一种基于条件相对平均熵的个性化推荐算法
2016-11-07吴柳陈萌石永革
吴柳,陈萌,石永革
(南昌大学 信息工程学院,江西 南昌 330031)
一种基于条件相对平均熵的个性化推荐算法
吴柳,陈萌,石永革
(南昌大学 信息工程学院,江西 南昌330031)
为了提高现有推荐算法的准确性,提出一种基于条件相对平均熵的个性化推荐算法.首先,采用加权的CNM算法构建复杂网络,挖掘该网络的社团结构,作为商品待推荐域;其次,利用条件互信息和条件相对平均熵生成有效的节点次序,以提升贝叶斯网络构建的准确性;然后采用K2算法学习贝叶斯网络,分析出用户的消费性格,并判断待推荐域中商品与消费性格的联系,向用户提供感兴趣和合理的推荐;最后,基于电信运营商的实际数据进行实证分析,验证了该算法的有效性.
条件相对平均熵;个性化推荐;消费性格;社团结构
电子商务个性化推荐的主要思路是基于各种相关关系进行推荐,如:商品关系、用户关系、用户与商品关系.它们严重依赖历史行为数据,即当相关关系间的联系缺乏时,无法通过相似度计算进行预测,出现数据稀疏性问题、冷启动问题,导致推荐准确性低,难以满足用户的推荐需求.如何从海量的消费数据中挖掘出用户感兴趣的资源,并精准的推荐给用户,成为个性化推荐研究的热点.许多学者对个性化推荐进行了深入研究,并提出了一些推荐算法.文献[1-3]分别针对评分数据稀疏、冷启动和浏览用户不提供推荐的问题,提出了一系列商品推荐算法,但相似度计算量大耗时多,不满足用户的实时推荐需求和准确性需求.文献[4-5]针对用户兴趣描述不准确的问题,提出了一种基于用户兴趣的、三维建模的个性化推荐算法,但用户兴趣模型的准确建立,严重依赖用户搜索行为数据.文献[6]通过构建用户之间的多维加权网络,提出此网络中的个性化推荐算法,有较高的查全率和准确率,但算法中的参数值不易确定,有待研究.文献[7-8]利用交易数据构建商品的复杂网络,提出了一种基于复杂网络社团发现的商品推荐方法,很好地解决推荐算法的冷启动、计算量大以及推荐结果覆盖度低的问题,但没有考虑到用户的消费性格,无法准确地推荐符合该消费需求的商品.文献[9]针对电子商务面临消费个性日益凸显,提出了一种基于消费性格的新商品推荐方法,通过判定新商品与其消费性格符合的程度,向用户提供感兴趣的推荐.
综上,文献[1-8]的个性化商品推荐方法侧重于对用户历史行为数据的浅层次分析,忽视了用户消费性格在商品推荐中的作用,从而导致推荐结果与用户的实际消费需求差异较大,例如,笔者通过对电信企业内部闲置资产交易行为的分析,发现当某用户的消费记录偏向经济实惠,向其推荐的资产却是多样性的.为此,本文基于文献[7]和文献[9]的研究,引入条件相对平均熵,提出了一种基于条件相对平均熵的个性化推荐算法,主要工作包括:1)根据用户历史交易数据,构建商品的复杂网络,采用加权的CNM算法在网络中发现和挖掘其社团结构,然后根据用户已购商品的所属社团,去获取相关用户的商品待推荐域;2)利用条件互信息和条件相对平均熵生成带权有向图,并构建最大权生成树,通过拓扑排序生成有效的初始节点次序作为K2算法的输入,然后采用K2算法学习贝叶斯网络,分析用户的消费性格;3)使用学习好的贝叶斯网络进行推理,判断用户待推荐域的商品与用户消费性格的联系,得到最终的商品推荐域;4)基于实际的企业资产数据进行实证分析,验证本文研究成果的有效性.
1 基于条件相对平均熵的个性化推荐算法
用户的消费性格是决定其消费行为的核心因素之一,同时用户的性格特点,也会体现在各自的消费活动中,形成各种各样的消费行为.按照消费态度角度的不同,消费性格[10]分为节俭型、自由型、保守型、怪癖型、顺应型5种类型.本文根据用户的购物记录,选用贝叶斯网络作为工具推断其消费性格.
