基于词项关联关系的FCM微博聚类算法
2016-11-01程玉胜王一宾
程玉胜,黎 康,王一宾,任 勇
(安庆师范大学 计算机与信息学院,安徽 安庆 246133)
基于词项关联关系的FCM微博聚类算法
程玉胜,黎康,王一宾,任勇
(安庆师范大学 计算机与信息学院,安徽 安庆 246133)
针对微博内容的稀疏、高维等特征,提出了一种基于词项关联关系的模糊C均值聚类算法。该算法通过挖掘词项间语义的关联程度,将文本特征最大化,并用提前标注部分同类文本的方式来指导模糊C均值算法在初始聚类中心上的选择,从而达到优化效果。实验结果表明,该算法一定程度上克服了微博本身存在的数据稀疏性问题,能高效地进行微博聚类。
微博;词项关联关系;模糊聚类
自2009年8月国内门户网站推出微博服务后至2013年上半年,新浪微博和腾讯微博的注册用户分别达到了5.36亿和5.07亿,微博作为一种新型的社交媒体,已经被人们广泛关注。如何从数量庞大的微博内容中得到有用舆情信息,从而权衡利弊,合理利用微博影响力,在舆情研究领域变得至关重要。传统的人工数据处理方法,效率低且不能对微博舆论内容的传播和发展进行准确及时的监测。因此,科学地分析微博数据,并对其热门话题实施追踪分析,对可能诱发社会动荡事件的不良信息进行监测和预警,才能推动微博长期健康有序的发展。
文本表示是实现文本聚类的核心部分。目前常见的文本表示方法是由Salton等人在20世纪70年代提出的向量空间模型[1-2](Vector Space Model,VSM),用空间中的向量运算来简化对文本内容的处理,而且他用空间上的相似度计算值代替表示语义上的相似度计算值,简单明了。然而,他认为所有词之间都是相互独立存在的,每个关键字只能表示一个概念或语义单元,但现实中却是文档中会出现许多一词多义和同义词的情况,所以这种假设很难解决实际问题;N-gram统计语言模型[3-4]没有把组成文本的语义单位考虑进来,仅仅把整个文本看作是不同字符组成的字符串,所以在表示包括汉语、阿拉伯语在内的各种语言文本文档时都非常简单。N-gram模型表示文本本质的是其统计特征,因而它的优势体现在计算机运算和机器学习方面。但N-gram表示有着计算量大、数据噪声大、特征生成复杂等缺点;1958年,IBM公司科学家Luhn提出词权重经典计算方法 TF-IDF[5](Term Frequency-Inversed Docu-ment Frequency)。传统的聚类方法采用特征向量来表示文本,以词或短语作为特征,使用TF-IDF方法计算每个特征词的权重。但由于微博文本非常短,很多词语在短文本中仅出现一至两次,TF值基本在1至2左右,使得TF值对TF-IDF的取值影响不大,更多是由IDF决定。而根据IDF取值规定,特征词出现的频率越高,它的IDF值越小,则整个TF-IDF权重就越小,这与短文本中高频特征词往往与主题息息相关相悖。对比传统文本,微博信息不仅内容较短,而且常常不以语法规则为前提,所以很难从中获取充足的语义信息来进行相似度计算,另一方面,词空间的高维、稀疏、多变和相关等特性,也让文本聚类变得困难重重。
