基于种子节点选择的网络环境下多标签分类算法研究
2016-11-25吴信东赵银凤
吴信东,赵银凤,李 磊
(1.合肥工业大学计算机与信息学院,安徽合肥 230009; 2.佛蒙特大学计算机科学系,美国伯灵顿 VT05405)
基于种子节点选择的网络环境下多标签分类算法研究
吴信东1,2,赵银凤1,李 磊1
(1.合肥工业大学计算机与信息学院,安徽合肥 230009; 2.佛蒙特大学计算机科学系,美国伯灵顿 VT05405)
多标签分类在基因分类,药物发现和文本分类等实际问题中有着广泛的应用.已存在的多标签分类算法,通常都是从网络中随机的选取节点作为训练集.然而,在分类算法执行的过程中,网络中不同节点所起的作用不同.在给定训练集数目的情况下,选择的训练集不同,分类精度也会不同.所以我们引入了种子节点的概念,标签分类从种子节点开始,经过不断推理,得到网络中其他所有节点的标签.本文提出了SHDA(Nodes Selection of High Degree from Each Affiliation)算法,即从网络的每个社团中,按比例的选取度数较大的节点,然后将其合并,处理后得到种子节点.真实数据集上的实验表明,将种子节点用作训练集进行多标签分类,能够提升网络环境下多标签分类的准确率.
多标签分类;网络;种子节点;推理;社团
1 引言
目前,多标签分类问题已经取得了广泛关注,并且在实际问题中有很多应用,比如:基因分类,药物发现和文本分类[1].已存在的多标签分类算法,通常都是随机的选取节点作为训练集.然而,在分类算法执行的过程中,网络中不同节点所起的作用不同.在给定训练集数目的情况下,选择的训练集不同,分类精度也会不同.所以随机方法不能有效的利用网络的拓扑结构,导致节点的标签分类结果不稳定.
本文引入了种子节点的概念,分类从种子节点开始,通过不断推理,得到网络中其他节点的标签.应该如何选择种子节点,从而在给定的多标签分类算法下获得较高的分类精度,是本文所要解决的问题,例如:一个大学的所有学生组成了一个网络,学生的标签代表他们的兴趣爱好,如果用一部分学生的标签来预测其他学生的标签,那么我们要解决的问题是,在网络中应该选择什么样的学生作为种子节点,从而使预测结果最好呢?
我们提出了SHDA算法来选择种子节点.首先使用EdgeCluster算法来获取网络中的节点之间潜在的社团[2],接着根据每个社团中包含的节点数目大小,按比例的选取每个社团中度数较高的一些节点,然后将其合并,处理后得到种子节点.本文将种子节点用作训练集进行多标签分类来验证SHDA算法的有效性.
2 相关工作
网络环境下的多标签分类数据一般具有同质性,即服从一阶马尔科夫假设,节点的标签倾向于与其直接邻居的标签相同.关系学习利用对象之间的联系来进行多标签分类,可以取得较好的分类结果[3].集体推理可以进一步改善分类的性能,减少分类错误[3~5].wvRN(weighted-vote Relational Neighbor classifier)算法计算节点vi属于类c的概率,P(yi=c|vi),是其邻居中属于类c的概率的带权平均值:
(1)

还有一种方法是利用标签间的相关性,郑等提出了一种基于随机游走模型的多标签分类算法MLRW(Multi-Label Random Walk algorithm)[7].
然而传统方法无法区分异质网络中对象和边的类型的差异.Ji等[8]提出了基于排序的迭代分类模型(Rankclass),提高了异质网络中的分类性能.Kong等[9]通过挖掘异质网络中对象间和标签间的关系进行多标签分类.Tang 等[2]提出了EdgeCluster算法,其以连接边的节点作为特征,使用Scalable K-means Variant方法将网络的边聚类成多个互不相交的集合,根据聚类结果,构建网络的社会维度,将其作为特征,使用SVM(Support Vector Machines)算法进行多标签分类.SCRN(multi-label iterative Relation Neighbor Classifier that employs Social features)算法[10]拓展了关系邻居分类器,其计算节点vi属于类c的概率为:
(2)
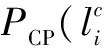
在种子节点选择方面,Qian等通过在隐式社交网络中选择种子节点解决了网络的影响力最大化问题[12].Jankowski等通过选择种子节点进行社交网络中的信息传播[13].
