基于SAS软件实现随机抽样及应用
2016-11-16胡良平
胡 完,胡良平,2*
(1.军事医学科学院生物医学统计学咨询中心,北京 100850;2.世界中医药联合会临床科研统计学专业委员会,北京 100029*通信作者:胡良平,E-mail:lphu812@sina.com)
基于SAS软件实现随机抽样及应用
胡 完1,胡良平1,2*
(1.军事医学科学院生物医学统计学咨询中心,北京 100850;2.世界中医药联合会临床科研统计学专业委员会,北京 100029*通信作者:胡良平,E-mail:lphu812@sina.com)
本文的目的是帮助读者方便快捷地运用SAS软件中的SURVEYSELECT过程实现随机抽样。首先,对SURVEYSELECT过程及SAS数据集Customers进行了简单介绍。接着,结合简单随机抽样、分层随机抽样和控制排序分层随机抽样,介绍了随机抽样的SAS实现方法。读者只需要修改本文中所呈现的SAS程序中的少量参数,就可很方便地使用SAS软件实现随机抽样任务。事实说明,尽管SAS软件非常难学难用,但借助现成的SAS程序,可以轻松自如地解决很多具体问题。
SAS软件;SAS数据集;SAS过程;简单随机抽样;分层随机抽样
1 在“科研方法专题”中为何要使用统计软件
本刊前两期(即2016年第3期和第4期)的“科研方法专题”[1-7]详细介绍了进行生物医学和临床科学研究时不可缺少的基础知识,即“三要素”和“四原则”。这些内容似乎仅仅与“文字描述”有关。然而,在确定受试对象的数量时,涉及到“样本含量估计”的技术问题;在从总体中选取受试对象时,涉及到“随机抽样”的技术问题;在将已选取的受试对象分配到不同的对比组中时,涉及到“随机分组”的技术问题。这里提及的三个“技术问题”,仅基于“文字描述”是得不到很好解决的,需要借助计算公式或查阅相应的表格方可实现。然而,在计算机已相当普及的今天,利用现成的统计软件方便快捷地实现前述的三个技术问题,则是大势所趋。本文在已介绍SAS软件基础知识和用法入门的基础上,介绍使用SAS软件实现随机抽样的基本方法。
2 与随机抽样有关问题的概述[8]
在SAS软件中,SURVEYSELECT过程提供了各种各样的概率随机抽样方法[1]。这个过程既可以进行简单随机抽样,也可以进行包括分层抽样、整群抽样、不等概率抽样在内的复杂多阶段设计的抽样。在概率抽样中,调查总体中的每个抽样单位都有一个已知的共同的概率被抽取。概率抽样的这种属性避免了选择偏倚,同时可让研究者根据统计理论和样本信息对调查总体做出有效推断。
用SURVEYSELECT过程选择样品并构成样本,在所输入的SAS数据集中需要包括抽样框,抽样框是包含全部抽样单位的目录性清单。抽样单位是个体观测者或观测组(群组)。用户可以指定抽样方法、所需样本大小或抽样比例和其他一些选择参数。用SURVEYSELECT过程抽取样本后,产生包含抽样单位、抽样概率以及抽样权重的输出数据集。当进行多阶段抽样时,对每一个抽样阶段都需要调用这个过程来设定抽样框和选择参数。在等概率抽样中,抽样框或同一层内的每一抽样单位都有相同的概率被抽取。在等比例(PPS)抽样中,每一抽样单位被抽取的概率和它所在层的大小成正比。
SURVEYSELECT过程提供的等概率抽样方法有:①简单随机抽样(无放回);②无限制随机抽样(有放回);③系统随机抽样;④序贯随机抽样;⑤贝努利抽样。
