基于MapReduce的CLOPE并行聚类算法
2016-11-12王玉平郝杨杨黄有方
王玉平,郝杨杨,黄有方
(1.上海海事大学信息化办公室, 上海201306; 2.上海海事大学物流研究中心, 上海201306)
基于MapReduce的CLOPE并行聚类算法
王玉平1,郝杨杨2,黄有方2
(1.上海海事大学信息化办公室, 上海201306; 2.上海海事大学物流研究中心, 上海201306)
事务型数据的CLOPE聚类算法在运行速度、内存开销和聚类效果方面表现优异,但随着数据量飞速增长,其运行时间也随之急剧变长甚至无法使用。为此,利用Hadoop框架下的YARN资源管理系统,对CLOPE算法进行改进,提出基于MapReduce架构的CLOPE并行聚类算法。该算法由两个阶段组成,第一阶段执行Map操作,Hadoop架构对数据集分片并行并运行CLOPE算法聚类成小聚簇;第二阶段执行Reduce操作,通过多次迭代把各个小聚簇聚合成大聚簇。实验结果证明:分析1 000条20 000个属性的亚马逊数据记录,MapReduce-CLOPE算法耗时稳定在22 s,而CLOPE算法耗时在50~60 s。随着数据量的增大,CLOPE算法无法计算而MapReduce-CLOPE算法耗时基本稳定。因此,MapReduce-CLOPE算法在计算时间方面要显著地优于CLOPE算法,且计算时间受数据量大小的影响较小,而在聚类质量方面与CLOPE算法相近。
数据挖掘;CLOPE;MapReduce;聚类算法;Hadoop
0 引 言
聚类是数据挖掘领域中的一种工具,它的作用是把数据对象集划分成多个组或簇的过程,使得簇内的对象具有很高的相似性,但又与其他簇中的对象很不相似。作为统计学的一个分支,聚类分析已经被广泛而深入的研究,成果主要集中在基于距离的聚类分析,如k-均值(k-means)、k-中心点(k-medoids)等方法。基于距离的聚类分析算法简单直接,擅长处理低维的数值数据。
然而,在现实生活中,存在大量的非数值型的标称事务数据,比如商场购物数据、域名访问数据和Web日志等等。由于这类数据维度较高且是标称数据,在数据量海量的情况下聚类速度显得很慢。关于事务型数据聚类算法的研究一直是热门的话题,目前已知的事务型数据聚类算法有很多种[1-5],其中CLOPE算法是在2002年问世,在运行速度、内存开销和聚类效果三方面都较其他算法优胜。CLOPE算法的时间复杂度是O(N×K×A),其中N代表记录个数,K代表每次迭代过程中产生的最大聚簇个数,A代表数据的维度。当数据量在海量情况下,不仅N值和K值均呈线性增长,而且迭代次数也将增加,造成算法的计算时间急剧增长。目前CLOPE算法后续的研究和改进工作并不多。Ong等[6]提出了SCLOPE算法用于对含有分类属性的数据流进行聚类操作,该算法的第一部分使用了一种数据流聚类框架,结合FP增长树构建小聚簇进行联机在线分析;第二部分采用第一部分产生的结果,结合CLOPE算法对小聚簇进行合并操作用于线下分析。随后,Ong等又在前面的基础上提出了改进版的σ-SCLOPE算法。这两种算法在处理低维数据时性能明显优于CLOPE算法。丁祥武等[7]在研究了CLOPE算法结果与数据输入顺序的敏感性问题后,提出了一种基于等分划分再排列思想的p-CLOPE大规模分类数据聚类算法。李洁等[8]提出了一种模糊CLOPE算法,然而在时间和空间开销方面缺乏对算法的性能进行评估。
