超高速全并行快速傅里叶变换器
2016-10-13陈杰男袁建生曾维棋胡剑浩
陈杰男 费 超 袁建生 曾维棋 卢 浩 胡剑浩
超高速全并行快速傅里叶变换器
陈杰男 费 超 袁建生 曾维棋 卢 浩 胡剑浩*
(电子科技大学通信抗干扰国家级重点实验室 成都 611731)
设计和实现超高速快速傅里叶变换器(FFT)在雷达与未来无线通信等系统中具有重要意义。该文提出首个全并行架构的FFT处理器,其避免了复杂的路由寻址以及数据访问冲突等问题,基于较大基进行分解降低运算复杂度。由于旋转因子已知和固定,大量的乘法转化为了定系数乘法。同时由于采用了串行的计算单元,在达到全并行结构的高速度同时硬件复杂度相对较低;所有的硬件计算单元处于满载的条件,其硬件效率能达到100%。根据实际的实现结果,所提出的512点FFT处理器结构能够达到5.97倍速度面积比的提升,同时硬件开销仅占用了Xilinx V7-980t FPGA 30%的查找表资源与9%的寄存器资源。
快速傅里叶变换;全并行;比特串行计算;常系数乘法
1 引言
FFT(Fast Fourier Transform)作为技术核心之一广泛应用于雷达以及无线通信领域。由于现有设计的吞吐率限制,系统中需要多个FFT单元协同处理。例如4G LTE(Long Term Evolution)中,需要近10套FFT以满足信号接收、信道估计与均衡等处理需要;而在未来5G移动通信系统中,Massive MIMO(Multiple Input Multiple Output)接收端可能需要多达64~128路FFT支持。为满足未来5G中低时延高吞吐率的需求,探究新的实现结构,以进一步提升FFT计算速度十分必要。
传统FFT实现技术主要分为两大类:基于流水线脉动结构与基于存储器寻址结构。基于流水线的结构利用了FFT计算的规整性进行设计,但计算时间难以提升很难满足未来高速处理需求。而基于存储器的FFT处理结构普遍采用部分并行的策略来提升处理速度,但在面积上又有相应增加。
并行作为一种“面积换时间”的策略,可以从结构上提升系统吞吐率,但在FFT传统实现方式中应用非常具有挑战。首先点FFT需要至log2次复数乘法,并行带来硬件复杂度较高。其次并行度提升后数据寻址、访问与调度困难较大,数据冲突难以克服。为折中面积与处理速度,文献[11]提出一种比特串行计算结构以面向低功耗场景。
