网络大数据下的信息隐藏分析
2016-11-21孔祥维郭维廓冯超禹杨明亮
孔祥维 郭维廓 冯超禹 张 祎 杨明亮
(大连理工大学电子信息与电气工程学部 辽宁大连 116024)
网络大数据下的信息隐藏分析
孔祥维 郭维廓 冯超禹 张 祎 杨明亮
(大连理工大学电子信息与电气工程学部 辽宁大连 116024)
(kongxw@dlut.edu.cn)
随着网络信息爆炸式的增长,近年来信息安全引起了广泛的关注.信息隐藏作为信息安全领域的热门方向,也同样面临着大数据带来的挑战.网络中存在着海量的数据且这些数据来源多样、质量不一等诸多特点,使很多实验室环境下的信息隐藏分析方法因此失效.以数字图像为例:首先分析了网络大数据下数字图像的特点.然后阐述了实验室环境下信息隐藏分析方法的国内外研究成果.通过实验说明了实验室环境下信息隐藏分析方法的优异性能在网络大数据环境下急剧下降,重点从对数据集研究、对特征的处理、对分类器的改进以及整体结构的改变4个方面介绍了当前针对网络大数据下存在的信息隐藏分析失配问题进行的研究工作.最后指出了网络大数据下信息隐藏分析的潜在问题与未来挑战.为解决大数据下信息隐藏分析问题提供了有效的方法借鉴.
信息隐藏分析;大数据;网络;大数据安全;比较研究
信息安全成为世界性的现实问题.它牵涉到国家的政治安全、经济安全、社会安全、军事安全乃至文化安全,世界主要国家和地区均将信息安全视为国家安全战略的重要基石.近5年来互联网发达国家密集出台国家网络安全新战略,加速战略核心内容的落地部署.自2013年投入103亿美元的网络安全预算以来,美国用于网络安全的资金投入近年来呈稳步增长趋势,美国总统奥巴马提议在2016 财年预算中,拟拨款140亿美元用于加强美国网络安全,以便更好地保护联邦政府和私有企业网络免遭黑客威胁[1].截至2014年,已经有40多个国家相继颁布了网络空间国家安全战略,仅美国就颁布了40多份与网络安全有关的文件.在欧洲,德国总理默克尔与法国总统奥朗德拟从战略层面绕开美国以强化数据安全.在亚洲,日本与印度也积极行动,日本于2013年6月出台了《网络安全战略》,明确提出“网络安全立国”.印度于2013年5月出台《国家网络安全策略》,目标是“安全可信的计算机环境.可以看出,加强网络信息安全建设已经成为世界范围内公认的重要战略决策之一.
我国是一个网络大国,但并不是网络强国,当前的信息安全形势非常严峻.习近平总书记曾明确指出:没有网络安全,就没有国家安全,网络安全和信息化是事关国家安全和国家发展、事关广大人民群众工作生活的重大战略问题.政府已制定和实施《国家安全战略纲要》,提出“网络空间立国”的思路,同时《国家中长期科学技术发展规划》也将面向核心应用的信息安全列为重点发展的优先主题[2].
网络空间环境下的网络信息战重要技术之一是隐蔽通信及其对抗,“9·11”事件使得全球反恐成为重点,也使得信息隐藏与信息隐藏分析成为隐蔽通信的研究热点.用于隐蔽通信的信息隐藏或隐写术(data hiding或steganography)是具有古老历史并沿用至今的隐蔽通信方式.steganography源自希腊文中的“掩蔽书写”,描述了一种创造隐藏信道的技术,其基本思想是把秘密消息隐藏在正常载体中,通过隐藏秘密消息的存在性来构建隐蔽通信.与古代相比,现在利用信息隐藏进行秘密数据的嵌入方法更加复杂,伪装所用的载体更为广泛.信息隐藏不仅限于要隐藏正在发送消息通信这一事实,还要让发送者和接收者对于监听者来说不可检测到,因此也需具备匿名性和隐私性.与加密成密文乱码让他人不懂的密码术比较,信息隐藏掩饰了通信的存在,让监听者查不出有隐蔽通信发生.基于数字多媒体信息隐藏的隐蔽通信最先发展并在近10多年最先受到以美国为首的先进国家以及国际学术界的重要关注[3-4],继而又发展了其他多媒体、自然语言、文件系统、网络协议等多样的载体形式[5].任何信息安全技术都是对抗性的,安全分析是发现系统的安全问题的重要手段.信息隐藏的安全分析——信息隐藏分析(steganalysis)集中在检测隐蔽通信的存在.但是,矛与盾这2个方面的研究并不平衡,这一点可以从信息隐藏软件工具的比例表明,信息隐藏嵌入软件远远多于信息隐藏分析检测软件.截至2012年2月,最大的信息隐藏工具商业数据库包含1 025种应用软件.