作为一种处理大数据的分布式编程模型,Hadoop架构下的MapReduce框架[9]使得大数据量的计算工作能够在多台计算节点上并行执行,已经在数据挖掘领域得到广泛使用。一些经典的聚类算法比如k-means、Canopy、k-medoids以及普聚类已经在该框架下实现[10-12],并且在计算速度上获得了较大提升。刘永增等[13]研究了基于Hadoop平台对Web日志进行并行分析,充分证明了Hadoop平台下的MapReduce框架对于算法并行计算的可行性。
当数据量急剧增长时,无论是最原始的CLOPE算法,还是基于CLOPE的各种单机上的改进算法,都无法有效地提升聚类速度。研究表明,在MapReduce框架上实现的各种数值型聚类和分类算法[14-15]充分利用了并行性的特点,可以有效地提高算法计算速度。李晔锋等[16]设计了一种MR-CLOPE并行算法,引入多个MapReduce过程来计算,需要数据的进行序列化后导入导出,增加了复杂性,在一定程度上降低了算法可用性。
本文在总结以上算法的基础上,在YARN框架下对CLOPE算法进行了改进,提出了基于MapReduce架构的CLOPE并行聚类算法。实验结果证明:该算法在处理海量数据集时,在计算时间方面要显著地优于CLOPE算法,且计算时间受数据量大小的影响较小,而在聚类质量方面与CLOPE算法相近。
1 CLOPE算法
1.1 CLOPE算法
CLOPE算法通过分析聚簇的高度和宽度,从几何学上来评测聚类的质量。举例来说,给定一个小型的数据集,包含5个事务对象{ab,abc,acd,de,def}。对于该数据集,笔者尝试比较两种聚类的质量:{{ab,abc,acd}, {de,def}}和{{ab,abc}, {acd,de,def}},并构建相应的直方图如图1所示:

图1 两个聚簇的直方图
从图1中可以得到每个小聚簇的属性总数(S)、属性种类的个数(W,又称为直方图的宽度)和直方图的高度(H=S/W)。对于聚簇{ab,abc,acd},它的S=8,W=4,H=2,高宽比H/W=0.5,其余三个聚簇的高宽比分别是0.556、0.556和0.32。由于0.5+0.556>0.556+0.32,所以第一种聚类的质量要优于第二种聚类的质量。由此可见,当每个聚簇中重叠的属性越多,聚类的质量越好。下面描述一下CLOPE算法。
假设事务数据集D={t1,t2,…,tn}包含n个事务,每个事务都是项(或属性)的集合I={i1,i2,…,im},则有以下定义:
定义1 事务(Transaction) 数据集D中的一个事务t可以表示为二元组〈key,A〉,其中key为该事务的关键字,A={ia,ib,…,ik}⊆I为该事务中所含的属性集合。




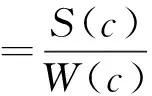

定义4 聚类(Clustering) 一个聚类C表示所有聚簇的集合,即C={c1,c2,…,ck}。
定义5 聚类的收益值评估函数,用下式表示:

由定义5可知,CLOPE算法的目标就是给定数据集D和排斥因子r,对其中的事务划分成聚簇,使得生成的聚类C达到最大的收益值,即聚类C为最优划分,并且本文还可以得到如下结论:
定理1 聚类的收益值仅与事务在各聚簇中的分布有关,与生成聚簇的数量无关。
证明 从定义5中可以看出,Profitr的分母实际上是一个常数,即数据集中事务的总数。当算法串行运行时,分母对聚类收益值没有任何影响,分子则表示事务在各聚簇中的分布情况,证毕。
CLOPE算法由两个阶段组成。第一阶段是初始化聚簇的过程,算法在向聚类中添加每一条事务时,将使用DeltaAdd函数对每个已有的聚簇进行比较,确定能够使聚类达到最大收益值的聚簇。第二阶段是迭代的过程,通过反复移动事务,使聚类的收益值达到最大。该阶段每次迭代会重新遍历数据集,并使用DeltaAdd函数与各聚簇分别进行比较。
1.2 CLOPE算法存在的问题
