电力系统实时仿真中细粒度并行实现
2016-11-05张炳达
王 潇,张炳达,陈 雄
(天津大学智能电网教育部重点实验室,天津 300072)
电力系统实时仿真中细粒度并行实现
王 潇,张炳达,陈 雄
(天津大学智能电网教育部重点实验室,天津 300072)
为充分利用FPGA的高度并行特性,设计了一种可实现加减乘除混合运算的变结构运算组件.从实用性和扩展性角度出发,用控制指令描述对运算组件的操作,用有向无环图描述计算任务之间的依赖关系,提出了一种新的基于FPGA的仿真程序设计方法.在此基础上,以30,μs仿真步长在一块5SGSMD5芯片上实现了IEEE-14电力系统的实时仿真,其实验结果与PSCAD仿真结果相吻合.
实时仿真;细粒度;现场可编程门阵列;变结构运算组件
在新能源变革形势下,智能电网已成为承担电网新使命的新一代电网.在推进智能电网的建设中,复杂控制设备的在环测试对实时数字仿真器的仿真规模和仿真步长提出了更高的要求.
传统的实时数字仿真通常将计算任务分解成许多子任务,由多个处理器协同完成[1].然后,在集群环境中,全局共享数据必须依靠机器间的通信来搬迁[2];在多核环境中,全局共享数据需要采用锁保护[3]. 正由于这一特点,常采用粗粒度并行处理技术对计算任务进行分解.文献[4]将多区戴维南等值方法用于电气网络的并行计算,且设法减少数据同步过程的时间开销.文献[5]灵活应用节点分裂法、分布参数线路解耦法,提出了一种交直流分割并行算法.文献[6]提出了一种元件级并行和网络级并行相结合的并行求解算法,有效地提高了并行计算的总体效率.文献[7-8]在保证求解稳定性的基础上,分别利用显隐式混合积分法和异步替代法使网络解耦,提高了分网的灵活性.但是,经分解的计算任务在单个处理器内部仍需串行执行.
