开源软件漏洞补丁的采集与整理
2016-11-21邹雅毅
邹雅毅,李 珍
(1.华中科技大学附属中学高二(1)班,湖北 武汉 430074; 2.华中科技大学计算机学院,湖北 武汉 430074)
开源软件漏洞补丁的采集与整理
邹雅毅1,李 珍2
(1.华中科技大学附属中学高二(1)班,湖北 武汉 430074; 2.华中科技大学计算机学院,湖北 武汉 430074)
针对美国国家漏洞数据库(National Vulnerability Database, NVD)中开源软件的漏洞,设计并实现了漏洞补丁采集与分析系统。该系统能自动采集漏洞补丁文件,生成漏洞补丁库。基于漏洞补丁数据,提取补丁特征并进行分类整理,为不同类型漏洞提供有效的漏洞检测方法等研究提供了数据和分析基础。
软件漏洞;补丁;漏洞库
在高度信息化的今天,人们享受着信息化带来便利的同时,也无时无刻不遭受着各种安全问题的威胁。由软件引发的信息安全事件层出不穷,如“维基泄密”事件、“棱镜门”事件等。“千里之堤,溃于蚁穴”,软件安全漏洞是绝大多数信息安全事件的根源,及时发现并修补软件漏洞是急需解决的重要问题。
开源软件的漏洞补丁,不仅能够在发现软件漏洞后提供相应的补救措施,而且作为分析漏洞位置及漏洞原理的关键数据,为进行有效的软件漏洞检测起到重要的指导作用。因此,如何自动地采集大量的漏洞补丁数据,构建漏洞补丁数据库,并对漏洞补丁特征进行分析研究,具有重要的理论价值和实践意义。
1 相关研究
由于漏洞库关系到国家安全,目前世界各国都十分重视漏洞库的建设,国外的漏洞库有美国国家漏洞数据库(National Vulnerability Database, NVD)[1]、开源漏洞库(Open Sourced Vulnerability Database, OSVDB)[2]等,国内的漏洞库有国家信息安全漏洞共享平台(China National Vulnerability Database, CNVD)[3]、中国国家信息安全漏洞库(China National Vulnerability Database of Information Security, CNNVD)[4]等。以NVD为例,采用唯一的通用漏洞与披露标识符(Common Vulnerability Exposures Identifier, CVE-ID)标识漏洞,为漏洞信息的共享提供了很大的帮助,是一个目前国际上权威和比较全面的漏洞库。目前的漏洞库主要提供漏洞的基本信息以及与该漏洞相关的参考链接,没有关于漏洞补丁的规范数据,无法直接得到与CVE-ID对应的补丁文件。本文在NVD的基础上,针对开源软件的漏洞,自动采集漏洞补丁文件,生成漏洞补丁库。基于漏洞补丁数据,提取补丁特征,进行基于补丁特征的分析,为不同类型漏洞提供更有效的漏洞检测方法等研究提供了数据和分析基础。
