一种基于动态决策块的超启发式跨单元调度方法
2016-11-08田云娜李冬妮刘兆赫郑丹
田云娜 李冬妮 刘兆赫 郑丹
一种基于动态决策块的超启发式跨单元调度方法
田云娜1,2李冬妮1刘兆赫1郑丹1
对运输能力受限条件下的跨单元调度问题进行分析,提出一种基于动态决策块和蚁群优化(Ant colony optimization,ACO)的超启发式方法,同时解决跨单元生产调度和运输调度问题.在传统超启发式方法的基础上,采用动态决策块策略,通过蚁群算法合理划分决策块,并为决策块选择合适的规则.实验表明,采用动态决策块策略的超启发式方法比传统的超启发式方法具有更好的性能,本文所提的方法在最小化加权延迟总和目标方面有较好的优化能力并且具有较高的计算效率.
动态决策块,超启发式,蚁群算法,跨单元调度
引用格式田云娜,李冬妮,刘兆赫,郑丹.一种基于动态决策块的超启发式跨单元调度方法.自动化学报,2016,42(4): 524−534
单元制造系统(Cellular manufacturing system,CMS)的思想是将成组技术应用在生产制造业领域中,通过构建功能相对独立的生产单元,将具有相同性质的一批工件集中在单元内加工,这种生产方式有效地降低了运输时间、响应时间等生产成本[1].然而在实际生产中,受到市场需求多样化和生产经济成本方面的约束,具有复杂工艺的工件需要通过多个单元协作加工,形成了跨单元协作的生产模式,由此产生了跨单元调度问题[2].
在现有的跨单元问题研究中,由于元启发式算法具备较强的优化能力,大部分学者采用这种方法解决跨单元调度问题.其中Solimanpur等[3]提出一种嵌套的禁忌搜索算法解决跨单元工件调度问题.Tang等[4]和Tavakkoli-Moghaddam等[5]采用分散搜索算法解决工件在多个单元间的跨单元调度问题.Zeng等[6]采用遗传算法和局部搜索结合的方法解决单元内工件排序问题,以最小化最大完工时间为启发式信息,采用轮盘赌方法解决单元间工件分派问题.Elmi等[7]采用模拟退火方法解决跨单元调度问题.Li等[8]采用蚁群优化算方法解决具有柔性路径的跨单元调度问题.在当前被验证过的最大问题规模下(60~80个工件/25~40台机器/6~8个单元),元启发式算法一般需要耗费数百秒(371s[8]、840s[5])才能得到调度解.然而,在装备制造业复杂产品的CMS中,通常有十余个单元、数百个工件、数百台机器、数千道工序,元启发式算法将无法承受如此大规模问题的计算压力,因此从计算效率的角度考虑,不能直接使用元启发式算法.
在上述跨单元问题的研究中,文献[3,5]忽略了跨单元转移时间,文献[4,6−8]考虑了跨单元转移时间.但是这些研究都隐含一个假设,即单元间运输能力充足,工件在单元间运输无需等待.而在装备制造业的实际生产中,由于各个单元分布在不同位置,工件具有一定的重量和体积,因此需要由运输工具完成跨单元转移,但运输工具的数量和容量却有限.因此如何高效地利用有限的运输工具成为实际生产中的重要问题.本文考虑运输能力受限的跨单元调度问题,同时处理工序分派、工序排序和小车运输三个子问题,问题在复杂度和规模两方面都有所增加,调度算法需要同时满足优化性能和计算效率两方面的需求.
在实际生产中,启发式规则在计算效率方面表现出良好的性能,因其简单、快捷和易实施的特点而被广泛应用[9],特别适用于复杂、具有动态特性的制造环境[10].但启发式规则的缺陷在于它对调度环境和调度目标的依赖性较强,没有哪个规则能在所有情况下都表现出良好的性能[11],而且选用规则都是根据人为经验事先指定的,优化能力较差,因此无法满足复杂调度问题的优化性能需求.
超启发式算法(Hyper-heuristic)作为一种“搜索启发式方法”(Heuristics to search heuristics)[12],相当于将启发式规则和其他搜索方法或学习机制的优势相结合,用优化能力较强的算法搜索或产生高效的规则,再用得到的规则求解.在已有的超启发式算法研究中,遗传算法被广泛应用于选择启发式规则[13−16].另外,Li等[17]采用基于蚁群优化算法的超启发式方法解决混合流水车间调度问题.贾凌云等[18]提出一种基于混合蛙跳算法的超启发式方法,并通过遗传规划产生的规则扩充超启发式算法的规则集.刘兆赫等[19]提出一种基于离散蜂群算法的超启发式方法.由于超启发式算法的搜索对象是启发式规则而不是问题的解,这样既避免了人工指定启发式规则的主观性,提高了优化能力,同时也缩小了搜索空间,提高了计算效率.
对于生产调度问题而言,超启发式算法通常是为生产环境中的“实体”(比如工件)搜索底层的启发式规则,然后对这些实体应用启发式规则进行调度.本文将超启发式算法中的决策单位称为“决策块”,决策块的大小决定了为多大范围的实体选择同一个启发式规则.按照决策块大小为分类标准,可以将超启发式算法的研究分为两类.一类是决策块大小均为1的情况,即为每个实体(机器/工件)选择一个启发式规则[13−14,17−18].另一类是决策块大小不全为1的情况,即为多个实体选择同一个启发式规则,Yang等[20]为每个阶段的所有机器选择一个启发式规则.V´azquez-Rodr´ıguez等[15−16]、刘兆赫等[19]将每次决策看作一个决策点,按时间顺序将所有决策点划分为多个决策块,为每个决策块选择一个启发式规则.
在上述两类方法中,决策块大小会直接影响算法的计算效率和优化性能.当决策块较小时,能够考虑到不同实体的状态特征,更有可能为每个实体选到合适的规则,使得算法的优化性能有保证,但也会因此付出较大的计算开销,反之亦然.因此,在解决大规模复杂问题时,决策块的大小成为影响算法计算效率和优化性能的关键因素.
在现有的超启发式算法研究中,决策块大小一般都是事先指定的[13−15,17−18],本文称之为静态决策块策略.在这类方法中,决策块大小在算法的运行过程中是确定不变的,这使算法的适应性受到限制.动态决策块策略则是通过迭代不断优化决策块的大小,动态寻找合理的决策块划分方案.在目前的研究中,采用动态决策块策略的文献还很少,V´azquez-Rodr´ıguez等[16]采用遗传算法动态优化决策块大小和启发式规则序列,解决多目标作业车间调度问题.
基于以上分析,本文设计了一种基于动态决策块和蚁群优化(Ant colony optimization,ACO)的超启发式算法(Dynamic decision block and ACO-based hyper-heuristic,DABH).在传统超启发式的框架上加入动态决策块策略,通过ACO动态构建决策块并搜索启发式规则.本文的主要贡献在于以下两点:1)动态决策块策略可以合理地缩小搜索空间,提高算法的计算效率;2)ACO算法作为一种构造型优化方法,通过信息素的引导,动态生成大小合适的决策块,从而达到优化性能和计算效率之间的平衡.
1 问题模型
本文根据作业车间跨单元调度问题抽象出问题模型,以最小化加权延迟总和(Total weighted tardiness,TWT),为优化调度目标.本文问题模型同时考虑跨单元生产和跨单元运输的协同.
1.1问题假设
本文研究运输能力受限的跨单元调度问题假设描述如下:
1)所有工件零时刻到达;
2)每个工件的交货日期已知;
3)工序在特定机器上的加工时间固定且已知,准备时间独立于工序次序;
4)每台机器在同一时刻只能加工一道工序;
5)工序一旦开始,便不允许中断和抢占;
6)单元间存在加工能力重叠的机器,即工件跨单元加工路径具有柔性,对于任意一道工序,单元内最多只有一台可加工的机器;
7)考虑工件的跨单元转移时间,忽略单元内转移时间;
8)小车负责运输由多个工件组成的一个批次,一个批次内的工件可以有不同的目的单元;
9)小车仅装载本单元内工件,从本单元出发后不在沿途各单元装载工件;
10)小车按照一定顺序访问目的单元并卸载相应工件,一旦所有工件卸载完毕,小车立即返回所属单元;
11)忽略小车装载和卸载工件的时间.