在本文中,一种“结构全并行,计算基于比特级粒度”的FFT设计策略被提出,由全并行的结构得到较大的吞吐率提升,由串行化的计算单元缩减硬件面积。假设处理点字长为bit的FFT,全并行结构在一个时钟得到全部点结果,而比特串行结构将这一个时钟的计算分解到个时钟。此外,全并行结构利用较大基分解以降低乘法数量,其固定的数据连线可以规避数据路由、寻址冲突等问题,固定的旋转因子可以使用常系数乘法优化。关键路径降低至加法器数量级,系统频率得以提升。采用该设计方法的512点FFT处理器在Xilinx V7-980t上能够达到9.931 GS/s的吞吐率,硬件开销上LUT资源占总资源的30%,寄存器资源占9%。计算精度与16 bit定点FFT处理器相同,速度面积比是已有设计的5.97倍。
本文第2节介绍FFT分解算法;第3节阐明基于比特串行计算结构的全并行FFT实现;第4节给出主要结果与讨论。
2 FFT分解算法
点离散傅里叶变换(DFT)以及旋转因子表达式分别为
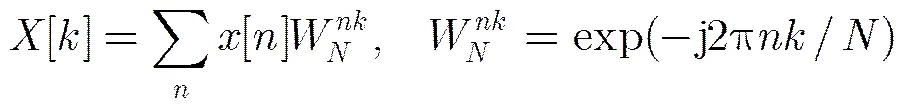
(2)
当分解因子不互质时,根据CTA算法[9]得(3)先进行1点FFT之后进行一次旋转因子调整,之后再进行2点计算。

3 基于位串架构的全并行FFT设计
3.1 全并行FFT结构
如前文所述,FFT可以依据算法迭代分解,设分解为级,其中第级处理/N个N点FFT,,分解算法为CTA时需要进行旋转因子调整,为PFA时只需要对数据进行合适连线。图1所示为比特串行架构的64点全并行FFT示例图,64点被分解为两级8点FFT, 8点又被进一步分解为4点×2点。数据在每个时钟分别逐比特输入,其输入顺序按CTA算法排列。
图1 64点全并行FFT结构示例图
3.2 串行计算单元设计
