基于关键词精化和句法树的商品图像句子标注
2016-11-25张红斌姬东鸿尹3任亚峰牛正雨
张红斌姬东鸿尹 兰,3任亚峰牛正雨
1(武汉大学计算机学院 武汉 430072)2(华东交通大学软件学院 南昌 330013)3(贵州师范大学大数据与计算机科学学院 贵阳 550001)4(百度在线网络技术(北京)有限公司 北京 100085)(zhanghongbin@whu.edu.cn)
基于关键词精化和句法树的商品图像句子标注
张红斌1,2姬东鸿1尹 兰1,3任亚峰1牛正雨4
1(武汉大学计算机学院 武汉 430072)2(华东交通大学软件学院 南昌 330013)3(贵州师范大学大数据与计算机科学学院 贵阳 550001)4(百度在线网络技术(北京)有限公司 北京 100085)(zhanghongbin@whu.edu.cn)
商品图像句子标注是图像标注中一项既有趣又富有挑战的研究任务.噪声单词干扰和句法结构错误是该项研究的制约因素,针对噪声单词干扰,提出关键词精化思想:用绝对排序特征强化关键词权重,完成第1次关键词精化;计算单词的语义相关度评分,进一步优选能准确刻画图像内容的单词,完成第2次关键词精化.设计词序列"拼积木"算法,把关键词拼装成N元词序列.针对句法结构错误,提出句法树思想:基于N元词序列和句法子树递归地构建一棵完整的句法树,遍历该树叶子结点输出句子,标注商品图像.实验结果表明:关键词精化和句法树均有助于改善标注性能,句中的语义信息兼容性和句法模式兼容性得以保持,句子内容更连贯、流畅.
图像标注;商品图像;句子标注;关键词精化;句法树;词序列“拼积木”;N元词序列;自然语言生成
Web网站包含大量文本、图像和视频等媒体数据,它们虽属不同模态、彼此异构,但在信息传递过程中却能相辅相成、互为补充,从不同的角度向人们阐述准确、丰富的语义信息.例如电子商务网站(www.like.com)上的在线商品既包含图像展示(如图1所示),又包含对应的文本描述(如表1所示).图像能直观地表达商品的颜色、材质、形状等视觉特性,图1中商品的颜色包括紫色、红色、黄色、褐色等,商品的材质包括皮质、PU、绸缎、嵌珠等,商品的形状包括矩形、梯形、圆形等.基于这些视觉特性,人们获取了关于在线商品更多感性的认知.
表1是图1商品的对应文本描述(标题).相比图像,文本描述更具体、详实,它既描绘商品的颜色、材质、形状等视觉特性,又刻画商品的类别、品名、用途等非视觉特性.基于文本描述,人们获取了关于在线商品更多理性的认知.可见,图像和文本相辅相成、互为补充,使人们能更全面、客观地了解在线商品,从而做出合理的购买决策.要图文并茂地展示在线商品,准确、完整的图像标注工作必不可少,且应采用蕴含组合语义信息的句子来标注商品图像.相比单词,句子能更准确且无歧义地刻画商品图像内容.此外,在实际应用中,大量数据都是未标注或弱标注的[1],若选择人工标注代价极大.因此,有必要设计自动标注模型,准确、高效地实现商品图像句子标注,以在异构的图像和文本之间建立有效的跨媒体关联,进而改善图像识别、图像检索的准确率,并向人们提供全新的跨媒体检索服务,全面提升电子商务网站的人机交互能力.

Fig. 1 Presentation of a group of online product images.图1 一组在线商品图像展示

NameTextDescriptionsProduct1Withenougheye-catchingdetailstogetyounoticed.ThisglamoroussatinclutchbyFelixReyistheperfectbagforeveningsoutonthetown!Product2Earthfriendlyhempandbamboobag.Product3Havealookatthiscasualsmallclutchbag.ItismadewiththefinestqualityleatherasyouwouldcometoexpectfromallMulhollandproducts.Availablecolors:skyblueendurance,redendurance,mustardendurance.Product4Fullybeadvintagebag.Product5Vanessasequinsbeadedeveningbagpink-eveningbags.
Notes: The underlined bold texts mean the visual characteristics of the product, other bold texts mean the non-visual characteristics of the product.
1 相关工作
图像句子标注是融合机器视觉(computer vision, CV)和自然语言生成(natural language generation, NLG)的交叉研究.相关研究成果如基于语义的图像检索、盲人视觉感知辅助系统、无人驾驶汽车等将为人们的工作和生活带来便利,并创造巨大的经济和社会效益.该研究源于Yao等人[2]的工作,他基于本体把图像分割结果映射为单词,结合单词和3-gram语言模型生成句子标注图像.该方法需借助人机交互完成图像分割,且本体定义的完备性也会影响标注性能.目前,图像句子标注主要有3种方法:检索法[3-5]、生成法[6-9]和摘取法[10-16].Farhadi等人[3]、Hodosh等人[4]、Li等人[5]基于图像和文本之间的语义相关性为图像检索最匹配的句子.然而,刻画图像内容的语义信息通常跨越多个句子,故检索结果无法全面地描绘图像内容.Yang等人[6]、Kulkarni等人[7]、Li等人[8]基于目标识别系统识别图像中的目标和场景,并推理目标之间的交互关系,采用隐马尔可夫模型(hidden Markov model, HMM)[6]或条件随机场(conditional random field, CRF)[7]或模板[8]生成句子. Kiros等人[9]为商品图像生成标注句子.显然,目标识别系统准确率有限,会影响标注性能.Feng等人[10]、Gupta等人[11]、Ushiku等人[12]摘取刻画图像内容的关键词或短语,采用语言模型[11]或Beam Search算法[10,12]生成句子,然而噪声单词会干扰句子生成.近年,电子商务快速发展,商品图像句子标注吸引了更多研究者的关注.Berg等人[13]基于多示例学习(multiple instance learning, MIL)模型摘取描述商品图像关键视觉特性的文本片段.Kiapour等人[14]用文本片段标注服装蕴含的时尚元素.文本片段[13-14]无法全面、准确地刻画图像内容.Mason[15],Zhang等人[16]分别基于Gist[17]和MKF特征(Gist[17],SIFT-EMK[18]等特征的后融合)检索视觉相似的训练图像,摘取图像标题中的关键文本标注商品.但仅用Gist,MKF等特征刻画商品图像是不充分的.Kiros等人[9]基于卷积神经网完成图像特征学习,设计基于模态偏好的对数函数双线性语言(modality-biased log-bilinear language, MLBL)模型分析图像与文本之间的跨模态相关性,根据该相关性生成句子.卷积神经网较复杂,MLBL模型调制参数时易陷入过拟合.此外,现有工作未深入考虑句子的句法结构,句中句法错误较多,影响了句子的连贯性.综上分析,本文聚焦商品图像句子标注的2个核心问题:1)关键词摘取.设计关键词精化(tag refinement, TR)方案,尽量降低噪声单词对标注的不利影响.2)句子生成.采用句法树(syntactic tree, ST)生成句子,以保持句中的语义信息兼容性和句法模式兼容性,增强句子的连贯性.
2 标注模型
标注模型包括4个部分:
1) 抽取商品图像梯度、形状、颜色核描述子(kernel descriptors, KDES)[19]特征,在多核学习(multiple kernel learning, MKL)模型[20]内融合它们,生成判别能力更强、解释能力更好的新特征,基于新特征完成图像分类,获取商品类别标签;
2) 提取单词的绝对排序(absolute rank, AR)[21]特征,强化关键词权重.基于AR权重设计关键词摘取模型,初选关键词,完成第1次关键词精化;
3) 设计融合关键词精化的词序列“拼积木”(word sequence blocks building, WSBB)算法,根据单词的语义相关度评分进一步优选关键词,完成第2次关键词精化,把关键词拼装成N元词序列;
4) 基于N元词序列和句法子树递归地构建一棵完整的句法树,遍历该树叶子结点生成句子,标注商品图像.
2.1 图像特征学习
图像特征学习思路:
1) 优选理论基础完备、运行效率良好的特征学习模型;
2) 新特征应具备较强的判别能力;
3) 新特征能较全面地解释商品图像内容.
因此,选取基于匹配核理论的KDES模型[19],从梯度、形状、颜色3个角度抽取图像KDES特征,并采用高效匹配核(efficient match kernels, EMK)模型[18]把各KDES特征都映射到低维空间得到匹配核特征,更紧凑、高效地刻画商品图像内容.在MKL模型[20]内融合匹配核特征,生成判别能力更强、解释能力更好的新特征MK-KDES.