1.2符号列表
与本文问题相关的符号变量定义如下所示.
索引
i:工件索引(i=1,···,N)
j:工件i的工序索引(j=1,···,J(i))
m:机器索引(m=1,···,M)
c:单元及所属小车索引(c=1,···,C)
b:小车c上批次索引(b=1,···,B(c))
q:第b个批次内工件的运输顺序索引
(q=1,···,Q(b))
系统变量
Oij:工件i的第j道工序
J(i):工件i的工序总数
pijm:工序Oij在机器m上的加工时间
si:工件i的体积
di:工件i的交货期
wi:工件i的权重
v:小车的容量
Tcc':从单元c到单元c'所需要的转移时间
tij:工序oij完工后所需要的转移时间
Dij:工序oij完工后转移的目的单元
sij:工序oij的开始时间
fij:工序oij的完工时间


1.3目标函数及约束条件
本文的调度目标是最小化加权延迟总和.目标函数的数学表达式如式(1)所示.
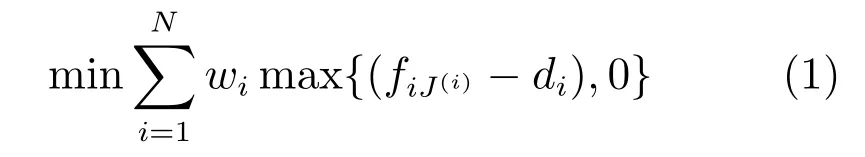
根据实际生产中的问题特性和约束,本文的约束条件描述如下.
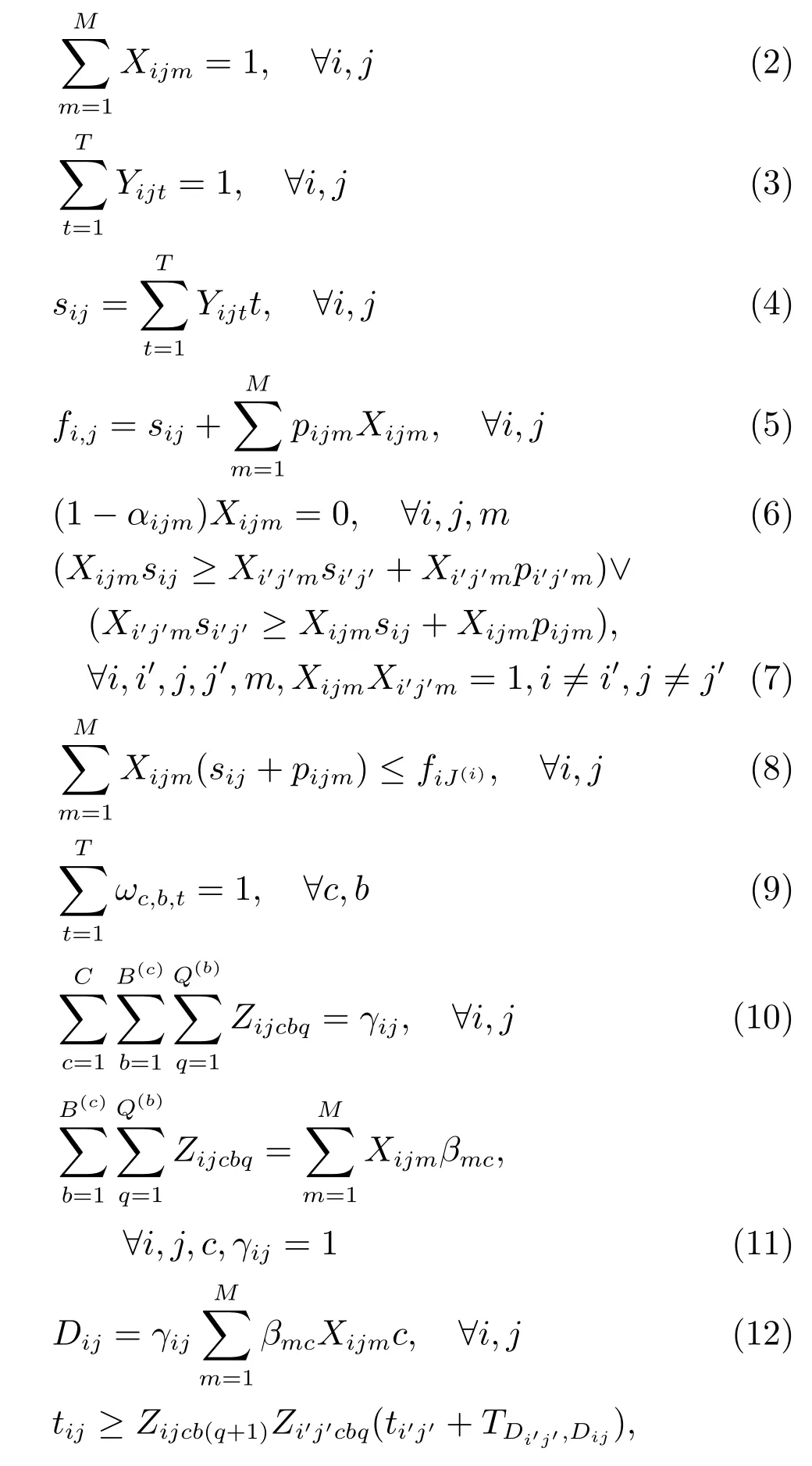
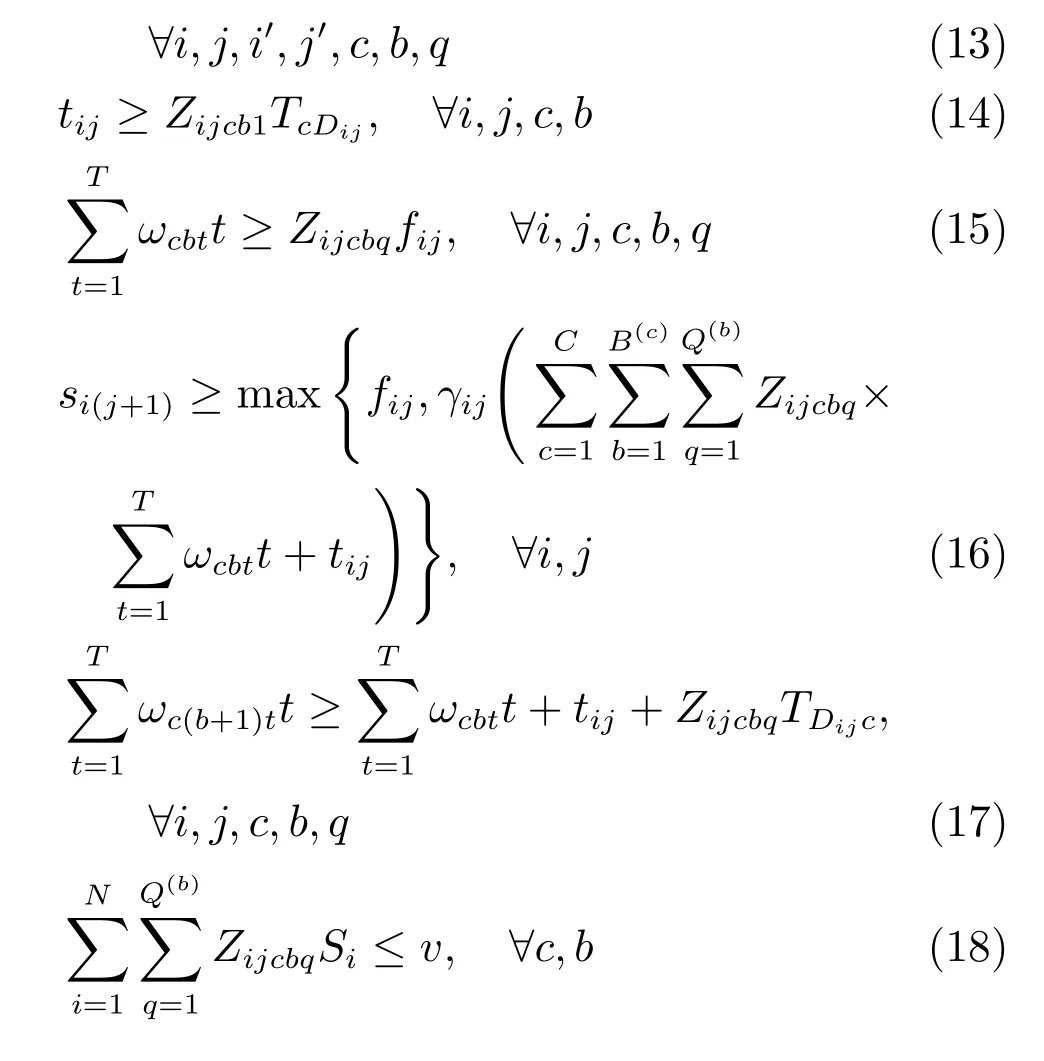
其中,式(2)表示一个工序只能在一个机器上进行加工;式(3)表示一个工序在同一时刻只能被加工一次;式(4)和式(5)分别表示工序的开始加工时间和完工时间;式(6)表示工序只能被分派到具有相应加工能力的机器上;式(7)保证被分派到机器上的工件的顺序性;式(8)表示工件的完工时间大于或等于其任意一道工序的完工时间;式(9)表示小车的一个批次只能被运输一次;式(10)表示一个工件只能被分派到一个小车的一个批次;式(11)表示需要跨单元的工件只能被分派到本单元的小车;式(12)定义小车运输目标单元;式(13)和式(14)表示任意批次的所有工件只有在小车到达其目的单元才能被卸载;式(15)表示每个批次必须等到批次内所有工件的前一道工序完成才能开始运输;式(16)表示任意工序只能在其前一道工序完成,并被运输至目的单元才能开始加工;式(17)表示每个小车运输完一个批次内所有工件并返回所在单元后才能开始下一批次运输;式(18)表示所有被分派到同一小车的同一批次的工件体积总和小于或等于小车容量.
2 DABH算法
在运输能力受限的跨单元调度问题中,需要考虑多个子问题以及它们之间的协同.在解决这一类大规模复杂调度问题时,需要兼顾算法的优化性能和计算效率.DABH在超启发式的框架上加入动态决策块策略,通过合理的缩小搜索空间,从而达到提高算法计算效率的目的.同时,DABH采用ACO作为超启发式算法的高层优化方法,通过信息素的引导动态寻找合理的决策块划分方案,并为不同的决策块选择合适的启发式规则,通过得到的启发式规则进行调度产生完整解.
2.1基于动态决策块的算法框架
本文问题模型包含三个子问题,其中工序分派为每道工序选择一台加工机器;工序排序确定机器缓冲队列中待加工工件的加工次序;小车运输包含对工件的组批和路径决策,组批确定小车每个批次运送哪些工件,路径决策确定工件的运输次序. DABH算法解决以上三个问题的流程描述如图1.
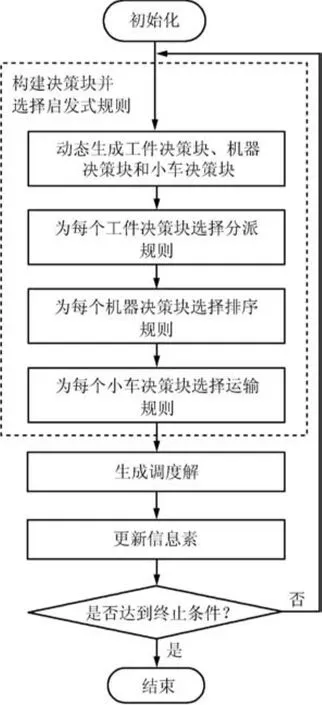