针对以上特点,本文提出一种基于融合词项关联关系[6-7]的模糊C均值聚类算法。该算法通过挖掘微博数据内部的词语信息以丰富微博的文本特征来辅助模糊C均值算法[8-11]进行聚类,进而挖掘出微博数据中潜在主题和语义信息。
1 词项关联关系
目前主要的短文本处理方法绝大多数是将特征词项看作相互独立的信息进行处理,没有考虑两个特征分量间或许具有关联关系。但实际情况是文本相似度的计算结果与特征词项分量间关联程度大小有着密不可分的关系。把词语的内联关系和外联关系加进来,不仅能很好地实现对短文本数据降维,还能使短文本的特征信息最大化。
1.1互信息向量
图1(a)中T1和T2代表不同的文档,字母A,B,C是T1和T2中的词项,其中字母B是T1和T2中都有的词项,右图显示的是不同模式下的关联词关系。(b)图描述的是文档内的词项关系,(c)图描述的是不同文档之间的词项关系。
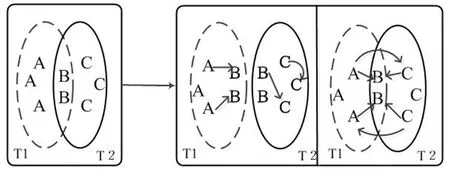
(a) (b) (c)
要表示某个词项fi的分布情况,可以用这个词项和它所在文本中其余的词项共现向量fi(w11,w12,…,wij),其中wij是衡量词fi和fj相互关联程度的互信息。基于词与其原文档中其他词的语义相关性来计算词项关联关系的具体步骤为
(1)
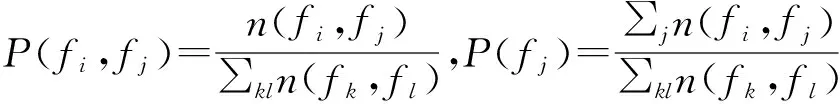
(2)n(fi,fj)是词项fi和fj同时出现的次数,这样就可以用互信息向量表示每个词项的分布情况。
1.2同一文档内关联关系
文档内关联关系简称内联关系,定义的是在一篇文档中两个词项之间的关系,如图1中,T1中有词fi和fk同时出现,T2中有词fj和fk同时出现,则认为这两对词在其对应的原文档中存在内联关系,采用经典余弦相似度计算公式如下
(3)
1.3不同文档间关联关系
两篇文档中的词与它们的共有词一起出现,那么认为这2个词存在文档间关联关系,简称外联关系,如图1中,两个词fi和fj,至少存在一个词fk,让词fi和fj同时出现,则认为fi和fj具有外联关系,其中词fk称为fi和fj的共有词。可以用如下公式计算词fi和fj的外联关系:
Dep(fi,fj/k)=
min{D-Dep(fi,fk),D-Dep(fj,fk)}
(4)因为共有词往往不止一个,所以需要对fi和fj所有的共有词求和,然后规范化到[0,1]区间:
(5)
从(5)式可知,任意不同词语间的关系亲疏程度与这两个词语的共有词数量呈正比。又因为加入了所有存在关联关系的共有词对应的文档,所以外联关系要比内联关系含有更多的语义信息。
目前为止,已经挖掘出文档内与文档间词语的全部关联关系,即
(6)式中,α表示两种词项关联关系对应的比例,取值范围为0到1。用以上方法计算获取的关联词关系既涵盖了同时出现词语的互信息,又涵盖了非同时出现词语的文档间关联关系,所以其必然可以挖掘出更多的信息。
2 FCM聚类算法
假设样本空间为X={x1,x2,…,xn},把它分成m个类,m为正整数,取值范围[0,∞],用模糊矩阵u=(uij)来表示,uij是用来度量第i个样本属于第j个类别的排斥性,用cj表示第j个聚类中心点,样本点xi到聚类中心点cj的欧氏距离用‖xi-cj‖表示,则
(7)
不难看出,排斥性的大小与样本点到聚类中心的欧式距离呈正比关系,其中
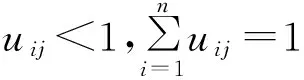
i=1,2,…,n,j=1,2,…,m
(8)
将FCM的目标函数F(u,C)定义为

(9)
式中b为模糊指数。很明显,F值的大小与‖xi-cj‖、uij的值大小呈正比。通过反复修改聚类中心的值,再按照步骤计算F(u,C),直到得出的结果符合条件。所以,FCM算法的本质是对目标函数F(u,C)的最小化迭代收敛过程。因为需要反复修改聚类中心值,所以可以将聚类中心点设置为
(10)
聚类结果的模糊程度与b的取值大小呈正比关系,目前还缺乏理论知识对b的取值选择进行指导,更多的是靠经验。正常情况下b的取值在1.5~2.5之间,有些情况下会直接将b的值赋为2。
3 基于词项关联关系的FCM聚类算法
首先通过互信息将每个词项表示为它和其他词项共现向量fi(w11,w12,…,wij),再根据词项关联关系公式计算出各词项所对应的值,通过定义,T-link表示为必属同类别的词项,F-link则表示必不属同类别的词项,再定义阈值3,计算词项关联关系的值,如果大于3,就认为其必属同一类别,反之则认为其必不属同一类别。显然,同一类词项具有传递效应。
通过词项关联关系计算可以初步确定部分文本的类别信息,此时选取词项关联关系计算时与其他词项相同类别次数最多和相异类别次数最多的词项其对应的文本作为模糊C均值聚类算法初次选取的聚类中心。
由此确定聚类算法的迭代过程如图2所示。
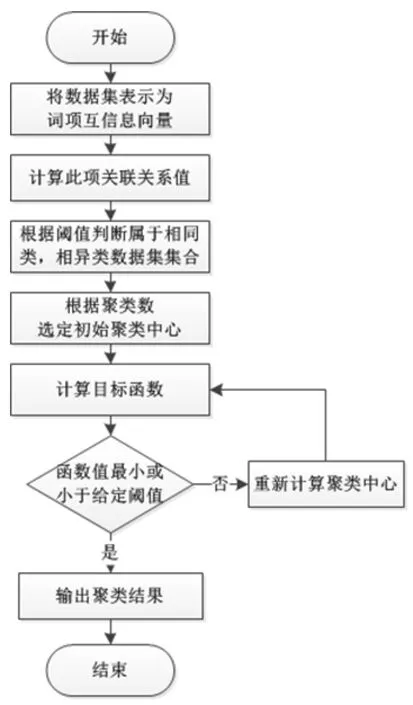
图2 算法流程图
步骤1分别设定聚类簇数和模糊指数b的值;
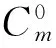