如图1中给出了基于比特串行的2点FFT运算单元示意图。输入0和1路在每个时钟输入一个比特。输入1路的数据逐比特输入串行乘法器,完成与旋转因子的乘法后分别输入到加法器和减法器;输入0路数据输入到流水乘法器延迟补偿器,经过一定数量延迟后输出。加法器和减法器串行完成两路输入相加及相减。位串加法器由全加器、进位寄存器与2-to-1 MUX构成。对字长为bit的输入,最低位LSB首先进行计算,此时进位选择为0,之后进位都连接寄存器输出。下一个字输入时依次循环。单比特减法器与加法器功能相似,只是将减数路取反,同时每个计算周期第一拍时钟初始进位设为1,等效于对减数的二进制补码取反再加1。
比特串行乘法器用于将串行输入的数据与FFT旋转因子完成乘法后再串行输出。在不充分进行符号位拓展的情况下,二进制补码乘法无法直接利用序列移位相加来计算,由文献[12],利用移位加形式以及部分积截断可以实现常系数乘法。如图2(a)所示,基于CSD数(1.0-01)CSD表示的常系数乘法的竖式表达式,其中“-”表示权重“-1”。其中为输入二进制向量,0表示部分积。为避免溢出,二进制数相加时需要进行符号位拓展,在图中用箭头表示。为了保证信号表示位数相同,需要在每一步加法时截位,截去的位在图中用框表示。串行乘法器实现如图2(b)所示。移位器由寄存器与多路选通器构成,通过在不同时刻选通不同寄存器,在一个时钟同时完成符号位拓展与结果截位。
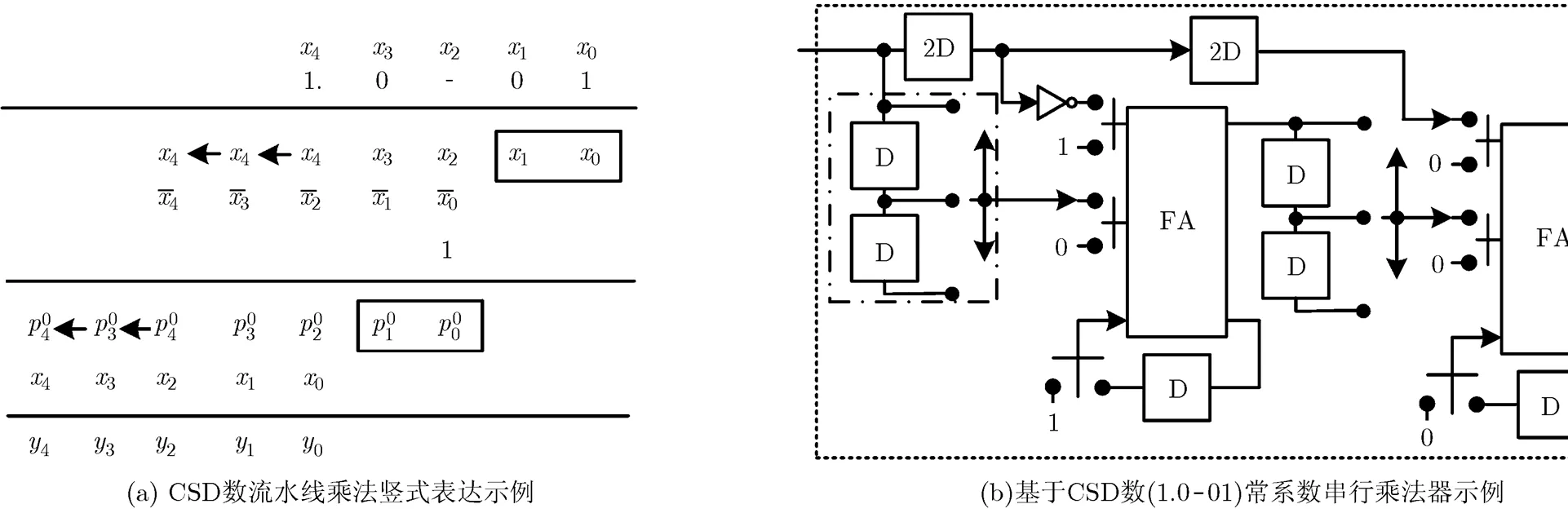
图2 常系数乘法器示例
4 设计结果与讨论
4.1 基于较大基的分解算法
降低FFT运算复杂度的关键是降低旋转因子乘法的复杂度。一次复数乘法需要3次实数乘法完成[12];当旋转因子, (=0,/4,/2, 3/4)时,旋转因子乘法可以由加减法完成;当(=/8, 3/8, 5/8, 7/8)时,旋转因子对应0.7071(±1±),一次复数乘法只需要两次实数乘法。当基于较大基分解时,分解可以向着旋转因子复杂度降低的方向进行。如表1所示,512点采用不同基分解时所需旋转因子乘法数。表中分解方式为32点乘16点时,32点分解如图3(b),可以看出采用较大基分解时乘法复杂度较低。

表1 512点不同分解方式所需乘法次数统计
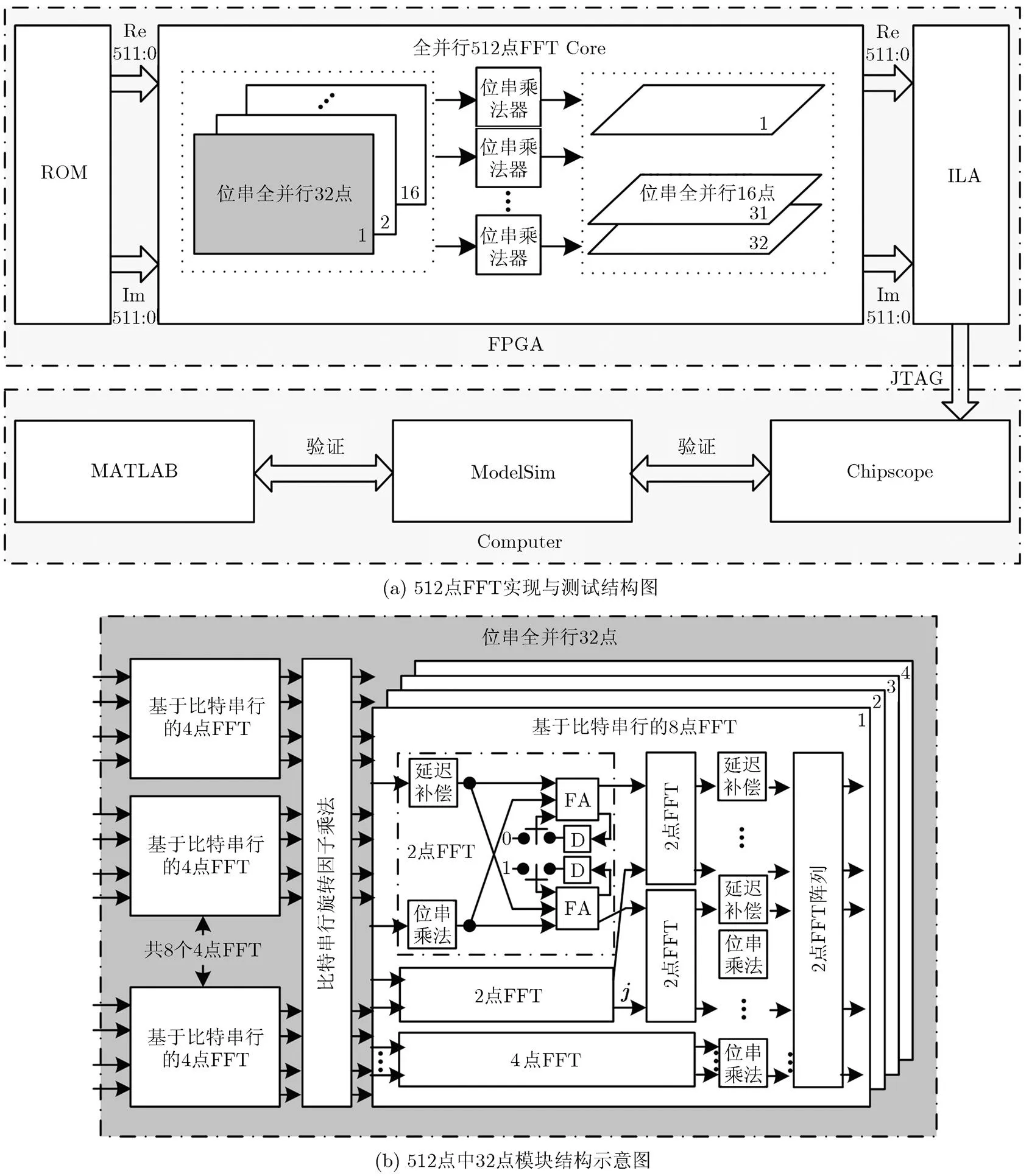
图3 基于比特串行结构的全并行512点实现与测试
