稀疏贝叶斯混合专家模型及其在光谱数据标定中的应用
2016-11-08俞斌峰季海波
俞斌峰 季海波
稀疏贝叶斯混合专家模型及其在光谱数据标定中的应用
俞斌峰1季海波1
在光谱数据的多元校正中,光谱数据通常是在多种不同的环境条件下收集的.为了建模来源于不同环境中的高维光谱数据,本文提出了一种新的稀疏贝叶斯混合专家模型,并将其用来选择多元校正模型的稀疏特征.混合专家模型能够把训练数据划分到不同的子类,之后使用不同的预测模型来分别对划分后的数据进行预测,因此这种方法适合于建模来自于多种环境下的光谱数据.本文提出的稀疏的混合专家模型利用稀疏贝叶斯的方法来进行特征选择,不依赖于事先指定的参数;同时利用probit模型作为门函数以得到解析的后验分布,避免了在门函数分类模型中进行特征提取时需要的近似.本文提出的模型与其他几种常用的回归模型在人工数据集和几个公开的光谱数据集上进行了比较,比较结果显示本文提出的模型对多个来源的光谱数据进行浓度预测时精度比传统的回归方法有一定的提高.
多元校正,混合专家模型,特征提取,变分推断
引用格式俞斌峰,季海波.稀疏贝叶斯混合专家模型及其在光谱数据标定中的应用.自动化学报,2016,42(4):566−579
在很多机器学习的回归或者分类问题中,训练样本通常可以划分为很多子集,不同的子集需要用不同的模型和不同的特征来进行描述,这时为了构建输入输出之间的关系,需要建立很复杂的预测函数.分而治之的方法因为可以把一个复杂的问题分解成多个相对简单的子问题而成为了处理复杂机器学习问题的一种常用方法.决策树算法是最常用的一种分而治之方法.决策树模型的每个分支递归的选择一个特征将输入该节点的样本空间划分成不同区域,然后在叶子节点上用不同的节点值来对不同区域的样本进行预测.决策树模型的一个缺陷是每次划分只依据单一的特征,忽略了特征之间的联系.另外决策树模型也难以建模输入输出之间的局部的线性关系.当根据领域知识输入输出关系更适合用线性模型来描述时,强行用决策树模型建模的话需要大量样本构建复杂的树结构.
与决策树模型将每个输入样本都划分到不同的节点、每个训练样本只由一个叶子节点负责预测不同,混合专家模型将概率方法引入到样本空间分割和子预测模型建模中.混合专家模型通过门函数来计算样本属于不同子类的概率,并且对不同的子类估计一个称为专家模型的输入输出的概率模型.混合专家模型通过门函数和多个专家模型的组合来建模输入输出之间复杂的概率关系[1].
和决策树模型一样,混合专家模型也是一种将预测问题分而治之的方法.相比于决策树模型使用硬的判决条件对输入空间进行分割,使用概率模型的混合专家模型可以认为是一种软分割的方法[2].混合专家模型使用的门函数决定了每个样本由不同专家预测的概率,也相当于对于每个样本分配了一组将子模型组合时的权值,之后用计算得到的概率权值把不同的专家模型的预测结果组合起来[3].
混合专家模型中的门函数和专家模型的选取有较大的自由,通常使用简单的线性模型来构建专家模型以建模输入输出之间局部的线性关系[1,4−5].另外也常使用高斯过程来构建非线性的专家模型[6−7].混合专家通常使用多类分类的softmax函数作为门函数来计算每个样本由不同专家进行预测的概率[5,8].文献[4]使用了多层的门函数,构建一个类似于决策树的多层混合专家模型.
近年来,随着各种特征选择方法的发展,学者们将特征选择与混合专家模型进行了结合,从而将混合专家模型推广到了处理高维数据上.文献[9]将L1惩罚加入到高斯混合模型训练的EM算法中以诱导稀疏的高斯模型均值.文献[8,10]沿着将L1正则和EM算法结合的思路,提出利用L1正则方法来使得混合专家模型的门函数和专家模型都只使用部分稀疏特征.L1范数正则的稀疏化方法需要设置适当的正则系数,这些L1正则和EM结合的方法通常都使用交叉检验的算法来估计正则系数.为了减小交叉检验的计算量,文献[8,10]中所有的专家模型和门函数都使用统一的正则系数.然而在实际中不同的专家模型可能需要使用的特征和特征数目都不相同,这种统一的正则惩罚可能会降低模型的泛化性能.另外由于训练混合模型时使用的EM算法不能保证每次都收敛到全局的最优解,只能够得到局部的极大值点,收敛得到的最终结果受到迭代初始值的影响,因此交叉检验的性能差异并不能完全确定是否是由于使用了不同的正则化系数而导致的.上面的这些原因导致了使用L1范数正则对混合专家模型进行特征选择在实践中使用的困难.
稀疏贝叶斯方法是另外一种常用的特征选择的方法.稀疏贝叶斯方法不像L1范数正则一样可以归结到的一个凸优化问题而能够保证收敛到全局最优值,它是一种概率的方法并且只能保证收敛到局部极值点[11−12].稀疏贝叶斯方法的主要优点在于不需要预设一个正则参数,避免了繁杂的参数选择问题.对于混合专家模型而言,由于训练多个模型混合就无法保证收敛到全局的最优,并且模型本身也是从概率角度进行描述的,因此用稀释贝叶斯方法来进行模型特征选择更加自然并且计算也更加简便.文献[5]使用了稀疏贝叶斯方法来选择混合的高斯专家模型的特征,但是其门函数使用的softmax函数难以使用合适的先验分布,使得后验分布具有容易计算的解析形式,因此他们的方法只能选择专家模型特征而不能选择门函数的特征.本文将probit模型[13]引入到混合专家模型的门函数建模中,用全贝叶斯方法建立了一种稀疏的混合专家模型,这种模型能够自动地确定不同的专家模型和门函数使用的特征并且不依赖于人为的设置的参数,因此新提出的模型适用于分析高维的输入数据.文献[14]提出了一种贝叶斯混合专家模型方法.本文与其主要区别在于本文的模型更注重于高维数据的特征选择.为了进行特征选择,本文提出的模型使用了不同的先验分布和门函数.本文提出的这种全贝叶斯的混合专家模型的框架也很容易使用其他的先验分布来进行推广,以提取具有其他性质的专家模型或者门函数.
本文主要是为了解决不同条件下的光谱数据多元校正问题.在光谱数据分析中,很多时候整个光谱数据集中的样本是在不同的条件下搜集的.如果我们能够确定光谱数据的来源,就可以对不同的来源的高维光谱数据分别建立回归模型.但当数据来源不确定时候,如果单纯只是将不同来源的数据放在一起用统一的线性模型估计的话可能会产生较大的误差,特别是部分环境中的样本点很小的时候[15].在光谱分析中为了分析来自不同来源的数据以及将一种环境中建立好的模型运用到另外不同的环境中人们提出了很多特殊的光谱校正迁移的算法[16].为了避免线性模型在建模数据来源复杂时预测精度下降的问题,很多非线性方法如支持向量机等也都被引入到了光谱多元校正中[17−21].但是这样的模型忽视了在同一个环境中光谱数据和预测值通常是具有线性关系的.因此本文将混合专家模型引入到光谱数据分析之中,混合专家模型能够把搜集于不同环境中的光谱数据首先用门函数来进行分类,然后划分到不同的专家模型进行预测,更加符合光谱分析中非线性产生的根源.
近年来为了分析来自不同来源的但是相互之间具有内在联系的数据,多任务学习(Multi-task learning)的方法得到了人们广泛关注[22−29].多任务学习的方法能够提取多个相关的机器学习任务之间的内在联系.即使在单个学习任务的训练样本不足的时候,多任务学习的方法也可以利用任务之间的关联来对每个学习任务建立泛化性能较好的模型[22].多任务学习研究的是在给定多个学习任务后同时学习多个学习任务,对于每个数据样本都要有一个任务标签来判断是属于哪一个任务.而有时我们并不清楚搜集到的数据具体属于哪个任务,不能给这些数据一些明确的任务标签,本文主要研究的是在不能够给定数据来源标签的情况下同时对数据进行划分和对划分后的数据建模.
本文内容安排如下:在第1节回顾了混合专家模型的基本形式,并且提出了新的稀疏混合专家模型.第2节基于变分推断方法给出了稀疏混合专家模型的训练算法,以及对新样本的预测算法.第3节将我们提出的新的模型在一个人工数据集和3个真实的多种来源的光谱数据集中进行了实验,展示了新的方法的预测性能.最后第4节对全文进行了总结.
1 稀疏混合专家模型
在本节中我们首先简要回顾经典的混合专家模型(Mixture of experts,ME),之后介绍本文的主要贡献:结合稀疏贝叶斯方法以及probit模型对经典的混合专家模型进行扩展后的使用贝叶斯方法选择稀疏特征的新的稀疏混合专家模型(Sparse mixture of experts,SME).
1.1混合专家模型
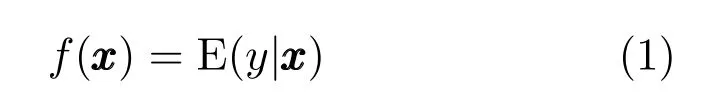
输入输出之间的条件概率有时比较复杂,难以用单个的概率模型来描述,混合专家模型采用多个局部的混合密度来估计输入输出之间的条件概率分布.
设有K个局部的概率模型,混合专家模型将条件分布P(y|x)分解为
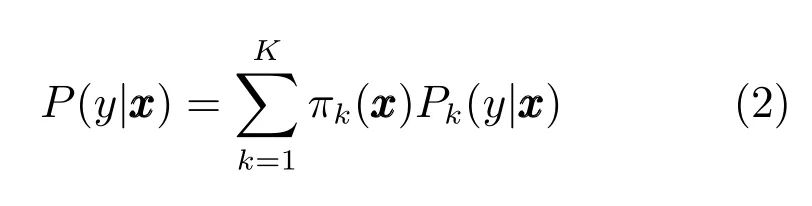
ME模型假设输入输出的条件概率是多个局部概率密度的加权混合,其中局部的概率密度函数称为ME模型中的专家,混合系数称为门函数.混合专家模型可以认为是一种概率上的决策树模型:其采用概率的门函数来计算各个输入更适合用哪个专家预测.决策树模型采用硬的分割规则来分割输入空间.相对于一般的概率混合模型,如高斯混合模型.混合专家模型假设混合模型的加权系数与输入有关,而概率混合模型中混合系数认为是常数.
