基于Spark的数据库增量准实时同步
2016-11-15王浩,葛昂,赵晴
王 浩,葛 昂,赵 晴
(华北计算机系统工程研究所,北京 100083)
基于Spark的数据库增量准实时同步
王 浩,葛 昂,赵 晴
(华北计算机系统工程研究所,北京 100083)
为了实现将传统关系型数据库中的增量数据快速导入同构或者异构目的库,在使用已有的增量提取方法的基础上,提出了通过增加并行度和流式计算的方法加快同步速度。此方法不仅支持插入、更新和删除的增量数据同步,而且可以抽取出数据库表结构信息动态支持表结构变更。与传统单点抽取方式相比,大大提高了目的库数据的新鲜度。
增量同步; Spark; 流式计算
0 引言
随着大数据技术的发展,越来越多的企业开始构建大数据平台进行数据处理。然而如何将保存在关系型数据库中的数据快速同步到大数据平台组件(例如HBase、HDFS)中,正成为很多企业面临的问题。Sqoop是常用的数据同步工具,其实质是MapReduce任务,延时较高,而且需要通过定时任务来达到自动化流程效果。本文在触发器记录数据变化的基础上,提出了一种使用Spark Streaming将增量数据抽取出来,然后根据需要写入到不同的目的库的方法。由于只提取增量数据,所以较Sqoop减少了数据量。另外由于是流式处理方式,降低了延时。
1 增量提取
1.1 增量提取的概念
增量提取是针对上一次提取而言,将上一次提取时间点到现在数据库中插入、更新、删除的数据提取出来[1]。
1.2 常用的增量提取方法
1.2.1基于业务系统日志
在业务中将数据库DML(Data Manipulation Language)语句输出以日志的方式存储,然后通过解析日志将DML语句在目的库中重放以达到目的。此方法需要侵入业务系统,对于已经成型的业务系统不适用。
1.2.2 基于数据库日志
解析数据库日志也能达到增量提取的目的,但是各大数据库厂商不对外开放数据库系统的日志格式,这就使得解析日志变成了问题。而且各数据库的日志格式还不尽相同,难以达到通用性。
1.2.3 基于触发器
基于触发器的方式,目前被广泛运用于数据库增量提取。它通过在源表上建立插入、更新、删除触发器来记录对数据的操作。每当有数据变化时,就会触发相应的触发器,然后运行触发器定义的逻辑,将变化记录到增量表。
1.3 基于触发器方法的具体实现
由于触发器方法具有实现逻辑简单,对业务无入侵,数据库通用等优点,所以本文采用了基于触发器方式的增量提取方法。具体实现方法如下:
(1)创建名为dml_log的数据库表,字段为id、table_name、record_id、execute_date、dml_type。其中id为自增id,table_name存储要同步的源表表名称,record_id是源表中发生变化的记录的唯一标识,execute_date为触发器执行时的时间戳,dml_type为I、U、D分别代表insert、update、delete操作。
(2)在源表上创建插入、更新、删除类型的触发器。创建语句在此省略。
2 构建Spark Streaming程序
2.1 Spark Streaming
Spark是目前大数据处理领域比较常用的计算框架。它将中间计算结果维护在内存中,这样不仅可以做到中间结果的重用,而且减少了磁盘IO,大大加快了计算速度。Spark Streaming是构建于Spark core之上的流式处理模块。其原理是将流式数据切分成一个个小的片段,以mini batch的形式来处理这一小部分数据,从而模拟流式计算达到准实时的效果。
2.2 JdbcRDD
弹性分布式数据集(Resilient Distributed Datasets,RDD),它是Spark数据抽象的基石。RDD是一个只读的分区记录集合,分区分散在各个计算节点[2]。RDD提供了transformation和action两类操作,其中transformation是lazy级别的,主要对数据处理流程进行标记,而不立即进行运算。action操作会触发作业的提交,然后进行回溯导致transformation操作进行运算。
JdbcRDD扩展自RDD,是RDD的子类。内部通过JDBC(Java Data Base Connectivity)操作以数据库为源头构建RDD。其构造函数签名为:
class JdbcRDD[T: ClassTag](
sc: SparkContext,
getConnection:()=> Connection,
sql: String,
lowerBound: Long,
upperBound: Long,
numPartitions: Int,
mapRow:(ResultSet) => T =
JdbcRDD.resultSetToObjectArray _)
extends RDD[T](sc,Nil) with Logging {…}
2.3 具体实现
Spark官方提供用于构建Spark Streaming的数据源没有对数据库进行支持,所以本文自己实现对数据库的支持。编写继承自InputDStream类的DirectJdbcInputDStream类,其签名为:
class DirectJdbcInputDStream[T: ClassTag](
@transient ssc_ : StreamingContext,
param: JdbcParam) extends
InputDStream[Row] (ssc_) with Logging {…}
对start()、compute()和stop()方法进行重写。
(1)在start函数中注册JDBC驱动,用于JDBC获取初始化信息(构造JdbcRDD时的参数);
(2)compute函数会被框架间隔指定的时间反复调用,其实质是如何返回一个JdbcRDD。首先通过JDBC获取本次需要拉取的trigger记录的id的上下界以及表的Schema信息;然后以这些信息为参数生成提取真实数据的SQL,其逻辑为用选中的trigger表中的记录和原表在record_id上进行左连接;最后使用该SQL当做参数构建JdbcRDD。值得说明的是,构建JdbcRDD时是可以指定并行度的,每个worker节点都会建立到数据库的JDBC连接,由多个节点并行去数据库拉取属于自己的那一部分数据,这就大大增加了提取和处理速度。