现场可编程门阵列(field programmable gate array,FPGA)拥有并行硬件结构,可实现高度并行的数值计算[9].近年来,FPGA逐渐在电力系统领域展示出高度并行的数值计算能力[10].文献[11]提出了一种基于FPGA的电磁暂态实时仿真器,在一片FPGA上仿真了含有15条传输线模型的电力系统.文献[12]针对有源配电网提出了基于FPGA的暂态实时仿真器的计算求解框架,并给出多个关键功能模块的硬件实现方式.文献[13-14]分别针对交流电机和变压器实时仿真提出了基于FPGA的并行实现方法. 文献[15]针对大规模电磁暂态实时仿真研究了多FPGA的仿真方案.这些文献都采用了功能化的设计思想,将发电机模型、稀疏矩阵求解模型、注入电流源求解模型等分别建立了并行化的硬件电路,其优点在于方便搭建新的应用,但是其硬件的资源利用率较低.
本文旨在硬件资源有限的前提下对实时仿真系统细粒度并行(运算级并行)的实现方法进行探索.为解决FPGA硬件资源有限,借助缓冲通道对运算器的输入输出口进行有效控制,使运算组件中的运算器位置不再固定,可方便地实现各种加减乘除混合运算.同时,用控制指令描述运算器输入输出端口的数据变迁,用有向无环图(directed acyclic graph,DAG)[16]描述计算任务之间的关系,通过表调度方法实现资源约束条件下的任务安排优化,提高了整个运算组件的工作效率.在此基础上,通过数据交换站使各运算组件协同工作,在一块5SGSMD5芯片上实现了IEEE-14电力系统实时仿真.
1 细粒度并行计算
仿真计算过程中存在着大量的可并行执行的运算表达式,如节点注入电流向量、right-looking并行LU分解、坐标变换等.同时,运算表达式中一般存在可并行执行的加减乘除基本运算.
以求解发电机端口方程的等效导纳矩阵Yabc为例来描述细粒度并行过程.由机械系统得到的转子转速ω可算出在dq坐标系下等效导纳矩阵Ydq0,其非零元素的计算公式为
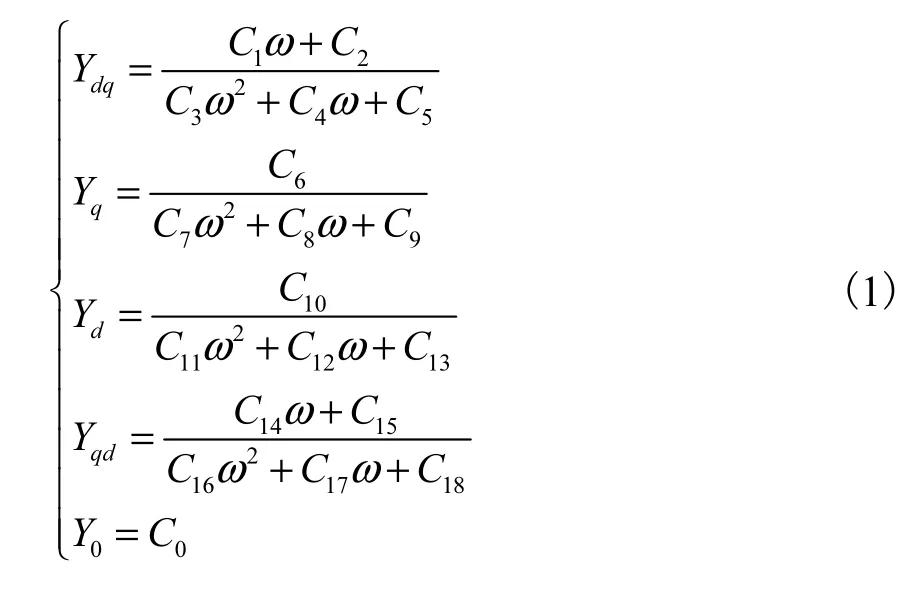
再经派克变换便可得到Yabc,即

