一种低信噪比条件下的高可懂度的语音增强算法
2016-11-08马建芬张雪英
孟 欣 马建芬 张雪英
(太原理工大学计算机科学与技术学院 山西 太原 030024)
一种低信噪比条件下的高可懂度的语音增强算法
孟欣马建芬*张雪英
(太原理工大学计算机科学与技术学院山西 太原 030024)
研究表明,增强后的语音与纯净语音相比,会存在两种不同类型的畸变:放大畸变和衰减畸变,而放大畸变对语音可懂度的影响较大。传统的语音增强算法大多不能有效提高语音增强后的可懂度,因为这些算法仅使用最小均方误差的方法来限制这两种畸变,从而抑制噪声,提高语音的质量,但忽略了不同的畸变类型对可懂度的影响不同。提出一种基于子空间的提高可懂度的语音增强算法,使用先验信噪比及增益矩阵来判断语音畸变的类型。同时注意到,在估计先验信噪比时会存在估计误差:高估和低估,而高估会产生放大畸变,对可懂度造成较大的影响。先对高估先验信噪比(小于-10dB)的增益矩阵进行修正,然后再对幅度谱畸变大于0dB及6.02dB的语音进行不同的限制。实验表明,所提出的算法能够有效增强语音的可懂度。
子空间语音可懂度语音畸变先验信噪比增益矩阵
0 引 言
语音增强所关心的问题是改善加噪语音的感性性能,目的是提高加噪语音的质量和可懂度。在长时间听一段语音时,听者的疲劳度会增加,提高语音质量可以降低听者的疲劳度。所以到目前为止,很多算法(包括谱减法、维纳滤波算法、统计模型算法及子空间法)都致力于提高语音的质量,且它们都能在一定程度上提高语音的质量。但它们都不能有效地提高语音的可懂度[1],因为它们都是使用最小均方误差的方法来抑制噪声。实际上,增强后的语音与纯净语音相比存在两种畸变:放大畸变和衰减畸变。放大畸变指的是语音增强后的幅度谱大于相对应的纯净语音的幅度谱;衰减畸变正相反,指的是语音增强后的幅度谱小于相对应的纯净语音的幅度谱。研究表明[2],不同的畸变类型对可懂度的影响不同。最小均方误差的方法把放大畸变和衰减畸变混在一起计算平均误差,忽略了不同的畸变类型给可懂度带来的影响。
近年来,很多研究都致力于通过减少语音畸变来提高语音增强的性能,包括改进的子空间法[3]、改进的谱减法[4]、改进的维纳滤波算法[5]、基于统计的方法(包括使用压缩感知[6]和非负矩阵分解[7]等)以及深度神经网络(DNN)的方法[8]。文献[3-5]是基于传统子空间法、谱减法和维纳滤波方法的改进,这些方法能在一定程度上提高语音的可懂度,但均只考虑了放大畸变大于6.02dB时对可懂度的影响。经实验验证,这些方法只有在实验数据量较少时能够提高少量加噪语音的平均可懂度,在实验数据较多时并没有明显提高语音的平均可懂度。而文献[6-8]中的方法虽然采用了先进的技术,但复杂度明显提高且可懂度并没有很大程度提高。
本文利用“直接判决”法[10,11]估计先验信噪比,在估计先验信噪比时会存在两种不同类型的误差[9,12]:高估和低估。高估指的是使用增强算法时估计的先验信噪比高于理想条件下的先验信噪比,低估指使用增强算法估计时先验信噪比低于理想条件下的先验信噪比。在文献[9]中采用聚类的方法减少“直接判决”法引入的高估和低估,但复杂度也明显提高。在文献[12]中通过限制先验信噪比小于-10db区域的高估同样能有效提高语音的可懂度。
为了减少复杂度,本文提出了一种改进的基于子空间的方法。但不同于文献[3-5]中的方法,本文讨论了所有放大畸变对可懂度的影响,并采用文献[12]中的方法,对先验估计信噪比进行修正,从而获得更高可懂度的语音增强算法。在实验中使用大量的实验数据证明本文提出的算法能够更有效提高可懂度。
1 子空间语音增强算法
假设噪音信号为x,纯净语音信号为s,噪声信号为n,且s与n互不相关,即:
x=s+n
(1)
其中x、s、n都是K维的信号矢量。
定义:
(2)
