基于记忆曲线的数据密集型动态用户行为建模*
2016-10-28尹子都付晓东刘惟一
尹子都,岳 昆+,武 浩,付晓东,刘惟一
1.云南大学 信息学院,昆明 650504
2.昆明理工大学 信息工程与自动化学院,昆明 650504
基于记忆曲线的数据密集型动态用户行为建模*
尹子都1,岳昆1+,武浩1,付晓东2,刘惟一1
1.云南大学 信息学院,昆明 650504
2.昆明理工大学 信息工程与自动化学院,昆明 650504
分析用户行为的历史数据,使用特定方法建立用户的偏好模型,是目前研究的热点和关键。考虑了数据产生的时序特征,以及具有时间特征的变量在用户行为模型中的影响,以心理学中的记忆曲线模型为依据,从用户的行为数据出发,给出了用户偏好的表示,并为用户的每个偏好建立一个记忆曲线模型,实时地表示用户的偏好。针对海量的用户行为数据,提出了基于MapReduce的模型参数增量更新算法和动态用户偏好计算方法,从而使得模型能反映动态变化的用户偏好。建立在真实数据上的实验结果表明,提出的模型和算法具有高效性、正确性和可用性。
动态用户行为模型;用户偏好;记忆曲线;增量更新;MapReduce
1 引言
自媒体的产生与云计算的成熟,使用户在互联网中的作用不断提升。用户的行为会产生大量数据,获取和分析这些用户行为数据能得到用户个人信息,可用于推荐、行为评判和预测等多个方面,因此以用户行为数据为核心的应用越来越多,基于云计算的“数据即服务”也日益流行[1]。用户偏好的表示与建模是数据分析的重点与研究的核心,用户偏好可理解为用户想与之交互或已经交互的对象,如某个商品、某条广告或某种言论等,而交互可以是用户的点击、评论、购买与关注等,统称用户行为。分析用户行为的历史数据,使用特定的方法建立用户的偏好模型(也称用户行为模型),成为当前研究的热点和相关应用的基础。
经典的用户建模方法中,研究人员用形式化的结构表达用户偏好,将用户的偏好表示为对商品或新闻的喜好程度的向量[2-3],从而方便计算和处理。但是,这些方法往往基于一段时间内的用户行为数据来构建用户偏好模型,不区分数据生成的时间先后,对表达时间变量的影响关注较少。为了合理地表达时间特征,动态地反映用户的偏好,已有越来越多的研究关注基于带有时间特征的用户行为数据来构建用户行为模型。例如,Marin等人[4]利用用户的交互行为,提出反馈型的用户偏好模型,偏好随用户的交互行为改变,并提出一种自动检测相关参数准确性的方法。Hawalah等人[5]提出一种动态表示用户偏好的方法,考虑用户偏好随时间推移所产生的消减和去除特性,用Sugiyama等人[6]提出的方法给出用户偏好的动态变化过程,这一思路为本文动态用户行为模型的研究提供了参考。然而,鉴于数据本身不确定性、随时间变化的特点,从带有时间特征的数据出发的用户行为模型要实现用户偏好的合理表达,仍存在如下挑战:
(1)用户的偏好往往会随着时间的推移而不断变化,并且往往呈现出一定的规律,因此需要构建一个合理的模型来反映用户偏好随时间变化的特征。
(2)随着用户行为数据的不断产生,需要根据新产生的数据,以增量的方式更新现有模型中的参数,使其能较好地反映新产生的数据对模型的影响。
(3)大量的用户产生海量的行为数据,需要采用有效的数据密集型计算策略对这些海量行为数据进行处理分析,进而实现前述(1)和(2)中动态偏好的建模与增量更新。
针对用户偏好随着时间不断变化的特征,邢春晓等人[7]为了及时反映用户兴趣变化,提出了基于时间和资源的数据权重,以及基于资源的协同过滤推荐算法。该方法考虑用户偏好随时间呈线性变化的情形,反映了用户偏好建模中的时间特征。事实上,从心理认知角度,用户偏好反映了其对特定对象(如商品、新闻和博客等)的欲望。已有研究针对用户的心理特性,得出了用户行为的特点以及用户偏好随时间变化的一般规律。例如,Khader等人[8]指出人的判断大多基于记忆而得出,偏好作为人对事物的判断同样基于记忆,即记忆的变化将导致偏好的变化,且这种变化未必呈线性趋势。由此,本文借鉴用户心理与记忆描述及建模机制,讨论从海量的行为数据中发现体现用户心理特性的偏好模型及其增量更新机制。