当前日益普及的数码相机、智能手机、多种信息处理软件以及蓬勃发展的互联网和社交网络大大提高了人们记录、处理、传播、交流多媒体内容的能力,使得网络上大量涌现的多媒体大数据可以对新闻、纪实、社会、生活等方面进行现场记录和事实重现.社交网络成为人人都可参与的互动平台,人人可以成为网民记者,可以成为摄影师,可以上传自己的拍照作品,随意下载网络的图像.固有的观念:百闻不如一见,有图有真相,一幅图胜过千言万语等等在网络上得以落地.在众多的网络多媒体数据当中,图像视觉具有的直观性、冲击力和写实性使得当前的网络正在进入读图时代,网络图像成为当前不可或缺的记录真实世界和社会现实的富媒体.
网络上海量的数字图像由于其直观可视特性得到了广泛的传播和应用.从宏观角度看,网络上的图像数量庞大、来源繁多;从微观角度看,网络上的图像来源各异,导致其质量良莠不齐、鱼龙混杂.下面我们从安全角度分析网络上图像的来源和处理状况.
第2种情况是隐藏了秘密信息的载密图像与未含有秘密信息的载体图像并存.在网络上出现的多种以图像作为掩护载体内嵌秘密信息的信息隐藏软件,这些信息隐藏软件相比传统的加密方法具有更好的隐蔽性和伪装性,可以在正常的图像通信中包含着秘密通信,使人眼难辨的伪装载体图像通过网络任意地传播.但隐蔽通信技术在政治、经济、军事等领域带来便利的同时,也遭到了不法分子的恶意使用,在非法通信、恐怖信息秘密传递中越来越多.2001年,《今日美国》发表文章指出“9·11”事件中极端主义分子使用信息隐藏技术来进行秘密联系,以策划和密谋恐怖事件[6].2006年,印度媒体报道称,7月11日发生在孟买的火车连续爆炸事件中恐怖分子使用了信息隐藏技术.2007年,美国全国广播公司报道指出了信息隐藏技术在伊斯兰基地组织中的应用.2010年,美国联邦调查局揭露了冷战以来俄罗斯在美国的最大间谍组织使用信息隐藏技术通过网络上的数字图像进行联系.另外,有消息称恐怖组织在其内部文章中鼓励不法分子使用信息隐藏技术进行通信,以达到不为人知的目的.除此之外,还有一些不法分子在商业活动中使用信息隐藏技术来传递和泄露商业机密,通过信息隐藏多媒体和正常媒体一起在网上到处传播,承担着传递秘密信息的任务.
综上所述,在实际网络环境下呈现出来的是混合多源图像,包含多种图像来源、多种图像质量、多种图像内容、多种伪造图像、多种藏密图像等等.这些网络图像呈现出真实和虚假、载体和载密等图像同时并存的状况,“有图有真相”的传统观念受到了严重质疑.网络上多源数字图像的特点可以总结为如下4点:
1) 图像多源.网络图像的多来源包括多种类型的手机、相机图像传感器所生成的原始图像,还包括修改图像、伪造图像、载密图像、社交网络图像等.
2) 图像异质.网络上存在着原始图像,使用图像处理软件进行几何转换、格式转换、JPEG压缩、社交网络限制等形成的多种质量、多种形式、多种参数的异质图像.
3) 图像伪造.网络上存在着从原始图像变化而生成的美化图像、拼接图像、增删图像等多种篡改伪造图像.
4) 图像藏密.信息隐藏中的图像是一种伪装载体,其中嵌入了秘密信息,成为图中藏密,且不影响正常图像的使用价值.
从以上分析可以看出,网络空间中竟然还有这么多来源不一、良莠不齐的图像,直观的网络图像中存在不可见的深度信息,这些事例颠覆了“眼见为实”的传统观念.人们不仅质疑网络上传播的图像的真实性,而且深度质疑这图像仅仅是幅表面呈现的图像还是幅隐藏着什么秘密的载体.这一系列质疑使得网络大数据下的信息隐藏分析已经成为当前多媒体信息安全研究领域最为紧迫的挑战之一.然而现有的信息隐藏分析大多数是在实验室环境下进行,实验室环境下的信息隐藏分析应用于网络大数据仍有很多问题尚未解决.2013年Ker等8位[7]本领域最具有名望的学者联合撰文,呼吁学术界加强实用信息隐藏技术和信息隐藏分析技术的研究,力求使这2项技术从实验室推向实际应用.孔祥维等人[8]曾对多媒体信息安全研究现状进行研究,分析各个方向领域的研究背景及研究现状.指出多媒体信息隐藏分析从科学研究走向现实仍面临非常大的挑战.
1 实验室环境下信息隐藏分析研究
信息隐藏分析的目标是利用训练中载体图像与载密图像的特征集合构建分类模型,再利用该模型来判定待测图像是否为隐藏信息.
当前实验室环境下的信息隐藏分析主要由3个部分组成:图像数据库、信息隐藏分析特征与分类器,其框架如图1所示.下面将分别对其研究现状进行介绍.

图1 传统信息隐藏分析流程图
1.1 实验室环境下的数据库
目前图像信息隐藏分析常用的图像库有BOWS库、BOSSbase库和相机库等.BOWS库中的图像是不同尺寸的自然图像经缩放和裁剪得到的,包括10 000幅尺寸为512×512的灰度图像.BOSSbase库由来自7个不同相机的未压缩的图像经过转换为灰度图像并裁剪成512×512尺寸组成.这2个图像库都是转换图库,可以用图像处理软件将图像压缩为某种特定质量因数的JPEG图像.相机库中的图像来自常见的尼康、佳能、索尼等品牌.
