结合微博网络特征和用户信用的微博情感分析
2016-11-08叶尔兰何扎提
叶尔兰·何扎提 李 鹏
1(新疆人民广播电台 新疆 乌鲁木齐 830000)2(北京大学信息科学技术学院 北京 100871)
结合微博网络特征和用户信用的微博情感分析
叶尔兰·何扎提1李鹏2
1(新疆人民广播电台新疆 乌鲁木齐 830000)2(北京大学信息科学技术学院北京 100871)
传统的情感分析方法没有充分地考虑微博自身的特点,在短小、不规范并且充满噪音的微博数据上难以取得良好的效果。结合微博内容本身的特点,提出了适于微博情感分类任务的情感语言模型。并进一步考虑了微博用户和社交网络的特征,基于微博转发网络上情感的传播和用户的信用值对提出的情感语言模型进行改进。在经过标注的新闻事件数据集上的实验结果表明,该方法能够有效地对新闻事件相关微博进行情感分类,在准确率等指标上都要优于传统的基于语言模型的方法,而且加入微博的网络特征和用户信用能明显地提高微博情感分类的效果。
微博情感分析社交网络文本分类语言模型
0 引 言
国外著名的微博网站twitter早在2006年就上线,而微博作为一种社交工具被人们普遍接受则是在2009年以后。用户在使用微博时,可以通过发布最长140字的文章(也有链接、图片等其他形式)来分享信息。在诸如新浪微博等国内著名的微博网站中,每天都有数以亿计的活跃用户创造、转发或者评论微博,产生大量的微博数据,也使得对微博数据进行分析、挖掘和理解的相关自然语言处理技术的需求变得十分迫切[1]。情感分析用自然语言处理的方法来识别和提取素材中的主观信息,以找出说话者在话题或者文本中两极的态度,在公司产品反馈[2]、社会舆情监测[3]等方面有很多应用。微博作为各种意见、评论和情感等信息的集散地,十分值得通过情感分析挖掘出有用的信息,这些信息往往潜在着巨大的商业和社会价值。在对微博数据进行情感分析时,传统的对文本进行情感分析的方法[4]并不适用,因为微博与传统的文本数据存在很大的区别,微博的内容短小精悍,表意上不如文本明确,而且微博数据中有很多俗语、非正式的表达以及噪音,对传统的情感分析带来很多困难,而微博中包含的大量表情、符号和图片等信息又为微博的情感分析提供了新的途径。
另一方面,随着网络的快速发展,网络新闻逐渐成为人们接受信息的主要方式,人们往往会对同一个新闻事件产生不同的观点和情感。微博庞杂的用户群体使得微博中的新闻事件具有实时性、传播性和敏感性等特点,如果能通过情感分析及时对微博中新闻事件的产生、传播和评论进行发现、监测和跟踪,对于新闻事件相关利益群体的决策将具有重要的帮助。我们希望通过对微博中新闻事件的情感分析,挖掘出人们对于各种新闻事件的情感和态度,在一定程度上体现出新闻事件的影响力。
