基于加权词频的I-Match算法改进及其应用分析
——以电商网站为例
2016-10-25尚珊珊
陈 璐 赵 衍 尚珊珊
(1.上海外国语大学国际工商管理学院,上海 201620;2.上海外国语大学信息技术中心,上海外国语大学电子政务国际化研究中心,上海 200083)
基于加权词频的I-Match算法改进及其应用分析
——以电商网站为例
陈璐1赵衍2尚珊珊1
(1.上海外国语大学国际工商管理学院,上海201620;2.上海外国语大学信息技术中心,上海外国语大学电子政务国际化研究中心,上海200083)
介绍网络产品重复评论研究现状;基于I-Match算法,提出一种基于TF词频的重复评论的改进算法;将该算法对某电子商务网站的产品评论进行重复性检测,获得了较理想的效果。
网络评论;重复评论检测;I-Match算法;词频;评论倾向
1 文献综述
对文本内容重复性自动检测技术的研究最早开始于20世纪90年代。从算法的角度可以将文本内容重复性检测技术分为基于语法和基于语义两大类。
1.1基于语法的文本重复性检测
1.2基于语义的文本重复性检测
2 网络产品重复评论识别流程及改进
2.1I-Match算法原理
使用I-Match算法对网络产品评论进行重复性检测的过程如图1。

图1 I-Match改进算法流程图
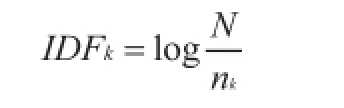
2.2I-Match的改进算法
尽管I-Match算法能够较高准确率的进行识别重复评论检测但检测过于笼统存在一定的误判率。根据网络产品无价值评论的特点对重复评论进行进一步信息挖掘识别评论是否为无意义评论、自我吹嘘评论或者恶意贬低评论。
采用人工或者机器学习的方式建立和维护三种类型词库:无意义评论词库、褒扬评论词库和贬低评论词库。并根据单词的惯用程度对每一类型单词进行分级并为每一级设置权重。本文使用的词库如下:

表1 无意义评论词库

表2 褒扬评论词库

表3 贬低评论词库
改进算法的处理过程如下:
(1)采用I-Match算法识别所有重复的产品评论;
(2)计算每一条评论中单词出现的频率:

(其中ni,j表示该词i在评论j中出现的次数表示所有词出现的次数之和)
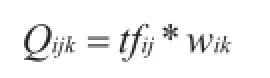
(其中Qijk表示评论j中单词i的k类型倾向权值wik为单词i在词库k中的权重)

(其中Qjk为文档j的k类型评论倾向权值)
(5)取三种类型评论集合的非交集的非交集为真正没有价值的产品评论。
3 实证分析
本文针对国内某电子商务网站中目前热销的iphone6s64G相关评论(截止时间2015年10月21日10:57数据)运用改进的I-match算法对评论进行重复性检测研究。处理过程如下:
表4 产品评论部分截图

