基于多种输出嵌入结合的无标签图像分类
2016-10-17卢建军刘志鹏
何 琪,卢建军,刘志鹏
(西安邮电大学 a.通信与信息工程学院;b.经济与管理学院, 陕西 西安 710121)
基于多种输出嵌入结合的无标签图像分类
何琪a,卢建军b,刘志鹏b
(西安邮电大学 a.通信与信息工程学院;b.经济与管理学院, 陕西 西安 710121)
利用多种输出嵌入相结合的方法,改善无标签图像的分类性能。以边信息作为标签嵌入,用图像特征作为输入嵌入,在标签嵌入和输入嵌入之间构建一个联合兼容函数,建立结构化联合嵌入框架。通过调整联合嵌入的权重矩阵,使兼容函数取得最大值,据此确定图像的分类。借助两个数据集进行的验证,实验结果显示,多种输出嵌入结合的图像分类方法准确率优于单输出嵌入的图像分类方法。
图像分类;标签嵌入;输出嵌入
大规模数量集如ImageNet[1]的出现,使得卷积神经网络[2]等深度学习[3-4]方法在大规模视觉识别中处于主导的地位,然而,卷积神经网络的训练过程需要大量的标签数据,对于无标签数据的图像分类卷积神经网络就有了局限性,因此需要与对象类相关的可替代的信息源。针对这一问题,本文采用边信息[5]作为对象类的信息源,进行标签嵌入[6]即输出嵌入。标签嵌入是一种有效模拟类别之间潜在关系的工具,主要包括独立数据嵌入、学习嵌入和边信息嵌入3种类型,本文只针对于边信息嵌入进行分析说明。本文介绍属性嵌入、文本嵌入和层次结构嵌入3种类型的边信息嵌入作为输出嵌入,因为不同的输出嵌入封装了图像的不同信息,为了获得更加完备的图像信息,通过串联或者并联的方式将多种输出嵌入进行结合,与单输出嵌入进行实验分析比较,在AWA[7]和CUB[8]两个数据集上进行验证,实验结果表明:多种输出嵌入相结合的图像分类准确率高于单输出嵌入的图像分类准确率。
结构化支持向量机(SVM)[9]是应用于图像分类的一种通用方法,该方法是对带标签的图像进行训练学习的,然而,标签的缺失限制了它在无标签图像分类中的应用,因此,基于标签嵌入技术和结构化支持向量机的原理,本文将标签嵌入和结构化支持向量机相结合,形成了结构化联合嵌入(SJE)框架。将图像特征作为输入嵌入,边信息作为输出嵌入分别映射到输入和输出嵌入空间,在输入输出空间建立一个兼容函数,通过对权值矩阵W的学习,使得输入嵌入输出嵌入达到最高的匹配。
本文采用深度卷积神经网络(CNN)和费舍尔向量(FV)[10]两种算法对图像进行特征提取,并对密集SIFT特征进行了优化。在2004年,DG Lowe提出了具有角度不变性的密集SIFT特征,该方法能够对少数收敛点进行特征提取,但当图像缺少纹理或者亮度较低时,特征提取效果不太理想。因此,本文采用了按网格点来提取SIFT特征的方法,从而得到图像的D-SIFT[11]特征,提高图像特征提取的准确度。
1 结构化联合嵌入框架
1.1模型

结构化联合嵌入框架如图1所示。

图1 结构化联合嵌入框架
在输入空间X和结构化输出空间Y之间,定义了一个兼容函数F:X×Y→R,给定一个特定的输入嵌入,在SJE结构中通过兼容函数F最大化得到一个预测值,如下

(1)
式中:W是D×E的矩阵,D代表输入嵌入的维度;E代表输出嵌入的维度。因此,兼容性函数F的双线性形式如下
(2)

