一种改进的有监督训练的TV语种识别方法
2016-11-09张翼飞腾潇琦
张翼飞 腾潇琦
1(上海大学机电工程与自动化学院 上海 200072)2(讯飞智元信息科技有限公司 安徽 合肥 230088)3(北京市互联网信息办公室 北京 100062)
一种改进的有监督训练的TV语种识别方法
张翼飞1,2腾潇琦3
1(上海大学机电工程与自动化学院上海 200072)2(讯飞智元信息科技有限公司安徽 合肥 230088)3(北京市互联网信息办公室北京 100062)
传统的GMM-TV(Gaussian Mixture Model-Total Variability,又称为i-vector)系统得益于它良好的识别效果以及优秀的识别效率,在语种识别LID(language identification)中得到广泛应用,然而载荷矩阵T的训练过程是无监督的,使得它的分类空间并没有得到最好的优化。已有的有监督TV(Supervised-TV,S-TV)算法,通过在均值超矢量上拼接一个带有标签信息的向量,使得T矩阵的训练过程变成一个有监督的过程,但是效果增长较弱,同时带来了载荷矩阵自由度问题。提出一种改进的有监督训练方法,在目标函数中引入正则化项来解决自由度的问题,同时大大提升它的分类效果。该方法在NIST LRE09的30s数据集实验中得到了很好的效果,等错误率EER(Equal Error Rate)从5.40%下降到4.96%,融合系统的EER达到了3.86%。
语种识别TV系统有监督训练载荷矩阵
0 引 言
语种识别LID是通过对给定的一段语音信号分析处理,识别其所属语言的种类。它往往作为语音识别和其他相关应用的一个前端处理技术,是在语音识别基础上发展起来的[1]。随着全球化趋势和国际互联网的发展,人们更加迫切地希望可以突破语言的障碍进行交流,因而对于语种识别技术的需求也与日俱增,比如音频和视频信息检索、自动机器翻译、电话自动转接、多语种语音识别和智能监测等。不仅如此,语种识别还广泛应用于军事、国家安全和各个信息产业领域,具有极为重要的应用价值和前景。
目前主流的LID方法有很多,但国际主流的方法都是以GMM-TV[2-4]为基础的,这主要得益于GMM-TV系统优秀的识别效率和良好的识别效果。然而传统的T矩阵的训练是无监督的过程,这就使得它的分类空间并没有得到最好的优化。2014年李明提出了一种有监督的TV系统S-TV[5]。该方法在原TV系统的基础上,在均值超矢量上拼接了一个带标签的语种标识向量,使得T矩阵的训练过程融入了监督信息,以此来增加T矩阵的区分性。实验结果表明,该方法在传统的TV系统基线上有一定的提升。
然而S-TV系统在迭代过程中T和W的方差不断地在增大,尤其在迭代了5次以后,方差的增大幅度在10倍以上,远远超过了传统TV系统中T矩阵方差的增长速度。而我们需要的是尽量收敛的T矩阵,于是本文对S-TV做了小小的改进,通过增加正则化项来抑制T和W矩阵的增长幅度,使得识别效果得到了很大的提升。在NIST LRE09数据集上,此方法取得了较好的效果。
1 传统TV系统
给定混合度为C的UBM模型λ,C个分量λc={wc,uc,Σc}。假设一条语音有L帧,它的特征序列为{x1,x2,…,xL},并且每个特征xi的维度为D,根据文献[4]:
z=(I+TtΣ-1NT)-1TtΣ-1Ny
(1)
其中z就是i-vector,维度为K。Σ为CD×CD维的协方差对角阵。N是一个CD×CD维的对角阵,并且由C个子块NcI构成,Nc为D×D维的对角阵,且所有元素都相同,它的值由下式确定:
(2)
其中,P(c|xt,λ)为xt在λc上的占有率。y是均值超矢量,它由C个分量构成:
(3)
于是y可以通过CD×K维的矩阵T映射到K维的空间上:
y→Tz
(4)
在通过式(1)得到i-vector之后,经过LDA并计算cosine距离即可实现分类。