SURVEYSELECT过程提供的等比例(PPS)抽样方法有:①无放回PPS抽样;②有放回PPS抽样;③PPS系统抽样;④基于PPS算法从每层抽取两个单元;⑤最小放回PPS序贯抽样。
该过程采用快速、高效的算法来实现这些抽样,它对于大的输入数据集或者抽样框表现很好。
SURVEYSELECT过程通过在层内选择独立样本来进行分层抽样,层内个体不重叠出现在调查总体的亚组中。分层可控制各层样本大小,广泛应用于调查个体多样的实践中。例如通过分层可以保证感兴趣但样本量小的亚组有足够的样本量,或通过分层提高对总体估计的精度。在系统抽样或序贯抽样中,SURVEYSELECT过程也可按控制变量的排序来额外控制隐性分层因素在层内的分布。
对于分层抽样,SURVEYSELECT过程提供了分配各层样本大小的调查设计方法。可用的分配方法包括按比例分配、Neyman分配和最优化分配。最优化分配在考虑层的大小、成本和方差情况下,在可用资源内使估计精度最大化。
SURVEYSELECT过程提供重复抽样,当总样本是由一组相同个体组成时,可用相同的方法抽取每一个体。用户可以利用重复抽样来研究变量的非抽样误差,例如不同面试官面试结果的变异性。用户也可以用重复抽样结合样本大小来估计标准误以及执行各种重复采样和仿真任务。
3 实施抽样研究所需要数据集的概况[8]
使用统计软件实施随机抽样的前提是要创建由拟被抽取样本的全体(即抽样总体)构成的数据集。下面借用SAS软件SURVEYSELECT过程的帮助信息中介绍的一个例子,来讲解如何实施各种随机抽样方法。一个互联网服务提供商进行了一项客户满意度调查,这个调查的目标人群是该公司当前的用户。该公司计划从当前用户中选择一个样本,采访选中客户,然后根据样本数据推断整个被调查总体的情况。
SAS数据集Customers包含抽样框,它是被调查总体的抽样单元目录。样本客户将从这个抽样框中抽取。数据集Customers是公司客户数据库的重要组成部分。它包括了每个客户的4项有关信息,即客户ID号(CustomerID)、客户来自的州名(State)、新老客户类型(Type)、服务使用量(Usage),共有13 471个客户。读者或用户在SAS程序编辑窗口内输入以下4句SAS语句:

title1'CustomerSatisfactionSurvey';title2'First10Observations';procprintdata=Customers(obs=10);run;
【程序说明】前两句将在输出结果的前两行产生标题,内容分别为“客户满意度调查(Customer Satisfaction Survey)”和“前10个观测(First 10 Observations)”;第3句是调用SAS中的print过程打印数据集中的信息,其选择项“data=Customers(obs=10)”的含义:采用的数据集名称为Customers,且仅输出该数据集中的前10行信息(即前10个观测者在4个变量上对应的全部信息)。
将上述4句语句组成的一段简单SAS程序(只有过程步,没有数据步,因为调用SAS软件中已有的SAS数据集Customers),便可显示Customers数据集中前10个观测数据,结果见表1。

表1 数据集Customers中前10位客户的有关信息