式(1)中存在4个可并行执行的计算表达式,各表达式中某些乘法和加法运算可并行执行,其中Ydq和Yq的计算可用如图1(a)和1(b)所示的逻辑电路来实现.式(2)中存在9个可并行执行的计算表达式,各表达式中的乘法可并行执行,其中Yab的计算可用如图1(c)所示的逻辑电路来实现.
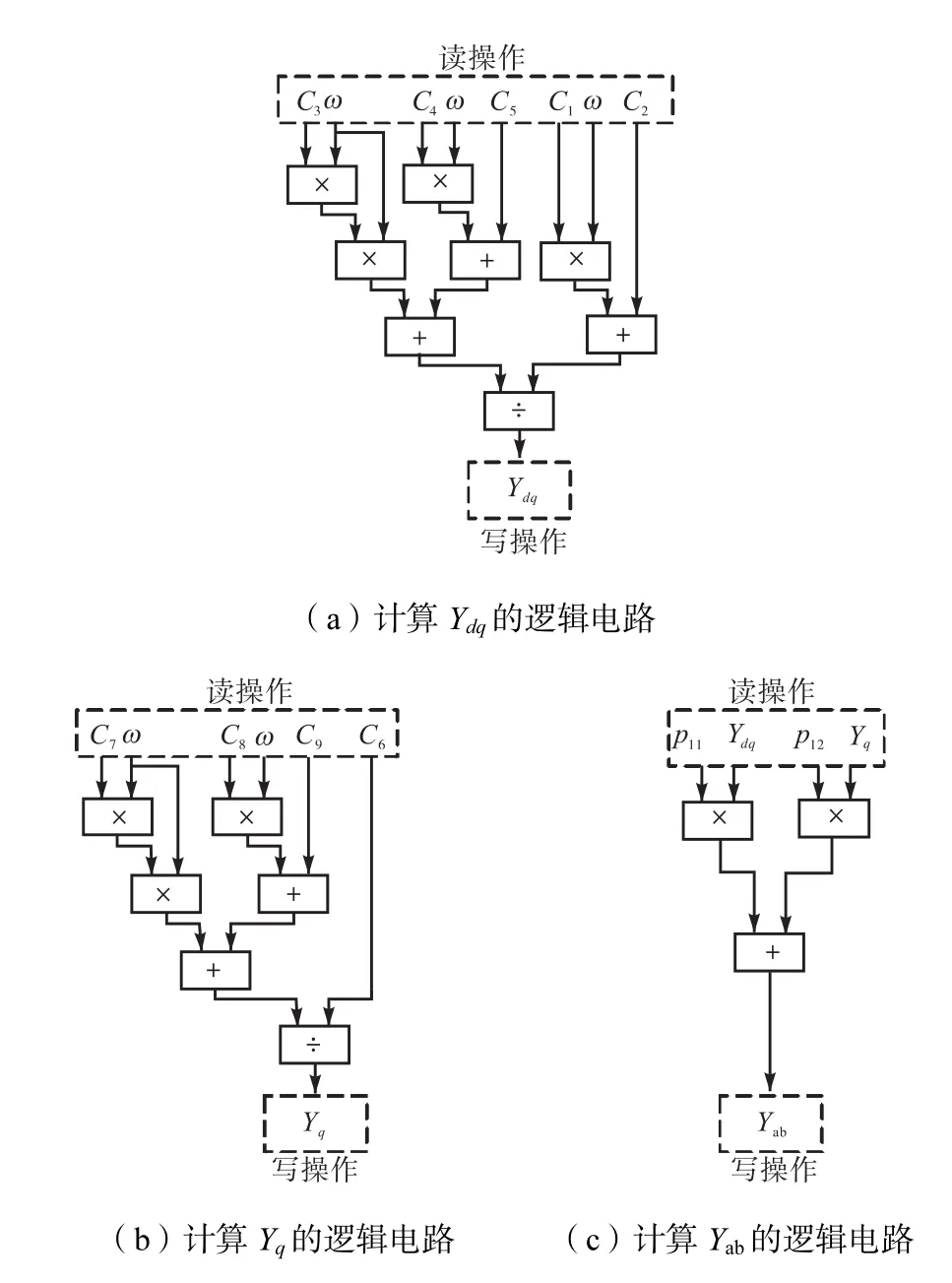
图1 计算部分参数的逻辑电路Fig.1 Logic circuits of calculating partial parameters
为每个计算表达式配备独特的逻辑电路可实现理想的细粒度并行,但这种方法受到FPGA片上资源的限制.这些计算表达式的逻辑电路具有相似性,可采用复用技术减轻对硬件资源的需求.如采用图2所示的运算组件可分别计算Ydq、Yq和Yab,但需对数据的输入口和输出口进行有效控制.
图2中的缓冲通道由多个寄存器串接而成,通过对寄存器的控制使数据从缓冲通道的一端移向另一端.放置这些缓冲通道的目的是保证运算组件的时序正确性.在图2中,假定乘法器的流水线长度短于加法器的流水线长度.