1.2 信息隐藏分析的特征及性能分析
近10年来,随着信息隐藏技术和信息隐藏分析技术的发展,用于信息隐藏分析的图像特征也层出不穷.从时间和维数来看:2006年,Shi等人[9]提出了利用马尔可夫过程来描述信息嵌入前后JPEG系数的方法,并得到324维图像特征集合,它对OutGuess,MB1,MB2等的检测正确率可达93%以上(图像的嵌入率为0.1,以下涉及到藏密的图像均是0.1的嵌入率);2007年,Fridrich等人将曾于2004年被提出的23维CFB特征[10]与324维的特征进行融合,得到274维的PEV特征集合[11],它对OutGuess的检测正确率可达99%以上,但是对MB1,MB2的检测正确率只有70%~75%;2008年,Chen等人[12]提出了基于块内和块间DCT系数共生矩阵的486维特征,它对OutGuess的检测正确率达到99%以上,且对MB1,MB2的检测正确率达到了95%;2010年,Pevny等人[13]将笛卡儿校准方法应用到以上方法中,提出了一种基于空域的686维特征SPAM, 2010年,Kodovsky等人[14]将PEV特征集合进行笛卡儿校准,得到CC-PEV特征集合,并且将其与SPAM特征进行进一步融合,得到了能很好对抗YASS的1 234维的CDF特征,它对YASS和MBS的检测正确率可达92%以上;2011年,Kodovsky等人[15]首次提出了基于DCT系数的共生矩阵对的48 600维高维数的特征集合CC-C300,并提出了空域的高维数特征集合SRM系列特征[16],其中常用的特征集合量阶为q1的特征SRMQ1,共12 753维;2011年,Liu等人[17]提出了基于DCT系数绝对值差分比例的216维特征Liu,它对MBS的检测率达91.8%;2012年,Kodovsky等人继续提出7 850维紧凑的高维特征集合CF*[18]、比较流行的有JRM(11 255维)[19]、CC-JRM(22510维)[19]、CC-JRM和SRMQ1的融合特征JSRM(35 263维)[19],其中,CC-JRM检测MBS,YASS,nsF5的正确率可达96%,97%,83%,JSRM的检测正确率比CC-JRM可提高2%左右;2013年和2015年Holub等人又提出了2种高维数的特征PSRM[20]和DCTR[21],DCTR对nsF5的检测正确率为80%,但是随着嵌入率的增长,DCTR的检测能力相对于其他高维特征更强一点.
除此之外,还有很多新的特征集合已经出现:PHARM[22],CFA-aware CRM[23],GFR[24]等.总体而言,现有的特征对2010年之前出现的大多数的信息隐藏方法(MB1,YASS,OutGuess等)的检测性能可达95%以上,但是对较新的信息隐藏方法(如UNIWARD,HUGO,WOW等)的检测性能还低于70%.
1.3 信息隐藏分析的分类器及性能分析
将从图像中提取的特征通过分类器进行处理,其输出就可以从待测图像中区分哪些图像是载体图像,而哪些是含密图像.
从时间上来看,人们最早使用的是多元回归,然后是Fisher线性分类器和SVM分类器[25].然而随着特征维数的不断升高,SVM分类器中的搜索超分类面参数的计算量越来越大,使其越来越不能满足信息隐藏分析的要求.为了解决检测器训练的复杂度增长的问题,FLD集成分类器(fisher linear discriminant ensemble classifier)因其良好的分类性能和较低的复杂度而越来越受信息隐藏分析者的青睐.FLD集成分类器是由一系列的线性分类器组成的.它首先将特征空间随机分成L个子空间.然后在每个子空间中应用Fisher线性分类器.最后,对L个基分类器的结果进行“大多数投票”确定最终的结果.因此,对于维数很高的特征,FLD集成分类器仍有很好的分类能力.并且,由于简化了计算的复杂度,FLD集成分类器有更快的速度.利用SVM和FLD集成分类器进行信息隐藏分析性能对比如表1、表2所示:

表1 nsF5藏密、CC-PEV特征、0.1嵌入率条件下分类器性能对比

表2 nsF5藏密、CF*特征、0.1嵌入率条件下分类器性能对比
表中,G-SVM表示高斯核的SVM分类器,L-SVM表示线性核的SVM分类器.由表中数据可知,在特征维数较高的情况下,集成分类器的检测正确率与SVM相当,但是分类所需时间大大减少.