在SAS数据集Customers中,变量CustomerID唯一地标识每个客户;变量State是客户所在州地址,该公司客户在4个州:格鲁吉亚(GA)、阿拉巴马州(AL)、佛罗里达州(FL)和南卡罗莱纳(SC);变量Type取值为“Old”表示该客户订购公司服务超过一年,与之相对应的取值为“New”;变量Usage表示客户几分钟内平均每月服务使用量。
接下来的部分展示了在三种不同设计下采用SURVEYSELECT过程对客户满意度实施概率抽样调查,给出所需要的SAS程序及抽样结果。这三种设计都是以每一个客户为一个抽样单位。第一种设计是不分层简单随机抽样;第二种设计是按State和Type分层,在层内采用简单随机抽样;第三种设计是按Usage分层,然后在层内排序,最后采用简单随机抽样。
4 简单随机抽样及SAS实现[8-9]
以下是PROC SURVEYSELECT语句采用简单随机抽样抽取Customers数据集中的一个概率样本。

title1'CustomerSatisfactionSurvey';title2'SimpleRandomSampling';procsurveyselectdata=customersmethod=srsn=100 out=samplesrs;run;
【程序说明】proc surveyselect语句调用surveyselect过程。该语句包含了如下4个选项:第1个选项为“data=customers”,指定SAS数据集Customers作为输入数据集来选择样本;第2个选项为“method=srs”,指定抽样方法为简单随机抽样。在简单随机抽样中,每一个抽样单位都有同等的概率被抽取,样本是无放回抽取的,意味着每一个抽样单元不能被多次抽取;第4个选项为“n=100”,指定被抽取的样本大小为100个客户;第4个选项为“out=samplesrs将抽取到的样本储存到名为samplesrs的SAS数据集中去。
上面的SAS程序可以产生如下的信息,见表2。
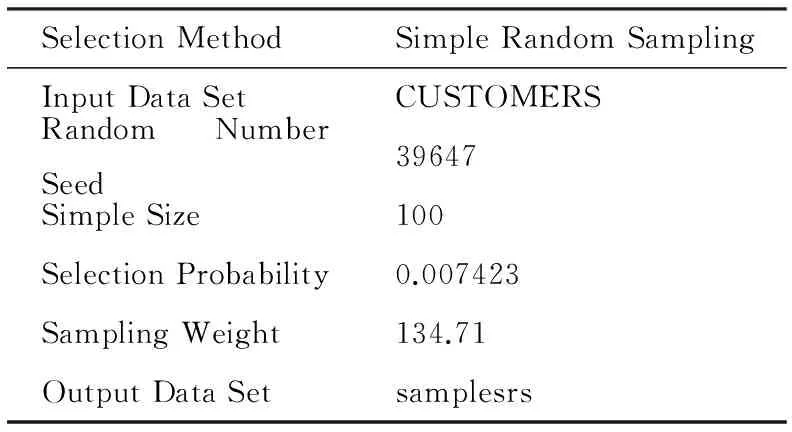
表2 对数据集Customers进行简单随机抽样的有关情况说明
表2概要地报告了使用SURVEYSELECT过程进行随机抽样的有关情况。采用简单随机抽样从Customers数据集中抽取了100个客户;随机种子数为39647,SURVEYSELECT过程用这个数字作为初始种子来产生随机数字。由于在SURVEYSELECT过程中没有指定seed=option选项,种子值采用的是计算机系统时间;每位客户被选中的概率为0.007423,该概率等于样本大小(100)除以总体容量(13471)所得的商;样本中每一客户的抽样权重为134.71,抽样权重是抽样概率的倒数;真正的抽样结果(即被抽取的100位客户在4个变量上的取值情况)被放置在输出数据集samplesrs中。
这100位样本客户被储存在SAS数据集samplesrs中。PROC SURVEYSELECT并没有直接显示此输出数据集的内容。下面用PROC PRINT语句显示samplesrs中前20个观测。

title1'CustomerSatisfactionSurvey';title2'Sampleof100Customers,SelectedbySRS';title3'(First20Observations)';procprintdata=samplesrs(obs=20);run;
【程序说明】参见前面产生表1的SAS程序后面的“程序说明”,此处从略。
上面这段SAS程序产生的结果见表3。