机器学习中传统的朴素贝叶斯、支持向量机等方法在对微博进行情感分析时受限于微博噪音较多的训练集难以取得理想的效果,而基于情感词典的情感分析方法则受限于情感词典的构建,对于充满各种符号、网络新词和不规范表达的微博文本,基于情感词典的方法在很多情况下不能有效地进行情感分析。因此,本文考虑将传统的语言模型引入到微博情感分析的任务中来,并为了使基于语言模型的方法更适合于情感分析,在已有的有监督的语言模型基础之上提出了情感语言模型,来对微博中的新闻事件进行情感分类。结合微博用户和社交网络的特点,加入用户的信用特征,考虑了用户情感在微博转发网络中的传播,对提出的情感语言模型进一步改进,使得模型更适于微博情感分析。我们在从新浪微博中抓取的多个新闻事件数据集上进行了实验,实验结果显示本文情感语言模型能够有效对微博进行情感分析,加入用户和网络特征对于微博情感分析的效果具有显著提升。
1 相关工作
情感分类作为情感分析的主要部分,近年来随着机器学习技术的飞速发展,逐渐成为主流的研究课题[5]。情感分类通过具有不同语义倾向的词语特征来对文档进行分类,传统的情感分类算法都主要基于机器学习中的经典分类算法,如朴素贝叶斯、决策树、支持向量机等。Wiebe等[6]首先提出利用朴素贝叶斯对文本进行主客观分类的方法,随后Pang等[7]受此启发,提出用于文本主客观分类的层次模型,先将文本进行主客观分类再进行情感分类。Pang等[8]还最先将机器学习的方法应用到文本的情感分类问题中,他们用机器学习经典的朴素贝叶斯、最大熵和支持向量机方法对电影评论进行了情感分类。目前多数情感分析的研究都是基于评论等主观性较强的文本,对于新闻事件这样客观性较强的文本的情感分析研究并不多。
有监督的学习算法主要通过人工标注的数据进行学习和训练。Jansen等[9]使用多项朴素贝叶斯模型对微博进行情感分析,Bermingham等[10]则在微博和博客的情感分析中对比了支持向量机和多项朴素贝叶斯方法,发现多项朴素贝叶斯方法在微博情感分析中比支持向量机方法更好。除了有监督的情感分类,还有很多基于情感词和词组的无监督情感分类方法,Hu等[11]提出了基于情感词典的方法,通过WordNet[12]中的同义词和反义词关系建立情感词典,通过统计正、负极性的情感词进行产品评论分析。Kim等[13]则通过情感词的组合来判断句子的情感。考虑到微博长度较短,词汇量丰富的特点,本文针对微博的情感分析方法并未采用基于情感词典的方法,而是采用基于语料库的方法。其它还有很多基于话题或者词向量等的情感分类方法,比如Tang等[14]用词向量嵌入的方法进行微博情感分类,Xiang等[15]使用基于话题的混合主题模型和半监督学习的方法提升微博情感分类的效果,Sun等[16]提出无监督的主题情感混合模型,通过采样情感标签对文本进行情感分类。本文在有监督的语言模型基础之上提出了情感语言模型,因此并没有考虑利用主题模型或者无监督的方法进行情感分类。