其中R·表示相应的信号矢量的协方差矩阵。对Σ进行特征分解:
ΣV=VΛΣ
(3)
式中V和ΛΣ分别代表Σ的特征向量和特征值。此处假设Σ的特征值按照λΣ(1)≥λΣ(2)≥…≥λΣ(k)排序,估计语音信号子空间的维度定义为:
(4)

(5)
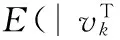
条件:
(6)
通过特征值分解以及代换处理[13,14],可以得到第m帧的增益矩阵的第k个对角线元素为:
(7)
其中μ可以通过如下公式计算得到[15]:
(8)
其中μ0=4.2,s0=6.25。SNRdB(k,m)为第m帧第k个谱分量的信噪比,记相应的后验信噪比为γ(k,m),则SNRdB(k,m)=10lgγ(k,m),其中:
(9)
记先验信噪比为ξ(k,m),可以由“直接判决”法[10,11]计算:
(10)
其中:a表示平滑系数,一般为0.8~1,此处取0.98。
2 修 正
在估计先验信噪比时,存在高估和低估,文献[9,12]中对高估和低估产生的区域及其对可懂度产生的影响进行了实验说明。通过对比真实信噪比和先验信噪比的值,得出在小于-10dB时,高估的情况较多。并通过试听测试,对比说明了高估时对可懂度的影响较大。
本文充分利用该技术,先对本算法的增益矩阵进行修正,即通过文献[12]的人工引入偏差方法对先验信噪比小于-10dB区域的增益矩阵进行修正,来提高可懂度:
gw(k,m)=(1-B)·g(k,m)+B20lg(ξ(k,j))<-10dB
(11)
其中,B为引进的修正系数。在本文中,分别对B取0.1、0.2、0.3、0.5、0.6、0.7、0.9,结果显示B取0.2时得到的效果最好。
3 高可懂度算法
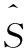
设第m帧第k个谱分量的纯净信号与增强信号比为:
(12)
将式(12)进行推导:
(13)
根据不同的放大区域对幅度谱进行限制:
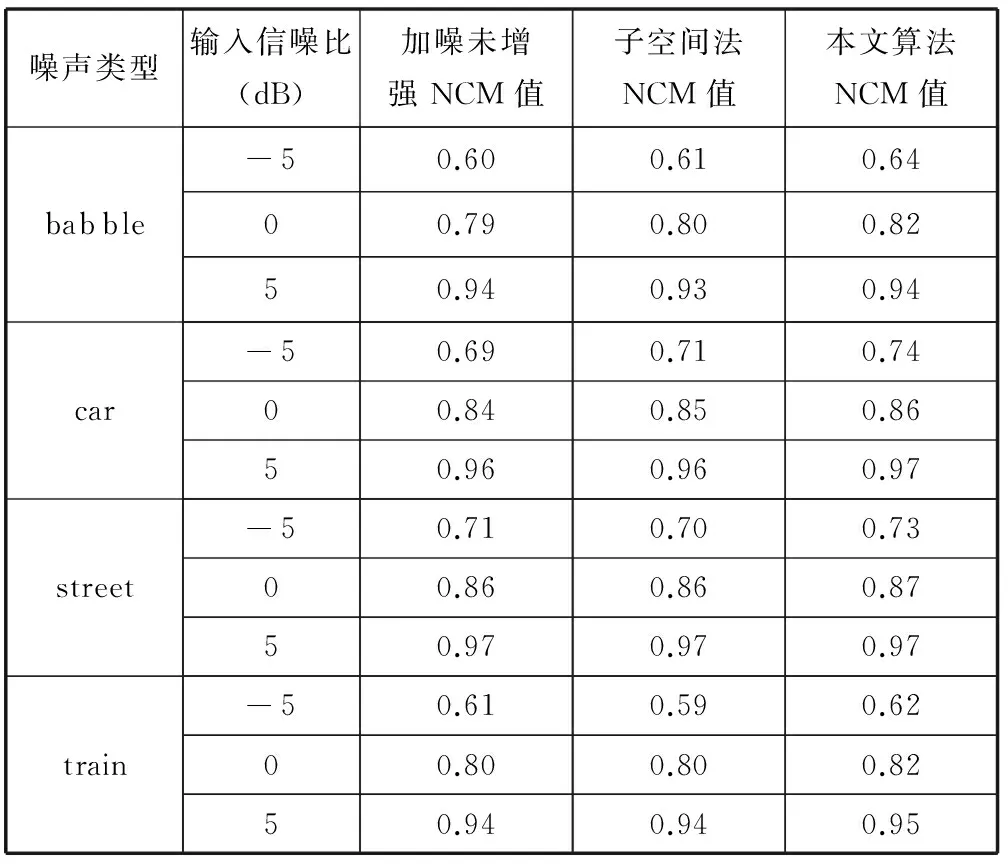
(14)
实验中,根据不同放大倍数对ρ(k,m)进行了从0.5~1的以0.05为增幅的递增取值,共进行了10×10,即100组实验。根据实验显示,当0.5 (15) (16) 根据本文所述的思路,可以通过如下步骤得到增强后的语音信号: (1) 计算出后验信噪比γ(k,m),见式(9); (2) 计算出系数μ,见式(8); (3) 计算出修正高估后增益矩阵的第m帧第k个对角元素gw(k,m),见式(7)和式(11); (4) 估计先验信噪比ξ(k,m),见式(10); (5) 估计纯净信号与噪音信号比SNRs/e,见式(13); 本文使用Matlab仿真验证语音可懂度算法的增强效果。噪声信号来源于Noisex-92噪声库中的4种噪音,分别为babble、car、street、train。纯净句子语音信号来自IEEE句子语音库的全部720组句子,纯净辅音信号来自IEEE辅音库的全部30组辅音。纯净语音及噪音的采样率均为8KHz,量化精度为16bit。 研究表明,经过增强算法增强过的语音与加噪未增强的语音相比,可懂度会降低,最好的情况就是持平,且子空间法是所有增强算法中效果最好的一种增强算法[1]。所以本文选用子空间法和加噪未增强与本文的增强算法进行对比。 本文对720组纯净句子语料分别在信噪比为-5dB,0dB及5dB的情况下进行加噪。在同一组信噪比条件下,分别使用加噪未增强、子空间算法和本文算法对加噪语音进行处理。同一种信噪比下的同一种类型噪声经过同一种降噪处理可以得到1种测试条件,再将这种测试条件下的720组句子的客观可懂度的平均值作为最终的可懂度值。这样的测试条件共有3×4×3,即36种。本文对30组纯净辅音语料分别在-15、-10、-5及5dB的情况下进行加噪。