图2 计算Ydq、Yq和Yab的运算组件Fig.2 Processing unit of calculating Ydq,Yqand Yab
2 变结构运算组件
由于图2中运算器的连接关系固定不变,在计算Yab时2/3的运算器处于无意义的工作状态,且流水线的长度比图1(c)有大幅度的增加.若组件中运算器能够根据不同的计算表达式来改变连接关系即位置可变,则可避免不必要的计算等待,从而提高仿真的计算速度.
为使组件中运算器的连接关系可变,为运算器的每个输入口配备一个输入口控制器,为运算器的每个输出口配备一个输出口控制器和一条由寄存器级联组成且任意位置可读写的缓冲通道,如图3所示.缓冲通道的首端连接运算器的输出口,末端悬空.输入口控制器负责从数据存储区或缓冲通道到运算器输入口的数据流控制,输出口控制器负责从缓冲通道到数据存储区的数据流控制.

图3 变结构运算组件的示意Fig.3 Sketch map of variable-structure processing unit
当某个运算器的两个输入数据来自同一数据块时,需要多花费一个时钟节拍来传送输入数据,这导致运算器的工作效率下降.如果允许数据存储区的数据流向缓冲通道,则可事先把其中的一个数据安放在缓冲通道上,需要时把它传送到运算器的输入口.因此,在图3中增加了以虚线箭头表示的从数据存储区到缓冲通道的数据流.这样,也解决了数组之间的数据流动问题.
对于图3所示的变结构运算组件,其核心是输入口控制器和输出口控制器.为使这些控制器具有通用性,把控制器细分成存储一系列控制指令的代码存储区、读取代码和解析代码的指令解码器、执行指令的多路开关.由于变结构运算组件中各个运算器均需要控制指令,故它比固定结构的运算组件需要更多的FPGA存储资源和逻辑资源.
为了缩短代码存储区的长度,一是采用短指令,二是对有规律的指令串用块指令替代.块指令包括停止、重复、地址递增、地址递减等.本文规定输入口指令的长度为16位,其格式如表1所示;输出口指令的长度为24位,其格式如表2所示.

表1 输入口控制指令格式Tab.1 Instruction format of input controller

表2 输出口控制指令格式Tab.2 Instruction format of output controller
组件中运算器的增加意味着缓冲通道和数组的增加.过多的缓冲通道和数组会使控制器的多路开关变得复杂,很难保证多路开关在较高频率下运行.因此,在表1和表2中规定了缓冲通道个数和长度不超过16和32,数据存储区的数组个数和长度不超过48和1,024.
实时模仿一个具有一定规模的电力系统通常需要几十个变结构运算组件.组件之间的数据交互通过交换站来完成.交换站由一组寄存器和若干个输出口控制器组成,其控制器负责交换站寄存器与某个组件的数据存储区之间的数据流控制.指令格式与表2一致,但需把通道变成交换站.当交换站所涉及的运算组件分散在不同FPGA芯片时,可通过具有控制光接口功能的输出口控制器完成芯片级的数据通信.由于芯片级数据通信有较长的时延,尽量不要把同一粗粒下的仿真计算分散到不同芯片中.
3 指令流的优化生成
合理安排控制器指令流是实现细粒度并行计算的关键.由高级语言的仿真程序生成控制器指令流的基本过程如图4所示.其中,任务生成算法将高级语言的仿真程序变成操作任务及其依赖关系的DAG,任务调度算法实现资源约束条件下对任务安排的优化,并给出具体的控制器指令流.

图4 指令流生成的基本过程Fig.4 Process of instruction stream generation
在任务生成算法中,将仿真程序中各运算表达式拆分为具体的操作任务T(其中,用T1表示运算任务,T2表示读RAM任务,T3表示写RAM任务).在按照运算符优先级确定运算任务依赖关系的基础上,优先安排等待时间最短的运算数据.由于运算数据可能是原始数据(由T2而来),也可能是中间数据(由T1而来),同优先级的运算任务之间也有依赖关系.
在任务调度算法中,用A(ti)表示任务ti∈T2∪T3的数据来源,用s(ti)表示任务ti开始执行时间,用p(ti)表示任务ti所用资源.其中,这里将加、乘、除运算器记为C类资源,将读、写RAM数据操作记为M类资源.用s1(ti)和s2(ti)表示任务ti的理想最早启动时间和理想最晚启动时间,即

式中:l(x)为任务x所用资源的流水线长度;p(x)和q(x)分别为任务x的前驱任务和后继任务;E(T)和F(T)分别为所有入口任务(无前驱)和出口任务(无后继).

