海量气象站点数据分布式存储测试及其应用
2016-11-29徐拥军何文春倪学磊
徐拥军,何文春,刘 振,王 琦,倪学磊
(国家气象信息中心,北京 100081)
海量气象站点数据分布式存储测试及其应用
徐拥军,何文春,刘 振,王 琦,倪学磊
(国家气象信息中心,北京 100081)
站点数据是气象观测数据的主要组成部分,每日检索量大,且时效要求高。为了更好地管理与服务气象资料,国家气象信息中心从2013年开始致力于新存储技术在气象领域的探索。为了更好地兼容目前的存储与服务方式,选择了分布式关系型数据库作为技术方案,并开展了一系列仿真气象业务场景的测试。测试结果表明,分布式数据库无论在数据插入还是在检索方面都具有较好的性能,同时具有较好的可靠性、灵活性和扩展性。根据测试结论,搭建了分布式存储试验系统,导入了CIMISS地面、高空等建站以来的历史数据,并接入了站点数据的实时流程。实现了海量站点资料的完全在线,同时也满足了气象业务对资料高时效性的需求。
气象站点数据;分布式存储;自动站;性能测试
1 引言
气象部门是一个以数据信息为核心的领域,2000年之前,其核心业务问题主要是通信和计算(NWP),近十几年来,核心业务问题逐渐转向数据信息存储、应用和服务[1]。随着气象事业的快速发展,气象探测设备不断增加,观测台站上传的数据正在急剧增加,存储总量呈现几何式增长。目前气象数据每年增量达到PB量级,已具备大数据的特征。随着公众对气象服务需求的日益增长,要求天气预报向精细化、全时空和集合预报的方向发展,气象服务多元化并从传统气象向“公共气象、安全气象、资源气象”拓展[2]。随着气象服务方式的改变,对气象资料服务的时效越来越高,气象发展面临着更大的挑战。
面对海量气象数据,传统的数据存储管理方式越来越不适应气象数据服务的需求,急需引进新技术解决面临的困境。由于大数据特征,气象数据存储管理系统必须具备以下三个特征:①高可用性。具备数据冗余存储,保证气象资料存储安全和业务运行连续性。②高性能。快速入库存储与检索服务。③高可扩展性。满足快速气象数据增长时,具备横向大规模扩展性。
气象资料种类很多,在存储上分为结构化与非结构化两种方式,结构化资料包含地面、高空、海洋、水文、气象辐射、农业气象等气象站点资料,非结构化资料包含雷达、卫星、数值预报等产品资料。在整个气象数据中结构化资料占据很重要一部分,地面自动站资料占据结构化数据的90%以上。结构化资料是气象预报、预警服务重点之一,目前采用的传统关系型数据库技术已经不能满足海量气象结构化资料存储和服务时效的需求。大数据技术的快速发展,为解决结构化资料服务时效提供了多种解决方案,本文以地面自动站资料为测试数据源,重点介绍分布式关系型数据库在气象领域的探索试验工作,主要包含分布式存储性能测试以及在业务中的应用。
2 地面自动站数据量以及未来增长估算
1951—2005年,地面站(2 000多个)主要为人工观测,以小时为单位收集数据,年数据增量为GB量级;2005年以后,地面气象观测自动站的建设,使得观测要素、观测频次得到极大提高[3],年数据增量在2011年达到TB量级。截至2014年6月,气象业务数据经多年的积累,现有数据规模约为12TB(单份数据),其中,2012年7月—2014年7月的数据量为3.5TB(不含索引数据),表现出一个大幅增长的趋势。由于观测自动化,观测台站建设变得越来越容易,2005年6月以来,自动站台站数每年都有相应的增长,增长趋势见图1,统计数据来源于每年6月国家气象信息中心接收自动站的上报量。
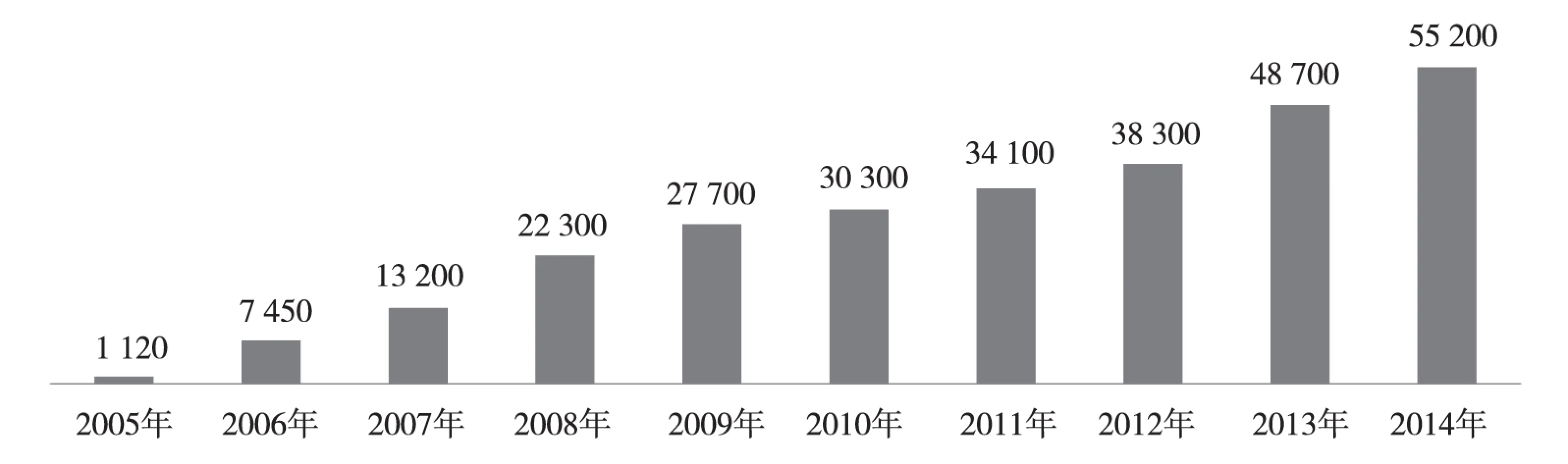