ME常采用多元logit模型来定义门函数:
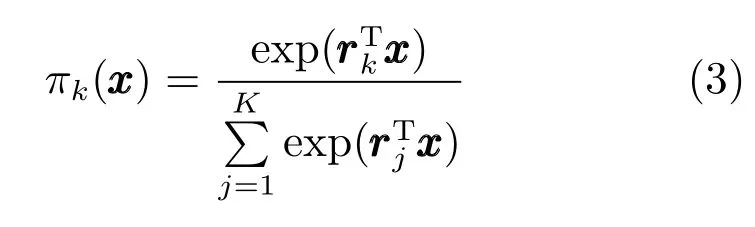

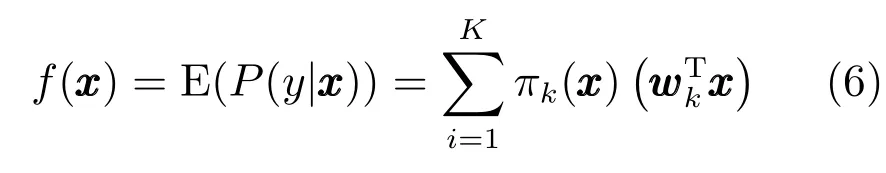
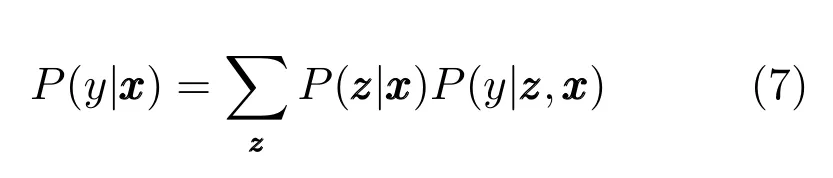
其中:
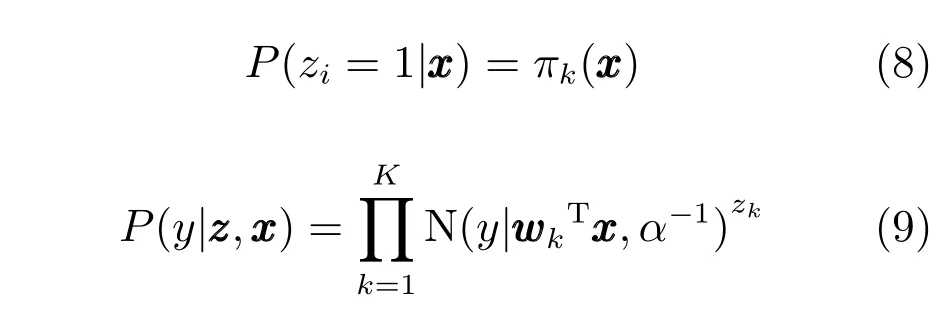
采用不同的门函数和专家模型,可以得到不同的混合专家模型.如对于分类问题,可采用逻辑回归模型作为专家模型来进行构建混合专家分类模型.文献[4]使用混合专家分类模型作为门函数得到了一种分层的混合专家模型.
1.2稀疏混合专家模型
当输入数据的维数大于训练样本数时,拟合线性的高斯模型以及线性的多元分类模型都会出现过拟合问题,因此传统的混合专家模型不适合处理高维的输入数据.而由于高维的输入特征中通常只有部分的特征与输出有关,对输入的特征进行提取是一种常用的分析高维数据的方法.本文将稀疏贝叶斯方法和probit模型与混合专家模型结合起来,提出一种能够自动提取输入特征的稀疏混合专家模型.
我们采用全贝叶斯的稀疏的线性回归模型作为专家模型:

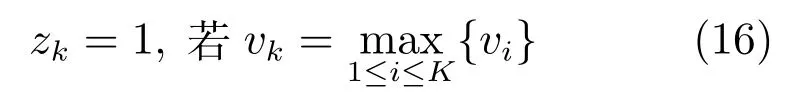
我们采用如下的贝叶斯probit门函数模型:
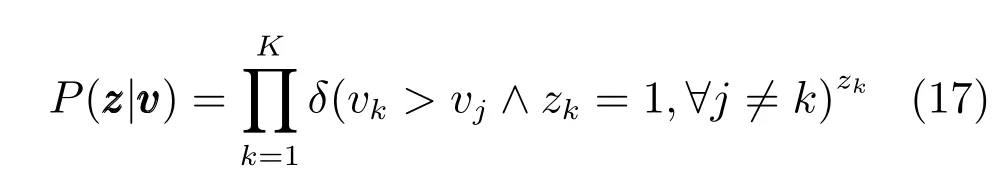
其中δ为0-1指示函数,记00=1,
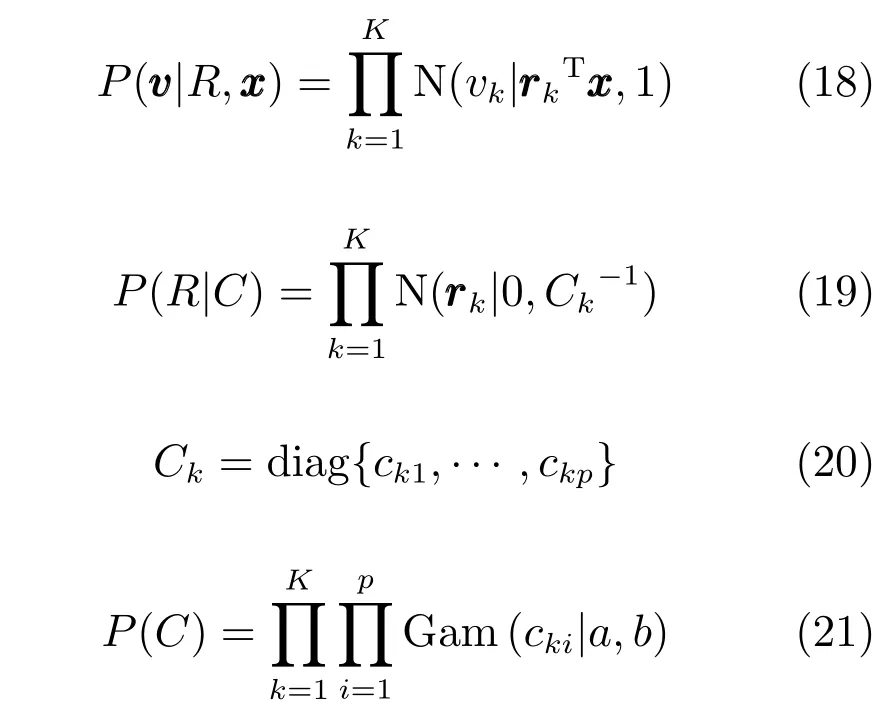
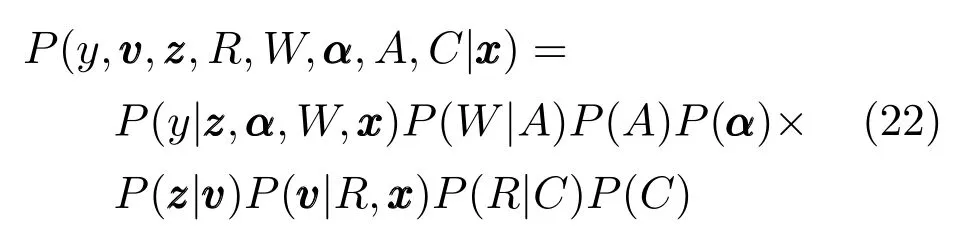
设有N个训练样本,可以用图1所示的概率图模型来表示上述的概率关系.
本文将文献[12]提出的稀疏probit分类方法引入到混合专家模型中对门函数进行建模.相比于文献[14]中贝叶斯的混合专家模型,本文提出的SME模型中每个专家的线性高斯模型的系数的先验分布具有不同的精度,这样SME模型的训练过程中能够根据这些精度的后验分布自动地选取特征.SME模型中使用probit模型作为门函数,可以直接处理多类的贝叶斯分类问题,而文献[14]需要对logistic回归中的sigmoid函数进行近似,并且需要构建一个复杂的树结构以使用两类分类方法来对多类进行分类.文献[8]采用了L1范数正则化的方法来获得稀疏的专家模型系数和门函数模型系数,但文献[8]中所有的专家模型和门函数都使用了同样的正则化参数,这样的限制可能会使得有些专家模型或者门函数模型使用了过多的特征而出现过拟合,而有些模型的正则化参数太大而出现欠拟合.如果对不同的专家使用不同的正则化系数,文献[8]中的方法将会有太多的正则参数需要事先确定,确定参数的计算量过大.文献[5]和本文一样使用了稀疏贝叶斯的线性模型作为专家模型.两者的混合专家模型的门函数使用的是多元logit模型,当把稀疏贝叶斯的思想用到多元logit模型时,需要在每步迭代中计算Kp×Kp的Hessian矩阵以及其逆矩阵,计算量过大.文献[5]的模型无法对门函数进行特征选择,当输入特征的维度很高时,可能不能得到合适的门函数.
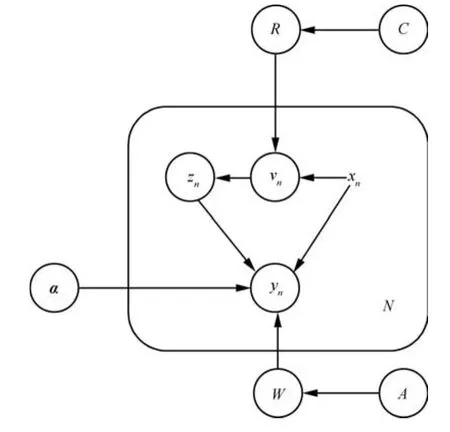
图1 SME的概率图模型Fig.1 The probabilistic graph of the SME model
2 变分推断以及预测
本节先通过变分推断(Variational inference)的方法推导出上面提出的SME模型的训练方法,之后给出当出现新样本时输出的预测方法.
