数据分布,元数据信息以及副本信息.为保证RS的高可用性,通常RS采取主备架构,主备之间强一致. MergeServer(MS),是SQL解析模块,产生查询计划,并将每个Tablet的读取请求发送到相应的CS.CS首先读取磁盘中包含的基准数据,接着请求UPS,获取相应的增量数据,并将基准数据与增量数据融合后得到最终结果,返回给Client[10].
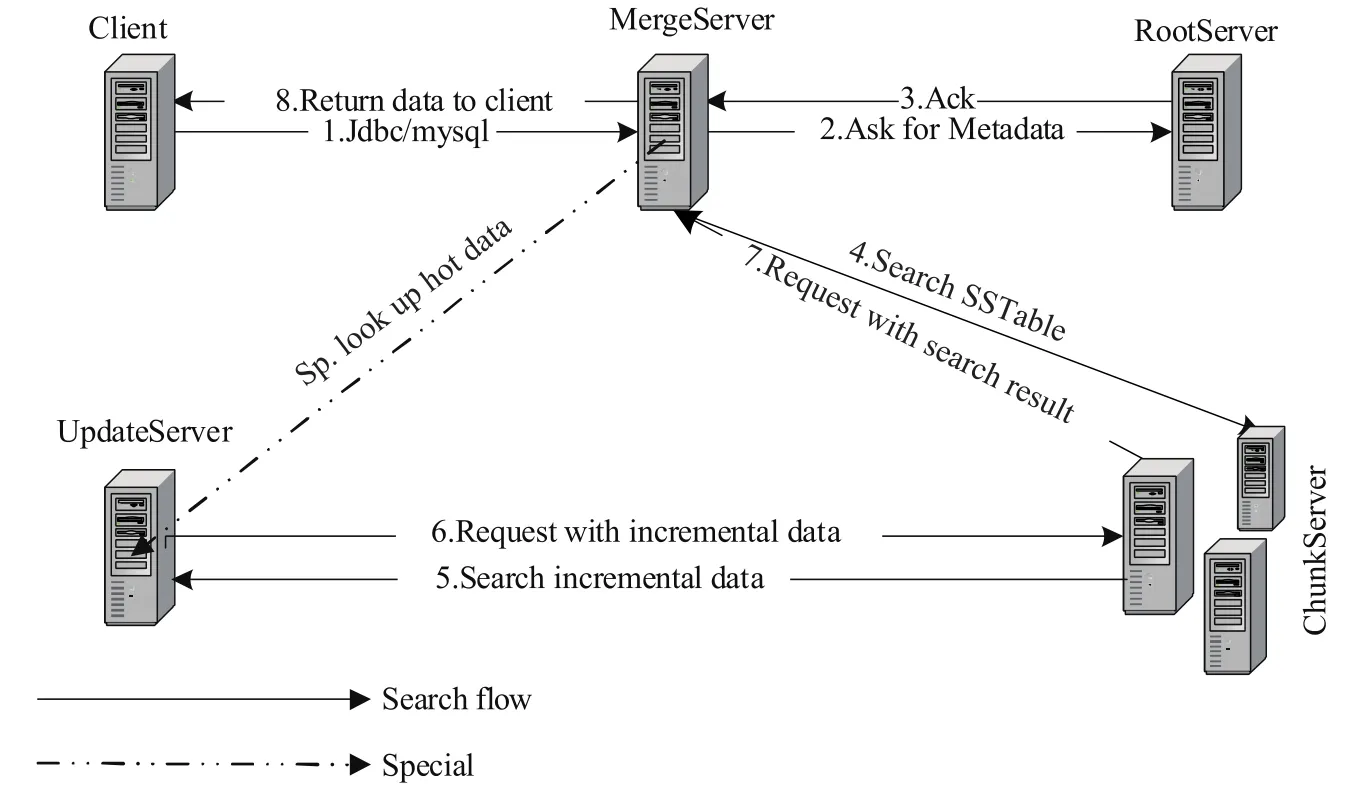
图2 分布式存储架构图Fig.2Distributed system architecture
2 辅助索引结构描述
2.1 索引存储结构
对于许多NoSQL系统而言,数据是以key-value对的形式组织在磁盘当中的.Key-value对是最简单的非基本数据模型之一,一些其他更复杂的数据模型则都是在它的基础之上建立的.由此本文定义了数据的存储模式:D={t|t=〈key,{values}〉}.此模式将数据库定义为元组的集合,元组以〈key,{values}〉的形式存储在磁盘上,并按照key值对数据进行排序, values是多个value的集合.key类似于传统数据库中的主键,不允许重复,因此key所在列构成NoSQL系统中的主索引.