图1 DABH算法的整体流程图Fig.1 General algorithm of DABH
在图1中,所有决策块大小在初始阶段随机生成,在迭代过程中根据解的优化性能更新部分最优解的信息素,然后根据信息素逐步优化决策块的大小,使决策块趋向于更加合理的划分.同时,根据候选规则的信息素浓度为每个决策块选择规则.在调度过程中,每个决策块内的实体采用相同的规则,生成最终调度解.
2.2基于动态决策块的编码
在DABH算法中,每个决策块的大小代表所包含实体的数量,这里实体指工件、机器和小车,决策块的大小决定一个启发式规则所作用的范围,本节对决策块以及基于决策块的编码进行形式化的描述.
本文将实体集合记为E={e1,···,eN},其中N表示实体的数量.将启发式规则集合记为代表工序分派规则集合,代表工序排序规则集合代表小车运输规则集合.在规则选取过程中,分别从H'、H''、H'''中为工件决策块、机器决策块和小车决策块选取规则,最终得到基于决策块的规则编码.
定义 1.将所有实体划分成若干个决策块,所有决策块构成的集合定义为B,B={b1,···,bi,···,bL},集合中元素须同时满足两个条件:S
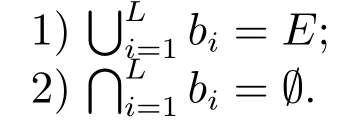
在定义1中,条件1)表示所有实体都被划分到各个决策块中,条件2)表示一个实体不能重复出现在多个决策块中.
例1.假设在工件分派子问题中有4个工件,这些工件被划分成两个决策块.那么两个决策块的大小之和为4,并且决策块之间没有重复的工件出现.
定义 2.对于决策块集合B={b1,···,bi,···,bL},基于决策块的规则编码定义为A={a1,···,ai,···,aL}.
例2.假设测试问题有8个实体,包括2个工件,4台机器和2个单元,即E={e1,···,e8},启发式规则集合
当决策块大小均为1时,即为每个实体选择一个规则.如图2所示,虚框内为基于8个实体的规则编码A={a1,···,ai,···,a8},在H中分派、排序和运输规则分别有2个,那么对应编码的搜索空间大小为22×24×22.
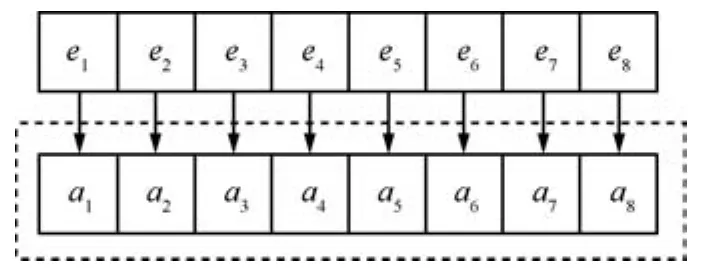
图2 决策块大小均为1的编码Fig.2 Representation of decision blocks whose size is 1
当决策块大小不全为1时,即存在为多个实体选择一个规则的情况.如图3所示,将8个实体划分为4个决策块,即B={b1,b2,b3,b4}.其中b1={e1,e2},b2={e3},b3={e4,e5,e6},b4={e7,e8},它们分别是1个工件决策块、2个机器决策块和1个小车决策块.
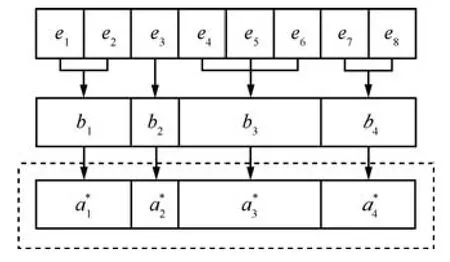
图3 决策块大小不全为1的编码Fig.3 Representation of decision blocks with different sizes
由此可见,当决策块大小不全为1时,决策块策略能够有效缩小搜索空间,在计算效率方面会有所提高.但是当决策块大小过大时,问题求解空间将过于单一,有可能遗漏掉优质解,导致算法的优化性能受到限制.因此确定合理的决策块大小,将有利于在提高计算效率的同时保证算法的优化性能.