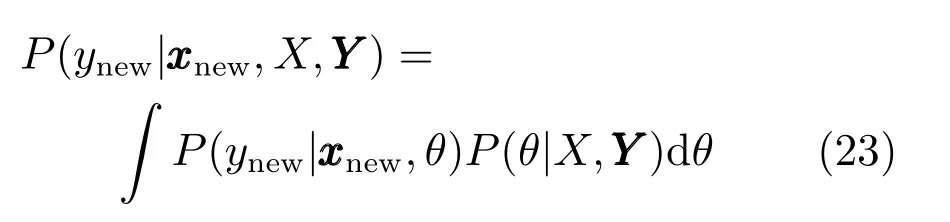
这里记:
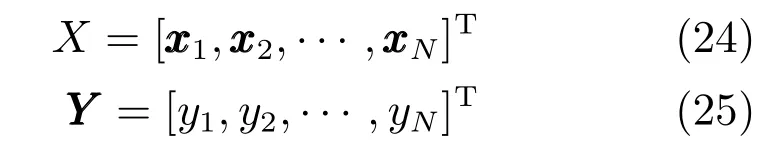
θ代表所有模型中未观测的隐藏变量,
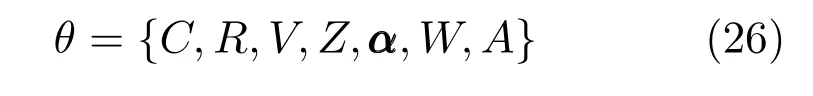
记:
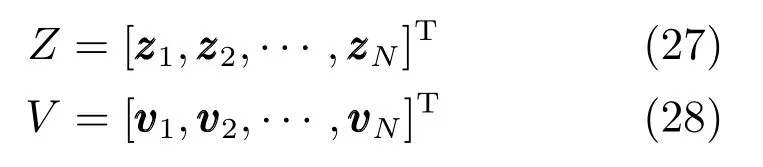
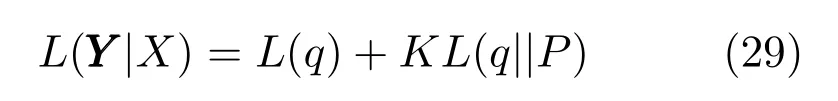
其中L(q)定义为
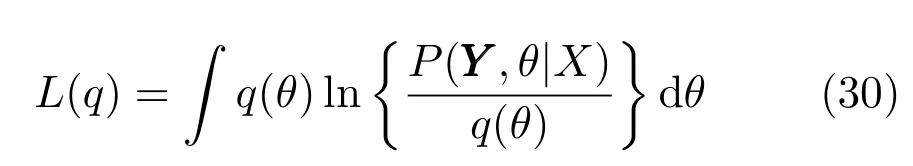
KL(q||P)定义为
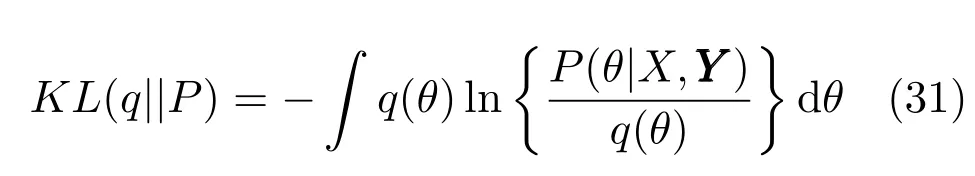
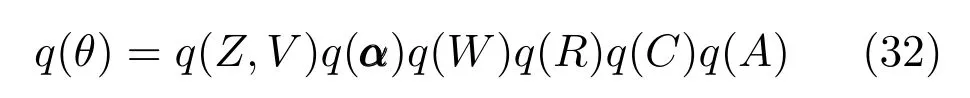
将式(32)代入到式(30),用变分法来极大化L(q),可以得到
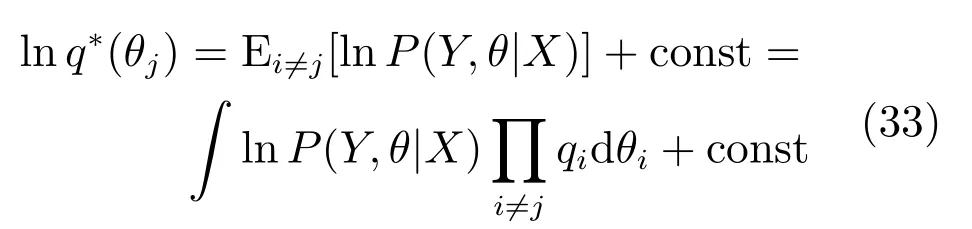
这里θi,θj代表式(32)中的因子项,如C,A等.根据式(33)可以得到一系列的关于每个因子分布的方程,式(32)中的每个因子与其他因子的期望有关,变分推断方法即是初始化每个因子,然后根据式(33)交替的计算每个因子分布并代替当前因子分布,一直循环迭代直到收敛.下面给出专家模型和门函数中每一个因子分布的具体计算方法.
2.1专家模型的变分推断
专家模型中包含了随机变量α ,W,A,根据式(22),q∗(W)满足:
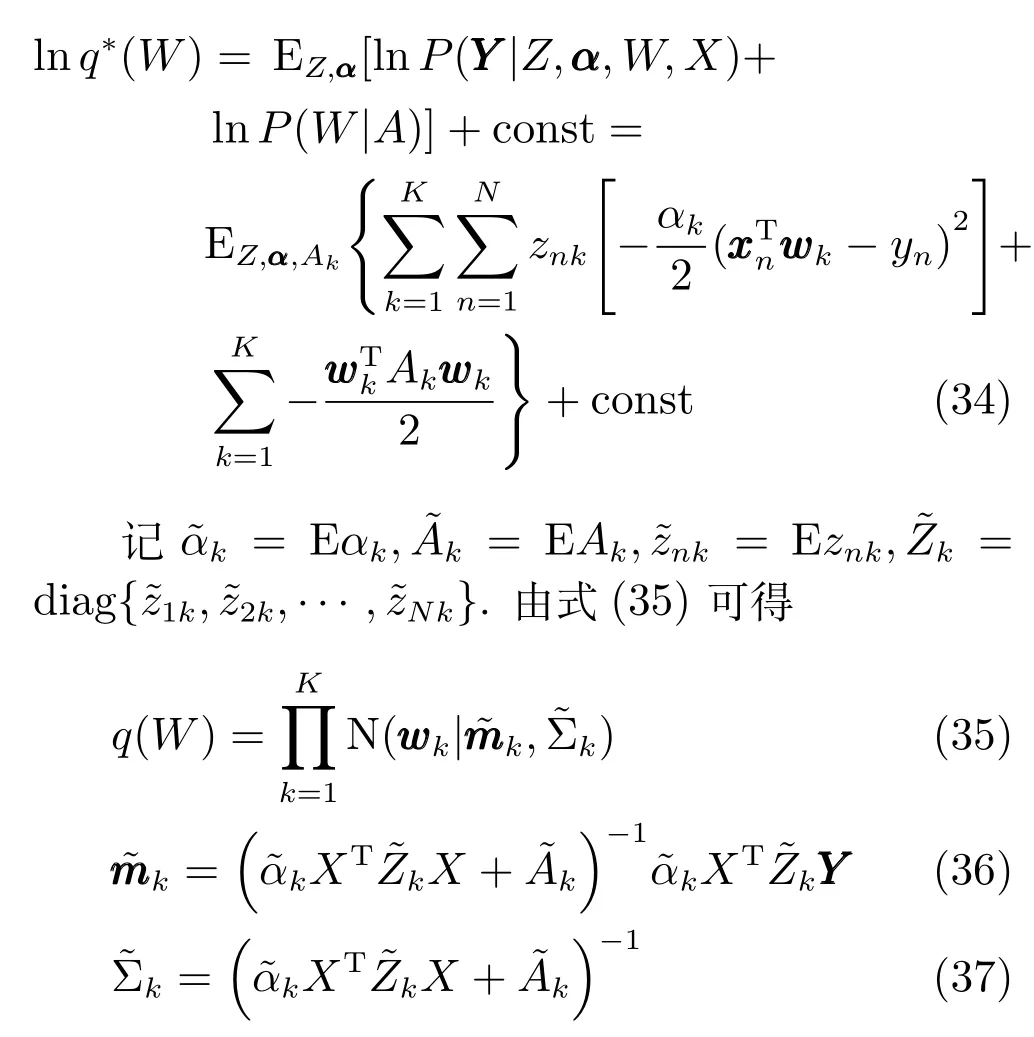
由于模型中采用了共轭先验,后验估计q(W)同样也为高斯分布,其期望与协方差矩阵分别为和与训练样本有关.q∗(α)满足:
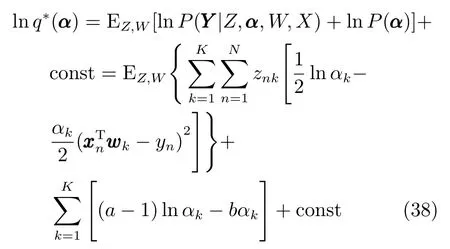
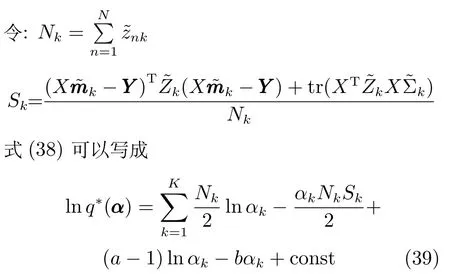
因此根据共轭先验,q∗(α)同样也为Gamma分布:
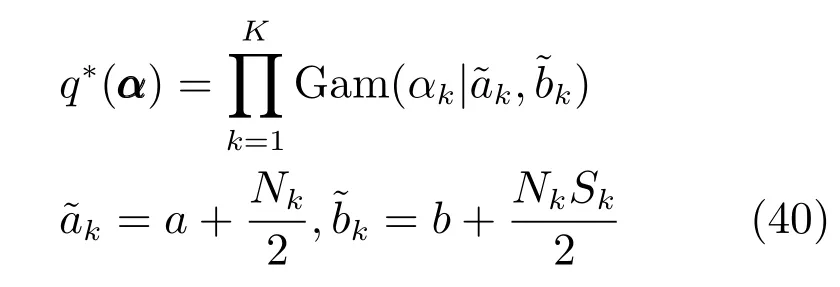
根据Gamma分布的性质有:
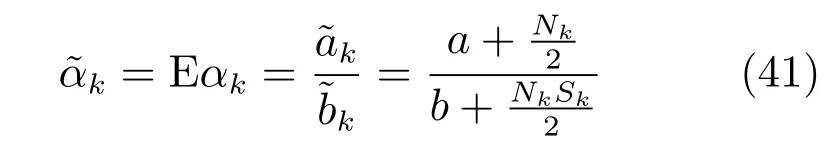
稀疏混合专家模型通过参数A进行特征选择,由式(22)和式(33)可以得到:
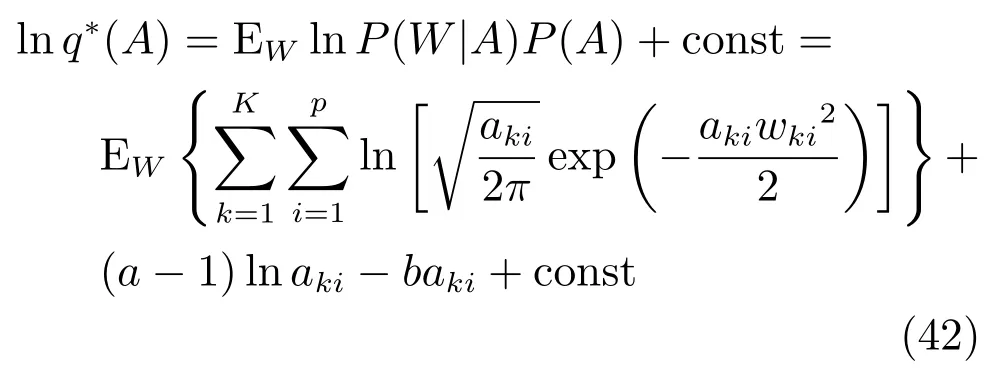
可以看出q∗(aki)同样为Gamma分布,
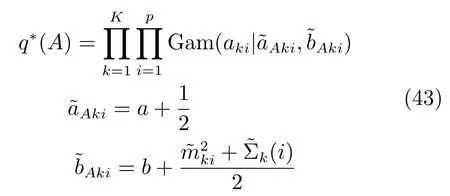
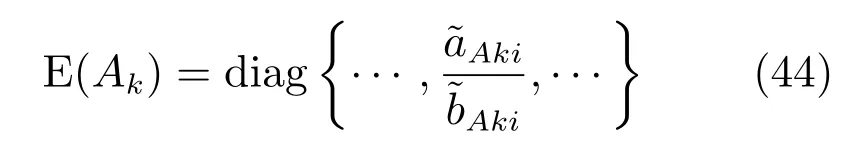
2.2门函数的变分推断
在概率图模型中,随机变量V,Z,R,C属于门函数模型,其中q(R),q(C)的推断和上面的专家模型中q(W),q(A)的推断类似:
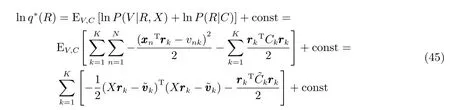
其中
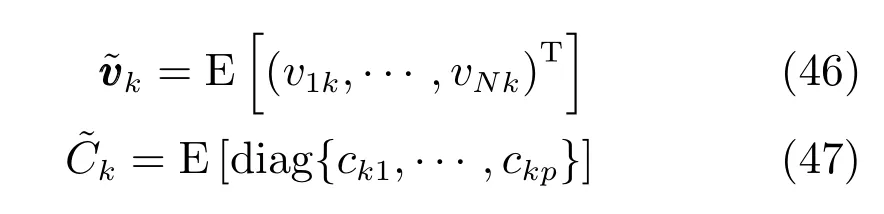
从式(45)中可以看出R的后验估计同样为高斯分布:
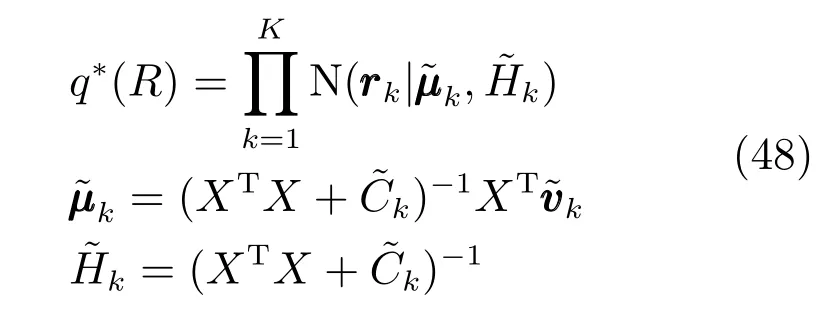
q∗(R)的均值和协方差矩阵分别为和满足:
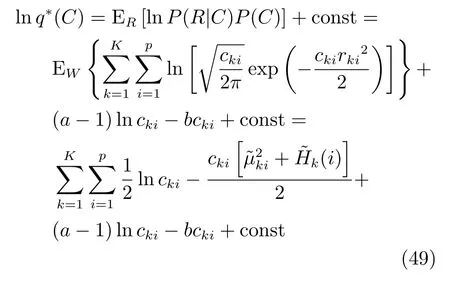
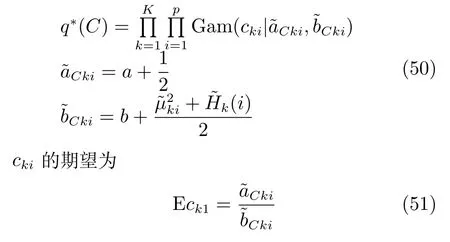
我们采用了稀疏贝叶斯的方法设专家模型和门函数中关于每个特征的拟合系数的先验分布有着不同的精度,在模型推断的时候,大部分精度的后验分布均值即Eak1和Eck1会变得很大,因此可以剔除很多冗余的特征,达到特征提取的目的[11].
