一种基于FPGA的频域脉冲压缩处理器的实现
2016-11-17顾峰,戴健
顾 峰,戴 健
(中国船舶重工集团公司第723研究所,扬州 225001)
一种基于FPGA的频域脉冲压缩处理器的实现
顾 峰,戴 健
(中国船舶重工集团公司第723研究所,扬州 225001)
针对某搜索雷达波束个数多、码型种类多的特点,设计了一种基于现场现场可编程门阵列(FPGA)的频域脉冲压缩处理模块。其中的快速傅里叶变换(FFT)/逆快速傅里叶变换(IFFT)使用流结构,同时为了减少量化误差的影响,FFT采用块浮点运算。模块使用外部双倍速率(DDR)同步动态随机存储器(SDRAM)缓存脉压前的数字波束形成(DBF)数据、脉冲压缩系数。文章还对正斜率和负斜率调频信号所对应脉压系数的关系进行了推导,结果使得脉压系数的存储空间减少了一半。
现场现场可编程门阵列;脉冲压缩;快速傅里叶变换;块浮点;频域
0 引 言
脉冲压缩技术在现代雷达中被广泛采用。脉冲压缩雷达发射时采用宽脉冲调制信号以提高发射的平均功率,保证足够大的作用距离;而接收时采用相应的脉冲压缩算法获得窄脉冲,以提高距离分辨率。脉压技术较好地解决了雷达作用距离与距离分辨率之间的矛盾,而且压缩是对已知信号做处理,所以脉压技术抗干扰能力也较强[1]。
近年来随着高性能现场可编程门阵列(FPGA)的出现,由于其具有高度并行性处理、流水线处理、低功耗等优势,使用FPGA进行雷达信号处理成为一种普遍现象。此外,FPGA有丰富的IP核,这些知识产权核可以大大简化FPGA的设计,加速设计速度,缩短研发周期。
本文针对某搜索雷达波束个数多、码型种类多的特点,设计了一种基于FPGA的频域脉冲压缩处理器,该处理器具有设计灵活,调试方便,可扩展性强的特点。
1 脉冲压缩处理技术
数字脉冲压缩的实现方式有2种: 一是时域卷积法;二是频域乘积法。
时域脉冲压缩的过程是通过对接收信号s(n)与匹配滤波器脉冲响应h(n)求卷积的方法实现的:
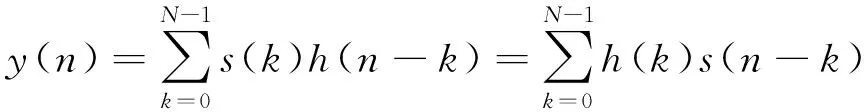
(1)
式中:N为匹配滤波器冲激长度。
根据匹配滤波理论:
(2)
即匹配滤波器是输入信号的共轭镜像。
由傅里叶变换的性质可知,时域卷积相当于频域相乘,因此,式(1)可以采用快速傅里叶变换(FFT)及反变换(IFFT)在频域内实现。用公式表示为:
y(n)=IFFT[S(W)*H(W)]=
IFFT[FFT(s(n))*FFT(h(n))]
(3)
一般情况下,对于大时宽带宽积信号,用频域脉压较好;对于小时宽带宽积信号,用时域脉压较好[2]。本文中脉冲压缩处理器即是基于频域法实现的,其原理框图如图1所示。
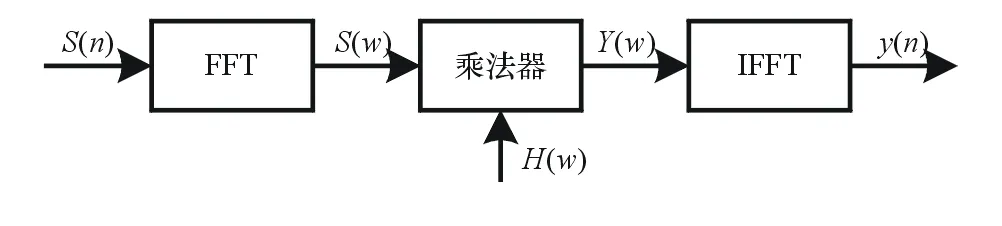
图1 频域脉压原理图
2 系统硬件平台
该脉冲压缩处理器用于某相控阵搜索雷达的信号处理部分。该雷达在阵面上完成数字波束形成(DBF),通过光纤将DBF数据发送给信号处理机,要求在信号处理机中完成脉冲压缩、动目标检测等处理,并将处理结果发送给PowerPC进行数据处理。其硬件结构如图2所示。
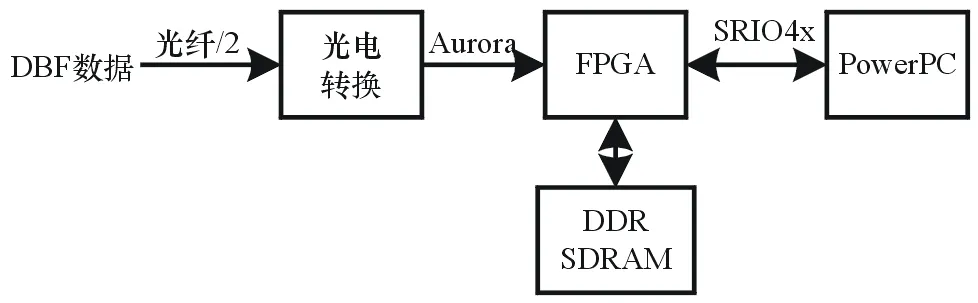
图2 硬件平台示意图
系统的硬件主要由光电转换模块、双倍速率(DDR)同步动态随机存储器(SDRAM)存储器、FPGA、PowerPC组成。DBF分机通过2根光纤将DBF数据发送给信号处理分机,传输协议为Aurora帧格式。1个PRT的数据组成1帧数据,1帧数据由固定长度的处理模式参数(包含DBF数据长度、波束数、码型、处理模式等信息)和可变长度的DBF数据组成。该雷达在1个脉冲重复时间(PRT)内同时形成16个波束,波束的数据率为10 MHz,数据位宽为32 bit,雷达根据工作模式的不同,使用不同的PRT及不同的码型,一个PRT内(一个波束的)DBF数据的长度最大为7 500个。
