一种基于GPU的移动对象并行处理框架
2016-11-08韦春丹龚奕利李文海
韦春丹 龚奕利 李文海,2*
1(武汉大学计算机学院 湖北 武汉 430072) 2(软件工程国家重点实验室 湖北 武汉 430072)
一种基于GPU的移动对象并行处理框架
韦春丹1龚奕利1李文海1,2*
1(武汉大学计算机学院湖北 武汉 430072)2(软件工程国家重点实验室湖北 武汉 430072)
PGrid是一个基于格网索引的移动对象并行处理框架。通过分析PGrid框架不利于在GPU上并行的因素,提出基于GPU的无锁并行处理G-LFPP(GPU Based Lock Free Parallel Processing)框架。采用基于操作分解/聚类的无锁更新策略,消除更新过程中并发控制对更新性能的影响;为了实现细粒度并行查询,提出基于候选集映射表和查询确认表的快速查询索引。实验表明,该方法更新和查询策略有利于大规模线程并发处理更新和查询。当移动对象的数量达到千万级时,更新速率和查询速率仍然可以超过每秒1100万次和110万次。与PGrid相比,并发处理更新和查询的速度提高了6.61倍。
并行计算图形处理单元异构计算格网索引移动对象数据库
0 引 言
近年来,随着移动互联网、车联网、物联网的普及,移动端设备上涌现了众多LBS应用。例如,在我国免费打车软件“滴滴打车”中,服务器端持续向移动客户端报告随机位置特定大小范围内所有计程车的位置和状态。这类应用通常包括单个处理位置信息的服务器和数量巨大的移动端设备——移动对象。移动对象可持续地向服务器端发送自身的坐标等位置信息,服务器端则负责实时更新移动对象的位置信息并响应对移动对象的查询请求。随着移动对象数量增多、更新/查询频率的提高,服务器端的工作负载也将显著增加,在实时性和响应速度上挑战服务器端的处理能力,基于CPU的移动对象并行处理技术已经越来越难以满足LBS的应用需求。
自从GPGPU(General Purpose GPU)的概念被提出之后,NVIDIA和AMD等显卡厂商均各自推出以GPU为协处理器的通用并行计算解决方案。其中,CUDA(Computer Unified Device Architecture)是NVIDIA推出的GPU通用计算解决方案。它提供的CUDA编程语言扩展、Kernel函数等机制,将大规模并行计算逻辑通过一种简单、有效的方式表达,成为充分利用GPU硬件实现程序加速的关键因素。如今,GPU已经在许多领域获得广泛的应用,研究基于GPU的移动对象处理技术,拓展GPU在数据库领域的应用范围,具有极其重要的意义。
1 相关工作
基于多核CPU的移动对象并行处理技术的研究成果已经颇为丰硕,主要包括索引结构、缓存技术和并发控制等研究方向。
在索引结构上,传统时空数据库广泛采用具有深度平衡特性的R树及其变种[1,2]。考虑到R树MBR交叠对并发控制以及查询性能的不利影响,基于空间填充降维思想的索引相继出现。其中,Bx利用空间填充曲线对索引进行降维,在更新性能上取得了显著提升。然而,由于Bx采用的MBR查询策略使得候选对象数量增长过快,不可避免地造成了查询效率相对低下。针对B+树[3,4]的并发策略,也因索引层次过深、路径遍历太长[5]、并发处理的锁代价等因素导致性能提升受限制。由于多线程并行处理要求任务分割的均匀性和无交叠性[6],因此,结构相对平坦的格网结构被引入移动对象数据库中[7,8]。

与此同时,基于GPU的并行算法也在各个领域得到了广泛应用。Elnaggar等人[11]通过取消线程分歧策略和细粒度并行算法,使GPU遍历NegaMax树的速度达到了多核CPU的 80倍。文献[12]通过研究天文数据抽取工具SExtractor中的并行性,利用剪枝策略使SExtractor在GPU上的处理性能比CPU版本高出6倍。文献[13]通过将决策树转换为完全平衡的范围树,实现线程负载均衡,使得网络流量分类算法性能相比其CPU版本提高了16倍。
最近几年,GPU也被越来越多地应用于数据挖掘和机器学习领域。文献[16]通过Kernel函数的融合和分裂算法,解决了利用GPU查询数据仓库时数据传输开销过大的问题。文献[17]利用GPU将机器学习中的卷积和深层神经网络算法的速度提高了450倍。深度信念网络是深度学习中进行数据建模的强有力工具,基于GPU的深度信念网络[18]版本执行速度比CPU版本快7到11倍。Rathi等人[19]将XML数据结构进行反串行化,实现了GPU线程在XML数据并发执行数据挖掘算法。
