基于关联规则挖掘的分布式小文件存储方法
2016-11-21钱能武郭卫斌范贵生
钱能武, 郭卫斌, 范贵生
(华东理工大学信息科学与工程学院,上海 200237)
基于关联规则挖掘的分布式小文件存储方法
钱能武, 郭卫斌, 范贵生
(华东理工大学信息科学与工程学院,上海 200237)
Hadoop分布式文件系统(HDFS)设计之初是针对大文件的处理,但无法高效地针对小文件进行存储,因此提出了一种基于关联规则挖掘的高效的小文件存储方法——ARMFS。ARMFS通过对Hadoop系统的审计日志进行关联规则挖掘,获得小文件间的关联性,通过文件合并算法将小文件合并存储至HDFS;在请求HDFS文件时,根据关联规则挖掘得到的高频访问表和预取机制表提出预取算法来进一步提高文件访问效率。实验结果表明,ARMFS方法明显提高了NameNode的内存使用效率,对于小文件的下载速度和访问效率的改善十分有效。
HDFS; 关联规则挖掘; 小文件关联性; 预取
Hadoop分布式文件系统(HDFS)是一种Master/Slave主从式结构,一个HDFS系统由一个NameNode节点和若干个DataNode节点组成。其中文件的元数据(MeteData)信息存放在系统NameNode节点的内存中,这样就导致了文件的存储规模受到内存大小的限制。例如,对于每1个文件HDFS存储的MeteData信息大约150 Byte,此时若有约107份大小为1 M的小文件存储至HDFS中,则将产生约1.4 G的元数据[1]。大量的小文件对于内存的消耗极大,同时大量的元数据对于数据的读取也会产生影响,从而影响整个系统的效率。
现实环境中,人们存取小文件的概率极大,如Office文档、音乐文件、PDF文件等,其中绝大数的文件均小于5 MB。Dong等[2]通过实验证明了小文件在小于4.35 MB这个阈值时将明显降低HDFS的文件存储效率,所以,有效地解决HDFS中小文件存储问题具有非常重要的实际意义。
针对Hadoop系统中小文件存储问题,本文提出了一种基于关联规则挖掘的高效的小文件存储方法——ARMFS(Association Rule Mining File System)。通过对Hadoop系统的审计日志进行关联规则挖掘,获得小文件间的关联性;通过小文件的关联性,文件合并算法将小文件合并压缩存储至HDFS;在关联规则挖掘的过程中,得到高频访问表和预取机制表,在访问HDFS文件时,基于高频访问表和预取机制表提出预取算法将文件预取至缓存中,从而有效地提高文件的访问效率。
1 相关研究
1.1 小文件解决方案
目前,解决Hadoop小文件存储的方法主要有3类:HAR小文件归档技术、Sequence file序列化二进制文件技术和自定义的CombineFile文件合并技术[3]。
HAR小文件归档技术是一个将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,减少NameNode内存使用。HAR文件一旦创建便不可改变,且存档文件不支持压缩,有很大的局限性。
Sequence file由一系列的二进制key/value组成,如果key为小文件名,value为文件内容,则可以将大批小文件合并成一个大文件。因为无大文件到小文件的索引,所以每次访问需要遍历整个Sequence大文件,访问效率低下。
CombineFile可以自定义文件输入格式,将多个文件合并成一个块,但是它本身是一个抽象类,使用该方法需要自己进行实现。
1.2 关联规则挖掘
实际应用中,如果某一用户访问一个包含多个小文件(如图片、文本、音频等)的网页,则属于该网页的所有小文件都将被访问。这些属于同一网页的小文件具有较强的关联性,如果将该类强关联性的小文件合并在一起进行存储,既能提高存储效率也能提高访问效率。
