基于深度自编码网络的异质人脸识别
2016-11-08刘超颖
刘超颖 杨 健 李 俊
(南京理工大学计算机科学与工程学院 江苏 南京 210094)
基于深度自编码网络的异质人脸识别
刘超颖杨健李俊
(南京理工大学计算机科学与工程学院江苏 南京 210094)
针对异质人脸识别中对不同模态数据间关系建模的问题,提出一种基于深度自编码网络的异质人脸特征提取和识别方法。首先用一个深度降噪自编码网络从两类异质人脸图像中提取人脸的高阶特征,并通过类别监督信号产生的目标函数来对网络进行微调,最后利用最近邻分类器对已提取特征分类,完成异质图像间的匹配。在CUHK、AR、CASIA HFB、SVHN与MNIST数据集上的实验结果表明,与目前基于子空间学习的异质人脸识别方法相比,该方法取得了更高的识别率,并且在基于异质图像的数字识别上表现出一定优势。
异质人脸识别深度自编码网络深层学习
0 引 言
人脸识别研究中,大部分所用的待识别人脸图像和数据库中的人脸图像都是同一模态的图像。然而在实际应用中待处理图像可能来自多种模态,例如近红外模态、可见光模态、素描模态等,这类不同模态人脸图像之间的识别问题属于异质人脸识别。2002年Tang等人[1]首先提出异质人脸识别问题,尽管最初异质人脸识别定义广泛,但目前最热门的两个研究是素描人脸识别[2]和近红外与可见光人脸识别[3],本文也将就这两个问题展开讨论。基于素描画像的人脸识别是个人身份认证中的一项关键技术,在安全保卫、犯罪嫌疑人搜捕等法律执行方面具有较大的实用价值。另一方面,虽然近红外人脸识别克服了可见光人脸识别中的光照问题,然而许多应用仍要求采用可见光图像对人员进行登记注册,原有近红外人脸识别在这种情况下是不可行的。为了实现可见光与近红外人脸的交叉注册与认证,提出了近红外与可见光人脸识别问题。
由于异质图像成像机理不同,不同模态图像间往往表现出巨大差异,因此采用以往单个模型的方法对异质图像比较是不可行的。一个直观的想法是减少不同模态图像外观上的差异,以提高人脸识别性能。Tang等[4]提出了一种方法,由素描合成伪照片,然后在照片模式下进行识别。Liu等人[5]针对该问题提出了一种非线性的方法,该方法基于流形学习中的局部线性嵌入LLE(Local Linear Embedding)将照片合成素描,然后利用非线性判别分析识别素描图像。文献[6]也提出了一种将可见光人脸图像转化为近红外人脸图像的方法。上述基于合成的方法主要是将异质图像转换到同一模态,再利用传统的人脸识别方法进行识别。Lin等[7]提出了使用CDFE(common discriminant feature extraction)的方法,将两类异质人脸图像投影到一个含有鉴别特征的公共子空间。CDFE方法能取得较高的识别率,但训练过程相对耗时,更适用于小样本数的情况。Yi等人[3]提出一种方法,分别在近红外和可见光人脸图像空间建立PCA[8]或LDA[9]子空间模型,通过典型相关分析CCA(canonical correlation analysis)的方法学习子空间的线性变换以对不同模态图像间的关系建模。Lei等[10]从图形嵌入和光谱回归的角度提出了耦合光谱回归CSR(Coupled Spectral Regression)的方法,CSR方法较以往方法具有更好的泛化能力。
从学习的角度来说,上述浅层模型一方面在计算机视觉中只能从丰富的数据中提取一些简单的特征,不能提取复杂结构的特征[11];另一方面在人工智能的任务中用大量的参数来表示一个功能,进而增加计算复杂度[12]。近年来在国际著名学者G. E. Hinton教授推动下,深层学习成为一种强有力的稳健分类方法,并且在语音识别[13,14]和图像识别[15-17]等应用领域获得了巨大的成功。针对异质人脸识别问题的特殊性、结合深层学习具有强大的数据特征学习能力的特点,本文提出了一种基于深度自编码网络的异质人脸识别方法。针对两类不同模态的数据,采用两个并行的深度自编码网络对异质图像进行监督训练,得到接近于类别信息的特征表,将网络的最终输出作为分类器的特征输入,完成异质人脸匹配。如图1所示,与原有方法相比,本文采用深层模型代替原有浅层学习模型,并且加入类别监督信号,将异质图像投影到类别子空间,这类特征表示更具有分类能力。本方法有如下优点:(1)从深层学习的角度解决异质人脸识别中的特征表示问题,在训练集与测试集类别重复情况下表现了监督训练的优势;(2)对旋转图像、真实环境图像都有较好的处理能力;(3)模型直观,可扩展到处理多模态异质图像的识别问题。