随着越来越多的应用采取NoSQL系统作为数据管理系统,而这些应用的负载大多是以value列为查询列,因此主索引无法满足应用的需求,建立value列上的辅助索引的需求也越来越强烈.传统的辅助索引定义形式如下:M={t|t=〈search key,pointer〉}.传统的辅助索引包括BTree索引和Hash索引等,都是将索引组织在内存当中,并以pointer的方式定位到磁盘中的数据.这种方式对处理海量数据的分布式数据库并不适用[11],主要原因有:维护代价大;制约了数据库的水平扩展性等.
本文提出一种基于读写分离式LSM架构的索引结构,其存储模式如下所示:MD={D mem+D disk|D mem={〈search key+primary key,{covering}〉},D disk= {〈search key+primary key,{covering}〉}}.索引分为两个部分:位于UPS中D mem部分和位于磁盘中的D disk部分.其存储结构中摒弃了传统索引的指针部分,而将search key和primary key作为索引存储结构的联合主键.与传统数据库类似,使用冗余列来实现覆盖索引(covering index),避免二次查询操作,从而提高查询效率.
在实现中,索引表按照联合主键水平切分成多个tablet.每个tablet按照一定的策略均匀分布到集群中的CS上,满足基线和增量数据分离特性,并由RS执行负载均衡.实验证明这种适应于架构的索引实现方法可以很好地满足非主键列查询需求.

图3 索引表存储模型Fig.3Storage model of secondary index
必须强调的是,本文的实现方法与传统的索引实现差别较大,但是能够满足索引高可扩展性以及高可用性的需求.从本质上说,索引表就是存储在数据库中的另一张数据表.图3中给出存储的一个示例,辅助索引表Si1(Secondary index 1)将索引列和原数据表T1(Table1)的主键列作为自身的联合主键,同时添加一些附加列信息.T1物理上按照主键列进行排序,并水平切分成为T1c1,T1c2和T1c3三个部分,分别存储在CS1,CS2和CS3上.Si1按联合主键在磁盘上重新排序,Si1c1,Si1c2和Si1c3是其对应的水平切片.T1的第一主键是itemkey,而Si1的第一主键是type.
辅助索引表构建时,并不构造出整张表.而是直接在每个CS上直接构造辅助索引的每个部分.并将构造完成的每个SSTable的主键范围信息汇报给RS,然后由RS发起拷贝副本的操作.
2.2 索引特征分析
存储代价:分布式数据库中引入索引对原来的系统的影响主要体现在更新数据表时带来的额外代价和索引存储的额外代价.然而,索引表一般只存储数据表的某些列,其存储空间远远小于数据表,属于可接受范围.因为更新操作均在UPS的内存中完成,时间成本也远远小于磁盘读操作,因此其对于性能的影响也可以接受.
可扩展性和弹性:本文实现的索引功能支持水平扩展,不会影响数据库的可扩展性.通过增加集群当中的CS和MS的数量,集群的整体性能“线性可扩展”.并且索引支持在集群运行过程当中,动态增加结点,弹性良好.
可用性:创建索引表的时候可以指定索引表在集群中的副本数目.在索引批量加载的过程中会在不同的CS上创建多份副本,以保证索引数据的可用性.目前,在构建索引过程中,CS发生故障会影响到索引的构建过程,每日合并结束后,索引状态不可用.索引创建失败不会影响集群的正常使用.
3 索引实现及维护
索引实现分为两个部分,一部分是索引构建完成后动态维护部分,这部分内容比较简单,实现时只需保证原数据表和索引表之间的数据一致性即可;另一部分是对原表上已经存在的数据的处理,必须将此部分数据同步到索引表中.很自然的想法是将原数据表中的数据一条条插入到索引表当中,但是此种方法效率难以接受.考虑到索引表在磁盘中是以SSTable的形式进行存储的,可以实现一种批量加载的方法,构造出索引表数据的SSTable.批量加载效率很高,但是难点在于如何收集分布在集群各个部分的CS上的数据,也在于如何对收集的数据进行排序.3.1将介绍批量加载实现,3.2节简单介绍索引一致性模型.
3.1 基线服务器上索引的批量加载
3.1.1 批量加载实现
批量加载的难点在于对收集的数据进行排序,为了尽可能避免全表扫描,本文将排序分为局部排序和全局排序两个阶段.批量加载过程充分利用架构特点,在集群中的每个CS上单独进行,可以避免大量数据迁移.同时使用多线程技术,并行处理数据表的不同tablet数据,加快批量加载流程的速度.