图1 自动站站点数增长趋势Fig.1 The growth trend of automatic meteorological station number
目前,在地面气象资料数据库中,小时资料表和分钟资料表的数据量最大,自动站全要素表小时资料5万站1 h一条记录。地面自动站分钟降水数据表中,约有1.8万左右的雨量观测站1 min采集一次信息,其余区域观测站为5 min采集一次。其它多要素分钟资料为5万站5 min 1条记录。总体来看,当前数据库的每日数据增加总量为350~450万条记录,每日的数据增长规模已达4~5 GB。
在不远的将来,随着业务拓展的需要,所有分钟资料数据表将是5万个观测站每分钟采集一次信息,其中,地面自动站分钟降水数据表字节数为400、地面分钟气压、温度、湿度、风速、地温常用要素数据表字节数为400、地面分钟其它要素数据表字节数600,3个表字节总数为1.4 KB。若以每日增量5万×60×24=72 00万记录计算,其每日数据规模增量约为100.8 GB左右。所有小时资料表将是5万个观测站每小时采集一次信息,其中,中国地面逐小时探测资料数据表字节数为1.2 KB、地面逐小时探测原始资料数据表字节数为4 KB,两表字节总数为5.2 KB。若以每日增量5万×24=120万记录计算,其每日数据规模增量约为6.2 GB左右。因此,未来数据库每日数据增长总规模将达到约107 GB左右。
随着新增观测台站数量的增加以及观测频次提高,数据将大幅增长,这给检索的时效要求带来严重的压力。如何提高大数据规模下的查询性能,尤其是在多用户并发访问时满足查询要求,将是一个非常大的难题。
3 分布式存储性能测试内容及方法
分布式数据库系统是物理上分散而逻辑上集中的数据库系统,其使用计算机网络将地理位置分散的多个逻辑单位连接起来,共同组成一个统一的数据库系统,是在集中式数据库基础上发展起来的,除了提供集中式数据库的功能外,还提供数据跟踪、分布式查询处理、分布式事务管理、复制数据管理、安全性管理等功能,系统主要有如下特点:数据具有物理分布性;分散在各个节点的数据,逻辑上却构成一个整体,有一个分布式数据库管理系统进行管理;各个节点的数据由本地的数据库系统分别管理。同时具有以下优点:良好的可靠性和可用性、较大的灵活性和可伸缩性、经济性、数据分布透明性和良好的节点自治性等[4]。基于气象数据存储服务的需求,在分布式数据库系统中进行了以下几个方面的功能测试。
3.1 高性能
传统关系数据库能勉强应付上万次SQL查询请求,但难以满足数据库高并发读写的需求。自动站资料在未来5 a,每分钟需要进行6万站次数据的入库操作,同时具有400~600个用户的并发数据检索服务。传统关系型数据库在此情况下,即使升级硬件,硬盘I/0也将面临极大的瓶颈。
3.1.1 入库性能测试 主要验证分布式关系型数据库进行自动站资料入库能力。具体方法如下:①导入上亿数据记录,积压一批自动站原始报文资料(比如1 d);②利用自动站解码程序,将自动站原始观测报文解析为数据库插入SQL语句,通过数据库提供的接口进行数据入库操作;③截取入库过程中的一段时间,查询入库记录数,计算平均每分钟入库量。
3.1.2 高并发检索性能 主要验证在实时数据入库(目前每5 min 5万记录入库)的同时,不同并发用户随机检索测试用例,并将检索数据返回内存的响应时间。测试方法如下:①编写模拟气象资料检索业务的并发检索程序;②在模拟并发用户的背景服务器上运行不同并发数的检索业务程序;③在模拟客户端服务器上运行1个气象业务检索应用,并记录检索用例的响应时间;④统计分析各个用例的时间,统计量为检索用例的平均时间、最大最小时间以及检索时间标准差。为了降低异常数据对整体性能的影响,在统计平均时间采用去除最大值和最小值后的平均值。平均时间可有效评估数据库用例检索的整体性能,最大、最小时间以及检索时间标准差可评估用例检索波动性,有助于了解整体数据库检索稳定性。