综上所述,面向LBS的移动对象处理技术研究已在索引结构、并发控制策略等层次深入展开,基于GPU的并行算法也在各个领域获得了广泛应用。因而研究基于GPU的移动对象并行处理技术,拓展GPU在数据库领域的应用范围,具有较强的理论研究价值和现实意义。
2 GPU并行计算概述
图形处理单元[21]GPU是显卡的计算核心,原本用以分担中央处理器CPU的二维和三维图形计算任务。通用计算GPU技术致力于利用可编程GPU执行CPU的通用计算任务。GPU具有计算能力强大、体积小、功耗低、成本低的优势,目前已经成为传统超级计算机的替代品,并且已经被大部分应用软件和操作系统采纳为第二个通用处理器。
2.1GPU架构与性能分析
GPU强大的计算能力源于它的体系结构和CPU的区别。作为通用处理单元,CPU通常只有若干(2~16)个算术逻辑单元,并且设计重心被放在复杂的缓存结构以及分支预测、乱序发射等控制逻辑上。相比之下,GPU没有复杂的缓存和控制逻辑,GPU芯片上大部分晶体管都服务于算术逻辑单元。这些架构差异决定了GPU虽然在灵活性和通用性上不如CPU,但是浮点计算能力却远远胜出。与CPU相比,GPU的缓存相对较小,GPU核心和显存之间数据交换很大程度依赖于简单的显存访问,严重影响到GPU的计算效率。为了解决这个问题,GPU架构中引入了两个特性:首先,设计较大的显存带宽来减少访问显存的等待时间;其次,GPU通过同时并发大量线程来弥补架构简单带来的不足。当某个线程在等待访存结果时,调度器会立即阻塞该线程,将另外的线程切换到GPU核心上执行。快速切换正在执行的线程可以掩盖访存延迟,使得GPU的计算性能不会因为频繁的访存请求而降低。
2.2并行计算平台CUDA
计算机统一设备架构[20]CUDA是NVIDIA面向GPGPU的一整套解决方案,在本质上是一个由CPU和GPU组成的异构计算平台。NVIDIA提供了一种基于C/C++语言的扩展编程语言——CUDA C/C++,用于在CUDA平台上开发GPU代码。CUDA C/C++ 是应用最广泛的CUDA编程语言,也是本文开发CUDA程序的编程语言。
CUDA采用一种分层的编程模型来组织线程。在开始计算之前,开发人员为程序配置自定义数量的线程,并且设计线程与数据的映射规则。在计算过程中,线程被划分为若干线程块(Block),每个Block被映射到GPU上的一组处理单元上。同一个Block内的线程会被同时创建、销毁。Block之间互不相干,所有Block根据GPU的具体硬件规格并发或者顺序地被激活。被Block映射到的硬件实现被称为流式多处理器SMX(Streaming Multiprocessor),每个SMX包含若干个标量处理器SP(Scalar Processor),SP也被称为CUDA核心。SP是具体计算指令的执行单位,SMX是拥有完整计算资源的最小单位。当控制器将一个Block分配给一个SMX之后,SMX中的SP会并行执行所有线程中的指令。一个支持CUDA计算的NVIDIA显卡中至少包含一个SMX。
CUDA的线程组织模型有利于开发人员充分利用GPU的计算资源,细化并行计算的粒度,并且有效地解决了实现线程控制时遇到的最大问题——硬件的不对等性,从而使同样的CUDA程序能够高效地在硬件规格不同的GPU上执行。
3 PGrid并行处理框架和瓶颈
由于多核CPU和GPU的并行计算模型不相同,PGrid虽然在多核CPU上表现优秀,但不能直接应用在GPU平台上。因此,本节主要分析PGrid框架中不利于在GPU上并行的因素。
3.1更新和查询请求定义

3.2格网索引结构
格网(Grid)索引结构是文献[14]提出的基于空间分区的移动对象索引结构,文献[8]在此基础上提出了可以并发多线程并行处理更新和查询的格网索引结构(PGrid)。
在格网索引中,移动对象位置表示模型采用点模型,并将应用场景抽象为二维矩形欧氏空间。二维欧式空间被划分为均匀大小的单元格(Cell)。由于应用场景的大小不变,因此,可以通过调整Cell的大小来调整被划分出来的Cell总数。