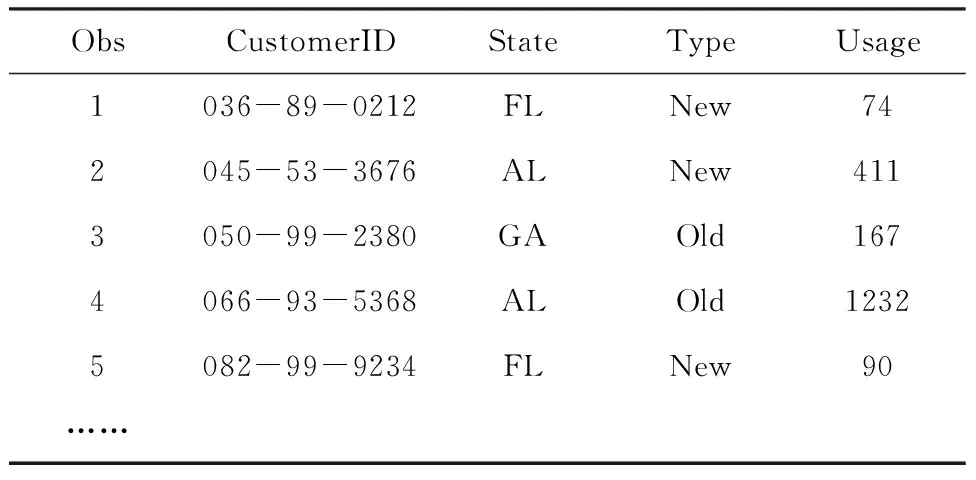
表3 采用简单随机抽样从customers中随机抽取的100位客户中的前20位
注:因篇幅所限,仅显示出了前5位
表3显示了包含样本客户的输出数据集samplesrs的前20个观测。这个数据集包含了输入数据集Customers中的所有变量。
5 分层随机抽样及SAS实现[8-9]
在Customers数据集中,抽样框是按State和Type分层后的所有客户目录性清单。这就把抽样框按State和Type取值分成了互不重叠的亚组,其亚组的数目等于State和Type两个变量或因素的水平数之乘积。然后,SAS软件将在每一层中独立选择样本。
PROC SURVEYSELECT要求输入数据集为按分层变量排序后的数据集。下面PROC SORT语句使Customers数据集按分层变量State和Type进行排序。

procsortdata=Customers;byStateType;run;
下面PROC FREQ语句显示customers数据集中State和Type两个变量所形成的交叉频数表。

title1'CustomerSatisfactionSurvey';title2'StrataofCustomers';procfreqdata=customers; tablesState*Type;run;
上面这段SAS程序被执行后,输出结果见表4。
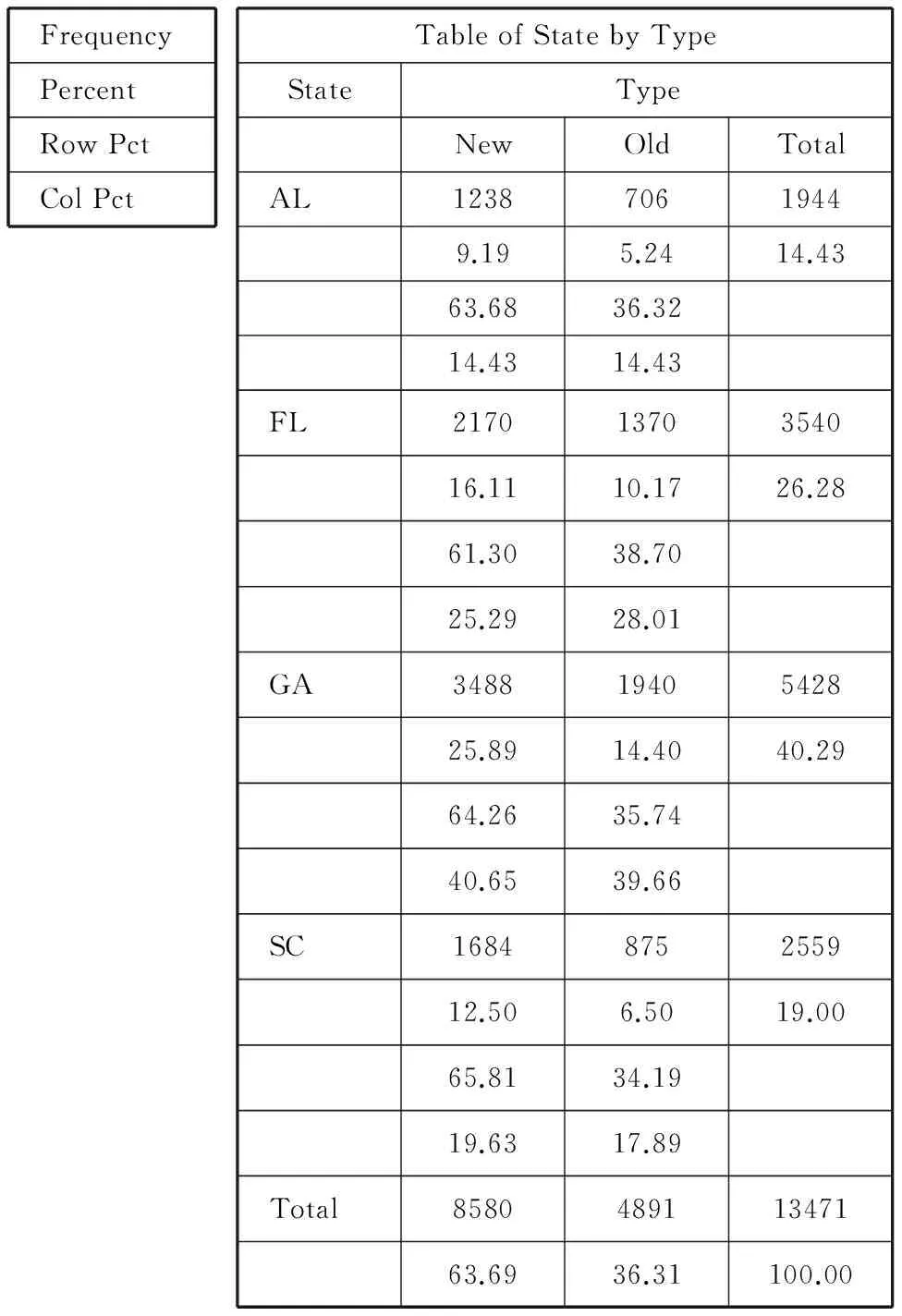
表4 数据集Customers按State和Type两变量形成交叉表后
表4给出了13471个客户按Type分组后再按State分组所形成的频数分布表。四个州和两类客户共形成8个层,每层中计算出4个数值,从上到下分别代表“频数”、“占全部客户数的百分比”、“占行合计的百分比”和“占列合计的百分比”。
下面PROC SURVEYSELECT语句根据State和Type两个变量进行分层随机抽样设计从Customers数据集按概率抽取一个客户样本。

title1'CustomerSatisfactionSurvey'; title2'StratifiedSampling'; procsurveyselectdata=customersmethod=srsn=15seed=1953out=samplestrata; stratastatetype; run;
【程序说明】strata语句声明分层变量为State和Type。在PROC SURVEYSELECT语句中,“method=srs”选项指定抽样方法为简单随机抽样;“n=15”选项指定每层抽取的样本大小为15位客户。如果想不同层指定不同样本大小,可以使用“n=SAS-data-set(即一个新数据集名)”选项来声明一个新数据集,该数据集包含每层样本大小。“seed=1953”选项指定“1953”为产生随机数的初始种子数。
上面这段SAS程序仅显示抽样情况的总结信息,一共有120位客户被抽取,因篇幅所限,有关分层随机抽样的总结信息从略。
下面PROC PRINT语句将显示分层随机抽样结果数据集samplestrata中前30个观测。

title1'CustomerSatisfactionSurvey';title2'SampleSelectedbyStratifiedDesign';title3'(First30Observations)';procprintdata=samplestrata(obs=30);run;