2.3基于动态决策块的规则选取
在DABH算法中,通过信息素引导动态生成决策块,以决策块为单位选择启发式规则,对决策块内的所有实体应用规则得到调度解.算法根据生成的调度解的优劣更新信息素,从而达到寻优的目标.
2.3.1信息素结构
在构造信息素结构时,DABH包含两类信息素矩阵,即决策块划分矩阵和启发式规则选择矩阵.
针对分派、排序、运输三个子问题,决策块划分矩阵分别为工件、机器和小车三个决策块划分矩阵.三个矩阵的大小分别为N×D'、M×D''和C×D''',其中N、M 和C分别表示工件、机器和小车的数量,D'、D''和D'''分别表示工件、机器和小车决策块大小的上限,上限取值通过参数实验获得,在第3.2节中有详细描述.矩阵中元素τi,p表示第i个决策块的大小为p的信息素浓度.
同上分析,启发式规则矩阵分别为工件、机器和小车三个分派规则矩阵.矩阵大小为分别为N×R'、M×R''和C×R''',其中R'、R''和R'''分别表示分派规则、排序规则和运输规则的数量.矩阵中元素τi,q表示第i个决策块选取第q个启发式规则的信息素浓度.
2.3.2候选规则集
针对三个子问题,候选规则分别对应分派、排序和运输三种规则.另外,由于工件交货期(Due date)直接影响TWT,因此在候选排序规则集中加入与交货期相关的规则,其中包含公认效果显著的Apparent tardiness cost、Cost over time、Minimum slack、Slack per remaining processing time等规则[9].
1)候选分派规则
First available(FA):选择最先可用机器.
Earliest finish time(EFT):选择加工该工序后具有最早完成时间的机器.
Least utilization(LU):选择加工该工序后具有最低占用率的机器.
Most available(MA):选择当前缓冲区内待加工工件最少的机器.
Shortest processing time(SPT):选择加工时间最短的机器.
2)候选排序规则
Shortest processing time(SPT):选择具有最短加工时间的工件.
Smallest processing time ratio(SPTR):选择具有最小加工时间比率的工件.
Shortest remaining processing time(SRPT):选择具有最短剩余加工时间的工件.
Weighted shortest processing time(WSPT):选择具有最小加权加工时间的工件.
Time in shop(TIS):选择在当前机器缓冲队列中等待时间最长的工件.
Earliest due date(EDD):选择具有最早交货期的工件.
Weighted earliest due date(WEDD):选择具有最小加权交货期的工件.
Minimum slack(MS):选择具有最小松弛时间的工件.
Apparent tardiness cost(ATC):选择ATC值最大的工件,具体计算见式(19).
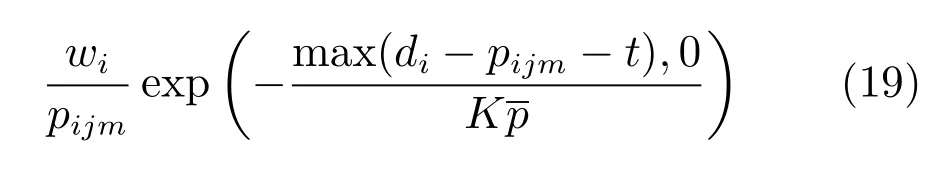
Cost over time(COVERT):选择COVERT值最大的工件,具体计算见式(20).
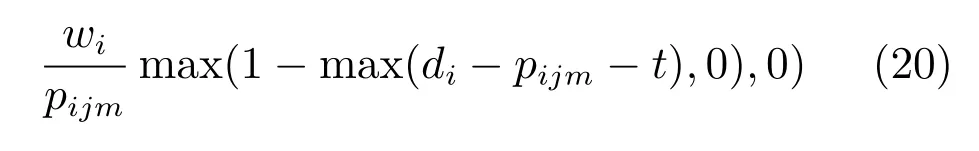
Slackperremainingprocessingtime(S/RPT):选择S/RPT值最小的工件,具体计算见式(21).
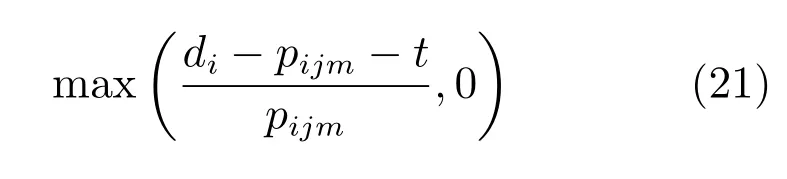
3)候选运输规则
Earliest due date(EDD):选择具有最早交货期的工件.
Shortest processing time(SPT):选择具有最短加工时间的工件.
Smallest processing time ratio(SPTR):选择具有最小加工时间比率的工件.
Shortest remaining processing time(SRPT):选择具有最短剩余加工时间的工件.
Weighted earliest due date(WEDD):选择具有最小加权交货期的工件.
Weighted shortest processing time(WSPT):选择具有最小加权加工时间的工件.
Time in shop(TIS):选择当前机器缓冲队列中等待时间最长的工件.
2.3.3确定决策块大小和规则
在DABH算法中,采用ACO算法来确定决策块的大小,并为每个决策块选取规则.每只蚂蚁通过信息素浓度计算选择决策块大小和启发式规则的概率.
1)当蚂蚁选择决策块大小时,第i个决策块的大小为p的概率由式(22)计算可得.
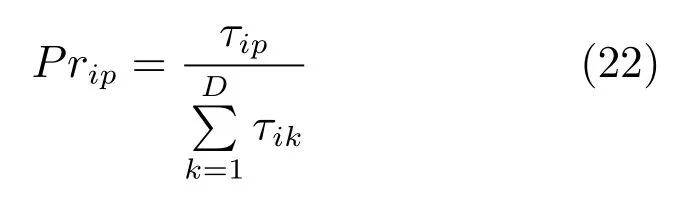
其中,τip表示第i个决策块的大小为i的信息素浓度.D表示决策块大小的上限,当选择工件决策块大小时,D为D';当选择机器决策块大小时,D为D'';当选择小车决策块大小时,D为D'''.
2)当蚂蚁选择启发式规则时,第i个决策块选取第q个启发式规则的概率由式(23)计算可得.
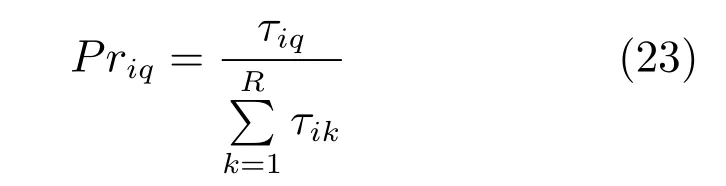
其中,τiq表示第i个决策块的选取第q个启发式规则的信息素浓度.R表示启发式规则的数量,为工件决策块选择规则时,R为R';为机器决策块选择规则时,R为R'';为小车决策块选择规则时,R为
R'''.
2.3.4信息素更新
本文采用最大最小蚂蚁系统(Max-min ant system,MMAS)的信息素更新方法,更新信息素的值限定在区间[τmin,τmax]内,τmin取值为0.1,τmax取值为5.在每次循环中,所有蚂蚁均完成调度解的构造后进行信息素更新,参与更新的仅为本次循环中的σ个最优解.这种方法既能使蚁群搜索的范围集中在较优解附近,又不会因使用循环中的单个最优解或全局最优解更新信息素而使收敛速度过慢[21].
信息素更新规则如下:
1)决策块大小信息素更新规则.若第i'个决策块大小确定为k,则决策块划分矩阵中的元素τi'k根据式(24)进行更新.