艾宾浩斯记忆遗忘曲线(也称记忆曲线)模型考虑用户自然遗忘的客观规律[9],近年来被广泛用于数据分析领域,涉及协同过滤与推荐[10-11]、机器学习[12]和图/网络[13-15]等方面。特别地,在基于记忆曲线的用户偏好建模方面,于洪等人[10]提出基于遗忘曲线的协同过滤推荐算法,根据记忆曲线将用户偏好分为长期和短期偏好,从而匹配不同用户间的偏好,进而完成协同过滤任务。印桂生等人[11]建立了遗忘曲线的协同过滤推荐模型。这些方法为基于记忆曲线的用户偏好研究提供了参考,但是用户的长期和短期偏好划分并不容易,并且面向海量的用户行为数据,这些方法仍需进一步扩展。
因此,针对挑战(1)和(2),本文以记忆曲线为依据,从用户行为数据出发,给出用户偏好的表示,为用户的每个偏好建立一个记忆曲线模型,实时地表示用户的各个偏好。同时,针对新产生的用户行为数据,本文提出了一种模型参数的增量更新方法,使新的模型能反映变化的用户偏好。
MapReduce编程模型是众所周知和业界公认的海量处理计算框架和编程模型[16-17],近年来广泛应用于用户建模领域。例如,Liang等人[18]讨论并提出了一种高效的基于MapReduce的并行用户建模方法;Shmueli-Scheuer等人[12]提出一种基于MapReduce实现的从大规模数据中建立用户行为模型的方法。因此,针对挑战(3),为了对海量的用户行为数据进行处理和分析,本文给出了基于MapReduce的参数增量更新和动态用户偏好建模的算法。
为了测试本文方法的有效性,爬取了新闻网站Engadget中国版[19]的真实用户行为数据,使用基于Hadoop的MapReduce数据密集型计算平台,编程实现并测试了本文提出的模型与算法。实验结果表明,本文方法具有高效性、正确性和可用性。
本文组织结构如下:第2章给出动态用户行为模型的表示;第3章给出从用户行为数据构建动态行为模型的算法;第4章给出实验结果;第5章总结全文并展望将来的工作。
2 动态用户行为模型的表示
2.1用户行为数据
本文用U={u1,u2,…,un}表示用户的集合,其中ui(1≤i≤n)表示第i个用户。用户ui的行为将以某个对象为目标,例如用户浏览新闻时会将一个新闻对象作为浏览的目标,用户评论时会将一个评论对象作为目标。针对目标对象集合,为了反映用户偏好的特点,可使用分布式近邻传播聚类方法[20](首先提取关键词,再使用此聚类的方法将相似的对象归为一类),并用一个代表性关键词作为一类的标签,从而得到由关键词构成的标签集合。例如,浏览新闻时每条新闻为一个对象,通过提取关键词将相似的新闻归为一类,并用其中一个关键词作为这一类的标签。用L={l1,l2,…,lm}表示用户偏好标签集合,其中lj(1≤j≤m)为第j个标签,表示用户浏览对象的第j个类别。
本文将从用户行为数据构建用户偏好模型,用户行为数据包含用户、时间和偏好。
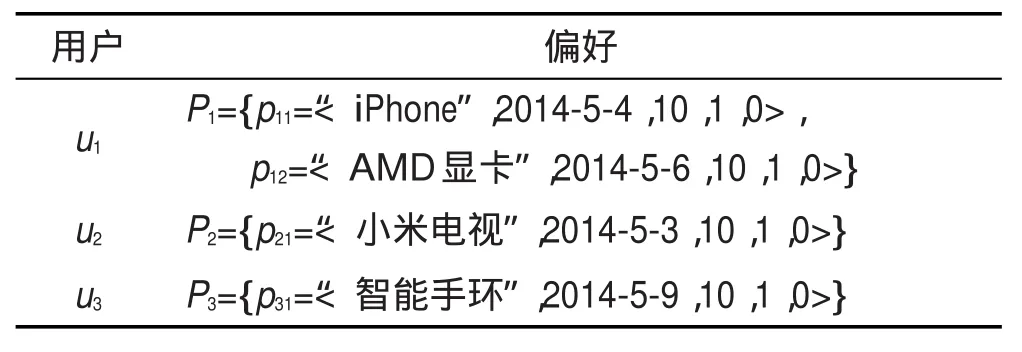
定义1(用户行为数据)用户的一条行为数据记录Item可表示为{ui,TB,lj},其中ui用以标识用户,TB为浏览时刻,lj为用户浏览的偏好对应的偏好标签。
表1给出了定义1中用户行为数据的示例。
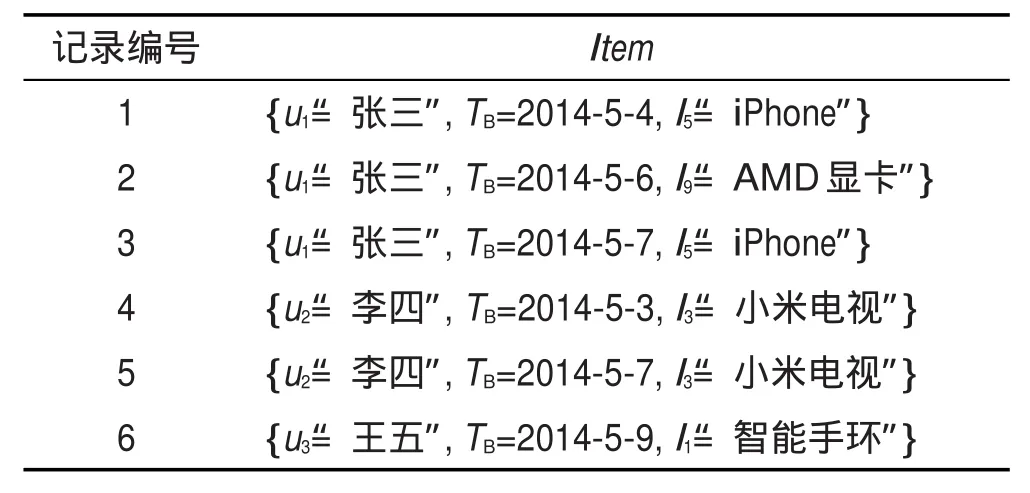
Table 1 Example of user behavior data表1 用户行为数据示例
2.2模型的基本思想
根据心理学相关研究,人对事物的遗忘过程可由记忆曲线模型描述,下面给出相关定义和概念。