2 系统的设计
软件漏洞补丁采集与分析系统的总体结构如图1所示。将NVD中开源软件漏洞CVE-IDs的漏洞信息作为系统的输入,通过漏洞补丁的采集来生成漏洞补丁库,基于补丁数据来提取补丁特征,进行基于补丁特征的分析,输出分析结果。下面分别对漏洞补丁的采集和补丁分析两个主要模块进行介绍。
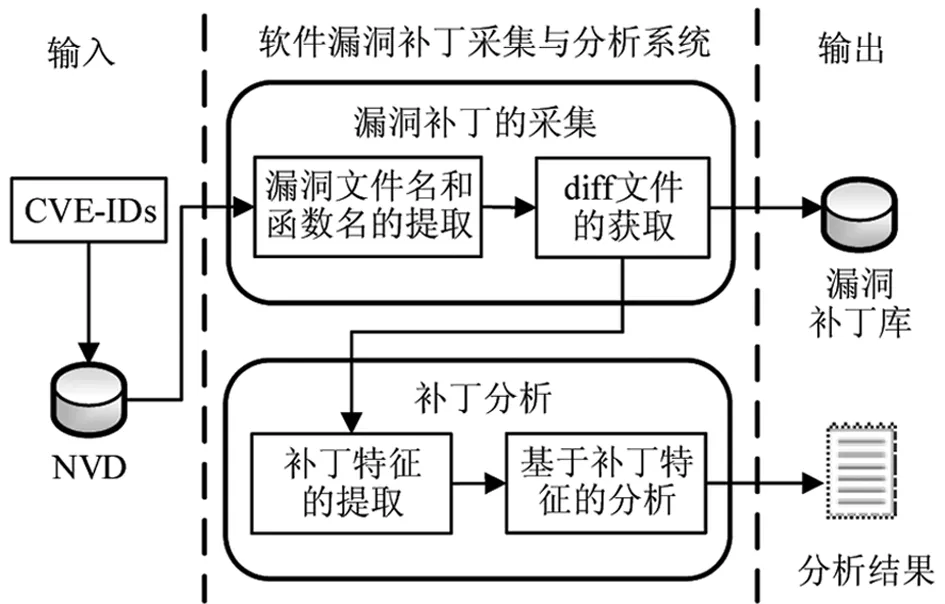
图1 系统总体结构

图2 CVE-2015-0823的diff文件
2.1 漏洞补丁的采集
开源软件的补丁通常以diff文件的形式提供,一个diff文件可能由多个以“@@”开头的diff段组成,每个diff段内代码连续,diff段间代码不连续。图2是漏洞CVE-2015-0823的diff文件中一个diff段。从diff段中提取“-”号前缀行和无前缀行,可以得到漏洞代码段;从diff段中提取“+”号前缀行和无前缀行,可以得到修补后代码段。
(1)漏洞文件名和函数名的提取
NVD中没有专门的数据项用来存储漏洞文件名或者函数名,它们存在于每个CVE-ID的“Overview”中,可通过分析漏洞描述的方式来提取。CVE-ID的“Overview”中给出了详细的漏洞描述信息,主要包括以下几部分内容:漏洞软件名及含漏洞的版本区间、漏洞所在的文件名和函数名(开源软件)、漏洞产生的主要原理、攻击成功后造成的影响等。
由于文件名有扩展名作为后缀,除了非标准的版本标识可能含有“.c”、“.h”等外,漏洞描述的其他部分一般不会出现类似扩展名的内容。对于非标准版本标识的情况,在字符串匹配的时候通过匹配〈指定文件扩展名〉〈空格〉的方式来避免,因为文件名后缀的下一个字符必定是空格,而作为版本标识的“.c”、“.h”等基本不可能出现在空格前面。因此,通过确定要收集的文件扩展名,并且在漏洞描述中匹配〈文件扩展名〉〈空格〉,找到所有满足条件的单词,即可得到漏洞描述中所有的文件名。
通过对NVD中CVE-ID的“Overview”进行统计分析发现,98%的函数名后面有“function in”这个关键词。这是因为函数名作为细粒度的漏洞定位信息,后面通常会有更粗粒度的定位信息,如文件名、构件等。其中,大于96.5%的函数名后面紧跟“function in”这个关键词,小于3.5%的“function in”前面不是具体的函数名,而是函数的功能描述。因此,我们提取“function in”前面的单词作为函数名,误报在可接受范围内。
(2)diff文件的获取
