基于模糊核聚类的多模式情感识别算法研究
2016-11-09韩志艳王健
韩志艳,王健
(渤海大学 辽宁 锦州121000)
基于模糊核聚类的多模式情感识别算法研究
韩志艳,王健
(渤海大学 辽宁 锦州121000)
为了克服单模式情感识别存在的局限性,该文以语音信号和面部表情信号为研究对象,提出了一种新型的多模式情感识别算法,实现对喜悦、愤怒、惊奇和悲伤4种人类基本情感的识别。首先,将获取的信号进行预处理并提取情感特征参数,然后利用模糊核聚类算法对其进行聚类分析,即利用Mercer核,将原始空间通过非线性映射到高维特征空间,在高维特征空间中对多模式情感特征进行模糊核聚类分析。由于经过了核函数的映射,使原来没有显现的特征突现出来。实验结果验证了该方法的可行性和有效性。
多模式情感识别;语音信号;面部表情信号;模糊核聚类
近年来,情感识别的研究工作在人机交互领域中已经成为一个热点问题。国内外情感识别的研究主要有两大类,一类是单模式情感识别,另一类是多模式情感识别。所谓单模式情感识别为只从单一信息通道中获得当前对象的情感状态,如从语音信号、面部表情信号或生理信号(血压、体温、脉搏、心电、脑电、皮肤电阻等)等。对于语音情感识别,1990年麻省理工大学多媒体实验室构造了一个“情感编辑器”对外界各种情感信号进行采样来识别各种情感,并让机器对各种情感做出适当的反应。北京航空航天大学的毛峡[1]通过用相关密度和分形维数作为情感特征参数来进行语音情感识别,获得了较好的性能。Attabi等[2]将锚模型的思想应用到了语音情感识别中,改进了识别系统的性能。Zheng等[3]通过对传统的最小二乘回归算法进行改进,提出了不完稀疏最小二乘回归算法,能同时对标记和未标记语音数据进行情感识别。Mao等[4]通过使用卷积神经网络来选择对情感有显著影响的特征,取得了很好的效果。对于面部表情识别,1978年开发出了面部动作编码系统(Facial Action Coding System,FACS)来检测面部表情的细微变化。1997年提出了基于视频的动态表情描述方法FACS+,解决了FACS中没有时间描述信息的问题。Rahulamathavan等[5]利用局部Fisher判别分析对加密面部表情信号进行了识别研究。中国科学技术大学的文沁等[6]提出一种基于三维数据的人脸情感识别方法,给出了基于三维特征的眼角和嘴角新的提取算法。Zheng等[7]提出了基于组稀疏降秩回归的多视角面部表情识别方法,能够从多尺度子域中自动选择出对情感识别贡献最大的子域。对于生理信号情感识别,Petrantonakis等[8]采用高阶过零技术(Higher order crossing,HOC)提取脑电波信号中的情感信息来进行情感识别。Zacharatos等[9]分析研究了身体姿势和动作对情感识别的重要性。
