基于即时学习的集成神经网络及其干点预测
2016-11-21吴朔枫颜学峰
吴朔枫, 颜学峰
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
基于即时学习的集成神经网络及其干点预测
吴朔枫, 颜学峰
(华东理工大学化工过程先进控制和优化技术教育部重点实验室,上海 200237)
针对单个神经网络泛化能力差、对不同样本预测精度波动大的问题,提出了一种基于即时学习集成神经网络方法。首先,基于训练样本,建立多个不同的神经网络模型。其次,根据即时学习的思想,在对样本进行预测时,在训练样本中寻找与预测样本最接近的若干邻近样本,根据各网络对邻近样本的训练误差,即时形成各神经网络的集成权重,实时构造集成神经网络模型,对预测样本进行预测。最后,将该方法应用于初顶石脑油干点的预测,相比于文献中提出的方法,得到了更好的预测结果。
神经网络; 即时学习; 集成; 干点
通常,化工过程输入输出变量较多,内部关系复杂,难以建立可靠的机理模型,往往根据已知的输入输出样本数据建立其所蕴含的复杂关系的模型。神经网络模型能够描述这类多输入多输出的非线性过程,在化工过程建模中广泛使用。但单一神经网络模型存在最优模型结构难以确定、泛化能力差、对不同样本预测波动性大、模型稳定性不足等缺点。
集成神经网络模型是由多个相似或相同目的建立的神经网络子模型组成的预测模型,其能有效提高模型的泛化能力和鲁棒性。文献[1]提出了一种基于多神经网络的水质预测模型,通过聚类将输入空间划分为局部空间,在每个子空间上建立子模型,然后用主元递归解决子模型之间的相关性问题,进而提高了模型的精度和鲁棒性;文献[2]提出了一种基于多神经网络的预测控制方法,采用广义信息熵融合各个子模型,提高了模型的准确性和可靠性;文献[3]提出了一种多神经网络建立动态软测量模型的方法,在二元精馏塔的塔底产品成分估计上取得了较好的效果;文献[4]采用RBF网络和Elman网络分别建立了稳压器的预测模型和诊断模型,然后用模糊逻辑对结果进行融合。