4.2 512点全并行结构实现与测试
512点全并行FFT的FPGA实现与测试结构如图3(a)所示,FPGA测试在Xilinx FPGA Vertex-7vx980t上进行,向量存储在ROM中,ROM输出为IQ两路,每路512 bit字长的数据。输出采用了ILA核采集输出信号,上载并与ModelSim以及Matlab对比验证正确性。
4.3 FPGA实现结果与对比讨论
实现结果如表2所示,在资源消耗上,全并行FFT占用了30%的查找表资源以及9%的寄存器资源;在处理性能上,处理器在16个时钟得到全部512点结果,等效为32 Symbols/s,以报告的系统频率310.348 MHz计算,系统可实现的吞吐率为9.931 GSymbol/s。表3给出了本文设计与已有文献的结果比较。为了公平起见,以式(4)所定义的符号吞吐率除以等效逻辑门数量来衡量设计增益:
速度面积比=符号吞吐率/逻辑门数 (4)

表2本文设计的全并行结构资源消耗与性能细节
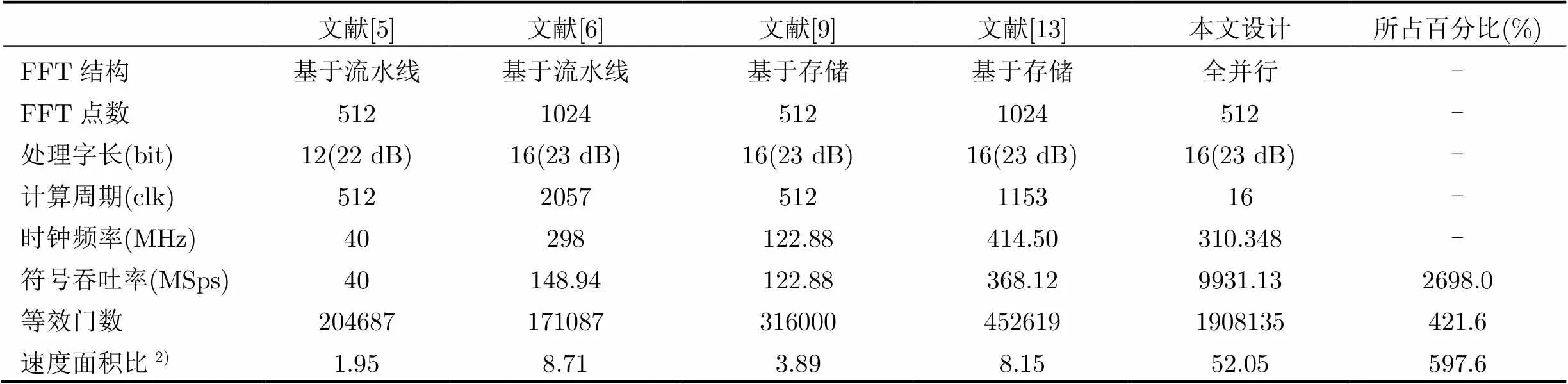
表3本文设计结构与已有文献比对
如表3所示,由于定点字长有限,量化字长不同时,FFT输出性噪比性能不同。采用先前文献[6]中的测试方法,FFT输入为加性高斯白噪声信号,信噪比25 dB时,输出信噪比在量化字长为12 bit时约为22 dB, 16 bit时约为23 dB。
由于采用了512点全并行的结构,本文结构相比较表中文献[13]的设计,本文设计面积约是其4倍。同时,本文设计的符号吞吐率为文献[13]的近27倍。在输出信噪比性能一致的情况下,我们的设计其速度面积比为文献[6]的近5.97倍。
5 结束语
本文提出一种应用于超高速大吞吐量要求的全并行FFT设计策略,基于“全并行结构比特串行”的方法。该设计通过在全并行的结构中串行化计算与存储单比特串行;与已有设计方法相比较,本文的方法可以获得更大的硬件效率和更高的吞吐率。
[1] 霍凯, 赵晶晶. OFDM新体制雷达研究现状与发展趋势[J]. 电子与信息学报, 2015, 37(11): 2776-2789. doi: 10.11999/ JEIT150335.