1.1数据预处理
用户选购商品时,将关注商品属性,如价格、折扣、质量、外观等.有的属性对决策变量的影响显著,需要保留;有的属性对决策变量的影响不显著,可以忽略,因此需要对属性变量降维,排除不重要的商品属性.本文利用logistics多变量回归分析
(1)
当P≤0.05时,属性变量对消费性格有很大影响;但P>0.05时,该属性变量与消费性格无关,从而从属性变量X={X1,X2,…,X12}中找到构建贝叶斯网络结构所需的变量X={X1,X2,…,Xm},m≤12.
贝叶斯网络使用的数据是离散型的,对用户的购买行为数据的数值型数据进行离散化处理,见表1,其中消费性格是决策变量,其余为属性变量.
1.2算法描述
以下算法过程的基础:已经应用加权CNM算法完成社团发现,获取了相关用户的商品待推荐域.
1)任意2个节点之间依赖关系的大小可以通过节点间的条件互信息[11]表示,在给定离散随机变量C的条件下,如果节点Xi和xj节点的条件互信息值较大,说明2节点具有较强的相互依赖关系.
本文引入条件互信息计算降维后的属性变量之间依赖关系,生成表示节点间依赖关系的带权无向图,边的权值为条件互信息值.据用户购买历史记录,计算每对属性变量Xi与Xj之间的条件互信息I(Xi;Xj|Ck)
(2)
其中,i,j=1,2,…,m,i≠j,m≤12,k=1,2,…,5,Xi、Xj和C均为属性变量,P为概率,xi、xj和ck为样本中某商品在相应属性变量上的取值,i和j为相应的具体属性编号,k为相应的具体消费性格类型.

表1 购物行为数据的离散化处理
2)信息熵用于衡量一个随机变量Xi取值的不确定程度,定义为
(3)
当给定变量Xi,变量Xj的不确定性程度可以用条件熵表示,定义为
(4)
本文引入条件相对平均熵[12]判断2节点之间的依赖倾向,确定带权无向图中无向边的方向,生成表示节点间依赖关系的带权有向图,为下一环节确定节点的先后顺序做准备.计算每对属性变量Xi与Xj之间的条件相对平均熵crae(Xj→Xi)
(5)
其中,|Xi|表示Xi所有可能取值的个数.
如果crae(Xj→Xi)>crae(Xi→Xj),则边的方向设置为从Xj指向xi,即Xj→Xi;反之,则边的方向设置为从Xi指向Xj,即Xi→Xj.
3)构建最大生成树,确定K2算法的初始节点的输入次序:假定带权有向图G(V,E),初始最大生成树为T(V,D),边数D为空;将图G的边集合E按权值降序排列;从权值最大的边开始遍历每条边,直至边集合连通了所有节点集合V,得到最大生成树;利用拓扑排序对生成树中节点进行排序,确定初始节点次序.
4)构建贝叶斯网络结构:初始一个空网络,根据3)中确定的K2算法的节点顺序,采用CH评分函数和后验概率作为网络结构的评分函数,如公式(6)、(7),依次为每一个节点添加合适的父节点,其中,父节点只能从该节点顺序之前的节点集合中选出.根据式(6)确定节点间的依赖关系,当式(7)所得概率值最高时,在2节点之间增加1条有向边.当所有的有向边都确定时,就得到一个贝叶斯网络结构图.
(6)
(7)
其中,D是实例数据,Bs是网络结构.yl为Y中各变量的取值,v(yl)为yl父节点的取值,即概率大小;h为该节点的父节点的数量;Γ()为Γ函数;∂lhg为yl的第g态度,∂lh=∑∂lhg;Nlhg为v(yi)的第g态度,Nlh=∑Nlhg.
5)根据前述评分公式(7),获取分值最高的贝叶斯网络结构,以及对应的节点概率分布表.学习决策属性C的概率分布为P(Ck),该概率分布表示用户的消费性格情况,概率值大的消费性格类别即为该用户的主导消费性格,将对应的概率值作为商品推荐阈值ε.