在NVD中寻找开源软件含有补丁链接的CVE-ID,从补丁链接所在页面提取diff,从而构建CVE-ID到diff的映射。由于NVD中每个CVE-ID有多个参考链接,因此需要识别出正确的补丁链接。很多软件通常有它自己的补丁提交或发布系统,例如Linux kernel的http://git.kernel.org,Firefox的https://bugzilla.mozilla.org等。对于相同软件的漏洞,它们的补丁链接具有很强的规律性。对这些软件,依据这些规则自动识别每个CVE-ID的补丁链接。然而,对于一个漏洞,满足规则的补丁链接也可能存在多个,这些补丁链接可能正是针对该CVE-ID的,也可能仅仅是与该CVE-ID有关。因此,需要判断补丁链接对应Web页中的diff是否是针对该CVE-ID的。采用两个启发式方法来实现自动化:
•对于CVE-ID的“Overview”中提到的漏洞文件名和函数名,如果包含在diff中,则认为这个diff是针对该CVE-ID的。依据是:大多数情况下,漏洞文件和函数正是需要修补的文件和函数。如果该CVE-ID不涉及函数的话,比如只与全局变量或宏定义有关,则只关注漏洞文件。
•如果补丁链接对应的Web页面中,如标题或提交的消息,提到了该CVE-ID,则认为这个diff是针对该CVE-ID的。
为了检测启发式方法的准确性,我们随机选取10%的样本,人工检查结果,发现没有错误的diff文件。对于无法通过上述启发式方法获取diff的CVE-ID,例如CVE-ID的“Overview”中提到的漏洞文件名和函数名与实际修补的文件名和函数名不一致,或者对于Web页中的diff,只能通过分析漏洞原理来确定是否是针对该CVE-ID的,目前无法实现自动化,可以通过人工分析获取。
获取diff文件后,将CVE-ID到diff文件的映射关系输出到漏洞补丁库。同时,获取的diff文件作为补丁分析模块的输入,进行后面补丁特征的提取。
2.2 补丁整理
定义如下5类补丁特征来描述漏洞代码段和修补后代码段的区别,如表1所示。第1类:非实质性修改特征,包括空格、格式或注释等对有效代码没有影响的代码变化;第2类:元素级特征,包括修改变量名、修改常量、修改变量类型、修改函数名等;第3类:表达式级特征,包括修改赋值表达式、if条件、for条件等;第4类:语句级特征,包括行的增加、删除、移动等;第5类:函数级特征,包括整个函数的增加、删除以及函数外的修改(如宏定义、全局变量等)。
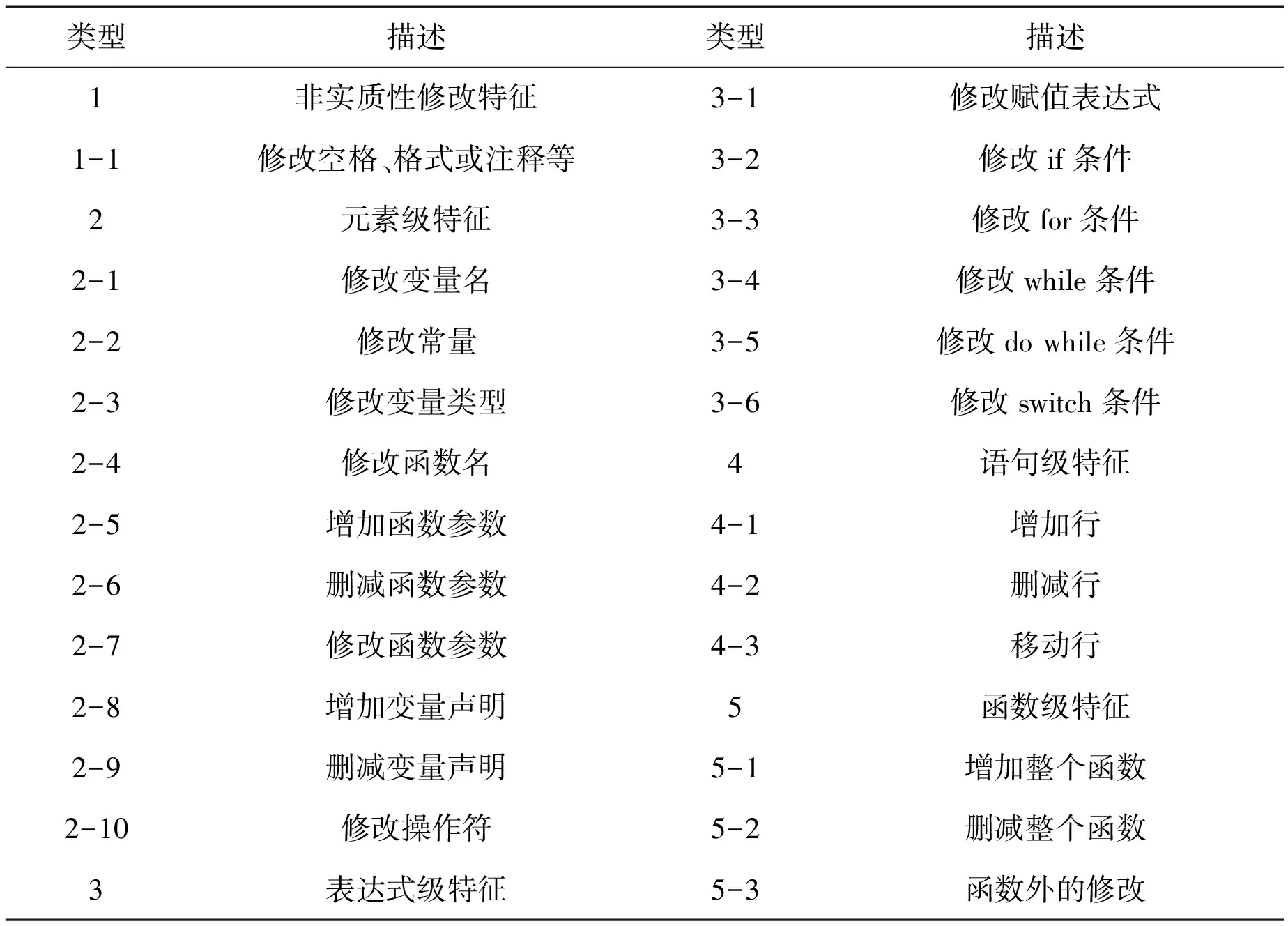
表1 补丁特征类型
将漏洞补丁库中的diff文件拆分成diff段,针对每个diff段提取补丁特征。其中,第1类和第5类补丁特征可直接分析diff段提取,第2, 3, 4类补丁特征通过将漏洞代码段和修补后代码段进行补全结构等预处理后,借助gumtree工具[5]来生成。
3 系统的实现