2 有监督的TV系统
为了让i-vector具有更好的区分性,文献[5]中的有监督TV在基线TV的均值超矢量后面加上了一个语种标识向量,语种标识向量的维度M等于语种的类别数。假设第j条语音的语种标识向量为Lj=(Lj1,Lj2,…,LjM)T,则有:
(5)
如图1所示,将M维的L拼接在CD维的均值超矢量后面,构成一条(CD+M)维的超矢量,同样在T矩阵下方拼接一个M×K的W矩阵,构成一个(CD+M)×K的矩阵。这样超矢量就代入了监督信息,并且参与了T矩阵的训练,使最后得到的i-vector的区分性更强。
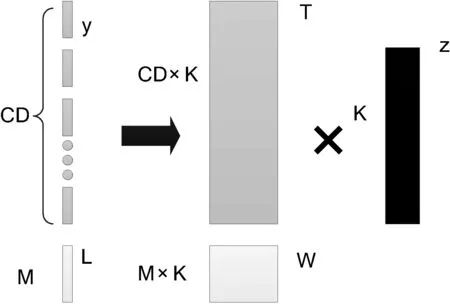
图1 S-TV结构图
类似于传统TV系统,假设zj服从于标准正态分布,则有:
P(zj)=N(0,I)
(6)
(7)
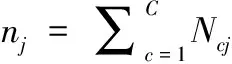
(8)
结合式(7)、式(8),通过简化操作得到优化函数,可以看出,EM算法的目标在于最小化J:
(9)
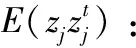
(10)
(11)
在M步骤,通过最小化上述函数J后可得W和T的更新公式:
(12)
(13)
式中,Tc是T矩阵在第c个高斯上的分量,ycj是yj在第c个高斯上的分量。
经过几次EM迭代后,T和W矩阵的参数会得到很好的修正。后面的提取i-vector阶段,利用修正的矩阵,采用传统的TV方法进行i-vector估计即可。
3 改进的有监督TV系统
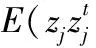
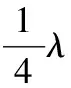
(14)
则最终的更新公式变为:
(15)
(16)
实验证明,加入正则化项后,成功抑制住了W和T矩阵过大的增长趋势,并且使得Supervised-TV的效果有了很大的提升。
4 实 验
4.1数据和参数
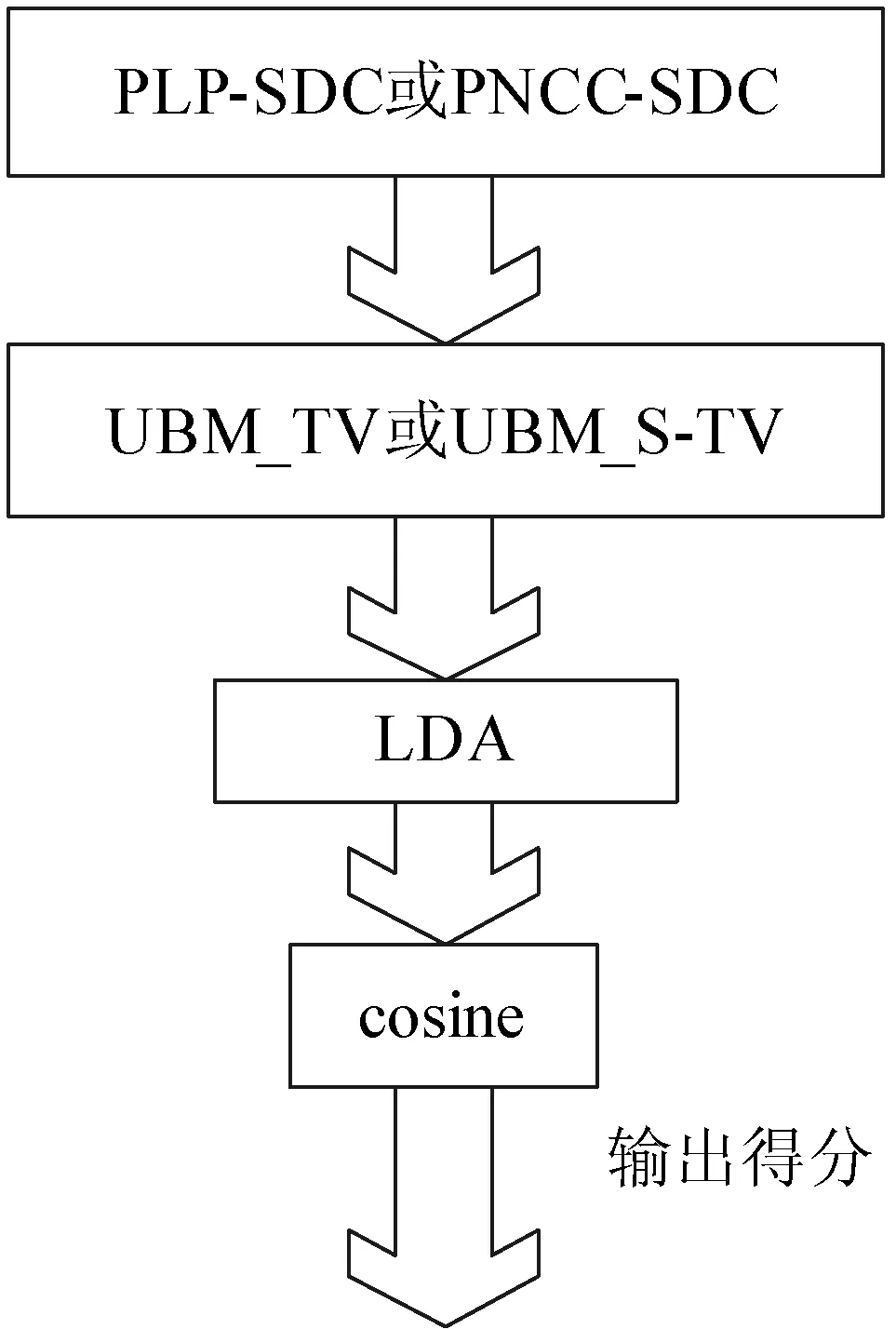
图2 LID测试流程
本次实验选用了NIST LRE09的30s数据集合,该集合有24个语种。特征选用了PLP-SDC特征[6]和PNCC-SDC特征[7,8],UBM的维度为512,i-vector维度为300。在开发集上,对S-TV的一些参数进行了调优,正则化项系数λ的值取1000,初始的W矩阵为随机生成,并且它的值服从均值为0,方差为1×10-6的高斯分布。后端采用LDA+cosine距离的组合,LDA矩阵的维度为300×23。整个测试系统如图2所示。
4.2实验结果与结论
首先看正则化项对优化函数J的影响。目标函数采用式(9),特征为PLP-SDC特征,我们取出迭代5次中的每一代结果,分别统计出相同的6条语音的目标函数J之和放在表1中。

表1 目标函数
从表1可以看出,带正则化项后的S-TV对目标函数J的优化更好,理论上会得到更好的结果。实验结果证明了我们的猜想,表2展示了正则化项对实验结果的影响。
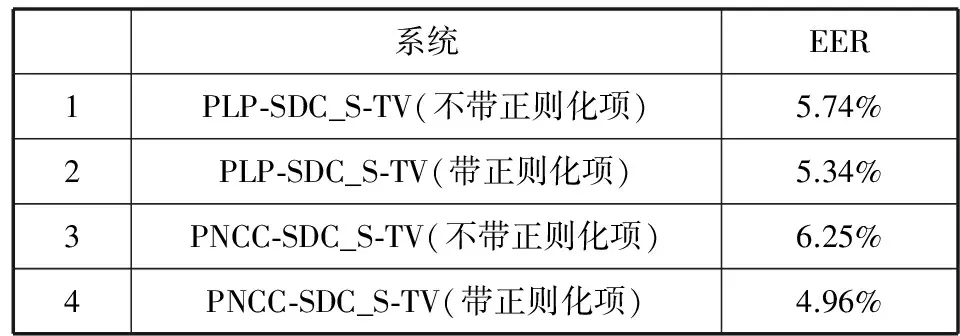
表2 不同配置下的S-TV系统结果
对比表2各项,正则化项对S-TV的提升很明显,特别是在使用PNCC-SDC特征时。表3对比了基线和S-TV的单系统效果(S-TV系统均是带正则化项的),图3是它们的DET曲线。
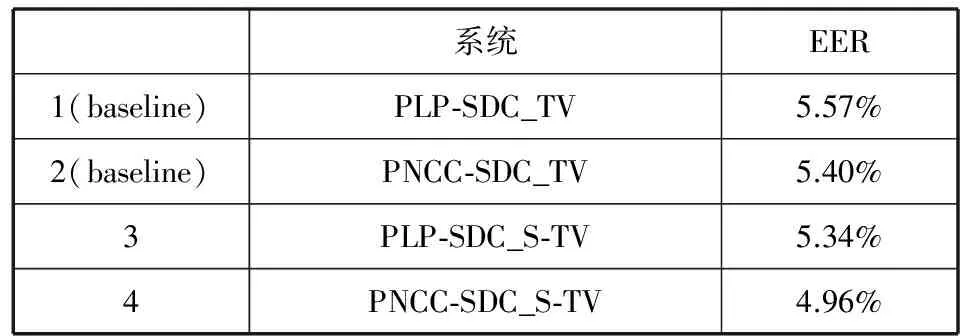
表3 各单系统结果
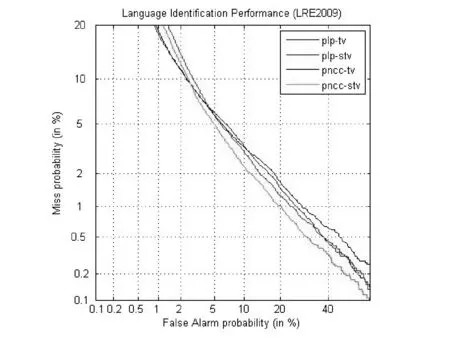
图3 单系统的DET曲线