(1)


(2)


(3)
基于像素的局部二值模式(local binary pattern, LBP)值构造形状匹配核,生成Shape-KDES.基于像素颜色值构造颜色匹配核,生成Color-KDES.Shape-KDES和Color-KDES也都从多个角度度量图像块之间的相似度.最后,在MKL模型[20]内融合核特征:Grad-KDES,Shape-KDES,Color-KDES,生成新特征MK-KDES.基于新特征完成商品图像分类,获取商品类别标签.
2.2 关键词摘取
基于新特征MK-KDES检索视觉相似的训练图像,在训练图像所构成的标题集合W′中摘取K个关键词{wrd1,wrd2,…,wrdK},为生成N元词序列奠定重要基础.关键词摘取的依据是它与商品图像内容的语义相关度,设计关键词摘取模型如下:
(4)
其中,P(Ii|Iq)基于函数SIM(Ii|Iq)计算训练图像Ii与测试图像Iq的视觉相似度,其定义如式(5)所示,它表明应从视觉相似度最高的训练图像的标题中摘取关键词.
(5)
P(wrdj|Ii)基于函数WORD_FEAT提取单词特征,并计算单词wrdj与训练图像Ii的语义相关度,其定义如式(6)所示,它表明应摘取训练图像标题中的代表性单词.
(6)
关键词精化指抑制噪声单词干扰,摘取能较准确刻画商品图像内容的单词.商品图像句子标注需综合考虑句子的语义相关性和句法结构准确性,故关键词精化应兼顾这2类指标,以改善标注性能,而函数WORD_FEAT是实现该目标的关键:图像标题中包含若干商品特性描述,如形状、纹理、颜色、品名、结构等,函数WORD_FEAT将优选单词特征以强化代表性单词权重,从而抑制噪声单词干扰,准确摘取出关键词.常用单词特征包括TF,TF-IDF,TF-IDF(SQRT),LDA(latent Dirichlet allocation),LSA(latent semantic analysis)等.TF,TF-IDF,TF-IDF(SQRT)等基于统计特性计算单词权重,LDA,LSA等基于中间语义空间(或主题层)中信息的分布计算单词权重.这些特征主要刻画单词蕴含的语义信息,而忽略对单词之间词序先后关系的挖掘.相反,Tag-rank模型[21]拟合单词在图像标题中出现位置的统计分布,计算出绝对排序AR特征,AR特征既较好地保持单词与图像内容的语义相关性,又隐含单词之间的词序先后关系约束(保证句法结构准确).故AR特征能强化关键词权重,提高代表性单词摘取的准确率.AR特征定义如下:
(7)
若单词wrdj在标题sent中出现多次,posj计算单词所有出现位置的平均值,此时,单词wrdj的ARj值是其出现位置posj的倒数;相反,若wrdj未出现在标题sent中,则ARj=0.式(7)表明:如果单词在商品图像标题中出现得越早,则应给它分配1个更大的权重.
2.3 基于WSBB算法构造N元词序列
2.3.1 构建单词-上下文矩阵
单词-上下文(term-context, TC)矩阵包括单词-上下文共现矩阵和单词-上下文位置矩阵.单词-上下文共现矩阵度量单词之间语义相关性,确保N元词序列的语义信息兼容性;单词-上下文位置矩阵度量单词之间词序先后关系,确保N元词序列的句法模式兼容性.基于正逐点互信息(positive pointwise mutual information, PPMI)度量词典D中单词wrdu和上下文C中单词wrdv之间的语义相关性,u=1,2,…,|D|,v=1,2,…,|C|.PPMI定义如下:
PMIuv=PMI(wrdu,wrdv)=
(8)
(9)
其中,Puv计算单词wrdu和wrdv之间的共现概率,它基于单词之间的共现频率;Pu·计算词典单词wrdu的出现概率,它通过累加wrdu与上下文中各单词的共现频率获取;P·v计算上下文单词wrdv的出现概率,它通过累加wrdv与词典中各单词的共现频率获取.设计正距离信息(positive distance information,PDI)度量单词wrdu和wrdv之间的词序先后关系.N元词序列是自左向右顺序构造,故PDIuv表示单词wrdv右邻接于单词wrdu.fuv计算单词之间的共现频率,函数DIST(wrdu,wrdv)num度量单词之间第num次共现时的物理距离.PDI定义如下:
DIuv=DI(wrdu,wrdv)=
(10)
(11)
2.3.2 设计WSBB算法
在商品图像标题中,基于语义信息兼容性和句法模式兼容性,N个关键词被有序地拼装成N元词序列,以描述商品特性.借鉴“拼积木”游戏原理,设计WSBB算法:根据语义重叠(语义相关或内容重叠)将关键词(积木)递归地拼装成N元词序列(建筑物).WSBB伪代码如算法1所示,其中Relevance_scores是式(4)计算出的单词的语义相关度评分;TC_PPMI_Matrix和TC_PDI_Matrix分别是基于PPMI的单词-上下文共现矩阵和基于PDI的单词-上下文位置矩阵,如TC_PPMI_Matrix(wrdu,wrdv)表示2个单词之间的PPMI值;Unigram_seqs,Bigram_seqs,Trigram_seqs分别是单词集合(经过第1次关键词精化)、2元词序列集合和3元词序列集合;Bigram_ppmi和Trigram_ppmi分别记录2元词序列、3元词序列的累积PPMI值.
算法1. 融合关键词精化的WSBB算法.
输入:TC_PPMI_Matrix,TC_PDI_Matrix,Relevance_scores,α,β,γ,M,Unigram_seqs,Bigram_seqs=NULL,Trigram_seqs=NULL,Bigram_ppmi=NULL,Trigram_ppmi=NULL;
输出:TopM的N元词序列.
Loop Until生成全部2元词序列 /*以迭代方式生成全部2元词序列*/
① 从Unigram_seqs中获取关键词wrdu和wrdv;
② IfRelevance_scores{wrdu}≤γorRelevance_scores{wrdv}≤γ/*执行第2次关键词精化*/
③ Continue; /*过滤相应噪声单词*/
④ End If
⑤ IfTC_PDI_Matrix(wrdu,wrdv)≤βandTC_PPMI_Matrix(wrdu,wrdv)≥α
/*既满足语义信息兼容性,又满足句法模式兼容性*/
⑥Bigram_seqs{end+1}←STRCAT(wrdu,wrdv); /*生成新的2元词序列*/
⑦Bigram_ppmi{end+1}←TC_PPMI_Matrix(wrdu,wrdv); /*计算2元词序列的累积PPMI值*/
⑧ End If
End Loop
Loop Until生成全部3元词序列 /*以迭代方式生成全部3元词序列*/
⑨ 从Bigram_seqs中选取2个2元词序列seqm,seqn; /*选取生成3元词序列的2个候选2元词序列*/
⑩ IfOVERLAP(seqm,seqn) /*根据语义重叠拼装2个2元词序列*/



