基于B+树的电力大数据分布式索引
2016-11-23曲朝阳孙立擎许劭庆蔺树全尹相爱
曲朝阳,孙立擎 ,许劭庆,蔺树全,尹相爱
(1.东北电力大学 信息工程学院,吉林 吉林 132012;2.国网吉林省电力有限公司 信息通信公司,吉林 吉林 132012;3.国网吉林省电力有限公司 吉林供电公司,吉林 吉林 132012)
基于B+树的电力大数据分布式索引
曲朝阳1,孙立擎1,许劭庆2,蔺树全3,尹相爱3
(1.东北电力大学 信息工程学院,吉林 吉林 132012;2.国网吉林省电力有限公司 信息通信公司,吉林 吉林 132012;3.国网吉林省电力有限公司 吉林供电公司,吉林 吉林 132012)
随着电力信息化的发展,电力数据来源广泛,具备体量大、类型多的特点,其中设备监测数据以及业务数据大多是浮点型、字符型数据,具有一定的时序性和结构化的特点。在数据检索时可能是对不同类型数据的联合查询,同时在大规模数据检索时存在查询效率不高,检索结果无法满足跨范围匹配的问题,对此本文设计并实现了一种基于B+树和倒排索引的分布式混合索引结构,引入层次化很合索引的思想,将数据集中的数据属性和属性值划分开来,并实现索引的并行化,提高了数据的索引构建时间和检索速度。
电力大数据,检索,分布式索引
随着电力信息通信与电力生产以及企业经营管理的深度融合,以及物联网和云计算为代表的新一代IT技术在电力行业中的广泛应用,电力行业中数据量呈指数级增长,也使数据来源更加多元化和复杂化[1]。电力大数据不仅反映行业内部规律特征,指导电力生产和企业经营管理,还反映经济社会发展状况,是未来电力发展的重要参考依据。在对海量的信息检索时,准确度、高效性、个性化需求等已成为信息检索的新要求,索引的建立是提高检索系统存储效率和系统检索性能、加快数据查询速度的重要技术手段之一[2],针对大规模数据检索查询效率不高、检索结果无法满足跨范围匹配的问题,本文提出了一种适合电力大数据的分布式索引结构。
1 混合索引构建
1.1 构建思想
针对电力数据的特点,在设计索引结构时对不同数据类型的数据创建不同结构的索引。首先根据电力数据的属性建立第一层索引。其次对上层属性所对应的属性值建立索引,如果是数值类型数据就建立B+树索引,如果是字符型数据就建立倒排索引。这样,不是所有的数据都建立树型索引避免了由结点分裂所引起的时间开销问题,除此之外,也减少了结点分裂的临时结点所占的用额外存储空间。当该索引构建完成后进行数值型数据范围检索时,就会直接由下层的树形索引部分完成,减小检索时间和成本。