HUO Kai and ZHAO Jinjin. The development and prospect of the new OFDM radar[J].&, 2015, 37(11): 2776-2789. doi: 10. 11999/JEIT150335.
[2] 张洪伦, 巴晓辉, 陈杰, 等. 基于FFT的微弱GPS信号频率精细估计[J]. 电子与信息学报, 2015, 37(9): 2132-2137. doi: 10.11999/JEIT150204.
ZHANG Honglun, BA Xiaohui, CHEN Jie,. FFT-based fine frequency estimation for weak GPS signal[J].&, 2015, 37(9): 2132-2137. doi: 10.11999/JEIT150204.
[3] 罗亚松, 许江湖, 胡洪宁, 等. 正交频分复用传输速率最大化自适应水声通信算法研究[J]. 电子与信息学报, 2015, 37(12): 2872-2876. doi: 10.11999/JEIT150440.
LUO Yasong, XU Jianghu, HU Hongning,. Research on self-adjusting OFDM underwater acoustic communication algorithm for transmission rate maximization[J].&, 2015, 37(12): 2872-2876. doi: 10.11999/JEIT150440.
[4] WANG Chao, YAN Yuwei, and FU Xiaoyu. A high- throughput low-complexity radix-24-2²-2³ FFT/IFFT processor with parallel and normal input/output order for IEEE 802.11ad systems[J]., 2015, 23(11): 2728-2732. doi: 10.1109/TVLSI.2014.2365586.