定义2(记忆曲线模型)记忆曲线模型表示为[9]:

其中,Δx=x′-x,x′和x分别表示目标时刻和最近一次记忆对象的时刻;v为时刻x′的记忆强度,为正确记忆的信息占全部信息的比例;b为相对记忆强度(取正整数),长期记忆b值大于短期记忆的b值。
式(1)表示Δx随着时间推移而增大,记忆的影响作用会下降,不同b值在区间[0,100]上的记忆曲线如图1所示。Khader等人[8]指出人的偏好或判断大多是基于记忆而得出的,不难看出,对于某个偏好而言,记忆过程可表达为偏好的强化过程;同时随着记忆的衰减,用户的偏好也会随之递减;偏好随着∆x的增加会下降,长期偏好与短期偏好的衰减速度不同,短期偏好对应短期记忆,较小的b值使偏好的影响作用下降较快;反之,长期偏好对应的b值较大,对应长期记忆,影响作用下降得慢。因此,将记忆对象与用户的偏好进行类比,记忆曲线体现了用户偏好随着时间变化的动态性,可表示用户偏好随时间的衰减。
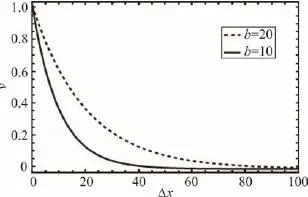
Fig.1 Forgetting curve with different b图1 不同b值的记忆曲线
定义3(用户行为模型)ui的用户行为模型可表示为一个偏好的有序集合Pi={pi1,pi2,…,piz},pij(1≤j≤z)表示ui的第j个偏好。pij可表示为一个五元组
定义3中的b和c值随着用户行为数据增长而动态更新,决定偏好变化速度的快慢,x和b用于生成用户某个偏好的强度v,参数的计算将在第3章详细讨论。用户行为模型的动态性包含如下两个层面:(1)模型参数的动态性。偏好的记忆曲线模型中,参数会随着用户行为数据的增长而不断改变,例如用户的短期偏好可能随着浏览行为逐渐成为长期偏好,使得b值增加,如图2(a)所示。(2)偏好强度的动态性。当pia中的各个参数相对稳定时,偏好强度的大小会随着时间的推移逐渐衰减,若产生一个时间增量∆x,则偏好的强度将从v变为v′(变化量为∆v),如图2(b)所示。第3章将分别讨论参数b和v的计算方法。
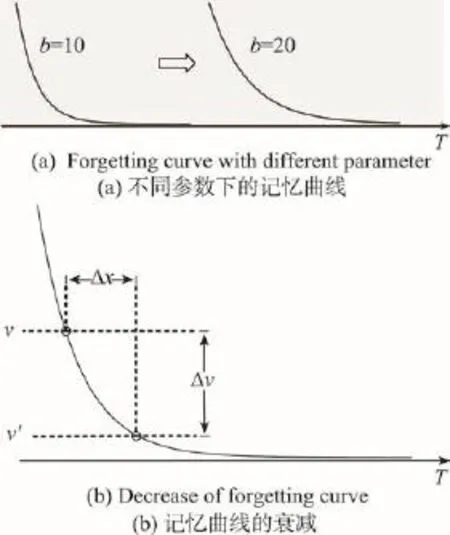
Fig.2 Dynamic preference model图2 动态偏好模型
3 动态用户偏好模型的构建
3.1模型参数的增量计算
如前所述,模型的参数决定了用户偏好变化的特点,针对新产生的用户行为数据,需要更新用户偏好的相关参数,为用户每个偏好确定新的记忆曲线,并有效地区分用户的长期或短期偏好,为个性化服务奠定基础。为了表示用户偏好本身的变化,本节讨论动态用户行为模型中参数b的增量更新方法,即根据新数据Itemnew={ui,TB,lj},更新某个用户ui对应的用户偏好集Pi。用Label(pij)表示Pi中偏好pij的标签,对于新的行为数据中所包含的用户偏好lj,按照Pi中是否包含lj,可分为如下两种情况:(1)不存在Label (pij)=lj,(2)存在Label(pij)=lj,分别对应初始情况和更新情况。下面分别讨论这两种情况下偏好模型参数的增量更新方法。
情况(1):对于ui来说,新出现的偏好不在Pi中,因此首先根据定义3建立一个新增偏好的五元组,并根据Itemnew中的lj确定该五元组中各参数的值。x为Itemnew中的TB,c=1代表一次记忆行为,平均记忆强度B是由经验获得的记忆曲线模型中b值的平均值,可在偏差较小的前提下表达大部分偏好的变化。根据实际中不同情形下偏好的强度可以对B赋予不同的值,一般地,若以“天”作为记忆强度的单位,B取值为10可以反映人对事物的平均记忆强度,因此也以此作为b的初值。
例如,从初始状态开始,使用表1中记录编号为1、2、4和6的4条记录建立用户u1、u2和u3的偏好模型,结果如表2所示。