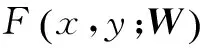
(3)
则此时输入输出的联合嵌入在一个相同的R维数空间上。
1.2参数学习
根据结构化支持向量机公式,目标是
(4)
(5)
(6)
式中:ηt是迭代t的学习步长。
1.3联合输出嵌入学习
每个输出嵌入捕获输出空间的不同方面,提供关于输出空间简短的信息,通过将多种输出嵌入结合起来得到一个更好的联合输出嵌入。则联合输出嵌入的兼容函数如下
(7)
约束条件为
∑KαK=1
(8)
式中:W1…WK是联合嵌入的权重矩阵,WK对应于第K个输出嵌入φK。先单独训练WK,之后在验证集上对αK进行网格搜索。
2 输出嵌入
2.1属性嵌入
属性[5,8]模拟了对象的共同特征,例如颜色、纹理、形状和空间联系等,这些属性通过众包技术[12]很容易获得。属性通过共享的对象特征将不同的类联系起来,一般通过人工来标注,并且转换成机器可读的矢量格式。描述性的属性集可以通过语言专家[9]来决定属性和类别之间的关系,其可能是一个二进制值φ0,1,它描述一个属性的存在/不存在,或者是一个连续值φA,它定义每个类的属性置信水平[8]。每个类的属性如下
(9)
ρy,i表示类和属性之间的连接关系,用实数或者二进制数表示,y代表类,E代表与类相关的属性数量。φA可能比φ0,1编码更多的信息。例如,以老鼠,猫和鲨鱼3类的大小作为属性,φ0,1={0,0,1}表示就体积而言,老鼠=猫<鲨鱼,然而φA={2,10,90}表示老鼠<猫<鲨鱼,其结果更加准确。
2.2文本嵌入
GloVe[13](φg):通过对经常在文档中一起出现的单词进行统计编码,语义相似的单词如“眉毛”和“眼睛”一起出现的频率比“眉毛”和“高楼”一起出现的频率要高。通过训练学习词向量使得这两个单词的点积等于它们同现的概率。
Bag-of-Words[14](φb):BoW通过计算每个单词在文档中出现的频率构建一个单词频率包,不保留每个单词在文档中出现的顺序。笔者收集与对象类相对应的维基百科文章,对出现频率较高的单词构建一个词汇表,最后建立这些单词的直方图使这些对象类向量化。
2.3层次结构嵌入
根据类的分类顺序[15]作为层次结构输出嵌入,这种分类可以从预定义的本体WordNet[1]中自动构建。在这种情况下,通过语义相似度来测量节点之间的距离。最后,从大量无监督的文本语料库中得到分布式文本表示作为层次结构嵌入。用φh表示类层次嵌入。
3 实验
3.1实验设置
在Caltech UCSD Birds(CUB)和Animals With Attributes(AWA)两个数据集中对结构化联合嵌入SJE进行实验分析, CUB数据集包含200种鸟的11 789张图像, AWA数据集中包含50种不同的动物的30 475张图像,在训练集和验证集上进行交叉验证,即训练不相交的子集。实验将CUB数据集中的150类作为训练集加验证集,其余50个不相交的类作为测试集。AWA有一个预定义分类, 40类为训练集加验证集,10类为测试集。
3.1.1输入嵌入
采用费舍尔向量(FV)和深度卷积神经网络(CNN)两种算法对图像进行特征提取,FV对每张图像进行统计,计算从本地图像补丁到固定长度的图像描述子。从多尺度正则网格中提取64维的D-SIFT特征,通过主成分分析算法(PCA)[16]将它们减少到32维,用128高斯模型构建一个视觉词汇表,最后费舍尔向量减少到2 048。同样,采用深度卷积网络进行特征提取时,这些特征通常是从充分激活的连接层中获得。将每个图像调整到112×112并传入由AlexNet[4]或者GoogLeNet[17]模型框架预先训练好的网络。AlexNet(记为CNN)模型用2 048维激活的顶层隐藏单元作为特征,而GoogLeNet(记为GOOG)模型则用512维顶层池化单元作为特征。这两种网络是用BVLC[18]实现的。
3.1.2输出嵌入
AWA类有85个二进制和连续属性,CUB类有312个连续属性二进制属性。
用英文维基百科对GloVe模型进行训练,首先通过更换类名对它进行预处理,即用学名替代特殊类名,再交叉验证嵌入的维度。对于BoW模型的训练,首先下载与每个类相对应的维基百科文章,并且通过删除低频和高频词汇来构建一个词汇表,然后交叉验证词汇表的大小。当这些词汇出现在对应的文档中时,则构成词汇表中单词的直方图。
层次结构嵌入模型使用的NLTK库来建立层次结构并测量节点间的相似性,因此,每个向量表示类与其他类的相似性程度。
3.1.3输出嵌入的结合
将监督属性、无监督GloVe、BoW、层次结构嵌入4种输出嵌入通过串联(cnc)或者并联(cmb)形式相结合。以AWA为例, 45维φA和200维φb串联时,构成245维的输出嵌入,以1 024维的GOOG作为输入嵌入,则只需要对1 024×245维的W进行学习,如果是并联,需要对1 024×45维的WA和1 024×200维的WB分别进行学习,再对系数α交叉验证。
3.2实验结果
3.2.1离散属性对比连续属性
属性用一个类向量表示,向量代表了各属性存在和缺失或者各属性的置信水平。在表1中, 在图像的深层特征方面,φA比φ0,1更好地表明了连续属性比二进制属性拥有更多的语义编码。总的来说,CNN优于FV,然而GOOG给出了最优的结果。
表1离散属性和连续属性对比结果 %