2 网络大数据下失配信息隐藏分析
实验室环境下的信息隐藏分析是在已知测试样本的一些先验信息的情况下进行的,通过已知的先验信息选择最优的训练数据进行信息隐藏分析.这些先验知识包括已知信息隐藏方法、已知量化表和嵌入率等,因而训练数据和测试数据的特性近似,我们称之为匹配信息隐藏分析.然而在网络大数据下,由于待测试的图像数据组成极其复杂,网络图像具有多来源和质量不一特性,包含了多种图像来源的混合多源图像,无法保证测试图像与训练图像之间的相机品牌、质量因数、嵌入率、信息隐藏方法等因素的一致性.测试图像与训练图像之间的差别会导致训练数据和测试数据的统计特性和特征分布的差异很大,使信息隐藏分析检测正确率大幅度下降,这就造成了训练样本和测试样本数据特性不匹配,导致信息隐藏分析来源失配现象产生.我们称之为失配信息隐藏分析.失配对信息隐藏分析的影响我们可以通过实验来说明,其实验结果如表3所示:
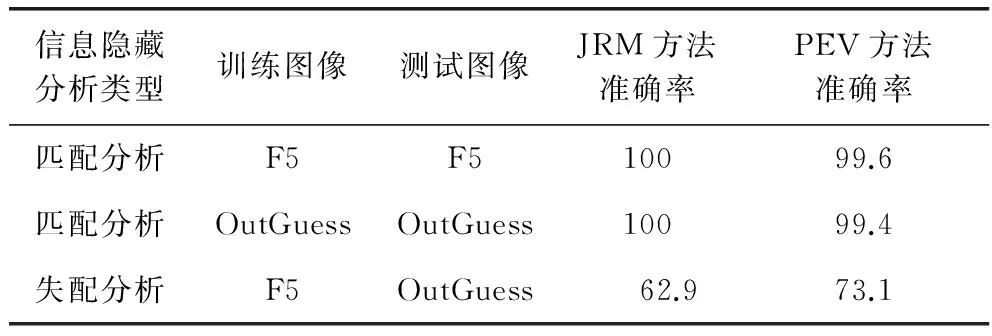
表3 失配与匹配情形信息隐藏分析准确率对比 %
表3中失配情况的信息隐藏分析相较于匹配情况下降了30%左右,因此研究在网络大数据的失配情况下的信息隐藏分析非常必要,针对网络大数据下的信息隐藏分析存在的失配问题,需要考虑到测试图像的来源多样、质量因数各异、隐藏方法不同等因素,国内外学者开展了一系列的研究,具体主要分为以下4个方面.
2.1 对数据多源和失衡的研究
现有的信息隐藏分析方法大多是针对原始图像和载密图像的二元分类.然而,网络环境中存在着诸如增强图像、PS图像以及伪造图像等复杂的图像类别.如何在众多图像类别中进行多类分类或化为二分类信息隐藏分析成为网络大数据环境下首先需要解决的一大问题.针对该问题,冯悦[26]提出多元混合图像信息隐藏分析系统框架,提出一种基于DCT系数构建马尔可夫模型检测重压缩的算法和基于图像偏移量的篡改定位算法.该方法可以对网络中多源混杂的图像进行分类,将原始图像、载密图像同伪造图像、社交网络图像、PS图像多源混合图像区分开以便进一步进行信息隐藏分析.冯悦提出的方法是基于原始图像为信息隐藏载体的前提.然而,在网络大数据的环境下,信息隐藏者不仅利用原始图像作为信息隐藏的载体,还利用PS图像、伪造图像、增强图像以及社交网络图像等多次压缩的图像作为信息隐藏载体,这就为在网络环境下进行信息隐藏分析提出了更大的挑战.李星等人[27]提出一种新的结合重压缩检测的JPEG图像多类信息隐藏分析方法.该方法可以估计待测图像的压缩质量因数,将经过一种质量因数压缩的图像和经过不同质量因数组合压缩的图像进行分类,为一次压缩图像和重压缩图像分别设计了不同的信息隐藏算法检测器,以实现一次压缩和重压缩图像中多种算法的识别.其系统框架分别如图2、图3所示:

图2 多元混合图像压缩检测框图

图3 JPEG信息隐藏算法多类分类器框图
网络中样本多来源、多质量、多形式、多参数等特点,造成了网络中图像样本数量大且类别多,而且每一类别中样本的数目可能会很少.这会导致我们不可能像在实验室环境下为每一类样本都建立信息隐藏模型,这对信息隐藏分析模型的建立也会造成一定的影响.所以,针对网络大数据的信息隐藏分析还需考虑如何解决训练样本类别多且每一类样本数目少的数据失衡问题.
曾利凯等人[28]提出用多任务学习的方法可以解决网络中图像具有多来源而每种来源训练样本少的问题.该方法将多源JPEG图像按照图像的不同来源及图像的压缩量化表分成若干个子图像库,再将每个子图像库的训练图像的特征融合采用多任务训练方式进行模型训练.多任务学习通过并行学习各个任务并利用相关任务训练样本中包含的域信息来提高学习效果.该方法可以提高独立训练信息隐藏分析框架在训练样本不充足时的模型泛化能力.Pasquet等人[29]提出了EC-FS算法和训练样本预处理算法.预处理算法通过k-means聚类为训练样本进行聚类,为每一类样本训练分类器,获得测试数据时计算测试数据与每个聚类中心的距离,找到最近距离,用相应的分类器进行信息隐藏分析.该方法通过将集成分类器与特征选择结合可以成倍地减少训练集的大小而不影响信息隐藏分析的性能.