由于M类资源与RAM有固定的匹配关系,读写任务能否安排取决于相应的M类资源的占用情况.而运算任务除了考虑相应的C类资源的占用情况外,还要优先选用前驱任务所安排的变结构运算组件内的资源.
对ti∈T且p(ti)∈C,p(ti)的输入口控制器指令流<it,ip>(it为时间序号,ip为操作源地址)和输出口控制器指令流<ot,op,oq>(ot为时间序号,op为操作源地址,oq为操作目标地址)可表示为

式中:B(x)表示与资源x对应的缓冲通道基地址;tj∈p(ti);tk∈q(ti).
具体的任务调度算法如下.
步骤 1 计算DAG各任务的s1和s2,置b3为零,并将所有任务放入未调度任务列表,计时器c置零.
步骤2 按照任务优先级原则对未调度任务列表排序.
步骤,,,3 当未调度任务列表空时转至步骤10.
步骤4 从未调度任务列表取出首任务ti.若s1(ti)>c,清理资源已占用标记.将满足b3(ti,tj)>h的所有tj∈p(ti)记为Tj,若Tj为非空转至步骤8.
步骤5 为任务ti从未占用资源中选取资源.若找不到可用资源转至步骤7.
步骤6 为任务ti所用资源打上已占用标记,把任务ti增添到已调度任务列表中去,c=s1(ti),转至步骤9.
步骤7 任务ti放回未调度任务列表.将与任务ti和 tj∈p(ti)有关的s1(ti)和b1(ti,tj)增1,计算相应的b2(tj)和b3(ti,tj),转至步骤9.
步骤8 Tj及其之后放入已调度任务列表的任务放回未调度任务列表.将与任务tj∈Tj和 tk∈p(tj)有关的s1(tj)和b1(tj,tk)增1,计算b2(tk)和b3(tj,tk),c=min{s1(tj)}.清理资源已占用标记,并将已调度任务列表中最近执行任务所占用的资源打上标记.
步骤9 重新计算未调度任务列表中各任务的s1和s2,转至步骤2.
步骤10 由式(5)和式(6)生成控制器的指令流<it,ip>或<ot,op,oq>,并按表1和表2指令格式进一步处理指令流.
4 仿真实例
搭建的硬件在环仿真系统的电力系统如图5所示,在发电机、变压器、母线、传输线之间设有断路器,在变压器出口、母线、传输线末端放置短路故障模型.同时,为发电机配备调速系统和励磁控制系统,为发电机、变压器、母线、传输线配备相应的保护.断路器状态、短路故障有无、保护投切(包括真实保护)通过人机界面来设置.

图5 IEEE-14电力系统Fig.5 IEEE-14 power system
本文选择Altera公司的DSP Stratix V官方开发板,如图6所示.开发板配有Stratix V系列FPGA 5SGSMD5,该芯片包含457,000个逻辑单元、172,600个自适应逻辑模块、39,Mbit嵌入式存储资源、3,180个18×18硬件乘法器和24个锁相环资源等.

图6 DSP Stratix V FPGA开发板Fig.6 DSP development kit,Stratix V FPGA
为模仿图5所示电力系统,在5SGSMD5芯片上创建了16个变结构运算组件和5个交换站.每个组件配有2个除法器、6个乘法器和8个加法器,缓冲通道长度为32.每个交换站配有16个控制器,缓冲通道长度为128.除运算组件和交换站之外,还搭建了时钟锁相环、电流过零检测、网络参数更改等硬件电路,并添加了Quartus II提供的逻辑分析仪Signaltap II模块以验证仿真结果.
双精度浮点数除法、乘法、加法运算器和读写RAM操作的流水线长度设计为7、5、10和2,经Quartus II提供的软件TimeQuest进行时序约束,将仿真运算的最高工作时钟频率定为184,MHz.通过表调度形成的仿真程序在一个步长内执行时间为27.1,μs.
当图5中线路a的保护采用真实的继电保护设备(南瑞继保公司的线路保护装置PCS-931GM-D)时,形成信号级硬件在环实时仿真系统.为验证仿真的准确性,记录短路故障和保护装置动作时间,用PSCAD仿真软件模拟同样的故障和保护.图7和图8分别给出了线路a发生三相接地故障后母线13的三相电压,发电机4的功角与励磁电压.