步骤3把通过步骤2获得的初始聚类中心代入(9)式中计算目标函数F(u,C),再用目前获得的uij去更新cj,重复本步骤,当F(u,C)的值达到最小,或是已经低于提前定义的阈值时,停止计算,输出结果。
4 实验结果与分析
4.1数据来源
本实验采用的数据取自国内新浪微博平台和国外的Twitter平台。实验数据采集的是2015年3月-2016年3月大量的微博数据,通过热点话题搜索,分类查找得到在此期间国内热门话题8个,国际热点话题4个。预处理实验数据:第1步,剔除数据文本中的标点符号、表情字符和转发链接等无效信息;第2步,对文本进行分词,剔除停用词、高频词和低频词后,得本文所需实验数据集合。本文采用的是NLPIR汉语分词系统,采用的1 028个停用词是由新浪平台提供的,得到的数据集如表1所示。
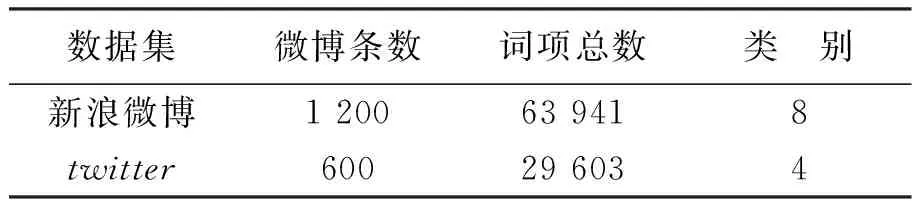
表1 实验所需数据信息
4.2实验结果与分析
为了取证本文方法的实际性能,现将FCM算法,K-means算法和本文算法对同组微博数据的聚类结果如表2所示。
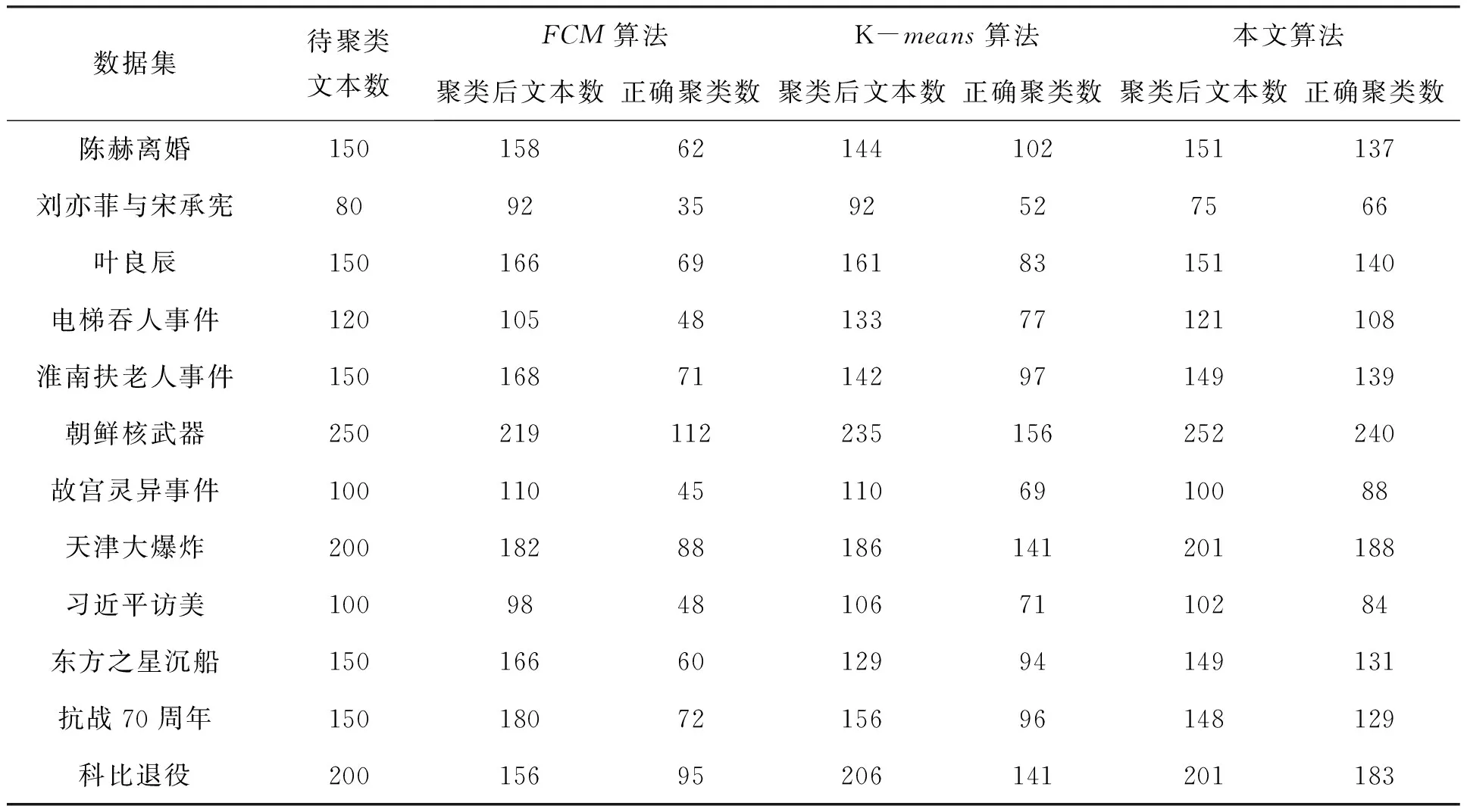
表2 聚类情况的对比
为了更为直观地观察3种算法对实验数据聚类的结果,将3种算法的准确性与时间消耗结果对应绘制成图3。
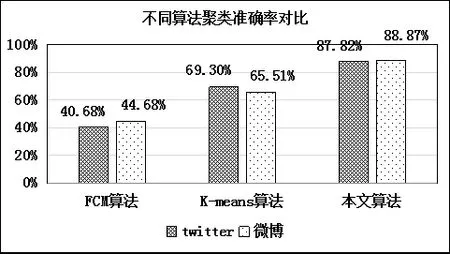
从图3可以明显看出,FCM算法不仅存在对数据聚类效果差的问题,而且时间消耗较多,相比之下,经典的K-means虽然在时间消耗上较少,但是其算法只从文字本身出发,不考虑词项间可能存在的关系,因而获得的词项矩阵比较稀疏,它的文档向量也不能准确地描述待测文档的原始信息,所以算法在准确性上还有待提高。而本文所提算法在考虑了词语间的互信息的同时,还最大限度发掘出词语间的关联关系,不仅克服了文本表示中忽略词语间关系而导致的实验结果不准确问题,而且在很大程度上降低了原始数据的高维稀疏性。因此本文提出的算法优于其他的两种聚类方法。
5 结束语
由于微博在现实生活中扮演的角色越来越重要,所以对微博数据的研究分析变得越来越有意义。考虑实际情况中现有的主要聚类算法很难解决微博数据分词后的词项矩阵稀疏难题,本文提出了基于融合词项关联关系的FCM聚类算法。该算法克服了微博短文本的高维稀疏问题,通过挖掘词项上下文关系丰富文本特征,并提前确定聚类中心的方法,减少了算法迭代次数,并且在聚类精度上取得了不错的结果,具有较好的性能。但是,本文算法依然存在一定缺陷,在进行词项关联关系计算时,α值是实验者主观选取的经验值,还没能建立一个有效简洁的标准,这将是下一步研究的问题。
[1]杨玉珍,刘培玉,姜沛佩.向量空间模型中结合句法的文本表示研究[J].计算机工程, 2011, 37(3): 58-60.