在数据表上创建索引表的时候,必须将数据表中已经存在的数据批量加载到索引表当中,之后,索引表才能够正常提供服务.合并子模块定期将UPS中的增量数据合并到CS中,论文[12]描述了一种具体的合并模块的工作流程,称为每日合并模块,采取排序合并算法进行数据合并.因为在索引批量加载过程当中,会阻断所有的DDL操作,并且索引表批量加载时必须获得最新的数据表静态数据,所以为了尽量减小索引构建过程对于整个系统的影响,本文将索引的批量加载安排普通的每日合并流程之后.批量加载主要分为以下四个阶段:第一阶段,进入批量加载的准备阶段.为了使得索引表能够获得最新的数据,我们在构建索引表之前需要进行一次每日合并.因此,合并过程成为批量加载的准备阶段.系统没有执行索引批量加载流程时,所有索引构建线程被阻塞,见算法1.

算法1批量加载算法-Schedule输入:tablet信息或者range信息输出:索引构建信息1.for every thread in each CS do 2.get tablets ranges() 3.if(get nothing) 4.pthread cond wait(&cond,&mutex); 5.else if(get tablets) 6.Call construct local(tablet);//完成数据tablet准备,进入局部阶段7.else 8.Call construct global(range);//收到Range信息,进入全局排序阶段9.end if 10.end for
其次,进入局部索引构建阶段.如算法2所示,当普通的每日合并完成之后,B开始索引的静态数据部分的构建.当CS接收到了RS的创建索引的信号之后,获得一个数据表的tablet,对这个tablet按索引列进行排序,并写到一个局部的sstable中.完成以上步骤之后,CS向RS汇报局部索引sstable的信息.

算法2批量加载算法-局部排序(construct local(type&tablet))输入:局部阶段开始信号输入:局部有序SStable文件1.get local index handler//唤醒工作线程2.for each local index handler do 3.create new sstable//用于存储排好序的SSTable 4.sort.get next row(row)//排序5.Add information into index reporter 6.Calc column checksum for data 7.tablet->add local index sstable//SSTable暂存在数据表的tablet上8.if(success) 9.Report information to RS 10.else 11.Push this into local failed list 12.end if 13.end for
第三阶段,进入全局索引构建阶段.如算法3所示,RS接收到了CS发过来的采样信息之后,将索引列划分为若干个range,尽量使得每个CS上的tablet的数量相等,以达到负载均衡. RS将切分后的range信息发送给CS.CS根据这个range信息互相之间拉取数据.这个阶段完成后,每个CS B完成了全局的索引构建.最后一个阶段是索引表批量加载完成阶段.这个阶段完成复制全局索引备份,检查数据校验和,修改索引表状态为可用.

算法3批量加载算法-全局排序(construct global(type&range))输入:全局阶段开始信号,RS发送过来的Range输出:全局有序SSTable文件1.get global index handler 2.for each global index handler do 3.start agent//agent从其他CS或自己上获取某个range内的数据4.execute get data plan 5.root.get next row()//调用local agent和interactive agent获取数据6.do column checksum 7.construct index tablet info//构造索引表的tablet信息8.close sstable//saving sstable in disk 9.if(success) 10.release sstable//释放局部阶段SStable信息11.do data checksum,modify index status 12.report information to RS 13.else 14.Push this into global failed list 15.end if 16.end for
3.1.2 范围切分算法
整个批量加载过程中涉及到CS和RS信息的交互以及CS之间的数据拉取.每台CS在完成索引构建局部排序阶段之后,进行Range信息采样,并汇报给RS,采样信息以等高直方图的形式记录.RS根据采样信息进行Range划分,决定每个CS全局排序的范围.样本数的设计会影响Range切分的均衡性,样本数越高,Range切分越均衡.但是样本数目太多,采样过于频繁影响性能,并且网络传输代价也会随之增大.因此本文实现将样本数定义为tablet的数目,并且设置一个最大值,当tablet数目超过最大值时,样本数被设置为最大值.
在算法4中,max bucket num是预设采样等高直方图桶的数目,值为256;tablet num是该数据表对应的数据分片的数目,sample num是样本数.采样时,每隔N行取出此行的主键信息作为Range的End key,N=(tablet总行数/sample num).每个CS独立完成采样,并将采样信息汇报给RS.RS接收到所有的来自CS的汇报信息之后将切分Range信息.首先RS将汇报信息做一个排序,见算法4的第三行;其次对Range进行切分,算法4的九到十三行描述了RS切分RANGE详细过程.

