基于BIRCH大数据聚类方法在证券业的个性化服务
2016-11-08枫苑博赵文瑜冯必成侯
俞 枫苑 博赵文瑜冯必成侯 秦
基于BIRCH大数据聚类方法在证券业的个性化服务
俞 枫1苑 博2赵文瑜3冯必成4侯 秦5
本文以客户细分、客户聚类为切入点,为证券企业对客户适当性服务与分类管理提供技术支持。第一,本文提出了一种适用于大数据集的组合聚类方法:BIRCH方法。其通过构建CF(聚类特征)树层次,实现对数据的压缩。第二,本文针对证券交易记录数据,从年度换手率,年度持仓率,年度持股时长等的特征提取算法。通过记录证券交易数据提取出可多方面描述客户状态的动态属性,可增加证券企业对客户的识别。并根据这些动态属性进行聚类,其结果可为证券企业探求不同客户的、最具偏好的针对性需求作支撑。
BIRCH方法;大数据;特征提取;证券交易
一、背景分析和问题提出
(一)背景分析
金融体制在中共“十八大”提出,将作为未来十年发展改革的重点。《中国大数据技术与产业发展白皮书(2013)》于2013年,中国计算机学会发布,其指出:“未来中国的金融企业将构建智慧型、智能型的数据分析体系,充分挖掘其中的规律,从而支持业务创新与服务创新。”我国各金融企业如今都制定了“十二五”发展规划,其中,最核心的指导思想和目标是以科技引领创新。未来几年,我国的金融行业在“大数据”时代下的转型主要集中在三大方面:(1)、根据巴塞尔协议和第二代偿付能力等的要求,建立全面的风险管理体制,向严监管转型,“大数据”能够加强风险的可审性和管理力度;(2)、企业管理模式从粗放式向精细化、集约化转型,并且将信息化重点从业务信息化向管理信息化转变。“大数据”能够支持精细化管理;(3)、企业工作中心从“以利润为中心”和“以保单为中心”向“以客户为中心”转型,“大数据”为服务创新提供“原料”支持,通过数据挖掘等技术可以更好地实现“以客户为中心”理念,通过对客户消费的行为模式进行分析,提高客户转化率,针对不同用户开发不同的、与之匹配的产品,以满足客户个性化市场需求,从而实现差异化竞争。我国金融三大支柱产业中,证券行业是与“大数据”粘合度最高的支柱产业,凭借其较高的信息化起点和较快的业务发展速度,其现已实现了交易撮合、价格生成发布的自动化和集中化。随着信息科技、互联网等技术的发展,证券行业的信息系统在发布、交易、结算、信息披露、技术监控、信息咨询与服务等方面已经逐渐完善。在“大数据”时代,互联网金融模式不仅可以大幅度削减交易的成本,还可以降低信息挖掘处理的成本。此外,证券企业的客户信息将逐渐成为新的资产和为客户提供个性化服务的原材料。
(二)问题提出
如今,我国证券行业,正由规模、佣金等两方面的竞争,逐步转向以资讯、产品、交易渠道等三方面的服务竞争,这势必将成为证券行业发展的大趋势。并且,这对我国证券行业的竞争格局产生较为深远的影响。这无疑对现有证券企业的管理体制是一次从头到脚的颠覆式改革。客户对证券企业的需求提升主要在信息资讯和投资咨询两方面体现。部分证券企业开始推出点对点服务、定期股评报告会等服务。但大多数证券企业推出新服务时,是以交易量为服务推出的动力源。
现在,证券行业已从传统的新增客户竞争,转向定量客户的巩固和持续。尽管佣金仍成为客户选择证券企业的关键因素,但越来越多的客户开始关注证券企业的个性化服务。
(三)本文主要研究内容及意义
第一,从“大数据时代”到来的关键要素的视角,阐述“证券业大数据”的由来,展示了业界和学术界内较为突出的“证券业大数据”研究成果和应用。并介绍“证券业大数据”的数据结构和数据特点。本文在聚类分析方法方面的主要研究对象是BIRCH方法。BIRCH方法是由Zhang、Ramakrishnan、Linvy提出的组合(多阶段)层次聚类方法。BIRCH方法通过CF(聚类特征)来刻画、概括一个簇,形成CF树。CF树可以在信息量没有较多损失的前提下,“压缩”聚类的层次结构。其次,再通过其它各类聚类方法对CF树的叶结点进行聚类,把稀疏的簇当做异常点剔除,把稠密的簇合并成更大的簇。并将第二阶段(宏聚类阶段)的聚类结果还原到第一阶段(微聚类阶段)的输入数据对象(观测)上,从而实现完成的聚类分析。该方法具有伸缩性强、储存空间小、抗异常数据干扰能力强等特点,且其在大数据集仍保持优良的有效性。在Zhang、Ramakrishnan、Linvy的基础上,大多数学者对BIRCH方法的衍生研究主要集中于BIRCH微聚类阶段:(1)阈值动态更新机制;(2)CF树结点分裂技术(3)混合型属性数据集处理。