微博的情感分析方法源自传统文本的情感分析,但由于微博短小、表达不规范以及掺杂表情符号、链接和网络用语等特点,又产生了独特的研究方法,如Go等[17]用表情来分析微博情感,并用带表情的微博作为训练集对微博情感进行分类。Barbosa等[18]用带噪音微博情感预测作为训练集,使用感叹词、微博表情作为额外特征对微博情感分类。Zhao等[19]将新浪微博中的表情符号分类,然后将训练集中的微博按照表情进行标注,最后用朴素贝叶斯方法对微博进行分类。本文就采用了这种基于微博表情标注的分类方法进行模型的平滑,另外还结合了微博用户和社交网络的特征进一步提高分类效果。
2 微博情感分类模型
2.1语言模型的引入
语言模型分为概率语言模型和非概率语言模型两种。目前的主流是概率语言模型,本文中也将采用这种语言模型。微博情感分类问题实际上是一个分类问题。在概率语言模型中,每一个词都有一个概率,使用概率语言模型便可对分类问题进行计算。为了将语言模型应用到微博情感分类的问题上来,首先需要对微博情感分类问题进行定义。将同一个类别c的微博形成的集合视为一篇文档d,对于情感分类问题会有两篇文档,一篇是通过正面的微博训练数据得到的文档d1,另一篇是负面的微博训练数据得到的文档d2,然后需要对这两篇文档分别学习语言模型。在测试阶段,将每条待测试的微博t视为查询语句,分别计算这个查询语句与两篇文档的相似度,以此来对微博进行分类。用c1和c2分别表示正面和负面的微博类别。对于一条微博t,分别计算P(t|c1)和P(t|c2)的值,即微博t在这两个类别中的条件概率,通过这个条件概率来确定微博t的类别,通过下面的公式计算:
(1)
其中n是微博t中包含的词的个数,P(wi|c)就是t中的词wi在不同类别中的概率,需要通过语言模型计算得到,可以通过下面的公式计算:
(2)
其中Ni,c表示wi在类别c中出现的次数,Nc表示类别c中所有词出现的次数。通过这种方式计算的结果很大程度上依赖训练集形成的词典,对于在测试集中出现但未在训练集中出现的词,这个方法会出现问题。因此需要一种平滑方法来减少这种情况带来的误差。
2.2情感语言模型
根据Liu等[20]的假设,包含表情符号”:)”的微博都为正面的,所以考虑通过结合表情符号对语言模型进行平滑,平滑公式如下:
P(wi|c)=βPα(wi|c)+(1-β)Pu(wi|c)
(3)
基于这个假设,为了计算Pu(wi|c)的值,需要统计wi和”:)”共同出现的微博数量nwi,这些微博发布的时间长度twi,包含”:)”表情符号的微博数量ns和时间长度ts。从而可以通过下面的公式计算Pu(wi|c1):
(4)
式中分子部分表示单位时间内,wi在类别c的微博中出现的次数,分母部分表示单位时间内,在类别c的微博中出现的词的总数,L是微博的长度,一般微博的长度约为15,因此L的取值定为15。引入标准化因子:
(5)
其中|V|表示数据集中所有词的数量。从而可以通过下面的公式对Pu(wi|c1)进行标准化:
(6)
