一种基于分块混淆的动态数据隐私保护机制
2016-11-25张宏磊史玉良张世栋周中民崔立真
张宏磊 史玉良 张世栋 周中民 崔立真
(山东大学计算机科学与技术学院 济南 250101) (yanlei1214@126.com)
一种基于分块混淆的动态数据隐私保护机制
张宏磊 史玉良 张世栋 周中民 崔立真
(山东大学计算机科学与技术学院 济南 250101) (yanlei1214@126.com)
云计算环境下,基于分块混淆的隐私保护机制通过对租户个性化隐私保护需求及应用性能的有效结合,实现了隐私信息在明文状态下的保护.然而随着云端多租户应用的持续运行,一方面,租户数据的插入、删除和修改等业务操作将会影响底层数据存储的分布状态,使分块间的关联关系因数据分布的不均匀而面临极大的泄露风险;另一方面,攻击者仍然可以通过局部时间内各分块的操作日志以及对应的数据快照分析出部分隐私信息.针对上述挑战,在三方安全交互模型的基础上,提出一种面向分块混淆的动态数据隐私保护机制.该机制通过可信第三方对新插入和修改的数据进行缓存并在满足条件时将数据进行分组和存储;通过保留关键分片来保证删除操作中被删数据和剩余数据的隐私安全;通过伪造数据回收机制实现存储资源消耗的降低和应用性能的优化.通过实验证明,提出的动态数据隐私保护机制具有较好的可行性和实用性.
多租户;分块混淆;动态数据;隐私保护;可信第三方
随着云计算的迅速发展,具有多租户特点的软件即服务(software as a service, SaaS)应用以其低费用、规模效益的商业运营模式和单实例、按需定制的软件交付特点,被越来越多的企业和服务商所采用.
在SaaS应用中,一方面,租户通过按需租赁和个性化定制,在满足自身业务需要的同时,节省了用于基础设施和后续升级、维护、管理等方面的高昂费用;另一方面,通过与SaaS服务商签订服务等级协议(service level agreement, SLA),保证了应用的服务质量,维护了租户和服务商双方的利益.
然而,随着SaaS应用的广泛推广和使用,租户隐私数据在云中的安全性也受到了越来越多的关注.在多租户应用中,为了满足租户对数据进行业务操作的需求,租户敏感数据通常需要以明文的形式在非完全可信的服务商处进行存储和处理,使租户的隐私数据脱离了租户的直接控制,可能被服务提供商恶意泄露.例如,在利益的驱动下,服务商可以将租赁其应用的某公司的产品定价信息及其客户关系转卖给其竞争对手,导致该公司经济利益受损.
针对SaaS应用面临的租户隐私泄露问题,我们在文献[1]中提出了一种基于分块混淆的数据组合隐私保护机制:1)根据租户定制的隐私约束将组合隐私属性切分到不同的分块中并混淆不同分片间的关联关系;2)针对分块中数据分布不均衡导致的隐私泄露问题,提出基于伪造数据的均衡化机制,通过添加伪造数据使各分块的分布达到均衡;3)通过与可信第三方进行交互构建混淆数据的重构机制,保证租户隐私数据的可用性.
文献[2-3]在此基础上又分别从不同方面进行了补充和优化.文献[2]基于租户的个性化隐私保护和事务处理需求,提出了基于策略的个性化隐私保护机制;文献[3]通过键能算法对属性进行聚类,将关联程度较高的属性尽量分到同一分块中,通过减少分块间的连接次数对应用性能进行提高.
然而在云计算环境下,随着多租户应用的持续运行,租户对数据的增加、删除、修改等业务操作将导致底层数据存储的持续变化,各分块的分布规律也将相应地发生变化,当数据分布不再均匀时,分片间的关联关系将以较大概率面临着被泄露的风险.另一方面,若攻击者可以获取局部时间内各分块的操作日志和数据快照,仍然可以通过对比分析推测出这部分数据中蕴含的隐私信息,这就要求所采取的隐私保护机制必须能适应这种变化,确保租户的隐私保护需求持续得到满足.
针对上述挑战,本文提出基于分块混淆的动态数据隐私保护机制,该机制以水平分组为单位对租户业务操作进行处理,通过可信第三方对新插入和修改的数据进行缓存并在满足条件时将数据进行分组并上传至存储层进行存储;通过保留关键分片来保证删除操作中被删数据和剩余数据的隐私安全;最后提出伪造数据回收机制,降低了存储资源的消耗并实现了应用性能的优化.论文最后进行了实验验证和性能评估,实验结果表明:该机制使租户隐私在业务处理过程中得到有效保护的同时,也具有良好的处理性能.
1 相关工作
针对隐私保护,数据加密和数据混淆是目前比较成熟的2种解决方案.但是加密后的数据往往丢失了可操作性,因此提高密文检索速度和处理效率是加密隐私保护的研究热点.文献[4]分析了云计算的特征,提出一种在云中实现隐私保护的关键词检索模式,它支持服务提供商可以参与部分解密工作以减少客户端负担,同时在加密数据上实现关键词检索,以保护租户数据隐私和用户查询隐私;文献[5]利用“理想格(ideal lattice)”的数学对象构造了隐私同态(privacy homomorphism)算法,使人们可以充分地操作加密状态的数据,加密方法对数据处理性能有较大影响,研究者提出通过其他方式来防止泄露隐私;文献[6]提出了(α,k)-匿名原则,其在保证数据表满足k-匿名化原则的同时,要求每个等价类中任一敏感属性值相关记录的百分比不高于α,从而避免攻击者利用一致性攻击和背景知识攻击来确认敏感数据与个人身份的联系;文献[7]提出l-diversity原则,要求每个等价类的敏感属性至少有l个不同的值,使得攻击者最多以1l的概率确认某个体的敏感信息;文献[8]有效结合了信息分解和数据加密,提出使用隐私约束的概念来实现信息分解,提出隐私约束的概念,用来描述需要经过加密保护的数据属性和同时出现会泄露隐私的数据属性组合,根据这些隐私约束,经过信息分解得到满足要求的分块模式,其中各个数据分块之间的关联关系保存在客户端;文献[9]针对事务数据库隐私保护发布的数据安全性与效用性不足,提出了一种有效的满足差分隐私约束的事物数据发布策略(transaction data publication strategy, TDPS),该策略基于项集I,构建事务数据库D的完整树Trie,然后基于压缩感知技术对完整树添加满足拆分隐私约束的噪音得到含噪Trie树,最后在此树上进行频繁项集挖掘任务,很好地保护了数据隐私.但是,这些研究主要面向的是数据发布领域中的隐私保护问题,很少涉及对隐私数据的增删改操作.