图1 两类异质人脸识别问题示例
1 基于深度自编码网络的异质人脸识别
由于成像方式不同,同一个人的近红外和可见光人脸图像在表观上存在着显著差异。但是从认知的角度讲,它们仍然可以被识别成为同一个人。这就意味着:1)近红外和可见光图像存在某种形式的关联;2)存在可识别的不变特征。本模型是基于以降噪自动编码器为结构单元的深度自编码网络,首先介绍降噪自动编码器与深度自编码网络。
1.1降噪自动编码器
自动编码器[18]就是一种尽可能复现输入信号的神经网络,它假设自身的输入与输出是相同的,通过训练调整网络参数,得到每一层的训练权重,则隐含层就是原始输入信号的近似表达,从而实现了无监督的特征提取。降噪自动编码器[19]是自动编码器的一个变形,它对原始输入加入噪声得到一个受污染的输入,降噪自动编码器必须学习去除这种噪声而还原真正的没有被噪声污染过的输入,这就迫使编码器去学习输入信号的更加鲁棒的表达,这也是它的泛化能力比传统编码器强的原因。
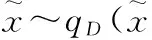
(1)

(2)
其中θ′={W′,b′},W′是d′×d的权重矩阵,W′可等于WT,此时称网络具有对称权重,b′是偏移向量。

(3)
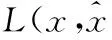
1.2深度自编码器网络
深度自编码网络[20]是由多个自动编码器或其变形模型堆叠而成的神经网络,前一层自动编码器的隐含层输出作为后一层自动编码器的输入,本文采用上述降噪自动编码器作为深度自编码网络的结构单元。
类似于深度置信网络[11],深度自编码网络采用逐层贪婪算法初始化网络:首先采用无监督学习算法对低层的降噪自动编码器进行训练,生成第一层深度自编码网络的初始参数值;然后将第一层的输出作为下一层的输入,同样采用无监督学习算法对该层参数进行初始化。在对多层进行初始化后,通常在顶层添加一个分类器,用监督学习算法对整个神经网络进行微调。这里要指出的是,为了学习到更加鲁棒的特征,逐层训练时每一层降噪自动编码器的输入都需要加入噪声。
由此,深度神经网络的精髓就是模拟人的视觉系统对信息的分级处理过程,这是一个不断迭代、不断抽象的过程。高层的特征是低层特征的组合,特征表示也更抽象,更能表现语义或者意图。而抽象层面越高,存在的可能猜测就越少,就越利于分类。
1.3实现细节
异质人脸识别的核心在于如何对不同模态数据的关系建模,同时保留其中具有鉴别能力的特征。显然,类别信息是最具鉴别能力的特征之一。基于此想法,本文以类别信号监督训练两个深度自编码网络,对两类异质图像间的关系建模。
以近红外与可见光人脸识别为例,模型结构如图2所示。深度自编码网络的输入层神经元个数为图像数据维度,输出层神经元个数为目标类别个数,根据实验效果调整网络层数以及每个隐含层神经元个数。在训练阶段,采用深度自编码网络1对近红外模态图像进行训练,深度自编码网络2对可见光模态图像进行训练,网络的监督信号为类别信息。在测试阶段,两类异质图像经过深度自编码网络投影到公共的类别子空间,采用最近邻分类器完成异质人脸匹配。