虽然单一地依靠语音信号、面部表情信号和生理参数来进行情感识别的研究取得了一定的成果,但却存在着很多局限性,因为人类是通过多模式的方式表达情感信息的,它具有表达的复杂性和文化的相对性。比如,在噪声环境下,当某一个通道的特征受到干扰或缺失时,多模式方法能在某种程度上产生互补的效应,弥补了单模式的不足,所以研究多模式情感识别的方法十分必要。如Kim等[10]融合了肌动电流、心电、皮肤电导和呼吸4个通道的生理参数,并采用听音乐的方式来诱发情感,实现了对积极和消极两大类情感的高效识别。东南大学的赵力、黄程韦等[11]通过融合语音信号与心电信号进行了多模式情感识别,获得较高的融合识别率。但是上述方法均为与生理信号相融合,而生理信号的测量必须与身体接触,因此对于此通道的信号获取有一定的困难,所以语音和面部表情作为两种最为主要的表征情感的方式,得到了广泛的研究。Hoch等[12]通过融合语音与表情信息,在车载环境下进行了正面(愉快)、负面(愤怒)与平静等3种情感状态的识别。Sayedelahl等[13]通过加权线性组合的方式在决策层对音视频信息中的情感特征进行融合识别。从一定意义上说,不同信道信息的融合是多模式情感识别研究的瓶颈问题,它直接关系到情感识别的准确性。聚类属于非监督模式识别问题,其特点是输入空间的样本没有期望输出。比较经典的聚类方法有传统的C-均值方法和模糊C-均值聚类方法,这些方法都没有对样本的特征进行优化,而是直接利用样本的特征进行聚类,这样上述这些方法的有效性很大程度上取决于样本的分布情况。Grolami[14]在结合核方法和聚类算法方面做了开创性的工作,他通过把模式空间的数据非线性映射到高维特征空间,增加了模式的线性可分概率,在高维特征空间达到线性可聚的目的。
因此,文中以语音信号和面部表情信号为基础,提出了一种基于模糊核聚类的多模式情感识别算法,对喜悦、愤怒、惊奇和悲伤4种人类基本情感进行识别。
1 情感信号预处理
通过噪声刺激和观看影视片段等诱发方式采集相应情感状态下的语音信号和面部表情信号,并将二者绑定存储。对于语音数据,在提取特征之前要进行一阶数字预加重、分帧、加汉明窗和端点检测等预处理。对于面部表情数据,在提取特征之前要首先用肤色模型进行脸部定位,然后进行图像几何特性归一化处理和图像光学特性的归一化处理,其中图像几何特性归一化主要以两眼位置为依据,而图像光学特性的归一化处理包括先用直方图均衡化方法对图像灰度做拉伸,以改善图像的对比度,然后对图像像素灰度值进行归一化处理,使标准人脸图像的像素灰度值为0,方差为1,如此可以部分消除光照对识别结果的影响。
2 参数提取
2.1 语音情感参数提取