经过标准化后可以发现,Pu(wi|c1)的取值与ns和ts无关。同样基于假设可以计算Pu(wi|c2),只需将表情符号换成”:(”即可。
2.3情感分类
有了微博的条件概率,通过计算每条微博的条件概率对微博的情感进行分类。我们将情感分类的问题分为两个步骤,首先是主客观的分类,其次是情感分类。对于主客观分类,可以将前面的c1和c2分别视为主观类别和客观类别,利用前面的式(1)和式(2)计算每条微博的条件概率,并根据条件概率的大小对文本进行分类。接着进行情感分类,利用式(3)计算得到每条微博正面和负面两种类别的条件概率,再根据条件概率的大小进行分类。
3 情感分类模型的改进
3.1用户信用值
微博是用户发布的,从而发布微博的用户信用值具有一定的重要性。一个正常用户和一个试图改变舆论的用户所发表的微博应该是不同的,因此在计算微博的情感分类值时,应当将发布微博的用户的特征也计算在内。在微博中针对每个用户都有一个个人认证,同时有微博会员,微博达人等多种身份认证。获得个人认证的用户,都经过了微博的实名认证,因此这类人是可信的。微博达人则是参与微博活动较多的用户,其可信度较个人认证的用户稍低一些,但仍然是可信的。微博会员则需要用户花钱去购买,这类用户也具有一定的可信度。因此,根据用户的身份认证可以对用户的信用值进行设定,赋予每一个用户一个介于0到1之间的信用值,用P(ui)表示,其值越高,可信度越高。
3.2微博的网络特征
微博具有很强的社交性,微博可以被广泛地转发和评论,微博的这些特点使得微博中的信息能够广泛传播。用户转发微博这一行为,说明用户对于所发微博是感兴趣的,并且认同或者否定所转发微博观点的。对于用户对所发的微博是认同还是否定则根据转发时附加的文本内容来判断。如果文本内容中包含否定或者转折词,则认为是否定,否则认为是认同。根据这种转发行为可以看出,转发与情感也存在一定的相关性。由于微博的社交特性,某一事件的微博随着用户的转发往往能形成一个网络,而用户的情感也会随着网络而传递。基于微博的这种特性,我们引入因子Pg(t|c),根据网络的传播特性,可以使用链接分析中的TrustRank[21]算法来进行计算。对于两条微博u和v,如果v转发了u,那么就存在一条从u指向v的有向边,如果没有否定词或转折词,则权值为1,否则为-1。
3.3情感分类模型的改进
在引入P(ui)和Pg(t|c)之后,对上面的情感分类模型进行调整如下:
Pi(t|c)=αPf(t|c)P(ui)+(1-α)Pg(t|c)
(7)
其中,Pf(t|c)是式(1)中的P(t|c),i表示用户ui所发布的微博,P(ui)是用户ui的信用度,Pg(t|c)是该条微博经过网络迭代计算后的值。这样我们得到了改进的情感分类模型。这个模型结合了微博的特点,考虑了微博的用户和传播网络的特征,使得对微博的情感分类更加合理。
4 实 验
4.1实验数据集