(STRCAT(wrd1,wrd2),wrd3);
/*生成新的3元词序列*/

/*计算3元词序列的累积PPMI值*/


End Loop

/*对N元词序列降序排列*/

在算法1中,首先设置语义相关度评分阈值γ,WSBB算法对初选的单词做第2次精化,选取与商品图像内容语义相关的关键词.继而,调节PPMI阈值α和PDI阈值β,把经过2次精化的关键词拼装成有实际含义的2元词序列.其次,函数OVERLAP分析2个2元词序列之间的语义重叠,获取构造3元词序列的候选单词wrd1,wrd2,wrd3.为保证3元词序列的句法模式兼容性,设置单词之间必须满足PDI约束:TC_PDI_Matrix(wrd1,wrd3)≤min{2,2β},生成有实际含义的3元词序列.最后,根据累积PPMI值降序排列N元词序列,输出TopM的N元词序列.
2.4 基于句法树生成句子
WSBB算法输出描述商品图像关键内容的N元词序列,它们是句子的核心组成部分.标注模型继续把N元词序列、商品类别标签等组装成完整句子,更连贯、流畅地刻画商品图像内容.受文献[22]启发,设计句法子树,以递归方式构造出蕴涵丰富语义信息且满足正确句法结构的完整句法树,遍历该树叶子结点生成句子,标注商品图像.设计的7种子树如图2所示:

Fig. 2 Seven kinds of syntactic subtrees designed in the paper.图2 设计的7种句法子树
子树生成规则如下所示:
1) 子树1(Subtree-1)生成3元词序列的规则 (生成2元词序列的规则类似)
NP→(JJ,adj|NN,noun)*:
∃wrd1,wrd2,wrd3∈{JJ|NN}((constrain1)∧(constrain2)),
constrain1=TC_PPMI_Matrix(wrd1,wrd2)≥
α∧TC_PDI_Matrix(wrd1,wrd2)≤β,
constrain2=TC_PPMI_Matrix(wrd2,wrd3)≥
α∧TC_PDI_Matrix(wrd1,wrd3)≤min{2,2β}.
2) 子树2(Subtree-2)生成3元词序列的规则 (生成2元词序列的规则类似)
NP→(NNP,noun)*:
∃noun1∈NNP∧noun2∈NNP∧noun3∈NNP((constrain1)∧
(constrain2)),
constrain1=TC_PPMI_Matrix(noun1,noun2)≥
α∧TC_PDI_Matrix(noun1,noun2)≤β,
constrain2=TC_PPMI_Matrix(noun2,noun3)≥
α∧TC_PDI_Matrix(noun1,noun3)≤min{2,2β}.
3) 子树3(Subtree-3)的生成规则
S→NP VP:
∃verb∈VB(G|N|Z)∧NP{Anchor noun}=SUBJ∧noun∈NN(constrain1),
constrain1=TC_PPMI_Matrix(noun,verb)≥
α∧TC_PDI_Matrix(noun,verb)≤β.
4) 子树4(Subtree-4)的生成规则
PP→IN NP:
∃in∈IN∧NP{NN noun}=OBJ∧noun∈NN(constrain1),
constrain1=TC_PPMI_Matrix(noun,in)≥
α∧TC_PDI_Matrix(noun,in)≤min{3,3β}.
5) 子树5(Subtree-5)的生成规则
VP→VB(G|N|Z) NP:
∃verb∈VB(G|N|Z)∧NP{NN noun}=OBJ∧noun∈NN(constrain1),
constrain1=TC_PPMI_Matrix(noun,verb)≥
α∧TC_PDI_Matrix(noun,verb)≤min{3,3β}.
6) 子树6(Subtree-6)的生成规则
VP→VB(G|N|Z) PP:
∃verb∈VB(G|N|Z)∧in∈IN(constrain1),
constrain1=TC_PPMI_Matrix(in,verb)≥
α∧TC_PDI_Matrix(in,verb)≤β.
7) 子树7(Subtree-7)的生成规则
NP→NP CC NP: ∃|NP|≥2(constrain1),
constrain1=OVERLAP(np1,np2)≤1∧np1∈NP∧np2∈NP.
基于子树1(或子树2)生成N元词序列,对应生成规则在算法1中已被使用.子树1(或子树2)包含2个constrain,以约束关键词拼装,其中在constrain2中,TC_PDI_Matrix(wrd1,wrd3)≤min{2,2β}(或TC_PDI_Matrix(noun1,noun3)≤min{2,2β}),这是1个强词序先后关系约束,它从句法结构角度确保词序列生成质量.当构造出N元词序列之后,作为Anchor的商品类别标签被扩展进这2棵子树,以准确刻画商品类别.因为,商品类别也是人们最关注的商品特性之一.子树3根据NP和VP构建一棵完整的句法树,NP是子树1(或子树2、子树7)的递归实现,VP是子树5(或子树6)的递归实现.为确保短语之间“平滑”拼装,子树3约束NP的Anchor在依存关系中是SUBJ(主语),这是基于对语料库中句子依存关系统计信息的分析.子树4构建PP短语,NP是子树1(或子树2、子树7)的递归实现.为保证介词与词序列之间“平滑”拼装,子树4约束NP中的名词在依存关系中是OBJ(宾语).子树5(或子树6)构建VP短语,依存关系约束同样被定义.子树7采用CC(连词)将2个NP短语(子树1或子树2)组合起来,从多个角度描述商品图像内容.最后,基于N元词序列和对应句法子树递归地构建一棵完整的句法树,自左向右遍历树中叶子结点,生成标注商品图像的句子,同时增加后处理.如在句首添加定冠词The、去除句中Null文本等,使句子在表达形式上更贴近人工标注.
3 实验结果及讨论
3.1 数据集
Bag是电子商务网站的代表性商品,选取Berg的Bag数据集[13]评价各模型标注性能.它包括Clutch,Hobo,Evening,Shoulder,Totes五类商品,样本数分别为1643,1630,1681,1596,1577,每个样本包含1张商品图像和1段文本描述(标题).随机选择70%样本构成训练集,剩余30%样本为测试集.图像特征抽取Color-KDES[20],Grad-KDES[20],Shape-KDES[20],在MKL模型[21]内融合生成4种MK-KDES新特征:MK-KDES-1(Grad-KDES与Shape-KDES融合)、MK-KDES-2(Grad-KDES与Color-KDES融合)、MK-KDES-3(Color-KDES与Shape-KDES融合)、MK-KDES-4(全部KDES特征融合).
3.2 基线说明
实验中对比了3类基线,基线定义如下:
1) 现有工作,包括Beam Search[10,12](基于新特征MK-KDES-1和3-gram语言模型),Gist-Based[15],MLBL模型[19].
2) 设计新的标注模型WSBB′,令式(6)中WORD_FEAT=TF_IDF,在N元词序列生成中基于TF评价单词之间语义相关性,且不考虑单词之间PDI约束.故它有别于算法1,采用WSBB′表示该类模型,以区别于WSBB.运用句子模板(TEMP)生成句子,该类模型包括:基于2元词序列的WSBB′-1、基于3元词序列的WSBB′-2和基于4元词序列的WSBB′-3.
3) 设计新的标注模型TC+X,根据上下文共现构建单词向量空间并计算单词间语义相关性,令式(6)中WORD_FEAT=TF_IDF,在N元词序列生成中基于相似度度量方法X评价单词之间语义相关性,考虑单词之间PDI约束.运用句法树(SGT)生成句子.该类模型包括:TC+COS,TC+NORM1,TC+NORM2,TC+DICE,TC+JACCARD,TC+PPMI.上下文窗口大小为10.
3.3 标注句子评估
1) 为句子标注优选合适的图像特征.选取RGB-Gist[15],MKF[16],SIFT-EMK[18],KDES[19],SP-BoW[23],SAE[24],ScSPM[25],MK-KDES等图像特征,执行商品图像分类、商品图像检索,摘取关键词(但不考虑关键词精化),将语义相关度评分TopK的关键词随机地拼装成句子,评价标注性能.针对不同K值计算BLEU[26]评分均值,结果如图3所示.
图3(a)中,BLEU-1评估标注模型的内容选择(content selection, CS)能力,即句子与商品图像内容的语义相关性.图3(a)表明:MK-KDES-1特征获取了最优的BLEU-1评分,即所摘取单词能较准确地刻画商品图像内容.主要原因:MK-KDES-1特征是Grad-KDES与Shape-KDES的多核学习融合,核权重分别是0.68和0.32,这说明MK-KDES-1特征主要刻画商品图像的纹理和形状视觉特性,这些特性在商品图像中较显著(如图1所示),且图像标题中也有相关文字描述,故视觉词与文本词频繁共现,MK-KDES-1特征有助于摘取更多与商品图像内容语义相关的纹理、形状等代表性单词,相应BLEU-1评分自然更优.
图3(b)中,BLEU-2评估标注模型的表面实现(surface realization, SR)能力,即句子的句法结构准确性.图3(b)表明:MK-KDES-1特征获取了最优的BLEU-2评分,当K>6时其优势更显著.主要原因:由于聚焦相同或相似的商品特性,被摘取的代表性单词多是语义相关的.通常,这些单词在词序先后关系上也存在相关性,如单词metal与mesh、单词lisa与david、单词satin与silk等,即使随机地拼装它们,所生成的句子仍保持一定的句法模式兼容性,相应的BLEU-2评分自然更优.综上分析,选取MK-KDES-1特征完成商品图像句子标注更为合适.
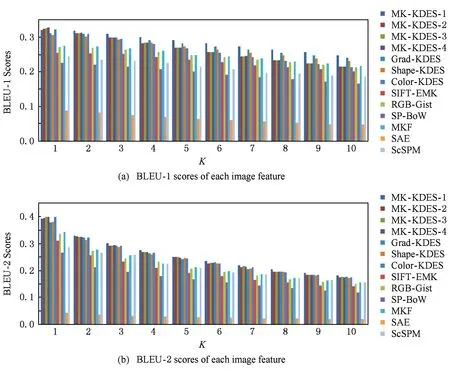
Fig. 3 Optimal selection of the image feature for caption generation.图3 为句子标注优选图像特征
2) 基于不同的N元词序列构造方法和句子生成方案生成句子,但不考虑关键词精化.即实现3.2节中的第2,3类基线,计算标注模型的BLEU评分,结果如表2所示:

Table 2 BLEU Scores Comparison between the Second Kind Baseline and the Third Kind Baseline
Notes:“√” means that the WSBB algorithm considers the PDI metric. The best scores are the values with underline.
表2中,基于3元词序列(或4元词序列)的WSBB′模型的BLEU-2和BLEU-3评分更优.相比WSBB′模型,TC+X模型的整体标注性能更优.与WSBB′-3模型比较,TC+PPMI模型BLEU-1评分提高(0.3689-0.3094)0.3094≈19.2%,BLEU-2评分提高(0.0797-0.0523)0.0523≈52.4%,BLEU-3评分提高(0.0143-0.0088)0.0088≈62.5%.
主要原因是:
① TC+X模型深入挖掘单词与上下文之间的共现关系,并基于相似度度量方法X准确评价单词之间语义相关性,这有助于保持N元词序列的语义信息兼容性;
② TC+X模型考虑单词之间PDI约束,故N元词序列遵循更严格的词序先后关系,这有助于保持N元词序列的句法模式兼容性;
③ TC+X模型基于句法树ST生成句子,这有助于保持完整句子的句法模式兼容性.而BLEU-3评分的提升幅度最大则进一步说明PDI约束和句法树ST在句子生成中发挥了关键作用(图4较好地验证了该分析).
3) 考虑关键词精化,基于AR特征强化关键词权重,并确定WSBB算法的3个重要参数α,β,γ,运用句法树ST生成句子.实验方案:令式(6)中WORD_FEAT=AR,WSBB算法中γ=0(γ=0表示先不执行第2次关键词精化),X=PPMI,基于设定的评价标准以格搜索(grid search, GS)方式获取对应的参数α和β,α∈[0,max_ppmi],β∈[0,max_pdi].根据参数α和β,继续搜索对应的参数γ,γ∈[0,max_ar].对已获得的参数α,β,γ,执行范围更小、精度更高的微格搜索(mini-grid search, MGS),确定最终参数.其中,参数搜索中的评价标准定义如下:
Best_Score=w1ScoreBLEU-1+
(12)
s.t.w1+w2+w3=1,
w1∈[0,1],w2∈[0,1],w3∈[0,1],
其中,ScoreBLEU-1,ScoreBLEU-2,ScoreBLEU-3是参数搜索中计算出的各BLEU评分;w1,w2,w3是BLEU评分权重.式(12)是1个灵活的评价标准:通过调节评分权重以聚焦不同的最优评价指标.例如,w1=0,w2=1,w3=0表示当前的评价标准是BLEU-2 BEST,即BLEU-2评分最优,其它标准以此类推.本文关注4个不同的评价标准:BLEU-1 BEST,BLEU-2 BEST,BLEU-3 BEST,BLEU-SUM BEST(w1=w2=w3≠0).根据不同的评价标准和关键词精化次数设计2类标注模型,分别是仅执行1次关键词精化的4个标注模型:BLEU-1 BEST(1),BLEU-2 BEST(1),BLEU-3 BEST(1),BLEU-SUM BEST(1)以及执行2次关键词精化的4个标注模型:BLEU-1 BEST(2),BLEU-2 BEST(2),BLEU-3 BEST(2),BLEU-SUM BEST(2),模型名称的后缀(1),(2)均表示关键词精化次数.调制各标注模型的参数α,β,γ并计算当前BLEU评分Best_Score,实验结果如表3所示:

Table 3 Key Parameters of Each Annotation Model and BLEU Scores Comparison
Notes:“↑” means that our models have improvements compared with the TC+PPMI model; “↓” means just the opposite.
The best scores are the values with underline. The values in brackets represent the number of tag refinement.
① 评判参数α,β,γ与标注模型的关系.BLEU-1 BEST模型具有较大的α值,其目的是加强单词之间的语义相关性约束,获取更多描述相同或相似商品特性的关键词,故该类模型BLEU-1评分最优.相比α值,它们的β值更大,这表明BLEU-1 BEST模型支持松散的句法结构约束,对应BLEU-2,BLEU-3评分较差.不同于BLEU-1 BEST模型,BLEU-2 BEST模型具有相对较小的β值,其目的是强化单词(或N元词序列)之间的句法结构约束,因此,它们的BLEU-2评分显著提高,而BLEU-2评分的提高还有利于BLEU-3评分的改善.相比前2类模型,BLEU-3 BEST模型具有相对更小的β值,这表明它们基于更严格的句法结构约束来构造有实际含义的3元词序列,BLEU-3评分也自然更优.BLEU-SUM BEST模型聚焦整体标注性能最优,其各项BLEU评分相对基线均有改善,而对应的α,β值则介于BLEU-2 BEST模型和BLEU-3 BEST模型之间.此外,基于合理的α,β值,设置较大的γ值也有利于2元词序列和3元词序列的构造(如BLEU-2 BEST模型和BLEU-SUM BEST模型),并提升BLEU-2评分和BLEU-3评分.综上分析,在生成标注句子的过程中α,β,γ相互配合、共同作用,需要联合调制它们,以获取最理想的标注性能.
② 在关键词摘取中运用AR特征强化关键词权重,执行第1次关键词精化,评估该精化方法在句子生成中的作用.表3中,第1次关键词精化之后,各标注模型所聚焦的BLEU指标相比基线均有提升.例如,BLEU-1 BEST(1)模型的BLEU-1评分提升(0.3782-0.3689)0.3689≈2.5%,BLEU-2 BEST(1)模型的BLEU-2评分提升(0.0823-0.0797)0.0797≈3.3%,BLEU-3 BEST(1)模型的BLEU-3评分提升(0.0151-0.0143)0.0143≈5.6%,共计8个BLEU评分指标有提高.主要原因:描述商品品名、纹理、形状等显著特性的关键词在商品图像标题中出现的位置更早(这缘于人们的一种心理暗示,即在标题中首先刻画商品的显著特性),而AR特征较好地强化了这些关键词的权重,故它们被模型优先摘取以生成句子.综合各BLEU评分指标,BLEU-2 BEST(1)和BLEU-SUM BEST(1)这2个模型的整体标注性能较优,它们具备一定实用价值.总之,第1次关键词精化有助于改善标注性能.
③ 在第1次关键词精化的基础上,为WSBB算法设置单词的语义相关度评分阈值γ,执行第2次关键词精化,评估该精化方法在句子生成中的作用.表3中,第2次关键词精化之后,各标注模型所聚焦的BLEU指标相比基线有更大幅度提升.例如,BLEU-1 BEST(2)模型的BLEU-1评分提升(0.3793-0.3689)0.3689≈2.8%,BLEU-2 BEST(2)模型的BLEU-2评分提升(0.0834-0.0797)0.0797≈4.6%,BLEU-3 BEST(2)模型的BLEU-3评分提升(0.0155-0.0143)0.0143≈8.4%.BLEU-2 BEST(2)和BLEU-SUM BEST(2)这2个模型获取了较1次精化模型更优的BLEU-2评分和BLEU-3评分.例如BLEU-2 BEST(1)模型的BLEU-2,BLEU-3评分相比基线分别提升3.3%和1.4%;而BLEU-2 BEST(2)模型的BLEU-2,BLEU-3评分相比基线分别提升4.6%和5.6%.这表明BLEU-2 BEST(2)和BLEU-SUM BEST(2)这2个模型在句法模式兼容性上更胜一筹.主要原因:WSBB算法中的单词语义相关度评分阈值γ能进一步优选关键词,为N元词序列构造奠定重要基础.当然,微格搜索也有助于提升标注性能.如BLEU-2 BEST(2)模型在微格搜索前BLEU-2,BLEU-3评分分别为0.0831和0.0148.综合各BLEU评分指标,BLEU-2 BEST(2),BLEU-SUM BEST(2)这2个模型的整体标注性能最优,它们具备更高的实用价值.综上分析,第2次关键词精化能进一步改善标注性能.
4) 以BLEU-BEST(2)模型为“标杆”,定量评估图像标注模型中各关键部件:正逐点互信息(PPMI)、关键词精化(TR)、句法树(ST)在句子生成中的作用,结果如图4所示.图4中,深色是模型的实际标注性能,而浅色则是标注性能的衰减幅度.