关联规则挖掘正是查找数据间“亲密度”的一种数据挖掘算法。通过对审计日志的挖掘,挖掘出具有较强关联性的小文件,再将具有较强关联性的小文件进行合并存储。关联规则算法是一种十分经典的数据挖掘算法,其中Apriori算法是一种最具影响力的挖掘关联规则的算法[4]。挖掘过程分为两步:一是查找频繁项集,二是产生强关联规则。
目前,对于Apriori算法的研究已经十分深入,无论是算法本身的优化,还是并行化实现[5-7]。本文提出的方法是在Hadoop分布式平台下,基于Mao等[8]提出的一种高效的并行Apriori算法——AprioriPMP。
2 ARMFS架构
ARMFS包含3个模块:审计日志挖掘模块、小文件合并模块和小文件预取模块,如图1所示。

图1 ARMFS架构Fig.1 Architecture of ARMFS
(1) 审计日志挖掘模块。首先是针对 Hadoop审计日志进行预处理后生成审计事务集,通过审计事务集挖掘小文件间的关联性,得到合并集合表、高频访问表和预取机制表。
(2) 小文件合并模块。通过得到的合并集合表,将具有强关联性的小文件进行合并存储至HDFS。
(3) 小文件预取模块。在初始读取文件时,通过高频访问表将高频访问文件放入缓存。文件读取过程中,使用预取机制表中的信息,将可能会访问的文件信息放入缓存中。
3 审计日志的关联规则挖掘
3.1 审计日志的预处理
很多情况下各个小文件间是有关联性的,例如,一个网页页面包含图片A和图片B两个图片文件,则在访问该网页时,图片A、B都将被访问到。如果图片A、B存储在HDFS中,则很难发现A和B之间的关联性,但是可以通过对文件历史访问记录来得到文件间的关联性。而寻找其中的关联性需使用Apriori算法。
Hadoop中对于访问文件的请求均记录在NameNode的审计日志中,Hadoop的默认审计日志是处于关闭状态的,可以通过log4j.properties修改audit=INFO即可打开审计日志功能,这样就可以实现记录文件系统所有文件访问请求的功能[9]。审计日志示例如表1所示。
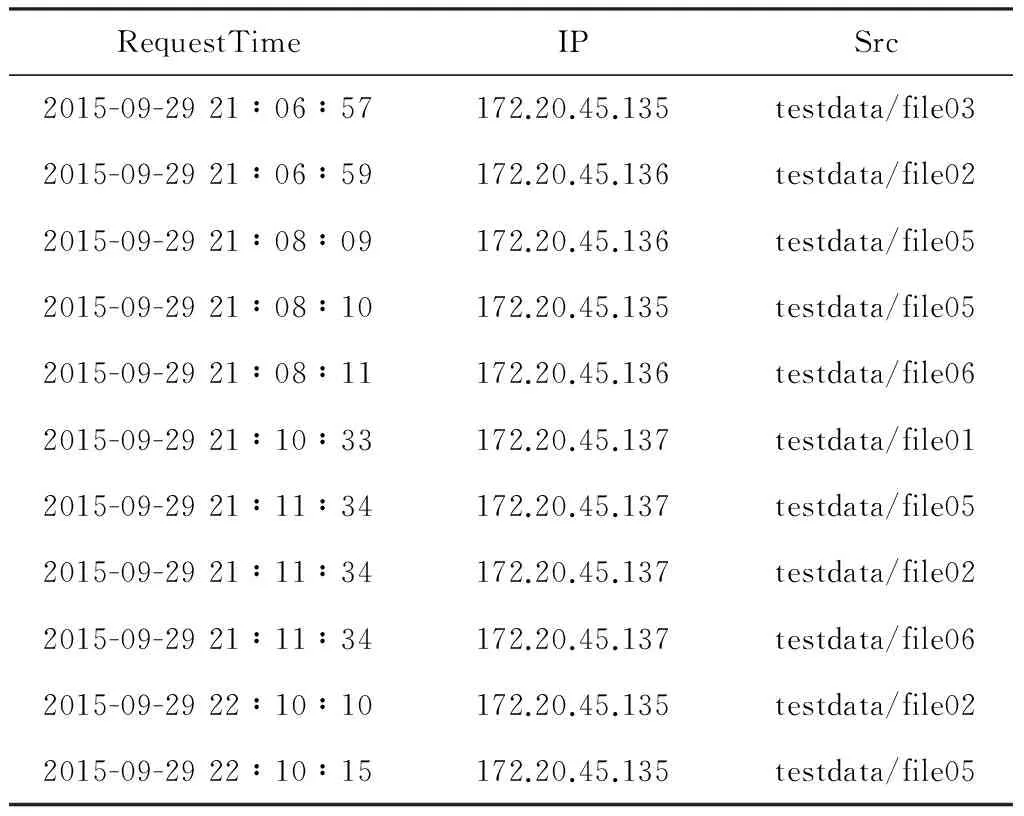
表1 审计日志示例Table 1 Examples of audit logs
参考关联规则挖掘在Web日志中的应用,将得到的访问日志进行预处理,根据不同的用户即IP的访问记录分别生成一条对应的访问事务,同时设置一个时间间隔阈值timeout[10]。Catledge等[11]通过实验验证了timeout设置为25.5 min时会得到较好的性能效果,一般将timeout设置为30 min。同一个IP访问超过timeout的话则重新生成一条记录。其算法描述如算法1所示。
算法1 审计日志预处理
输入:logs
输出:T{T1,T2,T3,…}
(1) Preprocess(logs){ //预处理
(2) for log in logs{
(3) if(log.ip is new){ ∥新用户判定
(4) newTi;
(5)Ti.add(log.file);
(6) }
(7) else if(prelog.time-log.time (8)Ti.add(log.file); (9) else{ //超过timeout的生成新事务 (10) newTi; (11)Ti.add(log.file); (12) } (13) } (14)T={T1,T2,T3,…}; (15) returnT; (16) } 针对表1中的示例,可得到审计事务集,如表2所示。 表2 审计事务集Table 2 Audit transaction set 3.2 基于关联规则的审计日志挖掘算法 对预处理后得到的审计事务集进行关联规则挖掘,本文使用了AprioriPMR并行关联规则算法,运行在Hadoop平台上,只需扫描2次数据库即可得到频繁项集。