表5 选取的研究对象以及评论表
(2)运用中科院ICTCLAS开源[12]中文分词算法对评论进行分词形成评论的单词集合。
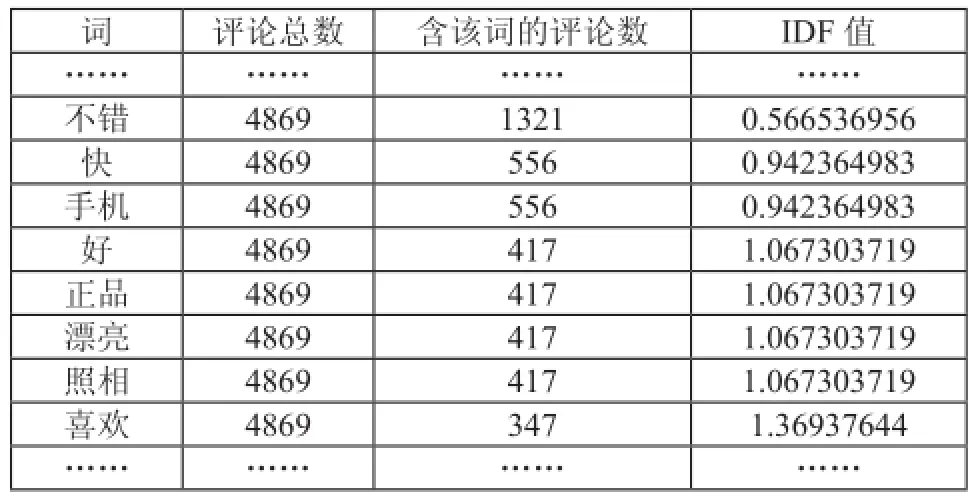
表6 部分词的IDF值以及按降序排列表
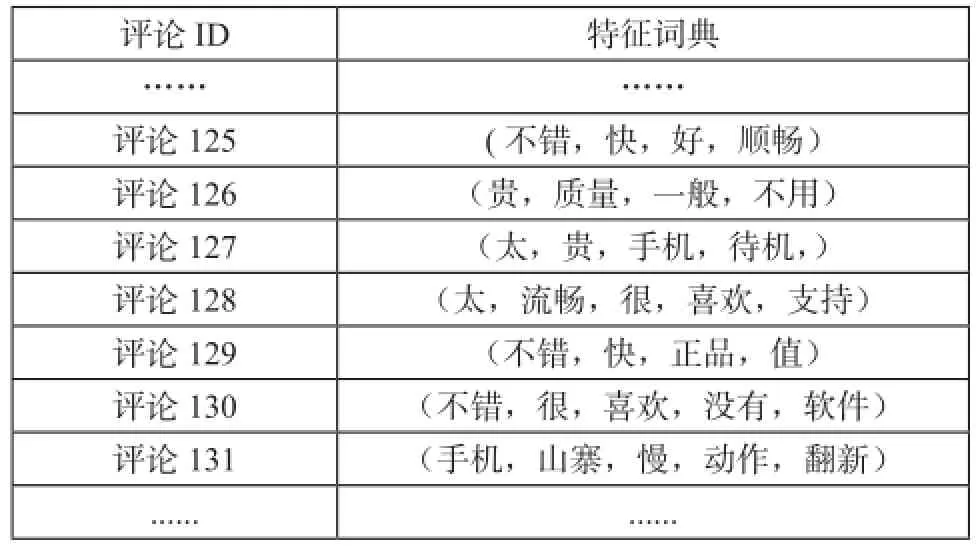
表7 部分评论的特征词典
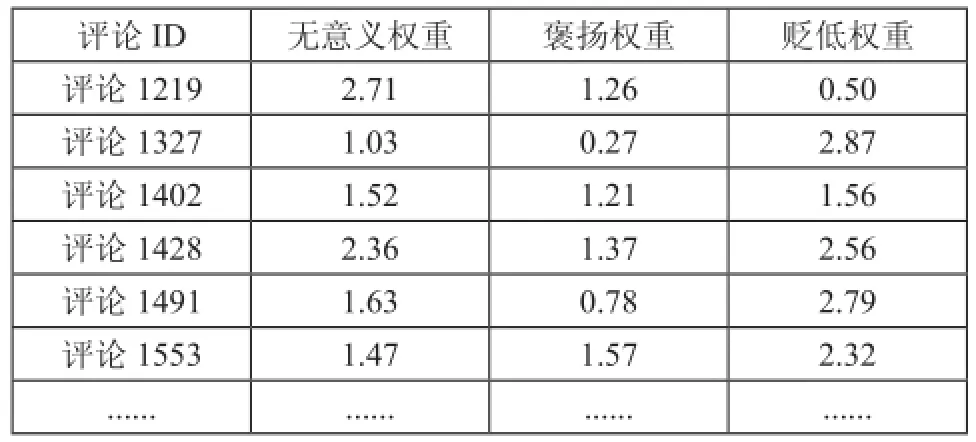
表8 部分重复评论的三种权值列表

表9 iPhone6s 64G无意义、褒扬和贬低重复评论数

表10 查全率和查准率分析
4 结语
本文主要针对电商网站网络产品的重复评论识别进行研究。将广泛使用的I-Match算法应用到网络产品评论的重复性检测。并针对网络评论的特点基于三种类型的词库对I-Match重复性检测结果进行评论的倾向性识别。改进后的I-Match算法提高了检测结果的准确性降低了误判率。
[1]Manber U.Finding similar files in a large file system[C],Proceedings of the Winter USENIX Conference1994:1-10.
[3]Heintze N.Scalable document fingerprinting[C], Proceedings of the2nd USENIX Workshop on Electronic Commerce.1996.
[9]Garcia-Molina HGravano LShivakumar N.dSCAM:Finding document copies across multiple databases[C/OL]. Proceedings of the4th International Conference on Parallel and Distributed Systems(PDIS'96).1996.
[11]Gurmeet Singh Manku, Arvind Jain, Anish Das Sarma.Detecting Near-Duplicates for Web Crawling[C].www2007Track:Data Mining.2007
The Improved I-Match Algorithm based on the Analysis of Weighted Word Frequency and Its Application in the Electronic Commerce Website
Chen LuZhao YanShang Shanshan
Study the recent status of network product duplication.Based on the I-Match Algorithm,proposing an improved algorithm based on weighted word frequency.At last, this improved algorithm is applied into the detecting of a certain electronic commerce website and gets a good result.
network review; detection of repeated comments; the I-Match algorithm;weighted word frequency;comment tendency
TP391
A
1005-9679(2016)01-0051-04
本研究得到2013年上海市哲学社会科学规划课题(编号:2013ETQ001)、上海市教育委员会2014年科研创新项目(编号:14ZS070)、上海外国语大学“2013教学科研团队”项目、上海外国语大学“2014青年教师创新团队”项目(编号:QJTD14ZY001)、上海外国语大学高层次人才发展计划(编号:KX171260)资助。
陈璐上海外国语大学信息管理与信息系统专业本科生; 赵衍上海外国语大学信息技术中心上海外国语大学电子政务国际化研究中心副教授博士;尚珊珊上海外国语大学国际工商管理学院讲师博士。