图7 母线13的三相电压Fig.7 Three-phase voltage of Bus 13

图8 发电机4的功角和励磁电压Fig.8 Power angle and excitation voltage of G4
由图7和图8所见,FPGA实时仿真平台与PSCAD的仿真波形基本一致,误差在5%,以内.
为验证所提仿真实现方法的高效性,本文与传统的FPGA编程的仿真实现方法[11-15]相对比.后者根据文献[15],针对图5的电力系统在5SGSMD5芯片中分别搭建发电机模型、注入电流源模型、开关模型以及线性网络求解模型的硬件电路,并由模型间电气量的连接关系编写状态机.在FPGA编程中,选择与本文方法相同的除法、乘法、加法运算器,并同样以184,MHz的工作时钟频率驱动时序电路,一个仿真步长的计算时间为42.9,μs,是本文方法的1.6倍.两种实现方法的资源消耗情况和运算器利用率如表3和表4所示.

表3 两种实现方法的FPGA资源消耗情况Tab.3FPGA resources utilized by two implementing methods

表4 两种实现方法的运算器利用率Tab.4Arithmetic unit utilization of two implementing methods %,
可见,在传统FPGA编程的实现方法中,使用的逻辑资源和硬件乘法器已接近90%,,其原因是模块间运算器相互独立且无法复用,运算器的利用率很低.而指令流优化生成方法能够对运算器作统一调度,提高了运算器的利用率,从而减少了对FPGA运算资源的需求.
考虑时序约束,5SGSMD5芯片中最多可创建24个变结构运算单元.经测试,它们完成2个图5所示仿真系统(共470个节点和10台发电机)的计算时间为45,μs,完全可实现仿真步长为50,μs的实时仿真.若使用RTDS仿真,同样的仿真规模至少需10个GPC卡(1个GPC卡可以处理66个节点或5个发电机模型).
5 结 论
(1)基于缓冲通道的变结构运算组件可灵活进行较大规模的加减乘除混合运算,提高了计算速度和资源利用率.
(2)采用任务生成算法和任务调度算法可将高级语言的仿真程序变成控制器指令流,在定制模式下用户不涉及FPGA编程.
(3)采用多FPGA的联合仿真可实现较大规模的电力系统实时仿真,并具有成本优势.
[1] 周保荣,房大中,Laurence A S,等. 全数字实时仿真器:HYPERSIM[J]. 电力系统自动化,2003,27(19):79-82. Zhou Baorong,Fang Dazhong,Laurence A S,et al. The fully digital real-time simulator:HYPERSIM[J]. Automation of Electric Power Systems,2003,27(19):79-82(in Chinese).
[2] 徐 箭,陈允平. 基于改进通信算法的暂态稳定并行仿真[J]. 中国电机工程学报,2006,26(15):12-18. Xu Jian,Chen Yunping. Parallel simulation for transient stability based on improved communication algorithm in cluster environment[J]. Proceedings of the CSEE,2006,26(15):12-18(in Chinese).
[3] 熊 玮,夏文龙,余晓鸿,等. 多核并行计算技术在电力系统短路计算中的应用[J]. 电力系统自动化,2011,35(8):49-53. Xiong Wei,Xia Wenlong,Yu Xiaohong,et al. Multicore parallel computation technique for power system short-circuit faults analysis[J]. Automation of Electric Power Systems,2011,35(8):49-53(in Chinese).
[4] 陈来军,陈 颖,梅生伟. 一种隐式同步策略及其在电磁暂态并行计算中的应用[J]. 电工电能新技术,2010,29(2):9-12,52. Chen Laijun,Chen Ying,Mei Shengwei. An implicit synchronization approach and its application in parallel computation of electro-magnetic transient[J]. Advanced Technology of Electrical Engineering and Energy,2010,29(2):9-12,52(in Chinese).
[5] 周孝信,田 芳. 交直流电力系统分割并行电磁暂态数字仿真方法[J]. 中国电机工程学报,2011,31(22):1-7. Zhou Xiaoxin,Tian Fang. Partition and parallel method for digital electromagnetic transient simulation of AC/DC power system[J]. Proceedings of the CSEE,2011,31(22):1-7(in Chinese).
[6] 陈来军,陈 颖,梅生伟,等. 一种混合并行算法及其在多相交直流混合电力系统中的应用[J]. 中国电机工程学报,2010,30(28):39-45. Chen Laijun,Chen Ying,Mei Shengwei,et al. A hybrid parallel computation algorithm and its application to multiphase hybrid AC/DC power systems[J]. Proceedings of the CSEE,2010,30(28):39-45(in Chinese).
[7] Toshiji K,Kaoru I,Takayuki F,et al. Multirate analysis method for a power electronic system by circuit partitioning[J]. IEEE Transactions on Power Electronic,2009,24:2791-2802.
[8] 刘 东,张炳达. 一种适合并行计算的仿真变电站一次系统模型[J]. 电力系统自动化,2010,34(20):71-76. Liu Dong,Zhang Bingda. A primary system model of simulation substation suitable for parallel computing[J]. Automation of Electric Power System,2010,34(20):71-76(in Chinese).