模型AWA准确率CUB准确率φ0,1φAφ0,1φAFV33.539.312.515.6CNN42.257.926.837.1GOOG48.760.733.746.9ALE[10]41.645.318.622.7
对表1进行分析,在CUB中,φA的准确率达到46.9%,远高于之前的22.7%,此外,φ0,1的准确率为33.7%也高于之前的18.6%。 AWA也有同样的趋势。对φ0,1和φA进行分析得到,应用深层神经网络提取特征,φA的分类性能明显比φ0,1好,这表明,结构化联合嵌入方法对W矩阵进行学习时,φA比φ0,1具有更好的图像和边信息的兼容性。
3.2.2文本嵌入
随着不同类的对象之间视觉相似度的不断增加,属性的收集成本也在增加,因此,从无标签的在线文本资源中自动提取类相似度很有必要。每种输出嵌入得到分类效果如表2所示。
表2结构化联合框架下的有监督和无监督的输出嵌入比较

方式来源φAWA准确率/%CUB准确率/%无监督文本φg55.721.4文本φb41.222.9WordNetφh48.918.9有监督人工φ0,149.534.4人工φA63.147.6
在表2中,AWA准确率最高的是φg(55.7%),高于之前有监督的45.3%(表1),CUB准确率最高的是φb(22.9%),超过了之前有监督的22.7%(表1),但在φg和φb之间没有优劣关系。
3.2.3层次结构嵌入
概念的层次结构通常体现了语言的一部分隐含信息,比如同义、语义关系等。通过类之间的层次距离定义语义相关性,其构成的数值向量将用于图像分类学习的输出嵌入。WordNet层次结构包括CUB的319个节点(200个类),AWA的104个节点(50个类),采用相似度测量方法来测量类之间的距离。
φh最高的准确率是48.9%(表2),这个值是紧随φ0,1(49.5%)之后并高于φb(41.2%),对于CUB,φh是18.9%(表2),仍在φ0,1(34.4%)之下,但接近φb(20.3%)。
3.2.4输出嵌入结合
表2汇总了每种输出嵌入得到的结果,因为不同的嵌入试图封装不同的信息,所以若将属性嵌入、文本嵌入和层次结构嵌入3种输出嵌入结合,图像分类的准确率应该会提高。本文将多种输出嵌入通过cnc或cmb两种方式进行连接。cnc将执行全部的结构化联合嵌入训练并对串联输出嵌入进行交叉验证,而cmb将对每个并行输出进行联合嵌入的学习并且通过交叉验证来找到整体的权重。与cnc方法相比,cmb可以提高性能,同时不需要用额外的联合训练。观察表3可知,在大部分情况下,cmb都优于cnc。
表3多种输出嵌入结合比较

输出嵌入AWA准确率/%CUB准确率/%φAφgφbφhcnccmbcnccmb—√—√57.256.925.626.3——√√46.645.723.324.4√√—√68.569.338.747.9√—√√65.867.237.746.8
在表3中,首先对无监督嵌入的结合进行分析, 在AWA数据集中,φg(55.7%,表2)与φh(48.9%,表2)结合,准确率达到57.2%(表3),与之前的(45.3%,表1)相比,准确率有所提升。对于CUB数据集,φg和φh结合,准确率达到26.3%(表3),高于之前有监督的准确率(22.7%,表1),实验结果表明,从文本和层次结构获得的无监督输出嵌入是可以互相补充的。在大部分情况下,cmb比cnc的准确率更高或者基本持平。有监督嵌入(φA)和无监督嵌入(φg,φb,φh)的结合显现出相似的趋势。对于AWA,将φA,φg和φh结合,准确率达到69.3%,高于之前的45.3%(表1)。对于CUB,将φA,φg和φh结合,准确率达到47.9%,超过了之前有监督的22.7%(表1)。这些实验表明,在结构化联合嵌入框架中,通过人工标注获得的有监督输出嵌入也能与无监督输出嵌入相互补充。
对结构化联合嵌入框架的有监督属性嵌入和从层次结构和无标签文本语料库中获得的无监督输出嵌入进行实验分析,通过结合多个输出嵌入,建立了一个关于AWA和CUB的表格,如表4所示。
表4SJE框架最优的分类结果