图5 k-means聚类的混合异构图像信息隐藏分析
以上提出的方法虽然可以从不同角度研究由网络大数据环境下样本来源与种类繁多、质量差异大、样本数量不同等特点造成的信息隐藏分析来源失配的问题.但是,网络上图像的多种操作方法以及各大社交网络特有的压缩与剪裁方式等造成载体图像具有的多样性依然对网络环境下信息隐藏分析模型的构建造成了一定的影响,如何更好地解决由图像多源、异质造成的信息隐藏来源失配问题仍是信息隐藏分析面临的一大挑战.
2.2 失配信息隐藏分析的特征
信息隐藏分析准确率与图像特征密切相关.现有的信息隐藏分析特征主要针对的是实验室环境下的匹配信息隐藏分析,对于网络大数据造成的失配信息隐藏分析,性能急剧下降.众多学者针对图像特征开展了深入研究,提出利用特征集中特征映射以及构建新特征等思路进行失配的信息隐藏分析. Ker等人[30]提出了运用特征聚合和集成的思想提高失配检测正确率.特征聚合通过对训练集和测试集载体样本特征质心进行处理来增强特征聚合度;特征集成通过利用多个样本特征获得多个训练模型,利用这些模型组合成为混杂模型应用同时到测试集,针对不同分类器分配不同的判决权重值获取最终的分析结果.Li等人[31]引入迁移学习的思想,通过特征映射的方式寻找新的特征空间以增加训练集和测试集特征分布相似度.该方法主要分为2步:第1步通过领域校准学习一个新的线性变换增大训练集与测试集间的类内相似度;第2步通过学习得到一个共有的特征空间使训练集和测试集统计分布差异最小化.从而获得训练集和测试集新的特征表示,训练获得最终的信息隐藏分析模型.该方法针对隐藏方法失配和量化表失配有较好的效果,同时不需要构建大量多样的训练库.Zeng等人[32]从已有JPEG图库中选取多个与测试图像相近的子图库作为训练库,对训练图像和测试图像提取特征,并使用鲁棒判别特征变换方法对特征进行处理得到新的特征表示.该方法提出了2个互补的建模原则:最小化训练数据和测试数据之间的特征离散度和最大化训练数据的特征辨识度,这2个互补原则在降低训练特征和测试特征之间特征分布差异的同时可以保持训练数据(含标签)的分类能力.利用非线性变换可以将原始的训练特征集和测试特征集转换到新的特征表示空间.在新的变换特征空间中再进行信息隐藏分析.Gul等人[33]提出了一种新的信息隐藏分析特征.该特征是利用马尔可夫随机场来构建k元变量概率密度函数,进一步将DCT系数进行统计获得的.该特征分为198维(k=2时)和657维(k>2时)2种,657维的检测能力特征比198维的检测能力特征高1%~2%.实验表明,该特征的检测性能比SHI,CHEN等特征提升了2%左右.同时,在图像库的来源失配情况下,其检测性能不受影响.
2.3 失配信息隐藏分析分类器
由于信息隐藏分析分类器的性能会直接影响最终结果,近年来,针对失配信息隐藏分析失配情况,不少学者开展了针对分类器的改进研究.Wu等人[34]针对嵌入率失配的问题提出了一种对集成分类器进行改进的方案.首先,在训练样本的每个随机子空间,利用线性判别式获得训练空间到判别空间的映射向量.然后将测试样本映射到判别空间后,进行k-means聚类,得到聚类结果.最后,将每个子空间的结果进行大多数投票,得到最终的判决结果.这个改进的分类器主要是利用k-means聚类代替了集成分类器中的阈值判决过程,从而缓解了嵌入率失配带来的影响.Xu等人[35]提出通过挑选多样且具有代表性的样本特征并构建重分权重的集成分类器模型的方法,来解决载体来源失配的问题.首先寻找类内差异大且冗余少的样本扩充训练样本库,再利用结合的思想,对训练多个集成分类器模型,通过分配不同的权重值,结合多个分类器结果进行最终判决.该方法增强了分类模型对高度类内变化的鲁棒性,从而获取有效的信息隐藏分析模型.Wu等人[36]提出了一种新的结构,将有监督的加权费舍尔线性分类器与无监督的k-means聚类整合到统一的半监督学习框架中,解决了网络大数据环境下经常出现的数据失衡的问题.Dong等人[37]提出了一种基于多超球面的一元支持向量机的半监督学习方法.该方法主要分为2个阶段:第1阶段首先利用多超球面一元支持向量机,仅仅使用原始图像作为训练样本训练出一个信息隐藏分析模型.随后,利用该模型针对测试图像进行信息隐藏分析.第2阶段是将原始图像和第1阶段测试得到的载密图像共同作为训练样本,利用软判决支持向量机进行分类模型训练得出最终的信息隐藏分析模型.这种方法在网络大数据的环境下避免了使用大量的载密图像作为训练样本,同时利用半监督学习的方法可以达到较好的信息隐藏分析效果.