16个波束的DBF数据的带宽为5 120 Mbps(16·10 MHz·32 bit),本系统传输DBF数据的光纤为2根,每根的波特率为4 Gbps,考虑到8b10b编码及Aurora协议的效率,该光纤通道也是能满足DBF数据传输要求的。光电转换模块使用的是武汉永力公司的TLD850M10GR,该光模块最大支持6.25 Gbps的传输波特率。
由于该雷达的DBF数据以及码型较多,但FPGA的片内存储资源有限,且FPGA需完成较多的信号处理任务,设计使用外部DDR来缓存脉压前的DBF数据、脉压系数等,考虑到DBF数据的速率为5 120 Mbps及DDR访问的效率0.8(为保险起见,按0.8考虑,实际测试约为0.89),外部DDR缓存的访问速度至少为12.5 Gbps(5 120 Mbps·2·1.25)。在本设计中,DDR芯片选用Micron公司的MT41J128M16HA-125T,该芯片的数据位宽为16 bit,存储容量为256 MB(128 MHz·16 bit)。该芯片的最大数据速率可以达到1 600 MT/s,即读写速度可以达到25.6 Gbps(1.6 GHz·16 bit),可以满足应用。
FPGA是信号处理分机的主要芯片,DBF数据接收、DDR控制器以及脉冲压缩模块等均在FPGA中实现,根据处理资源的评估,FPGA芯片选用Xilinx公司的xc7v485t。FPGA的功能示意图如图3所示。上电后,PowerPC将各码型的脉压系数通过串行高速输入输出(SRIO)发送给FPGA,FPGA将其写入DDR的相应空间中,同时PowerPC在FPGA中建立不同码型所对应的脉压系数,存放在DDR地址空间的索引表。FPGA将接收到的DBF数据写入DDR中,一帧数据接收完后,FPGA先从DDR中读取该帧数据的工作参数,根据工作参数中的码型信息,从脉压系数的地址索引表获取对应的脉压系数存放地址空间,然后从DDR的相应空间中加载脉压系数到片内存储空间;顺序从DDR中读取波束0~波束15的DBF数据到脉压模块,完成16个波束的脉冲压缩处理,再将处理结果送入后面的处理模块继续进行其他的处理。DBF数据的接收缓存和其脉冲压缩处理是并行进行的,即对当前接收到的DBF数据帧缓存的同时,可以对之前已缓存的DBF数据帧进行脉压处理。下面重点介绍脉冲压缩处理模块的设计,关于数据缓存部分的DDR控制器及其直接存储器存取(DMA)控制器的设计可参考文献[4]。
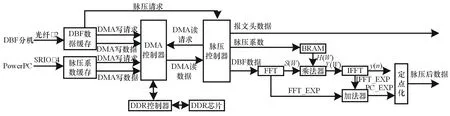
图3 FPGA的功能示意图
3 脉压模块的设计
3.1 FFT结构的选择
从图1容易看出,脉冲压缩模块所占用资源几乎都为傅里叶变换(FFT)/逆傅里叶变换(IFFT)所占用,应尽量减少脉冲压缩模块中FFT所占用的资源(片内块随机存取存储器(BRAM)存储资源、DSP48运算单元)。Xilinx公司提供了快速傅里叶变换IP核,可通过控制配置端口的信号来实时设置FFT变换长度,设置FFT运算或IFFT运算,这在很大程度上为设计提供了便利。该IP核提供3种结构选择[3]:
(1) 基-2,突发I/O。这种结构采用单个基-2蝶形单元对输入数据进行变换,运算消耗的时间最长,资源消耗最少。
(2) 基-4,突发I/O。这种结构采用单个基-4蝶形单元对输入数据进行变换,并利用BRAM来存储旋转因子,运算消耗的时间较长,资源消耗较少。
(3) 流水线型,数据流水I/O。这种结构将若干基-2蝶形单元级联起来,使得数据的输入、计算、输出可以流水进行,从而可以达到很高的处理速度,但资源消耗较大。