对于动态数据的隐私保护,目前已经有多钟不同的方法相继被提出[10-14],但是这些方法解决的也大都是面向数据发布和数据挖掘中的动态数据隐私保护,并不适合SaaS应用中的隐私保护.
文献[10]对持续增长数据集的隐私保护做了相应的研究,其思路是新的记录要插入必须满足2个限定条件:1)待插入记录数不能少于一定的数量;2)待插入的记录集要符合l-diversity 技术的要求.如果有其一达不到要求就不能插入.该方法存在数据更新不及时且数据的更新只局限于插入这一种操作的问题.同样地,文献[11]和文献[12]中提出的方法也只是针对插入操作对数据进行隐私保护,而在SaaS应用中租户需要经常对数据进行插入、删除和修改等操作,因此这些方法并不适应于SaaS应用.文献[13]提出了m-invariance匿名机制,其核心思想是在数据集的任何一个快照中,一条指定的数据记录都只能被放置在具有固定的隐私属性集的分片中,该方法很好地解决了数据发布过程中的值相关攻击.文献[14]针对数据发布中存在的值等价攻击问题,在文献[13]的基础上利用“最小割”算法提出了一种基于图的匿名算法,该算法同时对值相关攻击和值等价攻击问题进行了保护.文献[15]针对动态变化的外包数据库的隐私保护问题,在数据分解的基础上提出将用户最近插入和修改的数据通过加密后存放到外包数据库中,将加密秘钥保存在客户端,在删除数据时只删除包含识别信息的部分数据,该方法要求客户端保存加密秘钥并且需要明确区分标识信息和敏感信息,并且在业务操作中需要频繁进行加密和解密操作.而在SaaS应用中,租户不需要存储任何信息或拥有任何计算能力,并且租户需要能够对隐私需求进行个性化定制,指定的隐私约束中往往无法明确区分识别信息和敏感信息,因此文献[15]中的隐私保护方法并不能完全适合SaaS应用的动态隐私保护.
虽然上面提出的各种方法很好地应对了数据发布和数据挖掘中存在的各种动态隐私保护问题,但由于SaaS应用与数据发布具有完全不同的特点,使得上述方法都不能完全适应于SaaS应用.文献[1]针对SaaS应用,提出一种基于分块的隐私保护机制,根据租户提出的隐私约束将租户数据中的组合隐私分解到不同的数据分块中,并隐藏分片之间的关联关系,实现了明文状态下的SaaS数据隐私保护,通过插入伪造数据的方式,确保各分块中数据分布的持续均衡,防止服务运营商泄露租户的数据组合隐私,但该文献并没有提及租户对数据进行插入、删除和修改时如何对隐私数据进行保护,存在泄露数据块关联关系的危险.
2 问题分析
随着信息技术的高速发展,对数据的采集、存储和分析变得更加方便和快捷,技术手段也更加先进和完善.在现实生活中,由于企业管理和权限分配的不完善,云计算服务中经常会发生服务商或数据库管理员(本文将恶意泄露租户隐私的相关人员统称为攻击者)通过各种技术手段恶意获取用户数据及其变更记录,并通过分析后泄露用户隐私的情况.虽然租户数据在存储到云端之前已经通过分块混淆隐藏了不同分片之间的关联关系,但攻击者仍然可以通过对数据变更后各分块的不均匀分布情况或者数据变更日志及相应的局部数据快照进行分析得到部分租户的隐私信息.下面我们将通过图1所示示例对文献[1]所提隐私保护机制在租户进行业务操作时面临的隐私泄露威胁及其他不足分别进行分析.