q(Z,V)的估计相对复杂:
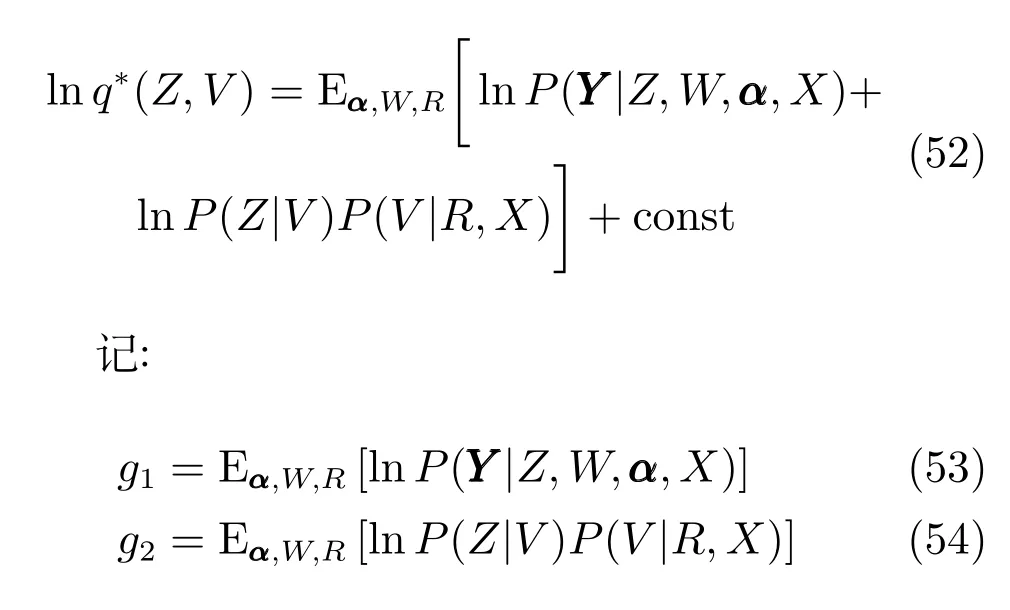
代入上面的分布函数可以计算得到:
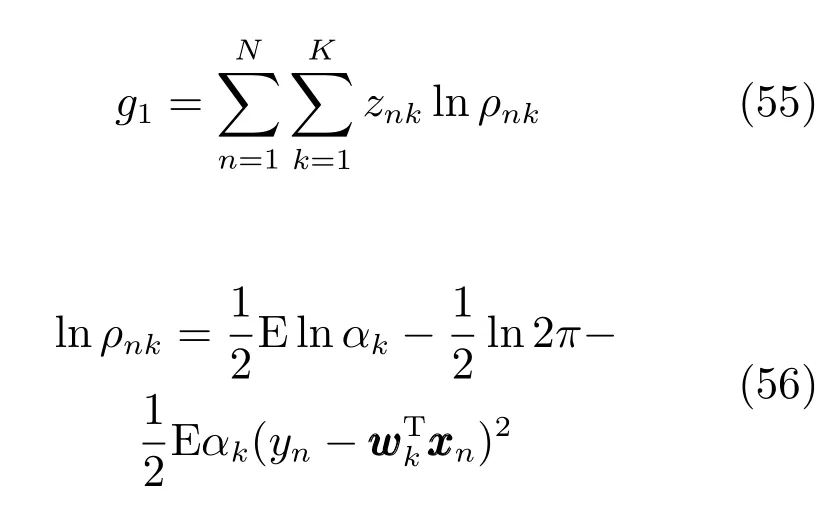
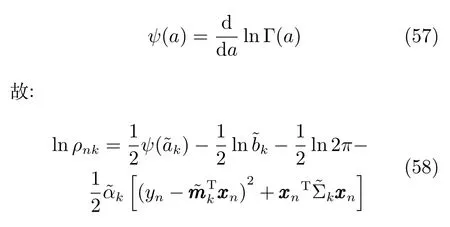
根据前面的模型定义:
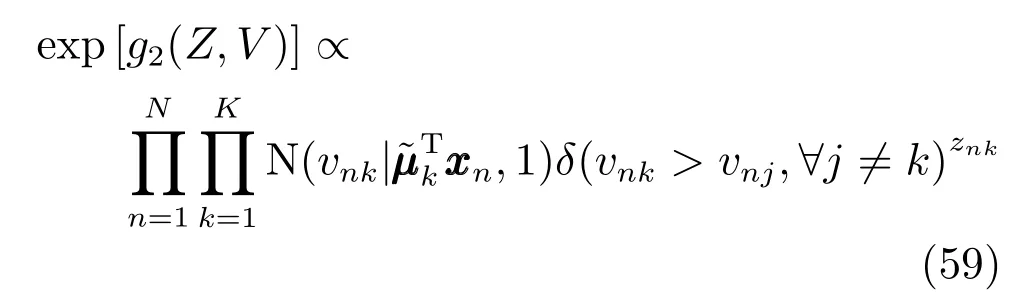
结合g1,g2可以得到:
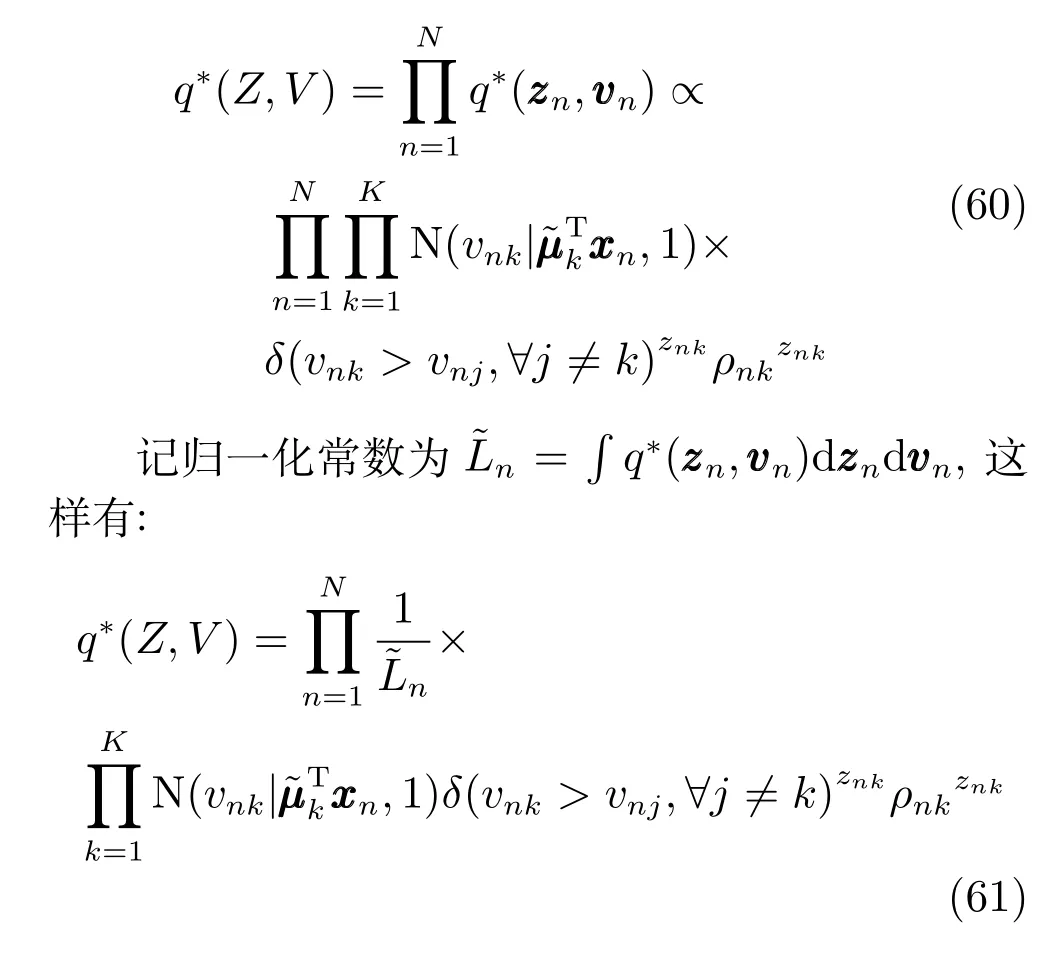

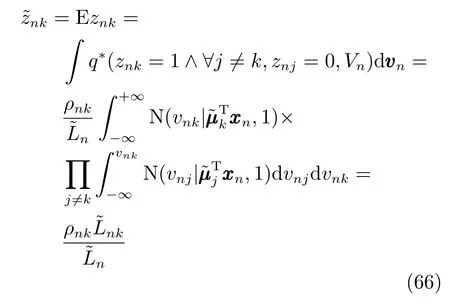
vn的后验分布估计的边缘分布为

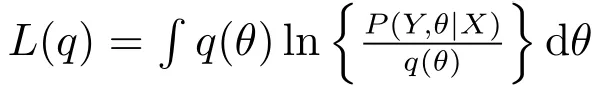
似然函数值下界可以写成
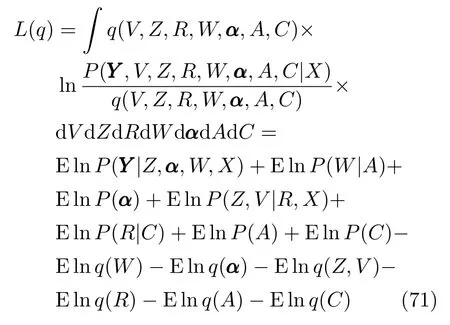
代入前面设定的模型的具体分布以及估计出的后验分布就可以得到极大化的似然函数值的下界.通过计算采用不同专家数时的不同的似然函数值的下界可以选择最优的专家个数.采用probit模型作为门函数不需要在每步对门函数模型的后验概率进行近似,而是采用多个独立分布的积利用变分推断来近似整个后验分布.在上面的变分推断中每次关于门函数的迭代中需要计算k个P×P的矩阵k及其逆,相比于用logit模型计算1个KP×KP的Hessian矩阵及其逆的计算量要小一点,前者的计算量为O(KP3),后者为O(K3P3).但是采用probit模型每步迭代时需要计算O(K2N)个一维积分,当专家数过多时积分的计算量会变得很大.