通过对关联规则挖掘的结果进行处理得到自己想要的结果,结果分为3个部分:合并集合表、高频访问表和预取机制表。 合并集合表(Merge file table,merge_table)是用于记录合并在一起存储的文件名的记录表,其中每一条记录对应一个合并文件集。对挖掘出的频繁项集进行筛选,其筛选过程如下:首先取频繁k-项集(k>K/2,K表示最大频繁k-项集的项集数),先按项集k的大小进行排序;其次是在排序过程中删除重复,即前面已经出现过的项集再次出现时则删除该项集。筛选后的频繁项集作为合并项集放入到合并集合表中。同时因为频繁k-项集的k>K/2,所以得到的合并项集文件个数适中,不会出现文件数较少而进行合并的情况。例如:频繁2-项集,只有2个文件合并,从而影响合并效率。 高频访问表(Frequent access table,fre_table)是用于记录审计日志中被访问次数最多的文件。其主要是针对得到的频繁1-项集按支持度进行排序,取出前N项作为高频访问表。 预取机制表(Prefetch table,pre_table)是记录强关联规则的表。从大于置信度的强关联规则中,选择由单个项集作为前提条件的,如f1=>{f3,f4}形式,而非{f1,f2}=>{f3,f4},认为某个用户访问了f1后必然会访问f3和f4。对于筛选后的强关联规则由置信度大小进行排序,最终将这些规则放入预取机制表中。基于关联规则的审计日志挖掘算法描述如算法2所示。 算法2 审计日志挖掘算法 输入:T{T1,T2,T3,…},mini_sup,mini_conf,N 输出:merge_table,fre_table,pre_table (1) Logs_Mining(){ (2) AprioriPMP(T,mini_sup,mini_conf); (3) get(Lk,Rk);∥得到频繁项集和强关联规则 (4)L1=Sort(L1,sup_num); (5) fre_table=get(L1,N); (6)K=max(Lk.itemNum) (7) forLinLk{ (8) if(L.itemNum>K/2) (9) merge_table.add(L); (10) } (11) SortByItemsNum(merge_table); ∥按频繁集的项集个数进行排序 (12) Distinct(merge_table); ∥去重操作 (13) pre_table=Rk; (14) return fre_table,merge_table,pre_table; (15) } 应用以上算法对表2中审计事务集进行挖掘,其中mini_su设置为2,mini_conf设置为60%,可得到merge_table、fre_table和pre_table,如表3~5所示。 表3 合并集合表Table 3 merge_table 表4 高频访问表Table 4 fre_table 表5 预取机制表Table 5 pre_table 3.3 小文件合并算法 通过审计日志的挖掘得到合并集合表用于小文件的合并存储。通过对审计日志的关联规则的挖掘得到了合并项集表,可以知道合并项集中的文件具有很强的“亲密度”,就可以将合并项集表中的对应小文件进行合并存储。 在小文件合并算法中,将merge_table作为输入参数,通过遍历 merge_table中的每一条记录,将记录中的小文件打包在一起进行合并存储。如果一条记录合并后空间没有达到64 M,则继续向该块中添加下一条merge_table记录中小文件,其中merge_table一条记录中的小文件作为一个整体,如果添加进去没有超过64 M,并且该添加记录中小文件都不进行合并存储,而是进行下一次合并存储操作,以此保证每条merge_table记录中小文件的整体性。