[5] YU Chu and YEN Mao-Hsu. Area-efficient 128-to 2048/ 1536-point pipeline FFT processor for LTE and mobile WiMAX systems[J]., 2014, 23(9): 1793-1800. doi: 10.1109/ TVLSI.2014.2350017.
[6] WANG Zeke, LIU Xue, HE Bingsheng,. A combined SDC-SDF architecture for normal I/O pipelined radix-2 FFT[J]., 2014, 23(5): 973-977. doi: 10.1109/TVLSI.2014. 2319335.
[7] CHEN Jienan, Hu Jianhao, and LEE Shuyang. High throughput and hardware efficient FFT architecture for LTE application[C]. IEEE Wireless Communications & Networking Conference. Shanghai, 2012: 826-831. doi: 10.1109/WCNC.2012.6214486.
[8] CHEN Jienan, HU Jianhao, LEE Shuyang,. Hardware efficient mixed radix-25/16/9 FFT for LTE systems[J]., 2015, 23(2): 221-229. doi: 10.1109/TVLSI.2014.2304834.
[9] COOLEY J W and TUKEY J W. An algorithm for the machine calculation of complex Fourier series[J]., 1965, 19(90): 297-301. doi: 10.2307/2003354.
[10] DUHAMEL P and VETTERLI M. Fast fourier transforms: a tutorial review and a state of the art[J]., 1990, 19(4): 259-299. doi: 10.1016/0165-1684(90)90158-U.
[11] YANG Lang and CHEN T W. A low power 64-point bit-serial FFT engine for implantable biomedical applications[C]. Euromicro Conference on Digital System Design, Funchal, Portugal, 2015: 383-389. doi: 10.1109/DSD.2015.30.
[12] PARHI K K. VLSI Digital Signal Processing Systems: Design and Implementation[M]. New York, USA, John Wiley & Sons, 1999: 490-499.
[13] MA Zhenguo, YIN Xiaobo, and YU Feng. A novel memory-based FFT architecture for real-valued signals based on radix-2 decimation-in-frequency algorithm[J].:,2015, 62(9): 876-880. doi: 10.1109/TCSII.2015.2435522.
An Ultra-high-speed Fully-parallel Fast Fourier Transform Design
CHEN Jienan FEI Chao YUAN Jiansheng ZENG Weiqi LU Hao HU Jianhao
(National Key Laboratory of Science and Technology on Communications, University of Electronic Science and Technology of China, Chengdu 611731, China)
The design and implementation of ultra-high-speed FFT processor is imperative in radar system and prospective wireless communication system. In this paper, the fully-parallel-architecture FFT with bit-serial arithmetic is proposed. This method avoids the complexity of data addressing, access and routing. Based on the high-radix factorization, the multiplication number can be reduced. Out of the reason that twiddle factors are fixed in the design, constant coefficient optimization can be used in multiplications. Besides, bit-serial arithmetic cuts down the hardware cost, and makes the computation elements full-load to get a 100% efficiency. As a result, the presented 512-point FFT processer has 5.97 times gain in speed-throughput ratio while its hardware only accounts for 30% LUTs and 9% registers resource based on Xilinx V7-980t FPGA.
Fast Fourier Transform (FFT); Full parallel; Bit-serialcalculation; Constant coefficient multiplication
TN47
A
1009-5896(2016)09-2410-05
10.11999/JEIT160036
2015-11-25;
2016-04-27;
2016-07-19
国家自然科学基金(6150010678, 61371104)
The National Natural Science Foundation of China (6150010678, 61371104)
胡剑浩 jhhu@uestc.edu.cn
陈杰男: 男,1986年生,副教授,研究方向为通信数字信号处理、超大规模集成电路设计与实现.
费 超: 男,1993年生,硕士生,研究方向为通信专用集成电路.
袁建生: 男,1992年生,硕士生,研究方向为通信与信息系统.
