一种改进遗传算法在人脸识别中的应用研究
2016-10-22朱洪华
朱洪华
(莆田学院 机电工程学院,福建 莆田 351100)
一种改进遗传算法在人脸识别中的应用研究
朱洪华
(莆田学院机电工程学院,福建莆田351100)
文章通过传统的小波变换和张量主成分分析(PCA)方法对人脸图像进行特征提取,然后研究了一类引入学习过程的新遗传算法.通过改进的遗传算法对PCA提取的特征进一步的优化,最后根据最优特征进行识别,并将之与简单遗传算法和自适应遗传算法进行比较,证明了改进的遗传算法的优越性.
人脸识别;遗传算法;PCA
1 引言
计算机人脸识别技术是利用计算机分析人脸图像,进而对人的脸部进行检测以及确认身份等工作的技术.人脸识别技术是最近几年来计算机图像处理和模式识别领域内最为热门的研究课题之一.主成分分析方法(PCA)是目前人脸特征提取最常用的方法之一.大量的研究表明,由于表情的变化以及光照的不均等等干扰的影响,假如直接对人脸图像特征进行提取,就会使人脸图像的维数很高,所以要对人脸图像进行降维预处理.
遗传算法是生命学科与工程学科互相交叉、互相渗透的结果.它启迪于自然界生物从简单低级到复杂高级以及人类的进化进程,又借鉴了物竞天择、优胜劣汰、适者生存的机理,并引入码串结构,在串与串之间进行有组织的却又随机的信息交换,优秀的品质被渐渐保存并进行组合,进而不断地产生出更优秀的个体,它的本质是一种求解问题的高效并行全局的搜索方法.在自然界的进化进程中,生物体通过遗传、变异来适应外界的环境,一代代地进行优胜劣汰以及繁衍进化.遗传算法模拟上述的进化现象,它把搜索空间映射为遗传空间,也就是把每一个可能的解编码为一个向量,称为一个染色体(或称为个体),向量的每一个元素叫做基因,所有的染色体组成群体(或者称为种群),并按预先设定的目标函数对每个染色体(个体)进行评价,根据得出的结果给出一个适应度值;算法首先以随机的方式产生了一些染色体,这些染色体其实就是我们所要求解的问题的一些候选的解,然后再进行适应度计算,根据计算得出的适应度大小来对各个候选解(也就是染色体)进行遗传操作,主要是进行选择、交叉和变异.遗传算法具有如下的特点[1-2]:
(1)并行性:定义长度短、高适应值模型将按照指数级增长方式代代相传,而且是并行地在执行.
(2)过程性:GA(遗传算法)的遗传操作和自然选择可以增加组织的适应度,遗传算法是模拟和实现进化的一个过程,在这样一种过程当中,算法是没办法判断解空间的个体的具体位置,所以必须要预先设定终止规则才能结束.
(3)不确定性:GA(遗传算法)的随机性为其带来了不确定性,GA(遗传算法)的各个步骤都包含有许多的随机因素在里面.因此在遗传算法的进化过程中,事件的发生或者不发生都是很难确定的.
(4)群体性:GA(遗传算法)具有群体性主要是体现在它由一群而不是单个个体的进化来进行.
(5)统计性:GA(遗传算法)的进化过程都需要通过统计来确定染色体的优秀与否,从而进一步推动进化继续下去.
(6)鲁棒性:GA(遗传算法)的鲁棒性是指算法可以应用于不同的条件和环境,确保其有效,这是因为进化计算具有良好的自适应特点.
(7)整体优化:我们常常采用启发式的策略来找到最优解.在一个单一的猜测解的领域内进行搜索,即便偶尔允许跳到更远的解空间,但是这些启发式的策略也往往会陷入局部最优.GA(遗传算法)的群体性使算法在不同领域搜索解空间的多个点,所以GA(遗传算法)可以找到整体最优解的概率更大.
在求解大规模复杂的条件下的优化问题时,特别适合使用GA(遗传算法).这是因为进化计算是应用达尔文的自然选择方式和进化方式来进行的,这使得它的进化不会受到搜索空间的限制,因此在人脸识别的过程中,采用遗传算法不仅可以获得更高的效率,并且操作更简单方便而且具有通用的功能.为了解决上述的问题,文章研究了一类引入学习过程的新遗传算法.