移动对象通过位置坐标与Cell映射。格网索引结构的索引只有一层索引节点。当格网被划分好之后,索引节点不需要进行分裂或者合并。因此,格网索引的索引层次比较浅,索引路径长度均匀,维护操作比树型索引简单,维护的时间开销也比较小。
格网索引的组织方式如图1所示。在实现过程中,每个Cell包含一个Bucket的序列,每个Bucket是一个固定长度的数组,用以存储移动对象。为了通过移动对象标识符直接查找移动对象,PGrid框架在主索引结构基础上增加了一个副索引。副索引是存放移动对象元数据信息的哈希表,移动对象元数据包括移动对象所属的Cell、Bucket指针以及对象在Bucket中存储的位置。
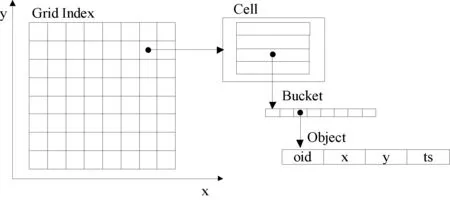
图1 格网索引结构组织方式
3.3PGrid不利于GPU并行的因素分析
(1) 更新瓶颈:线程相关和线程分歧
基于格网索引的移动对象更新请求可以分为两种基本类型:跨Cell更新和原地更新。跨Cell更新是指导致移动对象更新前后的位置不在同一个Cell里的更新请求,处理跨Cell更新请求需要将移动对象从旧Cell里删除,然后插入新Cell里。原地更新是指移动对象更新前后,位置仍然在同一个Cell里的更新请求,只需要刷新移动对象的位置坐标、时间戳。
PGrid并行处理更新请求的方式是将Cell与线程映射,每个Cell中的移动对象所提交的更新请求由该Cell映射到的线程负责处理。由于跨Cell更新的请求之间会存在数据相关,因此需要对Cell上锁进行并发控制。并发更新的线程规模越大,发生锁冲突的概率就越大,并发线程更新的效率反而会降低。此外,当GPU线程并发处理跨Cell更新和原地更新请求时,会导致线程分歧。
(2) 查询瓶颈:粗粒度并行
在PGrid框架中,查询请求属于范围查询,包含在查询范围内部或者与查询范围边界相交的Cell,称为被查询覆盖到的Cell。其中,完全包含在查询范围内的Cell属于完全被覆盖,与查询范围边界相交的Cell,属于部分被覆盖。完全被覆盖和部分被覆盖的Cell内的移动对象构成了查询请求的目标集。
当进行并行查询时,PGrid将查询请求与线程映射,每个线程需要遍历与之映射的查询请求的目标集。若目标集是部分被覆盖的,还需要将移动对象坐标与查询范围进行比较。由于GPU的工作频率比CPU低很多,因此单个GPU线程处理一个查询请求的速度就要比单个CPU线程慢很多,而且单个查询请求内部的并行性并没有得到开发。此外,由于处理部分被覆盖Cell和完全被覆盖Cell中移动对象的指令不一致,因此会出现线程分歧。综上,粗粒度并行方式和线程分歧,导致PGrid的并行查询策略无法在GPU上获得良好的性能。
4 基于GPU的无锁并行处理框架G-LFPP
通过对PGrid的分析,本文提出了基于GPU的无锁并行处理G-LFPP框架。
4.1G-LFPP工作方式
利用NVIDIA Kpeler架构GPU的Hyper-Q特性,G-LFPP可以使三个Kernel函数并发工作:分发Kernel、更新Kernel、查询Kernel。配置给这三个Kernel的GPU线程,分别称为分发线程、更新线程、查询线程。
G-LFPP工作流程如图2所示,更新/查询请求首先到达主机内存,分发Kernel根据先来先服务(FCFS)的原则从主机内存中获取更新/查询请求,进行预处理并写入更新/查询缓冲区。更新Kernel和查询Kernel分别从更新、查询缓冲区获取相应的请求。

图2 G-LFPP工作流程
G-LFPP框架采用缓存和批处理技术,从移动端发送进来的更新/查询请求会被缓存在主机内存上的请求队列里。分发Kernel每隔一段时间从请求队列中获取一批请求,这些被分批获取的请求被称为请求队列片段。
在运行时,分发Kernel与更新Kernel通过更新缓冲区进行同步,分发Kernel与查询Kernel通过查询缓冲区进行同步,而更新Kernel与查询Kernel通过分发Kernel间接地进行同步。
4.2更新算法