6)离散化处理用户待推荐域中的商品数据,并作为贝叶斯网络的属性输入,得到待推荐域商品的消费性格分布,与设定的阈值进行比较.若得到的消费性格类型大于设定的阈值,则说明此商品符合用户的消费性格,将其推荐给用户;否则不予推荐,从而得到最终的商品推荐域.
2 实证分析
实证数据来源于某省电信公司,从2014年11月至4月份的闲置资产交易成功记录中随机抽取1万条数据,格式见表2.表2中,资产类、项、目、节属性依次细化地描述闲置资产的分类情况,资产ID确定闲置资产的唯一性,盘活时间表示闲置资产成功交易的时间.
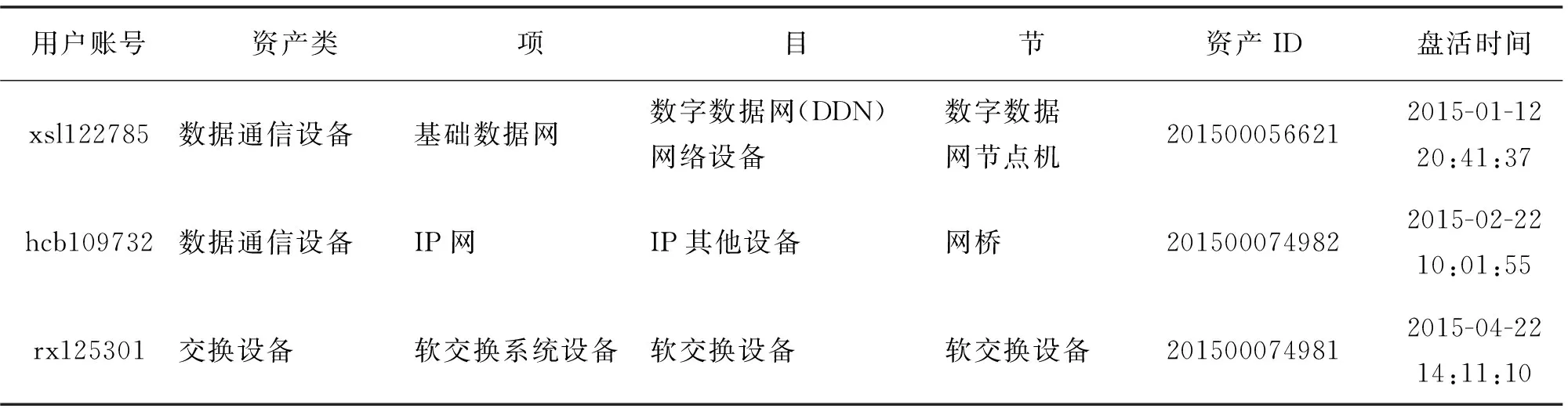
表2 闲置资产交易成功记录
1)统计所有用户成功交易的历史数据,根据文献[7]基于社团发现算法将其进行社团结构划分,可以看到每一个资产都归入某一个子社团中,图1为社团网络的部分图形.
账号为xsl122785的用户购买编号为1、4、8的资产,位于2个社团,合并这2个社团,发现资产1、4、8的共同邻接点集为{3,5},且边权重w1,3+w4,3+w8,3>w1,5+w4,5+w8,5,因而当前用户的商品待推荐域集合为{3,5}.
2)选取账号为xsl122785的用户的交易数据,利用SPSS进行logistics多变量回归分析,提取出对当前用户的消费性格有显著影响的属性变量,有:价格、折扣、质量、销量、新品、属地.
3)根据表1对xsl122785用户的交易数据进行离散化处理,计算降维后的属性变量间的条件互信息和条件相对平均熵,建立最大权生成树,如图2,利用拓扑排序得到贝叶斯网络K2算法的初始节点次序begin={消费性格,价格,属地,销量,折扣,新品,质量}.
4)通过初始节点次序begin构建评分值最高的贝叶斯网络,如图3,可以看到与消费性格直接相关的商品属性是价格、折扣和销量,其他间接关联.然后对该网络进行分析和学习,获取用户的消费性格概率分布,见表3.表中节俭型的概率值为0.498,所占的比例近50%,因而该用户的消费性格表现出节俭型的特点,同时将ε=0.498作为商品推荐的阈值.

