微博网络中基于社区的分布式协同过滤推荐*
2016-11-07荆笑鹏刘京菊
荆笑鹏 刘京菊
(电子工程学院 合肥 230037)
微博网络中基于社区的分布式协同过滤推荐*
荆笑鹏刘京菊
(电子工程学院合肥230037)
为实现可以应用于微博网络中大规模数据的话题推荐,提出一种基于社区的分布式协同过滤推荐算法。定义了微博中用户对话题评分的含义,包含了常见的用户对微博的操作类型。在社区的基础上针对有无历史数据提出两种预测评分的计算方法,对不同的用户类型采用不同的推荐策略。以社区为单位设计粗粒度的分布式结构,在具体的计算过程中,应用MapReduce架构进行细粒度的分布式计算,在提高了算法效率的同时,增加了推荐话题的覆盖度。实验结果表明,该算法具有一定的实际应用价值。
社区; 分布式算法; 协同过滤; 用户相似度
Class NumberTP391
1 引言
有许多方法可以实现个性化推荐,这些方法可以分为:基于内存的方法、基于协同过滤的方法和混合方法。传统的基于协同过滤的方法将用户的评价历史作为预测用户对项目兴趣大小的基础。然而,这种方法存在以下问题: 1) 需要其他用户对推荐项目的评分作为参考。 2) 具有较高的复杂度,无法适应大规模的数据 3) 冷启动问题。即难以对新用户产生合适的推荐。
针对上述问题,本文提出一种基于社区的协同过滤推荐算法。与传统的推荐算法不同,这种算法利用社会网络中用户的社区结构做出推荐,社会网络中用于划分社区结构的方法是基于相似度的社区发现算法。本文的主要贡献是: 1) 引入一种以用户的社会网络和用户-话题评分数据作为基础计算得到的预测评分矩阵; 2) 提出一种大规模微博网络数据条件下的分布式协同过滤推荐算法; 3) 使用Twitter数据集评估这种算法的效果。
2 相关工作
协同过滤推荐方法的主要思想是,利用已有用户群过去的行为或意见预测当前用户最可能喜欢哪些项目。通常,协同过滤方法可以分为以下三种:
1) 基于内存的协同过滤。基于内存的协同过滤[1]使用全部的用户-项目数据集,用评分矩阵来存储相应的数据,根据评分矩阵产生相应的推荐。这种方法可以分为两种:即基于用户的协同过滤[2]和基于项目的协同过滤[3]。
2) 基于模型的协同过滤。基于模型的协同过滤从训练数据中识别和抽取一些用于推荐的复杂模式,然后选择合适的模式对测试数据或是真实世界的数据执行协同过滤推荐。基于模型的协同过滤推荐包括潜在语义模型模型[4]、马尔科夫模型[5]和矩阵分解模型[6]等。
3) 混合协同过滤。混合推荐模型[7]通常将协同过滤推荐和其他推荐方法组合使用,目的在于克服协同过滤推荐的问题,提高预测和推荐的可扩展性和质量。混合协同过滤通常分为两部分:第一部分对数据进行预处理;第二部分设计不同推荐方法的组合规则。
3 微博网络中基于社区的分布式协
同过滤推荐算法
3.1基于相似度的社区发现算法
本文所使用的基于相似度的社区发现算法是基于局部模块度进行优化,与使用全局模块度相比,大大减小了时间复杂度,能够花费较少的时间,有效地计算出大规模社会网络的社区结构。模块度表示的是社区结构是随机产生的可能性,模块度越大,说明社区的聚合度越高,社区结构越明显。
3.2相关定义
在微博网络中,没有用户对话题、事件的评分功能,用户能够进行的操作是发布一个状态或者一个话题,或者对好友发布的状态或者是话题进行评论或者转发。Carmagnola等[8]提出用户关注的话题或采取的操作,能够体现出社区结构对当前用户节点的影响,而吸引用户的话题和事件能够增加用户之间的交流次数。用户在微博网络中的操作类型和操作次数代表了用户的个性和关注的热点。因而,通过对用户的操作类型和操作次数的量化分析,可以得到与用户-项目评分矩阵类似的评价矩阵。在此基础上,应用协同过滤的推荐算法,能够获得用户最关心的话题或者事件。