在更新算法中,本文将Cell与GPU线程进行映射。由于处理跨Cell更新请求时,需要在旧Cell和新Cell里分别执行删除、插入两个子操作。当线程将移动对象插入新Cell时,就会与负责更新新Cell的线程发生冲突。换言之,更新线程处理跨Cell更新请求时,不能在自己所负责的Cell内一步到位完成所有操作,还需要在其他线程所负责的Cell内执行部分操作。因此,如果将对新Cell进行插入的子操作转移给负责新Cell的线程,则Cell冲突的问题就可以解决了。为了实现子操作转移,首先要将跨Cell更新操作分解为删除和插入两个子操作。此时,在G-LFPP框架中,更新操作被分为三种基本类型:删除、插入、原地更新。
在分发阶段,分发线程首先判断更新请求的基本类型。如果属于跨Cell更新,则将更新操作分解为删除和插入子操作之后,再写入更新缓冲区,这个过程被称为更新操作的分解。
更新缓冲区的结构如图3所示,分发Kernel预处理后的输出结果分别写入删除、插入、原地更新队列里。删除、插入、原地更新队列分别与Cell映射。

图3 缓冲队列与Cell映射
在更新Kernel中,更新线程分三个阶段处理本周期的所有更新请求:1) 执行完本更新周期的所有删除操作,然后进行线程同步;2) 执行所有的插入操作,然后进行线程同步;3) 执行所有的原地更新操作,然后进行线程同步。由于更新线程之间访问的数据都是相互独立的,因此G-LFPP在更新过程中并不需要对线程上锁。
4.3查询算法
1) 双索引策略
在G-LFPP框架中,更新Kernel和查询Kernel并发执行更新和查询操作。为了实现查询时无挂起更新,G-LFPP采用了文献[7]提出的双索引思想,在框架中维护两个索引:索引0和索引1。更新Kernel和查询Kernel周期性地在这两个索引上轮替工作。轮替工作模式可以描述如下:
在第k周期,更新Kernel在索引kmod 2上执行更新操作,查询Kernel在索引(k+1) mod 2上执行查询操作。
在双索引结构中,每一个更新请求都需要在两个索引上得到体现,相比单索引结构,更新Kernel的工作负载增加了一倍。
2) 候选集映射表及映射规则
为了开发查询过程中的并行性,实现细粒度并行,本文提出了候选集映射算法。所谓候选集映射,就是在每个查询周期中将候选集中的移动对象与查询线程进行映射。在这里,候选Cell集合是指每个查询周期中被所有查询请求所覆盖到的Cell的集合,候选移动对象集合是候选Cell集合中所有移动对象的集合,简称候选集。
候选集是一个逻辑集合,集合中的移动对象实际分布在不同的候选Cell里。为了获得这些移动对象的存储位置,候选集映射算法借助一个辅助的候选集映射表,将候选Cell中已经存储了移动对象的存储位置都映射到查询线程上。
候选集映射表如图4所示,候选集中的移动对象通过映射参数和映射规则,间接地与查询线程映射。

图4 候选集映射表
候选集映射规则包含两个步骤:
第一步,候选集映射表中的索引号与查询线程进行映射,映射关系γ定义如式(1)所示:
(1)
其中,D是候选集映射表中索引号的集合,G是查询线程的集合,映射关系γ是满射。
第二步,将候选Cell集合中已经保存有移动对象的存储位置与候选集映射表中的索引号进行单射。
在候选集映射表中,每一列记录候选Cell中一个存储位置的映射参数。其中,每列第一行记录的是候选集映射表中的索引号d,第二行记录的是候选Cell的索引号c,第三行记录的是已经存储了移动对象的存储位置的索引号r。第二、第三行参数经过式(2)和式(3)所示的存储位置换算公式,就可以得到Cell中一个已经存储有移动对象的位置。
(2)
y=rmodL
(3)
其中,x表示Bucket在Cell中的索引号;y表示Bucket中的位置;L是Bucket长度。
3) 候选集映射表生成算法
候选集映射表的生成过程包含两个阶段:
第一阶段由分发Kernel负责处理。当分发Kernel从主机内存中获取查询请求分段之后,首先把本周期的所有查询请求所覆盖到的Cell添加到候选Cell列表Candidate_List中,候选Cell列表是候选Cell集合的实现形式。然后,将覆盖到每个候选Cell的所有查询请求写入查询确认表Confirmation_Table里。查询确认表是一个二维表,表中每一行对应候选Cell的一个私有查询请求队列,通过对应的私有查询请求队列可以获取本周期中覆盖到某个候选Cell的所有查询请求。候选Cell列表以及查询确认表最后被写入查询缓冲区。