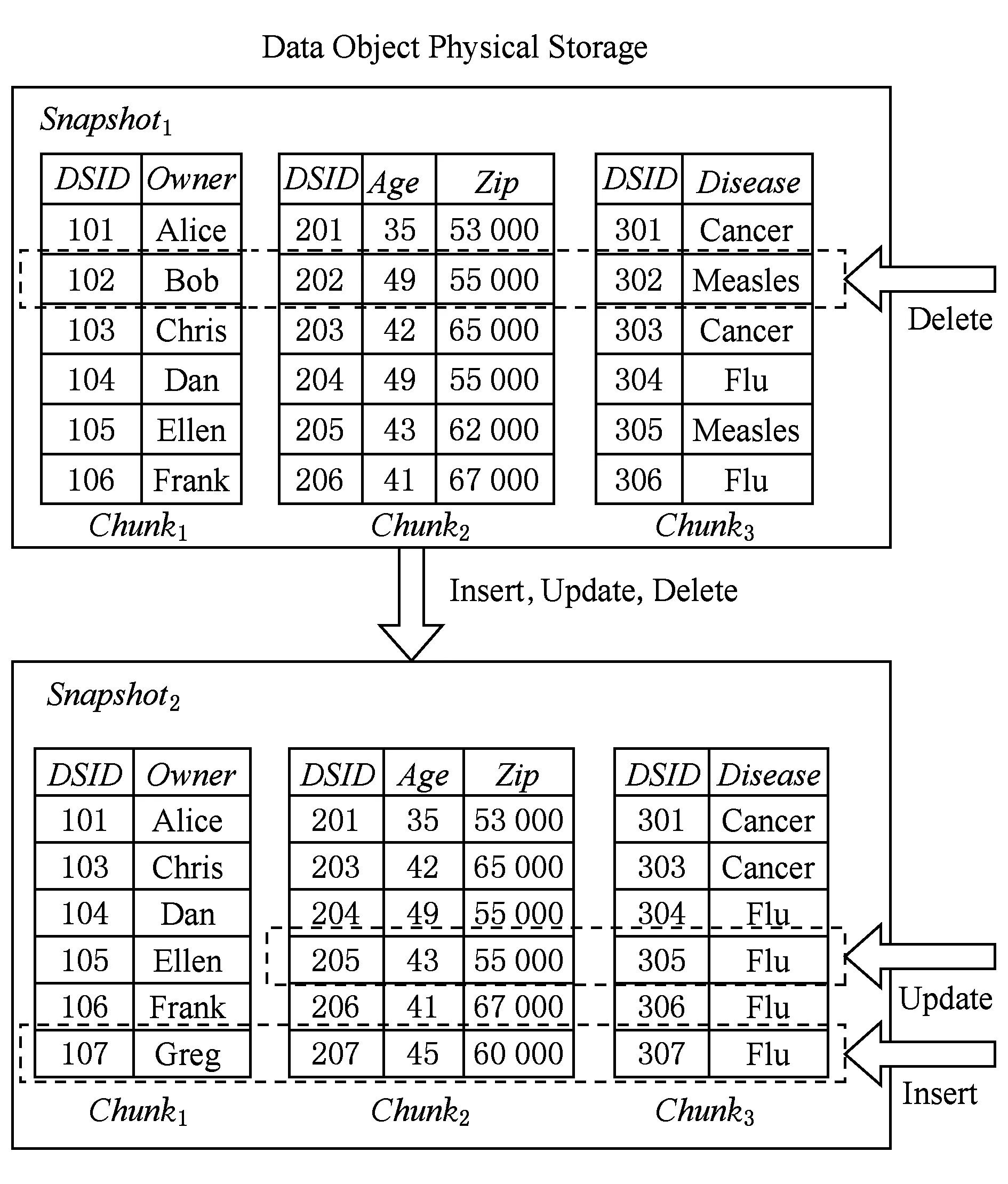
Fig. 1 Diagram of data updating.图1 数据变更示意图
图1中Snapshot1是进行业务操作前根据文献[1]提出的方法对租户数据的逻辑视图进行分块后得到的数据对象物理存储模式,Snapshot2是对Snapshot1分别执行了1次插入、删除和修改后得到的数据对象物理存储模式.表1为通过某种工具或技术获取的这段时间内租户对数据库的业务操作日志.
1) 通过操作日志和数据快照泄露租户隐私
当攻击者获取到数据变更日志(表1)以及变更前后的数据快照Snapshot1和Snapshot2后,通过日志可以发现这3个分块同时插入和删除过分片,通过对比Snapshot1和Snapshot2可以推测出该过程删除了1条关于Bob的数据并且Bob患有疾病Measles,新增了1条Greg的数据且Greg患有疾病Flu.由于同时在Chunk2和Chunk3中分别修改了1个分片的取值,可以推断出43岁且原先邮编为62 000的那位病人其患病信息已由Measles变更为Flu且其邮编也发生了变化.
2) 分块数据不均匀导致租户隐私泄露
3) 由分块均衡引起的伪造数据激增问题
图1中,业务操作完成后,Chunk3中分片只有2种取值:Cancer和Flu,且取值Flu所占比例为23.此时要使其符合租户指定的隐私保护水平要求13,则Chunk3中的分片数量至少需要达到12条,即至少需要向Chunk3中插入6条伪造数据进行均衡.此时伪造数据占总数据量的比值将达到12,在云计算环境中,随着用户数据量的急剧增加,较高的伪造数据占比不仅会浪费大量的存储空间,而且也会导致应用性能的急剧下降.另一方面,文献[1]提出的均衡策略是通过不断插入伪造分片实现的,随着应用的持续运行,系统中的伪造数据会一直增加,而在数据量较大时,再想通过删除伪造数据来实现数据均衡将需要付出巨大的计算代价.
从上面的举例分析可以看到,如果直接将租户的业务操作作用于云端数据,不仅会直接泄露本次被操作的租户的隐私信息,还会导致表中其他隐私数据因为分块中数据分布的不均匀而引起泄露.此外不合理的均衡机制也会导致系统因较高的伪造数据占比而付出较大的存储消耗和性能代价.
因此,为了应对SaaS应用中因多租户对数据的业务操作而引起的隐私泄露和分块均衡问题,本文提出先对数据进行水平分组,并以更细粒度的水平分组为单位对租户数据进行隐私保护,引入分块信息熵对分块的均衡状态进行评估,通过保证各水平分组在租户业务操作中的安全性,实现对整体隐私数据的保护.通过在水平分组时对分组均衡状态的兼顾以及后续对分组合并和伪造数据的回收,降低伪造数据对应用性能的影响.