情况(2):由于偏好lj在Pi中已存在,增量更新的目标为pij中的b值,该参数受到以下两方面因素的影响:一是偏好记忆的深刻程度。该因素与记忆强度成反比,表示长时间不发生某事还能回忆的能力,两次成功回忆之间的时间间隔(TB-x)越大,这种能力越强,v衰减越慢,与v成反比,比例为k,实验显示k取1可以得到较好的结果。二是偏好重复记忆次数c。用户对重复越多的事往往印象也越深,因此重复次数越多,c增加越多,且越倾向为长期偏好。以上两方面的因素相互独立,因此总的b值应为上述两部分之和,给出如下更新b值的方法:

针对海量的用户行为数据本文基于MapReduce给出增量更新算法。Map函数并行地选取每个用户的行为记录到一个单独的集合;Reduce函数首先按照时间先后对输入的用户行为数据记录列表进行排序,依次处理,每条记录对应一个偏好类别,从Pi中查找相同类别的元组,判断Pi与新数据Itemnew的关系,若没有找到,则用initTuple函数向Pi中添加新的五元组,否则用updateTuple函数更新此元组中b、x和c的值。算法1给出了以上思想。

例如,对于表2中的用户偏好,若新增表1中编号为3和5的两条记录,需要更新u1和u2的偏好。根据算法1,在用户u1对应的P1中使用findByLabel函数查找对应偏好为“5”的元组,发现已有元组存在,再使用updateTuple函数对记忆重复次数加1,得到c值为2。接着计算两次行为之间的时间差为3。最后根据式(2)计算1/exp(-3/10)+2,得到b值为3.3956。类似得到u2和u3的偏好,参数更新后的用户行为如表3所示。
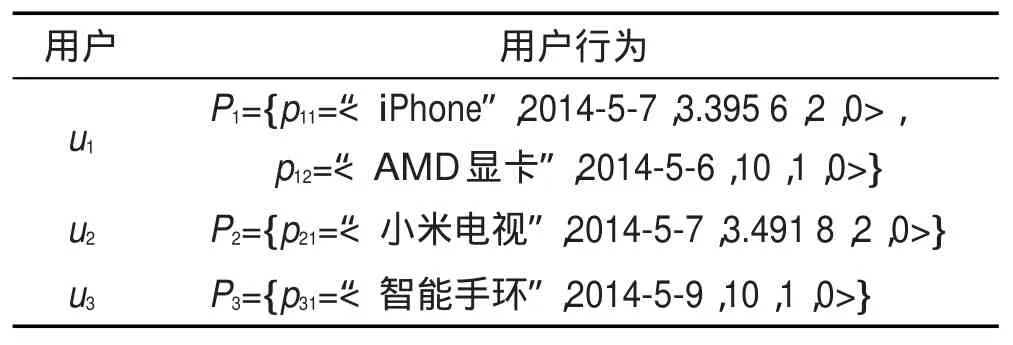
Table 3 User behaviors after updating variables表3 参数更新后的用户行为
由算法1可得到动态用户行为模型中的各参数,算法的时间复杂度取决于Reduce函数,每个Reduce函数处理一个用户的行为数据集。其中For循环执行次数为O(s),排序时间复杂度为O(s lb s),因此算法1的时间复杂度为O(s lb s),s为用户的行为数据记录数。
3.2动态偏好计算
根据3.1节对参数的计算结果,当前用户偏好的强度v由目标时刻距离上次用户行为的时间长度决定。因此,以式(1)为基础,给出用户偏好强度的定义。
定义4(用户偏好强度)目标时刻用户偏好强度的定义如下:

其中:v表示当前时刻偏好强度的大小;TD表示目标时刻,是x之后的某个时刻。
可知,用户的偏好强度在模型参数确定之后,会随时间递减,最终趋于0,代表用户的某一偏好被遗忘而消失。算法2实现了从海量用户行为数据动态获取用户的偏好强度,其基本思想如下:遍历U并找到其中每个ui对应的Pi,计算Pi中每个元素的v值。具体而言,算法中的Map函数获取用户偏好集合,Reduce函数并行地计算Pi中的v值。

算法2的时间复杂度为O(s),取决于Reduce函数,其中s为用户的行为数据记录数。
例如,基于算法2计算用户偏好在2014-5-15时刻的强度。以计算p11为例,其最近一次用户行为到此时刻的时间长度为15-7=8,再根据式(3)计算偏好的强度v=exp(-8/3.395 6)=0.094 7。同理计算其他用户的偏好,如表4所示。
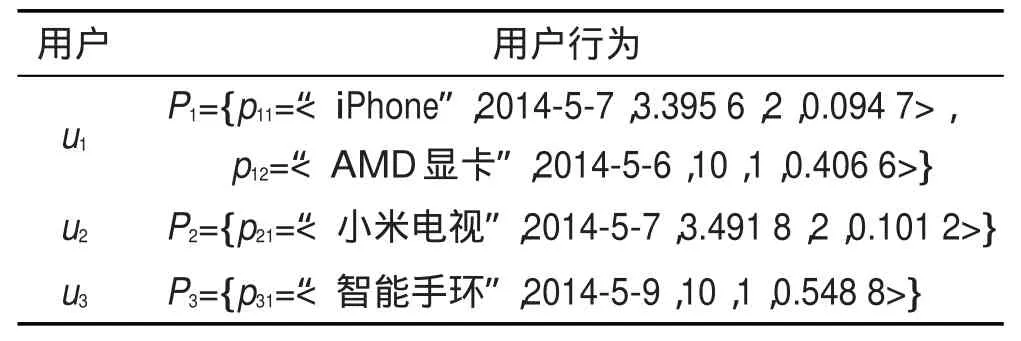
Table 4 User behaviors at 2014-5-15表4 2014-5-15时刻的用户行为
动态用户行为模型能表示偏好随时间推移不断变化的过程,体现偏好强度的动态性,并且模型的参数会根据新的行为数据不断更新,体现参数的动态性,为个性化服务提供支持。
4 实验结果