2.3变分预测分布
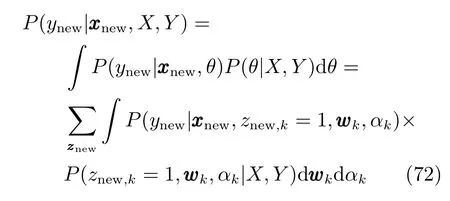
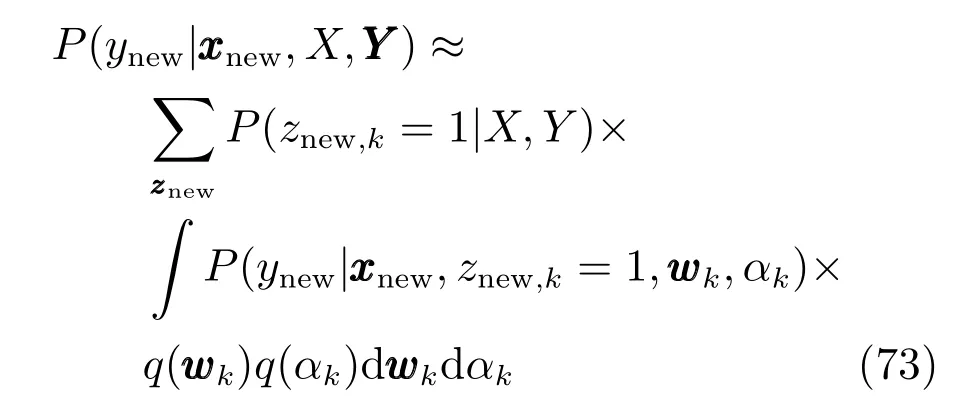
其中:
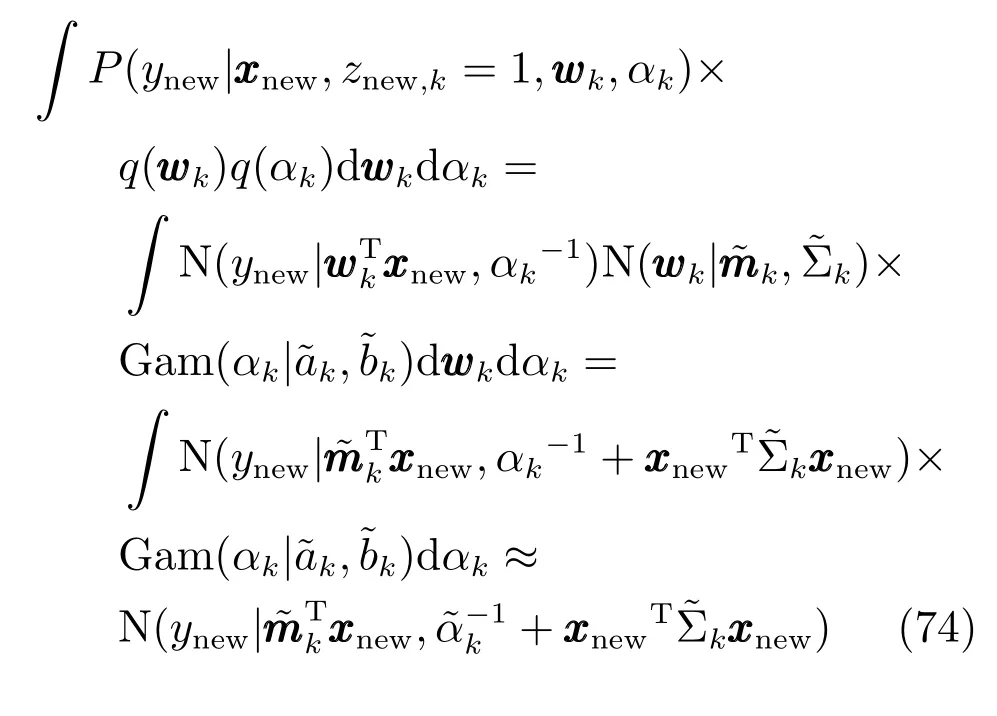
上式的第3行中的积分没有解析解.由于后验分布一般比较尖锐,可以直接用αk的均值近似在整个空间中对后验分布的积分.
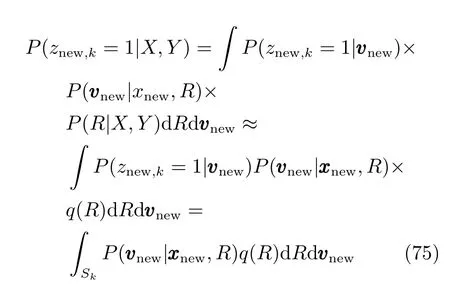
其中Sk={(v1,v2,···,vk)∈RK|vk>vj,∀j/=k},由于:
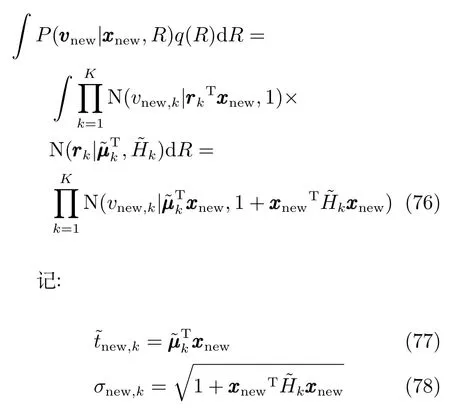
式(75)等于:
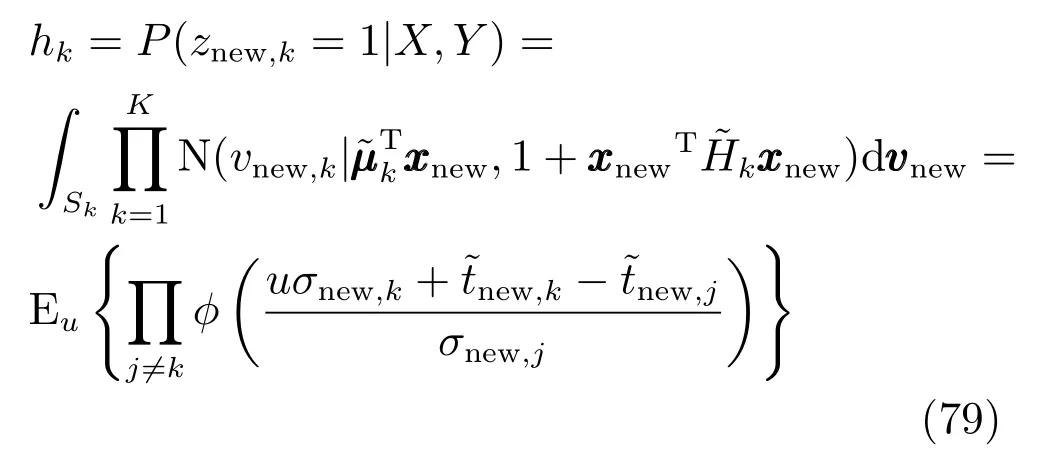
u为服从标准正态分布的随机变量.可以用下面的高斯混合分布来估计新样本输出ynew的分布:
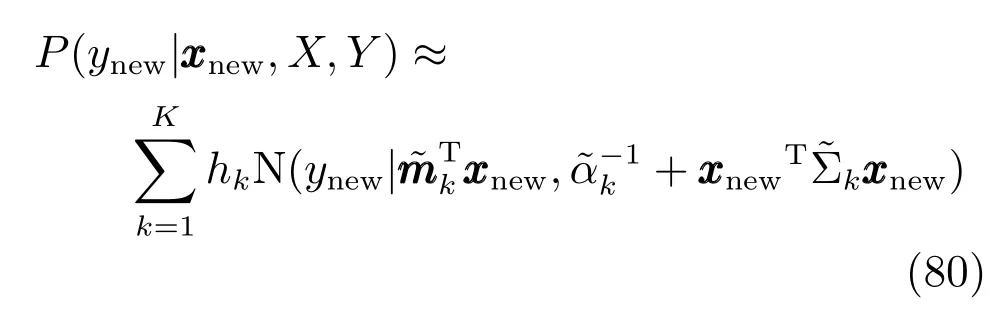
输出ynew的期望为
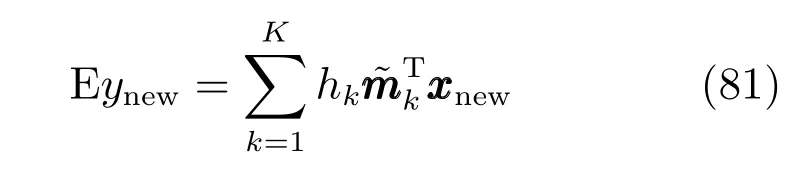
可以将上式作为混合专家模型对输出的预测公式.