为了减少重新进行人工标注所花费的时间,我们使用了之前邀请志愿者已经标注好的微博数据集,并通过分属于四个领域的八个事件来验证本文方法在不同领域下的效果。该数据集通过新浪微博的开放接口抓取微博数据,在抓取时尽量贴近事件发生的时间(例如两会和神九的抓取时间跨度分别为16天和14天,这分别是两会的开会时间和神九上天的时间)。抓取的数据集的统计信息在表1中。我们用E1到E8来表示这八个事件。在具体进行实验时,我们又从数据集中选取了抓取到的事件的一天内的全部微博,在对一些广告微博进行处理之后,每个事件的数据量在1000左右。
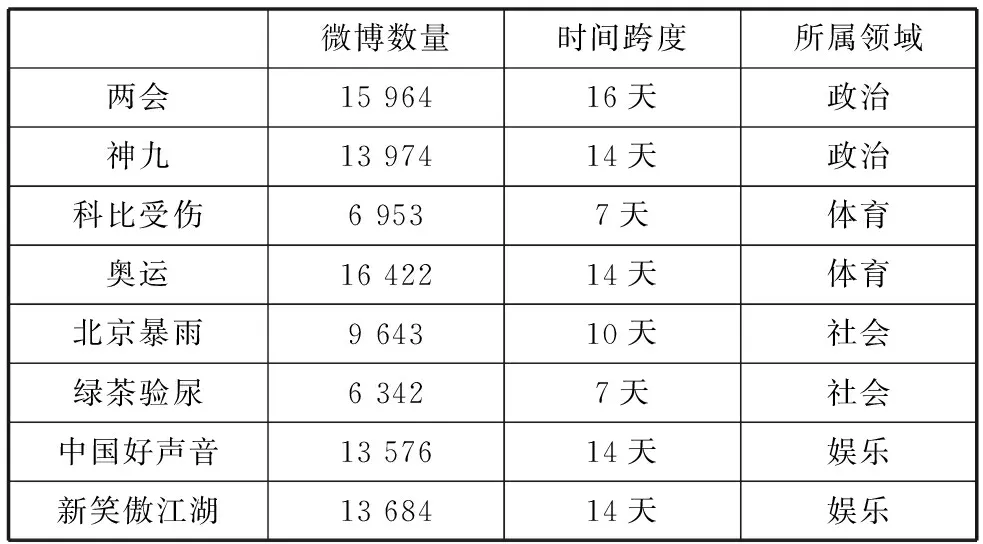
表1 微博数据集
4.2实验设定和评价标准
通过对比实验来验证本文方法以及基于微博特点改进的方法的有效性,我们实现了基于有监督学习的语言模型方法作为本文基于情感语言模型的方法的对比。对于本文所提的改进的情感分类模型的实验,我们首先使用仅增加用户信用值的模型以及仅增加微博网络特征的模型与本文所提的情感语言模型进行对比实验,以考察用户信用值和微博网络特征在改进的情感分类模型中的贡献度,最后再用同时结合用户信用和网络特征的模型与本文所提的情感语言模型进行对比以考察改进的方法对原语言模型的提升。我们使用LM表示基于有监督学习的语言模型方法,SLM表示基于情感语言模型的方法,SLM-u表示仅增加用户信用值的模型,SLM-n表示仅增加微博网络特征的模型,SLM-u,n表示同时结合用户信用和网络特征的模型。
在对微博语料进行分词时,由于微博中的网络词汇较多,我们进行了人工词典增补,添加了一些网络流行词汇(如“给力”等),以减少微博分词效果不好带来的影响。对于实验结果的评价,我们采用信息检索领域传统的评价指标准确率和F1对实验结果进行评价。
4.3实验结果与分析
基于语言模型的LM方法与本文情感语言模型的SLM方法在八个事件的数据集中对比实验的结果如图1所示。图中对每一个事件的微博情感分类结果分别列出了LM和SLM方法的准确率和F1值,最后一列M为所有事件情感分类结果的均值。从图中可以看出,本文所提的SLM方法在每个事件上的情感分类结果都要优于LM方法,而且本文的SLM方法准确率和F1值之间的差别较LM方法更小,表明本文基于情感语言模型的SLM方法比LM方法能对更多的微博进行情感分类,更适合于微博的情感分类任务。
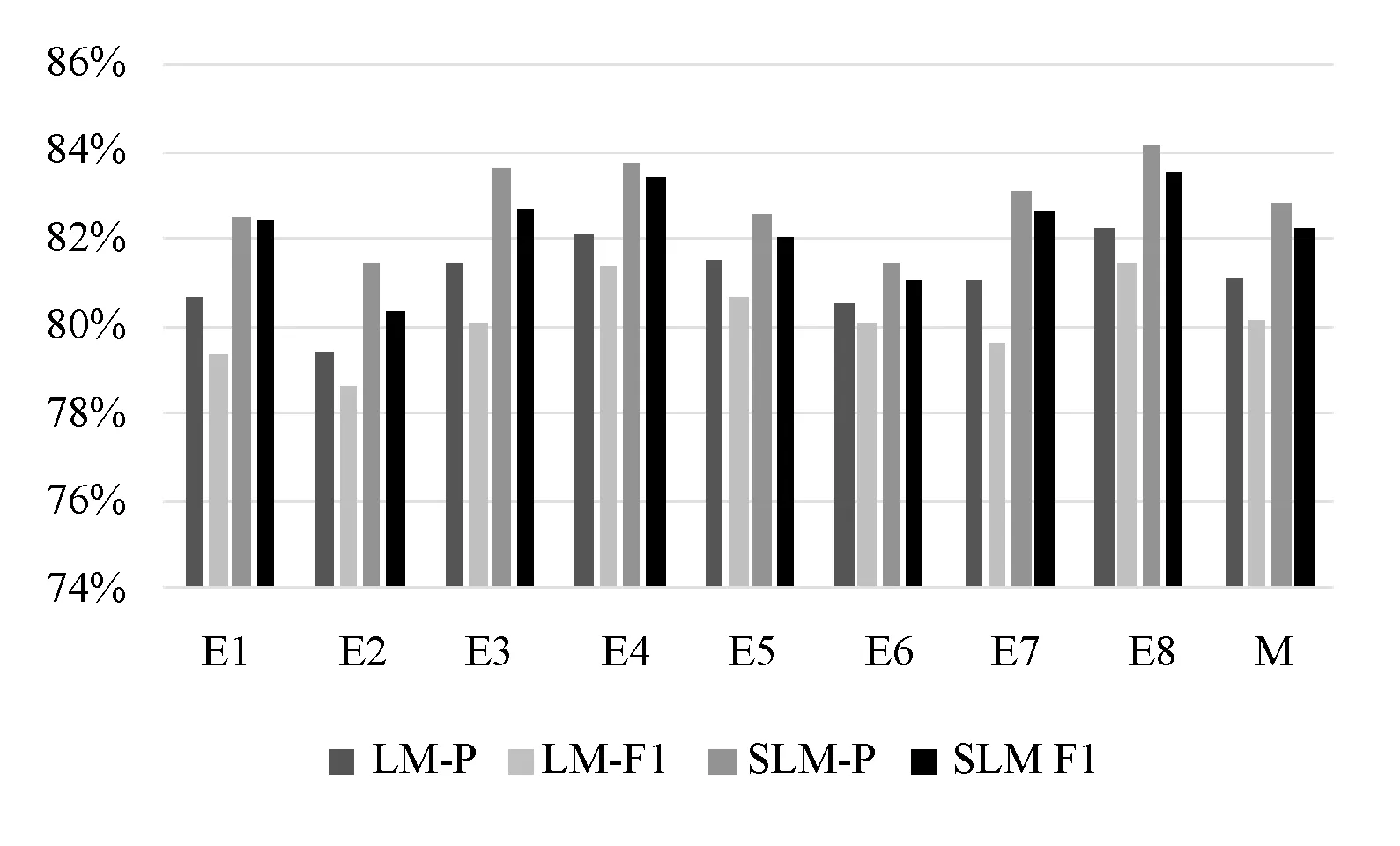
图1 微博情感分类结果
为了比较不同改进模型的情感分类效果,我们直接比较这些改进的模型和原模型在八个新闻事件上情感分类结果的平均值。不同的改进后情感分类模型的实验结果如图2所示。从图中可以看出加入用户信用值比加入微博网络特征对原模型的提升更多,并且最终改进的情感分类模型比原模型有显著的提升。SLM-u方法将每个用户的信用特征都加入到模型中,而由于微博转发网络的稀疏性,微博缺乏足够的转发量,SLM-n方法中用户的情感没有广泛地传播,因而SLM-n方法没有SLM-u方法对模型的提升更明显。SLM-u,n方法充分结合了微博的特点,从而能够更好地对微博进行情感分类。