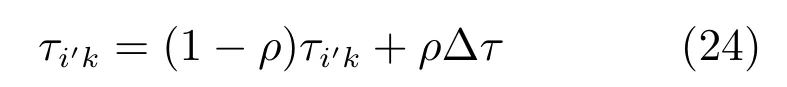
2)启发式规则的信息素更新规则.若第i'个决策块选择第l个分派规则,则启发式规则选择矩阵中的元素τi'l根据式(25)进行更新.
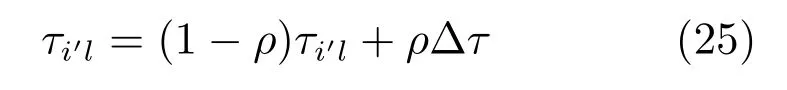
在式(24)和(25)中,∆τ=Q/Score,Q为信息素更新量影响因子,Score为更新信息素的调度解对应的目标函数值.
2.4基于动态决策块的解码
DABH算法通过ACO算法为决策块选择启发式规则,得到一组规则编码序列,系统将其转换成具体的调度解,即解码过程.解码算法描述如下:
步骤1.参数初始化,置离散事件模拟器(Discrete event simulation,DES)时钟t=0.
步骤2.分别把排序规则分配至各机器,分派规则分配至各工件,运输规则分配至各单元小车.
步骤3.如果所有工件都已完工,转步骤11.
步骤4.对于可分派工件,若存在单元间柔性路径,则根据分派规则选择加工机器,更新被选机器的缓冲队列;否则,说明其下一道工序的加工机器是确定的,直接分派到该机器的缓冲队列上.
步骤5.如果单元c的小车是空闲可用的且有要运输的工件,则转步骤6;否则,转步骤7.
步骤6.根据运输规则计算单元c中待运输工件的优先级,在不超过小车容量的情况下根据优先级进行组批并确定小车的运输路径.
步骤7.如果机器m变空闲,则转步骤8;否则,转步骤10.
步骤8.根据排序规则调度一个工件.
步骤9.记录该工件调度工序的开工时间,完工时间和对应的加工机器.
步骤10.t=t+1,转到步骤3.
步骤11.利用步骤9的记录信息,根据式(1)计算相应的目标函数值TWT.算法结束.
3 实验与分析
为了验证DABH算法的优化性能和计算效率,本文进行了多组对比实验,仿真实验采用JAVA语言实现,运行在3.10GHz Core i5-2400 CPU,4GB RAM的PC机上.
3.1实验设计
在运输能力受限的跨单元调度问题研究中,目前尚没有相关的Benchmark,因此设计了不同规模下的多组测试用例.测试用例的性能评价指标为目标函数值TWT,按照式(1)计算可得,与TWT相关的工件交货期di按式(26)进行计算.
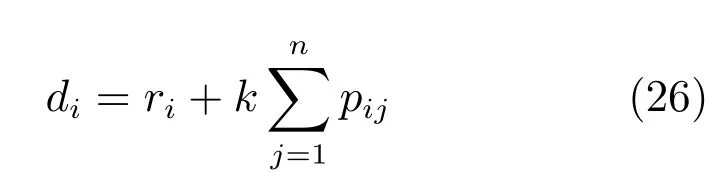
其中ri是工件i的到达时间,由于本文问题假设所有工件零时刻到达,因此是工件i在可选机器上的平均加工时间pij的总和,k为交货期因子,表示交货期的紧急程度,默认取值为6.
实验包括20个不同大小的规模,机器和工件相关属性的取值如表1所示.每个规模下根据表1的参数随机产生10个不同测试用例,对每个不同的测试用例进行5次独立的仿真实验.每个测试问题采用pn1mn2cn3的记法,表示该测试问题中包含n1个工件、n2台机器和n3个单元.

表1 生成算例属性值Table 1 Attributes for generating test problems
为了验证算法的有效性,实验分别在不同问题规模下获取多个测试用例的目标函数TWT的平均值,通过DABH方法与其他方法之间的Gap值进行对比分析.
3.2参数分析
本文参数设计采用全因子设计方法[22],使用ANOVA(Analysis of variance)方法从单因子效应和双因子交互作用两个方面进行分析,观测多个因素对算法优化目标TWT的影响,从而确定算法最优参数的设置.
由于DABH采用ACO算法搜索规则,因此信息素挥发因子ρ、信息素更新量影响因子Q和信息素浓度最大值τmax等参数会对算法的优化性能有所影响.由于信息素更新量与Q直接相关,在若干次迭代更新后优质解路径上的信息素浓度将达到τmax,因此将Q/τmax作为实验参数,其中τmax取值为5,ρ和Q/τmax的参数取值分4个级别,如表2所示.

表2 DABH参数Table 2 Parameters in DABH
本文以最小化TWT为优化目标值,图4展示了单因子主效应.由于影响算法性能包含两个因子,因此还需要分析因子之间的交互作用,图5展示了双因子的交互影响.从图4和图5可看出,当ρ=0.01,Q/τmax=0.05时,DABH都具有最优解性能.
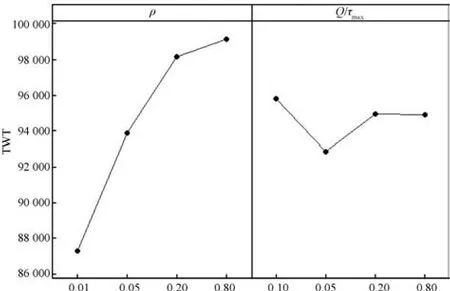
图4 最小化TWT目标下的单因子主效应图Fig.4 Influence of each factor with respect to minimizing TWT
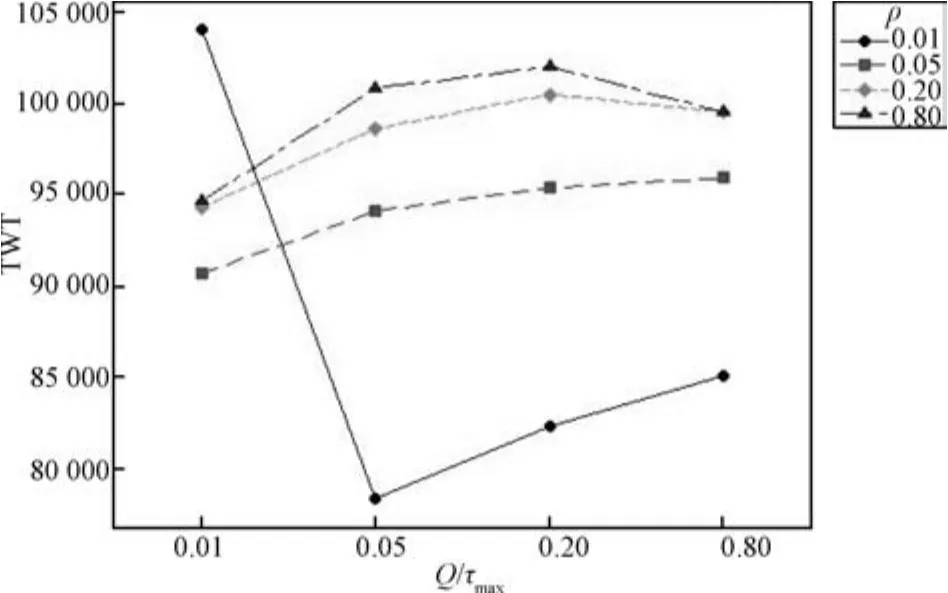
图5 最小化TWT目标下的双因子交互作用图Fig.5 Influence of 2-factor interaction with respect to minimizing TWT
在决策块大小上限的参数实验中,工件、机器和小车决策块数量的上限D'、D''、D'''分别根据三种实体数量的百分比{10%,20%,···,100%}进行取值,测试10种不同规格的参数设置,最终效果最好的上限参数为100%,因此D'、D''、D'''分别被设为三种实体的数量.