图2 模型示例
深度自编码网络可看作对异质图像的特征提取过程,由于加入了类别监督,学习到的特征更具有分类能力。对输出层特征采用最近邻分类器即可完成异质人脸图像的匹配。需要指出的是,由于深层学习是从样本自身去学习特征,模型对样本数量有一定要求,并且本方法是基于监督学习,因此它要求测试集的人都包含在训练集中。
2 实 验
为了验证上述模型的效果,本文在四个数据集上完成了三组实验,分别针对素描与照片人脸识别、近红外与可见光人脸识别以及手写数字与街景数字识别,同时将本方法与现有异质人脸方法PCA+CCA[3]、LDA+CCA[3]、CDFE[7]、CSR[10]、DSR[21]进行了比较。在匹配阶段,本文采用余弦距离衡量样本点间的相似度,其中余弦距离表示为:
(4)
2.1素描与照片人脸识别
针对素描与照片人脸识别问题,本文在CUFS数据集[2]中的CUHK数据集与AR数据集上进行了实验。CUHK数据集取自188名香港中文学生,每人对应一张照片图像和一张素描图像,共有376张人脸图像。AR数据集包含123人,每人对应一张照片图像和一张素描图像,共有246张人脸图像。其中,照片为彩色图像、素描为灰度图像,图像维度均为200×250。
如1.3节所述,原始CUHK和AR数据集中样例过少,训练集与测试集的设置方案不符合本模型适用情况。为此本文对数据做如下处理:调整图像大小,对每张图像在-15度到+15度的范围内进行旋转,提取图像中间20×20图像块作为实验使用数据。经过上述处理,每人对应20张素描图像与20张照片图像,每人10张素描与10张照片作为训练集,剩余图像作为测试集,多次实验以得到平均识别率。测试时以素描图像作为匹配图像,在一组照片图像中找到与之匹配的照片。

表2 CUHK和AR数据集上性能对比%
从表2可以看出,相比于PCA+CCA、LDA+CCA、CDFE、CSR和DSR,本文方法在素描与照片人脸识别上性能有了一定的提高。分析原因是由于训练集中已包含待验证人员的先验信息,通过引入监督信号,深度自编码网络能够学习到素描图像与照片图像的高阶特征,使得素描与照片人脸识别达到更佳的效果。
2.2近红外与可见光人脸识别
针对近红外与可见光人脸识别问题,本文在CASIA HFB数据集上[22]进行了实验。CASIA HFB数据集由来自202个人的3002张近红外图像和2095张可见光图像组成。这202人中,有2人未提供可将光照片,本文选择剩余200人近红外与可见光图像验证模型。在剩余200个人的2980张近红外图像和2095张可见光图像中,2305张近红外图像与1678张可见光图像作为训练集,余下675张近红外图像与417张可将光图像构成测试集,多次实验以得到平均识别率。其中,人脸图像均经过对齐、剪切处理,图像维度为128×128,本文将图像按比例缩减为32×32,并转换成1024维列向量作为模型输入。测试时,在一组可见光图像中,找到与近红外图像匹配的图像。

表3 CASIA HFB数据集上性能对比
从表3可以看出,本方法在CASIA HFB数据集上识别效果较PCA+CCA、LDA+CCA、CDFE、DSR更好,但略低于CSR。图3给出了测试集中五组匹配失败示例,可以看出存在表情(闭眼、微笑)、眼镜等干扰因素。本模型匹配效果依赖于两个深度自编码网络的学习能力,在处理近红外人脸图像时,单独的深度自编码网络不足以克服上述干扰因素,因此直接影响了近红外与可见光人脸识别的效果。

图3 CASIA HFB测试集匹配失败示例
第一行为近红外图像,第二行为对应的可将光图像,第三行为按本方法匹配失败得到的可见光图像。
2.3手写数字与街景数字识别

图4 街景数字(左)与手写数字(右)
手写数字与街景数字同属于异质图像,如图4所示,并且这两类图像表示更加真实丰富。为了验证本方法解决真实环境下异质图像识别问题的能力,本文结合MNIST数据集[23]与SVHN数据集[24],进行了如下实验。
MNIST数据集是一个公共的手写字体数据库,它由类别号为0-9的60 000张训练图像与10 000张测试图像组成。SVHN数据集由谷歌公司针对街景地图应用采集而成,它包含大量更加真实、复杂的街景门牌号图片。本文采用SVHN第二种格式数据进行实验,它由类别号为0-9的73 257张训练图像与26 032张测试图像构成,其中图像被分割成以单个字符为中心的32×32数据。针对手写数字与街景数字识别问题,本文选择MNIST中60 000张训练图像与SVHN中73 257张训练图像作为训练集,MNIST中10 000张测试图像与SVHN中26 032张测试图像为测试集,测试时,在一组手写数字图像中,找到与街景数字图像匹配的图像。如表4所示。