3 动态数据隐私保护框架
针对租户业务操作过程所面对的隐私泄露问题及其他不足,本文提出了基于分块混淆的动态数据隐私保护框架,如图2所示.该模型共包含应用层、隐私保护层、存储层和可信第三方4个部分.其中应用层负责管理租户租赁的应用并对租户的业务请求做出响应;隐私保护层负责对租户提交的业务请求进行处理并根据租户定制的隐私保护需求在处理过程中对租户隐私进行保护;存储层负责对分块处理后的租户数据进行存储;可信第三方负责管理租户最新更新的数据以及租户的隐私保护策略,并通过身份认证机制防止攻击者冒用身份对数据和隐私保护策略越权访问.

Fig. 2 Dynamic privacy protection framework.图2 动态隐私保护框架
图2所示的框架中,应用层接收到租户的业务请求后,通过步骤①将请求转发至数据更新模块进行处理;数据更新模块根据请求类型决定需要对存储层和可信第三方中分别进行哪些操作,并通过步骤②分别发送对应的操作指令;身份验证模块负责对操作进行验证;临时数据管理模块负责对最近更新的数据进行分组,分组完成后将通知分块处理模块;分块处理模块通过步骤③从可信第三方调用分块策略对临时数据分组进行分块处理,分块完成后通过步骤④通知均衡模块对各分块添加的伪造数据进行均衡数理,并通过步骤⑤将均衡后的分块存入存储层;伪造数据回收模块通过步骤⑥对存储层中各分组数据剩余量进行监控,定时回收多余伪造数据.
4 动态数据隐私保护机制的实现
第2,3节举例分析了SaaS应用持续运行过程中因租户业务操作引起的隐私泄露和分块均衡问题,并针对这些问题提出了基于分块混淆的动态数据隐私保护框架.本节将在第3节的基础上,详细介绍该框架的相关概念及具体实现,并将通过具体的公式和定理证明通过该框架对数据进行业务操作时可有效防止租户隐私的泄露.下面首先给出相关定义.
4.1 相关定义
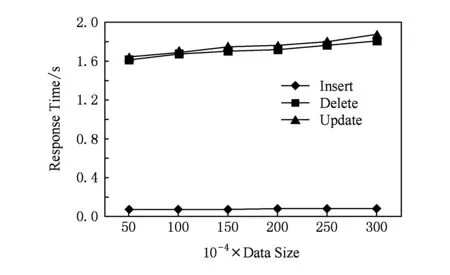
定义1. 水平分组G.G是租户数据逻辑视图T的一个子集,因此租户数据逻辑视图T可以表示为T=∪Gi(1≤i≤m),且其中任意2个不同的水平分组Gi和Gj均不重叠,即Gi∩Gj=φ(1≤i 定义2. 隐私保护策略(privacy protection strategy, PPS).根据租户提出的隐私约束将逻辑视图T的属性集Attrs={A1,A2,…,An}划分为几个不同子集,即Attrs=∪subAttrsi(i=1,2,…,k),其中k为分块数,使得每个子集均不违背隐私约束条件,且任意2个子集均不相互重叠,即subAttrsi∩subAttrsj=φ(1≤i 定义3. 分块信息熵H(X).给定一个数据分块X,分块中分片的值域为{v1,v2,…,vn},对应的每个取值出现的概率为{p(v1),p(v2),…,p(vn)},则该分块的信息熵为 (1) 其中,a表示为对数所使用的底,通常α=2,对应熵的单位为b.数据分块中的各分片取值越均匀则其信息熵越大,当各分片取值出现的概率均相等时,该分块的信息熵取得最大值;反之,当只有一种分片出现时其熵值最小为0. 定义4. 分片依赖p(x/y).用条件概率进行表示,其中x表示分块A中属性X的某一取值,y表示分块B中属性Y的某一取值,此时称分块A中X取值为x的分片以概率p(x/y)依赖于分块B中Y取值为y的分片. 在实际应用中,分片依赖的概念是普遍存在的,譬如公司中员工工资水平与其职位的关系.假设某公司普通员工的工资水平一般为3 000~5 000元,部门经理的工资水平为5 000~8 000元,但5 000~8 000元工资段也有约15%的是业绩突出的普通员工,而3 000~5 000元工资段也有5%的是业绩较差的部门经理,此时若给定某一工资水平为6 500元,则我们可以以85%的概率推断其为某一部门经理,即工资为6 500元的分片以85%的概率依赖于职位为“部门经理”的分片.此时,即使包含工资和职位属性的2个分块均已均衡,仍然可以以较大概率对分片进行关联. 为了描述在不同分块中的属性存在依赖关系时的数据均衡程度,本文引入了块间条件熵的概念. 定义5. 块间条件熵H(Y/X).表示在已知随机变量X值的前提下,随机变量Y的信息熵还有多少,用来衡量在已知随机变量X的条件下随机变量Y的不确定性.表示为 (2) 通过式(2)可以证明,当Y的值完全由X确定时,H(Y/X)取得最小值0;反之,当且仅当X和Y为相互独立变量时,H(Y/X)取最大值. 定义6. 临时更新表U.该表设置在可信第三方,用来存储租户最近更新的数据,其形式为 (id,A1,A2,…,An,Time), 其中,id为该记录的全局唯一标识,在分块时用来产生各分片的DSID;Time字段为一个时间戳,用来标识该条数据插入或修改的时间. 4.2 动态数据隐私保护的具体实现 文献[1-2]中为防止租户的隐私保护策略被攻击者恶意获取,提出使用可信第三方对隐私保护策略进行管理,并通过身份验证机制阻止攻击者的恶意请求.本文在可信第三方的基础上增设了临时数据管理模块,主要负责对租户最近更新的数据进行临时存储,并在生成水平分组后对水平分组进行垂直分块并存至存储层.通过可信第三方的身份认证机制防止临时数据被恶意获取,使临时数据可以安全地以明文形式进行存储,保证了租户请求数据时的响应时间. 4.2.1 插入数据 设租户Tenanti在时刻t1提交的原始插入请求为 INSERT INTOTVALUES(a1,a2,…,an). 根据第2节分析,若直接将数据写入云端数据库各分块中,则各分块将同时增加相同数目的记录,攻击者可以根据租户操作行为推测出新增分片间的关联关系,使租户的这部分隐私面临很大的泄露风险.因此本机制需要对原始插入请求进行如下转换: INSERT INTOUVALUES(id,a1,a2,…,an,t1), 转换过程将新插入的数据添加全局id和时间戳t1后插入临时表U中临时存储,当表U中数据量大于设定阈值Nmax时,调用分组生成算法3对表U中数据进行水平分组,并以水平分组为单位对数据进行分块和均衡,最后存入存储层.由于对表U的操作发生在可信第三方,数据存储到存储层时虽然将分组信息暴露给了攻击者,但分组内各分块已进行均衡处理,因此整个分组和插入过程也是可靠的. 4.2.2 删除数据 对于临时更新表U中的数据,删除操作发生在可信第三方,直接将对应数据删除即可.而对应于存储层各分块中的数据,同时执行删除操作会引起隐私泄露,因此在删除数据时需要对部分分块中的数据进行保留,为此首先引入以下概念. 定义7. 关键属性(key attribute, KA).指隐私约束中敏感程度较高的属性,由租户在隐私保护需求中指定.例如不相容约束{Owner,Age,Zip,Disease}中,病人对于Disease属性更为敏感,当病人身份信息被泄露时,仍希望其疾病信息能够得到保护,因此保证包含Disease属性分块的安全更加重要. 定义8. 关键分块(key chunk, KC).本文把包含有关键属性的分块称为关键分块. 定义9. 低权重分块(lower weighted chunk, LWC).指在业务处理过程中,除关键分块外,涉及频率最低的分块,该分块中数据量的大小不会对业务处理效率产生太大影响. 