以往对情感特征参数的有效提取主要以韵律特征为主,然而近年来通过深入研究发现,音质特征和韵律特征相互结合才能更准确地识别情感。研究发现,音质类特征对于区分激活维接近的情感有较好的效果,证实了共振峰等音质类特征与效价维度的相关性较强。
为了尽可能地利用语音信号中所包含的有关情感方面的信息,我们选取了语句发音持续时间与相应的平静语句持续时间的比值、基音频率平均值、基音频率最大值、基音频率平均值与相应平静语句的基音频率平均值的差值、基音频率最大值与相应平静语句的基音频率最大值的差值、振幅平均能量、振幅能量的动态范围、振幅平均能量与相应平静语句的振幅平均能量的差值、振幅能量动态范围与相应平静语句的振幅能量动态范围的差值、第一共振峰频率的平均值、第二共振峰频率的平均值、第三共振峰频率的平均值、谐波噪声比的均值、谐波噪声比的最大值、谐波噪声比的最小值、谐波噪声比的方差作为情感识别用的特征参数。
2.2 面部表情参数提取
目前面部表情特征的提取根据图像性质的不同可分为静态图像特征提取和序列图像特征提取,静态图像中提取的是表情的形变特征,而序列图像特征是运动特征。文中以静态图像为研究对象,采用Gabor小波变换来提取面部表情参数。具体过程如下:
1)将预处理后的人脸图像进行网格化,网格化为25×25像素,所以每张脸共有4行3列共12个网格。
2)将网格化后的图像和Gabor小波进行卷积,其公式如下:
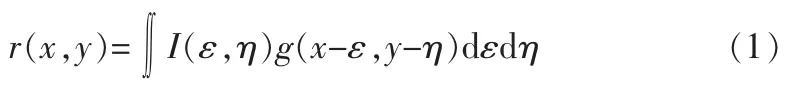
3)取‖r(x,y)‖的均值和方差作为面部表情参数;
4)用主成分分析法PCA对上述特征进行降维处理,获得的面部表情特征参数作为特征融合的特征参数。
3 算法描述
3.1 核方法
近年来,核方法已经成为机器学习研究的热点之一。核方法的基本思想是把输入空间的非线性样本映射到高维特征空间使之线性化,在高维空间中设计线性学习算法。但是高维特征空间的映射会使计算量成指数倍增长,因此通常利用Mercer核技巧来解决非线性变换带来的“维数灾难”问题[15]。
假设输入空间的样本xk,k=1,2,…,N被某种非线性映射Φ(·)映射到某一特征空间H得到Φ(x1),Φ(x2),…,Φ(xN)。那么在特征空间就可以用Mercer核来表示输入空间的点积形式:
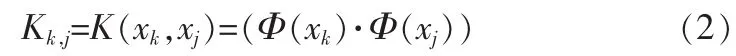
对任意的平方可积函数g(x),都满足:
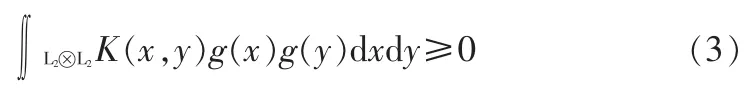
则就可以找到核函数K的特征函数和特征值,(Φi(x),λi),相应的核函数可以写成:
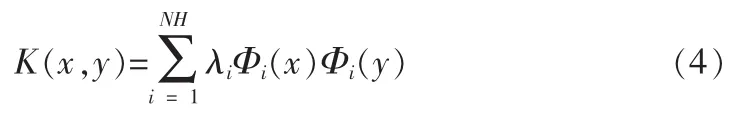
其中NH是特征空间维数,非线性映射函数可写成:
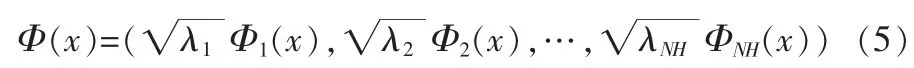
这样由式(4)和式(5),就可以得到式(2)。
常用的Mercer核函数有sigmoid核函数、多项式核函数和高斯核函数。目前还没有一个通用的标准来选择核函数,但由于高斯核函数所对应的特征空间是无穷维的,有限的样本在该特征空间中肯定是线性可分的,因此文中选用高斯核函数:
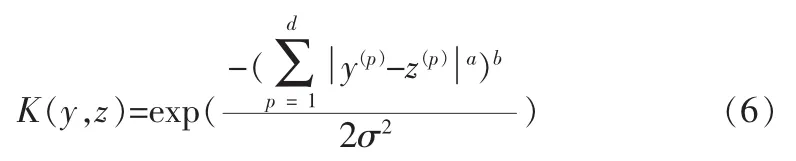
其中y(p)为矢量y的第p维分量,z(p)为矢量z的第p维分量,p=1,…,d,d为矢量的维数,σ为高斯核函数的宽度。通常采用欧式范数时,取a=2,b=1。
3.2 模糊核聚类算法
令X={x1,x2,…,xN}为输入模式空间Rd中的一个有限数据集,xk是维数为d的模式矢量。依照核方法的思想,利用非线性映射Φ(·)将输入模式空间变换到一个高维特征空间,在该高维特征空间扩展模糊C-均值算法,其目标函数为:
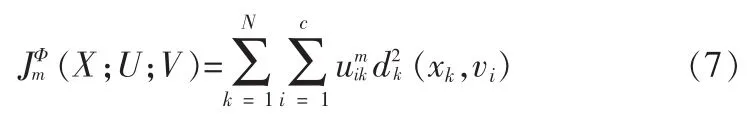
其中U=[uik],i=1,…c;k=1,N为模糊隶属度函数矩阵。V={v1,v2,…vc}是第i类的模式原型或聚类中心。m>1是模糊加权指数。利用Mercer核的性质,目标函数中模式矢量xk与vi在特征空间中的Euclid距离表示为:
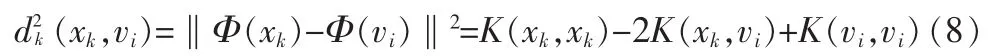
则在特征空间中的目标函数就可以写为:
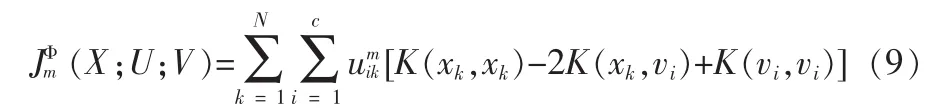
特征空间中的隶属度函数满足:
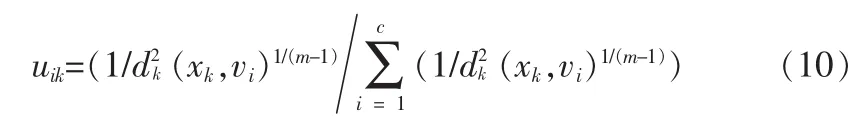
在特征空间Rq中新的类中心为:
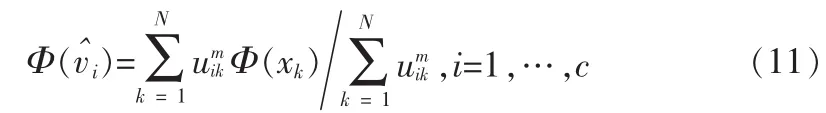
可计算得:
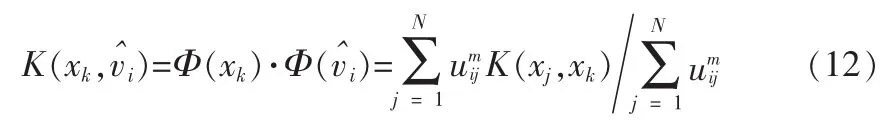
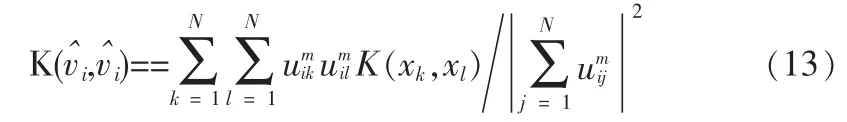
其中xk,xl∈X,j=1,…,N,l=1,…,N为模式矢量。所以在特征空间新隶属度函数uik更新为:
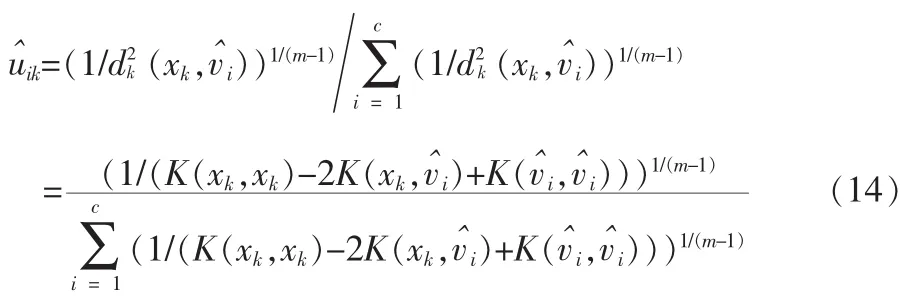
从上式可以看出,可以通过对两个核函数K(xk,)和K()的更新来完成对隶属度函数的更新,而不需要更新类的中心,因此大大减少了计算量。
本算法的具体实现过程为:
步骤1:选择类数c、迭代终止条件ε∈(0,1)及迭代次数T;
步骤2:选择核函数K及其参数;
步骤3:初始化类中心vi,i=1,…,c;
步骤4:利用式(10)计算每个样本在特征空间的隶属度函数;