3.2 高可靠性与可用性
由于分布式数据库采用相对廉价的机器进行整体系统搭架,各个节点的可靠性不高,为了保障整个系统的可靠性,分布式数据库采用多副本冗余策略。通过该项测试验证在单个节点故障场景中,整个系统是否能正常运行,节点故障前后数据是否完整。测试方法如下:①检索若干条SQL语句,并将结果存储;②拔除某个节点的网络,使之脱离整个数据库集群;③验证节点故障后,资料入库、检索是否正常运行。执行节点故障前的SQL语句,验证数据结果是否一致。
3.3 灵活性与可扩展性
在传统集中式数据库系统中,系统设计时需要对未来业务发展给出正确的评估,以及充分考虑系统的存储和处理能力,在业务运行初期,容易造成资源浪费,后期虽然留有余地但仍不能适应变化的需要。升级系统不但会影响应用的正常运行,而且当升级涉及不兼容的硬件或系统软件有修改时,应用软件也必须进行相应的修改,代价十分昂贵。分布式数据库系统增加节点不但容易而且不会影响现有系统结构和系统的正常运行,扩展节点后性能将得到提升。通过该项测试,验证分布式数据库增加节点过程中是否影响现有业务运行,节点增加后性能提升曲线。测试方法如下:①在一定数据量的数据库中,进行测试用例检索;②增加N个数据库节点;③验证增加节点对现有气象数据入库/查询检索的影响;④记录节点增加后,在数据均衡期间数据检索的效率;⑤记录数据完成均衡的时间,数据均衡后,气象数据检索的效率。
4 气象数据测试结果及分析
4.1 测试环境
为了验证分布式数据库系统管理海量结构化气象数据可能性与适应性,利用20台PC服务器、2台万兆交换机(由于测试服务器网卡限制,测试使用千兆网口),仿真业务环境搭建了气象数据分布式存储测试平台。服务器配置如下表1,网络布局如图2。
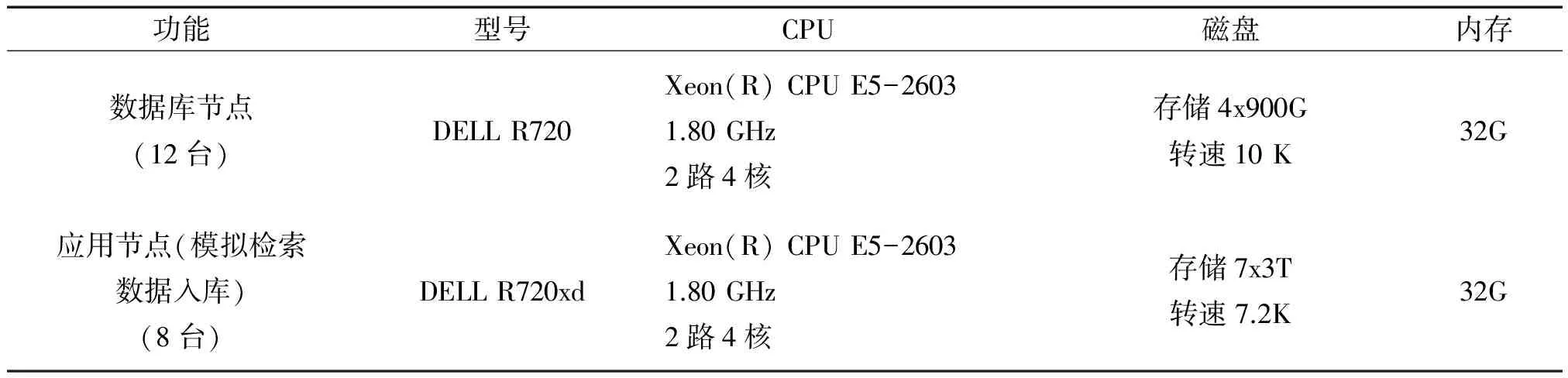
表1 测试服务器性能参数

图2 测试环境网络布局Fig.2 The network of test system
4.2 测试数据
采用2个数据副本保障节点故障时数据的可用性。在各项性能测试之前,导入单份550GB(单表5.5亿的记录),整个集群存储1.65TB历史数据,后续测试均在该数据基础上开展。
实时数据完全模拟现有业务,接收各省上传的自动站信息,利用入库程序实时处理并存储在数据库中,然后提供检索服务。针对气象业务特征以及用户检索习惯,选定了7个常用典型用例,涉及到实时数据检索、单站长时间序列检索以及统计检索3个方面,详见表2。
4.3 测试结果分析
传统数据库采用目前常用的关系数据库Oracle,服务器为IBM 740,其它与分布式测试环境相同。整个测试过程仿真气象业务场景,既有站点数据的入库又有测试用户的检索。检索结果为超过200个检索样本的平均值。
4.3.1 资料入库性能 验证单位时间内,通过入库程序解析自动站要素信息并存储在数据库的记录数。测试时分布式采用9个数据库存储节点,1台入库服务器。与传统数据库的对比结果见表3。

表2 气象结构化数据检索用例说明
4.3.2 高可靠性与可用性 验证在数据库某个节点发生故障时对业务无影响。在9个存储节点环境中,拔出任一节点的网线使之脱离数据库集群,模拟节点故障。通过测试,节点拔出前后,实时数据入库未出现中断,检索应用服务也能正常运行。并且节点拔出前后,相同检索SQL语句检索的结果完全一致,数据无丢失。

表3 入库性能对比