二、BIRCH算法
(一)Birch算法的主要思想
Birch算法通过扫描数据库,建立一个初始存放于内存中的聚类特征树,然后对聚类特征树的叶结点进行聚类。它的核心是聚类特征(CF)和聚类特征树(CFTree)。CF是指三元组CF=(N,LS,SS),用来概括子簇信息,而不是存储所有的数据点。其中:N:簇中D维点的数目;LS:N个点的线性和;SS:N个点的平方和。
在BIRCH算法中用到了两个重要的知识:聚类特征(CF)和CF-Tree聚类特征CF是一个三元组,其中N表示子集内点的数目;和是与数据点同维度的向量,是线性和,是平方和。
(二)BIRCH算法的过程
把待分类的数据插入一棵树中,并且原始数据都在叶子节点上。这棵树看起来是这个样子:

在这棵树中有3种类型的节点:Nonleaf、Leaf、MinCluster,Root可能是一种Nonleaf,也可能是一种Leaf。所有的Leaf放入一个双向链表中。每一个节点都包含一个CF值,CF是一个三元组是与数据点同维度的向量,是线性和,是平方和。
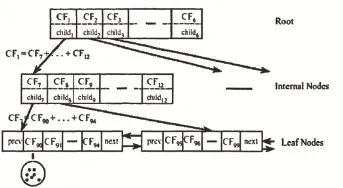
之后是插入过程,插入是从CF-Tree根节点开始的
(1)从数据库中读取第一条数据,用这条数据构造一个叶子节点和一个子簇,子簇就包含在叶子节点中
(2)当读到后面的第2,第3条数据时,需要加入判断,这个时候就要用到关键的参数B和T,如果新插入的这条数据符合已经存在的叶子节点,则将他封装为一个簇,加入到该叶子节点中,这里判断符合不符合的标准就是根据阈值T判断的,如果加入该叶子节点使得半径超过T,则需要新建簇作为该节点的兄弟节点,如果作为兄弟节点,其叶子节点的孩子节点超过B,则需要对叶子节点进行分裂,分裂的规则是选出簇间距离最大的二个孩子,分别作为二个叶子,然后其他的孩子按照就近分配。非叶子节点的分裂规则同上。
(3)最终的构造模样大致如此:
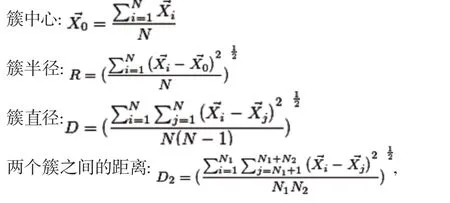
簇中心、簇半径、簇直径以及两簇之间的距离D0到D3都可以由CF来计算:
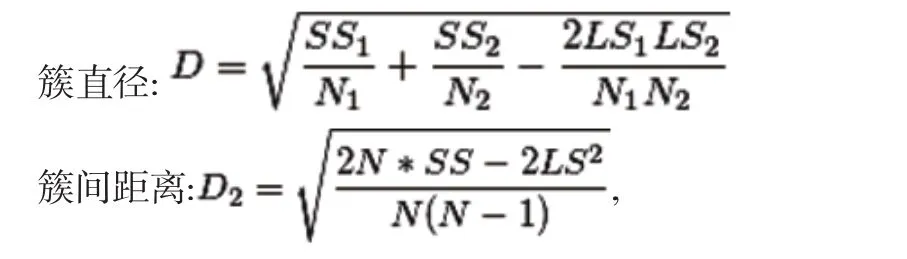
这里的N,LS和SS是指两簇合并后大簇的N,LS和SS。所谓两簇合并只需要两个对应的CF相加那可
CF1+CF2=(N1+N2,LS1+LS2,SS1+SS2)
每个节点的CF值就是其所有孩子节点CF值之和,以每个节点为根节点的子树都可以看成是一个簇。
Nonleaf、Leaf、MinCluster都是有大小限制的,Nonleaf的孩子节点不能超过B个,Leaf最多只能有L个MinCluster,而一个MinCluster的直径不能超过T。
(三)算法流程
BIRCH算法流程分为四个阶段,如下图所示:
三、基于BIRCH算法的证券客户细分
基于BIRCH算法的证券客户细分,在我国证券行业发展的初期,证券市场一直是个“买方’市场。这意味着客户主动找证券企业来寻求投资,而不需要证券企业去挖掘客户。这是造成证券企业不重视客户服务的原因之一。随着我国证券市场的发展,证券企业不断涌现,导致了证券企业之间相互竞争客户资源的现象。而我国证券市场也逐步由一个“买方”市场逐步转入到了一个“卖方”市场,这意味着证券行业在与证券市场协调发展的同时,随着证券市场不断规范和成熟,逐渐从粗放式管理向精细化、集约化管理转变。此外,证券企业间的竞争程度也受市场行情影响。

本文主要讨论客户年度换手率,客户年度持仓率,客户年度持股时长,客户年度资金流动率。
(一)客户年度换手率的特征提取
客户年度换手率是指客户在该年度进行股票投资时交易金额占可支配金额的平均比例。本文用中位数作为集中趋势的代表,避免了异常数据的干扰。具体算法思路如下:算法:年度换手率输入:D:(各个对象、数据集)。输出:各个对象的年度换手率。方法:(1)将D按客户编号排序,将客户编号一致的对象提取出,并合成子集D;(2)REPEAT;(3)在第i个子集中,将交易日期先后顺序排序,在同一日期的对象里,再按交易序号先后排序;(4)根据交易类型,选出交易类型是买入股票的对象;(5)计算所选出的每个对象换手率=买入金额/(买入股票+后资金额);(6)在所选出的每个对象的换手率中,取换手率的中位数作为年度换手率。