图1 复杂网络的社团结构Fig.1 Community structure in complex networks
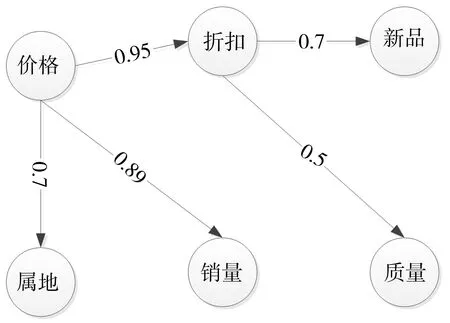
图2 最大权生成树Fig.2 Maximum spanning tree
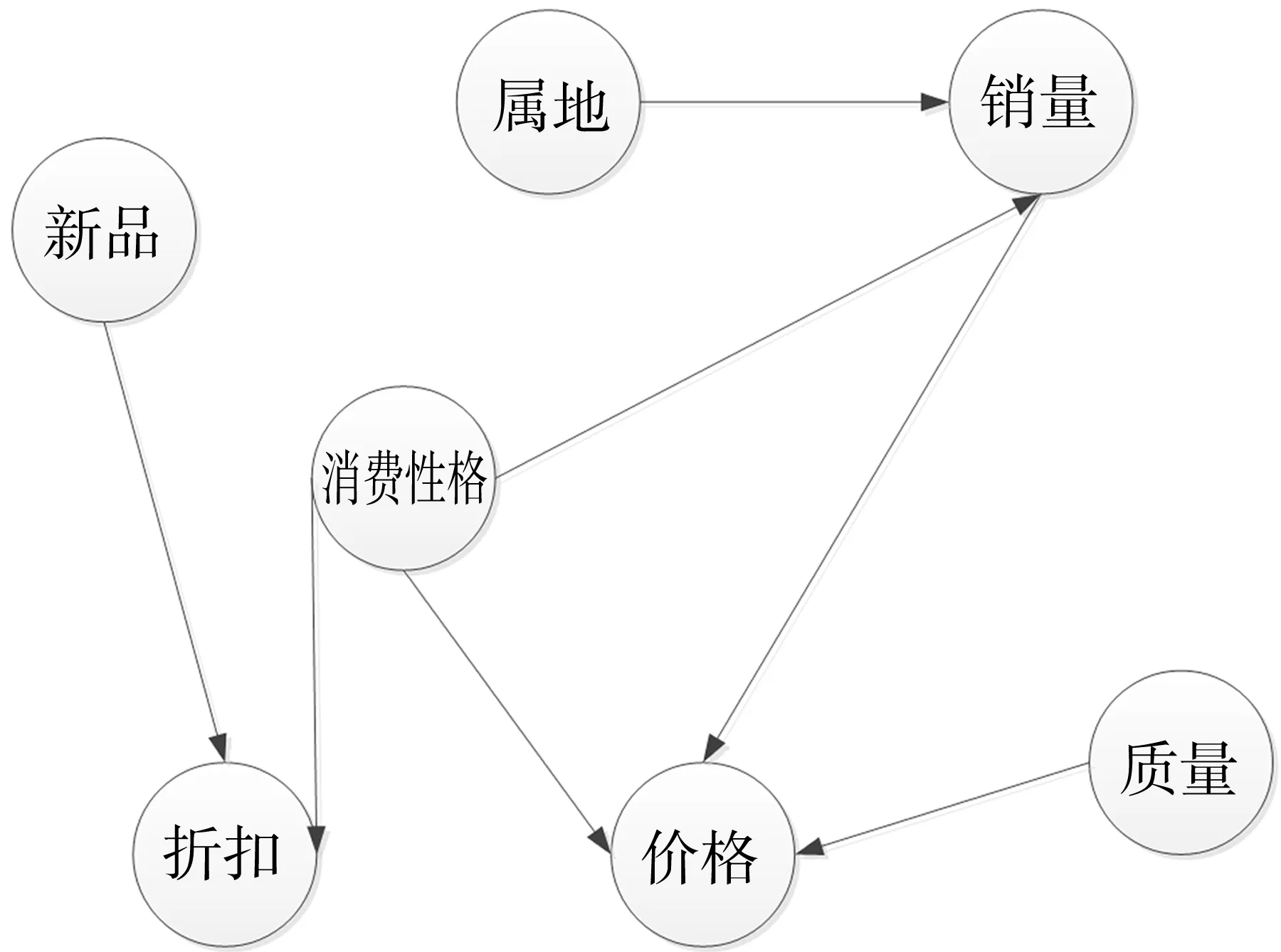
图3 xsl122785的贝叶斯网络结构Fig.3 Bayesian Network of xsl122785
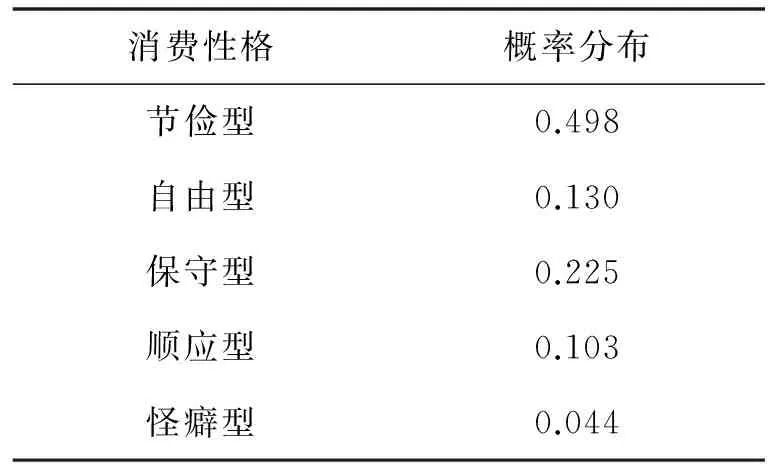
消费性格概率分布节俭型0.498自由型0.130保守型0.225顺应型0.103怪癖型0.044
5)在贝叶斯网络中输入1)中该用户商品待推荐域中各商品属性,获取对应的消费性格分布,见表4,得到该用户的商品最终推荐域.

表4 推荐结果
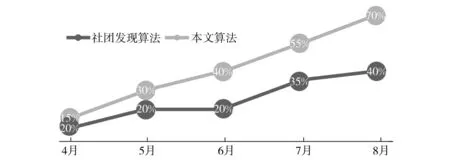
图4 本文算法与社团发现算法准确率比较Fig.4 Comparison of accuracy of this article and Community Detection
6)提取2015年5月至8月的闲置资产交易成功记录,验证该算法的合理性和有效性,如图4.从图4中可以看到,随着时间的变化,用户消费记录的增加,引入消费性格的基于条件相对平均熵的推荐算法和社团发现算法的推荐准确率均有所提高,但前者准确率增加的幅度明显高于后者,准确率也更高.
3 结束语
为了提高个性化推荐的准确性,本文综合考虑了用户的消费性格和商品的社团结构,提出了一种基于条件相对平均熵和消费性格分析的贝叶斯网络个性推荐算法,以历史交易数据为依据,借助贝叶斯网络分析消费性格,并以消费性格为纽带,确定社团发现后的推荐域,实现对用户的推荐,并基于实际数据验证了本文研究成果的有效性.
[1]邓爱林,朱扬勇,施伯乐.基于项目评分预测的协同过滤推荐算法[J].软件学报,2003,14(9):16-21.
DENG A L,ZHU Y Y,SHI B L.A collaborative filtering recommendation algorithm based on item rating prediction[J].Software Journal,2003,14(9):16-21.
[2]郭艳红,邓贵仕.协同过滤系统项目冷启动的混合推荐算法[J].计算机工程,2008,34(23):11-13.
GUO Y H,DENG G S.Hybrid recommendation algorithm of item cold-start in collaborative filtering system[J].Computer Engineering,2008.34(23):11-13.
[3]谢意,陈德仁,干红华.基于浏览偏好挖掘的实时商品推荐方法[J].计算机应用,2011,31(1):89-92. DOI:10.3724/SP.J.1087.2011.00089.
XIE Y,CHEN D R,GAN H H.Real-time recommendation method based on browsing preferences mining[J].Journal of Computer Application,2011,31(1):89-92.DOI:10.3724/SP.J.1087.2011.00089.