【程序说明】参见前面产生表1的SAS程序后面的“程序说明”,此处从略。
上面这段SAS程序被执行后,输出结果见表5。

表5 采用分层随机抽样从customers中随机抽取的120位客户中的前30位
注:因篇幅所限,仅显示出了前5位
表5显示了输出数据集samplestrata的前30个观测数据,samplestrata含有8个层,每层15位客户,一共有120位客户。变量SelectionProb指样本中每个客户被抽中的概率。由于在同一层中每位客户被抽中的概率相同,所以抽样概率等于层样本大小(15)除以该层的总样本含量之商。由于层间大小不同,所以抽样概率在不同层中是不一样的。变量SamplingWeight为抽样权重,抽样权重为抽样概率的倒数。
6 控制排序分层随机抽样及SAS实现[8]
下一个客户满意度调查抽样设计是按State分层,同时在层内按Type和Usage排序。在分层和控制排序后,在每一层中按系统随机抽样方法抽取客户。系统抽样加上抽样前控制排序使得样本的Type和Usage取值在每层(State)内是均匀分布的。下面PROC SURVEYSELECT语句根据这种设计从Customers数据集中按概率抽取客户样本。

title1'CustomerSatisfactionSurvey';title2'StratifiedSamplingwithControlSorting';procsurveyselectdata=Customersmethod=sysrate=.02 seed=1234out=SampleControl; strataState; controlTypeUsage;run;
【程序说明】 STRATA语句声明分层变量为State。CONTROL语句声明控制变量为Type和Usage。在PROC SURVEYSELECT语句中,“METHOD=SYS”选项指定抽样方法为系统随机抽样。“RATE=0.02”选项指定每层抽样率为0.02。“SEED=1234”选项指定产生随机数的初始种子数。
上面这段SAS程序仅显示抽样情况的总结信息,一共有271位客户被抽取,因篇幅所限,按State分层同时在层内按Type和Usage排序的总结信息和抽样结果(即采用PRINT过程输出数据集SampleControl的内容)均省略。
[1] 郭春雪, 胡良平. 正确把握精神卫生临床试验设计三要素的要领(Ⅰ)—受试对象[J]. 四川精神卫生, 2016, 28(3): 197-201.
[2] 胡完, 胡良平. 正确把握精神卫生临床试验设计三要素的要领(Ⅱ)—影响因素[J]. 四川精神卫生, 2016, 28(3): 202-206.
[3] 谷恒明, 胡良平. 正确把握精神卫生临床试验设计三要素的要领(Ⅲ)—观测指标[J]. 四川精神卫生, 2016, 28(3): 207-210.
[4] 杨孟渊, 胡良平. 精神卫生科研如何严格遵守试验设计四原则之随机原则[J]. 四川精神卫生, 2016, 29(4): 289-294.
[5] 沈宁, 胡良平. 精神卫生科研如何严格遵守试验设计四原则之对照原则[J]. 四川精神卫生, 2016, 29(4): 295-302.
[6] 张效嘉, 胡良平. 精神卫生科研如何严格遵守试验设计四原则之重复原则[J]. 四川精神卫生, 2016, 29(4): 303-306.