2.4 端到端的信息隐藏分析结构
近年来深度学习的一些特性引起了人们的广泛关注.深度学习能够自动地从图像中提取出特征表示,并在很多领域显示出更好的性能,因此信息隐藏分析领域也有学者尝试将深度学习与信息隐藏分析相结合以期获得更好的分析结果.Qian等人[38]改进了传统的CNN网络结构,首先利用一个设计好的高通滤波器对图像进行预处理,相对地放大了隐藏信息引入的弱信号,接下来将传统CNN所使用的激活函数改为高斯激活函数,使得传统CNN网络更适用于信息隐藏分析情景.Pibre等人[39]在Qian等人研究的基础上进行了进一步的研究,他们对传统CNN进行了各种改进,通过大量的实验证明了CNN结构与FNN结构用于信息隐藏分析时,由于能够求得系统的联合最优化参数,其性能要高于传统的Rich Models与集成分类器结合,且对于来源失配具有一定的鲁棒性.
然而,虽然针对将深度学习应用于信息隐藏分析的研究正在展开也取得了一定的进展,但遇到了很多挑战.
一方面,与传统的机器学习方法相比,深度学习从流程到思想有着明显的不同.如上文所述,传统机器学习解决信息隐藏分析问题的结构一般分为2步:首先传统机器学习会通过人为的特征提取方式对图像进行特征提取,然后利用提取出的特征训练出一个模型进行分类.而深度学习则能够自动地利用多个层从图像中提取一种特征表示,其分类过程与特征提取是在一个统一的网络结构下完成的.Qian等人[38]在其研究中通过图6对比了2种结构的不同.从图6中我们可以看出传统机器学习算法与深度学习算法在结构上存在着明显的差异,传统机器学习方法特征提取与分类过程依次进行,2个过程互不影响,因此也很难同时达到最优,这在很大程度上限制了传统机器学习方法的性能.与之相比,深度学习在一个统一的网络模型下通过不断迭代,在迭代过程中不断调整每一层的参数从而使得算法系统达到最优,这在直觉上对信息隐藏分析性能的提高是有益的,在Qian等人[38]与Pibre等人[39]的研究中通过实验证实了这一假设.

图6 传统信息隐藏分析与深度学习信息隐藏分析流程对比
另一方面,尽管深度学习在很多领域(如图像检索、语言识别等)取得了很好的成果,图像信息隐藏分析由于其任务的独特性对深度学习本身提出了更高的要求,现有的隐藏算法大多具有视觉不可感知性,隐藏加密过程只引入了很小的信号变化,当嵌入率较低时这个信号变化会更小.这个小信号不容易检测且很容易被破坏,这对深度学习提出了很大的挑战.尽管深度学习在很多现有领域有着出色的表现,但是现有的深度学习方法并没有考虑到统计特性在信息隐藏分析过程中的重要性,其对图像进行的一些典型操作(如降采样、池化等)都会破坏信息隐藏过程引起的微小改变,从而使得信息隐藏分析过程失败.因此,若想在信息隐藏分析领域应用深度学习方法,必须对现有深度学习网络进行改进.在Qian等人[38]与Pibre等人[39]的网络结构中去掉了降采样过程,并将目前深度学习在其他领域中广泛应用的最大池化改为平均值池化,以更好地保护隐藏算法引入的信息.
虽然信息隐藏分析任务的独特性对深度学习带来了很大的挑战,但信息隐藏分析也具有一些其他领域不具备的特性,如果对于这些特性加以利用将会使深度学习用于信息隐藏分析取得更好的效果.首先,信息隐藏分析可以获得大量的原始图像与藏密图像,这些有标签数据使得深度学习过程有了大量可靠的训练数据,对于训练出一个更加准确的模型有一定帮助.其次,由于信息隐藏算法对于图像的改变很小,因此用于信息隐藏分析的深度学习网络可能不需要很多层就能获得较好的效果.在Pibre等人[39]的研究中,他们对CNN进行了各种不同形式的改进并测试其性能,令人意外的是,取得最低的错误检测率的卷积神经网络只有2个卷积层,这会很大程度上减少需要通过迭代训练的参数数量,从而减小算法的运算成本,这个结果为接下来人们的研究提供了一个新颖的思路.
总的来说,现阶段将深度学习与信息隐藏分析相结合尚属起步阶段,其面临的挑战还很多,但将深度学习引入图像信息隐藏分析领域,为图像的信息隐藏分析注入了一丝新鲜的血液,这很可能将成为信息隐藏分析领域研究的热点之一.
3 结束语
随着网络的发展,网络中传递的信息正在以惊人的速度增长,大数据时代已经到来.本文在全面说明了实验室环境下信息隐藏分析的结构和方法的基础上,分别梳理和分析了目前国内外针对网络大数据下的信息隐藏分析所开展的研究.
网络中的数据规模巨大、来源复杂、扩散迅速,这对于实验室环境下的各种研究来说既是机遇也是挑战.
网络数据来源多样,造成多源分类下的信息隐藏分析的性能降低,如何在真假图像混杂情况下提高分析性能是一个挑战.