在本设计中,FFT的工作频率为200 MHz,通过仿真可知,在该工作频率下,2个基-2的FFT(1个FFT、1个IFFT)可在1个PRT内完成1个波束的脉冲压缩运算,16个波束的脉冲压缩需要32个基-2的FFT;1个基-4的FFT(FFT和IFFT复用1个IP核)可在1个PRT内完成1个波束的脉冲压缩运算,16个波束的脉冲压缩需要16个基-4的FFT;2个流水线型FFT(1个FFT、1个IFFT)可在1/18的PRT内完成1个波束的脉冲压缩处理,16个波束可复用该脉压模块,即16个波束的脉冲压缩只需要2个流水线型的FFT。
考虑到最长PRT的DBF数据长度及码型宽度,FFT的长度选择为8 192点。当然,随着PRT的减小,可通过FFT的配置端口相应减少FFT的变换长度。使用不同结构的FFT完成16个波束的脉冲压缩所占用资源如表1所示。

表1 脉压模块占用资源
从表1可知,流水型的FFT占用资源最少,因此选择了该结构,16个波束的DBF数据共用1个脉冲压缩模块,顺序对每个波束的DBF数据进行处理,为此,需要使用DDR缓存脉压前的16个波束的DBF数据。
3.2 脉压系数
脉压系数H(W)即为匹配滤波器脉冲响应h(n)的傅里叶变换。一般情况下,为了节省处理时间和处理资源,脉压系数都是事先算好,存储在片内的存储空间(如只读存储器(ROM))中。由于该雷达码型较多,有多种脉宽的线性调频、非线性调频的发射波形,如将其对应的脉压系数都存储在FPGA的片内存储空间,将会占用很多的存储空间,为了节省宝贵的片内存储空间,上电后,PowerPC将各码型的脉压系数发送给FPGA,FPGA将其写入DDR的相应空间中。脉压处理之前,FPGA首先将当前码型所对应的脉压系数从DDR中读取并写入片内的BRAM中;FFT输出时,顺序从BRAM中读取脉压系数,并将其与FFT输出数据相乘的结果作为IFFT的输入。
在本设备中发射波形为正斜率调频信号,由于混频器高低本振的原因,在14.5 GHz频率以下接收波形为正斜率,在14.5 GHz以上接收波形为负斜率,为此,每种码型需有2套脉压系数(正斜率和负斜率),但通过计算可知,负斜率的脉压系数可通过简单的变换正斜率的脉压系数获得。
负斜率的脉压系数H-(W)为其脉冲响应的h-(n)的傅里叶变化:
(4)
式中:N为FFT点数。
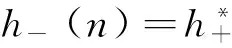
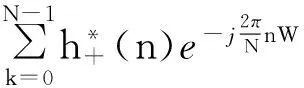

real[H+(-W)]-j·imag[H+(-W)]
(5)
若将式(5)乘以j的结果作为脉压系数,则其脉压结果为原脉压结果乘以j,这对脉压的性能指标没有任何影响。即脉压系数可表示为:
H-(W)={real[H+(-W)]-j·imag[H+(-W)]}·j=imag[H+(-W)]+j·real[H+(-W)]
(6)
因此,负斜率的脉压系数的实部为正斜率脉压系数的虚部的镜像,负斜率脉压系数的虚部为正斜率脉压系数实部的镜像。这使得负斜率的脉压系数不需要存储,只需简单地对正斜率的脉压系数进行镜像处理即可获得,镜像处理在FPGA中是容易实现的。当接收波形为正斜率时,存储脉压系数的BRAM的读取地址顺序为0~FFTN_1(FFTN_1为FFT点数减1);当接收波形为负斜率时,存储脉压系数的BRAM的读取地址顺序为FFTN_1~0。使用该方法对负斜率的回波进行脉压处理的仿真结果如图4所示(所仿真回波为线性调频(LFM)信号,带宽为5 MHz,时宽为10 μs,脉压系数使用海明窗加权)。
3.3 块浮点数据格式及其定点化