与句子相同,在同一组信噪比条件下,分别使用加噪未增强、子空间算法和本文算法对加噪语音进行处理。这样,测试条件共有4×4×3,即48种。 〗本文的可懂度测试采用NCM(归一化协方差法)[17]。该方法对于句子来说,与主观可懂度评价的相关度系数值r=0.89,标准偏差σe=0.07。相关系数值越大,说明与主观可懂度评价越相近,评价越精确。对于辅音来说,与主观可懂度评价的相关系数值r=0.77,标准差σe=0.08。相对于PESQ来说,对于句子而言,该方法整体优于PESQ,对于辅音而言,该方法与PESQ持平,所以最终选择NCM方法。 句子和辅音的客观评价结果分别如表1、表2所示。 表1 句子NCM值 表2 辅音NCM值 NCM值越大,可懂度越高。由表1和表2可以看出,对高估先验信噪比进行修正,对不同放大区域进行分段限制对于信噪比较低,尤其是信噪比为负值的加噪语音影响较大,这也进一步验证了猜想。与传统的子空间方法相比,本文提出的算法能够在负信噪比时较大程度提高语音的可懂度,且与加噪未增强的噪音相比,可懂度也明显提高。 本文首先论述了现今很多算法都是利用最小均方误差的方法进行语音增强,忽略了不同语音畸变区域对可懂度的影响,继而阐述了不同畸变区域对可懂度的影响不同。在估计先验信噪比时,会存在高估和低估,所以首先对小于-10 dB区域内的增益矩阵高估进行修正。为了验证猜想,在频域上约束子空间的特征分解法的基础上,使用先验信噪比和增益矩阵对不同的语音畸变区域(大于0 dB和大于6.02 dB)分段进行了限制。经过Matlab实验仿真结果可知,本文提出的算法确实能够有效地减小先验信噪比高估,降低畸变对语音的影响,提高了语音的可懂度。 [1] Hu Y,Loizou P C.A comparative intelligibility study of single-microphone noise reduction algorithms[J].Journal of the Acoustical Society of America,2007,122(3):1777-1786. [2] Loizou P C,Kim G.Reasons why current speech-enhancement algorithms do not improve speech intelligibility and suggested solutions[J].IEEE Transactions on.Audio,Speech and Language Processing,2011,19(1):47-56. [3] 刘鹏,马建芬.具有较高可懂度的子空间语音增强算法[J].计算机工程与设计,2013,34(7):2619-2622. [4] Yang Y X,Ma J F.Speech Intelligibility Enhancement Using Distortion Control[J].Advanced Materials Research,2014,912-914:1391-1394. [5] 郭利华,马建芬.具有高可懂度的改进的维纳滤波的语音增强算法[J].计算机应用与软件,2014,31(11):155-157. [6] Sharma P,Abrol V,Sao A K.Supervised speech enhancement using compressed sensing[C]//Communications (NCC),2015 Twenty First National Conference on.IEEE,2015:1-5. [7] Kwon K,Shin J W,Sonowat S,et al.Speech enhancement combining statistical