(1)
其中,Operation(u,m)表示u对m所做的操作类型,N(ou,m)表示操作类型ou,m的次数。
3.3基于社区的协同过滤推荐策略
1) 两种预测评分的计算方法
对于新用户,由于没有足够的信息支撑传统的协同过滤推荐算法,因此会产生冷启动问题[9]。这种情况下,如果用户有社会网络的信息,就可以通过抽取用户的社区结构信息帮助实现推荐。例如,对于金融圈中新加入的一个人而言,如果这个人经常活跃于微博网络,那么就可以利用其微博的社会网络信息产生一些关于金融的话题推荐。我们认为一个人的喜好和他的朋友是相似的,或者容易受到他的朋友的影响。使用基于相似度的社区发现算法划分图G的社区结构,得到{C1,C2,…,Ck}表示得到k个社区。下一步将根据式(1)计算得到的用户-话题评分数据按照社区进行划分,如果一个用户属于社区Ci,那么这个用户对话题的所有评分都被划分到社区Ci中。然后,针对不同的用户使用不同的方法计算预测评分矩阵。

(2)
另一个预测评分矩阵使用基于用户的协同过滤算法,社区Ci中,用户a和b的相似度可以用式(3)来表示。
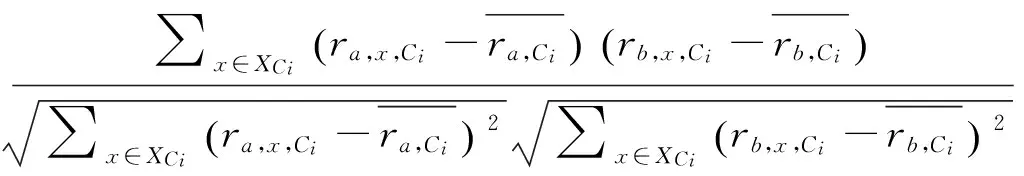
(3)

(4)
其中,sim(d,c,Ci)表示社区Ci中用户c和d的相似度。
2) 面向新用户的推荐策略
对于一个没有相关话题评分的新用户v,推荐策略分为以下三步:(1)寻找用户v所属的社区C。(2)在社区C中,按照式(2)计算话题的预测评分矩阵pv(C)。(3)对不同话题的评分结果进行排序,将评分结果最高的N个话题推荐给用户v。
3) 面向历史用户的推荐策略
在面向历史用户推荐的时候,一方面,使用式(2)计算得到的话题预测评分进行推荐,推荐一些这些用户没有谈论过的话题,提高推荐话题的覆盖度;另一方面,使用式(4)计算得到的话题预测评分进行推荐,获得更加精确的推荐结果。对于在社区C中的用户u,对话题z的评分预测值按照下式计算:
p(u,z,C)=λpv(u,z,C)+(1-λ)pcu(u,z,C)
(5)
其中,0≤λ≤1,本文中,λ的取值为0.5。对按照式(5)计算出的不同话题的评分预测值进行排序,将评分结果最高的N个话题推荐给用户u。
3.4算法过程
本文提出的分布式协同过滤推荐算法基于以下假设:每个社区之间是相互独立的。本文的算法可以同时运行k个作业,每个作业对应一个社区,有不同的输入数据。本文算法的完整计算过程如图1所示。