其算法描述见算法3。 算法3 小文件合并算法 输入:files,merge_table 输出:HDFS blocks (1) merge_Files (){ (2) while(merge_table){∥遍历merge_table (3) if(file in merge_table) (4) if(mergeFiles.Size<64 M) (5) mergeFiles.add(file); (6) blocks=merge(mergeFiles); (7) store blocks in HDFS; (8) } (9) } 可以发现该合并算法可以并行化操作,通过MapReduce并行编程实现小文件合并算法[12]。Map算法是将单个小文件输入,每个合并小文件属于merge_table的一条记录中,对应一条记录中的小文件用merge_key进行标记。则Map的输出是< merge_key,file_context >。小文件合并的Map算法描述见算法4。 算法4 小文件合并Map算法 输入:files,merge_table 输出: (1) merge_Map(){ (2) while(merge_table){ (3) for file in merge_table{ (4) write(merge_key,file_context) (5) } (6) } (7) } Reduce操作就是将Map任务的输出结果 算法5 小文件合并Reduce算法 输入: 输出:HDFS mergeFile (1) merge_Reduce (){ (2) for key1 in merge_keyList{ (3) mergeFiles.add(file_context); (4) for file_context>List{ (5) if(key1 == key2 ) (6) if(mergeFiles<64 M) (7) mergeFiles.add(file_context); (8) mergeFile(mergeFiles); (9) store mergeFile in HDFS; (10) } (11) } (12) } 4.1 小文件预取算法 定义1 触发文件(TriggerFile):当访问到该文件时,系统会预取与其相关联的文件到缓存当中。本文指fre_table中强关联规则左边的文件。如f1=>{f3,f4},则f1就是触发文件。 定义2 关联文件(RelatedFiles):和触发文件相关联的文件,当触发文件被访问,其将会被预取到缓存中的文件。本文指fre_table中强关联规则右边的文件。如f1=>{f3,f4},则{f3,f4}就是关联文件。 TriggerFile和RelatedFiles是成对出现的,如f1=>{f3,f4}这个强关联规则,f1是{f3,f4}的触发文件,而{f3,f4}是f1的关联文件。 本文提出的小文件预取算法包括两个步骤:第1步是在文件读取开始阶段,将fre_table中高频访问文件放入缓存中;第2步是在文件的读取进行阶段,当TriggerFile被访问了,则通过缓存置换算法ARP与TriggerFile相对应的RelatedFiles置换到缓存中。其算法描述见算法6。 算法6 小文件预取算法 输入:fre_table,pre_able 输出:pre_files (1) prefetch(){ (2) if(first_vist) ∥是否是首次进行读取操作 (3) cache.set(fre_table); (4) else{ (5) if(TriggerFile){ //触发文件预取操作 (6) cache.ARP (RelatedFiles); (7) } (8) } (9) } 4.2 缓存置换算法 缓存资源是有一定限度的,并不能无限地将要预取的文件放入缓存中,这就需要一种缓存置换策略,将利用率较低的文件置换出缓存。 