即时学习是一种寻找与当前数据最相似的历史数据来进行建模的方法。文献[5]提出了一种改进的即时模型辨识方法,然后与自校正极点配置算法相结合,设计出了一种多模型自适应控制器,对非线性系统的动态特性实现了较好的逼近,使系统的动态响应品质得到了改善。文献[6]将即时学习算法应用于非线性系统的迭代控制中,运用即时学习算法有效地估计了初始控制量,减小了初始输出误差,加快了算法收敛速度,使得经过有限次迭代的系统输出能准确地跟踪理想信号。文献[7]将即时学习算法应用在软测量建模上,提出了一种矢量近邻方法,提高了即时学习算法的预测能力,然后与最小二乘算法相结合,实现了较好的预测效果。
本文将即时学习和集成神经网络方法相结合,通过即时学习策略确定与预测样本相近的邻近样本,然后分析各子模型对邻近样本的预测能力,实现加权集成,并应用在初顶石脑油干点的预测上,取得了较好的效果。
1 基于即时学习的集成神经网络方法
1.1 概述
设一个多输入单输出的非线性系统,其中输入为x∈Rd,输出为y∈R,采集的样本数据集为{(xj,yj)}j=1,2,…,N(N代表样本数据总量)。假定输入输出之间存在一种未知的非线性映射关系y=f(x),通过集成神经网络建模,基于样本数据集,建立描述输入输出的非线性关系模型。
1.2 集成神经网络模型中单个神经网络模型的建立
采用包含输入层、隐含层、输出层的3层前馈神经网络,其中输入层和输出层的神经元个数由被建模对象的输入输出变量个数决定,隐单元数量则决定了网络的表达能力。较少的隐单元数无法拟合复杂的非线性关系,较多的隐单元数会出现过拟合现象。本文选用不同隐单元数的神经网络作为各个子模型,建立n个神经网络子模型,其中每个神经网络子模型都采用历史数据集{(xj,yj)}j=1,2,…,N进行训练。
1.3 数据选择方法
根据即时学习思想,从采集的大量历史数据中,选择出与当前工作状态最相近或最相似的历史数据,根据各个子模型在这些最相似历史数据上的训练误差,确定每个子模型预测输出在最终输出中所占的比重。影响数据选择效果的因素如下:
(1)数据选择条件。即评价历史数据与当前数据靠近程度的测算方法。因为只有采用一个较为合理的测算准则,才能选取出与当前数据最为相关的历史数据,进而获得较好的局部预测模型。
(2)所选数据的多少。如果数据较多,就会无法反映系统的局部特性;如果数据较少,就会无法得到一个较好的预测模型。