3 实验
本节中我们首先采用人工生成的实验数据来检测新提出的SME模型的函数拟合和特征选择能力,之后将提出的SME模型运用到了三个真实的光谱数据集中来检验新提出的方法在光谱数据的定量分析中的表现.SME模型将与经典的混合专家模型,以及几种常用的回归方法包括偏最小二乘(Partial least squares,PLS)、支持向量机回归(Support vector regression,SVR)、LASSO(Least absolute shrinkage and selection operator)和岭回归(Ridge regression)进行了比较.其中SVR中采用径向基函数(Radial basis function,RBF)作为核函数.在真实光谱数据集中,我们的算法还和使用Bagging方法集成的岭回归方法进行了比较.SME模型中只需要指定一个超参数,即共轭Gamma先验分布的a,b.与PLS、SVR以及LAR中的参数不同,我们通常希望贝叶斯模型中超参数对模型训练的结果的影响尽量小,因此可以直接指定为一个很小的值a=10−3,b=10−5.使用这样很小的超参数,可以减少SME模型中先验信息对后验概率分布的影响.其他模型的参数由5层交叉检验决定.Bagging集成学习方法采用了100次重新抽样.对于我们提出的这种稀疏混合专家模型,和文献[14]一样,我们使用了确定性退火(Deterministic annealing)的策略来减小迭代初值对最终得到的模型的影响,确定性退火策略的具体实现步骤参照文献[31−32].
3.1仿真数据
我们生成300个60维的随机输入.随机输入的生成方式如下:首先生成300个均值为0、协方差矩阵为UDUT的60维多元高斯分布随机数,其中U为60维的随机单位正交矩阵,D为对角矩阵,其前五个对角元为1,剩下的为0.01.之后将这些多元高斯分布随机数的前2维加上平移项,对前100个数据的前两维加上平移项(1,1),中间100个数据加上平移项(1,−1),最后100个数据加上平移项(−1,−1).这样这些输入数据可以根据前两维分成3类.接下来为了生成对应的输出,我们把这些数据的第3到4维按照之前分成的三堆分别乘上3个随机的系数向量并且加上方差为1的零均值高斯噪声以生成一维输出Y,其中随机系数向量服从均值为0、标准差为10的正态分布.通过上面的步骤我们生成了三堆可用通过前两维划分开的,同时输出只与输入的第3、4维有关的数据集.
我们根据生成的仿真数据训练多个不同专家数目的SME模型.为了确定最优的专家个数,分别计算专家数为2~6时的L(q),结果如图2所示.从图2中可以看出当专家数超过3时,进一步增加专家数模型L(q)反而降低,因此SME模型适合使用3个专家.图3和图4展示了SME模型中专家模型和门函数的代表拟合系数精度的随机变量A、C的均值.根据稀疏贝叶斯方法,矩阵A、C中对应特征的精度值越大,特征的对应系数就越集中到0.因此大精度值对应的特征就可以删去,从图3和图4中可以看出SME模型成功的找出了与专家模型相关的第3、4维特征,以及与门函数相关的第1、2维特征.
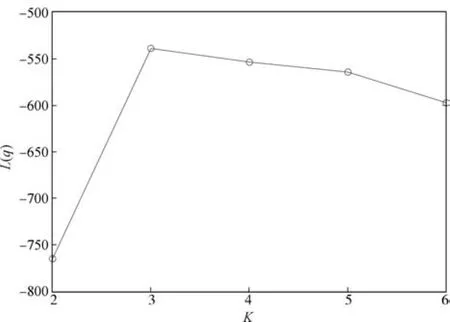
图2 不同专家数时的似然函数下界Fig.2 Plot of the lower bound L(q)versus the number of experts
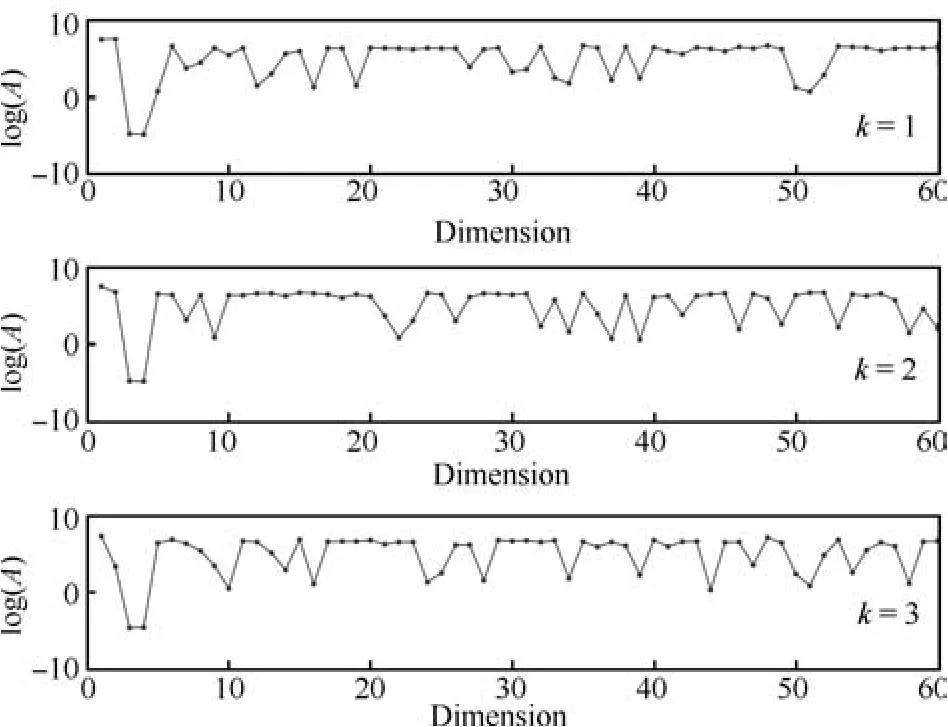
图3 专家模型在不同维度上的精度矩阵A的后验均值Fig.3 The means of the coefficients of expert models
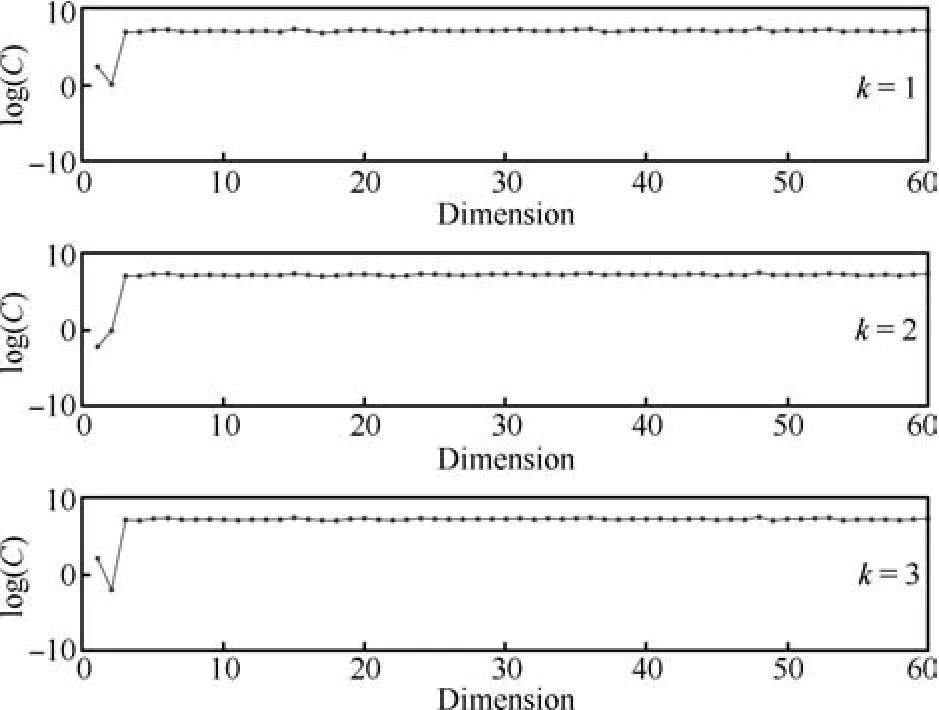
图4 门函数在不同维度上的精度矩阵C的后验均值Fig.4 The means of the coefficients of gate function
最后来检验生成的数据对输出预测效果,这里采用均方误差值(Root mean square error,RMSE)来作为各种方法的评价标准,设有n个测试样本RMSE值的定义如下:
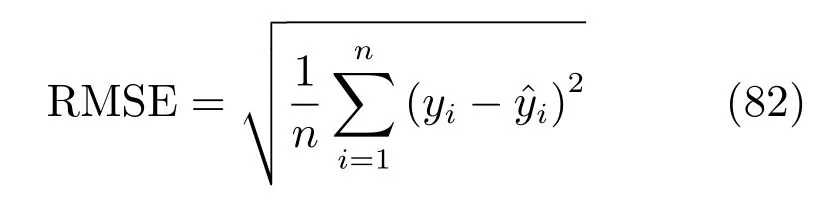
其中yi是真实的输出值,而i是预测值,我们用5层交叉检验的方法来计算预测结果,每次选取300个样本中的20% 的样本作为测试样本,剩下的80%样本作为训练样本.表1给出了采用PLS、SVR、LAR、经典的混合专家模型(ME)以及我们提出的SME方法的预测误差.对于这种有大量多余噪声维数同时可以用少量几个线性模型描述的数据集,SME方法取得了最好的预想结果,预测误差最接近贝叶斯误差1.0.而线性的PLS、LASSO、Ridge方法都不能很好地预测这类数据.由于具有大量的噪声维度,非线性的SVR方法的预测效果也很差.表1显示了经典的混合专家模型无法处理高维数据,因此在之后对光谱数据的实验中我们只考虑使用SME模型,不再进行和经典ME模型的比较.
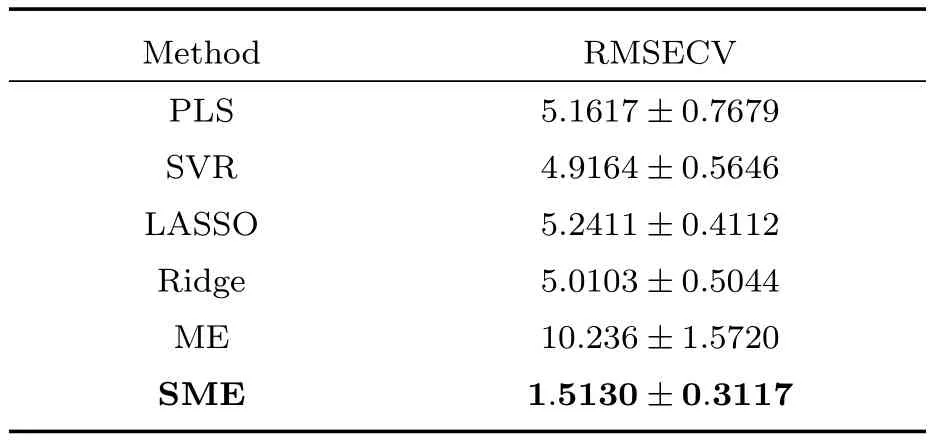
表1 在人工数据集上的预测结果Table 1 The prediction results in the artificial data set
3.2光谱数据
我们使用三个真实的光谱数据集来展示我们的算法在光谱分析中的应用效果,这三个数据集都是使用红外光谱来对物质含量或者浓度来进行预测.第1个数据集是玉米光谱数据集,数据集下载地址为:http://software.eigenvector.com/Data/Corn/ index.html,这个数据集包括了240条由三个不同的光谱仪测量的玉米样本的红外光谱以及其对应的蛋白质含量、脂肪含量、水分含量以及淀粉含量,我们只进行对水分的预测.玉米光谱的波长范围为1100nm~2498nm,每隔2nm测量光谱在该波长上的吸收度,这样玉米数据集的输入样本为240个700维的向量.而进行预测的输出的水分浓度的范围为9.38%~10.99%.第2个数据集是来自于IDRC Shootout 2002的药品数据集,这个数据集包含了由两个红外仪器测654个样本得到的1308条光谱以及对应药品成分含量,这个数据集的输入为从600nm~1898nm每隔2nm进行记录的1308个650维的向量,预测输出为在152nm~239mg范围内的药品有效成分的含量.第3个数据集是来自于文献[15]的温度数据集,包含了19个水,乙醇等混合物样本在30◦C~70◦C时测得的95条光谱数据,我们研究对乙醇的预测.温度数据集的输入为850nm~1049nm间每隔1nm测量的95个200维向量,预测输出为浓度范围为0%~100%的乙醇浓度.我们首先使用玉米数据集的所有240个样本训练了一个使用3个专家的SME模型.图5显示了这个SME模型的专家模型的回归系数的均值,即式(35)中的W的后验估计q(W)的均值k,k=1,2,3.从图5中可以看出每个专家模型都只使用了部分的波长,这显示了SME模型可以实现特征选择的目标.