Fig. 4 Impact evaluations of each key component in the presented image annotation model.图4 评估图像标注模型中各关键部件的作用
图4表明:PPMI+ST模型未执行关键词精化TR,噪声单词会干扰关键词摘取及N元词序列构造,其BLEU-2和BLEU-3评分相对“标杆”分别衰减4.6%和5.6%;在COS+TR+ST模型中,令X=COS,以替换PPMI度量单词之间的语义相关性,显然COS度量方式不够精确,影响了N元词序列的质量,其BLEU-2和BLEU-3评分相对“标杆”分别衰减5.6%和6.6%;PPMI+TR+TEMP模型用模板(TEMP)替换句法树ST,众所周知,模板的灵活性较差,无法较好地保持句中的语义信息兼容性和句法模式兼容性,其BLEU-1,BLEU-2,BLEU-3评分衰减更为严重,分别达到10.4%,33.7%,42.4%.综上分析,标注模型各关键部件在句子生成中的作用排名:ST>PPMI>TR.因此,需同时运用这三大关键部件来构造图像标注模型,以提升标注性能,增强模型的实用价值。
5) 选取Gist-Based,Beam Search(基于MK-KDES-1特征和3-gram语言模型),MLBL,WSBB′-3,TC+PPMI等主要基线与BLEU-2 BEST(2)模型做标注性能的比较,实验结果如图5所示:

Fig. 5 Performance comparison of our model and the main baselines.图5 本文模型与主要基线的比较
图5表明:首先,BLEU-2 BEST(2)模型的BLEU-1评分优于全部基线,这得益于MK-KDES-1特征提取、第1次关键词精化和基于PPMI的单词之间语义相关性度量.MK-KDES-1特征刻画商品图像的纹理和形状视觉特性,这些特性已体现于商品图像标题中,并被赋予较大的AR权重,根据AR权重,模型较准确地摘取出对应关键词.此外,PPMI能聚合更多语义相关的单词,丰富了对商品图像内容的描述,句子的BLEU-1评分自然更优.其次,BLEU-2 BEST(2)模型的BLEU-2评分优于全部基线,这得益于WSBB算法及句法树ST.在WSBB算法中,一方面,调制参数γ执行第2次关键词精化,较好地抑制噪声单词对2元词序列构造的干扰,而2元词序列是构造高元词序列的重要保障;另一方面,联合调制参数α和β,确保N元词序列的语义信息兼容性和句法模式兼容性.句法树ST则进一步强化了完整句子的句法结构约束.最后,BLEU-2 BEST(2)模型的BLEU-3评分(约0.0151)已逼近深度学习模型MLBL的BLEU-3评分(约0.0170).相比MLBL模型,BLEU-2 BEST(2)模型的主要优点:①仅抽取图像匹配核特征,无需大规模的特征学习;②仅依赖训练图像及其标题构成的语料库,不依赖外部语料库;③模型参数更少,可近似为“无参”模型,模型调制也变得更简单;④整体标注性能更突出,主要体现在BLEU-1,BLEU-2评分,如BLEU-2 BEST(2)模型的BLEU-2评分是MLBL模型的0.08340.0480≈1.74倍.
总之,基于关键词精化和句法树的商品图像句子标注模型,无论是标注性能还是模型复杂度、运行效率等均优于主要基线,所生成的句子也更连贯、流畅.
3.4 标注结果展示
分别运用TC+PPMI和BLEU-2 BEST(2)模型进行商品图像句子标注实验,得到如表4所示的部分标注结果.
表4中,TC+PPMI模型能生成正确的N元词序列metal mesh,boutique designer等,以刻画商品图像特性.但它也产生了许多错误标注,包括句法结构错误(如simpson town jessica)、语义信息不相关(如black manmade,material cotton leather)等.相比TC+PPMI模型,BLEU-2 BEST(2)模型的标注结果无论是语义相关性还是句法结构准确性都更贴近原始标注.主要原因:1)2次关键词精化较好地抑制了噪声单词干扰,为生成正确的N元词序列奠定重要基础;2)句法树强化了句中的句法结构约束,有助于生成连贯、流畅的句子.此外,BLEU-2 BEST(2)模型还获取了一些非常有趣的标注结果,如sleek chic,black leather等,这些N元词序列虽未出现在原始标注中,但却是对商品图像内容描述的有益补充.当然,标注中也存在错误.例如:mesh与beaded文本词所对应的MK-KDES-1特征视觉词之间出现歧义;松散的依存关系约束导致east west词序列的生成;视觉词与文本词的稀疏共现使某些重要的视觉特性未被有效地标识出.
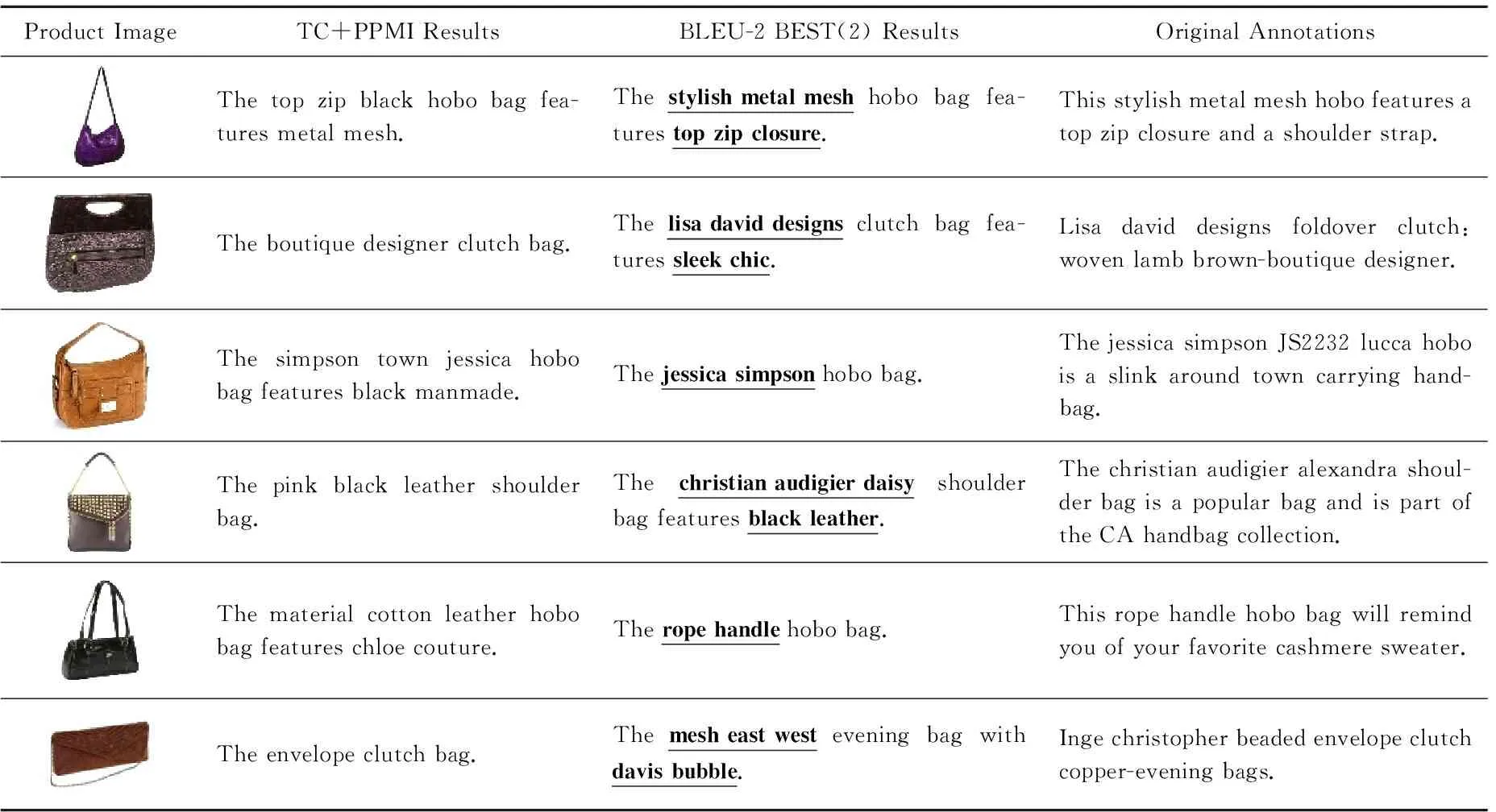
Table 4 Some Annotation Results
Notes: The underlined bold texts are generated by the WSBB algorithm.
4 结论及展望
首先,提出关键词精化思想:基于AR特征强化关键词权重,约束单词的语义相关度评分,优选与商品图像内容语义相关的关键词,为N元词序列构造奠定重要基础;其次,设计WSBB算法,把精化后的关键词拼装成N元词序列,进而构造句法树ST:基于句法子树及N元词序列,递归地构建一棵完整的句法树,遍历该树叶子结点生成句子,标注商品图像;最后,提出更灵活的句子评价标准,如式(12)所示.实验结果表明:1)BLEU-2 BEST(2)和BLEU-SUM BEST(2)这2个模型的整体标注性能最优,它们的实用价值也最大;2)关键词精化能较好地抑制噪声单词干扰,有助于摘取出正确的关键词并改善标注性能;3)句法树使句子的句法结构更准确,句中的语义信息兼容性和句法模式兼容性均得以保持.而BLEU-2和BLEU-3评分的改善促使句子的连贯性、流畅性更佳.
总之,本文实现了一个有效的图像标注模型,它较好地解决了商品图像句子标注的两大核心问题:噪声单词干扰和句法结构错误.该标注模型是自然语言处理中“经验主义”与“理性主义”的有机结合,可为相关研究提供有益的参考.
未来的工作有4个方面:
1) 基于词向量(word vector, WV)[27]分析单词之间语义相关性,进一步挖掘能准确描述商品图像内容的关键词,丰富和完善关键词精化方案;
2) 基于深度依存分析(deep dependency analysis, DDA)度量单词之间的词序先后关系,构造更多语义信息丰富且句法结构准确的N元词序列,为生成句子奠定重要基础;
3) 基于概率部分典型相关性分析(probabilistic partial canonical correlation analysis, PPCCA)[28]模型或多模态分布式语义(multimodal distributional semantics, MDS)[29]深入分析图像与文本之间的语义相关性,期望能借助图-文共现信息降低视觉词歧义对句子标注的不利影响;
4) 着手建立中文语料库,并调整少量句法子树的生成规则,以完成商品图像的中文句子标注,进一步延伸和拓展本文图像标注模型的应用领域.
[1]Tian Feng, Shen Xukun. Image annotation by semantic neighborhood learning from weakly labeled dataset [J]. Journal of Computer Research and Development, 2014, 51(8): 1821-1832 (in Chinese)
(田枫, 沈旭昆. 弱标签环境下基于语义邻域学习的图像标注[J]. 计算机研究与发展, 2014, 51(8): 1821-1832)
[2]Yao B, Yang X, Lin L, et al. I2T: Image parsing to text description [J]. Proceedings of the IEEE, 2010, 98(8): 1485-1508
[3]Farhadi A, Hejrati M, Sadeghi M. A, et al. Every picture tells a story: Generating sentences from images[C] //Proc of the 11th European Conf on Computer Vision. Berlin: Springer, 2010: 15-29
[4]Hodosh M, Young P, Hockenmaier J. Framing image description as a ranking task: Data, models and evaluation metrics [J]. Journal of Artificial Intelligence Resource, 2013, 47(1): 853-899
[5]Li Piji, Ma Jun, Gao Shuai. Learning to summarize Web image and text mutually [C] //Proc of the 2nd ACM Int Conf on Multimedia Retrieval. New York: ACM, 2012: 1-8
[6]Yang Y, Teo C L, Daume H(Ⅲ), et al. Corpus-guided sentence generation of natural images[C] //Proc of the 16th Conf on Empirical Methods on Natural Language Processing. London: Oxford University Press, 2011: 444-454
[7]Kulkarni G, Premraj V, Dhar S, et al. Baby talk: Understanding and generating simple image descriptions [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(12): 2891-2903
[8]Li Siming, Kulkarni G, Berg T, et al. Composing simple image descriptions using Web-scale n-grams [C] // Proc of the 15th Conf on Computational Natural Language Learning. Stroudsburg, PA: ACL, 2011: 220-228
[9]Kiros R, Salakhutdinov R, Zemel R. Multimodal neural language models[C] //Proc of the 31st Int Conf on Machine Learning, JMLR Workshop. New York: ACM, 2014: 595-603
[10]Feng Yansong, Lapata M. Automatic caption generation for news images [J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2013, 35(4): 797-812
[11]Gupta A, Verma Y, Jawahar C V. Choosing linguistics over vision to describe images[C] //Proc of the 26th American Association for Artificial Intelligence. Menlo Park, CA: AAAI, 2012: 606-611
[12]Ushiku Y, Harada T, Kuniyoshi Y. Automatic sentence generation from images[C] //Proc of the 19th ACM Int Conf on Multimedia. New York: ACM, 2011: 1533-1536
[13]Berg T L, Berg A C, Shih J. Automatic attribute discovery and characterization from noisy Web data[C] //Proc of the 11th European Conf on Computer Vision. Berlin: Springer, 2010: 663-676
[14]Kiapour H, Yamaguchi K, Berg A C, et al. Hipster wars: Discovering elements of fashion styles[C] //Proc of the 13th European Conf on Computer Vision. Berlin: Springer, 2014: 472-488
[15]Mason R. Domain-independent captioning of domain-specific images[C] //Proc of the 10th North American Association for Computational Linguistics-Student Research Workshop. Stroudsburg, PA: ACL, 2013: 69-76
[16]Zhang Hongbin, Ji Donghong, Ren Yafeng, et al. Product image sentence annotation based on multiple kernel learning [J]. Journal of Frontiers of Computer Science and Technology, 2015, 9(11): 1351-1361 (in Chinese)
(张红斌, 姬东鸿, 任亚峰, 等. 基于多核学习的商品图像句子标注[J]. 计算机科学与探索, 2015, 9(11): 1351-1361)
[17]Torralba A, Murphy K P, Freeman W T, et al. Context-based vision system for place and object recognition[C] //Proc of the 9th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2003: 273-280
[18]Bo L, Ren X, Fox D. Efficient match kernels between sets of features for visual recognition [C] //Proc of the 23rd Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2009: 135-143
[19]Bo L, Ren X, Fox D. Kernel descriptors for visual recognition [C] //Proc of the 24th Advances in Neural Information Processing Systems. Cambridge, MA: MIT Press, 2010: 1734-1742
[20]Vedaldi A, Gulshan V, Varma M, et al. Multiple kernels for object detection[C] //Proc of the 12th IEEE Int Conf on Computer Vision. Piscataway, NJ: IEEE, 2009
[21]Hwang S, Grauman K. Learning the relative importance of objects from tagged images for retrieval and cross-modal search [J]. International Journal of Computer Vision, 2012, 100(2): 134-153
[22]Mitchell M, Dodge J, Goyal A, et al. Midge: Generating image descriptions from computer vision detections [C] //Proc of the 13th European Association for Computational Linguistics. Stroudsburg, PA: ACL, 2012: 747-756
[23]Lazebnik S, Schmid C, Ponce J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories [C] //Proc of the 19th IEEE Conf on Computer Vision and Pattern Recognition, vol 2. Piscataway, NJ: IEEE, 2006: 2169-2178
[24]Sivaram G, Hermansky H. Sparse multilayer perceptron for phoneme recognition [J]. IEEE Trans on Audio, Speech, & Language Process, 2012, 20(1): 23-29
[25]Yang J, Yu K, Gong Y, et al. Linear spatial pyramid matching using sparse coding for image classification[C] //Proc of the 22nd IEEE Conf on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2009: 1794-1801
[26]Papineni K, Roukos S, Ward T, et al. BLEU: A method for automatic evaluation of machine translation[C] //Proc of the 40th Annual Meeting on Association for Computational Linguistics. Stroudsburg, PA: ACL, 2002: 311-318
[27]Maas A, Daly R, TPham P, et al. Learning word vectors for sentiment analysis[C] //Proc of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. Stroudsburg, PA: ACL, 2011: 142-150
[28]Mukuta Y, Harada T. Probabilistic partial canonical correlation analysis[C] //Proc of the 15th Int Conf on Machine Learning. New York: ACM, 2014: 1449-1457
[29]Bruni E, Khanh T N, Baroni M. Multimodal distributional semantics [J]. Journal of Artificial Intelligence Resource, 2014, 49(1): 1-47