常见的置换算法主要有两种:最近最少使用(LRU)和最近频繁使用(LFU)算法[13-14]。LRU存在局部性限制,LFU存在缓存污染等弊端。因此,本文提出了一个基于关联规则的全新缓存替换算法(Association Rules Prefetching,ARP)。 ARP针对被访问的TriggerFile,添加一个参数rencentTime用于记录最近访问时间。每次访问了TriggerFile就需要将其关联的RelatedFiles调入缓存中,如果缓存已满则需要置换缓存中的“无用数据”。算法分为两步:首先查找当前时间和rencentTime的差值,超过阈值T的置换出缓存;其次是比较TriggerFile在pre_table中的置信度大小,置信度小的话说明访问的可能性低,将其置换出内存。如果没有找到可以置换的文件则不做预取操作。算法描述见算法7。 算法7 缓存置换算法 输入:TriggerFile,RelatedFiles,pre_table 输出:cache file (1) ARP(TriggerFile,RelatedFiles,pre_table){ (2) if(cache.available | | TriggerFile.exit){ (3) RelatedFiles.recenttime=now; (4) cache.put(RelatedFiles); (5) else{ (6) for(trigFile in cache){ (7) if(now-recentTime>T) //时间差 (8) exchange(trigFile.RelatedFiles); (9) cache.add(RelatedFiles); (10) if(trigFile.conf< TriggerFile.conf) //置信度比较 (11) exchange(trigFile.RelatedFiles); (12) cache.add(RelatedFiles); (13) } (14)} 5.1 实验软硬件环境 实验使用两台Win Server 08服务器,共搭建了4个节点,1个Master节点和3个Slave节点。Master节点位于其中1台服务器上,其CPU为Intel(R) Xeon E5620,内存16 GB,主频2.40 GHz;3个Slave节点位于另外1台服务器,其CPU为Intel(R) Xeon E5620,内存16 GB,主频2.40 GHz。 使用在虚拟机中搭建的Ubuntu系统作为节点。实验使用的虚拟机是VMware Workstation 9.0,操作系统是Ubuntu desktop 12.10,Hadoop的版本是Hadoop 1.0.4,JDK 版本为1.6,OpenSSH版本6.0。 实验选取了5种不同格式的小文件,平均大小约为1 MB,通过预处理得到2 000、4 000、6 000、8 000、10 000份测试文件,分别将测试数据上传至HDFS。对于ARMFS算法,通过随机模拟访问生成约106条的审计日志记录,分别针对2 000、4 000、6 000、8 000、10 000份测试文件进行数据测试实验。 5.2 支持度大小的选取 选择支持度大小时,尽量以能得到好的合并项集为目标,这样就能更好地实现小文件间的合并。如果得到的合并项集中大多数合并集的个数为60个左右,即合并文件的大小为60 MB左右,就很接近一个数据块的大小(64 MB),合并效果及合并效率将更高。 实验中发现,支持度的大小与文件的平均访问次数有很大的关系,如:106条记录对于2 000个文件,平均访问次数是500次,而对于10 000个文件则是100次,支持度定位在平均访问次数的10%较为合理。