本文采用如下方法作为相近程度的评价准则[7]:
假设两个向量xp,xq,其中xp表示历史数据集中的一个输入向量,xq表示当前采集到的用来预测系统输出的输入向量;两个向量的欧氏距离d与夹角θ定义为
(1)
(2)
(1) 当cos[θ(xp,xq)]<0时,认为两个向量偏离较大,在子模型训练时,抛弃这个历史数据。
(2) 当cos[θ(xp,xq)]>0时,采用式(3)作为两个向量的靠近程度,其中0≤λ≤1。
(3)
(3) 定义一个阈值0≤ζ≤1,如果J(xp,xq)>ζ,将其作为需要考虑的邻近样本,否则就抛弃它,最后得到k个邻近样本。
1.4 网络集成步骤
(1) 使用历史数据集{(xj,yj)}j=1,2,…,N中的所有数据对1.2节中构造的n个不同隐单元数的神经网络进行训练。
(2) 对于测试集中的一个输入向量xq,采用1.3节中的计算方法选择出k个邻近样本。计算n个子模型在这k个邻近样本上各自的平均训练误差ei,然后构造1×n维的权值向量w,其中wi=1/ei,i∈[1,n]。
(3) 计算n个子模型对输入数据xq的预测结果,得到1×n 维的输出向量y。
(4) 计算最终的预测结果。
(4)
2 初顶石脑油干点预测模型
2.1 概述
图1示出了初馏塔的工艺流程,为了确保精馏效果以及提高塔内的处理量,控制气液相的负荷,初馏塔设置了一个顶回流、两个循环回流(First pump-around和 Second pump-around)。采用初顶石脑油干点的工业数据作为本文的样本数据。在实际石化工业过程中,有非常多的环境因素共同决定着初顶石脑油的干点。
2.2 模型数据
采集的样本一共包含了275组数据。每组数据由10个输入量和1个输出量组成,10个输入量主要描述的是精馏塔的状态量,输出量是初顶石脑油干点,如表1所示。
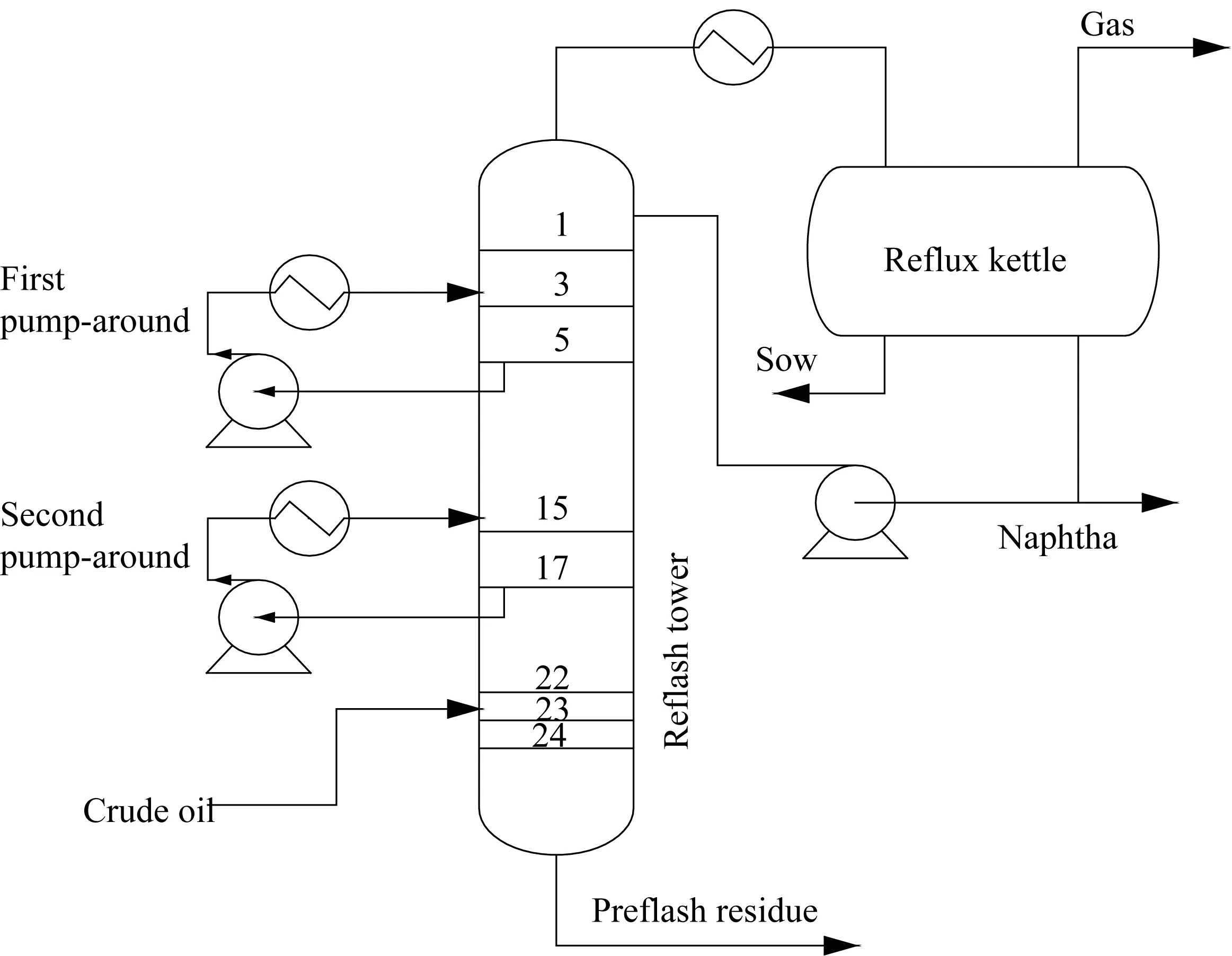
图1 初馏塔流程图Fig.1 Flow chart of primary distillation tower表1 模型输入量和输出量Table 1 Input and output variables of model
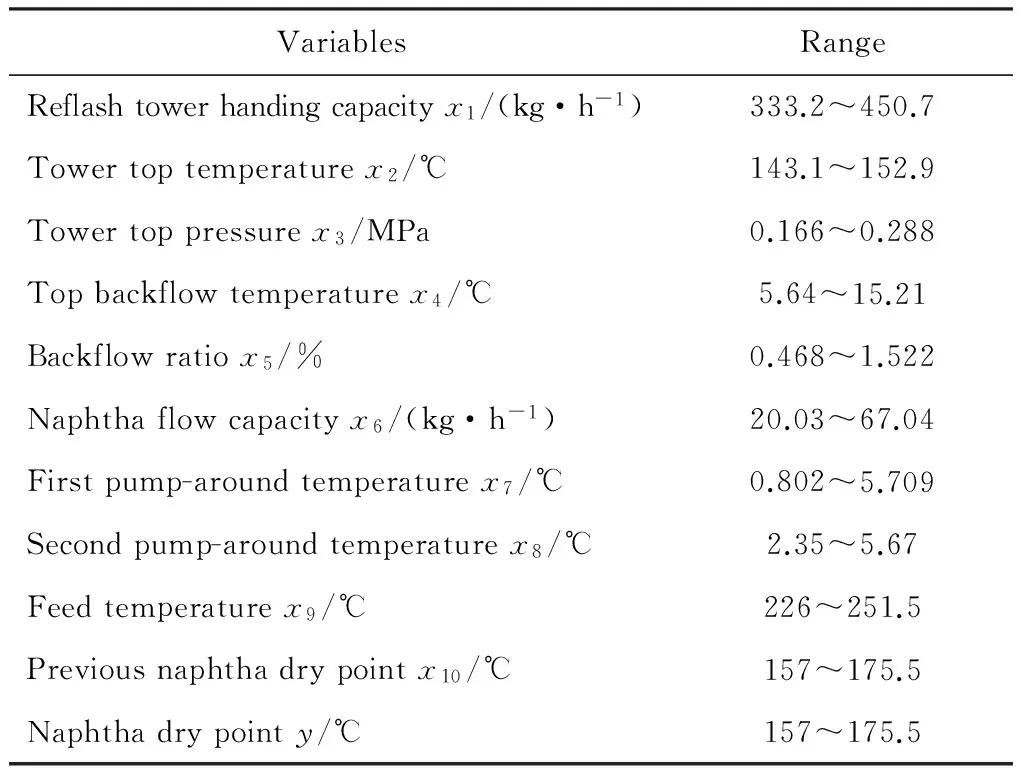