4.3.3 高并发检索性能 验证测试用例在不同并发背景环境中检索性能是否符合业务需求。在进行高并发检索测试之前,为了真实有效地了解对数据库施压量,需要对每台背景服务器最大加压数进行测试。通过对单台背景服务器分别进行40、60、80、100个模拟用户同时检索,以及对背景服务器各项性能指标的监视,得到系统资源使用情况,最后确认单台背景服务器并发数不超过80,详见表4。

表4 背景服务器不同并发资源使用参数
利用分布式环境中9个存储节点,9个背景服务器,1个模拟客户端服务器以及1个入库服务器,得到该环境中7个测试用例的检索性能,结果如表5,其中数据均为多次检索的平均值,单位为ms。

表5 不同并发背景测试用例检索结果
利用相同的方法,在相同数据量(5.5亿记录)的环境中,测试了7个用例在传统数据库中加压50个模拟用户并发时的检索时效,其中分布式数据库7个用例的平均检索性能是传统数据库的9.5倍,对比结果如图3所示。为了图形具有较好的显示效果,纵坐标采用基为10的对数刻度。
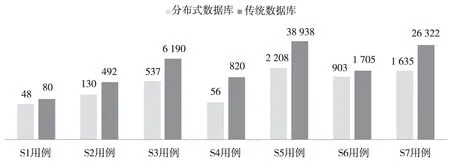
图3 测试用例检索时间对比(单位:ms)Fig.3 The comparison of retrieval time about test case ( unit: ms )
为了验证分布式数据库检索结果离散情况,对检索结果数据分布情况进行了离散分析。选取50个模拟用户并发S1~S4用例的检索数据,检索分布情况见图4。
通过与传统数据的离散系统比较,可看出分布式数据库离散系数不高,检索结果相对集中,对比情况见表6,其中平均值单位ms。从分布图可以看出,大部分样本都集中在均值附近,具有较好的稳定性。
4.3.4 可扩展性 分布开展6、9、12个数据库节点,在数据量基本相同的环境中进行高并发的检索性能测试,得到节点扩展对应用的影响。测试结果表明,增加节点,现有业务无需调整也不会中断,可连续提供服务。节点增加后,原有集群中的数据会自动向新增节点均衡,在数据均衡过程中,业务检索性能略有下降,随着数据均衡的结束,整体检索性能得到很大的提升。
测试1.65TB自动站数据从9节点增加到12节点后,整个数据均衡时间共耗费7个多小时,在节点增加以及数据均衡过程期间,业务连续正常运行。均衡期间,由于需要进行数据迁移,对数据库节点资源有一定的消耗,故而检索效率有一定的下降。选取200并发的性能测试数据,说明数据均衡对性能的影响见图5。
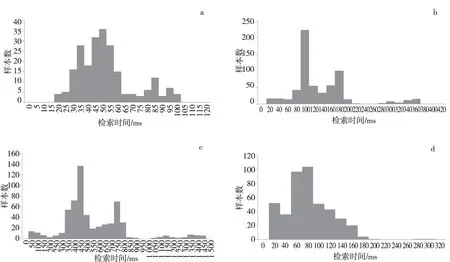
图4 用例检索结果分布图(a:S1;b:S2,c:S3;d:S4)Fig.4 Retrieval results distribution of test case(a:S1;b:S2,c:S3;d:S4)

用例分布式数据库样本数平均值标准差离散系数传统数据库样本数平均值标准差离散系数S1225486118630387383497801093S26071243767230541845372337305069S36075306426594050183677004458897068S4440712640390572098204439024047

图5 数据均衡对检索性能的影响(单位:ms)Fig.5 The influence of data migration on the retrieval performance (unit: ms)
在1.65TB数据量的环境中,随着数据库节点数的增加,测试用例检索的性能逐步提升。选取各个节点300个模拟用户并发背景时,S1~S6用例检索结果以及随节点数的变化趋势(图略),节点扩展检索性能提升率见表7,其中提升率等于6节点检索时间除以12节点检索时间。

表7 节点增加1倍(6-12)检索性能提升率
4.4 测试结论