接下来的实验中,支持度的大小都是按照此规则制定,而置信度大小都取为60%。 5.3 内存使用对比测试 分别对2 000、4 000、6 000、8 000、10 000份小文件随机产生了约100万条审计日志,在HDFS、HAR和ARMFS环境下进行实验。HAR和ARMFS需要进行小文件合并存储的操作,实验中记录在3种环境下文件对于NameNode主内存的消耗情况,其结果如图2所示。 图2 HDFS、HAR和ARMFS内存使用对比Fig.2 Memory use of HDFS,HAR and ARMFS 通过实验数据计算,HDFS、HAR和ARMFS的平均文件占内存大小为0.016、0.002 1、0.001 5 MB。从图2也可以看出,HDFS内存消耗较大,HAR技术能有效改善内存使用率,而ARMFS在数据量不断上升时,相对于HAR进一步优化了内存使用,说明ARMFS针对海量的小文件具有更强的适应性。 5.4 文件下载速度对比测试 对小文件合并存储后,分别对2 000、4 000、6 000、8 000、10 000份小文件进行访问下载实验,根据审计日志的内容获取2 000、4 000、6 000、8 000、10 000份小文件到本地中。文件下载时间如图3所示。 图3 HDFS和ARMFS下载时间对比Fig.3 Download time of HDFS and ARMFS 通过实验数据计算,HDFS和ARMFS的平均下载时间为0.038 s和0.016 s。从图3中也可以直观地看出,ARMFS相对于HDFS在下载效率上有很大的提升,速度提升了约57.9%,说明ARMFS能很好地预取文件,提升文件的下载效率。 5.5 缓存置换算法对比测试 ARMFS方法提出了一个全新的缓存置换算法ARP,将其与传统的LRU和LFU算法进行对比测试。同样在实验中根据审计日志的内容去获取2 000、4 000、6 000、8 000、10 000份小文件到本地中,实验结果如图4所示。 图4 LRU、LFU和ARMFS下载时间对比Fig.4 Download time of LRU,LFU and ARMFS 通过实验数据计算,LRU、LFU和ARMFS的平均文件下载速度为0.025 、0.023 、0.016 s。从图4可以看出,使用LRU和LFU基本没有差别,但ARMFS相对于LRU和LFU具有一定的效率提升,说明缓存置换算法ARP在缓存置换中有一定优势,能提高缓存命中率。 本文提出了一种基于关联规则的分布式小文件存储方法ARMFS,有效地解决了HDFS中存在的小文件存储问题。该方法使用关联规则挖掘算法挖掘小文件的审计日志,从而发现小文件间的关联性,在小文件合并过程中关联性强的小文件进行合并存储在一起。同时,ARMFS也提出了新的缓存置换算法ARP。实验表明,ARMFS能够显著减少NameNode的内存消耗,有效地提高了小文件的下载速度和访问效率。该方法也存在不足之处,如在缓存置换算法中,未考虑文件访问次数和文件大小等因素,接下来,将对此进行改进,进一步提高文件的访问效率。 [1] KONSTANTIN S,HAIRAING K,SANYJY R,etal.The Hadoop distributed file system[C]//Proceedings of the 2010 IEEE 26th Symposium on Mass Storage Systems and Technologies(MSST).USA:IEEE,2010:1-10. [2] DONG Bo,QIU Jie,ZHENG Qinghua,etal.A novel approach to improving the efficiency of