图1 基于社区的分布式协同过滤推荐算法流程
本文算法包含三个主要的计算过程: 1) 计算社区C中话题的平均评分; 2) 计算社区C中的用户相似度; 3) 计算社区C中用户对话题的评分。算法的分布式结构通过MapReduce架构实现。
1) 计算社区C中话题的平均评分
此过程用户-话题评价数据用三元组〈u,x,pu,x,C〉表示,即社区C中用户u对话题x的评分是pu,x,C,这种表示方法可以克服用户-话题评价数据的稀疏性。话题的平均评分定义如式(6)所示。
(6)
其中,m表示社区C中,对话题有评分记录的用户的个数,计算得到的结果可以用二元组〈x,pv(x,C)〉表示。使用MapReduce实现话题平均评分的过程如下:Mapavg使用用户-话题评价数据〈u,x,pu,x,C〉作为输入,把话题x当作key,把评分pu,x,C当作value,消除了数据中关于用户的部分,使得相同话题的数据被重组到同一台机器。Reduceavg使用话题和与话题对应的评价数据计算每个话题的平均评价值,输出话题和其平均评价值〈x,pv(x,C)〉。
2) 计算社区C中的用户相似度
此过程使用MapReduce实现用户相似度计算的过程如下:Mapsim1使用用户-话题评价数据〈u,x,pu,x,C〉作为输入,把话题作为key,用户和评分的二元组〈u,pu,x,C〉作为value,使得所有属于同一话题的数据被重组到同一台机器。Reducesim1把社区C中每个话题的〈u,pu,x,C〉作为输入,输出此话题的所有评分项〈u,pu,x,C〉。Mapsim2使用Reducesim1的输出作为输入,即〈x,list(u,pu,x,C)〉,移除话题部分,输出时把用户对作为key,对应的评分对序列作为value,输出的用户对是评价了同一话题的。将用户对作为key使得那些同时评价了相同话题的所有用户被重组到同一台机器。Reducesim2的输入将用户对作为key,对应的评分对序列作为value。Reducesim2计算用户之间相似度,输出时将用户对作为key,将用户对的相似度作为value,即〈u1,u2,sim(u1,u2,C)〉。
3) 计算社区C中用户对话题的评分
此过程同时使用用户-话题评价数据和上一过程得到的用户之间的相似度数据,具体计算过程如下:Mapp1把〈u,x,pu,x,C〉和〈u1,u2,sim(u1,u2,C)〉作为输入,输出时将用户作为key,使得同一用户的所有数据被重组到同一台机器。Reducep1使用用户和其对应的〈x,pu,x,C〉序列或者〈u2,sim(u1,u2,C)〉序列作为输入数据,输出〈u1,x,pu,x,C,list(u2,sim(u1,u2,C))〉,这里的u2是与u1相似的用户。Mapp2的输出以用户作为key,Reducep2的输入以用户为key,以话题、相似用户对的所有评分和用户之间的相似度作为value,即〈x,pu,x,C,list(u2,sim(u1,u2,C))〉。Reducep2对用户没有评分的话题计算评分预测值,输出〈u,x,pcu(u,x,C)〉。
4 实验与结果分析
本文实验使用真实的Twitter网络数据集来检验提出的算法的效率和有效性。Twitter数据集来自于斯坦福大学公开的用于学术研究的数据集(snap.stanford.edu/data/),实验使用这个数据集中2000个用户和323000条Tweets,其中每条Tweets包含作者id、时间和内容,Tweets类型包括发表、评论和转发。实验使用三台配置为IntelCorei7-4770的处理器和8GB内存的台式计算机上,每台机器上配置运行单核心,内存为2G的虚拟机,运行CentOS操作系统。
为检验分布式算法的执行性能,实验使用加速比[10]作为评价算法并行运行性能的指标。其定义如下:
(7)
其中,Ts表示单个核心的处理器顺序执行算法所花费的时间,Tp表示p个核心的处理器并行运行算法所花费的时间。实验结果如图2所示,结果显示随着并行的节点的数量增加,加速比同时在增加,增加程度低于理想情况,主要原因在于经过划分得到的社区结构不均衡。图3显示的是本文算法与基于用户的协同过滤推荐算法(对比算法)的运行时间。可以看出,本文算法的运行时间远远低于基于用户的协同过滤推荐算法。

图2 本文算法的加速比

图3 基于用户的协同过滤推荐算法(对比算法)与本文算法的运行时间
为检验分布式算法的推荐话题的多样性,实验使用覆盖度[11]作为评价指标,其定义如下:
(8)
其中,No表示可供推荐的话题的数量,Ns表示预测推荐话题的数量。图4显示本文算法与基于用户的协同过滤推荐算法(对比算法)在不同实验次数的条件下,所产生的话题覆盖度。可以看出,在将微博网络划分为社区和综合使用两种预测方法的情况下,本文算法具有相对较高的话题覆盖度。