3 SHDA算法
我们首先介绍一下种子节点的定义.
定义1(种子节点) 种子节点是网络环境下多标签分类的起点,通过整个网络对标签的传播和扩散,可预测出网络中其他节点的标签.
下面介绍本文提出的SHDA算法的步骤:
第1步:计算网络中各节点的度数.
第2步:使用EdgeCluster算法[2]提取网络的社会维度.社会维度是节点对各个社团从属程度的描述,一个节点可以从属于多个社团[14].我们去除每个社团中属于测试集的节点,计算η={η1,η2,…,ηN} ,即每个社团中包含的节点数目,以节点度数由高到底的顺序对每个社团中的节点进行排序.
第3步:计算需要从每个社团中选取的节点数目mi:

(3)
其中ntr代表训练集的大小,向上取整函数保证了mi是一个整数.从每个社团中选取前mi个节点,这些节点即是度数排在前mi个的节点.
第4步:合并上述从每个社团中所选的节点作为种子节点集合,由于一个节点可以从属于多个社团,导致节点的重复选取,同时向上取整函数也会导致节点选择的增多,使得种子节点集合的数目与训练集大小不相等,所以要去除重复节点,然后调整种子节点集合大小.
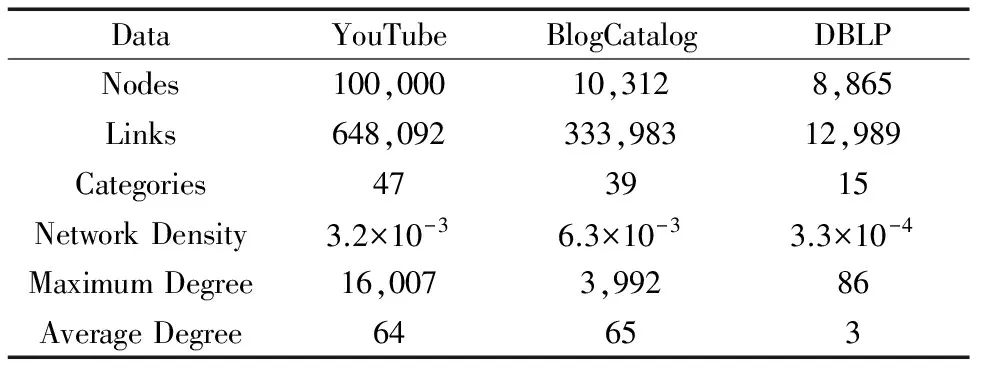
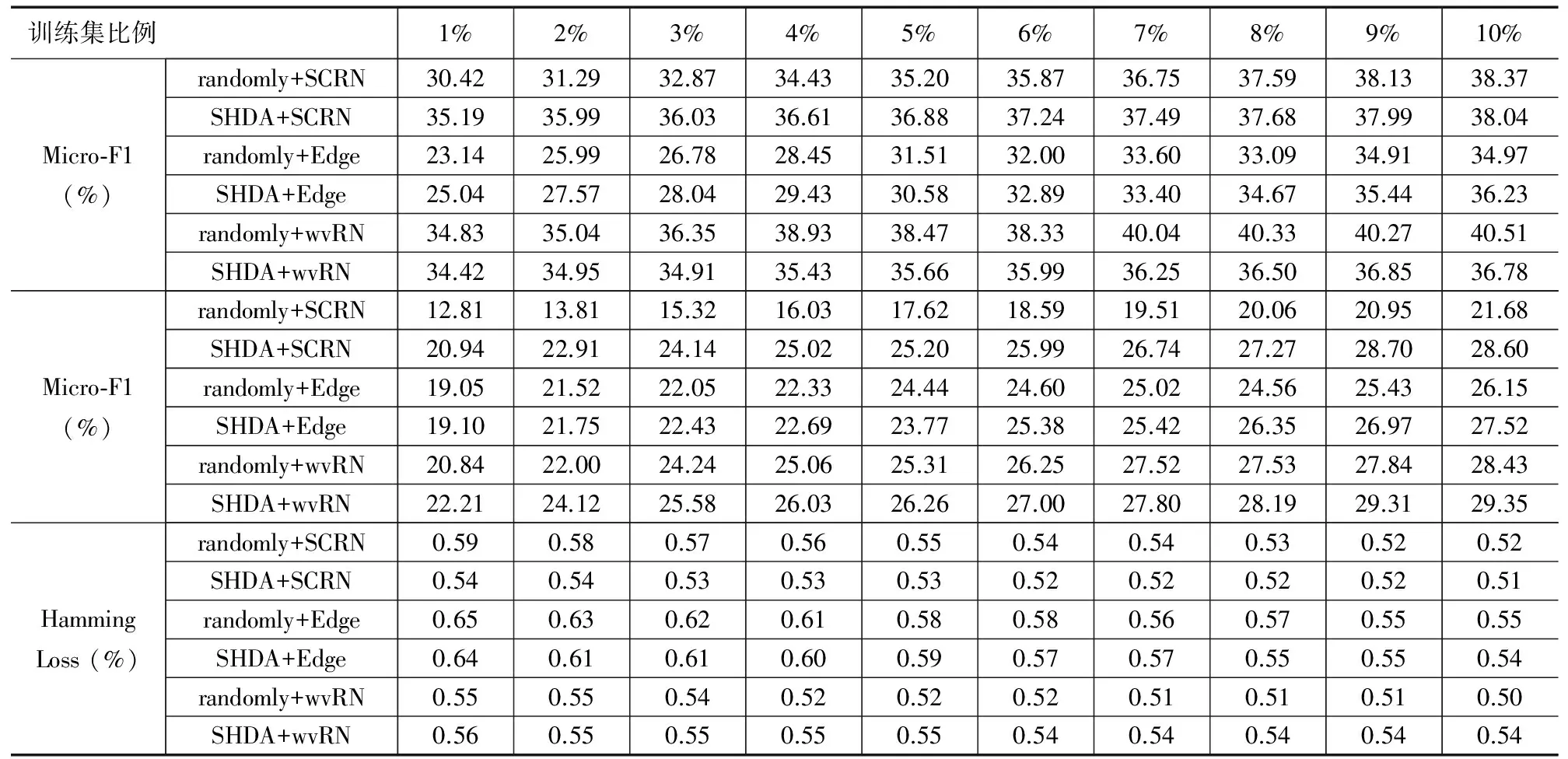
去除重复节点后的种子节点集合大小记为nseed,若nseed>ntr,我们就从种子节点集合中随机选取ntr个节点作为种子节点,若nseed 算法流程总结起来就是:无向图G被划分成多个社团,在每个社团中去除属于测试集的节点,利用式(3)选取前mi个度数较大的节点,然后合并为种子节点集合,最后去除重复节点,调整种子节点集合大小后,得到种子节点. 种子节点的标签是已知的,并且标签分类从这些节点开始,经过不断推理,得到网络中其他节点的标签.选择的种子节点度数都比较高,与其他节点的联系比较紧密,同时种子节点在每个社团上分布的比较均匀,有利于标签传播过程中,更准确的把标签扩散至整个网络,减少分类错误,改善多标签分类的性能. 我们选择了3个真实数据集,DBLP、BlogCatalog 和YouTube进行实验[2,10].关于数据集的详细信息见表1. 我们使用SHDA算法选择的种子节点作为训练集,并分别使用SCRN、wvRN和Edge(EdgeCluster)算法进行网络环境下的多标签分类实验,记为SHDA+SCRN、SHDA+wvRN和SHDA+Edge.在对比算法中,我们随机的从网络中选择节点作为训练集,分类算法也采用SCRN、wvRN和Edge算法,记为randomly+SCRN、randomly+wvRN和randomly+Edge.通过比较SHDA+SCRN/wvRN/Edge和randomly+SCRN/wvRN/Edge方法的分类评估结果,来验证SHDA算法的有效性. 我们将DBLP、BlogCatalog和YouTube数据集的社会特征的维数分别设置为1000、5000和1000[2,10],训练集选择的比例分别设置为5%到30%,10%到60%和1%到10%.我们采用网络交叉验证NCV(Network Cross-Validation)方法[15]来减少测试样本的重叠选取.评估指标选用宏观F1值,微观F1值和汉明损失(Hamming Loss)[10].Micro-F1值和Macro-F1值越大,分类性能越好,Hamming Loss值越小,分类性能越好.实验结果取10次实验的平均值. 表1 数据集描述 5.1 实验结果 实验结果记录在表2~4中,代表randomly+SCRN/wvRN/Edge方法和SHDA+SCRN/wvRN/Edge方法在各个数据集上的多标签分类结果. YouTube数据集上的实验结果记录在表2中,分析数据可知:在Micro-F1指标下,SHDA+SCRN、SHDA+Edge和SHDA+wvRN方法分别比randomly+SCRN、randomly+Edge和randomly+wvRN方法提高了15.63%、3.16%和-6.45%.在Macro-F1指标下,提高了46.78%、2.53%和4.42%.