2 引入学习过程的新遗传算法[3-4]
GA是一种通过生成群体再进行检测的迭代过程,GA采用的是群体搜索方式以及群体之中各个个体之间进行信息交换和搜索.但GA存在诸如早期收敛速度较慢以及后期会在最优解的附近进行振荡等缺点,下面是这类问题的解决方案.
(1)改进和协调进化过程中的交叉算子和变异算子的使用.我们可以反进化的过程分为两个阶段:渐进进化和变异,并使用不同的设计方法对新的交叉算子和变异算子进行设计.
(2)为了解决算法的局部搜索能力差的问题,可以使用全局搜索和局部搜索相相结合的混合式遗传算法.
(3)为了解决单一的群体更新方式导致的多样性和收敛性的问题,可以采用设定一定的条件的父代替代的方法.
(4)为了解决收敛速度慢的问题,我们可以采用以下方式来改进算法:
①初始种群的改良,产生更好的种群
②应用小生境技术对算法进行改进
③应用移民技术对算法进行改进
④通过使用动态的参数编码对算法进行改进
2.1引入学习过程的遗传算法的论证[3-4]
(1)引:用基本遗传算法求函数f(x)=x2在区间[0,63]上取得最大值的解X.
在[0,63]区间上的X可以使用六位二进制数对其进行编码,例如
变量X=0对应000000数字串
变量X=16对应010000数字串
变量X=32对应100000数字串
变量X=40对应101000数字串
变量X=63对应111111数字串
本例中我们选取的群体规模N为4来进行随机实验,产生了四个数字串个体:001101,011000,001000,010011,由这四个数字串来组成初始群体,如表1所示.
这四个数字串个体经过遗传算法的遗传操作之后,我们可以得到新的一代群体:001100,011001,011011,010000,如表2示.
综上所述,我们可以考虑由高适应度的染色体向低适应度的染色体学习,这样我们就可以最大限度地保留优秀的短距模式(**1**).另一方面,为了使算法能够更快地趋于收敛,我们可以让低适应度的染色体向高适应度的染色体进行学习.

表1 初始的种群和适应度

表2 经过第一次遗传操作之后的结果
(2)自从1962年GA诞生以来,出现了许许多多、形形色色的改进的遗传算法,但是这些方法都仅仅局限于在个体的竞争机制之中进行优化.我们可以从生物以及人类社会的发展过程中得到启发,种群的发展不仅仅需要竞争,而且还要通过人与人之间之间的合作和互相学习,这样才能让社会进一步发展下去.种群的发展也不仅仅只取决于个人(个体)的先天血统(先天性因素)好坏,还会受到后天环境(同代个个体之间互相学习和合作)的影响.综上,我们可以考虑在GA的复制算子、交叉算子和变异算子的基础上再引入学习的过程,使算法进一步优化.
(3)具体步骤如下:
1、对参数进行编码;
2、初始种群的生成;
3、进行适应度值的计算,并由此来判断符合不符合条件.如果符合条件则进行解码,完成寻优过程;如果不符合条件则转到下一步骤;
4、个体之间进行复制、交叉以及变异操作;
5、个体进行互相学习;
6、新种群的生成,并转到步骤3继续进行.
该算法的基本原理是:首先我们在这新的一代的群体中识别区分出两个染色体群,一个是比较好的染色体群,另一个是比较劣质的染色体群,并使这两个染色体群进行随机的相互学习.然后提出了两个学习概率PL1和PL2.
PL1:比较劣质的染色体向比较好的染色体学习的概率.
PL2:比较好的染色体向比较劣质的染色体学习的概率.
假设群体的规模大小为N,终止进化的代数设为G,学习的方式分为以下三个步骤:
(1)把整个群体中的个体按照适应度的大小进行排序,从小到大可以分为1到N/2的染色体(前一半的染色体)和1+N/2到N的染色体(后一半的染色体),其中前一半的染色体组成的群体是比较劣质的子群体,而后一半的染色体组成的群体是比较好的群体.