Zhang Hongbin, born in 1979. PhD candidate. Associate professor. Member of China Computer Federation. His main research interests include image annotation, natural language processing and machine learning.

Ji Donghong, born in 1967. PhD supervisor and professor. His main research interests include natural language processing and machine learning (dhji@whu.edu.cn).

Yin Lan, born in 1979. PhD candidate and associate professor. Her main research interests include natural language processing and machine learning (yindew@gmail.com).

Ren Yafeng, born in 1986. PhD. Member of China Computer Federation. His main research interests include opinion mining and machine learning (renyafeng@whu.edu.cn).

Niu Zhengyu, born in 1976. PhD. His main research interests include natural language processing and machine learning (530845455@qq.com).
Caption Generation from Product Image Based on Tag Refinement and Syntactic Tree
Zhang Hongbin1,2, Ji Donghong1, Yin Lan1,3, Ren Yafeng1, and Niu Zhengyu4
1(ComputerSchool,WuhanUniversity,Wuhan430072)2(SchoolofSoftware,EastChinaJiaotongUniversity,Nanchang330013)3(SchoolofBigDataandComputerScience,GuizhouNormalUniversity,Guiyang550001)4(BaiduOnlineNetworkTechnology(Beijing)Co,Ltd,Beijing100085)
Automatic caption generation from product image is an interesting and challenging research task of image annotation. However, noisy words interference and inaccurate syntactic structures are the key problems that affect the research heavily. For the first problem, a novel idea of tag refinement (TR) is presented: absolute rank (AR) feature is applied to strengthen the key words’ weights. The process is called the first tag refinement. The semantic correlation score of each word is calculated in turn and the words that have the tightest semantic correlations with images’ content are summarized for caption generation. The process is called the second tag refinement. A novel natural language generation (NLG) algorithm named word sequence blocks building (WSBB) is designed accordingly to generateNgram word sequences. For the second problem, a novel idea of syntactic tree (ST) is presented: a complete syntactic tree is constructed recursively based on theNgram word sequences and predefined syntactic subtrees. Finally, sentence is generated by traversing all leaf nodes of the syntactic tree. Experimental results show both the tag refinement and the syntactic tree help to improve the annotation performance. More importantly, not only the semantic information compatibility but also the syntactic mode compatibility of the generated sentence is better retained simultaneously. Moreover, the sentence contains abundant semantic information as well as coherent syntactic structure.
image annotation; product image; caption generation; tag refinement (TR); syntactic tree (ST); word sequence blocks building;Ngram word sequence; natural language generation (NLG)
2015-10-13;
2016-04-19
国家自然科学基金项目(61133012);国家社会科学基金重大招标项目(11&ZD189);教育部人文社科基金项目(16YJAZH029);江西省科技厅科技攻关项目(20121BBG70050,20142BBG70011);江西省高校人文社科基金项目(XW1502,TQ1503);江西省普通本科高校中青年教师发展计划访问学者专项资金;江西省社科规划项目(16TQ02)
TP391
This work was supported by the National Natural Science Foundation of China (61133012), the National Social Science Major Tender Project (11&ZD189), the Humanity and Social Science Foundation of Ministry of Education (16YJAZH029), the Science and Technology Research Project of Jiangxi Provincial Department of Science and Technology (20121BBG70050,20142BBG70011), the Humanity and Social Science Foundation of Jiangxi Provincial Universities (XW1502,TQ1503), the Visiting Scholar Special Fund for the Development Plan of Young and Middle-Aged Teachers of General Universities in Jiangxi Province, and the Social Science Planning Project of Jiangxi Province (16TQ02).