定义10. 不相容分块(mutually exclusive chunks, MEC).本文将同一不相容隐私约束所涉及的所有分块称为一组不相容分块(如图1中Chunk1,Chunk2,Chunk3即为一组不相容分块),当隐私需求中包含多个不相容约束时,则对应的分块结果中会存在多组不相容分块. 在进行删除处理时,对于同一组不相容分块,保留被删数据在关键分块和低权重分块中的分片,此时攻击者最多只能对同一条数据的部分分片进行重构,无法破坏隐私约束,保证了租户隐私的安全.删除算法的过程描述如下: 算法1. 数据删除算法. 输入:数据对象物理视图DOPV、临时更新表U、隐私分块策略pps、删除条件rc; 输出:数据删除操作执行结果. ① 从U中删除符合rc的数据; ② 获取除关键分块和低权重分块的所有分块号,存入数组chunk; ③ 根据算法4获取DOPV中符合条件rc的原始数据的全局标识resultSet; ④ for eachidinresultSetdo fori=0 tochunk.length-1 do 计算id在chunk[i]中的DSID编号并删除其在chunk[i]中对应的分片; ⑤ end for ⑥ end for 下面提出2个辅助定理证明在分组信息暴露的场景下,算法1在删除操作时不会引起隐私泄露. 定理1. 对于一个不相容分块组,保持某一分块数据不变,在每次删除数据时只删除其余分块中的数据,则数据删除后各分块的信息熵大于等于数据删除前各分块信息熵. 证明. 设某不相容分块组包含C1和C2这2个分块,在执行删除请求时只删除C2中的分片,由于分块C1中的数据分布始终不变,所以分块C1的信息熵也保持不变.对于分块C2,设删除分片前的数据分布为{p(v1),p(v2),…,p(vn)},根据最大熵的含义,在已知部分知识的前提下,关于未知部分最合理的推断就是符合已知知识的最随机的推断,因此我们总能找到一种数据填充方式使补充后数据分布为{p1(v1),p1(v2),…,p1(vn)},并且有: 即攻击者推测的分块C2的当前熵值只能大于或等于其初始熵值,即在对分块中数据分布无背景知识的前提下,攻击者只能以C2分块符合尽量均匀分布来对隐私进行猜测. 证毕. 定理2. 对于一个不相容分块组,保持某一分块数据不变,在每次删除数据时只删除其余分块中的数据,则数据删除后各分块的条件熵大于等于数据删除前各分块条件熵. 证明. 设事件X和Y分别表示从分块C1和C2中取值事件,在本文我们只关心给定X=xi猜测Y=yj需要的信息熵或者给定Y=yj猜测X=xi需要的信息熵,因此只需要证明H(Y/X=x)和H(X/Y=y)不减即可.由 可知X的取值不变,而给定x,y时P(x/y)是保持不变的,因此H(X/Y=y)保持初始大小.而对于H(Y/X=x),则 当删除分块C2中的分片后可能导致Y的取值数目减少,但在无背景知识时,攻击者只能认为Y可以取剩余取值之外的其他取值,即Y的取值数目只能大于或等于初始数目使得H(Y/X=x)大于或等于其初始值. 证毕. 由辅助定理1和定理2可知,当只删除部分分片时,总能够保持各分块的熵值和分块间的条件熵值是不减的,因此在删除过程中不会因熵值的减少而泄露租户隐私. 随着SaaS应用的不断运行,云端数据库中可能会逐渐出现这样的情况,即一个水平分组中的数据经过多次删除和修改后只剩下极少量有效数据,为了保证删除数据时租户的隐私安全,需要完整保留关键分块和低权重分块的数据,同时还有数据均衡时的伪造数据,此时为了存储这少量数据就需要付出比较大的存储代价,而当这种水平分组的数量越来越多时,较大的伪造数据占比也会对查询效率造成较大影响. 因此本文在设计算法时,增加了伪造数据回收机制,当一个水平分组中的剩余数据所占比例小于设定的下限值Tremain时,将剩余数据插入临时更新表U中,并将该分组中的所有数据删除,对表U中数据进行分组后重新进行存储.算法过程描述如下: 算法2. 伪造数据回收. 输入:分组信息表group_info、剩余数据占比阈值Tremain; 输出:伪造数据回收操作执行结果. ① for eachgidingroup_infodo ② ifremain/tatal ③ 调用算法4获取分组gid中剩余数据对应的全局id的集合resultSet; ④ for eachidinresultSet ⑤ 将id对应的原始数据插入U中; ⑥ end for ⑦ 调用算法1,将分组gid所有数据从存储层中删除; ⑧ end if ⑨ end for 4.2.3 修改数据 对于临时更新表U中的数据,修改操作发生在可信第三方,直接修改对应数据即可.而对应于存储层各分块中的数据,由于同时对各分块执行修改操作会引起隐私泄露,因此本文的处理方式是将修改后得到的数据直接插入临时更新表U中进行存储,并同时将原始数据从存储层各分块中删除.在4.2.2节中证明了删除算法1的删除过程是安全的,而插入操作发生在可信第三方,因此整个修改过程是安全的. 4.2.4 分组生成及数据分块 算法3. 分组生成和分块算法. 输入:临时数据表U、最小组大小N、最小分块熵H1和最小条件熵H2; 输出:分组g. ① 创建空组g(g中元素为U中记录的唯一标识); ② 对表U中关键属性的取值按其出现频率从小到大进行排序; ③ whileg.length 按照步骤②中的排序结果,依次选取关键属性取值,并将包含此取值的数据id取值加入g; ④ end while ⑤ 从表U的剩余数据中依次选取数据r,若将其加入g后对应各分块的熵值都不小于H1,则将r.id加入g; ⑥ 调用分块策略对g中数据进行分块; ⑦ 根据H1和H2构造伪造数据对各分块进行均衡; ⑧ 将各分块数据存入存储层; ⑨ returng. 算法3中,以关键属性为基准进行分组,分组结果中首先保证关键分块尽量均衡.行②首先将关键属性依其出现频率进行排序,行③一次选取出现频率较小的关键属性并将其对应的数据加入分组中,这样可以使分组中关键属性有较多的取值,分布更加均匀.行④采用贪心思想,从剩余分块中依次选取数据进行尝试,将其加入g时能使各分块的熵值不小于H1,则接受其加入g;行⑤~⑦在产生分组g后,调用分块策略对分组进行分块,并采用文献[1]的均衡方法对各分块进行均衡处理. 4.2.5 隐私数据重构 隐私数据经过分块混淆后,其数据可用性也随之丧失,而在SaaS应用中租户需要频繁对原始数据进行访问、删除和修改等.因此,如何对隐私数据进行快速重构成为SaaS应用隐私保护的一大关键问题. 对隐私数据进行分块时,会根据原始数据的全局id为每个分片生成1个唯一的分片标识DSID,该标识主要用于对原始数据进行重构并对伪造数据进行过滤.算法4为基于可信第三方的原始数据重构算法,输入为数据对象物理视图DOPV、租户隐私分块策略pps和重构条件rc,输出为满足条件的原始记录的全局id.算法4首行先根据分块策略将重构条件rc划分为rc={rc1,rc2,…,rci,…,rck},其中k为分块数,rci为分块Chunki上的重构条件;行②在每个分块Chunki上查询符合条件rci的DSID并将其转换为全局id后放入集合idSeti中,行⑤对所有idSet求交集,得到最终符合重构条件rc的原始数据全局id集合resultSet;行⑥将resultSet中伪造数据对应的全局id进行过滤;行⑦将rc和resultSet缓存到cache中,提高下次相同重构请求的执行效率.