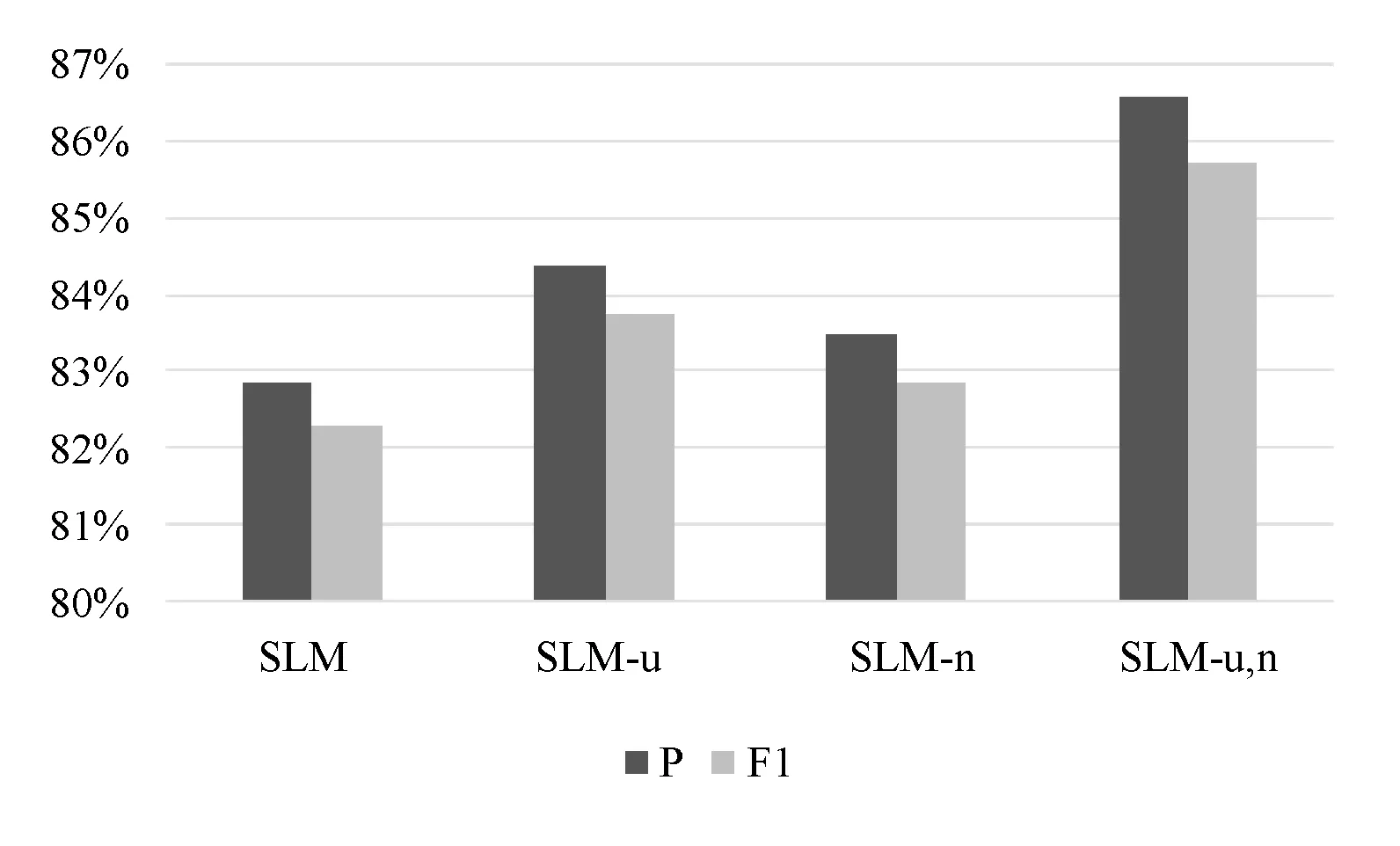
图2 微博情感分类改进结果
5 结 语
本文结合微博的相关特点对微博情感分析问题进行了研究。首先将语言模型引入微博情感分类的问题中,并在原有的语言模型基础之上提出了情感语言模型,通过微博表情符号的标注,计算微博的条件概率对微博进行情感分类。此外,我们还结合微博用户和社交网络的特点,将用户的信用值和情感在微博网络中的传播特征加入到情感语言模型中,进一步改进了情感语言模型。在新闻事件数据集上的实验结果表明,本文所提出的基于情感语言模型的方法能够很好地对微博情感进行分类,而且加入微博网络特征和用户信用对模型的情感分类效果有显著的提升。
虽然本文基于微博网络特征和用户信用的情感分类模型在新闻事件数据集上取得了良好的效果,但是本文的情感分类方法对于中文分词和表情标注的效果依赖度很高,糟糕的分词结果或者表情标注的噪音都会影响最终的分类效果。另外,本文有监督的学习方法在数据量特别大的数据集上效率不高,未来还可以考虑无监督的学习方法。
[1]AlexanderPak,PatrickParoubek.Twitterasacorpusforsentimentanalysisandopinionmining[C] //ProceedingsoftheInternationalConferenceonLanguageResourcesandEvaluation.Valletta,Malta:LREC, 2010: 1320-1326.
[2]FeldmanR.Techniquesandapplicationsforsentimentanalysis[J].CommunicationsoftheACM, 2013, 56(4): 82-89.
[3]BingLiu.SentimentAnalysisandopinionmining[M].Morgan&ClaypoolPublishers, 2012: 1-167.
[4]BautinMikhail,LohitVijayarenu,StevenSkiena.InternationalsentimentanalysisforNewsandBlogs[C] //ProcoftheInternationalConferenceonWeblogsandSocialMedia.Seattle:ICWSM, 2008: 19-26.
[5]BoPang,LillianLee.Opinionminingandsentimentanalysis[J].JournalFoundationsandTrendsinInformationRetrieval, 2008, 2(1): 1-135.