在Hamming Loss指标下,降低了4.26%、1.15%和-4.47%. BlogCatalog数据集上的实验结果记录在表3中,分析结果可得:SHDA算法应用于SCRN、EdgeCluster和wvRN算法分别比随机方法应用于这些算法,提高了9.08%、-0.68%和4.34%的Micro-F1值,提高了14.82%、-0.64%和5.32%的Macro-F1值,降低了2.81%、-0.30%和1.54%的Hamming Loss值. DBLP数据集上的实验结果记录在表4中,由结果可得:SHDA+SCRN、SHDA+Edge和SHDA+wvRN方法分别比randomly+SCRN、randomly+Edge和randomly+wvRN方法,提高了3.18%、5.89%和1.15%的Micro-F1值,提高了3.47%、7.92%和0.94%.的Macro-F1值,降低了3.69%、5.33%和1.18%的Hamming Loss值. 综合所述,大部分情况下,SHDA算法在多标签分类方法上的性能要比随机方法好.某些情况下,SHDA 表2 YouTube数据集上实验结果 算法表现的不如随机方法,可能是因为SHDA算法在最后一步时,从集合G′中随机选取ntr-nseed个节点并入训练集,导致SHDA算法在多标签分类实验中表现的稍微不稳定.但是从整体上来说,SHDA算法由于利用了网络的拓扑结构,有助于提高网络环境下多标签分类的性能. 表3 BlogCatalog数据集上实验结果 表4 DBLP数据集上实验结果 5.2 算法迭代次数分析 SCRN和wvRN算法使用标签松弛法来进行集体推理.在每一次迭代过程中,算法根据上一次的预测结果,逐次更新节点属于各个类的概率,更新类的参考特征,更新类的传播概率,根据更新后的结果预测标签,直至预测出的节点标签趋于稳定或者迭代次数到达最大值,算法终止. 我们在YouTube、BlogCatalog和DBLP三个数据集上分别做了实验来讨论SHDA+SCRN/wvRN 和randomly+SCRN/wvRN方法的实验结果随着迭代次数的变化情况.EdgeCluster算法利用社会特征使用SVM算法进行分类,不在本部分讨论的范围之内.图1~3记录了YouTube、BlogCatalog和DBLP数据集上,训练集分别选择2%、5%和20%时,实验结果随着迭代次数的变化情况. 分析结果发现,SHDA+SCRN/wvRN方法的实验结果在迭代次数大于5的时候基本趋于稳定.而randomly+SCRN/wvRN方法可能导致实验结果在迭代次数等于2的时候达到达最大值,然后随着迭代次数的增加而下降.所以SHDA算法应用于多标签分类时有助于保持算法的稳定性. 5.3 算法运行效率分析 分析SHDA算法可知,该算法的执行时间与社会特征的维数,网络规模以及种子节点数目有关.其中社会特征的维数对SHDA算法的影响最大.而随机方法只与网络的节点数和训练集大小相关.我们在Intel(R)双核2.60GHz,32GB内存的PC机上分别计算了SHDA算法和随机方法应用于多标签分类时,各算法的运行时间,结果记录在表5~8中,单位时间为s. 分析结果可得:SHDA算法在BlogCatalog数据集上耗时最长,其次是YouTube数据集,再次是DBLP数据集.SHDA算法由于利用了网络的拓扑结构,执行的时间没有随机方法快,但是时间是在可以接受的范围内(10s以内). 与随机方法相比,SHDA算法应用于SCRN和wvRN算法时,降低了SCRN和wvRN算法的执行时间.因为种子节点与网络中其他节点的关联性较强,能够加快标签传播和扩散的速度.EdgeCluster算法在使用种子节点后,算法的执行时间增大,因为EdgeCluster算法利用节点的社会特征使用SVM分类器进行分类,种子节点带有的特征比一般节点多,使得算法需要花费更多的时间来分类. SHDA+EdgeCluster方法比randomly+EdgeCluster方法执行的时间长.SHDA+SCRN/wvRN方法在BlogCatalog和You Tube数据集上比randomly+SCRN/wvRN方法执行的时间短,在DBLP数据集上两者执行的时间大致相当.