(3)在stop函数中关闭JDBC连接。总体来看,就是在driver程序中执行的JDBC程序获取初始化参数,在executor中执行的JDBC程序拉取真实的数据。
(4)编写driver程序:
val sc = new SparkContext(new SparkConf)
val ssc = new StreamingContext(sc,Seconds(30))
val directStream = new DirectJdbcInputDStream[Row](ssc,jdbcParam)
directStream.foreachRDD(rdd => {
…//对数据进行处理
})
2.4 限流
假设当前时间点到上次提取的时间点之间新增数据量太大,就会导致在新一次作业提交时,上一次的作业仍然没有完成,可能会因此造成作业积压使得系统不稳定。本文使用了基于规则的限流方法,综合考虑集群处理能力以及间隔时间,可以配置化设置每次最大提取条数。如果当前需要提取的数据条数大于最大提取条数,则本次就只提取最大条数,剩下的延时到下次再进行提取。这样做的好处是削减了峰流对系统造成的影响。
3 测试分析
测试环境:VMware虚拟机,处理器设置为4核心,2 GB内存, 64位CentOS 6.5操作系统,Spark 1.5.1,Oracle 11g。使用4台虚拟机搭建成Spark集群,1台为Master,3台为Worker。数据库表分别设置为20、40个字段,每次最大抽取记录数分别设置为10 000、50 000、500 000。将抽取出来的数据写成parquet格式的文件存储到hdfs上。测试结果如表1所示。
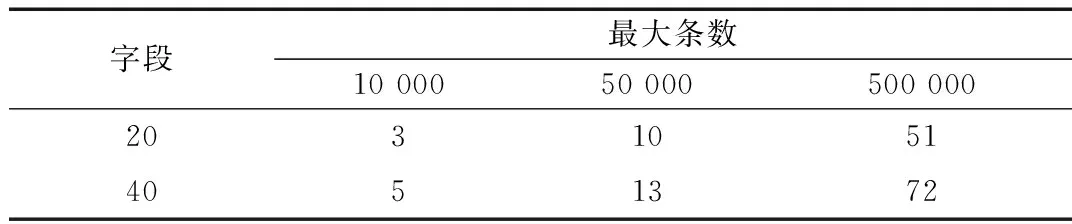
表1 运行时间 (单位:s)
4 结束语
本文在基于数据库触发器记录数据变化的基础上,通过自己构造DirectJdbcStream类提供Spark Streaming对数据库的支持,达到准实时从数据库中抽取出增量数据的目的。并且可以对抽取出来的数据进行过滤、清洗等操作,根据需求灵活地写入到不同的目的库。
[1] 郭亮.基于MD5与HASH的数据库增量提取算法及其应用[D].长沙:湖南大学,2013.
[2] ZAHARIA M, CHOWDHURY M,DAS T,et al.Resilient distributed datasets: a fault-tolerant abstraction for in-memory cluster computing[C].Usenix Conference on Networked Systems Design & Implementation,2012,70(2):141-146.
[3] DEAN J, GHEMAWAT S.MapReduce: simplified dataprocessing on large clusters[C].USENIX Association OSDI′04: 6th Symposium on Operating Systems Design and Implementation,2004:137-149.
[4] MARTIN O.Programming in scala[M].California: Artima Press,2010.
[5] YADAV R.Spark cookbook[M].UK: Packt Publishing Ltd,2015.
[6] KARAU H.Learning spark[M].America: O’Reilly Media,Inc.2015.
[7] 梁刚.企业大数据管理解决方案[J].微型机与应用,2013,32(24):7-10,13.
Spark-based database increment near-real-time synchronization
Wang Hao,Ge Ang,Zhao Qing
(National Computer System Engineering Research Institute of China,Beijing 100083,China)
In order to export incremental data stored in traditional database to homogeneous or heterogeneous destination,on the basis of existing incremental extraction method,we proposed a solution to speed up synchronization by increasing parallelism and using streaming instead of batch.This approach supports incremental data of inserting,updating and deleting,and can extract the database table schema information to support dynamic table structure changes.Compared with traditional single-point mode,it makes data more fresh.
increment extraction; Spark; streaming computing
TP311.1
A DOI:10.19358/j.issn.1674-7720.2016.19.002
王浩,葛昂,赵晴.基于Spark的数据库增量准实时同步[J].微型机与应用,2016,35(19):9-10,13.
2016-05-05)
王浩(1989-),男,硕士,主要研究方向:大数据。
葛昂(1972-),男,硕士,高级工程师,主要研究方向:企业软件架构、多维数据综合应用。
赵晴(1964-),男,学士,高级工程师,主要研究方向:工业控制物联网。