方式方法AWA准确率/%CUB准确率/%无监督SJE57.226.3有监督SJE69.347.9
实验结果表明,结构化联合嵌入的无监督的图像分类在原来基础上得到了改善,AWA达到了57.2%,CUB达到26.3%。
4 小结
本文提出了多种输出嵌入相结合的方法,将多种输出嵌入通过串并联的方式进行连接,同时,采用了优化的D-SIFT对图像的特征进行提取,并将标签嵌入和支持向量机通过兼容函数结合起来。实验表明,多种输出嵌入相结合的方法能很好地实现图像分类,提高了分类的准确性。当然,本文仍有进一步研究的空间,在下一步的工作中,主要研究如何从文本中得到更好地表示图像特征的输出嵌入方法。
[1]DENGJ,DONGW,LIFF.Imagenet:alargeVscalehierarchicalimagedatabase[C]//IEEEComputerSocietyConferenceonComputerVisionandPatterRecognition.Miami,USA:IEEE,2009:248-255.
[2]许可.卷积神经网络在图像识别上的应用研究[D].杭州:浙江大学,2012:10-37.
[3]李卫.深度学习在图像识别中的研究及应用[D].武汉:武汉理工大学,2014:27-34.
[4]KRIZHEVSKYA,STUSKEVERI,HINTONG.Imagenetclassificationwithdeepconvolutionalneuralnetworks[C]//The25thAnnualConferenceonNeuralInformationProcessingSystems.Nevada,US:MIT,2012: 1106-1114.
[5]FERRARIV,ZISSERMANA.Learningvisualattributes[C]//The20thAnnualConferenceonNeuralInformationProcessingSystems. [S.l.]:MIT, 2007: 433-400.
[6]AKATAZ,PRRRONNINF,SCHMIDC.Labelembeddingforimageclassification[EB/OL].[2015-08-28].http://arxiv.org/pdf/1503.08677.pdf.
[7]PERONAP,BRANSONP,BELONGIES.Multiclassrecognitionandpartlocalizationwithhumansintheloop[C]//IEEEInternationalConferenceonComputerVision. [S.l.]:IEEE, 2011:2524-2531.
[8]LAMPERTC,NICKISCHH,HARMELINGH.Attribute4-basedclassificationforzeroVshotvisualobjectcategorization[J].IEEEtransactionsonpatternanalysisandmachineintelligence, 2013,36(3):435-465.
[9]TSOCHANTARIDISI,JOACHIMST,ALTUNY.Largemarginmethodsforstructuredandinterdependentoutputvariables[J].Journalofmachinelearningresearch, 2005,6:1453-1484.
[10]PERRONNINF,DANCEC.Fisherkernelsonvisualvocabulariesforimagecategorization[C]//IEEEComputerSocietyConferenceonComputerVisionandPatterRecognition. [S.l.]:IEEE,2007: 332-340.
[11]张帆.基于密集SIFT特征及其池化模型的图像分类[D].长沙:中南大学, 2014:18-22.
[12]DENGJ,KRAUSEJ,LIFF.Fine-grainedcrowdsourcingforfine-grainedrecognition[C]//IEEEComputerSocietyConferenceonComputerVisionandPatterRecognition. [S.l.]:IEEE,2013:580-587.
[13]PENNINGTONJ,SOCHERR,MANNNINGCD.Glove:Globalvectorsforwordrepresentation[C]//Proc.ConferenceonEmpiricalMethodsinNaturalLanguageProcessing. [S.l.]:ACL,2014:1532-1543.
[14]吴丽娜.基于词袋模型的图像分类算法研究[D].北京:北京交通大学,2013:18-29.
[15]胡广寰.基于内容图像检索中图像语义技术分类研究[D].杭州:浙江大学,2015:12-35.
[16]邢杰,萧德云.基于PCA的概率神经网络结构优化[J].清华大学学报(自然科学版),2008,48(1):141-144.
[17]SZEGEDYC,LIUW,JIAYQ.Goingdeeperwithconvolutions[EB/OL].[2015-09-17].http://arxiv.org/pdf/1409.4842.pdf.
[18]JIAYQ,SHELHAMERE,DARRELLT.Caffe:convolutionalarchitectureforfastfeatureembedding[EB/OL].[2015-09-02].http://arxiv.org/pdf/1408.5093.pdf.
责任编辑:闫雯雯
Unlabeled image classification based on multiple output embeddings
HE Qia,LU Jianjunb,LIU Zhipengb
(a.SchoolofCommunicationandInformationEngineering;b.SchoolofManagementEngineering,Xi’anUniversityofPostsandTelecommunications,Xi’an710121,China)
By using the method of combining multiple output embeddings, the performance of unlabeled image classification is improved. Side information is used as label embedding and image features are used as output embedding, by introducing a joint compatibility function between label embedding and output embedding, the structured joint embedding framework is established. By adjusting the weighting matrix to make the compatibility function to the maximum, and thus the image classification is determined. Validation with two data sets, the experiment results show that the image classification method of combining multiple output embeddings has superior accuracy to that of using the single output embedding.
image classification;label embedding;output embedding
TP309
A
10.16280/j.videoe.2016.09.027
2015-11-05
文献引用格式:何琪,卢建军,刘志鹏. 基于多种输出嵌入结合的无标签图像分类[J].电视技术,2016,40(9):132-136.
HE Q,LU J J,LIU Z P. Unlabeled image classification based on multiple output embeddings [J]. Video engineering,2016,40(9):132-136.