步骤5:利用式(12)、(13)计算核函数,并按式(14)更新隶属度;
4 仿真实验及结果分析
实验中获取的语音信号采样频率是11.025 kHz,量化精度是16 bit;面部表情信号则是通过摄像机拍摄,每幅图像大小为256×256像素。
4.1 不同高斯核宽度对系统性能的影响
在该算法中核函数的计算对系统性能会有较大的影响。图1给出了系统错聚率随高斯核函数的变化曲线。
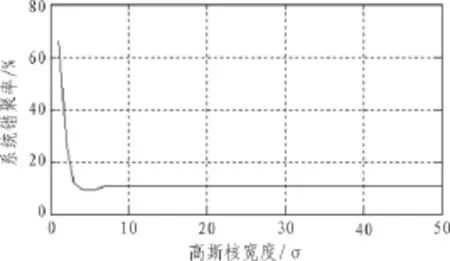
图1 系统错聚率随核宽度的变化曲线图
从图1可以看出,当高斯核宽度σ<5时,系统错聚率随σ着的增大而迅速减小。当σ=5时,错聚率是最小的。但当σ>5时,错聚率却有所提高,在σ≥7时错聚率基本保持恒定。这主要是由于随着σ的增大或减小,就越接近1或0,从而使(xk,vi)就越接近于0,此时特征空间中矢量之间的可区分性减少,导致了聚类效果的下降。
4.2 算法结果比较
为了验证该算法的可行性和有效性,我们对σ=5时3种聚类算法进行了比较研究。同时为了证明该文方法的识别效果,将单模式条件下的识别结果与多模式条件下的识别结果进行了对比。我们对样本集进行了10次试验,表1为仅通过语音信号进行聚类的对比结果;表2为仅通过面部表情信号进行聚类的对比结果;表3为在多模式条件下,通过用该文方法进行聚类的对比结果。

表1 仅通过语音信号进行聚类
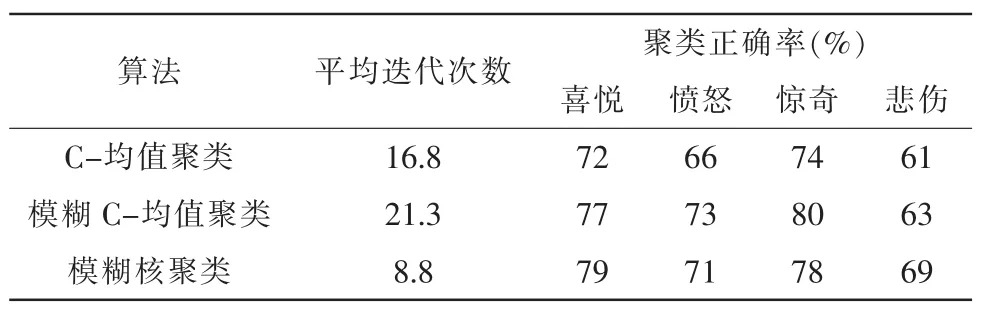
表2 仅通过面部表情信号进行聚类
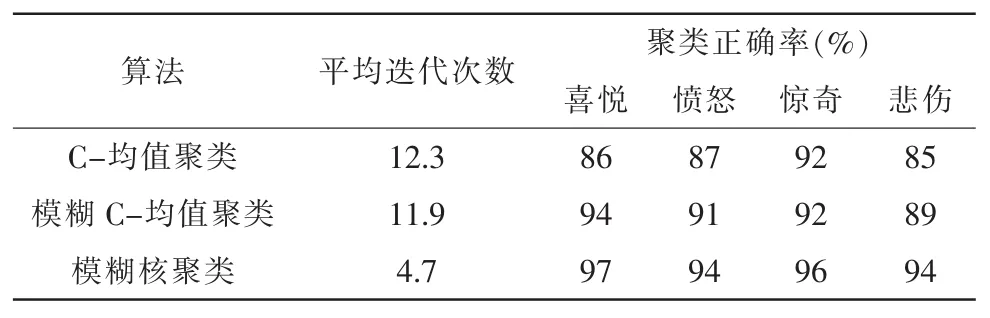
表3 通过该文方法
从表1、表2和表3可以看出,用模糊核聚类的方法收敛速度最快,聚类正确率明显高于其它两类。还可以看出仅通过语音信号特征和仅通过面部表情信号特征进行聚类分析的平均聚类正确率较同时用语音信号特征和面部表情特征进行聚类分析的平均聚类正确率低。因此,单纯依靠语音信号或面部表情信号进行聚类分析在实际应用中会遇到一定的困难,因为人类是通过多模式的方式表达情感信息的,所以研究多模式情感识别的方法十分必要。
5 结 论
该文提出了一种基于模糊核聚类的多模式情感识别方法,而且仿真实验结果也证实了该方法的可行性。但是该文只是针对特定文本的语音情感进行识别,距离实用还有一定的距离,所以非特定文本的语音情感识别将成为我们下一步的研究方向。
[1]Mao X,Chen L J.Speech emotion recognition based on parametric filter and fractal dimension[J].IEICE Trans on Information and Systems,2010,93(8):2324-2326.