VariablesRangeReflashtowerhandingcapacityx1/(kg·h-1)333.2~450.7Towertoptemperaturex2/℃143.1~152.9Towertoppressurex3/MPa0.166~0.288Topbackflowtemperaturex4/℃5.64~15.21Backflowratiox5/%0.468~1.522Naphthaflowcapacityx6/(kg·h-1)20.03~67.04Firstpump-aroundtemperaturex7/℃0.802~5.709Secondpump-aroundtemperaturex8/℃2.35~5.67Feedtemperaturex9/℃226~251.5Previousnaphthadrypointx10/℃157~175.5Naphthadrypointy/℃157~175.5
图2示出了模型输入量与输出量的关系。从图2可以看出,各个输入与输出之间呈现出了非常明显的非线性关系。
2.3 初顶石脑油干点预测模型的建立
2.3.1数据预处理 将275组数据随机分为两部分,185组作为训练数据,90组作为测试数据。为了便于神经网络的训练,把所有数据归一化到[-1,1]中。
(5)

2.3.2 子模型训练 根据文献[8]可知,对于神经网络来说,网络的训练误差会因隐单元数不同而发生变化。本文分别采用2~9个隐单元的神经网络作为子模型,用训练集中的数据对各个子模型进行10次训练,图3示出了各子模型10次训练中的平均训练误差。
从图3可以看出,在185组训练数据上,随着隐单元数的增加,网络的平均训练误差逐渐减小。
针对测试集中的90组数据,计算各子模型在10次训练中的平均预测误差,图4示出了2~9个隐单元的子模型在90组数据上的平均预测误差。
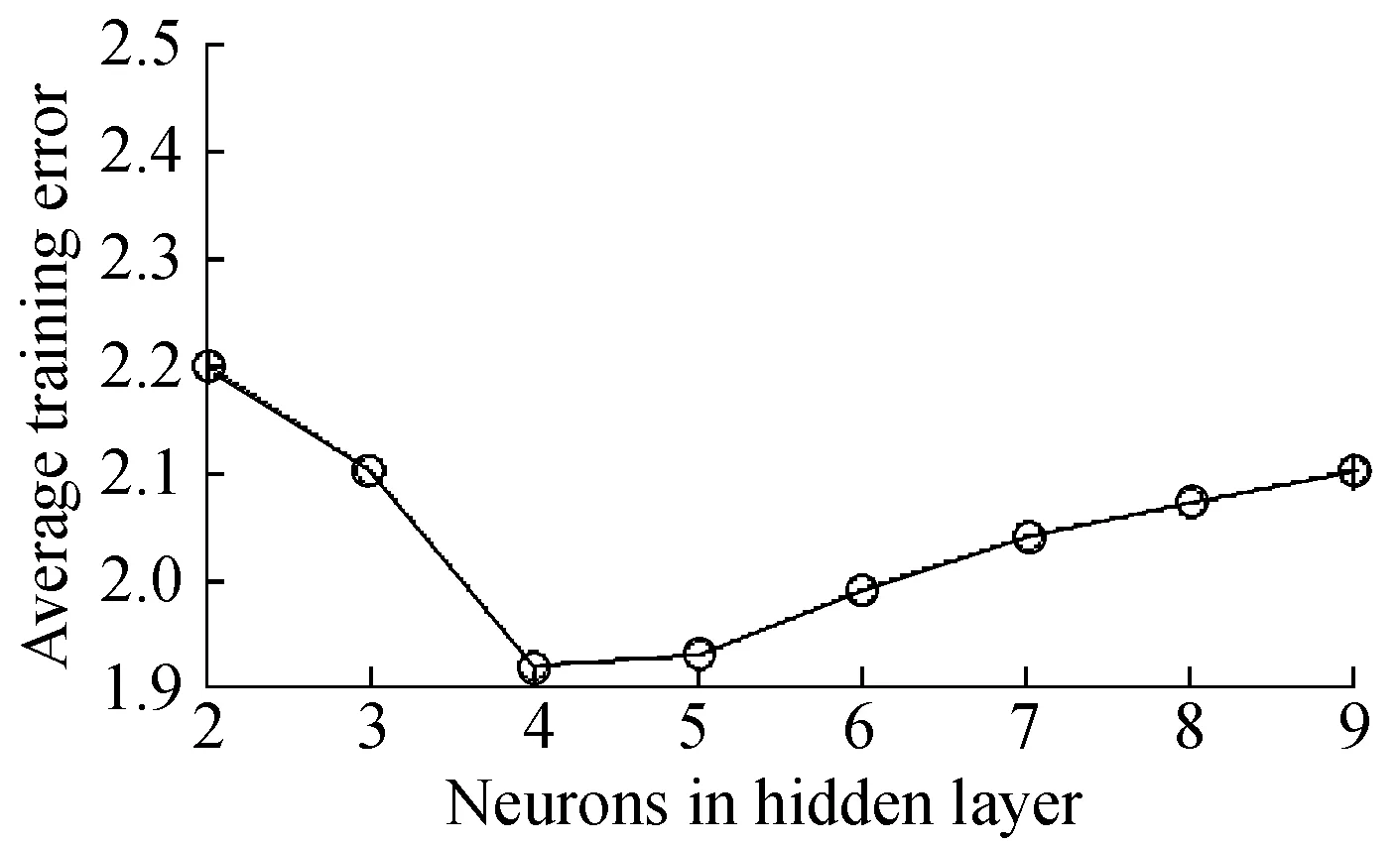
图4 各子模型平均预测误差Fig.4 Average test error of every sub-network