对于网络大数据下的信息隐藏失配分析新问题,针对传统分析结构基础上的改进能局部提高分析性能,但多方面的综合失配分析是实用需要解决的关键问题.
网络大数据环境下可能出现多样新的隐藏范式,传统的特征和分类器的信息隐藏分析结构处于被动的应对策略,端到端的新结构虽然也能进行信息隐藏分析,在目前还没有性能提升,但在图像识别和人工智能的巨大进步影响下,将是一条崭新的道路.
总之,信息隐藏分析已经逐步从实验室环境走向更为广阔的网络大数据环境,尽管目前已经有一些积极的尝试与探索性的研究工作正在展开,但总体上来说,网络大数据下的信息隐藏分析尚且存在着很多亟待解决的问题.
[1]中国日报网. 奥巴马拟拨款140亿美元增强网络安全建设[OL]. [2016-04-01]. http:world.chinadaily.com.cn2015-0213content_19573777.htm
[2]新华社. 国家中长期科学和技术发展规划纲要[OL]. [2016-04-01]. http:www.gov.cnjrzg2006-0209content_183787.htm
[3]Cheddad A, Condell J, Curran K, et al. Digital image steganography: Survey and analysis of current methods[J]. Signal Processing, 2010, 90(3): 727-752
[4]Fridrich J. Modern trends in steganography and steganalysis[M]Digital Forensics and Watermarking. Berlin: Springer, 2012: 1-1
[5]Zielińska E, Mazurczyk W, Szczypiorski K. Trends in steganography[J]. Communications of the ACM, 2014, 57(3): 86-95
[6]Kelley J. Terror groups hide behind Web encryption[JOL]. USA Today, [2016-04-01]. http:usatoday30.usatoday.comtechnews2001-02-05-binladen.htm
[7]Ker A D, Bas P, Böhme R, et al. Moving steganography and steganalysis from the laboratory into the real world[C]Proc of ACM Workshop on Information Hiding & Multimedia Security. New York: ACM, 2013: 45-58
[8]孔祥维, 王波, 李晓龙. 多媒体信息安全研究综述[J]. 信息安全研究, 2015, 1(1): 44-53
[9]Shi Y Q, Chen C, Chen W. A Markov process based approach to effective attacking JPEG steganography[C]Information Hiding. Berlin:Springer, 2006: 249-264
[10]Fridrich J. Feature-based steganalysis for JPEG images and its implications for future design of steganographic schemes[C]Information Hiding. Berlin: Springer, 2004: 67-81
[11]Pevny T, Fridrich J. Merging Markov and DCT features for multi-class JPEG steganalysis[C]Proc of SPIE6506: Security, Steganography, and Watermarking of Multimedia Contents IX. Bellingham, WA: SPIE, 2007: 650503
[12]Chen C, Shi Y Q. JPEG image steganalysis utilizing both intrablock and interblock correlations[C]Proc of IEEE Int Symp on Circuits and Systems. Piscataway, NJ: IEEE, 2008: 3029-3032
[13]Pevny T, Bas P, Fridrich J. Steganalysis by subtractive pixel adjacency matrix[J]. IEEE Trans on Information Forensics and Security, 2010, 5(2): 215-224
[16]Fridrich J, Kodovsky J. Rich models for steganalysis of digital images[J]. IEEE Trans on Information Forensics and Security, 2012, 7(3): 868-882
[17]Liu Q. Steganalysis of DCT-embedding based adaptive steganography and YASS[C]Proc of the 13th ACM Multimedia Workshop on Multimedia and Security. New York: ACM, 2011: 77-86
[18]Kodovsky J, Fridrich J, Holub V. Ensemble classifiers for steganalysis of digital media[J]. IEEE Trans on Information Forensics and Security, 2012, 7(2): 432-444
[20]Holub V, Fridrich J. Random projections of residuals for digital image steganalysis[J]. IEEE Trans on Information Forensics and Security, 2013, 8(12): 1996-2006
[21]Holub V, Fridrich J. Low-complexity features for JPEG steganalysis using undecimated DCT[J]. IEEE Trans on Information Forensics and Security, 2015, 10(2): 219-228
[22]Holub V, Fridrich J. Phase-aware projection model for steganalysis of JPEG images[C]Proc of SPIE9409: Media Watermarking, Security, and Forensics 2015. SPIE, 2015. Bellingham, WA: SPIE, 94090T
[23]Goljan M, Fridrich J. CFA-aware features for steganalysis of color images[C]Proc of SPIE9409: Media Watermarking, Security, and Forensics 2015. Bellingham, WA: SPIE, 2015: 94090V
[24]Song X, Liu F, Yang C, et al. Steganalysis of adaptive JPEG steganography using 2D Gabor filters[C]Proc of the 3rd ACM Workshop on Information Hiding and Multimedia Security. New York: ACM, 2015: 15-23
[25]Schölkopf B, Smola A J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond[M]. Cambridge: MIT Press, 2002
[26]冯悦. 多元混合图像的特征分析与取证研究[D]. 大连: 大连理工大学, 2015
[27]李星, 张涛, 何赞园, 等. 结合重压缩检测的JPEG图像多类隐写分析[J]. 应用科学学报, 2013, 31(2): 190-196
[28]曾利凯, 白雪葵, 孔祥维, 等. 基于多任务学习的JPEG图像信息隐藏分析[COL]第11届全国信息隐藏暨多媒体信息安全学术大会CIHW2012论文集. 2012 [2016-04-01]. http:d.wanfangdata.com.cnConference8310750
[29]Pasquet J, Bringay S, Chaumont M. Steganalysis with cover-source mismatch and a small learning database[C]Proc of Signal Processing Conf. Piscataway, NJ: IEEE, 2014: 2425-2429