测试结果表明分布式数据库在数据插入与检索方面都具有较好的性能,由于share-nothing以及多副本技术使得其具有较好的可靠性,其灵活性和扩展性使得分布式具有强大的生命力。测试结论如下:
①相同资料的单位时间入库性能,分布式数据库系统是传统数据库的2.5倍。相同并发背景时,分布式数据库系统各个用例的平均检索性能优于传统数据库9.5倍。数据检索结果相对集中,波动性低,具有较好的稳定性。
②分布式数据库系统不受单点故障的影响,可用廉价的服务器搭建具有高性能的数据存储管理系统。
③分布式数据库系统具有很好的灵活性和扩展性,可方便、快速地进行节点水平扩展以提高业务检索性能,对未来业务具有较好的适应性。性能与节点数呈现准线性关系,可有效预测未来业务硬件投入成本。
④硬件价格低廉,可大大节约成本,且具有较好的性能。本次测试中数据库存储硬件总价为25万,而传统数据库硬件价格高达200万。
5 分布式存储在气象业务中的应用
根据测试结论,选定国产分布式关系型数据库—虚谷数据库作为数据存储管理软件,搭架具有16台服务器,最大数据容量320TB规模的国家级气象站点数据分布式存储集群系统。遵循CIMISS站点数据存储标准[5],接入地面、高空、海洋、农气、辐射、大气成分等7大类99种气象资料实时数据,详见表8,导入自动站以及中国高空历史资料,实现部分气象资料建站以来数据的在线存储。截至2016年1月1日,集群共存储站点资料32TB,每日数据以10GB增长。

表8 存储资料分类
分布式存储系统通过与MUSIC系统对接,提供数据服务。MUSIC(气象数据统一访问接口)系统是国家气象信息中心联合省级气象信息中心自主研发的系统,支持多语言(CC++、C#、JAVA、PHP、FORTRAN等)、多服务方式(REST、SDK客户端、脚本)、多操作系统(WINDOWS、Linux、AIX),极大满足了气象业务系统与科研人员使用CIMISS数据资源的需求。
虚谷分布式气象数据存储系统自从2014年12月上线开始试运行,未出现一次系统异常,运行稳定、高效。目前已为多个业务系统提供数据服务支撑,比如天气预报业务系统(MICAPS)、气候监测预测业务平台(CIPAS2.0)、气象业务综合信息服务门户(气象业务内网)、中国气象局对外气象数据服务门户(中国气象数据网)等,服务方式见图6。数据服务水平较传统数据库具有较高的提升,响应时间在1 s内,性能完全满足业务需求。
6 结语
分布式数据库在入库性能与检索性能方面都高于传统数据库,并且可利用性价比高的PC服务器,搭架具有高可靠性、灵活性和扩展性好的分布式集群系统,提高服务能力,节约建设成本。其使用方式与传统数据库的使用基本相同,对于数据的接入与服务非常便捷,利于现有系统对接。国家级气象站点分布式存储试验系统的建立,实现了地面数据全部在线服务功能,提高了数据服务能力,提升了业务系统对数据高效获取的需求。
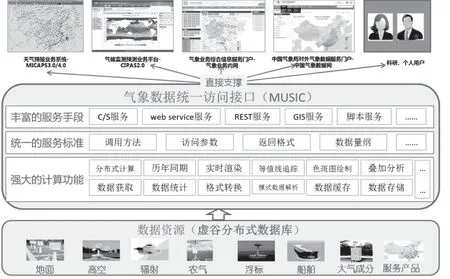
图6 分布式数据库服务方式Fig.6 Framework of distributed database service
[1] 沈文海.气象信息化进程中云计算的意义[J].中国信息化,2015(3):80-88.
[2] 秦大河,孙鸿烈,孙枢,等.中国气象事业发展战略研究[M].北京:气象出版社,2004.
[3] 沈文海.对气象信息化的理解和再认识[J].气象科技进展,2013(5).
[4] 徐俊刚,邵佩英.分布式数据库系统及其应用[M].北京:科学出版社,2012.
[5] 熊安元,赵芳,王颖,等.全国综合气象信息共享系统的设与实现[J].应用气象学报,2015,26(4):500-512.