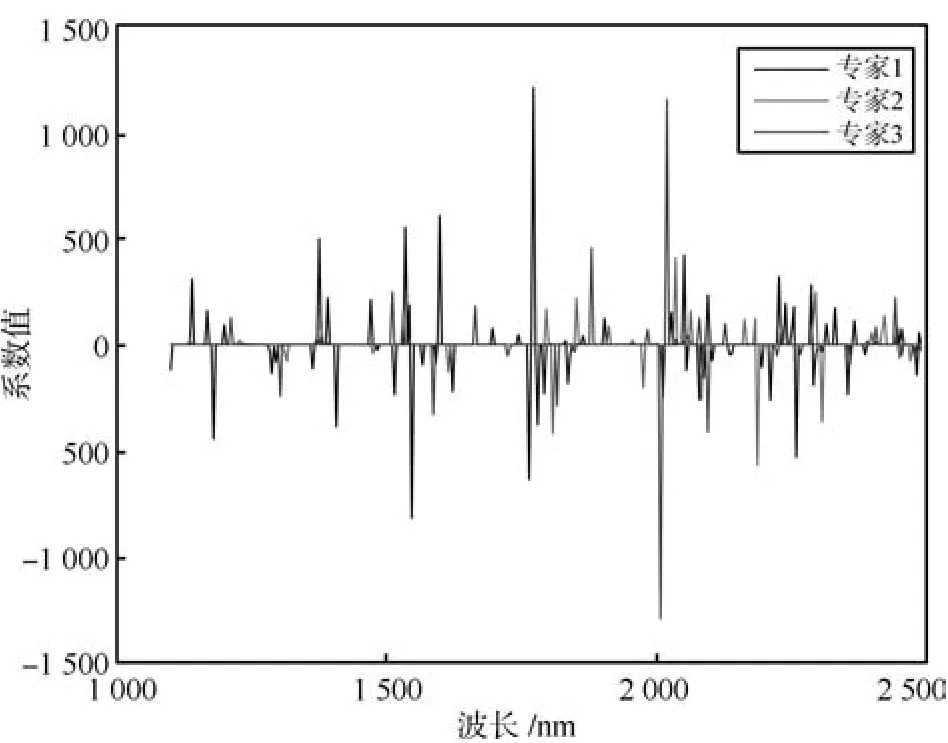
图5 根据玉米数据集的全部样本训练的三个专家的SME模型的专家模型回归系数的均值Fig.5 The means of the coefficients of the three expert models of SME trained with the corn data set
由于贝叶斯方法不需要进行参数选择,对于新提出的SME模型,我们只需要将数据分成训练集和测试集,用训练集上数据来训练SME模型,然后用测试集上的数据来检验预测效果.和PLS、SVR等模型不同,SME模型不需要一个独立的验证集来选择模型参数.为了充分利用所有的训练样本,我们直接使用交叉检验误差来评估SME模型在真实光谱数据集上的预测效果.对于其他需要选择参数的建模方法,我们给出了使得交叉检验误差最小的模型参数的RMSECV(Root mean square error of cross validation)值.对于玉米数据集,我们将240个样本用5层交叉检验的方法来划分训练集和验证集.每次选择192个样本作为训练集,选择剩下的48个样本作为验证集.对于药品数据集,我们和文献[33]一样首先去掉了部分异常样本,之后对剩下的1208个样本同样进行5层交叉检验来选择部分模型的参数和评价不同模型预测结果.最后对温度数据集的不同温度下的95个样本计算交叉检验的均方误差.实验的三个光谱数据集包含了每条光谱的测量仪器或者测量环境信息,这样我们也可以根据测量仪器或者测量环境的不同,将浓度预测问题划分成几个子问题,然后用多任务学习的方法来分别对不同仪器或者不同环境的光谱数据建立预测模型.我们实验了多任务学习中的L2,1范数正则的方法以同时对子问题建模和提取模型间的共有稀疏特征[27,34].三个数据集中不同建模方法的预测误差如表2~4所示.
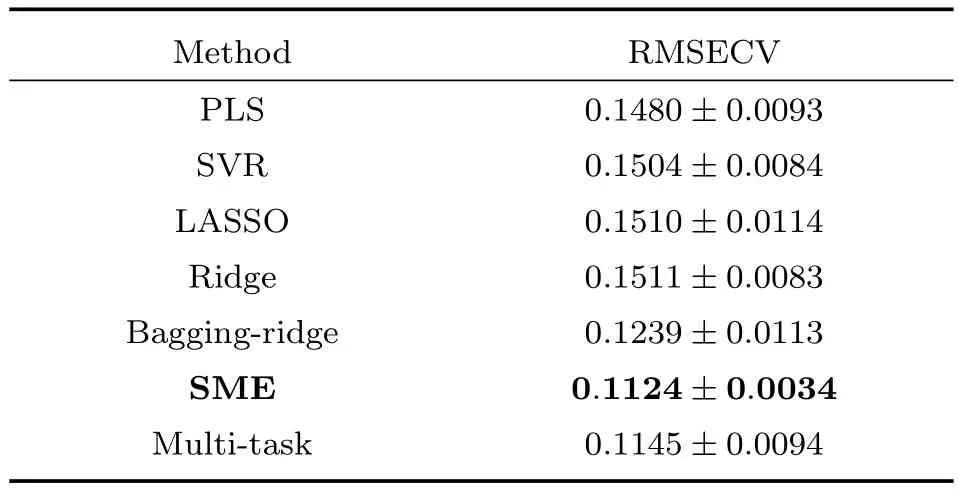
表2 玉米光谱数据集的预测结果Table 2 The prediction results in corn data set
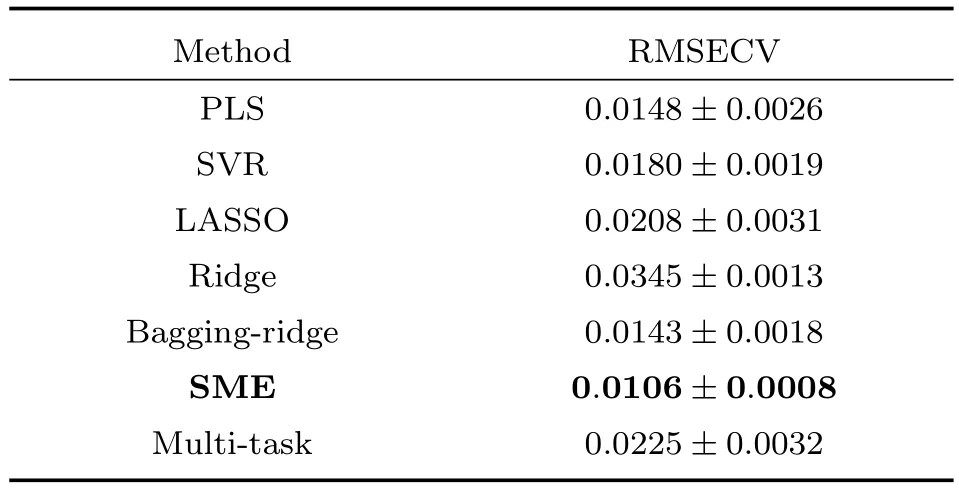
表3 温度数据集的预测结果Table 3 The prediction results in temperature data set
从表2~4可以看出在三个数据集中,SME方法都取得了最好的预测结果,这说明对于光谱数据采用混合专家模型方法将几个线性模型组合,能够得到比单一线性模型更好的结果.在不知道光谱来源的情况下,SME方法的预测结果甚至还优于知道光谱测量仪器或者测量环境时的共同稀疏特征提取的多任务学习方法(Multi-task).与多任务学习方法不同,SME方法可以在不明确光谱数据来源的情况下根据输入输出数据自动地对输入样本进行分类,之后再分别建立模型.在对光谱数据建模的问题上比多任务学习方法更加灵活:因为有时可能没有记录光谱的来源.与非线性的方法相比,SME的预测结果在三个数据集上也优于采用高斯核函数建模的SVR方法.实验结果说明当不知道光谱数据的来源时,SME方法可以自动地构建适合不同环境中的光谱数据的预测模型,同时判断模型的适用范围,相比于单一的模型能够取得更好的预测结果.
集成学习的方法将多个线性模型进行集成后最终得到的还是线性模型.和集成学习方法(如Boosting、Bagging方法)不同,SME方法得到的模型可以用多个分段的线性模型来建模更加复杂的非线性关系,也更适合建模不同环境中搜集到的光谱数据.由于基于决策树的回归方法,如随机森林(Random forest,RF)、GDBT(Gradient boosting decision tree)等,无法建模线性关系,而理论上光谱数据和预测浓度在很大的一个范围内都满足适当的线性关系,我们没有实验基于树模型的集成学习方法.我们将SME方法和采用了Bagging进行集成的岭回归方法进行了比较,从实验结果中可以看出采用Bagging方法进行集成后的岭回归模型的预测误差比原有的岭回归模型的预测误差在玉米和温度数据集上有很大的降低,但仍然高于SME方法.这是因为SME用多个分段线性函数构建预测模型,更符合光谱预测数据中的非线性产生的根源,也就能够取得更好的预测结果.尽管我们在训练模型时采用了确定性退火的策略,但当专家个数较多时,混合模型的优化结果将受到初值影响,因此实验中采用了较小的专家个数.为了减小初值影响,同时避免计算过程中产生奇异点,需要研究如何在混合模型训练时同时对专家进行合并与重新分割.另一方面,SME模型的计算量随着专家个数的增加而会变得很大,当专家个数较多时,每个专家模型的训练样本可能会出现不足,这些都可能会限制SME模型建立更加复杂的非线性模型和在其他高维的数据分析中的应用.将混合专家模型和多任务学习方法进行结合可能是解决专家个数较多时训练样本不足的一种途径.最后将这种SME方法的学习框架扩展到提取其他的专家模型以及门函数的结构也是我们接下来需要进一步研究的目标.