算法描述如下: 算法4. 隐私数据重构算法. 输入:数据对象物理视图DOPV、隐私分块策略pps、重构条件rc; 输出:原始数据全局id集合resultSet. ① 根据pps划分重构条件rc; ② fori=1 tokdo ③ 查询分块Chunki上符合rci的DSID,将其对应的全局id放入集合idSeti; ④ end for ⑥ 过滤resultSet中伪造数据对应的全局id; ⑦ 将rc和resultSet存入cache; ⑧ returnresultSet. 算法4中,在各分块中查询符合条件的DSID采取并行执行方式,查询时间与数据量大小成正比关系.设所有N为idSet长度的最大值,若采用二路归并求交,则其时间复杂度为O(N2lbk).一般情况下,符合条件的N取值都不是很大,因此该时间复杂度在可接受范围内. 5.1 实验环境 为进行实验,作者采用从本实验室云计算平台申请的虚拟机作为可信第三方,其配置为8核、16 GB内存和500 GB硬盘.用MongoDB3.0.0存储租户隐私保护策略,用Mysql5.6.22存储临时更新表数据. 用1台浪潮刀片服务器模拟部署多租户应用,配置为12核CPU(主频3.10 GHz)、32 GB内存、2TB硬盘.存储层同样使用Mysql5.6.22做存储数据库,多租户应用使用Java1.8编写程序进行模拟. 数据集取自本实验室社保项目内部测试数据集的参保人医疗登记基本信息表中的数据,数据量大小为300万条左右.数据选取了姓氏(已模糊处理)、医疗人员类别、性别、年龄、信任等级、孤寡类别、单位组织、医疗账户以及其他属性等共20个属性进行实验.不相容隐私约束为姓氏、性别、年龄、单位组织. Fig. 3 The change of business operation with the increasing of data volume.图3 业务操作随数据量增加的变化 5.2 业务处理开销实验 图3为在本文提出的动态数据隐私保护机制下,增删改3种不同操作在不同数据量下的操作处理时间,横轴为数据量大小,纵轴为响应时间. 从图3可以看出,由于新插入数据总是被存储到临时表中,而表U中只存储少量数据并且数据量基本保持稳定,所以插入数据的处理速度很快,只有几十毫秒左右.而对于删除和修改操作,由于需要首先对被更新的数据进行重构,导致其处理时间大大增加,并且随着数据量的增大而线性增加. 图4将本文提出的方法与其他3种方法在业务处理效率方面进行了对比.方法A为不进行隐私保护,本文提出动态隐私保护机制,采用文献[1]中的分块策略,方法B为文献[1]提出的隐私保护机制,方法C为文献[3]对数据属性进行聚类后的隐私保护方法.数据量大小为200万条左右,查询、插入和修改这3类业务操作中每类操作涉及的属性数又分为2,4,6,8,10这5个级别,实验结果采用所有级别处理时间的平均值. Fig. 4 The business operation costs of different methods.图4 不同方法下业务操作开销 从图4可以看出,不进行隐私保护时处理速度最快,而本文方法和方法B虽然查询、删除和修改都受制于数据量大小,但由于在相同数据量时,本文提出的隐私保护方法中伪造数据相对减少,所以总体上本文方法比文献[1]的方法B在性能上还是有所提升;方法C由于对数据属性按业务操作进行了聚类,所以处理效率要比方法B要高,但受伪造数据的影响,还是要比本文方法效率差一些. 5.3 伪造数据占比实验 图5对比了在分块最小信息熵取3时,本文方法、方法B、方法C中伪造数据占比随时间的变化.从图5可以看出,当使用方法B、方法C时,伪造数据占比会随着应用的运行逐渐增加,并且开始阶段提升的幅度比较大.其原因在于在较短时间内数据集中姓氏和年龄的分布并不完全与总体分布一致,数据分布比较不均匀,当数据量随时间逐渐增加时,其分布越接近于总体分布,但是随着对数据操作次数的不断增加,需要增加更多伪造数据进行均衡.而本文方法中由于分组时尽量选取使分组数据分布均匀的数据组成分组,辅以伪造数据回收模块对伪造数据的回收处理,使整个过程中伪造数据占比都比较稳定. Fig. 5 The change of bogus data ratio over time.图5 伪造数据占比随时间的变化 图6对比了伪造数据占比随分组大小产生的变化.当分组较小时,由于分组取值个数相对较少,导致分组内数据分布不均匀,要进行均衡需要添加较多伪造数据;随着分组大小的逐渐增大,分片取值个数逐渐增加,分块分布逐渐均匀;而当分组大小继续增加时,分组内数据分布逐渐接近整体分布,由于总体分布中姓氏和年龄并不是服从均匀分布的,所以分组再次趋向于不均匀状态,导致伪造数据占比又重新升高. Fig. 6 The change of bogus data ratio with the size of group.图6 伪造数据占比随分组大小的变化 从以上2个实验对比可以看出,相对文献[1]中的方法B,本文提出的隐私保护机制具有更高的操作效率,而且随着应用的不断运行,其伪造数据占比更低且始终保持稳定. 对于SaaS应用而言,现有的隐私保护机制缺乏对租户业务操作的有效支持,难以保证数据动态变化过程中租户隐私信息的安全.本文针对SaaS模式下由租户业务操作引起的隐私泄露问题以及伪造数据占比较高的不足,提出了基于分块混淆的动态数据隐私保护机制.该机制将租户最新插入和修改的数据在可信第三方进行缓存,当具备分块条件时再将数据以分组为单位分块均衡后存入存储层;对于删除操作,保留关键分块和低权重分块中的数据不被删除,防止攻击者通过数据操作行为对租户隐私进行重构;最后提出伪造数据回收机制对存储层冗余的伪造数据进行回收,降低伪造数据占总数据量的比例.实验结果证明,本文所提出的动态数据隐私保护机制,在保证租户隐私的同时,对应用的性能也起到了很好的优化效果.下一步工作将主要研究数据动态变化过程中,不同的租户数据放置策略对应用性能的影响. [1]Zhang Kun, Li Qingzhong, Shi Yuliang. Research on data combination privacy preservation mechanism for SaaS[J]. Chinese Journal of Computers, 2010, 33(11): 2044-2054 (in Chinese) (张坤, 李庆忠, 史玉良. 面向SaaS应用的数据组合隐私保护机制研究[J]. 