表4 MNIST-SVHN数据集上性能对比
由于SVHN数据集是将门牌号以单个数字切割成图像的,很多图像存在背景干扰与相邻数字干扰,很大程度影响了街景数字的学习效果,因此手写数字与街景数字识别效果没有上述两类识别问题正确率高。此外,PCA+CCA、LDA+CCA、CDFE、CSR和DSR方法必须基于对齐、规整的图像,这类方法处理手写数字与街景数字识别效果很差,在处理真实环境下异质图像识别问题时,本模型表现出了一定优势。
3 结 语
深度自编码网络具有强大的表达能力,它能够学习到输入数据更加有利于分类的高阶特征。异质人脸识别的核心是学得到一种特征表示,使同类样本距离更小、不同类样本距离更大。基于上述思想,本文提出一种基于深度自编码网络的异质人脸识别方法,利用两个并行的深度自编码网络对异质图像间的关系建模,在现有数据集上都取得了较好的识别效果。本模型为利用深层学习解决异质人脸识别问题奠定了了基础,同时也侧面验证了本方法处理真实环境下异质图像识别的优势。但是也有一些问题将在今后的工作中继续探讨,例如,本文的异质人脸识别情况只适合于内部人员交叉注册认证的情况,如何不依赖于类别信息学习异质图像间的关系是今后研究的重点。
[1] Tang X, Wang X. Face photo recognition using sketch [C]//2002 International Conference on Image Processing, Rochester, NY, USA, 2002. Rochester: IEEE, 2002,1:257-260.
[2] Wang X, Tang X. Face photo-sketch synthesis and recognition [J]. IEEE Transactions on Pattern Analysis and Machine intelligence, 2009, 31(11):1955-1967.
[3] Yi D, Liu R, Chu R, et al. Face matching between near infrared and visible light images[C]//2nd International Conference on Biometrics (ICB2007), Seoul, Korea, 2007. Seoul: Springer, 2007:523-530.
[4] Tang X, Wang X. Face sketch synthesis and recognition[C]//9th IEEE International Conference on Computer Vision (ICCV 2003), Nice, France, 2003. Nice: IEEE, 2003, 1:687-694.
[5] Liu Q, Tang X, Jin H, et al. A nonlinear approach for face sketch synthesis and recognition[C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 2005. San Diego: IEEE, 2005, 1:1005-1010.
[6] Wang R, Yang J, Yi D, et al. An analysis-by-synthesis method for heterogeneous face biometrics[C]//The 3rd IAPR/IEEE International Conference on Biometrics (ICB 2009), Alghero, Italy, 2009. Alghero: Springer, 2009:319-326.
[7] Lin D, Tang X. Inter-modality face recognition[C]//9th European Conference on Computer Vision (ECCV 2006), Graz, Austria, 2006. Graz: Springer, 2006:13-26.
[8] Turk M, Pentland A. Face recognition using eigenfaces[C]//1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 1991), Maui, HI, 1991. Hawaii: IEEE, 1991:586-591.
[9] Belhumeur P, Hespanha J, Kriegman D. Eigenfaces vs.f isherfaces: recognition using class specific linear projection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(7):711-720.
[10] Lei Z, Li S. Coupled spectral regression for matching heterogeneous faces[C]// 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, Florida, USA, 2009. Miami: IEEE, 2009:1123-1128.
[11] Hinton G E, Salakhutdinov R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313:504-507.
[12] Bengio Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1):1-127.
[13] Lee H, Pham P, Largman Y, et al. Unsupervised feature learning for audio classification using convolutional deep belief networks[C]//Advances in Neural Information Processing Systems 22 (NIPS 2009), Vancouver, British Columbia, Canada, 2009. Vancouver: MIT Press, 2009:1096-1104.
[14] Hamel P, Eck D. Learning features from music audio with deep belief networks[C]//11th International Society for Music Information Retrieval Conference (ISMIR 2010), Utrecht, Netherlands, 2010. Utrecht: International Society for Music Information Retrieval, 2010:339-344.
[15] Taylor G, Hinton G, Roweis S. Modeling human motion using binary latent variables[C]//Advances in Neural Information Processing Systems 19(NIPS 2006), Vancouver, British Columbia, Canada, 2006. Cambridge: MIT Press, 2007:1345-1352.