(2)确定互相学习的概率:
①为了避免早期较劣质的染色体向比较好的染色体过度学习造成模式上的垄断,导致过早收敛,所以早期的PL1(比较劣质的染色体向比较好的染色体学习的概率)应该取的比较小.
②为了避免比较好的染色体造成模式上的垄断,以及比较劣质的染色体可能被消除而使一些比较好的模式损失掉,从而降低了群体的多样性,所以早期的PL2(比较好的染色体向比较劣质的染色体学习的概率)应该取的比较大.
③为了避免后期在最优解附近振荡的问题,应该增加PL1(比较劣质的染色体向比较好的染色体学习的概率),减小PL2(比较好的染色体向比较劣质的染色体学习的概率).
我们假设PL1和PL2的初始值设为为PL10和PL20,
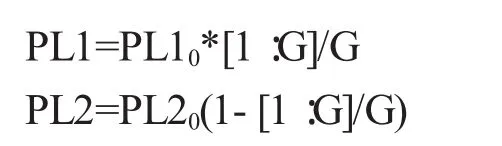
从上面的公式中,我们可以发现,随着进化的开展PL1会渐渐变大,而PL2会渐渐变小.
(3)学习方式:较劣质的染色体群与较好的染色体群之间进行随机的相互学习,下面我们用二进制编码为例子来说明染色体体之间是如何相互学习的.假设b1=011000为适应度值较低的染色体体,b2=110111为适应度值较高的染色体体.b1向b2学习的概率为PL1,即产生一个c(c为0~1的随机数),若PL1>c,则将b1中的一位随机的用b2代替掉.假设是第2位的话则可以得到下面的结果:
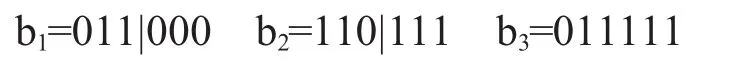
b3为经过学习之后产生的新个体.以上是单点学习的方法.如果编码的长度较长,也可以可考虑多点学习的方式,方法跟单点学习的方法类似.
3 仿真研究
3.1人脸图像特征提取[5]
由于光的照射、表情的变化和配件的变动等因素都会影响到原始的人脸图像,使得图像的维数偏高.所以为了降低图像的维数就必须在人脸识别过程中对图像进行预处理,从而达到将图像中的干扰信息消除掉的目的.本次仿真我们使用的是小波变换来对图像进行预处理.通过预处理之后,我们可以得到四个子图,其中有一个低频子图和三个高频子图(垂直方向、水平方向、对角线方向各一个),而且通过预处理之后的子图的长度和宽度都变成原图的一半,后面的小波变换都是根据上一层的子图进行操作.
3.2实验采用的人脸库
本次实验我们采用的是ORL标准人脸库,该库是由40个人,每个人10幅图像(像素为112X92)组合而成.图1是ORL人脸库中部分图像.

图1 ORL标准人脸库中的部分人脸图像
3.3实验结果
三类遗传算法参数选取如下:群体规模的大小为30;终止代数为150;交叉的概率A1=0.80,;变异的概率A2=0.05;学习的概率为PL1=0.2*[1:G]/G PL2=0.8(1-[1:G]/G).
3.4结果与分析
从表3中可知,与普通遗传算法和自适应遗传算法进行比较,我们可以发现新遗传算法识别的精度最高,达到了97.7%,而且收收敛速度更快.这主要是因为引入学习过程的新遗传算法极大地增强了算法的全局搜索能力;增加了群体的多样性,同时又避免陷入局部最优,并使收敛速度更加快.
〔1〕王晓平,曹立明.遗传算法-理论、应用于软件实现[M].西安:西安交通大学出版社,2002.1.
〔2〕薛景浩,章毓晋,林行刚.二维遗传算法用于图像动态分割[J].自动化学报,2000,26(5):685-689.
〔3〕雷英杰,张善文,李续武.MATLAB遗传算法工具箱及其应用[M].西安:西安电子科技大学出版社,2005.22-30.
〔4〕胡艳艳,蔡建立.一类新遗传算法[J].厦门大学学报(自然科学版),2006(5).
〔5〕吴建龙;罗海兵.遗传算法在人脸识别中的应用研究[J].计算机仿真,2010(12).
TP317.4
A
1673-260X(2016)09-0017-03
2016-04-13