Testing and application of distributed storage on massive data observed from meteorological station
XU Yongjun,HE Wenchun,LIU Zhen,WANG Qi,NI Xuelei
(National Meteorological Information Center, Beijing 100081, China)
The station observation data is the main component of the meteorological observation data, which has high access and high timeliness needs. In order to manage and serve meteorological data better, the National Meteorological Information Center began to focus on new storage technology in the field of Meteorology from 2013. In order to be compatible with the current storage and service mode, the distributed relational database is selected as a technical scheme, and a series of simulation weather business scenarios testing were carried out. The results show that the distributed database has better performance in terms of data loader and retrieval, and has good reliability, flexibility and scalability. According to the results, the distributed storage system was built, and the historical data of the CIMISS were introduced, and the real-time process flow of the station data was accessed. This system have completed the goal of the stations information online, at the same time, it also meets the requirement of the meteorological data service for the high efficiency.
data of meteorological stations; distributed storage; automatic meteorological station; performance testing
1003-6598(2016)05-0061-08
2016-02-26
徐拥军(1986—),男(土家族),硕士,工程师,主要从事数据管理与应用支撑工作,E-Mail:xuyj@cma.gov.cn。
中国气象局预报预测核心业务发展专项面上项目“分布式存储在统一气象数据环境中应用和推广”(CMAHX20160705)。
TP311.52
B