2.3.3 网络集成 首先,采用1.3节中的方法选择邻近数据,在选择过程中,将ζ设置为0.7,λ设置为0.5,经过计算可以得到90组测试数据各自的邻近数据。采用类似概率分布的方式来展示90组测试数据的邻近数据选择结果,如图5所示。图中横坐标表示邻近数据的组数,纵坐标表示测试数据的组数,例如,柱状图最高的那一项表示:有16组测试数据,它们邻近数据的组数是15,即这16组测试数据各自都有15组邻近数据。从图中可以看出,各组测试数据上邻近数据的组数在大尺度范围上近似呈现正态分布的模式,但有些测试数据的邻近数据较少,可能会影响本文方法在这类测试数据上的预测效果。

图5 邻近数据选择结果Fig.5 Result of adjacent data selection
接下来,确定在一个特定的测试数据上各子网络模型的权值系数。例如,对于归一化后的一组测试数据x,设它有k组邻近数据,然后计算已经训练出的8个子网络模型分别在这组测试数据上的预测值(y1,y2,…..,y8)以及k组邻近数据上的平均训练误差(e1,e2,…,e8),采用公式wi=1/ei,i∈[1,8]计算各子模型的权值,最后采用1.4节中的式(4)计算最终的预测值y。
针对90组测试数据,计算每组数据的预测值,总体的预测效果见表2。表中RMSE为均方根误差;APE为平均百分比误差;r为预测输出与实际输出的相关系数。计算公式如下:
(6)
(7)
(8)
比较表2与图4可以看出,集成后的预测误差相比各个子模型的预测误差都要小,因此可以说集成方法成功地减小了预测误差。

表2 集成神经网络的预测效果Table 2 Prediction result of intergraded neural network
图6示出了集成方法的预测误差分布情况,可以看出接近90%的预测误差小于1.5(系统输出实际值范围是157~175.5 ℃,即90%的误差小于取值范围的10%)。

图6 预测误差分布图Fig.6 Distribution of test error
2.3.4 结果分析 表3 示出了各子模型的权重总和。可以看出,各个子模型在组合过程中对于预测输出的贡献度(即在90组测试数据上的权值总和)基本相近,因此,在组合过程中,每个子模型的输出结果总体来说基本上是同等重要的。
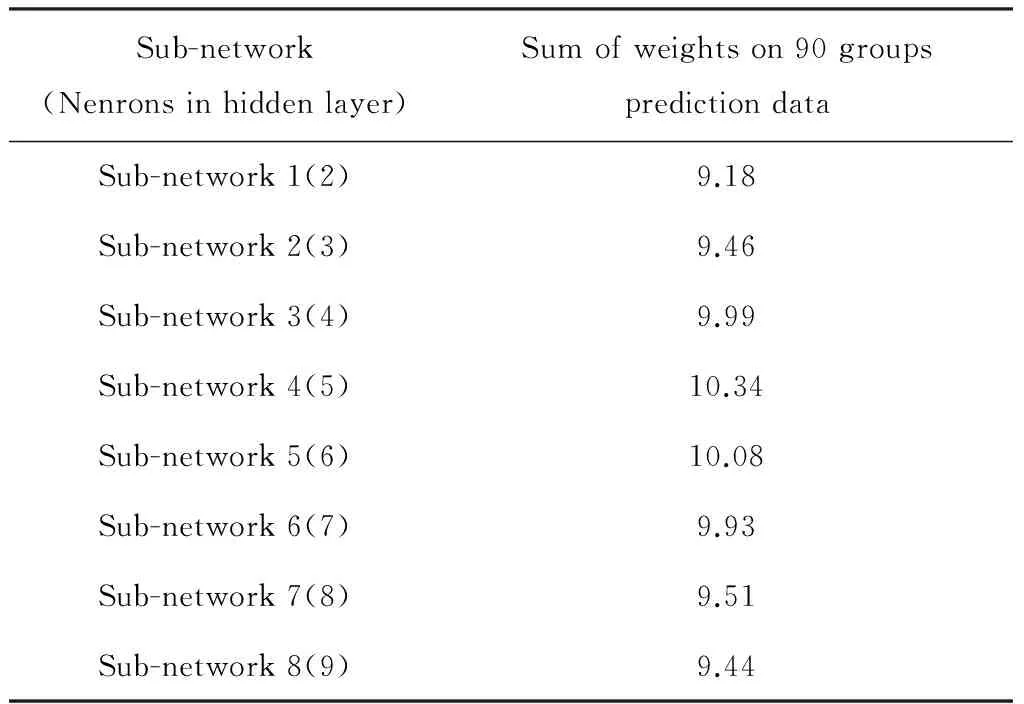