系统实现采用的Python语言,使用Python中的CElementTree模块解析XML文件,从公开发布的NVD漏洞库[1]构建NVD的副本。针对NVD中3个开源软件即Linux kernel, Ffmpeg, Wireshark的漏洞进行了diff文件的采集,涉及807个漏洞的1274个diff段。借助gumtree工具[5]实现第2, 3, 4类补丁特征的提取,对diff段的补丁特征进行了统计分析,其分布如图2所示。可以看出,较多diff段含有1-1, 2-7, 3-1, 3-2, 4-1,4-2, 4-3类补丁特征,而很少diff段含有2-8, 2-9, 2-10, 3-4, 3-5, 3-6类补丁特征。而且,23%的diff段具有单一的补丁特征,含有单一补丁特征较多的类型有4-1,3-2和3-1类。对于具有单一补丁特征的diff段,该补丁特征可能直接影响漏洞检测算法的有效性,而具有多个补丁特征的diff段,则需要考虑多个补丁特征的关联及相互影响。
系统以ReDebug[6]漏洞检测算法为例,通过增加分类标签,来分析补丁特征与漏洞检测有效性的联系。由漏洞补丁库得到的每个diff段对应的补丁特征作为一个样本,使用ReDebug在由diff得到的修补后代码段中检测是否含有漏洞,若在修补后代码段中检测出漏洞,则产生误报,将样本的分类标签置为0;否则将分类标签置为1。对于带有分类标签的样本,70%作为训练集,30%作为测试集,分析哪些补丁特征对ReDebug的检测结果有影响。结果显示1-1类补丁特征对ReDebug的检测结果分类起主要作用。这是因为ReDebug对diff中漏洞代码段以行为单位作为漏洞特征,除了空格、格式或注释等修改外,均不会造成上述误报。
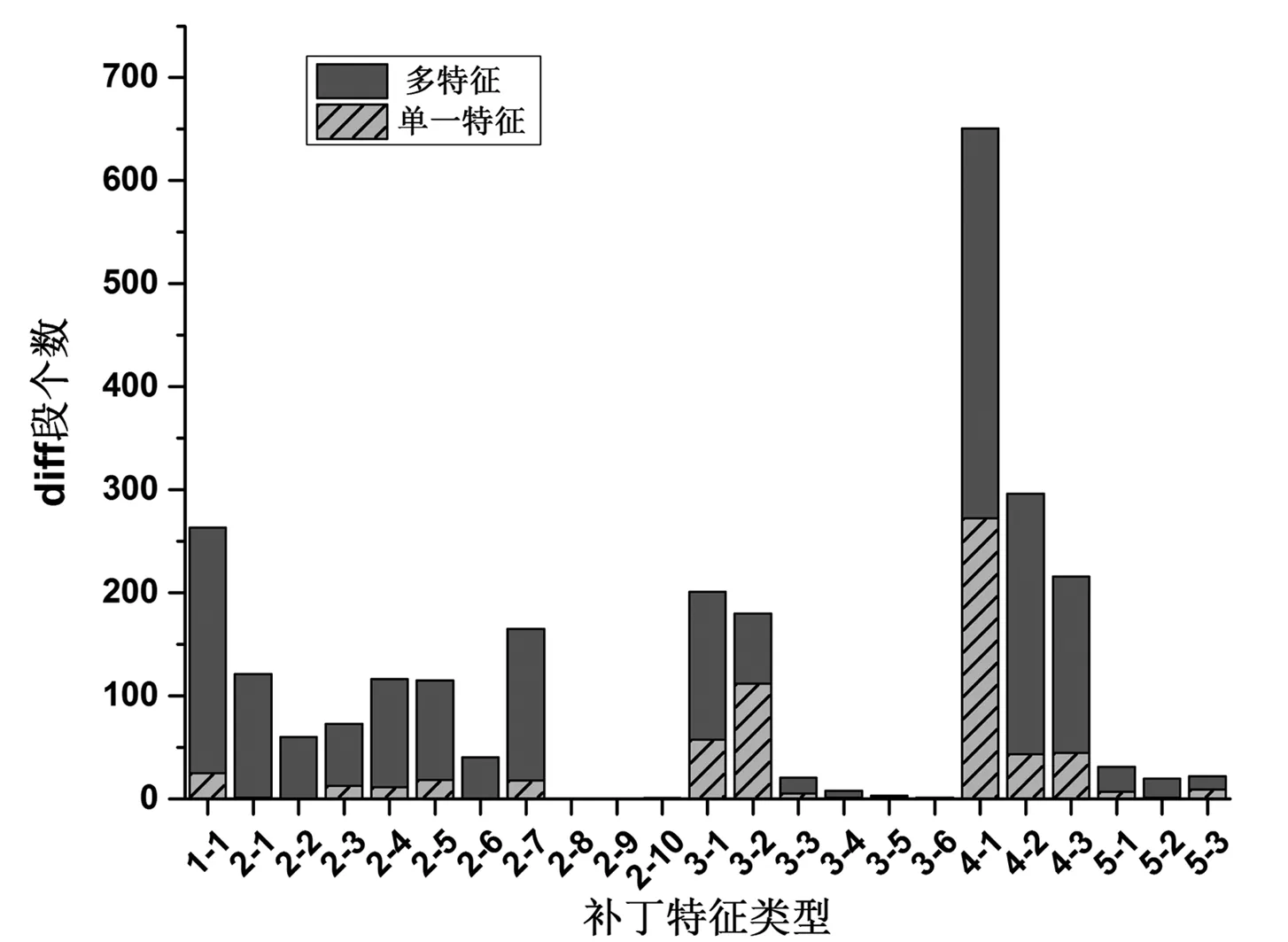
图3 补丁特征类型的分布
4 结束语
本系统基于目前国际上权威的美国国家漏洞库NVD,自动采集漏洞补丁数据,形成漏洞补丁库。在此基础上提取补丁特征并进行分类整理,为以后软件漏洞分析等后续研究提供了数据和分析基础。
[1] 美国国家漏洞数据库[EB/OL].https://nvd.nist.gov/.
[2] 开源漏洞库[EB/OL].http://www.osvdb.org/
[3] 国家信息安全漏洞共享平台[EB/OL].http://www.cnvd.org.cn/
[4] 中国国家信息安全漏洞库[EB/OL].http://www.cnnvd.org.cn/
[5] J.R.Falleri, F.Morandat, X.Blanc, M.Martinez, and M.Montperrus.Fine-grained and accurate source code differencing[C].In Proceedings of the 29th ACM/IEEE international conference on Automated software engineering, ACM, 2014: 313-324.
[6] J.Jang, A.Agrawal, and D.Brumley.ReDeBug:Finding unpatched code clones in entire OS distributions[C].In Proceedings of the 35th IEEE Symposium on Security and Privacy, IEEE, 2012: 48-62.
Open source software vulnerability patch collection and management
ZOU Ya-yi1, LI Zhen2
(1.Class1Senior2,HighSchoolAttachedtoHuazhongUniversityofScienceandTechnology,WuhanHubei430074,China;2.SchoolofComputerScienceandTechnology,HuazhongUniversityofScienceandTechnology,WuhanHubei430074,China)
This paper presents a software vulnerability patch collection and analysis system for vulnerabilities of open source software in the National Vulnerability Database (NVD).The system collects vulnerability patches automatically and generates the vulnerability patch database.It extracts the patch features from the vulnerability patches and then classifies and orders them.The system can provide the data and analysis basis for the study of effective vulnerability detection approaches for different types of vulnerabilities.
Software vulnerability; Patch; Vulnerability database
2016-08-20
邹雅毅(2000-),女,湖北武汉人,爱好钻研软件漏洞和黑客攻防知识.
1001-9383(2016)03-0018-05
TP393.08
A