[4]王冰怡,刘杨,聂长新,等.基于用户兴趣三维建模的个性化推荐算法[J].计算机工程,2015,41(1):65-70.DOI:10.3969/j.issn.1000-3428.2015.01.012.
WANG B Y,LIU Y,NIE C X,et al.Personalized recommendation algorithm based on three-dimensional user interest modeling[J].Computer Engineering,2015,41(1):65-70.DOI:10.3969/j.issn.1000-3428.2015.01.012.
[5]LI J,ZHANG P.Mining explainable user interest from scalable user behavior data[J].Procedia Computer Science,2013,17:789-796.DOI:10.1016/j.procs.2013.05.101.
[6]张华青,王红,滕兆明,等.多维加权社会网络中的个性化推荐算法[J].计算机应用,2011.31(9):2408-2411.DOI:10.3724/SP.J.1087.2011.02408.
ZHANG H Q,WANG H,TENG Z M,et al.Personalized recommendation algorithm in multidimensional and weighted social network[J].Journal of Computer Application,2011,31(9):2408-2411.DOI:10.3724/SP.J.1087.2011.02408.
[7]卢丹,王君博,武森.电子商务中基于复杂网络社团发现的商品推荐研究[J].工业技术创新,2015,2(1):61-65.DOI:10.14103/j.issn.2095-8412.2015.01.013.LU D,WANG J B,WU S.Research on commodity recommendation in E-commerce based on community detection in complex networks[J].Industrial Technology Innovation,2015,2(1):61-65.DOI:10.14103/j.issn.2095-8412.2015.01.013.
XIE Z,WANG X F.An overview of algorithms for analyzing community structure in complex networks[J].Complex Systems and Complexity Science,2005,2(3):1-12.
[9]张光前,白雪.基于消费性格的新商品推荐方法[J].管理科学,2015,28(2):60-68.DOI:10.3969 /j.issn.1672-0334.2015.02.006.ZHANG G Q,BAI X.Method of new commodities recommendation based on consuming personalities[J].Journal of Management Science,2015,28(2):60-68.DOI:10.3969 /j.issn.1672-0334.2015.02.006.
[10]刘鲁蓉,孙顺根.消费心理学[M].北京:科学出版社,2007:5-9.
[11]SOTOCA J M, PLA F.Supervised feature selection by clustering using conditional mutual information-based distances[J].Pattern Recognition ,2010(43):2068-2081.DOI:10.1016/j.patcog.2009.12.013.
[12]JIANG J,WANG J Y,YU H,et al.Poison identification based on Bayesian network:a novel improvement on K2 algorithm via Markov blanket[J].Advances in Swarm Intelligence,2013,7929:173-182.DOI:10.1007/978-3-642-38715-9_21.
(责任编辑:孟素兰)
A personalized recommendation algorithm based on conditional relative average entropy
WU Liu,CHEN Meng,SHI Yongge
(Information and Engineering School,Nanchang University,Nanchang 330031,China)
In order to improve the accuracy of recommendation algorithm,one personalized recommendation algorithm based on conditional relative average entropy is presented.First of all,through weighted CNM algorithm we construct complex network and excavate the network’s community structure. The result is regarded as the uncertain recommendation domain. Further more ,conditional mutual information and conditional relative average entropy are used to determine the effective node ordering as input of K2 algorithm,which can improve the accuracy of Bayesian network construction,and then learn Bayesian network by K2 algorithm and analyze the consumer characteristics. We use the relationship between the commodity and the consumer characteristics to confirm the recommendation domain.Finally,the empirical analysis of the actual data of the telecom operators is carried out to verify the validity of the above algorithm.
conditional relative average entropy;personality recommendation;consumer characteristics;community structure
10.3969/j.issn.1000-1565.2016.04.017
2015-11-17
国家自然科学基金资助项目(61163005)
吴柳(1991—),女,江西萍乡人,南昌大学在读硕士研究生,主要从事数据挖掘、算法分析研究工作.
E-mail:1203414419@qq.com
陈萌(1977—),男,江西南昌人,南昌大学副教授,主要从事计算机网络、数据挖掘方向研究.
E-mail:chengmeng@ncu.edu.cn
TP391
A
1000-1565(2016)04-0438-06