[30]Ker A D, Pevny T. A mishmash of methods for mitigating the model mismatch mess[C]Proc of Society of Photo-Optical Instrumentation Engineers (SPIE) Conf Series. Bellingham, WA: SPIE, 2014: 79-85
[31]Li X, Kong X, Wang B, et al. Generalized transfer component analysis for mismatched JPEG steganalysis[C]Proc of IEEE Int Conf on Image Processing. Piscataway, NJ: IEEE, 2013: 4432-4436
[32]Zeng L, Kong X, Li M, et al. JPEG quantization table mismatched steganalysis via robust discriminative feature transformation[C]Proc of SPIE9409: Media Watermarking, Security, and Forensics 2015. Bellingham, WA: SPIE, 2015: 94090U
[33]Gul G, Kurugollu F. JPEG image steganalysis using multivariate PDF estimates with MRF cliques[J]. IEEE Trans on Information Forensics & Security, 2013, 8(8): 578-587
[34]Wu A, Feng G. Payload mismatch detection of image steganalysis using ensemble linear discriminant clustering[C]Proc of IEEE Int Conf on Signal Processing, Communications and Computing. Piscatawany, NJ: IEEE, 2015
[35]Xu X, Dong J, Wang W, et al. Robust steganalysis based on training set construction and ensemble classifiers weighting[C]Proc of IEEE Int Conf on Image Processing (ICIP). Piscataway, NJ: IEEE, 2015: 1498-1502
[36]Wu A, Feng G, Zhang X, et al. Unbalanced JPEG image steganalysis via multiview data match[J]. Journal of Visual Communication & Image Representation, 2015, 34: 103-107
[37]Dong Y, Zhang T, Xi L. Blind steganalysis method for JPEG steganography combined with the semisupervised learning and soft margin support vector machine[J]. Journal of Electronic Imaging, 2015, 24(1): 013008-013008
[38]Qian Y, Dong J, Wang W, et al. Deep learning for steganalysis via convolutional neural networks[C]Proc of SPIE9409 Media Watermarking, Security, and Forensics 2015. Bellingham, WA: SPIE, 2015: 94090J
[39]Pibre L, Pasquet J, Ienco D, et al. Deep learning is a good steganalysis tool when embedding key is reused for different images, even if there is a cover sourcemismatch[C]Proc of Media Watermarking, Security, and Forensics. Bellingham, WA: SPIE, 2016: 79-95

孔祥维
教授,博士生导师, 主要研究方向为多媒体信息安全、数字图像处理和识别、大数据下的多媒体语义理解、多媒体知识管理和商务智能、多源信息感知和信息融合等.
kongxw@dlut.edu.cn

郭维廓
硕士研究生,主要研究方向为多媒体信息安全、 图像语义分析和分类.
guoweikuo@mail.dlut.edu.cn

冯超禹
硕士研究生,主要研究方向为信息隐藏分析.
fengchaoyu@mail.dlut.edu.cn

张 祎
硕士研究生,主要研究方向为信息隐藏分析.
yiz@mail.dlut.edu.cn

杨明亮
硕士研究生,主要研究方向为信息隐藏分析.
yangml@mail.dlut.edu.cn
Steganalysis of the Big Data over Network
Kong Xiangwei, Guo Weikuo, Feng Chaoyu, Zhang Yi, and Yang Mingliang
(DepartmentofElectronicsandInformationEngineering,DalianUniversityofTechnology,Dalian,Liaoning116024)
With the explosive growth of information on the Internet, information security has caused wide public concern over the recent years. Steganalysis as a popular direction in the field of information security, is also facing the challenges posed by big data. The data over network always presents in huge amount and comes from multiple sources and different qualities, which makes the steganalysis methods under laboratory become invalid. This paper takes digital images as an example, at first introduces the research situation of steganalysis under laboratory environment, and then analyzes the characteristics of image under the big data over network. Steganalysis methods under laboratory always have dramatic performance decrease under the big data over network by experiment. The paper focuses on the research on the mismatch of steganalysis of the big data over networks, researches on the key technology and the latest progress form four aspects which are the research on the data set, the process on the feature, the improvement of the classifier and the change of steganalysis framework . In the end, the potential problems and future challenges of steganalysis of the big data over network are pointed out, which provide a relatively comprehensive reference basis for future research.
steganalysis; big data; network; big data security; comparison study
2016-04-12
国家自然科学基金创新群体基金项目(71421001);国家自然科学基金项目(61502076)
TP393.08