[2]彭京, 杨冬青, 唐世渭, 等.一种基于语义内积空间模型的文本聚类算法[J].计算机学报, 2007, 30(8): 1354-1363.
[3]秦健. N-gram技术在中文词法分析中的应用研究 [D]. 青岛:中国海洋大学, 2009.
[4]廖祥文,李艺红. 基于N-gram超核的中文倾向性句子识别[J]. 中文信息学报, 2011, 25(5): 89-100.
[5]黄承慧,印鉴,侯昉.一种结合词项语义信息和 TF-IDF 方法的文本相似度量方法[J].计算机学报, 2011, 34(5): 856-864.
[6]Mao Yuqing, Kimberly V A, Li Donghui, et al. Corpus Construction for the BioCreative IV GO Task [C]. Proceedings of the 4th BioCreative Challenge Evaluation Workshop, Bethesda, USA: BioCreative Organizing Committee, 2013: 128-138.
[7]马慧芳,贾美惠子,袁媛,等. 融合词项关联关系的半监督微博聚类算法[J]. 计算机工程, 2015, 41(5): 202-212.
[8]Ahmed E B, Nabli A, Gargouri F. Group extraction from professional social network using a new semi-supervised hierarchical clustering[J]. Knowledge and Information Systems, 2014, 40(1):29-47.
[9]Herawan T, Deris M M, Abawajy J H. A rough set approach for selecting clustering attribute[J]. Knowledge-Based Systems, 2010, 23: 220-231.
[10]朱琪,张会福,杨宇波,等. 基于减法聚类的合并最优路径层次聚类算法[J].计算机工程, 2015, 41(6): 178-187.
[11]王丹,吴孟达. 动态阈值粗糙C均值算法[J]. 计算机科学, 2011, 38(3): 218-242.
Fuzzy C-means Microblog Clustering Based on AlgorithmTerm Correlation Relationship
CHENG Yu-sheng ,LI Kang,WANG Yi-bing,REN Yong
(School of Computer and Information,Anqing Normal University, Anqing, Anhui 246133, China)
Because of feature of quick and easy to operate and strong interactive, micro-blog text has become the bridge and link of modern information communication. At the same time, it is likely to become the hotbed of false information since the supervision system is not perfect. Therefore, it is necessary to strengthen the micro-blog public opinion supervision, analysis and early warning. The paper puts forward a method based on term correlation relationship of fuzzy c-means clustering algorithm, which aiming at the features of sparse and high dimensional. The algorithm maximizes the feature of the text by excavating the relationship between different items. Meanwhile, by means of tagging part of the same text to guide the algorithm of fuzzy c-means to choice it’s clustering center, so as to achieve the effect of optimization. Experimental results show that the algorithm can overcome the sparse of micro-blog to a certain degree, and can clustering efficiently.
micro-blog; term correlation relationship; fuzzy clustering
2016-03-05
安徽省高等学校自然科学基金(KJ2013A177)。
程玉胜,男,安徽桐城人,博士,安庆师范大学计算机与信息学院教授,研究方向为文本挖掘、粗糙集理论等。E-mail: chengysh@aqnu.edu.cn
时间:2016-8-17 11:31
http://www.cnki.net/kcms/detail/34.1150.N.20160817.1131.019.html
TP3
A
1007-4260(2016)03-0068-05
10.13757/j.cnki.cn34-1150/n.2016.03.019