算法4:RS Range切分算法输入:来自CS的汇报信息ReportInfo输出:切分结果集Res 1.key=decode ReportInfo 2.if all reported is true and decoded successfully 3.sort all range info from ReportInfo//对汇报结果进行排序4.end if 5.sample num=min(max bucket num,tablet num)//计算样本数目6.for iter in[SortedReportInfo.begin(),SortedReportInfo.end())do 7.temp range count++ 8.end for 9.range step=temp range count/sample num//RS计算切分步长10.divide range count=(temp range count%range step==0)?sample num:sample num+1 11.for(int I=0;I<temp range count;I+=range step)do 12.Res[I].put(key) 13.end for 14.return Res
3.2 索引缓存方式调整
LSM Tree架构下的索引与传统的索引比较,其读操作需要一次内存访问和至少一次磁盘访问,因此速度会比传统的索引读操作慢一些.
在很多应用场景下,应用程序处理的语句几乎都是相同,而变化的都是where,set或者values后面的变量的具体数值.
针对这种场景,缓存索引查询的计划树,动态调整查询参数是非常有意义的.实现时,为每个索引查询分配一个sql id,将<sql id,query plan>以hashmap的形式存储在内存当中.相同的sql id可以在内存中获取相同的查询计划,避免了重复的查询解析过程.
4 实验结果与分析
4.1 实验环境
本文在阿里巴巴集团开源的分布式数据库系统OceanBase[13]上实现了辅助索引功能,以下简称OB.OB是一款增量数据和基线数据分离的LSM架构的分布式数据库产品,主要是为了解决淘宝网面临的大规模数据存储和管理问题.OB具有良好的可扩展性,能够实现了数千亿条记录、数百TB数据上的跨行跨表事务[14].
本文实验集群搭建在4台服务器上.每台服务器的硬件环境如下:64-bit 2.00 GHz 24核Intel(R)Xeon(R)CPU E5-2620,132 GB内存,千兆以太网,磁盘3.7TB,操作系统CentOS release 6.5(Final).将RS和UPS配置在同一台服务器上,另外三台服务器均配置为MS和CS,数据库的副本数目设为3.
实验的目的在于验证本文实现的辅助索引对于提高查询速度的带来的贡献,以及验证本文在索引上所做的一系列优化的效果.
4.2 实验结果及分析
实验1使用雅虎的标准测试工具YCSB(Yahoo!Cloud Serving Benchmark)[15]进行测试,并选择工作负载C,这个工作负载是100%的读操作,Query执行总次数为10万次,为了与索引读返回列数相同,readallfields设置为false.本文对YCSB进行了扩展,使得YCSB核心负载集能够进行非主键列查询.为简化实验,本文重新定义数据生成方式,保证索引列于PRIMARY KEY是一对一的关系.实验采用数据集为1000万行,使用YCSB实现的JDBC数据库层接口逐行导入.在未添加索引时,利用YCSB对OB非主键进行查询,超出YCSB响应时间限制,未得出实验数据.实验1可以从侧面反映出辅助索引实现后对于查询的性能提升.考虑到索引的具体实现,本文将原表索引查询与原表主键查询进行对比,结果如图4.

图4 YCSB只读查询性能对比Fig.4Only-read performance using YCSB
可以看到,索引查询速度基本和主键查询速度一致.两组实验分别在80和100个线程数时吞吐率达到最优,这是因为本文所做的实验使用YCSB连接到一个MS上.单台MS对于连接数目有一定限制,当超过这个限制的时候,线程在MS发生冲突,并排队等待,性能不会随着线程数目上升.实验可以得出结论:索引查询性能能够达到主键查询的性能,而未实现索引查询之前,非主键列查询无法完成.
实验2测试使用一张商品表item,主键为itemkey,在type属性上建立索引,count是表中不被索引表覆盖的一列.数据集大小为1 000万行,891MB.测试中使用SQL如下所示:
Query1:select itemkey from item where type=
Query2:select itemkey from item where type=?
Query3:select count from item where type=
Query4:select count from item where type=?
参数使用随机数产生,保证一定命中数据库中的数据.?表示此版本的数据库实现了索引查询计划的缓存.
基于辅助索引的实现策略,可以将索引查询分为两类:回表和不回表,具体是指查询是否需要从索引表对应的数据表中取出数据.如图5中所示,NotBack prepared代表的是不回表的查询并且会缓存索引查询执行计划(Query2),Notback Notprepared代表的是不回表且不会缓存执行计划的查询(Query1),Back prepared代表的是回表且缓存执行计划的查询(Query4), Back Notprepared代表的是回表且不会缓存执行计划的查询(Query3).分别比较回表和不回表情况下,缓存索引查询计划对于性能的提升.回表情况下性能提升了6倍左右,不回表的情况下性能提升在3~7倍之间.