①CLOPE算法的时间开销非常大。整个算法的时间复杂度为O(N×K×A)。显然,当数据量增大,N值急剧增长时,对应的聚族数量K以及迭代次数也将相应增加,算法所产生的时间开销非常庞大。
②CLOPE算法结果与事务输入顺序有关。假设有一组事务{ab,bc,ac,abd,bcd,acd},并且设置排斥因子取值为2,通过CLOPE算法可得聚类结果{{ab,abd}, {bc,bcd}, {ac,acd}},其聚类收益函数分子值为(5×2÷32)×3≈3.33。若调整事务顺序为{abd,bcd,acd,ab,bc,ac},得到聚类{{abd,acd,ab,ac},{bcd,bc}},其聚类收益函数分子值为10×4÷42+5×2÷32=3.6111。由此可见,不同的事务顺序会导致不同的聚类结果,所以CLOPE算法与事务输入顺序有关。
③CLOPE算法在第二阶段每步操作只能移动一条事务,既限制了找出最大收益值的可能性,也降低了算法的执行效率。
2 基于MapReduce的CLOPE并行聚类算法
针对以上分析,笔者提出基于MapReduce的CLOPE并行聚类算法,通过引入MapReduce框架高度并行计算,提高总体事务型数据聚类的速度,减少时间开销,并用聚簇合并的方式实现多条事务并行移动,从而获得更大的计算效率。
算法按照MapReduce架构分成两个阶段进行。第一阶段执行map操作,Hadoop框架把输入数据集按照区块大小自动划分到多个Mapper任务中,每个Mapper任务独立执行CLOPE算法并生成一组带编号的聚簇,最后,分区(partition)任务根据编号对聚簇进行重新分区并传递给第二阶段。第一阶段不但在分片内减小了N值,而且使得CLOPE算法并行执行。第二阶段执行reduce操作,算法对第一阶段生成的聚簇进行合并操作,直到满足最优条件为止,最终输出到HDFS文件系统中。第二阶段以K取代N,进一步减小了算法的时间复杂度。
2.1 Map阶段
在起始状态,所有的事务型数据以文本的形式逐行存储在HDFS文件系统中。开始执行时,事务型数据被Hadoop根据区块大小自动划分成M个分片,分配给各个Mapper任务。任务中的map函数根据最大收益值原则把事务存放到最佳的聚簇中,而cleanup函数执行事务的移动操作,直到整个局部聚类达到最大收益值。该阶段分片聚簇并分区的伪代码如下文所示,全局变量中,InstanceList代表事务列表,ClusterList代表聚簇列表。
void map(key, value){
InstanceList.add(value)
AddInstanceToBestCluster(value);
}
void cleanup(context){
do{
moved = false;
for(instance in InstanceList){
if(MoveInstanceToBestCluster(instance))
moved = true;
}
}while(moved);
for(j=0 to ClusterList.size-1){
context.write(j, ClusterList[j]);
}
}
在该阶段,每个Mapper任务结束后都会生成一组聚簇传递给Reducer任务。假设Cm表示第m个Mapper任务产生的聚簇构成的子聚类,C表示所有聚簇构成的聚类,nm表示Cm中的事务数,n表示C中的事务数,并定义:

(1)
其中Cm={c1,c2,…,cj},则聚类的收益值为:
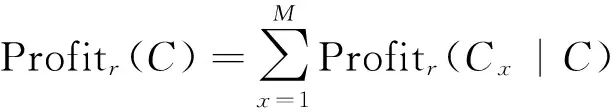
(2)
由此可以得出以下结论:
定理2 对任意的子聚类Cm以及事务t∈Cm和聚簇c⊂Cm并且t∉c,如果Profitr(Cm)已达到最大,则把t移动到c中必定不能使Profitr(Cm|C)值增大。
证明 根据式(1)可知,Profitr(Cm)和Profitr(Cm|C)的不同在于其分母,分别为nm和n不同,分子完全相同。根据定理1,由于Profitr(Cm)已达到局部最大值,因此其分子已达到最大值,对任意事务t∈Cm的移动操作均无法使其增大,证毕。
由于在第二阶段中聚簇的合并操作相当于事务集合的移动操作,定理2证明了来自同一个数据分片中的聚簇合并不会增加收益值,因此只要合并来自不同数据分片的聚簇才会使得整个聚类C的收益值增大。据此设计分区函数partition的输入包括聚簇编号(key)、聚簇(value)、Reducer任务数(R),输出Reducer任务的编号。MapReduce框架在Shuffle阶段把聚簇编号用R取模,结果相同的聚簇输出到对应的Reducer任务中,从而保证下一阶段合并操作的有效性。
2.2 Reduce阶段
根据定理1可知,聚类的收益值只跟其分子有关,由此可以得出以下推论:
推论1 对于聚簇ca,cb∈C,合并后的聚簇设为cc,则聚簇ca和cb可合并的充分条件为:

(3)
式(3)变形可得:
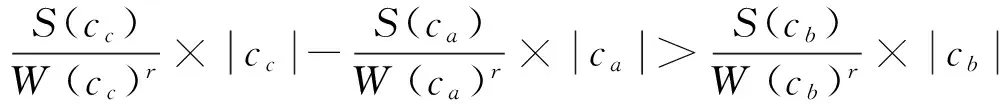
(4)
根据式(4),本文对原始CLOPE算法的DeltaAdd函数进行了扩展,使之能够实现聚簇合并前的判断操作。伪代码如下文所示,输入变量中,ca代表源聚簇,cb代表待合并聚簇。
double DeltaAddCluster(ca,cb,r){
S_new=S(ca)+S(cb);
W_new=W(ca);
N_new=N(ca)+N(cb);
for(item incb)
if(occ(item,ca)==NULL)W_new++;
retrunS_new×N_new/(W_new)r-S(ca)×N(ca)/W(ca)r;
}
推论2 当聚簇ca,cb满足式(4),并且DeltaAdd(ca,cb,r)达到最大值时,ca为cb的最佳可并入聚簇。
根据此推论,结合扩展后的DeltaAddCluster函数,设计了MergeClusterToBestCluster和MoveClusterToBestCluster函数,用于第二阶段每一次迭代的Reducer任务中。伪代码如下文所示,输入变量中,key代表聚簇编号,value代表分区后的聚簇列表;全局变量中,ClusterList代表待合并聚簇列表,MergedClusterList代表合并后的聚簇列表。
void reduce(key, Iterable
for(cluster in values){
MergeClusterToBestCluster(cluster);
}
}
void cleanup(context){
maxProfit=0;
do{
moved = false;
for(cluster in ClusterList){
if(MoveClusterToBestCluster(cluster)
moved = true;
}
if(moved){
if(profit <= maxProfit) moved=false;
else maxProfit = profit;
}
}while(moved);
for(j=0 to MergedClusterList.size-1){
context.write(j, ClusterList[j]);
}
}
由于聚簇的数量要远小于事务数量,且不需要再次循环属性计算,因而降低了该阶段的时间复杂度。在迭代过程中,由于CLOPE算法与事务的先后顺序有关,如果聚簇的移动带来的收益值不再增大则停止移动,或者某一次迭代过程中没有发生任何的聚簇合并操作时,算法终止。