storing and accessing samll fileson Hadoop:A case study by PowerPoint files[C]//IEEE International Conference on Services Computing.Miami:IEEE,2010:65-72. [3] LIU Xuhui,HAN Jizhong,ZHONG Yunqin,etal.Implementing WebGIS on Hadoop:A case study of improving small file I/O performance on HDFS[C]//∥IEEE International Conference on Cluster Computing and WorkShops.Piscataway:IEEE,2009:1-8. [4] TAN P N,MICHAEL S,VIPIN K.数据挖掘导论[M].北京:人民邮电出版社,2013:201-240. [5] AOUAD L M,LE-KHAC N A,KECHADI T M.Performance study of distributed apriori-like frequent itemsets mining[J].Knowledge and Information Systems,2010,23(1):55-72. [6] TAO Limin,HUANG Linpeng.Cherry:Analgorithm for mining frequent closed itemsets without subset checking[J].Journal of Software,2008,19(2):379-388. [7] SHANKAR S,PURUSOTHAMAN T.Utility sentient frequent mining and association rule mining:A literature survey and comparative study[J].International Journal of Soft Computing Applications,2009,4:81-95. [8] MAO Weijun,GUO Weibin.An improved association rules mining algorithm based on power set and Hadoop[C]// 2013 International Conference on Information Science and Cloud Computing Companion(ISCC-C).Guangzhou:IEEE,2013:236-241. [9] 陆嘉恒.Hadoop实战[M].北京:机械工业出版社,2014:196-197. [10] ZHU T S.Web usage mining for Internet recommendation[D].Canada:University of Alberta Edmonton,2001. [11] CATLEDGE L D,PITKOW J E.Characterizing browsing stratagies in the word-wide Web[J].Computer Networks and ISDN Systems,1995,27(6):1065-1073. [12] 黄宜华,苗凯翔.深入理解大数据[M].