[7] 张效嘉, 胡良平. 精神卫生科研如何严格遵守试验设计四原则之均衡原则[J]. 四川精神卫生, 2016, 29(4): 307-310.
[8] SAS Institute Inc. SAS/STAT 9.3 User’s Guide[M]. Cary, NC: SAS Institute Inc, 2011: 7633-7704.
[9] 胡良平. 科研设计与统计分析[M]. 北京: 军事医学科学出版社, 2012: 206-227.
(本文编辑:陈 霞)
How to implement random sampling and application based on SAS software
HUWan1,HULiang-ping1,2*
(1.ConsultingCenterofBiomedicalStatistics,AcademyofMilitaryMedicalSciences,Beijing100850,China;2.SpecialtyCommitteeofClinicalScientificResearchStatisticsofWorldFederationofChineseMedicineSocieties,Beijing100029,China
HULiang-ping,E-mail:lphu812@sina.com)
The purpose of this article is to help readers to use SURVEYSELECT procedure in SAS software to implement random sampling fast and conveniently. Firstly, introducing SURVEYSELECT procedure and SAS data set customers. Then, introducing how to perform random sampling based on SAS combined with simple random sampling, stratified random sampling and control sorting stratified random sampling. The readers can finish their own random sampling task by using SAS software easily through modifying a few parameters in the SAS programs presented in this article. The fact is that despite the SAS software is very difficult to learn and use, but the users can solve many specific problems with a ready-made SAS program.
SAS software; SAS data set; SAS procedure; Simple random sampling; Stratified random sampling
R195.1
A doi:10.11886/j.issn.1007-3256.2016.05.002
2016-10-11)