3.3与基于静态决策块的方法比较
为了检验DABH算法中动态决策块划分策略的有效性,本节对比实验基于采用DABH的算法框架,将动态决策块划分策略与三种不同的静态决策块划分策略进行比较.为了保证实验的公平性,三组对比实验采取相同的运行时间作为终止条件.
1)每个决策块的范围是调度中的一个实体
在调度中每个决策块包含一个实体,将这种方法记为DABH-ONE.
实验按照式(27)计算DABH与DABH-ONE之间的Gap值,记为GapONE.由于计算方法类似,在后续的对比实验中,DABH与其它算法之间的Gap值计算方法均参考式(27).
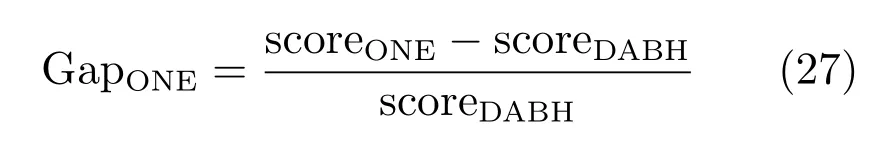
其中,scoreONE和scoreDABH分别代表决策块大小均为1的方法和DABH的目标函数值.
实验结果如表3所示,在不同规模的测试问题下,DABH均优于DABH-ONE的优化性能,Gap平均值为11.5%.这组实验表明,随着问题规模增大,实体的数量增多,DABH-ONE的解编码长度也增大,因此搜索空间变大.而DABH根据问题规模将所有实体划分为若干个决策块,每个决策块最少包含一个实体,决策块的数量小于或等于实体的数量,相应的解编码长度减少,从而适当地缩小了搜索空间.由此可见,DABH-ONE虽然能关注每个实体的状态,但由于搜索空间过大,使得在相同条件下前者的计算能力下降,所以综合求解能力与DABH相比较差.
2)每个决策块的范围是调度中的一类实体
在调度中每个决策块包含一类实体,将这种方法记为DABH-ALL.本文的问题针对工件、机器和小车三类实体.DABH与DABH-ALL之间的Gap值记为GapALL.如表3所示,DABH相比于DABH-ALL在平均性能上提升了26.8%.实验表明,DABH-ALL过度缩小了搜索空间,使解的多样性受到限制,从而影响解的质量.而DABH通过动态寻找合理的决策块划分方案,既保留了解的多样性,又使得计算时间处于合理的范围.
3)每个决策块的范围是调度中的多个实体
为了避免决策块过大或过小,本节针对1)和2)提出的决策块划分方案,将决策块的大小设置为决策块候选取值的中间值,记为DABH-AVG.DABH与DABH-AVG之间的Gap值记为GapAVG.如表3所示,DABH相比于DABH-AVG在平均性能上提升了14.2%.为了直观地进行对比,将DABH与三种策略对比的Gap值绘制成折线图,如图6所示.
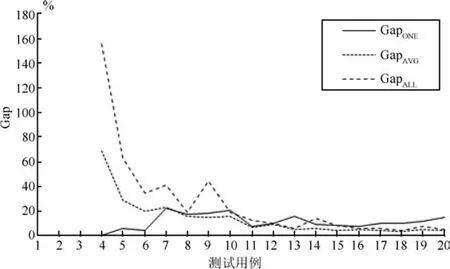
图6 DABH与不同决策块划分策略之间的Gap比较Fig.6 Gap values between DABH and different decision block strategies
结合表3与图6分析发现,从平均性能来看,DABH-AVG处于中间的位置,这主要与DABHAVG的决策块大小适中有关.从图6可以看出,当问题规模较小时,DABH-ALL的相对性能最差,当问题规模较大时,DABH-ONE的性能最差,而DABH-AVG的表现相对平稳.
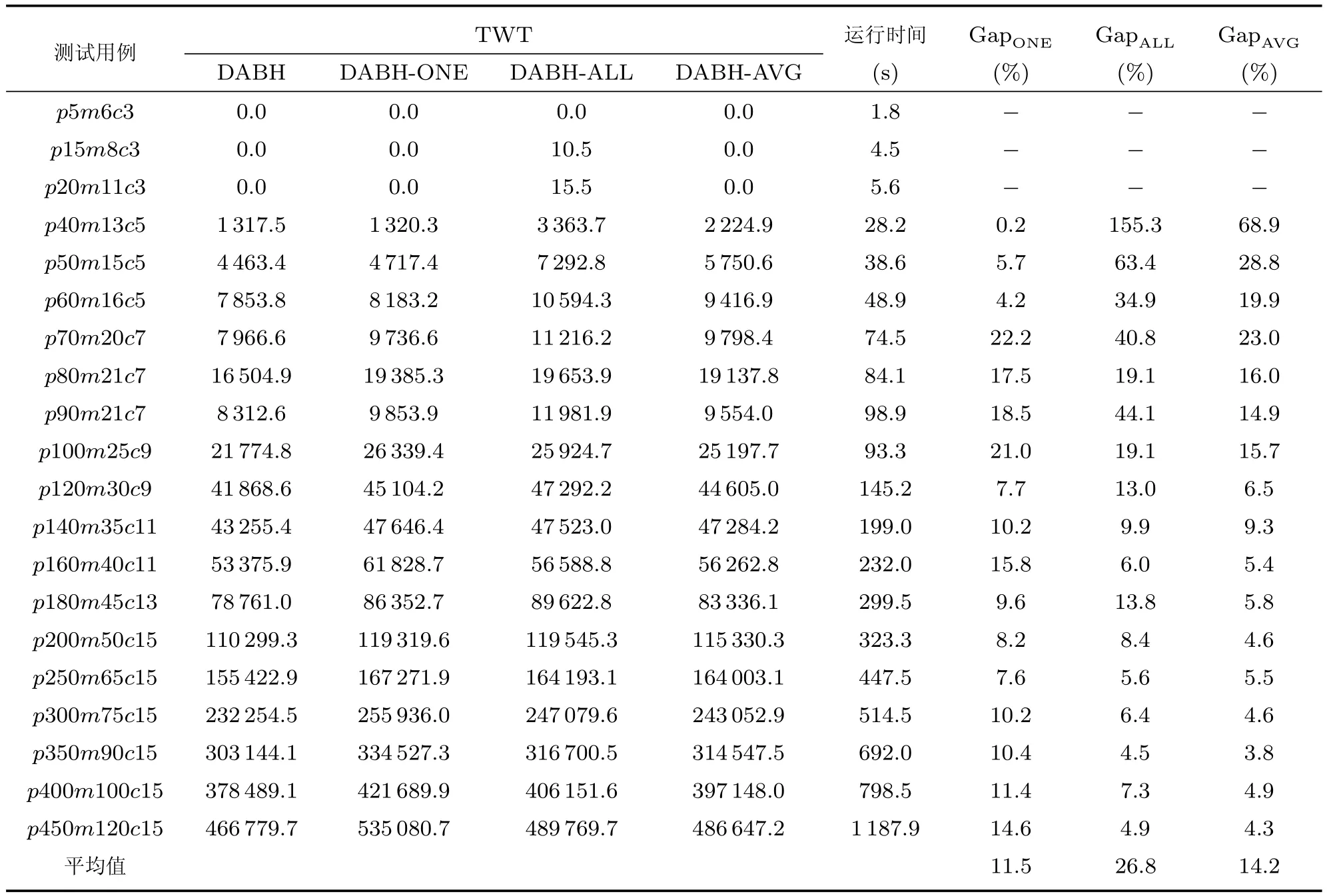
表3 DABH与静态决策块划分策略的性能比较Table 3 Comparison between DABH and static decision block strategies
综合实验1)~3)进行分析,决策块大小过小或过大都会影响算法的计算效率和优化性能,即使DABH-AVG的决策块大小适中,但由于决策块大小确定不变,因此性能也会受到影响.而DABH在每次迭代中根据信息素引导更新决策块大小,然后为每个决策块选择合适有效的启发式规则.这样不但在一定程度上减少了搜索空间,而且寻优能力也得到了保障.通过本节的实验可看出,动态决策块策略相比与静态决策块策略体现出多方面的优势.