3 实 验
实验使用的Hadoop集群包含1台NameNode主机和7台DataNode主机,每台主机的基本配置为Intel四核CPU、8 GB内存和256 GB硬盘,操作系统为CentOS 6.6,使用的Hadoop版本为2.6.3。实验共分为两组:第一组使用常用的、数据量和维度均较小的蘑菇数据集,第二组使用维度较高的Amazon访问数据集。
3.1 蘑菇数据集
蘑菇数据集是测试机器学习算法有效性的常用数据集,它的大小为364.9 KB,包含8 124条蘑菇数据,有22个属性。对于MapReduce框架来说,HDFS的最小块大小为16 MB,为了验证MapReduce-CLOPE算法的正确性,实验过程中人为的复制蘑菇数据集,增大数量为2 000 000个,文件大小为88 MB,如此可以划分为6个Map任务。
算法的性能测试如图2所示。在实验中,分别复制不同数量的蘑菇数据集,执行CLOPE算法和本文提出的基于MapReduce的CLOPE并行聚类算法(MapReduce-CLOPE算法),得出两个算法的执行时间。从实验结果来看,400 000个蘑菇数据是分界,超过这个值,也就是开始分布式计算时,MapReduce-CLOPE算法发挥优势,且时间与数据量的斜线角度非常小;而CLOPE算法则随着数据量的增加,耗费的时间急剧增加。实验结果表明,MapReduce-CLOPE算法在大数据量情况下计算性能优于CLOPE算法。
此外,MapReduce-CLOPE算法采用与CLOPE算法同样的精度测度方法,引入纯度的概念,通过累加每个聚簇中可食用蘑菇数和有毒蘑菇数中较大的值的和得到。在图3中,横坐标表示排斥因子(Repulsion),纵坐标表示纯度,每个柱状图代表在该排斥因子下的算法得出的聚簇的纯度总和。图3中的曲线代表当前排斥因子下通过MapReduce算法得出的聚簇数量,该数量与CLOPE计算结果比较,结果非常相近。在排斥因子超过或等于3的情况下,纯度为2 000 000,聚类结果完全正确。

图2 蘑菇数据集上的算法计算性能比较
Fig.2 Performance comparison on the mushroom dataset

图3 不同排斥因子下的纯度测量和聚簇个数
Fig.3 Purity and cluster number comparison at different repulsion values
实验经过多次计算,并比对纯度测定,在排斥因子大于等于3的情况下,算法划分的聚簇纯度都可以达到100%。但综合考虑,可以采用CLOPE算法,推荐排斥因子为2.6。
3.2 Amazon访问数据集
本实验采用了Amazon网站上来自某高校的访问记录(https://archive.ics.uci.edu/ml/datasets/Amazon+Access+Samples)。该数据集的属性有20 000个,记录数据30 000个,文件大小为3.9 GB。由于该数据集记录数较大,CLOPE算法无法计算。实验在测试仅含有10 000条记录集时,需要调整内存到32 GB, CLOPE算法才可以计算并且耗时5个多小时。为了便于比较,实验仅取前1 000条记录,文件大小为64 MB,既能运行CLOPE算法,又恰好可以分割为4份进行MapReduce-CLOPE算法。
实验首先根据不同的排斥因子进行耗时计算,实验结果如图4所示,在只有1 000条记录的情况下,MapReduce-CLOPE算法耗时稳定在22 s,而CLOPE算法耗时在50~60 s。也就是说算法的耗时与排斥因子的大小关系不大,因此,在以后的计算中可以选用3.0作为优先的排斥因子。