图4 基于用户的协同过滤推荐算法(对比算法)与本文算法的话题覆盖度
5 结语
本文在分析了微博中的各类操作后,定义了用户对话题评分的计算方法。为解决传统协同过滤推荐算法具有冷启动和较低的时间效率的问题,本文提出了微博网络中基于社区的分布式协同过滤推荐算法。针对冷启动问题,本文算法综合使用两种话题评分预测方法,在缓解冷启动问题的同时,提高了推荐话题的覆盖率。针对时间效率的问题,本文算法结合MapReduce的框架,提出一种分布式的协同过滤推荐算法,最后实验表明,本文算法在实际网络上运行时,在冷启动问题和时间效率问题上表现出了良好的性能。
[1] 赵琴琴.基于内存的协同过滤推荐算法研究[D].北京:中国科学院研究生院,2011.
ZHAO Qinqin. Research on memory based collaborative filtering recommendation algorithm[D]. Beijing: University of Chinese Academy of Sciences,2011.
[2] Zhao Z D, Shang M S. User-based collaborative-filtering recommendation algorithms on hadoop[C]//Knowledge Discovery and Data Mining, 2010. WKDD’10. Third International Conference on. IEEE,2010:478-481.
[3] Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web. ACM,2001:285-295.
[4] Hofmann T. Latent semantic models for collaborative filtering[J]. ACM Transactions on Information Systems (TOIS),2004,22(1):89-115.
[5] Sahoo N, Singh P V, Mukhopadhyay T. A Hidden Markov Model for Collaborative Filtering[J]. Ssrn Electronic Journal,2010,36(4):1329-1356.
[6] Pirasteh P, Hwang D, Jung J J. Exploiting matrix factorization to asymmetric user similarities in recommendation systems[J]. Knowledge-Based Systems,2015,83:51-57.
[7] Fiasconaro A, Tumminello M, Nicosia V, et al. Hybrid recommendation methods in complex networks[J]. Physical Review E,2015,92(1):012-811.
[8] Carmagnola F, Vernero F, Grillo P. SoNARS: A Social Networks-Based Algorithm for Social Recommender Systems[J]. User Modeling Adaptation & Personalization,2009,5535:223-234.
[9] Fatemi M, Tokarchuk L. A Community Based Social Recommender System for Individuals & Groups[C]//Social Computing(Social Com), 2013 International Conference on. IEEE,2013:351-356.
[10] Jiang J, Lu J, Zhang G, et al. Scaling-Up Item-Based Collaborative Filtering Recommendation Algorithm Based on Hadoop[C]//Proceedings of the 2011 IEEE World Congress on Services. IEEE Computer Society,2011:490-497.
[11] Ge M, Delgado-Battenfeld C, Jannach D. Beyond accuracy:evaluating recommender systems by coverage and serendipity[C]//Proceedings of the fourth ACM conference on Recommender systems. ACM,2010:257-260.
Community Based Distributed Collaborative Filtering Recommendation in Microblog Network
JING XiaopengLIU Jingju
(Electronic Engineering Institute, Hefei230037)
To better meet the application requirements of topics recommendation in large-scale microblog network data,this paper proposed a community based distributed collaborative filtering recommendation algorithm. The algorithm defines the meaning of the topic of user rating in the microblog,containing the common users operation type in the microblog. The algorithm proposes two calculation methods of predictions ratings for the presence or absence of historical data on the basis of the community. These allow for different types of users with different recommended strategies. The algorithm designs coarse-grained distributed architecture on the basis of communities and applies fine-grained distributed architecture of the MapReduce. It improves the efficiency of the algorithm,while increasing the coverage of recommended topics. Experimental results show that the algorithm has some practical value.
community, distributed algorithms, collaborative filtering, users similarity
2016年4月7日,
2016年5月26日
荆笑鹏,男,硕士研究生,研究方向:数据挖掘,网络安全。刘京菊,女,硕士,副教授,研究方向:数据挖掘,网络安全。
TP391
10.3969/j.issn.1672-9722.2016.10.025