所以SHDA算法能够提升网络环境下多标签分类的性能,还能提升部分多标签分类算法的运行速度. 表5 YouTube数据集上各算法的运行时间 表6 YouTube数据集上各算法的运行时间 表7 BlogCatalog数据集上各算法的运行时间 表8 DBLP数据集上各算法的运行时间 在网络环境下的多标签分类中,给定训练集的节点数目,如果选择的训练集不同,分类精度也会不同.我们提出了SHDA算法,利用网络的拓扑结构来选择种子节点,首先根据网络中每个社团的大小,按比例的选取每个社团中度数较高的节点,然后将这些节点合并,处理后得到种子节点,将种子节点用作训练集进行多标签分类.实验证明,相比于从网络中随机选取节点作为训练集,这种方法不仅有助于提高多标签分类的性能,还能改善部分多标签分类算法的运行速率. SHDA算法是从种子节点选择的方面来提高多标签分类的性能,我们今后的研究方向将从改善多标签分类算法这方面,研究提高多标签分类性能的更有效的方法. [1]Yang S,Jiang Y.Zhou Z.Multi-label learning with weak label[A].Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence[C].Atlanta:AAAI,2010.593-598. [2]Tang L,Liu H.Scalable learning of collective behavior based on sparse social dimensions[A].Proceedings of the 18th ACM Conference on Information and Knowledge Management[C].Hong Kong:ACM,2009.1107-1116. [3]Macskassy S A,Provost F.A simple relational classifier[A].Proceedings of the Multi-relational Data Mining Workshop at the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Washington:ACM,2003.64-76. [4]Lu Q,Getoor L.Link-based classification[A].Proceedings of the Twentieth International Conference on Machine Learning[C].Washington:JMLR,2003.496-503. [5]Neville J,Jensen D.Relational dependency networks[J].Journal of Machine Learning Research,2007,8:653-692. [6]Jensen D,Neville J,Gallagher B.Why collective inference improves relational classification[A].Proceedings of the tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Seattle:ACM,2004.593-598. [7]郑伟,王朝坤,刘璋,王建民.一种基于随机游走模型的多标签分类算法[J].计算机学报,2010,33(8):1418-1426. Zheng Wei,Wang Chao-kun,Liu Zhang,Wang Jian-min.A multi-label classification algorithm based on random walk model[J].Chinese Journal of Computers,2010,33(8):1418-1426.