为了比较MapReduce-CLOPE算法与CLOPE算法结果是否一致,采用收益值作为两个算法比较的度量值。实验对比不同排斥因子下的收益值总和,结果如图5所示,两条折线几乎是重叠的,说明两个算法的结果近似于一致,因此可以采用MapReduce-CLOPE来替代CLOPE算法。
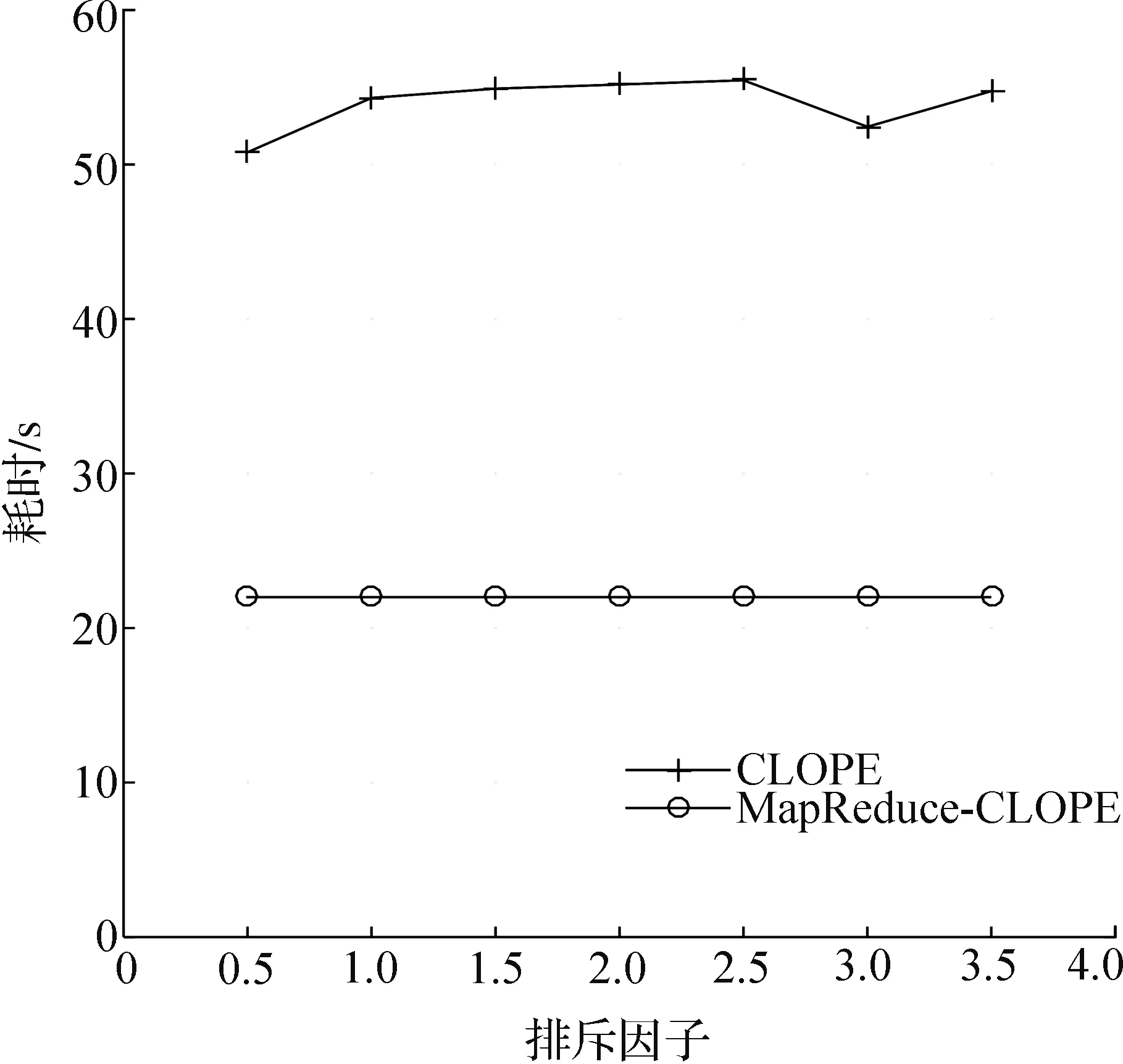
图4 Amazon访问数据集上的算法计算速度比较
Fig.4 Time comparison at different repulsion values using Amazon access log

图5 算法精度比较
Fig.5 Profit value comparison at different repulsion values using Amazon access log
4 结 论
本文利用Hadoop框架下的YARN资源管理系统的并行性优势,对CLOPE算法在大数据环境下进行改进,提出基于MapReduce架构的CLOPE并行聚类算法。该算法通过引入MapReduce框架高度并行计算,提高总体事务型数据聚类的速度,减少时间开销,并用聚簇合并的方式实现多条事务并行移动,从而获得更大的计算效率。实验结果表明,与传统的串行CLOPE算法相比,该算法在处理海量数据集时,在计算时间方面要显著地优于CLOPE算法,且计算时间受数据量大小的影响较小,而在聚类质量方面与CLOPE算法相近。如实验中分析1 000条20 000个属性的亚马逊数据记录,MapReduce-CLOPE算法耗时稳定在22 s,而CLOPE算法耗时在50~60 s。随着数据量的增大,CLOPE算法无法计算而MapReduce-CLOPE算法耗时基本稳定。
此外,本文还存在一些不足,比如CLOPE算法的质量与事务的先后顺序有关,以及在HDFS中数据块的大小影响到MapReduce的个数,算法最终的聚簇质量与个数的关系等问题是本文以后继续研究的方向。
[1] BAI L, LIANG J, DANG C, et al.A cluster centers initialization method for clustering categorical data[J]. Expert Systems with Applications, 2012,39(9):8022-8029.
[2] CHEN T, ZHANG N L, LIU T, et al.Model-based multidimensional clustering of categorical data[J]. Artificial Intelligence, 2012, 176(1): 2246-2269.
[3] IAM-ON N, BOONGEON T, GARRETT S, et al.A link-based cluster ensemble approach for categorical data clustering[J]. Knowledge and Data Engineering, IEEE Transactions, 2012, 24(3):413-425.
[4] JI J, PANG W, ZHOU C, et al.A fuzzy k-prototype clustering algorithm for mixed numeric and categorical data[J]. Knowledge-Based Systems, 2012, 30:129-135.