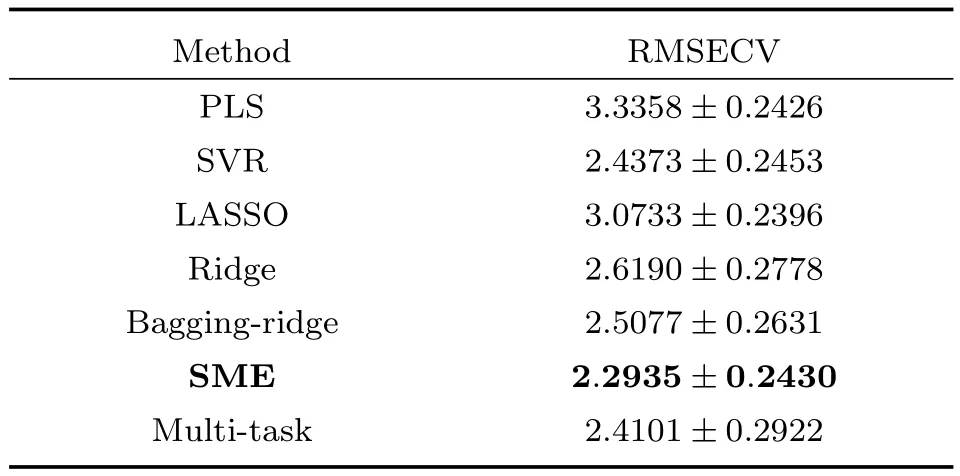
表4 药片光谱数据集的预测结果Table 4 The prediction results in pharmaceutical data set
4 结论
本文利用稀疏贝叶斯方法和probit模型分类方法提出一种新的稀疏的混合专家模型.这种模型利用了稀疏贝叶斯方法的自动相关判决技术来选择混合专家模型的门函数和专家模型的特征,并且利用probit模型构建门函数得到了一个全贝叶斯的混合专家模型.相对于现有混合专家模型中的特征选择方法,本文提出的方法不需要使用交叉检验来调整模型参数,避免了使用EM算法收敛到局部极值点时对交叉检验结果的影响.之后我们将提出的新的模型运用到了多来源的光谱数据的多元校正的建模之中,本文提出的模型可以为这种多个来源的光谱数据分别建立合适的线性模型,并判断各个模型所适用的光谱数据.在几个真实的光谱数据集上的实验结果表明本文提出的模型相对于光谱多元校正常用的支持向量机和偏最小二乘方法在预测精度上有一定的提高.
References
1 Jacobs R A,Jordan M I,Nowlan S J,Hinton G E.Adaptive mixtures of local experts.Neural Computation,1991,3(1): 79−87
2 Bishop C M.Pattern Recognition and Machine Learning. New York:Springer,2006.
3 Yuksel S E,Wilson J N,Gader P D.Twenty years of mixture of experts.IEEE Transactions on Neural Networks and Learning Systems,2012,23(8):1177−1193
4 Jordan M I,Jacobs R A.Hierarchical mixtures of experts and the EM algorithm.Neural Computation,1994,6(2): 181−214
5 Bo L F,Sminchisescu C,Kanaujia A,Metaxas D.Fast algorithms for large scale conditional 3D prediction.In:Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition.Anchorage,AK:IEEE,2008.1−8
6 Rasmussen C E,Ghahramani Z.Infinite mixtures of Gaussian process experts.In:Proceedings of the 2002 Advances in Neural Information Processing Systems.Cambridge MA: MIT Press,2002.881−888
7 Meeds E,Osindero S.An alternative infinite mixture of Gaussian process experts.In:Proceedings of the 2006 Advances in Neural Information Processing Systems.Cambridge MA:MIT Press,2006.883−890
8 PeraltaB,SotoA.Embeddedlocalfeatureselection within mixture of experts.Information Sciences,2014,269: 176−187
9 Pan W,Shen X T.Penalized model-based clustering with application to variable selection.The Journal of Machine Learning Research,2007,8:1145−1164
10 Khalili A.New estimation and feature selection methods in mixture-of-experts models.Canadian Journal of Statistics,2010,38(4):519−539
11 Tipping M E.Sparse Bayesian learning and the relevance vector machine.The Journal of Machine Learning Research,2001,1:211−244
12 Ding Y F,Harrison R F.A sparse multinomial probit model for classification.Pattern Analysis and Applications,2011,14(1):47−55
13 Xu Dan-Lei,Du Lan,Liu Hong-Wei,Hong Ling,Li Yan-Bing.Joint feature selection and classification design based on variational relevance vector machine.Acta Automatica Sinica,2011,37(8):932−943(徐丹蕾,杜兰,刘宏伟,洪灵,李彦兵.一种基于变分相关向量机的特征选择和分类结合方法.自动化学报,2011,37(8):932−943)
14 Bishop C M,Svensen M.Bayesian hierarchical mixtures of experts.In:Proceedings of the 19th Conference on Uncertainty in Artificial Intelligence.Acapulco,Mexico:Morgan Kaufmann Publishers Inc.,2003.57−64
15 W¨ulfert F,Kok W T,Smilde A K.Influence of temperature on vibrational spectra and consequences for the predictive ability of multivariate models.Analytical Chemistry,1998,70(9):1761−1767
16 Feudale R N,Woody N A,Tan H W,Myles A J,Brown S D,Ferr´e J.Transfer of multivariate calibration models:a review.Chemometrics and Intelligent Laboratory Systems,2002,64(2):181−192
17 Thissen U,¨Ust¨un B,Melssen W J,Buydens L M C.Multivariate calibration with least-squares support vector machines.Analytical Chemistry,2004,76(11):3099−3105
18 Thissen U,Pepers M,¨Ust¨un B,Melssen W J,Buydens L M C.Comparing support vector machines to PLS for spectral regression applications.Chemometrics and Intelligent Laboratory Systems,2004,73(2):169−179
19 Hern´andez N,Talavera I,Biscay R J,Porro D,Ferreira M M C.Support vector regression for functional data in multivariate calibration problems.Analytica Chimica Acta,2009,642(1−2):110−116
20 Barman I,Kong C R,Dingari N C,Dasari R R,Feld M S.Development of robust calibration models using support vector machines for spectroscopic monitoring of blood glucose.Analytical Chemistry,2010,82(23):9719−9726
21 Hern´andez N,Talavera I,Dago A,Biscay R J,Ferreira M M C,Porro D.Relevance vector machines for multivariate calibration purposes.Journal of Chemometrics,2008,22(11−12):686−694
22 Pan S J,Yang Q.A survey on transfer learning.IEEE Transactions on Knowledge and Data Engineering,2010,22(10): 1345−1359
23 Chen J H,Tang L,Liu J,Ye J P.A convex formulation for learning a shared predictive structure from multiple tasks. IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(5):1025−1038
24 Ando R K,Zhang T.A framework for learning predictive structures from multiple tasks and unlabeled data.The Journal of Machine Learning Research,2005,6:1817−1853
25 Romera-Paredes B,Argyriou A,Bianchi-Berthouze N,Pontil M.Exploiting unrelated tasks in multi-task learning.In: Proceedings of the 15th International Conference on Artificial Intelligence and Statistics.La Palma,Canary Islands,2012.951−959
26 Caruana R.Multitask learning.Machine Learning,1997,28(1):41−75
27 Argyriou A,Evgeniou T,Pontil M.Convex multi-task feature learning.Machine Learning,2008,73(3):243−272
28 Zhang W L,Li R J,Zeng T,Sun Q,Kumar S,Ye J P,Ji S W.Deep model based transfer and multi-task learning for biological image analysis.In:Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2015.1475−1484
29 Liu A A,Xu N,Su Y T,Hong L,Hao T,Yang Z X. Single/multi-view human action recognition via regularized multi-task learning.Neurocomputing,2015,151:544−553
30 Archambeau C,Guo S B,Zoeter O.Sparse Bayesian multitask learning.In:Proceedings of the 2011 Advances in Neural Information Processing Systems.Cambridge MA:MIT Press,2011.1755−1763
31 Ueda N,Nakano R.Deterministic annealing EM algorithm. Neural Networks,1998,11(2):271−282
32 Katahira K,Watanabe K,Okada M.Deterministic annealing variant of variational Bayes method.Journal of Physics: Conference Series,2008,95(1):012015
33 Lin Z Z,Xu B,Li Y,Shi X Y,Qiao Y J.Application of orthogonal space regression to calibration transfer without standards.Journal of Chemometrics,2013,27(11): 406−413
34 Jun L,Ji S W,Ye J P.Multi-task feature learning via efficient L2,1-norm minimization.In:Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence.Montreal,Canada,2009.339−348

俞斌峰中国科学技术大学自动化系博士研究生.2010年获得中国科学技术大学自动化系学士学位.主要研究方向为机器学习和光谱分析.本文通信作者.E-mail:ybfeng@mail.ustc.edu.cn
(YU Bin-FengPh.D.candidate in the Department of Automation,University of Science and Technology of China.He received his bachelor degree from University of Science and Technology of China in 2010.His research interest covers machine learning and spectral analysis.Corresponding author of this paper.)

季海波中国科学技术大学自动化系教授.1984年获得浙江大学力学与机械工程系学士学位,1990年获得北京大学力学与工程科学系理学博士学位.主要研究方向为非线性及自适应控制.E-mail:jihb@ustc.edu.cn
(JI Hai-BoProfessor in the Department of Automation,University of Science and Technology of China.He received his bachelor degree and Ph.D.degree in mechanical engineering from Zhejiang University and Beijing University,in 1984 and 1990,respectively.His research interest covers nonlinear control and adaptive control.)
Sparse Bayesian Mixture of Experts and Its Application to Spectral Multivariate Calibration
YU Bin-Feng1JI Hai-Bo1
In spectral multivariate calibration,high dimensional spectral data are often measured on different conditions. To predict the property value of a spectrum without knowing its source,a new sparse Bayesian mixture experts(ME)model is proposed and applied to the multivariate calibration model for selecting the sparse features.The technique of mixture of experts can divide the training data into some different classes and estimate the different predictive functions for each class.Therefore,ME is suitable for prediction of multiple-source spectral data.To analyze high dimensional spectral data,the new ME model employs the sparse Bayesian method to select certain features without tuning parameters.Moreover,the multinomial probit model is used as the gate function to obtain the analytic posterior distribution in this model.This new method is compared with some classical multivariate calibration methods on artificial and some real-world datasets. Experimental results show the advantage of proposed model for high dimensional spectral data.
Multivariate calibration,mixture of experts,feature selection,variational inference
Manuscript April 29,2015;accepted August 31,2015
10.16383/j.aas.2016.c150255
Yu Bin-Feng,Ji Hai-Bo.Sparse Bayesian mixture of experts and its application to spectral multivariate calibration.Acta Automatica Sinica,2016,42(4):566−579
2015-04-29录用日期2015-08-31
国家高技术研究发展计划(863计划)(AA2100100021)资助
Supported by National High Technology Research and Development Program of China(863 Program)(AA2100100021)
本文责任编委贾云得
Recommended by Associate Editor JIA Yun-De
1.中国科学技术大学自动化系合肥230027
1.Department of Automation,University of Science and Technology of China,Hefei 230027