在数字信号处理系统中,数据表示格式可分为定点制、浮点制和块浮点制,它们在实现时对系统资源的要求不同,工作速度也不同,有着不同的适用范围[5]。
定点表示法使用最多,简单且速度快,但动态范围有限,需要用合适的溢出控制规则(如定比例法)适当压缩输入信号的动态范围,但这样会降低输出信号的信噪比。浮点表示法的优点是动态范围大,可避免溢出,能在很大的动态范围内达到很高的信噪比,主要缺点是系统实现复杂,硬件需求量大,成本和功耗高,而且速度较慢。
块浮点表示法是定点法和浮点法的结合,兼有以上2种表示法的某些优点。这种制式,1组数具有1个共同的指数,这个指数是这组数中最大的那个数的指数。由于块浮点法只用1个单一的指数表示1组数的指数,因而节约了存储器,简化了系统。其主要优点是:大动态范围、低截断(或舍入)噪声。从芯片实现角度上看,块浮点表示法能够在保证较高的信号处理质量前提下,资源占用与定点算法相当。这种表示法对于要运算的数比较多、数值相近的情况特别适用,尤其适用于实现快速傅里叶变换算法。本脉压模块中的FFT核可选择块浮点表示法,考虑到块浮点表示法的优点,我们选择了该表示法。
从式(3)容易看出,脉压后数据的块指数PC_EXP为FFT运算后数据的块指数FFT_EXP加上IFFT运算后数据的块指数IFFT_EXP(如图3所示)。由于脉压后的处理都为定点运算,所以块浮点表示法的脉压后数据需转换为定点表示法的脉压后数据。
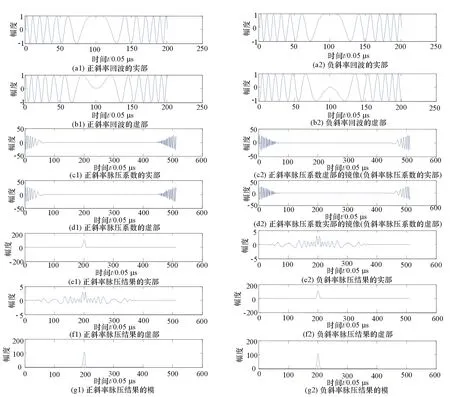
图4 正负斜率LFM脉压仿真
根据FFT的设置,块浮点的脉压后数据的尾数为24 bit,指数为6 bit,根据设计,脉压后的定点数据的位宽为32 bit。定点化的目的是使最大的脉压后定点数据的有效数据位宽为32 bit,由于脉压系统为线性系统,脉压前数据的幅度最大时,脉压后数据的幅度也最大,为此设计了如下的定点化流程:在某一码型下,模拟一帧幅度最大的脉压前DBF数据,通过仿真,可得出此时脉压后块浮点数据的块指数,该块指数的值减去8记为该码型的定点化指数。在实际工作时,根据脉压后块浮点数据的块指数与该定点化指数的差值,对脉压后块浮点数据的24 bit的尾数进行相应的移位,如指数差值为正,脉压后块浮点数据的尾数左移相应的位数(移位数为指数差值的绝对值);如指数差值为负,右移相应的位数(移位数为指数差值的绝对值)。容易理解,当脉压前的数据为最大时,脉压后的块浮点数据的24 bit的尾数需左移8位,此时得到的32 bit的定点数据的有效数据位宽为32 bit。不同码型对应的定点化指数不一样,需分别仿真确定。上电后,PowerPC将不同码型对应的定点化指数加载到FPGA中,在对块浮点数据定点化时,根据码型信息查找对应的定点化指数。
4 脉冲压缩模块的测试
使用超高速集成电路硬件描述语言(VHDL)编写FPGA程序,完成综合与实现后,利用ModelSim仿真软件对脉冲压缩模块进行布局布线后仿真,此时的仿真已基本接近真实情况。仿真信号同图4中负斜率LFM信号,仿真波形如图5所示,横坐标为运行时间,纵坐标为幅度。从图4和图5可以看出波形一致,表明软件设计正确,运行正常。
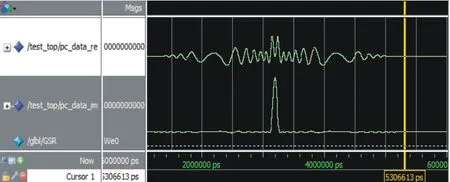
图5 脉压模块的Modelsim仿真
5 结束语
脉压实现有时域法或频域法。频域法里的FFT有多种不同的实现结构,没有哪一种方法是最好的,工程应用时需根据具体的运算量来选择实现方法,以达到较好的性价比。本文针对某型搜索雷达设计了一种频域脉冲压缩处理模块,其中的FFT采用流水线型,该模块在占用资源较少的情况下,能完成16个波束的脉冲压缩处理,且其中的块浮点算法减小了定点算法中的截断误差对脉压输出信噪比的影响。在FPGA软件不变的情况下,通过PowerPC加载不同码型的脉压系数及其定点化指数,可实现不同码型的脉冲压缩处理,具有较好的灵活性。