B+树由于叶子结点的有序性保证了它对数值型数据检索时具有优势,在进行数据查找时具有稳定的I/O开销,较好的支持索引更新。同时其索引层次能够保持与数据文件大小相适应[3,4];倒排索引对完成数值型数据的范围检索不能提供很好地支持,但索引的实现相对简单、查询速度快,检索可以一次定位,对字符型数据的索引构建提供良好的支持。混合索引结合用并延续了B+树和倒排索引两种结构的优点,同时又避开了这两种结构各自的不足。在达到提高索引创建速度和空间利用率的同时还能满足数值型数据的范围查询需求。
1.2 混合索引结构设计
根据上述索引的构建思想,本文设计的电力大数据索引结构如图1所示:

图1 索引结构
第一层树形索引结构是为要建立索引的数据对象所包含的属性建立的,其中所有的具体属性都存储在非叶子结点中,而B+树的所有叶子结点中存储三部分信息Ai、PType、Pointer,表示的含义分别为:
(1)Ai是索引对象的数据属性,其中n为数据集中所包含的所有属性个数,i∈[1,n];
(2)PType表示指针类型,具体类型有PType { Inverted _ index,B+-tree };
(3)Pointer指针,指向第二层索引,根据属性值的不同数据类型,该指针指向不同的索引结构,即指向倒排表表头或B+树的根结点。
第二层索引是为各个属性值建立的索引,包括为数值型数据建立的B+树索引结构和为字符型数据建立的倒排表索引结构。其中B+树索引结构的非叶子结点只包含具体的数据值,叶子结点都是有序排列的且每个叶子结点中都包含三部分信息ARVS、Loc、Doc,表示的含义分别是:
(1)ARVS为第R个属性的第S个属性值,R∈[1,n2]、S∈[1,p],n2为数据集中包含的数值属性的个数,P为第R个属性的属性值的个数。
(2)Loc为包含此属性值的文件所在的位置信息。
(3)Doc为包含此属性值的文件编号,每个文件编号是唯一的。
倒排索引分为两个部分,一个是由不同的关键词组成的索引表,称为词典,其中保存了各种中文关键字以及这些词汇所对应的统计信息。另一个部分是由每个索引词出现过的文档集合,及其位置信息组成,也称为记录表。第二层的倒排索引结构中具体包含AiVj、Doc、Loc、F四部分信息,表示的含义分别为:
(1)AiVj为第i个属性的第j个属性值,i∈[1,n1]、j∈[1,m],n1为字符属性的个数,m为第i个属性包含的属性值的个数。
(2)Doc为所查询条件的属性值所在的文件编号,每个文件编号唯一。
(3)Loc为包含查询关键词的文件所在的位置信息。
(4)F为查询关键词在文件中出现的频率。
2 索引的并行化实现
随着数据规模的不断扩大,使得对数据的检索查询也越来越复杂,采用集中式处理方法具有检索速度慢、容易出现访问瓶颈、可扩展性不强等多方面的不足[5]。分布式技术以其特有的高性能数据处理特点,正逐渐成为解决这类复杂问题的有效手段。分布式索引在逻辑上是一个统一的整体,在物理上则是分别存储在不同的物理结点机上[6]。如图2所示。
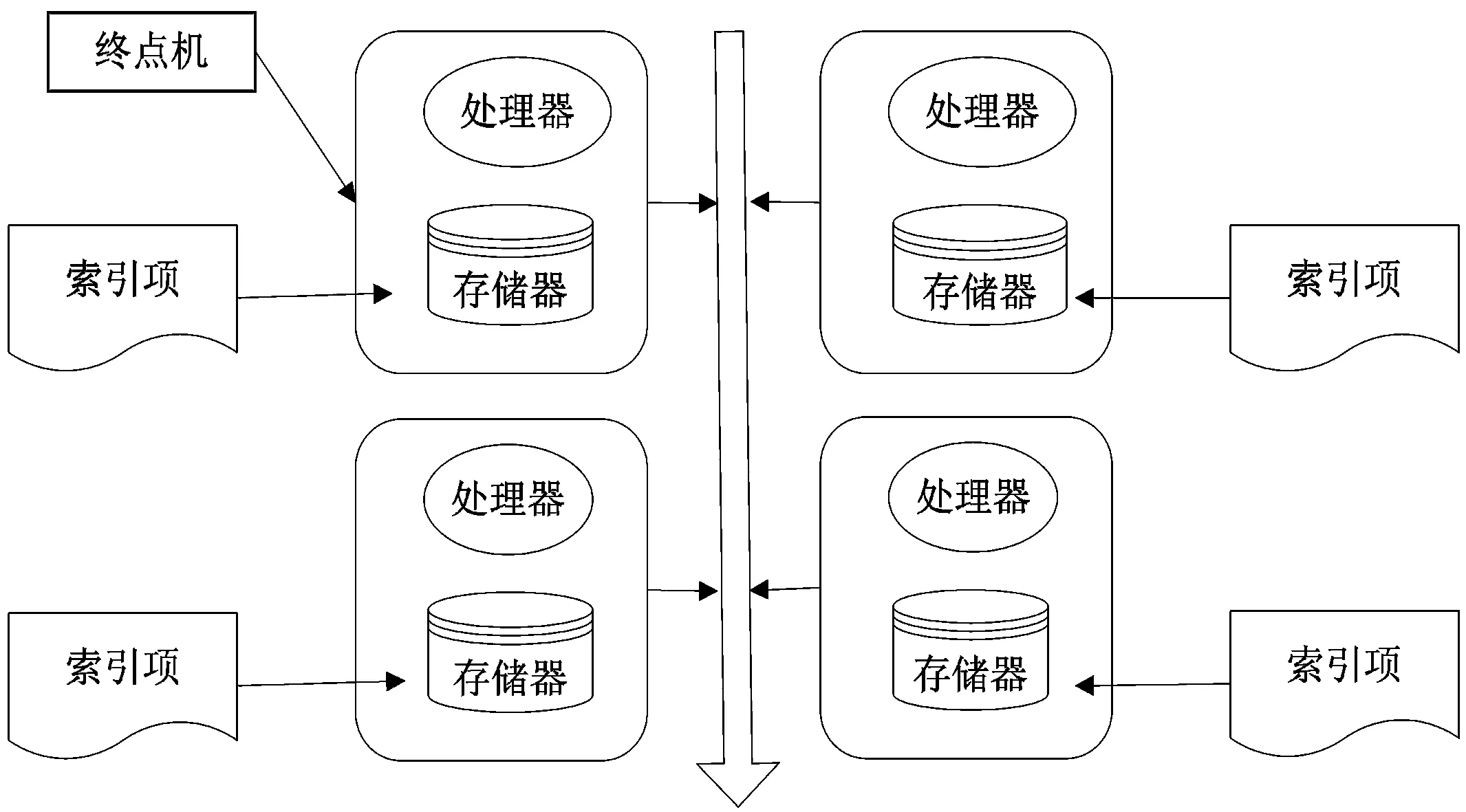
图2 分布式索引物理结构
本文实现索引的并行化的主要思想是将上述混合索引分布式地存储在各个服务器上,且客户端保留所有这些索引节点的副本。在实际存储数据的物理节点上建立本地索引,然后在服务器端建立全局索引。全局索引采用倒排索引结构,将本地索引以关键字的形式存储在全局索引中,当用户查询数据时,通过服务器端的全局索引定位到本地索引,进行数据查询。
利用MapReduce编程模型在Hadoop平台上编程实现分布式索引的构建,一个MapReduce作业一般由Map、Combine和Reduce三个过程构成,这三个过程都以
(1)Map过程。
以不同的文档作为输入数据,通过调用Map函数,把输入的数据按照文档ID自动分割成N片,并以key-value对的形式分发到不同的TaskTracker节点上,使得输入的数据能在多个节点上同时进行处理。具体算法如表1所示:
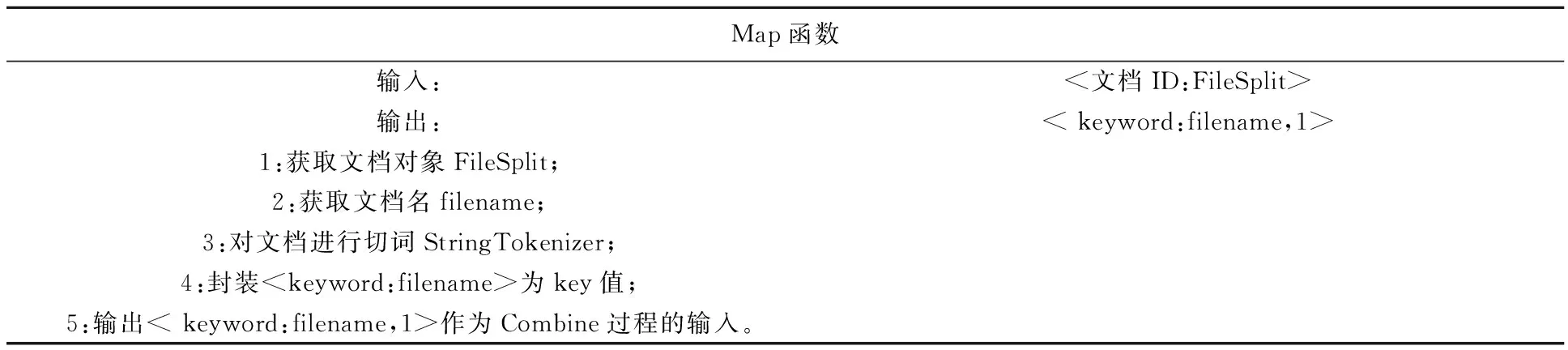
表1 Map过程算法
(2)Combine过程
Combine过程以上述的Map操作所产生的结果作为自己的输入。Combine过程主要将输入的key-value键值对中Key值相同的Value进行累加计算,实现了关键字在各自文档中词频统计的功能。具体算法过程如表2所示:

表2 Combine过程算法