为了测试本文方法的有效性,从Engadget中国版[18]网站上随机选取超过4 000名用户,通过解析站内所有新闻页面获取用户的评论信息。具体而言,收集了所有相关用户从2014年1月1日到2015年5月1日共1 919 925条评论信息,作为本实验中的用户行为。实验环境如下:1台CPU主频2.3 GHz,内存2 GB的机器作为主节点(NameNode),6台CPU主频3.4 GHz,内存 1 GB的机器作为计算节点(DataNode),路由器总带宽450 Mb/s,基于此构建HadoopMapReduce环境。本文测试了所构建的动态用户行为模型的有效性,以及算法1和算法2的执行时间、加速比和并行效率。实验中对每个指标取多次测试结果的平均值。
4.1模型有效性测试
为了测试所构建模型的有效性,本文将所提出的动态用户行为模型用于新闻推送。从历史行为数据中计算得到的用户行为,若偏好pij中的v大于给定阈值,则将l类的新闻推送给用户ui;若用户点击浏览了推送的新闻,说明新闻推送成功。
本文使用50 000条用户行为数据,70%用于建模,30%用于测试,对查准率(Precision)、查全率(Recall)和F值[21]进行了测试。为了对用户偏好的建模及测试具有一致性,选取整段时间内对新闻都进行了评论的用户(即前70%建模数据和后30%测试数据中都涉及到的用户),进而选取这些用户的行为数据,并且给定用户偏好强度阈值,因此实验中用户数约为350。首先,对传统的用户点击模型(不基于用户行为历史数据,称为“静态模型”)、文献[7]提出的基于线性权重函数的用户模型(称为“线性模型”)以及基于本文所提出模型(称为“动态模型”)得到的新闻推送结果,针对查准率和查全率进行了比较。其中,查准率定义为基于用户偏好成功推送的新闻数占为用户推送新闻总数的比例;查全率定义为基于用户偏好成功推送的新闻数与用户实际浏览新闻总数的比例。由于各模型下得到的测试结果差距较大,本文对查准率和查全率取对数刻度,分别如图3和图4所示。由于用户对新闻的海量评论信息本身具有稀疏性(即用户往往评论了给定新闻页面集合中一个较小的部分),基于不同模型得到的查全率和查准率都不高,图3和图4中的结果与这一实际情形相吻合。不难看出,动态模型的查全率与查准率均高于静态模型,具有较高的新闻推送成功率。
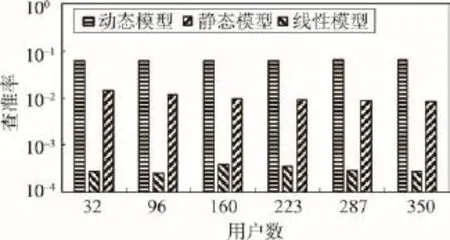
Fig.3 Precision图3 查准率
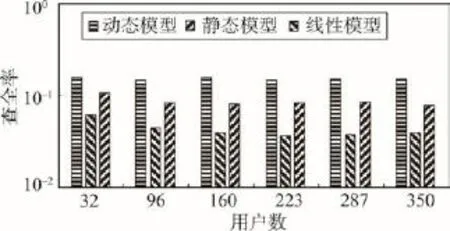
Fig.4 Recall图4 查全率
接着,比较了静态模型和动态模型在进行新闻推送时的F值,F值计算公式如下:

两种模型下F值(对数刻度)的比较如图5所示。可以看出,基于动态模型能得到与传统静态模型相同的稳定性,但基于动态模型的F值明显高于基于静态模型的F值。F值可以反映在新闻推送中推送成功的程度,即使提升很小的幅度,都会对全体用户带来较大的影响,因此动态模型远优于静态模型。
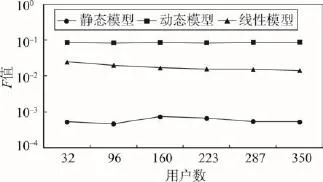
Fig.5 F score图5 F值
4.2模型参数增量更新算法测试
本文使用855 MB、共7 679 700条用户行为数据,在不同计算节点数情形下,对算法1的总执行时间(简称执行时间)进行了测试,结果如图6所示。可以看出,算法1的执行时间随着测试数据集增长呈对数趋势增长,且数据量越大,计算节点越多,算法1的优势越显著。这说明算法1能针对海量用户行为数据进行偏好模型参数的增量更新,具有较好的可扩展性。
Fig.6 AT ofAlgorithm1图6 算法1的执行时间
进一步,对4个计算节点下随着数据量增加算法1中Map函数的执行时间(MT)、Reduce函数的执行时间(RT)以及算法1执行时间(AT)进行了测试,结果如图7所示。由于Hadoop平台处理任务时性能存在波动性,从而可能导致算法执行时间上的波动性(如图7中数据量为153 MB时的情况)。总的来说,在绝大多数情形下,RT都大于MT。这说明算法1的执行时间主要来自其中Reduce函数的执行,与3.1节中的理论分析结论一致。