3.4与基于动态决策块的方法比较
在现有的研究中,V´azquez-Rodr´ıguez等[16]采用基于动态决策块和GA的超启发式方法(Dynamic decision block GA-based hyper-heuristic),以解决作业车间调度问题,本文将其称作DGBH. DGBH针对调度中的决策,将所有决策划分为若干个大小不等的决策块.而DABH是将所有实体划分为多个决策块.本节将进行DABH与DGBH的对比实验.
为了保证实验的公平性,对比实验采用相同的问题模型和候选规则集,种群数目为100,终止条件为DGBH算法运行200代所需要的时间.
本实验DABH与DGBH之间Gap值记为GapDGBH.实验结果如表4所示,在不同问题规模下,DABH在TWT性能方面平均提升了5.0%.在收敛性方面,图7展示了在问题规模p40m25下两种方法运行200代的收敛情况.
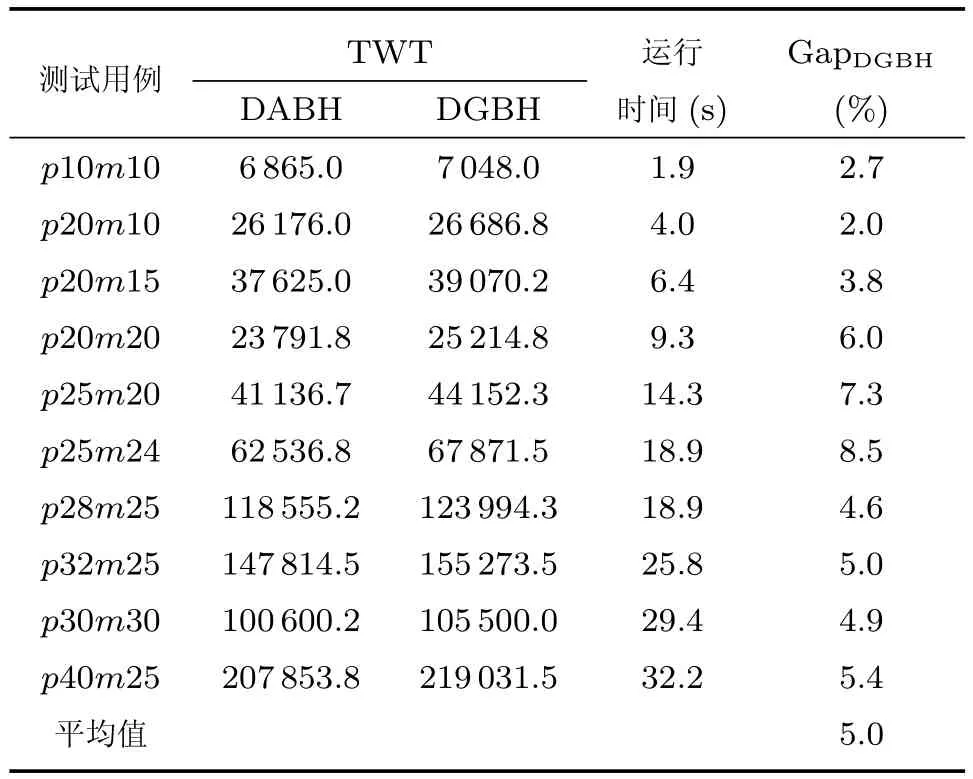
表4 DABH与DGBH的性能比较Table 4 Comparison between DABH and DGBH
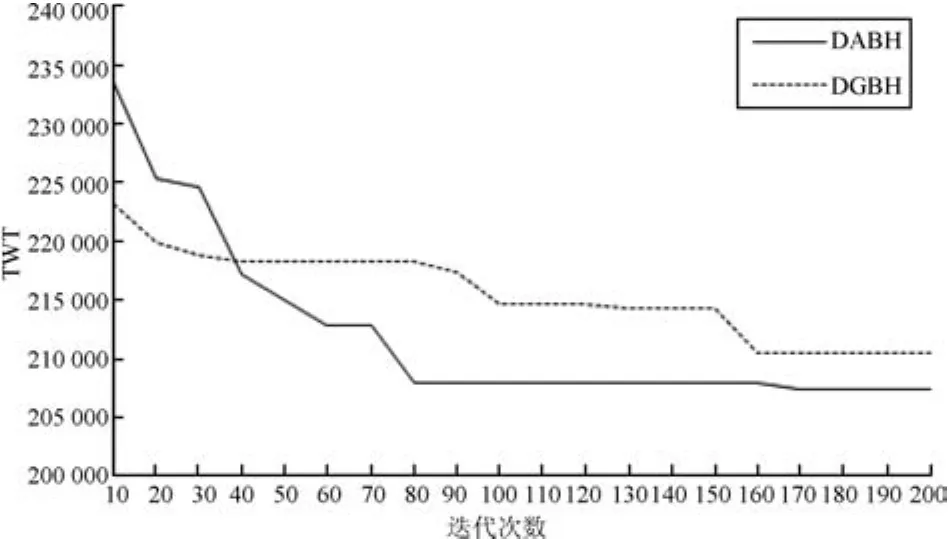
图7 DABH与DGBH的收敛过程比较Fig.7 Evolutionary processes of DABH and DGBH
从图7中可以看出,DABH在第80代之后趋于稳定,DGBH在第150代后趋于稳定,DABH的收敛速度快于DGBH方法,体现出DABH在寻优能力方面上的优势.
分析实验结果,DGBH主要存在两方面局限性.一方面,DGBH的决策块编码中每位数字代表一个决策块的大小,所有基因位上的数值总和应与决策总数相等.然而在编码交叉变换时,DGBH通过对两条父代染色体上随机位置上的编码进行交叉变换产生子代染色体,这可能会产生基因位上的数值总和小于或大于决策总数的情况,需要通过若干次加1或减1的调整获得可行解,这个过程不但破坏了父代的优秀的遗传信息,而且降低了计算效率.另一方面,在突变过程中,DGBH的决策块编码随机选择两个元素交换,启发式规则编码则是采取单点变换,解的多样性受到限制.相比而言,DABH编码是通过信息素引导生成,能更好地处理动态决策块大小的不确定性.在每次迭代过程中,所有蚂蚁根据信息素重新构建决策块及启发式规则,增加了解的多样性,保证了算法的寻优能力.由此可见,ACO算法在动态决策块划分方面具有一定优势.
4 结论
本文针对运输能力受限的跨单元调度问题的特点,从实际应用的要求出发,提出一种基于动态决策块的超启发式方法,解决运输能力受限的跨单元调度问题.在该方法中,决策块的组成和大小通过迭代优化产生,将传统方法中为每个实体或所有实体选择一个规则的形式转化为为每个决策块选择一个规则,从而获得计算效率和优化能力之间的平衡.实验结果表明,与静态决策块相比,动态决策块能够产生更合适的搜索空间,既节省了计算时间,又保留了合适的多样性.与基于动态决策块的超启发式方法相比,ACO比GA具有更好的性能.这种差异的原因在于,构造型算法与改进型算法相比,能更好地处理动态决策块大小的不确定性,而改进型算法则需要用更多的操作来处理进化过程中的不可行解.由此可见,DABH同时兼备计算效率和优化性能的优势,因此非常适合在实际应用中解决规模大、复杂性高的跨单元调度问题.
考虑到不同的实体具有不同的属性,在今后的工作中可以考虑根据实体之间的相关性划分决策块,使决策块的划分过程与问题的特性相互适应,从而提升算法的性能.