models and NMF with update of speech and noise bases[C]//Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on. IEEE,2014:7053-7057. [8] Xu Y,Du J,Dai L R,et al.A Regression Approach to Speech Enhancement Based on Deep Neural Networks[J].Audio,Speech and Language Processing,IEEE/ACM Transactions on,2015,23(1):7-19. [9] Djendi M,Scalart P.Reducing over- and under-estimation of the a priori SNR in speech enhancement techniques[J].Digital Signal Processing,2014,32:124-136. [10] 张亮,龚卫国.一种改进的维纳滤波语音增强算法[J].计算机工程与应用,2010,46(26):129-131. [11] Lu Y,Loizou P C.Speech enhancement by combining statistical estimators of speech and noise[C]//Proceedings of IEEE International Conference on Acoustics,Speech and Signal Processing,2010:4754-4757. [12] Chen F,Loizou P C.Impact of SNR and gain-function over- and under-estimation on speech intelligibility[J].Speech Communication,2012,54(2):272-281. [13] 武奕峰,贾海蓉,郭欣.用子空间提高有色噪声背景下的语音质量[J].太原理工大学学报,2015,46(2):192-195. [14] 陈国明,赵力,邹采荣.窄带噪声下的子空间语音增强算法[J].应用科学学报,2007,25(3):243-246. [15] Hu Y,Loizou P C.A generalized subspace approach for enhancing speech corrupted by colored noise[J].Speech and Audio Processing,IEEE Transactions on,2003,11(4):334-341. [16] Loizou P C,Ma J.Extending the articulation index to account for non-linear distortions introduced by noise-suppression algorithms[J].Journal of the Acoustical Society of America,2011,130(2):986-995. [17] Ma J,Hu Y,Loizou P C.Objective measures for predicting speech intelligibility in noisy conditions based on new band-importance functions[J].Journal of the Acoustical Society of