表3 各子模型的权重总和Table 3 Sum of weights in every sub-network
同时也不难发现,权值总和最大的子模型4(5)对应的预测误差最小,而权值总和最小的子模型1(2)对应的预测误差最大。因此,可以看出子模型预测输出对总体的贡献度与子模型本身的预测误差有关系。
2.3.5 结果比较 图7示出了本文方法在初顶石脑油干点预测上的实验结果,图8示出了文献[9]的实验结果,图9示出了文献[10]的实验结果。通过比较可以发现,本文方法的实验结果更好。

图7 本文方法实验结果Fig.7 Result of this paper
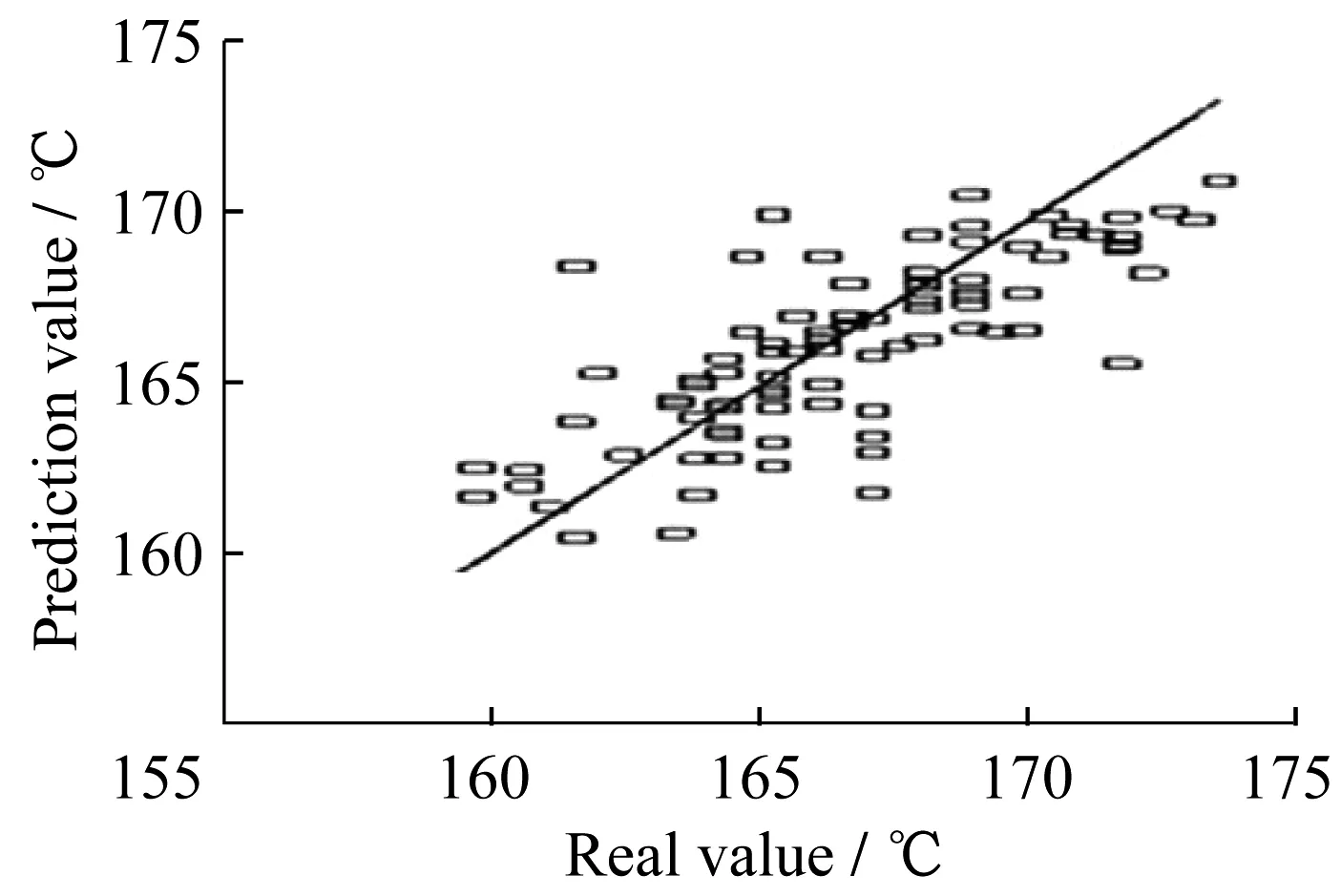
图8 文献[9]方法实验结果Fig.8 Result of literature[9]
图9 文献[10]方法实验结果Fig.9 Result of literature[10]
3 结 论
本文提出了一种基于即时学习的集成神经网络方法,主要思想是利用各神经网络子模型的局部预测精确度,通过子模型集成构造一个更加精确的预测模型,然后将此方法应用于初顶石脑油干点的预测。实验结果表明,本文提出的集成神经网络方法成功地减小了预测误差,与文献[9-10]提出的方法相比,本文方法有着更好的预测效果。同时不难看出,本文提出的集成方法不仅可以应用于神经网络,也可以应用于其他的一些基于数据的拟合算法。
[1] 余伟,罗飞,杨红,等.基于多神经网络的污水氨氮预测模型[J].华南理工大学学报(自然科学版),2010,38(12):79-83.
[2] 熊智华,王雄,徐用懋.基于广义信息熵融合的多神经网络建模方法[J].信息与控制,1999,41(增刊):346-349.
[3] 罗健旭,邵惠鹤.应用多神经网络建立动态软测量模型[J].化工学报,2003,54(12):1770-1773.
[4] 韩龙,周月,孙旭升.基于集成神经网络与模糊逻辑融合的稳压器泄漏监测方法[J].原子能科学技术,2014,48(Z1):474-479.
[5] 孙维,王伟.基于即时学习算法非线性系统多模型自适应控制[J].大连理工大学学报,2002,42(5):611-615.