计算机学报, 2010, 33(11): 2044-2054) [2]Shi Yuliang, Jiang Zhen, Zhang Kun. Policy-based customized privacy preserving mechanism for SaaS applications[G] //LNCS 7861: Proc of the 8th Int Conf on Grid and Pervasive Computing. Berlin: Springer, 2013: 491-500 [3]Shao Yali, Shi Yuliang, Li Hui. A novel cloud data fragmentation cluster-based privacy preserving mechanism[J]. International Journal of Grid & Distributed Computing, 2014, 7(4): 21-32 [4]Liu Qin, Wang Guojun, Wu Jie. An efficient privacy preserving keyword search scheme in cloud computing[C] //Proc of the 12th IEEE Int Conf on Computational Science and Engineering. Piscataway, NJ: IEEE, 2009: 715-720 [5]Gentry C. Fully homomorphic encryption using ideal lattices[C] //Proc of the 41st ACM Symp on Theory of Computing. New York: ACM, 2009: 169-178 [6]Wong R C W, Li J, Fu A W C, et al. (α,k)-anonymity: An enhancedk-anonymity model for privacy-preserving data publishing[C] //Proc of the ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2006: 754-759 [7]Machanavajjhala A, Gehrke J, Kifer D.l-diversity: Privacy beyondk-anonymity[C] //Proc of the 22nd Int Conf on Data Engineering. Los Alamitos, CA: IEEE Computer Society, 2006: 24-35 [8]Ciriani V, Di Vimercati S D C, Foresti S, et al. Fragmentation an encryption to enforce privacy in data storage[G] //LNCS 4734: Proc of the 12th European Symp on Research in Computer Security. Berlin: Springer, 2007: 171-186 [9]Ouyang Jia, Yin Jian, Liu Shaopeng, et al. An effective differential privacy transaction data publication strategy[J]. Journal of Computer Research and Development, 2014, 51(10): 2195-2205 (in Chinese) (欧阳佳, 印鉴, 刘少鹏, 等. 一种有效的差分隐私事务数据发布策略[J]. 计算机研究与发展, 2014, 51(10): 2195-2205) [10]Byun J W, Sohn Y, Bertino E, et al. Secure anonymization for incremental datasets[G] //LNCS 4165: Proc of SDM 2006. Berlin: Springer, 2006: 48-63 [11]Pei Jian, Xu Jian, Wang Zhibin, et al. Maintainingk-anonymity against incremental updates[C] //Proc of the 19th Int Conf on Scientific and Statistical Database Management. Piscataway, NJ: IEEE, 2007: 5-14 [12]Byun J W, Li T, Bertino E, et al. Privacy-preserving incremental data dissemination[J]. Journal of Computer Security, 2009, 17(1): 43-68 [13]Xiao Xiaokui, Tao Yufei.m-invariance: Towards privacy preserving re-publication of dynamic datasets[C] //Proc of the 2007 ACM SIGMOD Int Conf on Management of Data. New York: ACM, 2007: 689-700 [14]He Y, Barman S, Naughton J F. Preventing equivalence attacks in updated, anonymized data[C] //Proc of the 27th Int Conf on Data Engineering. Piscataway, NJ: IEEE, 2011: 529-540 [15]Nergiz A E, Clifton C, Malluhi Q M. Updating outsourced anatomized private databases[C] //Proc of the 16th Int Conf on Extending Database Technology. New York: ACM, 2013: 179-190 Zhang Honglei, born in 1987. Master from the School of Computer Science and Technology, Shandong University. His main research interests include cloud computing, privacy preserving. Shi Yuliang, born in 1978. PhD and associate professor in the School of Computer Science and Technology, Shandong University. Member of China Computer Federation. His main research interests include service computing, cloud computing and database. Zhang Shidong, born in 1969. PhD and professor in the School of