[6]WiebeJanyceM,BruceRebeccaF.O’haraThomasP.Developmentanduseofagold-standarddatasetforsubjectivityslassifications[C] //Proceedingsofthe37thAnnualMeetingoftheAssociationforComputationalLinguisticsonComputationalLinguistics.Maryland,USA:ACL,1999: 246-253.
[7]PangB,LeeL.Asentimentaleducation:sentimentanalysisusingsubjectivitysummarizationbasedonminimumcuts[C] //Proceedingsofthe42ndAnnualMeetingonAssociationforComputationalLinguistics.Barcelona,Spain:ACL, 2004: 271.
[8]PangB,LeeL,SVaithyanathan.Thumbsup?sentimentclassificationusingmachinelearningtechniques[C] //ProceedingsoftheACL-02ConferenceonEmpiricalMethodsinNaturalLanguageProcessing,EMNLP, 2002: 79-86.
[9]BernardJJansen,MimiZhang,KateSobel,etal.Twitterpower:tweetsaselectronicwordofmouth[J].JournaloftheAmericanSocietyforInformationScienceandTechnology, 2009, 60(11): 2169-2188.
[10]AdamBermingham,AlanFSmeaton.Classifyingsentimentinmicroblogs:isbrevityanadvantage? [C] //Proceedingsofthe19thACMInternationalConferenceonInformationandKnowledgeManagement.Toronto:CIKM, 2010: 1833-1836.
[11]HuM,LiuB.Miningandsummarizingcustomerreviews[C] //ProceedingsofthetenthACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.Seattle:SIGKDD, 2004: 168-177.