[5] YANG Y, GUAN X, YOU J.CLOPE: a fast and effective clustering algorithm for transactional data[C]//Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York, ACM, 2002: 682-687.
[6] ONG K L, LI W, NG W K, et al.SCLOPE: An algorithm for clustering data streams of categorical attributes[M]. Germany: Springer Berlin Heidelberg, 2004.
[7] 丁祥武,郭涛,王梅,等.一种大规模分类数据聚类算法及其并行实现[J]. 计算机研究与发展,2016,53(5):1063-1071.
[8] 李洁, 高新波, 焦李成.模糊CLOPE算法及其参数优选[J]. 控制与决策, 2004, 19(11):1250-1254.
[9] 陈全, 邓倩妮.云计算及其关键技术[J]. 计算机应用, 2009, 29(9):2562-2567.
[10]ZHAO W, MA H, HE Q.Parallelk-means clustering based on MapReduce[C]//Proceedings of the 1st International Conference on Cloud Computing. Germany: Springer-Verlag, 2009:674-679.
[11]牛怡晗,海沫.Hadoop平台下Mahout聚类算法的比较研究[J]. 计算机科学,2015,42(6A):465-469.
[12]李静滨,杨柳,陈宁江.基于MapReduce的改进K-Medoids并行算法[J]. 广西大学学报(自然科学版),2014,39(2):341-345.
[13]刘永增, 张晓景, 李先毅.基于Hadoop/Hive的web日志分析系统的设计[J]. 广西大学学报(自然科学版), 2011, 36(2):314-317.
[14]刘义,景宁,陈荦,等.MapReduce框架下基于R-树的k-近邻连接算法[J]. 软件学报,2013,24(8):1836-1851.
[15]HE Q, ZHUANG F, LI J, et al.Parallel implementation of classification algorithms based on MapReduce[M]. Germany: Springer Berlin Heidelberg, 2010: 655-662.
[16]李晔锋,乐嘉锦,王梅,等.MR-CLOPE: A Map Reduce based transactional clustering algorithm for DNS query log analysis[J]. Journal of Central South University,2015,22(9):3485-3494.
(责任编辑 梁碧芬)
A CLOPE parallel clustering algorithm based on MapReduce
WANG Yu-ping1, HAO Yang-yang2, HUANG You-fang2
(1.Infomation Office, Shanghai Maritime University, Shanghai 201306, China; 2.Logistics Research Center, Shanghai Maritime University, Shanghai 201306, China)
A CLOPE parallel algorithm based on MapReduce (MapReduce-CLOPE) is presented in this paper. The algorithm consists of two phases:. In the first phase, the large datasets on Hadoop are split into multiple small data blocks by Map operations. and the CLOPE algorithm is executed on each data block in parallel to form small clusters. In the second phase, the algorithm will merge the small clusters into multiple large clusters through multiple iterations, by executing Reduce operations. The experiments show that it takes 22 seconds steadily in MapReduce-CLOPE algorithm when analyzing 1 000 Amazon data records of 20 000 attributes, while it takes between 50 and 60 seconds in CLOPE algorithm. With the data volume increasing, CLOPE algorithm cannot finish the calculation, however, MapReduce-CLOPE algorithm can get the calculation with stable time. Therefore, MapReduce-CLOPE algorithm is superior significantly than CLOPE algorithm in the time and the influence of data volume, and it’s close to CLOPE algorithm in clustering quality.
data mining; CLOPE; MapReduce; clustering algorithm; Hadoop
2016-04-11;
2016-05-12
国家自然科学基金资助项目(71301101);交通运输部建设科技项目(2015328810160);上海市科委重点项目(14DZ2280200)
黄有方(1959—),男,上海人,上海海事大学教授,博士生导师;E-mail:yhuang@shmtu.edu.cn。
王玉平,郝杨杨,黄有方.基于MapReduce的CLOPE并行聚类算法[J].广西大学学报(自然科学版),2016,41(5):1567-1575.
10.13624/j.cnki.issn.1001-7445.2016.1567
TP311
A
1001-7445(2016)05-1567-09