从以上结果可以得出结论,单系统中,PNCC-SDC特征整体上优于PLP-SDC特征,并且在使用PNCC-SDC特征时,S-TV令基线系统的EER从5.40%下降到4.96%,效果相对提升达到了8.15%。
表4展示了各种融合系统的效果,可以看出,融合系统的效果有很显著的提升,说明PNCC-SDC特征和 PLP-SDC特征以及S-TV和TV的互补性都较强。当四个单系统融合时,EER达到了3.86%的最小值。

表4 融合系统结果
在效率方面,文献[5]给出了TV和S-TV的时间复杂度,分别为O(K3+K2C+KCD)和O(K3+K2C+K(CD+M))。在一般情况下,M< 表5 改进S-TV与传统TV的效率对比 本文在GMM-TV系统以及已有的有监督训练的TV系统下,提出了一种改进的有监督训练TV系统,在原本训练T矩阵的基础上给训练数据增加标识向量来增加T空间的区分性,同时在目标函数中引入正则化项,来控制空间训练的自由度。实验结果表明,此方法在不影响效率的情况下有效地提高了语种识别的效果,在NIST LRE09数据集合上,所提出的融合系统相比基线系统提升非常明显。本文方法为模型域层面的改进,可以用于国际主流的Bottleneck特征[9]中。 [1] 付强.基于高斯混合模型的语种识别的研究[D].中国科学技术大学,2009. [2] 郭武.复杂信道下的说话人识别[D].中国科学技术大学,2007. [3] Dehak N,Kenny P,Dehak R,et al.Front-End Factor Analysis for Speaker Verification[J].Audio Speech & Language Processing IEEE Transactions on,2011,19(4):788-798. [4] Kenny P.Joint factor analysis of speaker and session variability:Theory and algorithm[R].Technical report CRIM-06/08-13,CRIM,2006. [5] Li ming,Shrikanth Narayanan.Simplified Supervised I-vector Modeling with Application to Robust and Efficient Language Identification and Speaker Verification[J].Computer Speech & Language,2014,28(4):940-958. [6] Kohler M A,Kennedy M.Language identification using shifted delta cepstra[C]//Circuits and Systems,2002.MWSCAS-2002.The 2002 45th Midwest Symposium on.IEEE,2002:III-69-72. [7] Kim C,Stern R M.Feature extraction for robust speech recognition using a power-law nonlinearity and power-bias subtraction[J].Interspeech,2009:28-31. [8] Kim C,Stern R M.Power-Normalized Cepstral Coefficients (PNCC) for robust speech recognition[C]//2012 IEEE International Conference on Acoustics,Speech and Signal Processing(ICASSP),2012,22(10):4101-4104. [9] Jiang Bing,Song