北京:中国电影出版社,2014:91-122. [13] TANTER E,FIGUEROA I,TABAREAU N.Execution levels for aspect-oriented programming:Design,semantics,implementations and applications[J].Science of Computer Programming,2014,80(2):311-342. [14] 鲍东星,李晓明.一种基于LRU的高速缓存方案研究[J].计算机工程学报,2007,33(9):272-274. Approach of Distributed Small File Storage Based on Association Rule Mining QIAN Neng-wu, GUO Wei-bin, FAN Gui-sheng (School of Information Science and Engineering,East China University of Science and Technology,Shanghai 200237,China) Hadoop distributed file system (HDFS) is previously designed for large file processing,but it is not effective for small file storage.This paper proposes an efficient method of distributed small file storage by means of association rule mining and named ARMFS.By analyzing the audit logs to obtain the association of small files,these small files are merged and compressed to HDFS via file merge algorithm.When requesting HDFS file,the prefetching algorithm is further proposed to improve the access efficiency according to the high frequency access table and prefetching table that is based on association rules.The experiment results show that the ARMFS method can significantly improve the memory efficiency on NameNode and the access efficiency of the small file on HDFS. HDFS; association rule mining; the association of small files; prefetching 1006-3080(2016)05-0708-07 10.14135/j.cnki.1006-3080.2016.05.019 2015-11-18 国家自然科学基金(61300041,61272198) 钱能武(1990-),男,安徽芜湖人,硕士生,研究方向为分布式文件存储。 E-mail:1173618916@qq.com 郭卫斌,E-mail:gweibin@ecust.edu.cn TP316.4 A



4 小文件的预取与缓存
5 数值实验
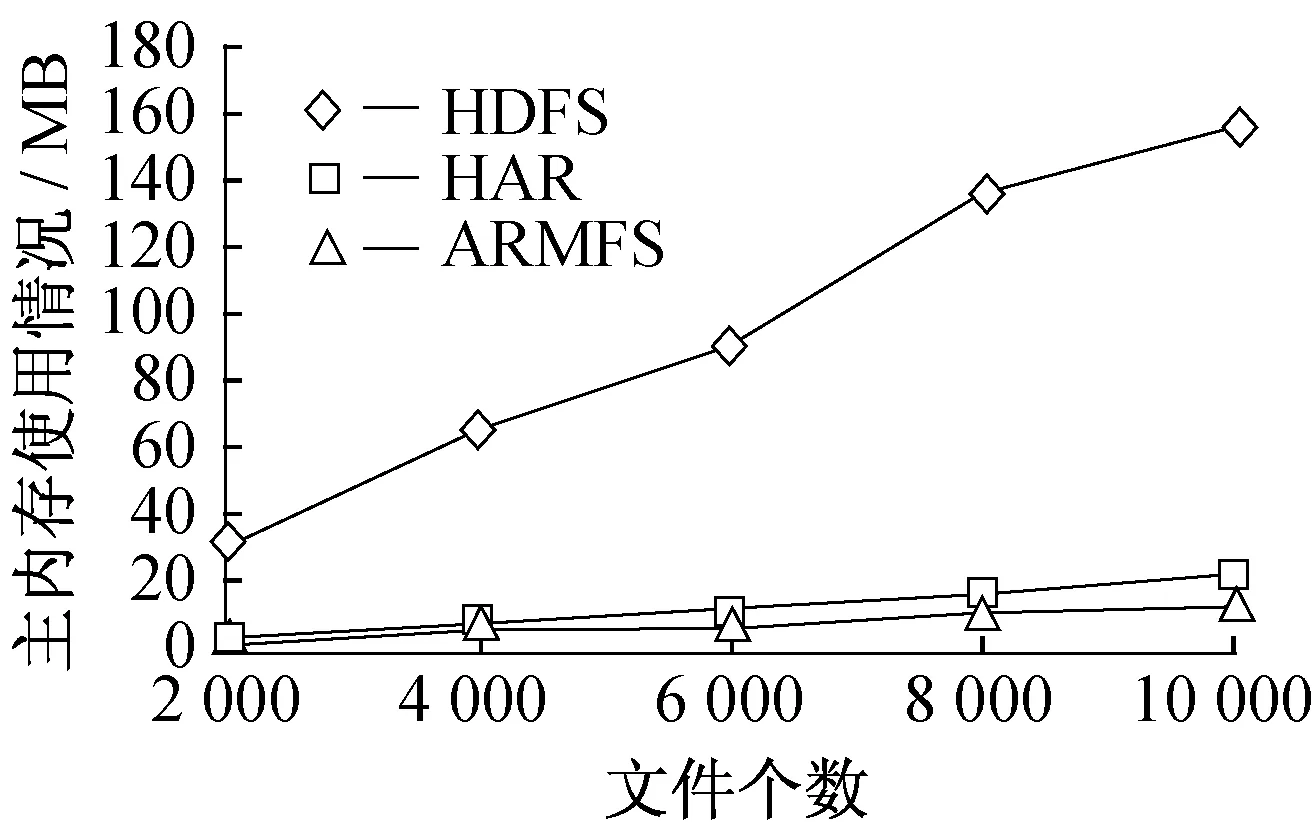
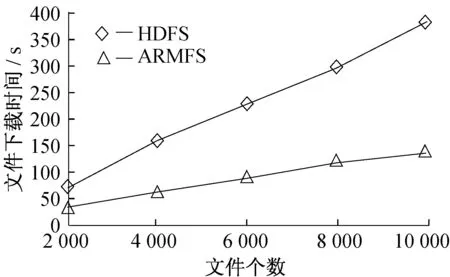
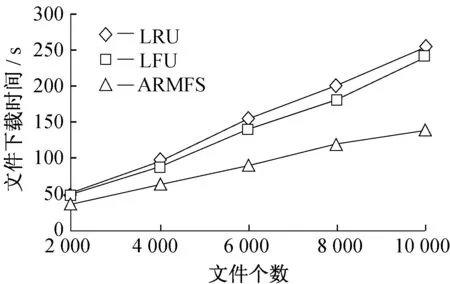
6 结束语