[6] 朱瑞军.即时学习算法在非线性系统迭代学习控制中的应用[J].控制与决策,2003,18(3):278-281.
[7] 王其红,潘天红,邹云.基于即时学习算法的软测量建模方法[J].南京理工大学学报,2007,31(6):278-281.
[8] RICHARD O D,PETER E H,DAVID G S.模式分类[M].北京:机械工业出版社,2003.
[9] ZHOU Weihua,YAN Xuefeng,CHEN Chao,etal. Optimization of RBF neural networks using a rough K-means algorithm and application to naphtha dry point soft sensors[J].Journal of Chemical Engineering of Japan,2013,46(7):501-508.
[10] 颜学峰.基于改进神经网络的干点软测量[J].高技术通讯,2007,17(1):44-48.
Integrated Neural Network Based on Just-in-Time Learning and Application on Dry Point Prediction
WU Shuo-feng, YAN Xue-feng
(Key Laboratory of Advanced Control and Optimization for Chemical Process,Ministry of Education,East China University of Science and Technology,Shanghai 200237,China)
Aiming at the poor generalization ability of single neural networks and large fluctuations of test accuracy for different samples,this paper presents an integrated neural network method based on the just-in-time learning.Firstly,several different neural network models are established based on the training samples.Secondly,several adjacent samples closest to the predicted samples are selected based on the just-in-time learning while predicting the samples.According to the training errors of the sub-networks on the adjacent samples,the integrated weights of the neural networks are generated immediately to establish the integrated neural network model in real time for predicting the test samples.Finally,the proposed method is applied to predict the naphtha dry point and a better prediction result is achieved,compared with the existing methods.
neural network; just-in-time learning; integration; dry point
1006-3080(2016)05-0696-07
10.14135/j.cnki.1006-3080.2016.05.017
2015-12-04
国家“973”计划 (2013CB733605);国家自然科学基金 (21176073)
吴朔枫(1990-),男,山东人,硕士生,研究方向为化工过程建模。E-mail:715122013@qq.com
颜学峰,E-mail:xfyan@ecust.edu.cn
TP183
A