Fig.7 MT,RT andAT ofAlgorithm1图7 算法1的MT、RT和AT
加速比(Speedup)是算法并行执行时间与串行执行时间的比值,算法1随着测试数据集增大的加速比如图8所示。可以看出,加速比随着测试数据规模增加而增加,且逐渐接近理论最大值(机器数量),这进一步说明算法1具有较好的并行性和可扩展性。并行效率(parallel efficiency)是加速比与处理器数量的比值,算法1随着测试数据集增大的并行效率如图9所示。可以看出,并行效率随着测试数据集增加而增加,并稳定在0.8左右,这也说明算法1具有较好的并行性。
Fig.8 Speedup ratio ofAlgorithm1图8 算法1加速比
Fig.9 Parallel efficiency ofAlgorithm1图9 算法1的并行效率
4.3动态偏好计算算法测试
类似地,本文测试了算法2随着测试数据集增加,在不同计算节点数情形下的执行时间,如图10所示。可以看出,在不同计算节点数下,算法2的执行时间基本呈线性趋势,与3.2节中的理论分析结论一致,且数据量越大,计算节点越多,算法2的优势越显著。算法2执行时的MT、RT和AT如图11所示,与算法1的MT和RT相比较,虽然存在如前所述由于Ha-doop平台的特点而存在执行时间的波动性(如数据规模为390 MB时RT),绝大多数情形下MT和RT占AT的比例基本相同,这说明算法2的Map函数和Reduce函数的执行时间相差不大,计算量基本相当。
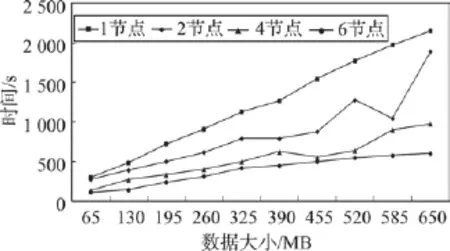
Fig.10 AT ofAlgorithm2图10 算法2的执行时间
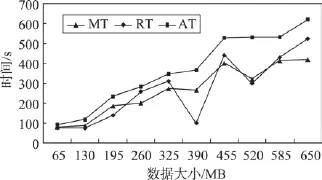
Fig.11 MT,RT andAT ofAlgorithm2图11 算法2的MT、RT和AT
进一步,也测试了算法2随着测试数据集增大的加速比和并行效率,分别如图12和图13所示。可以看出,加速比随着计算节点增加而提升,计算节点数越多,加速比越高;但随着数据量的提升,并行效率随着计算节点数增加而逐渐提升。
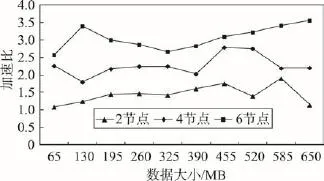
Fig.12 Speedup ratio ofAlgorithm2图12 算法2的加速比
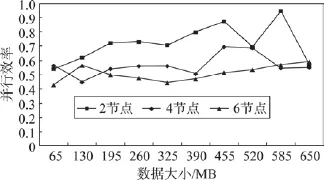
Fig.13 Parallel efficiency ofAlgorithm2图13 算法2的并行效率
5 结束语
本文针对用户行为模型的动态性,基于记忆曲线模型,提出了一种从海量的用户行为数据中构建用户偏好模型的方法,并给出了基于MapReduce的算法,最后通过建立在真实数据上的实验结果验证了本文方法的高效性、可扩展性和有效性。本文的研究为针对带有时间特征的用户行为数据分析和偏好发现提供了一种思路,但作为这一问题的初步探索,针对一段时间内多个时间片的用户行为模型构建、用户不同偏好之间的联系,仍需进一步研究,也是人们将要开展的工作。
References:
[1]Vu Q H,Pham T V,Truong H L,et al.DEMODS:a description model for data-as-a-service[C]//Proceedings of the 2012 IEEE 26th International Conference on Advanced Information Networking and Applications,Fukuoka,Japan,Mar 26-29,2012.Piscataway,USA:IEEE,2012:605-612.