yan,Wei si,et al.Deep Bottleneck Features for Spoken Language Identification[J].PLOS ONE,2014,9(7):e100795. AN IMPROVED LANGUAGE IDENTIFICATION METHOD USING SUPERVISED TOTAL VARIABILITY Zhang Yifei1,2Teng Xiaoqi3 1(School of Mechatronics Engineering and Automation,Shanghai University,Shanghai 200072,China)2(IflytekIntelligentSystemCo.,Ltd,Hefei230088,Anhui,China)3(TheOfficeofInternetInformation,Beijing100062,China) Traditional GMM-TV (Gaussian mixture model-total variability) system is benefited from its good recognition effect and excellent recognition efficiency, and has been widely used in language identification (LID). However the training process of load matrix T is unsupervised, this leads to its classification space not being optimised the best. Existing supervised-TV (S-TV) algorithm, through stitching a vector with tag information on mean super vector, makes the training process of T matrix become a supervised process, but it only achieves a little performance gain while introduces the problem of load matrix’s freedom. In this paper we propose an improved S-TV method which puts a regularisation item into the objective function for solving the freedom problem and meanwhile greatly improves its classification effect. The improved system achieves excellent effect in the experiment on 30s dataset of NIST LRE2009, the equal error rate (EER) reduces to 4.96% from 5.40% and the fusion system’s EER has even reached 3.86%. Language identificationTV systemSupervised trainingLoad matrix 2015-05-20。北京市科委项目(Z141100006014002)。张翼飞,硕士生,主研领域:声纹语种识别。腾潇琦,硕士生。 TP3 A 10.3969/j.issn.1000-386x.2016.09.038
5 结 语