(二)客户年度持仓率的特征提取
客户年度持仓率是指客户在该年度月末平均持仓率。其中,月末平均持仓率为月末持有股票资产占月末总资产的比例。本文用中位数作为集中趋势的代表,避免了异常数据的干扰。具体算法思路如下:算法:年度持仓率输入:D:(各个对象、数据集)。输出:各个对象的年度换手率。方法:(1)将D按客户编号排序,将客户编号一致的对象提取出,并合成子集D;(2)REPEAT;(3)在第i个子集中,将交易日期先后顺序排序,在同一日期的对象里,再按交易序号先后排序;(4)按交易日期,对象提取出来,并生成第k个子子集;(5)REPEAT;(6)按交易日期,生成第i个子子子集DIKi(i=1,2,…,12);(7)根据交易类型,选出交易类型是买入的对象;(8)计算交易类型是买入的所有对象的股数A的∑A。
(三)客户年度持股时长的特征提取
客户年度持股时长是指客户在该年度所卖出的股票的平均持有时间长度。本文用中位数作为集中趋势的代表,避免了异常数据的干扰。具体算法思路如下:算法:年度持股时长输入:D:(各个对象、数据集)。输出:各个对象的年度换手率。方法:(1)将D按客户编号排序,将客户编号一致的对象提取出,并合成子集d;(2)REPEAT;(3)在第i个子集中,将交易日期先后顺序排序,在同一日期的对象里,再按交易序号先后排序;(4)按交易日期,对象提取出来,并生成第j个子子集DIK(j=1,2,…,9);(5)根据交易类型,选出交易类型是买的对象;(6)客户的年度持股时长为各证券编号股票上的持股时长的中位数;(7)UNTIL所有年份的子子集计算结束;(8)UNTIL所有客户子集计算结束。
(四)客户年度资金流动率的特征提取
客户年度资金流动率是指客户在该年度资金流入、流出次数之和占交易总次数的比例。具体算法思路如下:算法:年度资金流动率输入:D:(各个对象、数据集)。输出:各个对象的年度换手率。方法:(1)将D按客户编号排序,将客户编号一致的对象提取出,并合成子集D;(2)REPEAT;(3)在第i个子集中,将交易日期先后顺序排序,在同一日期的对象里,再按交易序号先后排序;(4)计算对象个数n1;(5)根据交易类型,选出交易类型是资金流入的对象;(6)计算交易类型是资金流入的对象个数n2;(7)IF n2=0,THEN该年度资金流动率直接输入0;(8)根据交易类型,选出交易类型是资金流出的对象;(9)计算交易类型是资金流入的对象个数n3;(10)年度资金流动率=(n2+n3)/n1;(11)REPEAT所有年份子子集计算结束;(12)REPEAT所有客户子集计算结束。
[1]曾晓迪.一种基于 K-mediods 改进 BIRCH 的大数据聚类方法 2015.学位论文
[2]曾晓迪,石磊,李兴奇.基于非结构化数据的金融大数据分析方法介绍[J].泛亚金融.2014 年 11 月(创刊号):91-99.
[3]曾晓迪.基于灰色理论的区域宜居性模糊综合评价:以上海市交通便捷和区域宜居分析为例[J].云南财经大学研究生学刊,2014年第 1 期:91-109.
[4]王园.证券业客户细分模型构建及实证研究[J].上海管理科学,2012,34(2):30-35.
[5]刘静.基于数据挖掘的证券公司客户细分及其应用研究[D].同济大学,2008.
[6]李君锋.数据挖掘在证券业 CRM 中的应用研究[D].西安电子科技大学,2009.
[7]张效严,齐春莹.基于数据挖掘技术的证券客户分析系统[J].计算机应用,2008,28,369-375.
[8]陈农心,张效严.数据掘技术在证券分析系统的应用研究[J].计算机仿真,2010,27(10),301-305.
[9]熊淑华.数据挖掘技术在证券业 CRM 中的应用研究[D].南昌大学,2008.
[10]王圣明.数据挖掘在证券行业的应用[D].浙江工商大学,2008.
俞枫 男,1969年出生,上海国泰君安信息技术部经理,教授级高级工程师
苑博 男,1982年出生,上海国泰君安信息技术部大数据平台总监
赵文瑜 男,1966年出生,上海华东理工大学金融大数据联合研究中心
冯必成 男,1976年出生,上海华腾软件系统有限公司技术研发总监,高级工程师
侯秦 女,1969年出生,上海华腾软件系统有限公司市场主管,工程师