图5 缓存执行计划性能对比Fig.5Execution plan performance
5 结语
主索引和辅助索引对于数据库查询优化有重要的意义.现在绝大多数流行的NoSQL数据库一般只支持到主索引,但是越来越多的应用要求非排序列上的查询操作.本文根据读写分离架构存储体系的特点设计实现分布式的二级索引方案.此方案符合一般的NoSQL架构,可以很容易在迁移到HBase等其他架构类似的系统中.在索引构建过程中,遇到各种问题时故障恢复工作,以及分布式索引缓存优化是本文未来将要考虑的工作.
[1]APACHE ORG.Apache HBase[EB/OL].[2016-07-07].https://hbase.apache.org/.
[2]LAKSHMAN A,MALIK P.Cassandra:A decentralized structured storage system[J].ACM SIGOPS Operating Systems Review,2010,44(2):35-40.
[3]O’NEIL P,CHENG E,GAWLICK D,et al.The log-structured merge-tree(LSM-tree)[J].Acta Informatica, 1996,33(4):351-385.
[4]HUAWEI.Secondary index in HBase[EB/OL].[2016-07-07].https://github.com/Huawei-Hadoop/hindex.[5]CORBETT J C,DEAN J,EPSTEIN M,ET A L.Spanner:Google’s globally distributed database[J].ACM Transactions on Computer Systems(TOCS),2013,31(3):8.
[6]CHEN G,VO H T,WU S,et al.A framework for supporting DBMS-like indexes in the cloud[J].Proceedings of The Vldb Endowment,2011,4(11):702-713.
[7]翁海星,宫学庆,朱燕超,等.集群环境下分布式索引的实现[J].计算机应用,2016,36(1):1-7.
[8]CHANG F,DEAN J,GHEMAWAT S,et al.Bigtable:A distributed storage system for structured data[J].ACM Transactions on Computer Systems,2008,26(2):4.
[9]TAN W,TATA S,TANG Y,et al.Diff-index:differentiated index in distributed log-structured data stores[C]. Extending Database Technology,2014:700-711.
[10]阳振坤.OceanBase关系数据库架构[J].华东师范大学学报(自然科学版),2014(5):141-148.
[11]孟必平,王腾蛟,李红燕,等.分片位图索引:一种适用于云数据管理的辅助索引机制[J].计算机学报,2012,35(11): 2306-2316.
[12]黄贵,庄明强.OceanBase分布式存储引擎[J].华东师范大学学报(自然科学版),2014(5):164-172.
[13]ALIBABA INC.OceanBase[Z/OL].[2016-07-07].https://github.com/alibaba/oceanbase/tree/master/oceanbase 0.4.
[14]杨传辉.大规模分布式存储系统:原理解析与架构实战[M].北京:机械工业出版社,2013.
[15]COOPER B F,SILBERSTEIN A,TAM E,et al.Benchmarking cloud serving systems with YCSB[C]// Proceedings of the 1st ACM Symposium on Cloud Computing.ACM,2010:143-154.
(责任编辑:李万会)
Distributed secondary index based on LSM Tree
LONG Fei,WENG Hai-xing,GAO Ming,ZHANG Zhao
(Institute for Data Science and Engineering,East China Normal University, Shanghai200062,China)
In recent years,Log-Structured-Merge Tree has been widely used in NoSQL systems.This is mainly because it has proposed two algorithms:update delayed and batch write,convert random write to batch write,reducing the cost of moving the disk arm therefore the write performance of database has been enhanced greatly.However,the read performance of database has also been affected negatively.The essential difference between LSM Tree and B Tree makes NoSQL not suitable for using B Tree as index structure directly.This paper implements a distributed secondary index based on LSM Tree,and proposes a bulk loading method in this read and write separation architecture.We also do lots of works on the optimization of index query plan to avoid repeatly query parsing IO so that the performance of index read has been greatly improved.
Secondary Index;LSM Tree;NoSQL
TP31
A
10.3969/j.issn.1000-5641.2016.05.005
1000-5641(2016)05-0036-09
2016-05
国家863计划项目(2015AA015307);国家自然科学基金(U1401256,61402180, 61402177);CCF-腾讯联合研究基金(AGR20150114);上海市自然科学研究基金(14ZR1412600)
隆飞,男,硕士生,研究方向为分布式数据库.E-mail:451858158@qq.com.
张召,女,副教授,硕士生导师,研究方向为数据库.E-mail:zhzhang@sei.ecnu.edu.cn.