(3)Reduce过程
Reduce过程将所有Combine操作所产生的结果作为自己的输入,然后对输入序列中相同Key值的Value进行字符串处理,使之组合形成索引格式中文档信息部分的内容。
最后,Reduce操作将相同关键字的所有<文档名:词频>值进行连接合并计算,最终形成键值对,其格式为<关键字,文档0:词频;文档1:词频,…>,然后将结果输出为索引文件并存储到HDFS文件系统中。
3 实验分析与验证
3.1 混合索引的有效性验证
索引构建的好坏将直接影响到数据的组织效果和查询效率,本文提出的双层混合索引结构在有效性验证时,分别从索引构建的时间性能和数据的查询效率上进行了比较和分析[9,10]。
(1)时间性能分析与比较
设n1、n2分别为数值型属性个数和每个属性的属性值的平均个数,n3、n4分别为字符型属性的个数以及每个属性包含的属性值的平均个数。则所有的属性值的个数为N=n1×n2+n3×n4。设第一层B+树索引结构的阶为k,第二层B+树索引结构的阶为m[11-12]。此时第一层B+树索引需要进行分裂的结点就有FBdiv个,由公式(1)计算得出:
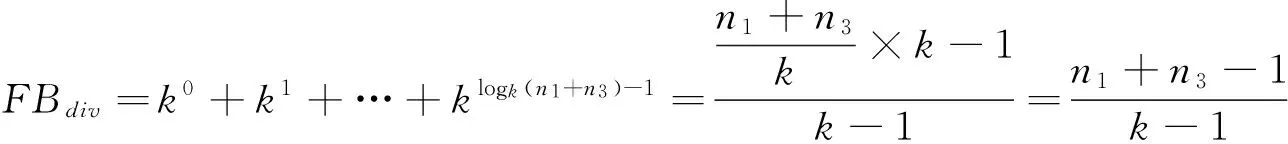
(1)
第二层B+树的高度为logmn2,假设所有非叶子结点都有m个子结点。此时B+树要进行分裂的节点有SBdiv个,由公式(2)计算得出:
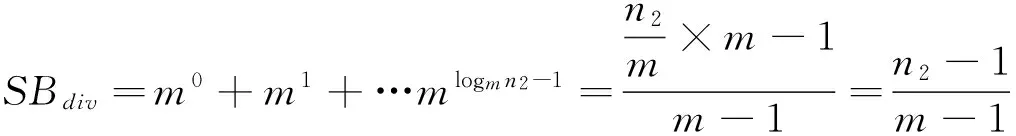
(2)
则所有分裂结点的个数总共有:
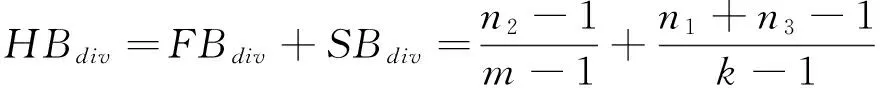
(3)
如果数据集的整个索引都采用传统的B+树结构进行索引[13-14],即为所有的属性值都建立树形索引结构,则分裂节点的总个数为:
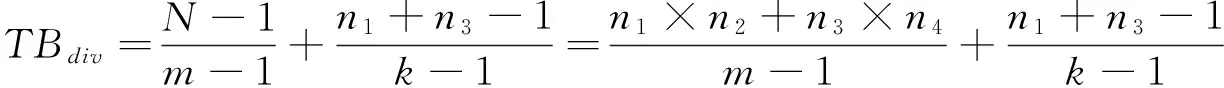
(4)
将公式(3)和公式(4)进行比较可知,本文设计的混合索引结构在索引创建时间上相对单一索引结构而言具有较为明显的优越性。
(2)查询效率分析与比较
如果按检索条件查询返回的结果为数值型属性时[13],在上述混合索引结构中其算法查找的时间复杂度约为:
logkn1+logm(n1×n2) .
(5)
如果查找条件返回的结果为字符型属性时,在上述混合索引结构中其算法查找的时间复杂度约为:
logkn3+logm(n3×n4) .
(6)
那么该混合索引结构的查找时间复杂度介于公式(5)和公式(6)之间。如果采用传统的全部B+树结构索引,无论是查找数值类型属性数据还是字符类型属性的数据,其查找的时间复杂度都约为:
logk(n1+n3)+logm(n1×n2+n3×n4) .
(7)
查找数值属性的数据时将公式(5)和公式(7)进行比较,可以看出B+树索引的查找效率明显低于混合索引结构的查询效率。公式(6)和公式(7)两者的大小与m的取值范围有关。当m=2时,公式(7)的值大于公式(6),即在查找字符型属性数据时本文提出的索引结构查询效率较高。
通过上述在理论上的性能分析与比较,表明本文设计的索引具有更有效的空间利用率和更高的检索性能[14-15]。
3.2 分布式索引实验验证
实验中采用实验室局域网中的四台计算机来模拟分布式计算平台,每台机器的通信带宽为10 Mbps,处理器为Inter(R) Core(TM) i5 CPU,2.40 HZ,内存2.00 GB,硬盘320 GB,每台计算机间通过一台以太网交换机相连。使用其中一台作为NameNode节点,四台均作为DataNode节点参与计算。
在软件方面,在四台计算机中安装Linux操作系统,并且搭建了Hadoop集群环境,采用Java编程环境实现索引方案。实验通过对不同数据量分别在分布式环境和单机环境的检索时间进行比较来验证本索引方案的有效性。实验数据是釆用的是500M数据量以及1.0G数据量的风电数据集和设备状态检修数据集中数据序列进行索引,选择平均风速、平均有功功率、总发电量最大值、平均环境温度、设备检修记录等10个属性,选取的属性中既包含数值型数据也包含字符型数据,随机抽取1000条序列进行数据检索测试,具体的实验结果如表3所示:

表3 实验数据对比分析
上表中的数据量是部分原始数据量,由实验数据可以看出,随着数据量和搜索序列的增加,搜索时间会呈现线性的增长,而且还会因为内存空间的限制而无法操作,表中的“-”表示的是内存限制,无法进行操作的标志。但是分布式模式下在同等数据量的情况下,分布式索引具有明显的优势,在时间和空间上都有较好的表现。
[1] 黄斌,彭宇行,彭小宁.云计算中海量数据高效索引方法[J].计算机应用究,2014,29(10):3075-3077.