[2]Attabi Y,Dumouchel P.Anchor models for emotion recognition from speech[J].IEEE Trans on Affective Computing,2013,4(3):280-290.
[3]Zheng W M,Xin M H,Wang X L et al.A novel speech emotion recognition method via incomplete sparse least square regression[J].IEEE Signal Processing Letters,2014,21(5):569-572.
[4]Mao Q R,Dong M,Huang Z W et al.Learning salient features for speech emotion recognition using convolutional neural networks[J].IEEE Trans on Multimedia,2014,16(8):2203-2213.
[5]Rahulamathavan Y,Phan R C-W,Chambers J A et al. Facial expression recognition in the encrypted domain based on local fisherdiscriminant analysis[J].IEEE Trans on Affective Computing,2013,4(1):83-92.
[6]文沁,汪增福.基于三维数据的人脸表情识别[J].计算机仿真,2005,25(7):99-103.
[7]Zheng W M.Multi-view facial expression recognition based on group sparse reduced-rank regression[J].IEEE Trans on Affective Computing,2014,5(1):71-85.
[8]Petrantonakis P C,Hadjileontiadis L J.Emotion recognition from EEG using higher order crossings[J].IEEE Trans on Information Technology in Biomedicine,2010,14(2):186-197.
[9]Zacharatos H,Gatzoulis C,Chrysanthou Y L.Automatic emotion recognition based on body movement analysis:a survey [J].IEEE Computer Graphics and Applications,2014,34(6):35-45.
[10]Kim J,Andre E.Emotion recognition based on physiological changes in music listening[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2008,30(12):2067-2083.
[11]黄程韦,金赟,王青云等.基于语音信号与心电信号的多模态情感识别[J].东南大学学报:自然科学版,2010,40(5): 895-900.
[12]Hoch S,Althoff F,Mcglaun G et al.Bimodal fusion of emotional data in an automotive environment:IEEE International Conference on Acoustics, Speech, and Signal Processing,2005[C]∥USA:IEEE,2005:1085-1088.
[13]Sayedelahl A,Araujo R,Kamel M S.Audio-visual featuredecision level fusion for spontaneous emotion estimation in speech conversations:2013 IEEE International Conference on Multimedia and Expo Workshops,2013[C].USA:IEEE,2013:1-6.
[14]Mao X,Chen L J.Mercer kernel based clustering in feature space[J].IEEE Trans on Neural Networks,2002,13(3): 780-784.
[15]林琳,王树勋,郭纲.短语音说话人识别新方法的研究[J].系统仿真学报,2007,19(10):2272-2275.
Research on multimodal emotion recognition algorithm based on fuzzy kernel clustering
HAN Zhi-yan,WANG Jian
(BohaiUniversity,Jinzhou 121000,China)
In order to overcome the limitation of singlemode emotion recognition.This paper described a novelmultimodal emotion recognition algorithm,took speech signal and facial expression signal as the research subjects,and accomplished recognition for six kinds of human emotion(joy,anger,surprise,sadness).First,made some pre-processing and extracted emotion feature for speech signaland facialexpression signal.Second,used the fuzzy kernel clustering for clustering analysis. That is to say,by using Mercer kernel function,the data in original spaceweremapped to a high-dimensional eigen-space,and then used the fuzzy clustering for the speech features in the high-dimensional eigen-space.Because of the kernel mapping,the feature inherent in the emotion signals explores,which improves the discriminations of the different emotion category.Experimental results verify the feasibility and effectivenessof the proposedmethod.
multimodal emotion recognition;speech signal;facial expression signal;fuzzy kernel clustering
TN101
A
1674-6236(2016)20-0001-04
2016-03-12 稿件编号:201603150
国家自然科学基金资助(61503038;61403042)
韩志艳(1982—),女,内蒙古赤峰人,博士,副教授。研究方向:情感识别、情感可视化。