Computer Science and Technology, Shandong University. His main research interests include database, Web data integration and cloud computing (zsd@sdu.edu.cn). Zhou Zhongmin, born in 1989. Master from the School of Computer Science and Technology, Shandong University. His main research interests include cloud computing, privacy preserving (zhoumin_12@163.com). Cui Lizhen, born in 1976. Professor in the School of Computer Science and Technology, Shandong University. Senior member of China Computer Federation. His main research interests include cloud data management and workflow management (clz@sdu.edu.cn). A Privacy Protection Mechanism for Dynamic Data Based on Partition-Confusion Zhang Honglei, Shi Yuliang, Zhang Shidong, Zhou Zhongmin, and Cui Lizhen (SchoolofComputerScienceandTechnology,ShandongUniversity,Jinan250101) Under the cloud computing environment, the privacy protection in the plaintext state can be realized, by the partition-confusion-based privacy protection mechanism which effectively combines tenants’ personalized privacy protection requirements and application performance. However, as the multi-tenant applications continue to run, on the one hand, the insertion, deletion, modification and other business operations of the tenant data can affect the distribution of the underlying data storage, making the relationships between the chunks in a significant risk of leakage due to the uneven data distribution; on the other hand, the attacker can still analyze a part of private information by the operation log of every chunk and the snapshot of the corresponding data in the local time. In response to these challenges, the present paper proposes a dynamic data privacy protection mechanism for partition confusion on the basis of the tripartite security interaction model. This mechanism can cache the data newly inserted and modified by a trusted third party and then group and upload it under the proper conditions; retaining key fragmentation in the deletion operation can ensure the privacy of the deleted and remained data; the falsifying data collection mechanism can achieve lower consumption of resources storage and optimize the application performance. The experimental result proves that the dynamic data privacy protection mechanism proposed in this paper has better feasibility and practicality. multi-tenancy; partition confusion; dynamic data; privacy protection; trusted third party 2015-06-16; 2015-09-07 国家自然科学基金项目(61272241,61572295);科技部创新方法工作专项(2015IM010200);山东省泰山产业领军人才工程专项经费;山东省科技重大专项(2015ZDXX0201B03,2015ZDXX0201A04,2015ZDJQ01002) 史玉良(shiyuliang@sdu.edu.cn) TP309.2 The research work was supported by the National Natural Science Foundation of China (61272241, 61572295), the Innovation Methods Work Special Project (2015IM010200), the Taishan Industrial Experts Programme of Shandong Province, and the Shandong Province Science and Technology Major Special Project (2015ZDXX0201B03, 2015ZDXX0201A04, 2015ZDJQ01002).


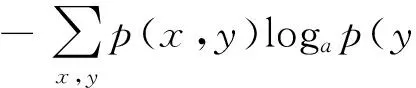



5 实验评估



6 总结与未来工作