[2] 张文燚,项连志,王小芳.支持高效查询检索的大数据资源描述模型[J].哈尔滨工程大学学报,2014,35(5):594-601.
[3] Wang J B,Wu S,Gao H,et al.Indexing Multi-dimensional Data Base on DB-tree in a Cloud System[C].Proceedings of the SIGMOD Conference.Indianapolis,2010:591-602.
[4] 长孙妮妮,张毅坤,华灯鑫,等.一种基于B+树的混合索引结构[J].计算机工程,2012,38(14):35-37,40.
[5] Chen D W,Zhuang J.A Real Time Index Model for Big Data Based on DC-Tree[C].International Conference on Advanced Cloud and Big Data,2013:99-104.
[6] C.Zhang,F.Wang.A multilevel approach for learning from labeled and unlabeled data on graphs[J].Pattern Recognition,2010,43(6):2301-2314.
[7] Wang J,Zhang Y,Gao Y.pLSM:A Highly Efficient LSM-Tree Index Supporting Real-Time BigData Analysis[C].IEEE 37th Annual Computer Software and Applications Conference,2013:240-245.
[8] 丁琳琳,信俊昌,王国仁,等.基于Map-Reduce的海量数据高效Skyline查询处理[J].计算机学报,2011,34(10):1785-1796.
[9] Lin J,Dyer C.Data-Itensive Text Processing with MapReduce[M].California:Morgan and Claypool Publishers,2010:24-25.
[10] Peter M,Barcelona S.Distributed indexing for semantic search[C].In:Proc.of the 3rd Int’l Semantic Search Workshop.New York:ACM,2010:1-4.
[11] 吴炜,苏永红,李瑞轩,等.基于DHT的分布式索引技术研究与实现[J].计算机科学,2010,37(2):65-70.
[12] Hsu YT,Pan YC,Wei LY,Peng WC,Lee WC.Key formulation schemes for spatial index in cloud data managements[C].In:Proc.of the 13th IEEE Conf.on Mobile Data Management.Washington:IEEE Computer Society,2012:21-26.
[13] Diana M,Denis S,Gylfi G,Laurent A.Indexing and searching 100M images with map-reduce[C].In:Proc.of the 3rd ACM Conf.on Int’l Conf.on Multimedia Retrieval.New York:ACM,2013:17-24.
[14] 曲朝阳,张率,刘洪涛.基于用电影响因素回归的小区用电预测模型[J].东北电力大学学报,2015,35(1):73-77.
[15] 郭晓利,朝啸.电网知识协同发现策略研究[J].东北电力大学学报,2014,34(1):94-96.
Power Big Data Distributed Index Based on B+ Tree And Inverted Index
QU Zhao-yang1,SUN Li-qing1,XU Shao-qing2,LIN Shu-quan3,YIN Xiang-ai3
(1.College of Information Engineering,Northeast Dianli University,Jilin Jilin 132012;2.Information and communication company in Jilin Electric Power Corporation Limited,Jilin Jilin 132012;3.State Grid Jilin Electric Power Co.,Ltd.Jilin power supply company,Jilin Jilin 132012)
With the development of electric power information technology,electric power data comes from a variety of sources,and have the characteristics of large volume and a lot of types,equipment monitoring data and business data mostly floating-point type,character type,has the characteristics of sequential and structured.In the data retrieval,it is possible to combine the different types of data,the query efficiency is not high According to the characteristics of electric power data,this paper proposes a distributed hybrid index structure based on inverted index and B+-Tree,introducing the idea of hierarchical indexing,the data stream contains attributes and attribute values separated to improve the retrieval speed.
Power big data;Search;Distributed index
2016-04-12
曲朝阳(1964-),男,吉林省吉林市人,东北电力大学信息工程学院教授,博士,主要研究方向:电力信息化、计算机网络技术.
1005-2992(2016)05-0080-06
TP29
A