America,2009,125(5):3387-3405. ASPEECHENHANCEMENTALGORITHMWITHHIGHINTELLIGIBILITYUNDERLOWSNRCONDITION MengXinMaJianfen*ZhangXueying (CollegeofComputerScienceandTechnology,TaiyuanUniversityofTechnology,Taiyuan030024,Shanxi,China) Researchshowsthatcomparedwithpurespeech,therewillbetwotypesofdistortioninenhancedspeech:theamplifierdistortionandtheattenuationdistortion,andtheamplifierdistortionhasabiggerinfluenceonthespeechintelligibility.Mostoftraditionalspeechenhancementalgorithmscannoteffectivelyimprovetheintelligibilityafterthespeechbeingenhanced,becausetheyonlyusetheminimummeansquareerrormethodtolimitthesetwokindsofdistortionsforsuppressingnoiseandimprovingthequalityofthespeech,butneglectthedifferentdistortionshavingdifferenteffectsonintelligibility.Thispaperproposesasubspace-basedspeechenhancementalgorithmwhichcanimprovetheintelligibility,itusespriorisignal-to-noiseratio(SNR)andgainmatrixtojudgethetypeofspeechdistortion.Atthesametime,itisnoticedthatwhenestimatingtheprioriSNR,thereistheestimationerror:overestimationandunderestimation.Theoverestimationwillproduceamplifierdistortion,andhasabiginfluenceontheintelligibility.WefirstcorrectthegainmatrixoftheoverestimatedprioriSNR(lessthan-10dB),andthenmakedifferentrestrictionsonthespeecheswithamplitudespectrumdistortiongreaterthan0dBand6.02dBseparately.Experimentalresultsshowthattheproposedalgorithmcaneffectivelyenhancetheintelligibilityofthespeech. SubspaceSpeechintelligibilitySpeechdistortionPrioriSNRGainmatrix 2015-06-23。国家自然科学基金项目(61371193)。孟欣,硕士生,主研领域:语音信号处理。马建芬,教授。张雪英,教授。 TP ADOI:10.3969/j.issn.1000-386x.2016.10.032
4 实验结果及分析
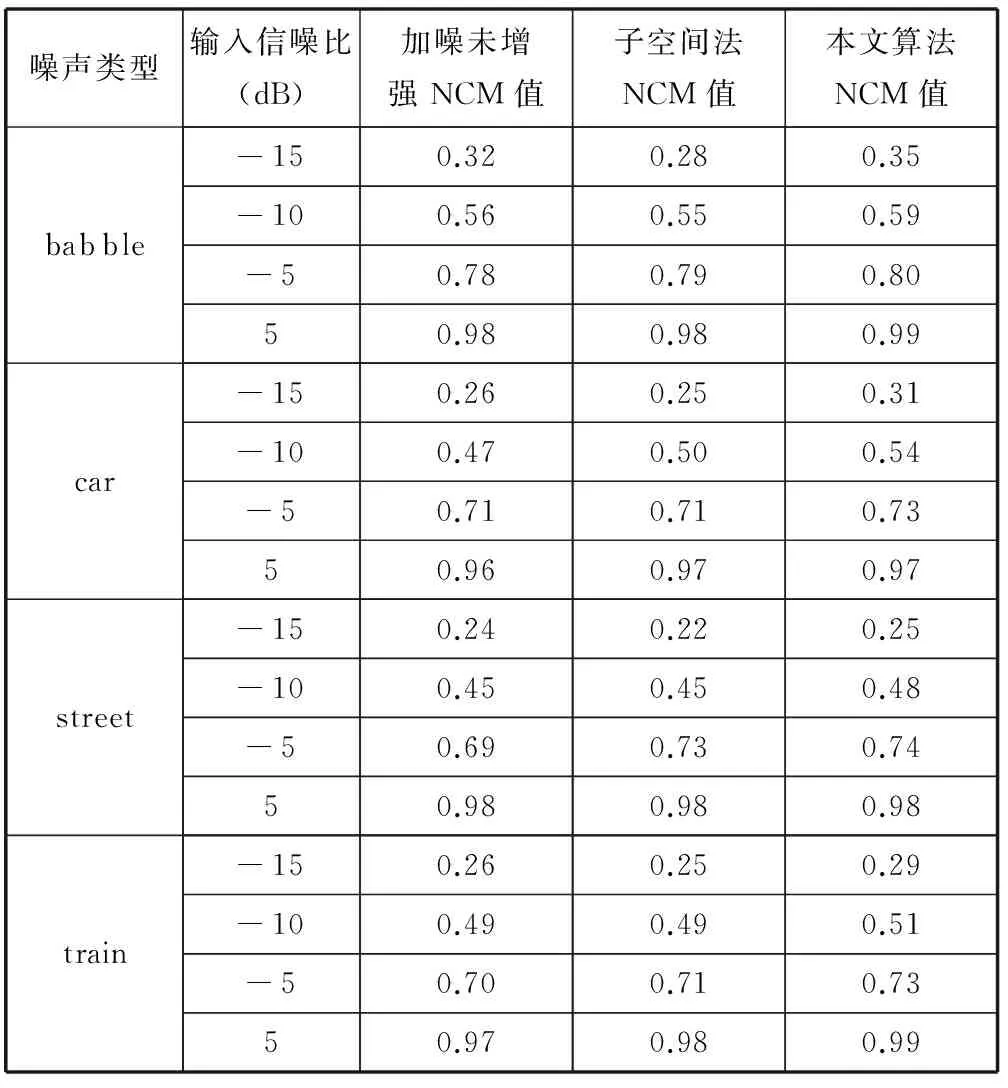
5 结 语