第二阶段由查询Kernel负责处理。查询Kernel从查询缓冲区中获取候选Cell列表和查询确认表,然后通过下列三个步骤生成候选集映射表。
第一步,将每个候选Cell中移动对象的数目写入数组Bound_Table中。数组Bound_Table是映射边界表的输入数组,为了方便下面生成映射边界表,令Bound_Table[0]等于0,Bound_Table[i]等于第i个候选Cell的移动对象数目。
第二步,生成映射边界表。映射边界表记录候选Cell中已经存储了移动对象的存储位置映射到候选集映射表索引号的上界up_bound和下界down_bound,简称为映射上界和映射下界。当候选Cell中的移动对象个数为m时,它需要映射到候选集映射表中的m个索引号上。当已知映射下界down_bound之后,映射上界up_bound就可以通过计算公式down_bound+m-1得到。
在候选Cell列表中,只有当位置i-1中的候选Cell的映射上界确定之后,才能确定位置i中的候选Cell的映射下界。所以,生成映射边界表的过程,实质上是确定候选Cell列表中每个Cell的映射下界和上界的过程。由于候选Cell的映射下界依赖于其前续的映射上界,因此,对候选Cell的映射边界的确定只能按照候选Cell在候选Cell列表中的排列顺序依次进行。
由于位置i中的候选Cell的映射下界和位置i-1中的候选Cell的映射上界保存的信息重复,为了减少存储空间以及GPU线程访问设备内存的次数,这两个信息只需要保留一个即可,另一个信息可以通过计算获得。在实现过程中,G-LFPP的边界映射表只保存映射下界。由于候选Cell列表中第一个候选Cell的映射下界是0,因此,在前文的第一步中,令Bound_Table[0]等于0,这个值对应第一个候选Cell的映射下界。以此类推,第i个候选Cell的映射下界保存在Bound_Table[i-1]中。
映射边界表在输入数组Bound_Table的基础上生成,生成映射边界表的伪代码如下所示:

第三步,根据映射边界表生成候选集映射表。生成映射边界表之后,只要将候选Cell和线程进行映射,线程就可以通过映射边界表界定其在候选集映射表上的工作边界。所以,映射边界表使得GPU线程可以并行工作生成候选集映射表。生成候选集映射表的伪代码如下所示。

4) 快速查询索引:候选集映射表与查询确认表
生成候选集映射表之后,查询线程通过结合候选集映射表和查询确认表处理本周期的所有查询请求。
候选集映射表和查询确认表还有另一个作用:同一周期中,当移动对象所在的Cell被两个以上查询请求覆盖到时,查询线程只需要读取移动对象一次,就可以满足覆盖到该对象的所有查询请求,从而减少查询线程访问设备内存的次数。
综上所述,候选集映射表和查询确认表有两个重要的辅助作用:
(1) 实现细粒度的并行,减少线程分歧和线程闲置。
(2) 减少线程访问设备内存次数。
候选集映射表在本质上是对移动对象的索引,查询确认表是对查询请求的索引。通过这两个数据结构的辅助,加快了GPU线程处理查询请求的速度。
5 实验结果
为了验证G-LFPP并发处理更新和查询的能力,本文设计了三组实验。实验主机的CPU型号为 Intel Xeon E5-2650;主机内存容量为16 GB;主板PCI-E接口为PCI-E 3.0;GPU型号为NVIDIA Tesla K40。
操作系统版本为CentOS release 6.2 (Final),Linux内核版本号为2.6.32-220.el6.x86_64,CUDA版本为CUDA 6.5。
实验数据由文献[15]给出的MOIBenchmark生成,移动对象总数为一千万,分布方式是均匀分布。由于以下各个实验验证目标不同,因此其他具体实验参数将在实验中设定。
5.1Cell总数对性能的影响
本节实验主要验证在线程数量保持不变的情况下,Cell的划分粒度分别给更新和查询性能带来的影响。在实验中,实验场景为固定大小的二维矩形区域,该矩形区域被划分为均匀大小的Cell。当Cell的尺寸越小,即Cell的划分粒度越细时,Cell的总数就会越大,相应地,G-LFPP框架的性能也会受到影响。
(1) 实验参数