[9] Nechma T,Zwolinski M. Parallel sparse matrix solution for circuit simulation on FPGAs[J]. IEEE Transactions on Computers,2015,64(4):1090-1103.
[10] Cardenas A,Guzman C,Agbossou K. Development of a FPGA based real-time power analysis and control for distributed generation interface[J]. IEEE Transactions on Power Systems,2012,27(3):1343-1353.
[11] Chen Y,Dinavahi V. FPGA-based real-time EMTP[J]. IEEE Transactions on Power Delivery,2009,24(2):892-902.
[12] 王成山,丁承第,李 鹏,等. 基于FPGA的配电网暂态实时仿真研究(一):功能模块实现[J]. 中国电机工程学报,2014,34(1):161-167. Wang Chengshan,Ding Chengdi,Li Peng,et al. Realtime transient simulation for distribution systems based on FPGA(part,Ⅰ):Module realization[J]. Proceedings of the CSEE,2014,34(1):161-167(in Chinese).
[13] Matar M,Iravani R. Massively parallel implementation of AC machine models for FPGA-based real-time simulation of electromagnetic transients[J]. IEEE Transactions on Power Delivery,2011,26(2):830-840.
[14] Liu J D,Dinavahi V. A real-time nonlinear hysteretic power transformer transient model on FPGA[J]. IEEE Transactions on Industrial Electronics,2014,61(7):3587-3597.
[15] Chen Y,Dinavahi V. Multi-FPGA digital hardware design for detailed large-scale real-time electromagnetic transient simulation of power systems[J]. IET Generation,Transmission & Distribution,2013,7(5):451-463.
[16] Cho S,Elhourani T,Ramasubramanian S. Independent directed acyclic graphs for resilient multipath routing[J]. IEEE Transactions on Networking,2012,20(1):153-162.
(责任编辑:孙立华)
Implementation of Fine Granularity Parallelization in Power System Real-Time Simulation
Wang Xiao,Zhang Bingda,Chen Xiong
(Key Laboratory of Smart Grid of Ministry of Education,Tianjin University,Tianjin 300072,China)
In order to make full use of highly parallel characteristic of FPGA,a variable-structure processing unit was designed to achieve arithmetic with the mixed operation of addition,subtraction,multiplication and division.From the perspective of practicability and extensibility,applying the control instruction to describing the operation of processing unit and the directed acyclic graph to describing the process of parallel computing,a new simulation program design method based on FPGA was proposed.On this basis,a real-time simulation of IEEE-14 bus power system has been realized on a 5SGSMD5 chip with 30 μs time-step,and the experimental results are consistent with the PSCAD simulation results.
real-time simulation;fine granularity;field programmable gate array(FPGA);variable-structure processing unit
TM744
A
0493-2137(2016)05-0513-07
10.11784/tdxbz201506073
2015-06-21;
2015-10-10.
国家自然科学基金资助项目(51477114);天津市科技计划资助项目(13TXSYJC40400).
王 潇(1987—),男,博士研究生,wangxiao@tju.edu.cn.
张炳达,bdzhang@tju.edu.cn.
网络出版时间:2015-11-11. 网络出版地址:http://www.cnki.net/kcms/detail/12.1127.N.20151111.1759.006.html.