[16] Nair V, Hinton G. 3D object recognition with deep belief nets[C]//Advances in Neural Information Processing Systems 22 (NIPS 2009), Vancouver, British Columbia, Canada, 2009. Vancouver: MIT Press, 2009:1339-1347.
[17] Li J, Chang H, Yang J. Sparse Deep Stacking Network for Image Classification[C]//29th AAAI Conference on Artificial Intelligence (AAAI 2015), Austin, Texas, USA, 2015. Austin: AAAI Press, 2015:1-7.
[18] Bengio Y, Lamblin P, Popovici D, et al. Greedy layer-wise training of deep networks[C]//Twenty-First Annual Conference on Neural Information Processing Systems(NIPS 2007), Vancouver, British Columbia, Canada, 2007. Cambridge: MIT Press, 2007:153-160.
[19] Vincent P, Larochelle H, Bengio Y, et al. Extracting and Composing Robust Features with Denosing Autoencoders[C]//25th International Conference on Machine Learning (ICML 2008), Helsinki, Finland, 2008. Helsinki: ACM, 2008:1096-1103.
[20] Vincent P, Larochelle H, Lajoie I, et al. Stacked denoising autoencoders: learning useful representations in a deep network with a local denoising criterion[J]. Journal of Machine Learning Research, 2010, 11(3):3371-3408.
[21] Huang X, Lei Z, Fan M, et al. A regularized discriminative spectral regression method for heterogeneous face matching[J]. IEEE Transaction on Image Processing, 2013, 22(1):353-362.
[22] Li S, Lei Z, Ao M. The HFB face database for heterogeneous face biometrics research[C]//6th IEEE Workshop on Object Tracking and Classification Beyond and in the Visible Spectrum (OTCBVS, in conjunction with CVPR 2009), Miami, Florida, 2009. Miami: IEEE, 2009:1-8.
[23] Lecun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of The IEEE, 1998, 86(11):2278-2323.
[24] Netzer Y, Wang T, Coates A, et al. Reading Digits in Natural Images with Unsupervised Feature Learning[C]//NIPS 2011 workshop on deep learning and unsupervised feature learning, Granada, Spain, 2011. Granada: MIT Press, 2011(2):5.
HETEROGENEOUS FACE RECOGNITION BASED ON DEEP AUTO-ENCODER NETWORKS
Liu ChaoyingYang JianLi Jun
(SchoolofComputerScienceandEngineering,NanjingUniversityofScienceandTechnology,Nanjing210094,Jiangsu,China)
Considering the problem of modelling the relation between different modalities data in heterogeneous face recognition, we proposed a heterogeneous face feature extraction and recognition method, which is based on deep auto-encoder networks. The method first extracts the high-order feature from two kinds of heterogeneous face image respectively using one deep denoising auto-encoder networks. Then, it fine-tunes the network through the objective function generated by category monitoring signals. Finally, it uses nearest neighbour classifier to classify the extracted features so as to complete the matching of heterogeneous face images. Results of experiments conducted on datasets of CUHK, AR, CASIA HFB, SVHN and MNIST showed that, compared with existing subspace learning-based heterogeneous face recognition methods, the proposed one reaches higher recognition rate, and exhibits certain advantage in heterogeneous image-based digital recognition.
Heterogeneous face recognitionDeep auto-encoder networkDeep learning
2015-08-17。国家杰出青年科学基金项目(611253 05)。刘超颖,硕士生,主研领域:异质人脸识别,深度学习。杨健,教授。李俊,博士。
TP391.4
A
10.3969/j.issn.1000-386x.2016.10.039