实验模拟场景大小100 km×100 km;移动对象总数1千万;移动对象分布方式为均匀分布;移动对象移动速率1~1000 m/s;更新次数4000万;更新线程12 288;查询次数400万;查询线程8192;查询范围边长取实验场景边长的0.001,即100 km×0.001=100 m,查询范围大小为10 000 m2。
(2) 实验方案
测试更新性能时,只启动分发Kernel和更新Kernel。测试查询性能的过程分为两步:1) 只启动分发Kernel和更新Krenel进行4000万次更新;2) 终止更新Krenel,启动查询Kernel,进行400万次查询。
(3) 更新性能测试及结果分析
图5展示了在更新线程数量不变的前提下,随着Cell划分粒度的变化,即Cell的总数变化时,更新性能的变化情况。从图5中可以看到,当Cell的总数小于更新线程总数时,随着Cell数量的增加,更新性能获得提升;而当Cell的总数超过更新线程总数之后,随着Cell数量的增加,更新性能反而下降。
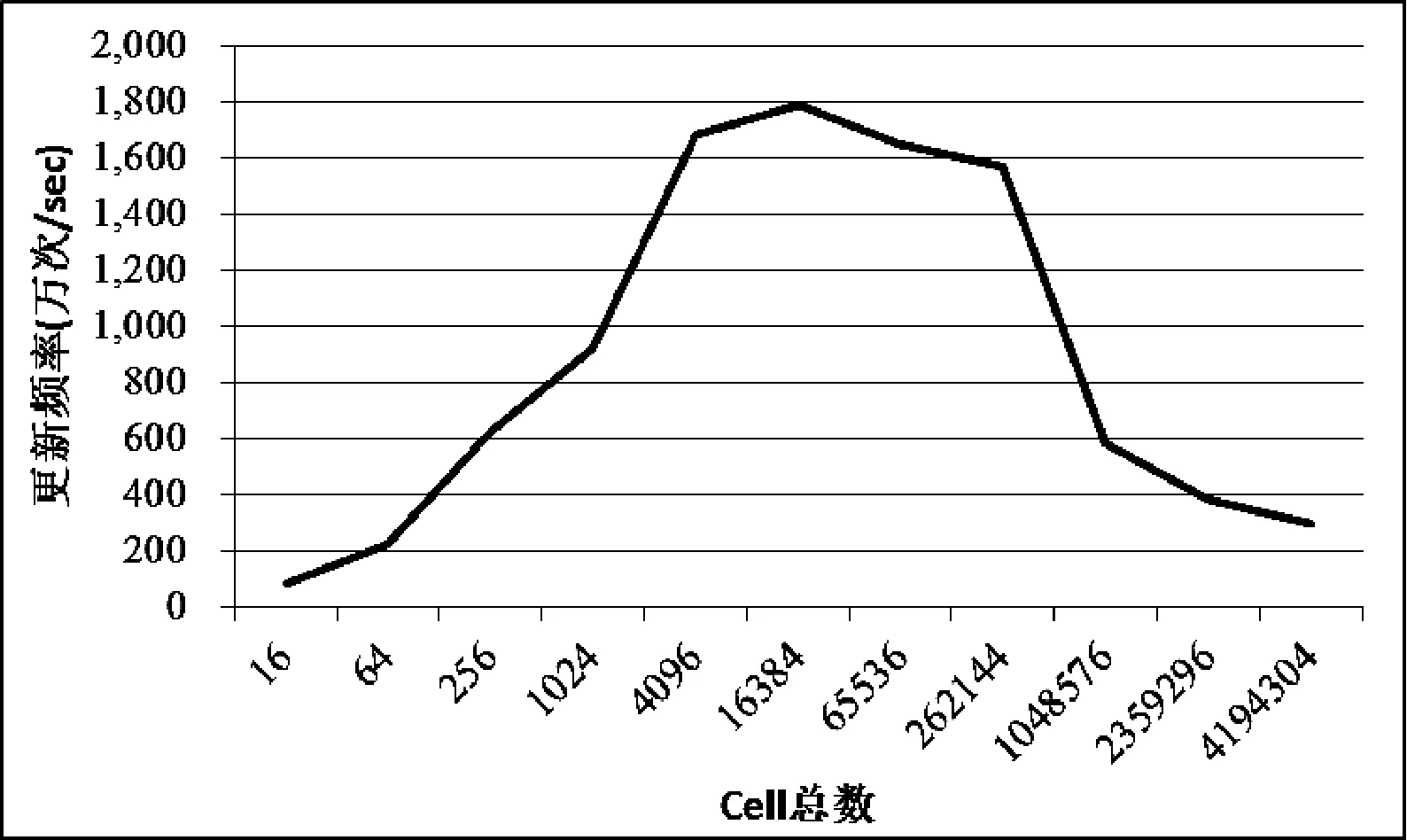
图5 Cell划分粒度对更新性能的影响
由于在G-LFPP框架中,Cell与更新线程是满射关系,当Cell数量小于更新线程数量时,更新Krenel中还有可用的更新线程。随着Cell总数的增加,参与更新操作的线程数量也随着增加。此外,由于每个周期更新请求分段长度固定,当Cell总数增加之后,每个Cell中需要进行的更新操作会相对减少,因此,在这个阶段中,更新性能也随着Cell总数的增加而提升。
当Cell总数超过更新线程数量时,更新Kernel中已经没有多余的更新线程。随着Cell总数的进一步增加,映射到每一个更新线程上的Cell也增加,每个更新线程需要负责更新的Cell数目增加。因此,在这种情况下,更新性能反而会随着Cell总数的增加而下降。
综上所述,在更新线程数量不变的前提下,当Cell的数量和更新线程数量大致相等时,更新Krenel达到最优性能。在本次实验中,更新线程数量为12 288,因此,当Cell总数为16 384时,更新速率最快。而当Cell数量小于或者大于更新线程数量时,更新性能均会下降。
(4) 查询性能测试及结果分析
实验结果如图6所示,随着Cell总数不断增加,查询性能呈现出和更新性能相似的趋势,先提升后下降。

图6 Cell划分粒度对查询性能的影响
查询过程中,生成映射边界表和候选集映射表的时间开销与候选Cell集合的大小相关,而查询线程遍历候选集中移动对象的时间开销与候选集大小有关。
为了方便分析,设x为候选Cell集合大小,y为候选集大小,生成边界映射表和候选集映射表的时间开销为f(x),查询线程遍历候选集中移动对象的时间开销为g(y)。则每个周期查询时间的计算公式如式(4)所示:
t=f+g+C
(4)
其中,C是常数,表示查询过程中不会受Cell尺寸影响的固定时间开销。查询时间随着Cell尺寸变化如式(5)所示:
Δt=Δf+Δg
(5)
随着Cell尺寸的缩小,候选Cell集合规模保持增加,但是候选集的规模却一直减小。因此,有Δf的符号为正,Δg的符号为负。此时,查询时间变化如式(6)所示:
Δt=|Δf|-|Δg|
(6)
在开始阶段,随着Cell尺寸的减小,候选Cell集合规模增加的速度小于候选集规模减小的速度。此时有|Δf|<|Δg|,Δt<0,查询时间递减,查询性能提升。
随着Cell尺寸进一步减小,候选Cell集合规模增加的速度加快,而候选集规模减小的速度放缓。此时有|Δf|>|Δg|,Δt>0,查询时间开销递增,查询性能下降。
综上所述,随着Cell尺寸的缩小,查询性能先提升后下降。实验结果显示,当Cell总数在26万左右时,查询性能接近最大值。
5.2线程数量对性能的影响
本节实验主要验证当Cell划分粒度不变,即Cell的总数不变的情况下,线程规模对更新和查询性能的影响。
(1) 实验参数
实验模拟场景大小100 km×100 km;移动对象总数1千万;移动对象分布方式为均匀分布;移动对象移动速率1~1000 m/s;更新次数4000万;查询次数400万;查询范围10 000平方米;Cell总数65 536。