(in Chinese) [8]Ji M,Han J,Danilevsky M.Ranking-based classification of heterogeneous information networks[A].Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].San Diego:ACM,2011.1298-1306. [9]Kong X,Cao B,Yu P S.Multi-label classification by mining label and instances correlations from heterogeneous information networks[A].Proceedings of the 19th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Chicago:ACM,2013.614-622. [10]Wang X,Sukthankar G.Multi-label relational neighbor classification using social context features[A].Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Chicago:ACM,2013.464-472. [11]Zhou Y,Liu L.Activity-edge centric multi-label classification for mining heterogeneous information networks[A].Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].New York:ACM,2014.1276-1285. [12]Qian T,Liu J.Influence maximization through identifying seed nodes from implicit social networks[A].Proceedings of the 4th International Conference on Ubiquitous Information Management and Communication[C].Suwon:ACM,2010.193-196. [13]Jankowski J,Michalski R,Kazienko P.Compensatory seeding in networks with varying availability of nodes[A].Proceedings of the 2013 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining[C].Niagara:ACM,2013.42-1249. [14]Tang L,Liu H.Relational learning via latent social dimensions[A].Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining[C].Paris:ACM,2009.817-825. [15]Neville J,Gallagher B,et al.Correcting evaluation bias of relational classifiers with network cross validation[J].Knowledge and Information Systems,2012,30(1):32-52. 