[2]Zhang Yongzheng,Pennacchiotti M.Predicting purchase behavior from social media[C]//Proceedings of the 22nd International World Wide Web Conference,Rio de Janeiro,Brazil,May 13-17,2013.New York:ACM,2013:1521-1532.
[3]Pennock D,Horvitz E,Lawrence S,et al.Collaborative filtering by personality diagnosis:a hybrid memory-and modelbased approach[C]//Proceedings of the 16th Conference on Uncertainty in Artificial Intelligence,Stanford,USA,Jun 30-Jul 3,2000.San Francisco,USA:Morgan Kaufmann Publishers Inc,2000:473-480.
[4]Marin L,Isern D,Moreno A.Dynamic adaptation of numer-ical attributes in a user profile[J].Applied Intelligence, 2013,39(2):421-437.
[5]Hawalah A,Fasli M.Dynamic user profiles for Web personalisation[J].Expert Systems with Applications,2015,42 (5):2547-2569.
[6]Sugiyama K,Hatano K,Yoshikawa M.Adaptive Web search based on user profile constructed without any effort from users[C]//Proceedings of the 13th International Conference on World Wide Web,New York,May 17-20,2004.New York:ACM,2004:675-684.
[7]Xing Chunxiao,Gao Fengrong,Zhan Sinan,et al.A collaborative filtering recommendation algorithm incorporated with user interest change[J].Journal of Computer Research and Development,2007,44(2):2547-2569.
[8]Khader P H,Pachur T,Meier S,et al.Memory-based decisionmaking with heuristics:evidence for a controlled activation of memory representations[J].Journal of Cognitive Neuroscience,2011,23(11):3540-3554.
[9]Ebbinghaus H.Memory:a contribution to experimental psychology[J].Annals of Neurosciences,1913,20(4):155-156.
[10]Yu Hong,Li Zhuanyun.A collaborative filtering recommendation algorithm based on forgetting curve[J].Journal of Nanjing University:Natural Science Edition,2010,46(5): 520-527.
[11]Yin Guisheng,Cui Xiaohui,Ma Zhiqiang.Forgetting curvebased collaborative filtering recommendation model[J]. Journal of Harbin Engineering University,2012,33(1):85-90.
[12]Shmueli-Scheuer M,Roitman H,Carmel D,et al.Extracting user profiles from large scale data[C]//Proceedings of the 2010 International Workshop on Massive Data Analytics over the Cloud,Raleigh,USA,Apr 26,2010.New York: ACM,2010:4.
[13]Feng Naiqin,Tian Yong,Wang Xianfang,et al.Logarithmic and exponential morphological associative memories[J]. Journal of Software,2010,33(1):157-166.
[14]Kudelka M,Horak Z,Snasel V,et al.Weighted co-authorship network based on forgetting[J].Future Information Technology:Communications in Computer and Information Science,2011,185:72-79.
[15]Ye Xiaoming,Lin Xiaozhu,Dai Xiaojuan.The ART2 network based on memorizing-forgetting mechanism[C]//LNCS 6675:Proceedings of the 8th International Symposium on Neural Networks,Guilin,China,May 29-Jun 1,2011.Berlin,Heidelberg:Springer,2011:60-67.
[16]Wang Shan,Wang Huiju,Qin Xiongpai,et al.Architecting big data:challenges,studies and forecasts[J].Chinese Journal of Computers,2011,34(10):1741-1752.
[17]Dean J,Ghemawat S.MapReduce:a fiexible data processing tool[J].Communications of theACM,2010,53(1):72-77.
[18]Liang H,Hogan J,Xu Y.Parallel user profiling based on folksonomy for large scaled recommender systems:an implementation of cascading MapReduce[C]//Proceedings of the 10th IEEE International Conference on Data Mining Workshops,Sydney,Australia,Dec 13,2010.Piscataway,USA: IEEE,2010:154-161.
[19]Engadget[EB/OL].(2015)[2015-06-28].http://cn.engadget. com/.
[20]Lu Weiming,Du Chenyang,Wei Baogang,et al.Distributed affinity propagation clustering based on MapReduce[J]. Journal of Computer Research and Development,2012,49 (8):1762-1772.
[21]Baeza-Yates R A,Ribeiro-Neto B.Modern information retrieval[M].[S.l.]:Addison Wesley,2011:75-79.
附中文参考文献:
[7]邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
[10]于洪,李转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报:自然科学版,2010,46(5):520-527.
[11]印桂生,崔晓晖,马志强.遗忘曲线的协同过滤推荐模型[J].哈尔滨工程大学学报,2012,33(1):85-90.
[13]冯乃勤,田勇,王鲜芳,等.对数-指数形态学联想记忆[J].软件学报,2010,33(1):157-166.
[16]王珊,王会举,覃雄派,等.架构大数据:挑战、现状与展望[J].计算机学报,2011,34(10):1741-1752.