由于G-LFPP在运行时需要进行Block之间的同步,因此在Tesla K40 GPU上只能并发15个Block。并且,为了避免分发Kernel成为瓶颈,需要为它配置3个Block。所以,在实验中更新和查询Kernel能够获得的Block数量最多为12个,可以使用的线程数量上限为12 288。
(2) 实验结果分析
实验结果如图7所示。当线程数量从1024增加到12 288时,查询性能获得持续提升。这是因为每个周期候选集中移动对象的数量仍然远远超过线程数量,当增加线程时,并行处理的速度就会有提高。而对于更新Kernel来说,当更新线程为9126个时,更新速度达到峰值,接近每秒1800万次;之后继续增加更新线程,则更新速度逐渐变慢。这是由于Cell的总数不是更新线程数量的整数倍。每个周期更新中,都会有更新线程闲置,随着更新线程数量增加,闲置线程也增加。


图7 线程数量对更新和查询性能的影响
5.3G-LFPP与PGrid性能比较
本节实验由5次实验组成,每次实验采用不同的更新查询比,比较 G-LFPP和PGrid并发处理更新和查询请求性能。其中,在一次实验中,总更新次数和总查询次数的比率,称为更新查询比。
(1) 实验参数
实验模拟场景大小100 km×100 km;移动对象总数1千万;移动对象分布方式为均匀分布;移动对象移动速率1~1000m/s;更新次数为4000万次,更新查询比从100∶10增加到100∶1,即查询次数从400万次减少到40万次;查询范围:10 000平方米。
(2) 实验方案
总共进行5次实验,每次实验中G-LFPP和PGrid处理相同数量的更新和查询请求,但是每次实验之间的更新查询比不相同。为G-LFPP配置的GPU线程总数为15 360,其中分发Kernel的线程数量为3072,更新Kernel的线程数量为4096,查询Kernel的线程数量为8192。为PGrid配置的CPU线程总数为16,其中分发线程数量为2,更新线程数量为4,查询线程数量为10。
(3) 实验结果与分析
对G-LFPP和PGrid来说,处理查询请求的操作都是计算量最大的部分。因此,在分配线程时,查询线程的数量都会多于更新线程。在G-LFPP和PGrid运行时,查询线程的比例分别占总线程数的53.33%和75%,这是由于PGrid单个Cell的尺寸比较大,即每个Cell内包含的移动对象数量比较多。这就意味着查询的待选集规模比较大,查询的负载相应地要大很多,因而PGrid中处理查询请求的线程比例高于G-LFPP。
实验结果如表1所示,从表1中可以看到,当移动对象总数为1000万、更新次数为4000万、查询次数为400万次,即更新查询比为10∶1时,G-LFPP同时处理更新和查询消耗的时间为3.1175秒,每秒处理的更新和查询次数分别为1283万和128万;而PGrid消耗时间为20.6018秒,每秒处理的更新和查询次数分别为194万和19.4万。此时,G-LFPP的处理速度是PGrid的6.61倍。
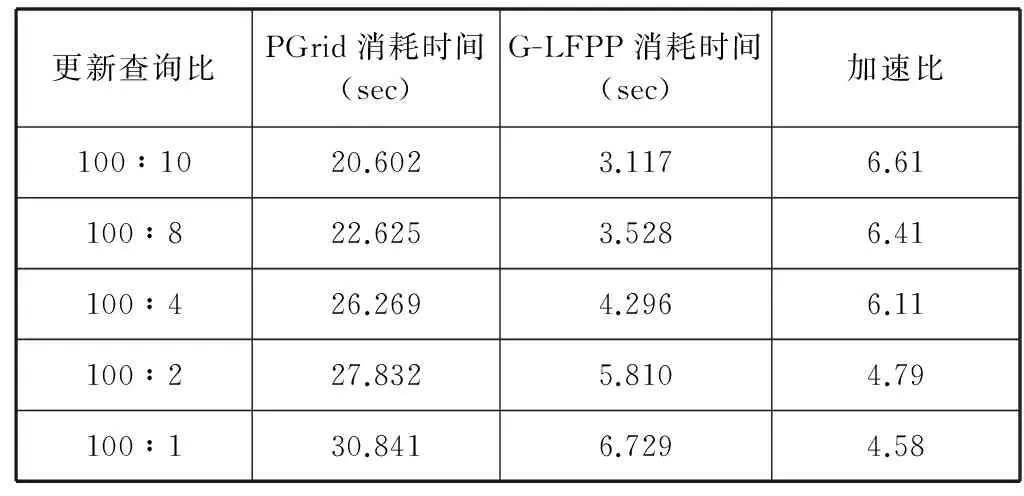
表1 G-LFPP与PGrid性能比较
当总更新次数不变时,随着更新查询比的增加,总查询次数会相应减少,G-LFPP的加速比也随之减小。这是因为,G-LFPP主要的提速部分在查询部分,查询数量越大,G-LFPP的提速效果就越明显,加速比越大;反之,加速比越小。
6 结 语
基于操作分解/聚类的无锁更新策略和基于快速查询索引的查询策略是G-LFPP框架的核心,这个两个策略使得G-LFPP能够充分利用GPU大规模并发的线程提高处理效率,与PGrid相比,处理速度提高了6.61倍。
但是,本文的算法均以移动对象均匀分布为假设前提,当移动对象呈高斯分布时,处理更新和查询的线程之间会出现工作负载不均衡,这将是基于GPU的移动对象并行处理框架需要进一步解决的问题。
[1] Lu C T,Dai J,Jin Y,et al.GLIP:A concurrency control protocol for clipping indexing [J].IEEE Transactions on Knowledge and Data Engineering,2009,21(5):714-728.