References
1 Wemmerlov U,Johnson D J.Cellular manufacturing at 46 user plants:implementation experiences and performance improvements.International Journal of Production Research,1997,35(1):29−49
2 Garza O,Smunt T L.Countering the negative impact of intercell flow in cellular manufacturing.Journal of Operations Management,1991,10(1):92−118
3 Solimanpur M,Elmi A.A tabu search approach for cell scheduling problem with makespan criterion.International Journal of Production Economics,2013,141(2):639−645
4 Tang J,Wang X,Kaku I,Yung K L.Optimization of parts scheduling in multiple cells considering intercell move using scatter search approach.Journal of Intelligent Manufacturing,2009,21(4):525−537
5 Tavakkoli-MoghaddamR,JavadianN,KhorramiA,Gholipour-Kanani Y.Design of a scatter search method for a novel multi-criteria group scheduling problem in a cellularmanufacturing system.Expert Systems with Applications,2010,37(3):2661−2669
6 Zeng C K,Tang J F,Yan C J.Job-shop cell-scheduling problem with inter-cell moves and automated guided vehicles. Journal of Intelligent Manufacturing,2015,26(5):845−859
7 Elmi A,Solimanpur M,Topaloglu S,Elmi A.A simulated annealing algorithm for the job shop cell scheduling problem with intercellular moves and reentrant parts.Computers& Industrial Engineering,2011,61(1):171−178
8 Li D N,Wang Y,Xiao G X,Tang J F.Dynamic parts scheduling in multiple job shop cells considering intercell moves and flexible routes.Computers&Operations Research,2013,40(5):1207−1223
9 Vepsalainen A P J,Morton T E.Priority rules for job shops with weighted tardiness costs.Management Science,1987,33(8):1035−1047
10 Ruiz R,V´azquez-Rodr´ıguez J A.The hybrid flow shop scheduling problem.European Journal of Operational Research,2010,205(1):1−18
11 Park S C,Raman N,Shaw M J.Adaptive scheduling in dynamic flexible manufacturing systems:a dynamic rule selection approach.IEEE Transactions on Robotics and Automation,1997,13(4):486−502
12 Burke E K,Gendreau M,Hyde M,Kendall G,Ochoa G,zcan E,Qu R.Hyper-heuristics:a survey of the state of the art.Journal of the Operational Research Society,2013,64(12):1695−1724
13 Huang J,S¨uer G A.A dispatching rule-based genetic algorithm for multi-objective job shop scheduling using fuzzy satisfaction levels.Computers&Industrial Engineering,2015,86:29−42
14 Zhang R,Song S J,Wu C.A dispatching rule-based hybrid genetic algorithm focusing on non-delay schedules for the job shop scheduling problem.The International Journal of Advanced Manufacturing Technology,2013,67(1−4):5−17
15 V´azquez-Rodr´ıguez J A,Petrovic S,Salhi A.An investigation of hyper-heuristic search spaces.In:Proceeding of the 2007 IEEE Congress on Evolutionary Computation.Singapore:IEEE,2007.3776−3783
16 V´azquez-Rodr´ıguez J A,Petrovic S.A new dispatching rule based genetic algorithm for the multi-objective job shop problem.Journal of Heuristics,2010,16(6):771−793
17 Li D N,Li M,Meng X W,Tian Y N.A hyperheuristic approach for intercell scheduling with single processing machines and batch processing machines.IEEE Transactions on Systems,Man,and Cybernetics:Systems,2015,45(2): 315−325
18 Jia Ling-Yun,Li Dong-Ni,Tian Yun-Na.An Intercell scheduling approach using shuffled frog leaping algorithm and genetic programming.Acta Automatica Sinica,2015,41(5):936−948(贾凌云,李冬妮,田云娜.基于混合蛙跳和遗传规划的跨单元调度方法.自动化学报,2015,41(5):936−948)
19 Liu Zhao-He,Li Dong-Ni,Wang Le-Heng,Tian Yun-Na. An inter-cell scheduling approach considering transportation capacity constraints.Acta Automatica Sinica,2015,41(5):885−898(刘兆赫,李冬妮,王乐衡,田云娜.考虑运输能力限制的跨单元调度方法.自动化学报,2015,41(5):885−898)
20 Yang T,Kuo Y,Cho C.A genetic algorithms simulation approach for the multi-attribute combinatorial dispatching decision problem.European Journal of Operational Research,2007,176(3):1859−1873
21 Huang K L,Liao C J.Ant colony optimization combined with taboo search for the job shop scheduling problem.Computers&Operations Research,2008,35(4):1030−1046
22 Montgomery D C.Design and Analysis of Experiments(6th Edition).New York:John Wiley&Sons,2005.

田云娜北京理工大学计算机学院智能信息技术北京市重点实验室博士研究生,延安大学数学与计算机科学学院讲师.主要研究方向为进化计算与智能优化方法.E-mail:ydtianyunna@163.com
(TIAN Yun-NaPh.D.candidate at the Beijing Key Laboratory of Intelligent Information Technology,School of Computer Science,Beijing Institute of Technology and lecturer at the College of Mathematics and Computer Science,Yan'an University.Her research interest covers evolutionary computation and intelligent optimization approaches.)

李冬妮北京理工大学计算机学院智能信息技术北京市重点实验室副教授.主要研究方向为智能优化方法及其在制造业的应用.本文通信作者.E-mail:ldn@bit.edu.cn
(LI Dong-NiAssociate professor at the Beijing Key Laboratory of Intelligent Information Technology,School of Computer Science,Beijing Institute of Technology.Her research interest covers intelligent optimization approaches and their applications to the manufacturing industry.Corresponding author of this paper.)

刘兆赫北京理工大学计算机学院智能信息技术北京市重点实验室硕士研究生.主要研究方向为进化计算和生产调度.E-mail:719042341@qq.com
(LIU Zhao-HeMaster student at the Beijing Key Laboratory of Intelligent Information Technology,School of Computer Science,Beijing Institute of Technology.His research interest covers evolutionary computation and production scheduling.)

郑 丹北京理工大学计算机学院智能信息技术北京市重点实验室硕士研究生.主要研究方向为进化计算和生产调度.E-mail:zhengdan04@163.com
(ZHENG DanMaster student at the Beijing Key Laboratory of Intelligent Information Technology,School of Computer Science,Beijing Institute of Technology.Her research interest covers evolutionary computation and production scheduling.)
A Hyper-heuristic Approach with Dynamic Decision Blocks for Inter-cell Scheduling
TIAN Yun-Na1,2LI Dong-Ni1LIU Zhao-He1ZHENG Dan1
In this paper,the inter-cell scheduling problem with a transportation capacity constraint is analyzed.An ant colony optimization(ACO)-based hyper-heuristic with dynamic decision blocks is proposed,which selects appropriate heuristic rules for production and transportation simultaneously.On the basis of traditional hyper-heuristics,a dynamic decision block strategy is proposed,in which several entities are grouped into a decision block under the guidance of pheromones,and appropriate heuristic rules are selected for each decision block.Comparisons between the proposed method and other hyper-heuristics with different decision block strategies are conducted.Computational results show a satisfying performance of the proposed method in minimizing total weighted tardiness with less computational costs.
Dynamic decision block,hyper-heuristic,ant colony optimization(ACO),inter-cell scheduling
Manuscript June 25,2015;accepted December 28,2015
10.16383/j.aas.2016.c150402
Tian Yun-Na,Li Dong-Ni,Liu Zhao-He,Zheng Dan.A hyper-heuristic approach with dynamic decision blocks for inter-cell scheduling.Acta Automatica Sinica,2016,42(4):524−534
2015-06-25录用日期2015-12-28
国家自然科学基金(71401014)资助
Supported by National Natural Science Foundation of China(71401014)
本文责任编委赵千川
Recommended by Associate Editor ZHAO Qian-Chuan
1.北京理工大学计算机学院智能信息技术北京市重点实验室 北京1000812.延安大学数学与计算机科学学院延安716000
1.Beijing Key Laboratory of Intelligent Information Technology,School of Computer Science,Beijing Institute of Technology,Beijing 1000812.College of Mathematics and Computer Science,Yan'an University,Yan'an 716000