[20]鲁伟明,杜晨阳,魏宝刚,等.基于MapReduce的分布式近邻传播聚类算法[J].计算机研究与发展,2012,49(8):1762-1772.

YIN Zidu was born in 1990.He is a Ph D.candidate at Yunnan University.His research interests include knowledge representation and reasoning,massive data analysis and services.
尹子都(1990—),男,甘肃天水人,云南大学博士研究生,主要研究领域为知识的表示与推理,海量数据分析与服务。

YUN Kun was born in 1979.He received the M.S.degree in computer science from Fudan University in 2004,and the Ph.D.degree in computer science from Yunnan University in 2009.Now he is a professor and Ph.D.supervisor of Yunnan University,and the member of CCF.His research interests include massive data analysis and services.
岳昆(1979—),男,云南曲靖人,2004年于复旦大学获得计算机硕士学位,2009年于云南大学获得计算机博士学位,现为云南大学教授、博士生导师,CCF会员,主要研究为海量数据分析与服务。

WU Hao was born in 1979.He received the Ph.D.degree in computer science from Huazhong University of Science and Technology in 2007.Now he is an associate professor at Yunnan University.His research interests include information retrieval,recommendation system and service computing.
武浩(1979—),男,河南平顶山人,2007年于华中科技大学获得计算机博士学位,现为云南大学副教授,主要研究领域为信息检索,推荐系统,服务计算。

FU Xiaodong was born in 1975.He received the M.S.degree in computer science from Kunming University of Science and Technology in 2000,and the Ph.D.degree in management from Kunming University of Science and Technology in 2008.Now he is a professor at Kunming University of Science and Technology,and the senior member of CCF.His research interests include service computing and intelligent decision.
付晓东(1975—),男,云南镇雄人,2000年于昆明理工大学获得计算机硕士学位,2008年于昆明理工大学获得管理学博士学位,现为昆明理工大学教授,CCF高级会员,主要研究领域为服务计算,智能决策。

LIU Weiyi was born in 1950.He graduated from Huazhong University of Science and Technology in 1976.Now he is a professor and Ph.D.supervisor at Yunnan University,and the senior member of CCF.His research interests include artificial intelligence,data and knowledge engineering.
刘惟一(1950—),男,云南昆明人,1976年毕业于华中科技大学,现为云南大学教授、博士生导师,CCF高级会员,主要研究领域为人工智能,数据与知识工程。
Data Intensive Modeling of Dynamic User Behaviors Based on Forgetting Curve*
YIN Zidu1,YUE Kun1+,WU Hao1,FU Xiaodong2,LIU Weiyi1
1.School of Information Science and Engineering,Yunnan University,Kunming 650504,China
2.Faculty of Information Engineering and Automation,Kunming University of Science and Technology,Kunming 650504,China
E-mail:kyue@ynu.edu.cn
Analyzing historical user behavior data and establishing user preference model by some certain method is the critical subject with great attention.This paper considers the time series characteristics of data generation and the influence of the variables with temporal characteristics on user behavior models.Based on the forgetting curve in psychology,this paper starts from user behavior data and gives the representation of user p
.Thus,a forgetting curve model can be established for each preference and user preferences can be represented by real time manner. Aiming at massive user behavior data,this paper proposes the MapReduce-based algorithms for the incremental update of model parameters and the computation of dynamic user preferences.Thus,inherently dynamic user preferences can be reflected by the constructed user behavior model.The experimental results conducted on real data show that the proposed model and algorithms are efficient,correct and applicable.
dynamic user behavior model;user preference;forgetting curve;incremental update;MapReduce
用户u 1u 2u 3偏好P1= { p11= <“i P h o n e”,2 0 1 4 -5 -4,1 0,1,0 >,p12= <“A M D显卡”,2 0 1 4 -5 -6,1 0,1,0 > } P2= { p21= <“小米电视”,2 0 1 4 -5 -3,1 0,1,0 > } P3= { p31= <“智能手环”,2 0 1 4 -5 -9,1 0,1,0 > }
2015-08,Accepted 2015-11.
10.3778/j.issn.1673-9418.1508049
A
TP311
*The National Natural Science Foundation of China under Grant Nos.61472345,61163003,61462056,61562090(国家自然科学基金);the Natural Science Foundation of Yunnan Province under Grant Nos.2014FA023,2014FA028(云南省应用基础研究计划);the Yunnan Provincial Foundation for Leaders of Disciplines in Science and Technology under Grant No.2012HB004(云南省中青年学术和技术带头人后备人才培养计划);the Program for Innovative Research Team in Yunnan University under Grant No.XT412011 (云南大学创新团队培育计划);the Program for Excellent Young Talents of Yunnan University under Grant No.XT412003(云南大学青年英才培养计划).
CNKI网络优先出版:2015-12-02,http://www.cnki.net/kcms/detail/11.5602.TP.20151202.1349.002.html
YIN Zidu,YUE Kun,WU Hao,et al.Data intensive modeling of dynamic user behaviors based on forgetting curve.Journal of Frontiers of Computer Science and Technology,2016,10(10):1376-1386.