[2] Song S I,Kim Y H,Yoo J S.An enhanced concurrency control scheme for multidimensional index structures [J].IEEE Transactions on Knowledge and Data Engineering,2004,16(1):97-111.
[3] Graefe G,Halim F,Idreos S,et al.Concurrency control for adaptive indexing [C]//Proceedings of the VLDB Endowment,2012,5(7):656-667.
[4] Lomet D.Simple,robust and highly concurrent B-trees with node deletion [C]//Proceedings of the 20th International Conference on Data Engineering (ICDE).Boston,MA,USA,2004:18-27.
[5] Yiu M L,Tao Y F,Mamoulis N.The Bdual-tree:indexing moving objects by space filling curves in the dual space [J].The VLDB Journal,2008,17(3):379-400.
[6] Popa I S,Zeitouni K,Oria V,et al.Indexing in-network trajectory flows [J].The VLDB Journal.2011,20(5):643-669.
[11] Elnaggar A A,Gadallah M,Aziem M A,et al.Enhanced parallel NegaMax tree search algorithm on GPU [C]//Proceedings of 2014 International Conference on Informatics and Computing (PIC).Shanghai,2014:546-550.
[12] Baoxue Zhao,Qiong Luo,Chao Wu.Parallelizing astronomical source extraction on the GPU [C]//Proceedings of 2013 IEEE 9th International Conference on eScience.Beijing,2013:88-97.
[13] Zhou S J,Nittoor P R,Prasanna V K.High-performance traffic classification on GPU [C]//Proceedings of 2014 IEEE 26th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD).Jussieu,2014:97-104.
[14] Saulys D,Johansen J M,Christiansen C W.Indexing moving objects in main memory [C]//Proceedings of 2008 Annual IEEE Conference on Student Paper.Aalborg,2008:1-5.
[15] Chen S,Jesen C S,Lin D.A benchmark for evaluating moving object indexes [C]//Proceedings of the VLDB Endowment,2008,1(2):1574-1585.
[16] Wu H C,Diamos G,Wang J,et al.Optimizing data warehousing applications for GPUs using Kernel fusion/fission [C]//Proceedings of 2012 IEEE 26th International Conference on Parallel and Distributed Processing Symposium Workshops & PhD Forum (IPDPSW).Shanghai,2012:2433-2442.
[17] Yunji Chen,Tao Luo,Shaoli Liu,et al.A machine-learning supercomputer [C]//Proceedings of 2014 47th Annual IEEE/ACM International Symposium Conference on Microarchitecture.Cambridge,2014:609-622.
[18] Zhilu Chen,Jing Wang,Haibo He,et al.A fast deep learning system using GPU [C]//Proceedings of 2014 IEEE International Symposium Conference on Circuits and Systems (ISCAS).Melbourne VIC,2014:1552-1555.
[19] Rathi S,Dhote C A,Bangera V.Accelerating XML mining using graphic processors [C]//Proceedings of 2014 International Conference on Control,Instrumentation,Communication and Computational Technologies (ICCICCT).Kanyakumari,2014:144-148.
[20] Jason Sanders,Edward Kandrot.CUDA by example:an introduction to General-Purpose GPU programming [M].Massachusetts:Addison-Wesley Professional,2010.
[21] 仇德元.GPGPU编程技术 [M].北京:机械工业出版社,2011.
A GPU-BASED MOVING OBJECT PARALLEL PROCESSING FRAMEWORK
Wei Chundan1Gong Yili1Li Wenhai1,2*
1(SchoolofComputer,WuhanUniversity,Wuhan430072,Hubei,China)2(StateKeyLaboratoryofSoftwareEngineering,Wuhan430072,Hubei,China)
PGrid is a parallel processing framework for moving objects based on grid index.This paper proposes a GPU-based lock-free parallel processing (G-LFPP) framework on the basis of analysing the factors of PGrid framework not being conducive to parallel on GPU.It uses a lock-free update strategy,which is based on operation splitting/clustering,to eliminate the impact of concurrency control on update performance in updating process.In order to implement fine-grained parallel queries,the paper also presents a fast query index composed of candidate set mapping table and query confirmation table.Experiments show that the proposed update and query strategies avail the large-scale threads in processing updates and queries concurrently.Whilst the number of moving objects reaches a level of ten million,the update and query rates can still be over 11 million per second and 1.1 million per second respectively,which are 6.61 times higher than those of PGrid.
Parallel computingGPUHeterogeneous computingGrid indexMoving object database
2015-04-29。国家自然科学基金项目(61100020);华为公司创新研究计划资助项目。韦春丹,硕士,主研领域:并行计算。龚奕利,副教授。 李文海,副教授。
TP3
A
10.3969/j.issn.1000-386x.2016.10.050