[1] 吴太亮,刘峥.基于FPGA的时域脉冲压缩器研究[J].制导与引信,2007,28(4):45-50.
[2] 贺知明,黄巍,向敬成.数字脉压时域与频域处理方法的对比研究[J].电子科技大学学报,2002,31(2):120-124.
[3] Xilinx Company.Data Sheet.Fast Fourier Transform V9.0[R].San Jose,USA:Xilinx Company,2015.
[4] 顾峰.基于DMA传输方式方式的SDRAM控制器的设计与实现[J].舰船电子对抗,2009,32(2):108-111.
[5] 马翠梅,陈禾,章菲菲.脉冲压缩定点处理的量化噪声分析[J].北京理工大学学报,2013,33(9):965-969.
Realization of A Pulse Compression Processor in Frequency Domain Based on FPGA
GU Feng,DAI Jian
(The 723 Institute of CSIC,Yangzhou 225001,China)
Aiming at the characteristics of multiple beams and multiple code types,this paper designs a pulse compression processing module in frequency domain based on field programmable gate array (FPGA).The fast fourier transform (FFT) and inverse FFT (IFFT) in the compressor use streaming structure,and block float operation is adopted in FFT for reducing the influence of quantization error.The module uses digital beam forming (DBF) data and pulse compression coefficient before external double data rate (DDR) synchronous dynamic random access memory (SDRAM) buffer memory pulse compression.The relationship of corresponding pulse compression coefficients between positive frequency modulation (FM) signal and negative FM signal is also deduced,which can reduce a half of memory space for pulse compression coefficient.
field programmable gate array;pulse compression;fast Fourier transform;block float;frequency domain
2016-01-11
TN957.5
A
CN32-1413(2016)04-0105-05
10.16426/j.cnki.jcdzdk.2016.04.023