[12]MillerGA.WordNet:alexicaldatabaseforenglish[J].CommunicationsoftheACM, 1995, 38(11): 39-41.
[13]KimSM,HovyE.Determiningthesentimentofopinions[C]//Proceedingsofthe20thInternationalConferenceonComputationalLinguistics,ICCL2004: 1367.
[14]DuyuTang,FuruWei,NanYang,etal.Learningsentiment-specificwordembeddingfortwittersentimentclassification[C] //Proceedingsofthe52ndAnnualMeetingoftheAssociationforComputationalLinguistics.Baltimore,Maryland,USA:ACL, 2014: 1555-1565.
[15]BingXiang,LiangZhou.ImprovingtwittersentimentanalysiswithTopic-Basedmixturemodelingandsemi-supervisedtraining[C] //Proceedingsofthe52ndAnnualMeetingoftheAssociationforComputationalLinguistics.Baltimore,Maryland,USA:ACL, 2014: 434-439.
[16] 孙艳, 周学广, 付伟. 基于主题情感混合模型的无监督文本情感分析[J]. 北京大学学报:自然科学版, 2013, 49(1): 102-108.
[17]GoA,BhayaniR,HuangL.Twittersentimentclassificationusingdistantsupervision.CS224N[R]ProjectReport,Stanford, 2009: 1-12.
[18]BarbosaL,FengJ.Robustsentimentdetectionontwitterfrombiasedandnoisydata” [C] //Proceedingsofthe23rdInternationalConferenceonComputationalLinguistics:Posters, 2010: 36-44.
[19]ZhaoJ,DongL,WuJ,etal.Moodlens:anemoticon-basedsentimentanalysissystemforChinesetweets[C] //Proceedingsofthe18thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining2012: 1528-1531.
[20]KunLinLiu,WuJunLi,MinyiGuo.Emoticonsmoothedlanguagemodelsfortwittersentimentanalysis[C] //ProceedingsofTwenty-SixthAAAIConferenceonArtificialIntelligence. 2012: 1678-1684.
[21]GyöngyiZ,Garcia-MolinaH,PedersenJ.CombatingWebspamwithtrustrank[C] //Proceedingsofthe30thVLDBConference.Toronto,Canada: 2004:576-587.
MICROBLOGSENTIMENTANALYSISCOMBININGFEATUREOFMICROBLOGGINGNETWORKANDUSER’SCREDIT
YeErlan·HeZhati1LiPeng2
1(XinjiangPeople’sBroadcastingStation,Urumqi830000,Xinjiang,China)2(SchoolofElectronicsEngineeringandComputerScience,PekingUniversity,Beijing100871,China)
Traditionalsentimentanalysismethoddoesnotadequatelyconsiderthecharacteristicsofmicroblogitself,andishardtoachieveexcellenteffectonmicrobloggingdatawhichisshort,irregularandfullofnoises.Combiningwiththecharacteristicsofmicrobloggingcontentitself,inthispaperweproposeasentimentlanguagemodelsuitableforthetaskofmicroblogsentimentclassification,andfurtherconsiderthefeaturesofmicroblogginguserandsocialnetwork.Moreover,wemaketheimprovementsontheproposedsentimentlanguagemodelbasedonthepropagationofthesentimentonnetworkforwardedbymicroblogsandthevalueofuser’scredit.Itisdemonstratedbytheresultsofexperimentonannotatednewseventsdatasetsthatthismethodcaneffectivelycarryoutsentimentclassificationonthemicroblogscorrelatedwithnewsevents,andoutperformstraditionallanguagemodel-basedmethodinindexessuchasprecision,etc.,furthermore,theadditionofthenetworkcharacteristicsofmicroblogsanduser’screditcansignificantlyimprovetheeffectofmicrobloggingsentimentclassification.
MicroblogSentimentanalysisSocialnetworkTextclassificationLanguagemodel
2015-07-26。叶尔兰·何扎提,高工,主研领域:信息检索,文本挖掘。李鹏,硕士。
TP
ADOI:10.3969/j.issn.1000-386x.2016.10.022