吴信东 男,1963年出生于安徽枞阳,教授,博士生导师,IEEE Fellow,AAAS Fellow,主要研究方向为数据挖掘,大数据分析,基于知识的系统和万维网信息探索. E-mail:xwu@hfut.edu.cn 赵银凤 女,1990年出生于安徽淮北,硕士研究生,主要研究方向为数据挖掘,社交网络. E-mail:zhyinfeng@163.com 李 磊 男,1981年出生于辽宁鞍山,副教授,主要研究社会计算,数据挖掘和信任计算. E-mail:lilei@hfut.edu.cn Multi-label Classification in Network Environments via Seed Node Selection WU Xin-dong1,2,ZHAO Yin-feng1,LI Lei1 (1.SchoolofComputerScienceandInformationEngineering,HefeiUniversityofTechnology,Hefei,Anhui230009,China;2.DepartmentofComputerScience,UniversityofVermont,BurlingtonVT05405,USA) Multi-label classification is widely used in genetic classification,drug discovery and text classification.The existing multi-label classification algorithms usually select nodes randomly from the network as their training set.However,during multi-label classification,different nodes have different effects.Given the number of nodes in the training set,a different training sub-set can lead to different classification accuracy.Hence,we introduce the concept of seed nodes, the classification procedure starts from the seed nodes,and after continuous reasoning,the labels of other nodes are inferred in the network.We propose an SHDA algorithm (Nodes Selection of High Degree from Each Affiliation) in which the nodes of high degrees from each affiliation belonging to the network are selected and merged,and after processing,the seed nodes are obtained.Experiments on several real-world datasets demonstrate that taking seed nodes as the training set to classify multi-labeled data can improve the classification performance. multi-label classification;network;seed nodes 2015-01-30; 2015-05-18;责任编辑:覃怀银 国家重点基础研究发展规划(973计划)项目(No.2013CB329604);教育部创新团队(No.IRT13059);国家自然科学基金项目(No.61229301,No.61503114) TP181;TP391 A 0372-2112 (2016)09-2074-07 ��学报URL:http://www.ejournal.org.cn 10.3969/j.issn.0372-2112.2016.09.0084 实验设计
5 实验结果与分析









6 总结



