换热网络合成问题的并行BB/SQP混合算法
2016-10-13姜楠刘永忠朱天鸿
姜楠,刘永忠,2,朱天鸿
换热网络合成问题的并行BB/SQP混合算法
姜楠1,刘永忠1,2,朱天鸿1
(1西安交通大学化学工程与技术学院,陕西西安 710049;2热流科学与工程教育部重点实验室,陕西西安 710049)
换热网络合成问题通常可用非凸、非线性、不可微的混合整数非线性规划模型描述。基于GPU的并行计算技术为求解大规模模型提供了高效支撑。针对已有并行SQP算法求解换热网络合成问题中存在二元变量组合数过多、并行SQP算法求解结果严重依赖初值等问题,提出了BB/SQP混合并行算法。该算法采用BB算法代替枚举法,不但大大减少了模型求解中可能的二元变量组合,而且为SQP算法选出了可行的初值,从而提高了算法的求解质量。研究表明,所提出的混合并行算法能够有效求解换热网络合成问题,且并行计算相比串行计算的求解速度显著增加,加速比可达39。
换热网络合成;混合整数非线性规划;GPU;并行算法
引 言
为了获得最小公用工程费用、最少换热单元数、最小换热面积和总投资费用的换热网络[1-4],其问题可抽象为复杂的混合整数非线性规划(MINLP)模型[5-6]。该模型具有非线性和非凸性的特点。采用启发式算法难以得到全局最优解,而确定性算法的求解时间过长。因此,目前的趋势是通过并行加速策略来求解大规模优化模型。目前所采用的主要方法为:直接使用易于并行化的启发式算法对模型进行求解;或通过模型分割的方法将原问题拆解为可并行求解的一系列子问题,之后对子问题采取并行化处理。
在使用并行的启发式算法时,由于图形处理器(GPU)表现出优越的并行计算性能,被引入到通用计算的领域中。一些学者提出了基于GPU并行加速的粒子群算法求解多目标优化问题[7-10],提高了问题的求解效率和算法的寻优概率。Wong[11]实现了基于GPU的并行遗传算法,且提出了一种基于GPU的多目标进化算法。Munawar等[12]基于GPU使用改进的遗传算法求解MINLP问题,使用熵测量的方法调整基因搜索的方向,达到了双精度下20和单精度下40的加速比。康丽霞等[13]提出了一个基于OpenMP系统的并行遗传算法,在基本遗传算法的基础上引入了一系列调节和控制策略,用于改善算法的收敛性,提高了算法获得最优解的概率。然而,上述并行求解优化问题的算法仅限于进化类算法,这是由进化类算法天然并行的特点决定的,并未克服进化类算法易于陷入局部最优和易于发散的缺陷。
采用模型分割方法实现并行化,首先需要将MINLP问题拆解成众多可并行求解的子问题,主要途径是通过分解模型中的约束条件来达到目的。针对较大规模的MINLP问题,Wah等[14]提出了约束分割法,通过将模型中的约束按一定规则分割,从而得到一定数量的子问题,之后即可对子问题进行并行求解。Bogataj等[15]提出了一种通过将非凸MINLP问题转化为求解一类单凸MINLP问题的方法,并证明了该方法在模型规模较小时能够保证全局最优解。Bjorkqvist等[16]提出了基于Internet的分布式并行求解方法,其目的还是需要整合更多的计算资源来辅助并行解决MINLP问题中存在的大量计算密集型任务。由于GPU更擅长处理计算密集型任务,当问题规模不大或者算法处理的任务数目或迭代的次数较少时,GPU并不能显著提升计算性能。而随着问题规模的增大,处理数据迭代规模增大时,GPU的加速效果越发明显。
目前对使用确定性算法求解换热网络MINLP问题的研究相对较少,针对确定性算法求解大规模MINLP问题所需时间过长甚至无法在有限时间内求解的问题,康丽霞等[17]提出了基于GPU加速求解MINLP问题的SQP并行算法,采用CPU/GPU异构并行的策略,以枚举的方式保证了整数变量解空间的完备性,构建了异步并行的内核函数实现了NLP子问题的求解。然而,该算法占用内存空间较大,且初值依赖性强。
针对启发式算法求解质量差、确定性算法求解时间长等问题,通过分析分支定界算法(BB)的可并行性和序贯二次规划算法(SQP)求解约束优化问题的全局收敛性及其超线性的收敛速度,本文提出了基于GPU加速求解换热网络合成问题的BB/SQP混合并行算法,目标是提高求解精度、加快计算速度。本文将分别介绍串行和并行的BB/SQP混合算法的设计,然后采用串行和并行算法分别对换热网络优化问题进行求解,通过对比,阐明本文算法的准确性和求解效率。
1 BB与SQP混合算法流程
分支定界算法(BB)是一种求解纯整数或混合整数规划的有效算法,主要通过分支、定界、比较与剪枝3个关键的步骤进行寻优,通常其计算量大大少于穷举法。序贯二次规划算法(SQP)是求解有约束的非线性规划问题(NLP)的有效算法之一,是一种循环迭代算法,具有良好的全局收敛性和超线性的收敛速度。
换热网络合成问题可描述为

模型中包含连续型变量和二元变量两类变量。换热量或流股温度等参数用连续型变量表示,是否存在换热单元用二元变量表示。
根据分支定界法的思想,构造原问题的松弛问题0,表示为

求解该松弛问题的结果可分为3种情况:
(1)该松弛问题无解,则原问题也无解,计算结束;
(2)该松弛问题有解,且最优解满足原问题的约束,则得到了原问题的最优解,计算结束;
(3)该松弛问题有解,但最优解不满足原问题的约束,则需要进行下一步的分支。


求解1和2子问题,如果1得到了满足原问题约束的可行解,则将其作为当前得到的最优解,其相应的目标函数值1作为当前的上界。接着对结点2进行检查,如果其有解,再分为3种情况:
(1)若2的解不满足原问题的约束,且2不小于当前的上界,则将2剪枝,1的解即为所求解;
(2)若2的解满足原问题的约束,且2小于当前的上界,则2的解即为所求的全局最优解;
(3)若2的解不满足原问题的约束,且2小于当前的上界,则其仍有望得到最优解,以2作为父结点继续进行分支。
对于第3种情况,选取2的解中某一不满足整数约束的解,重复分支步骤。如此不断重复上述的分支、定界和剪枝的过程,如果出现更好的上界,则随时更新上界为更小的目标函数值。
对换热网络合成问题的混合整数非线性规划(MINLP)模型,本文将其分解为一系列的混合整数规划(MIP)和非线性规划(NLP)子问题,其中的MIP问题可以使用BB算法对混合整数组合进行有选择的取舍,选取其中有可能通往最优解的结点进行分支,同时每一个结点都是一个NLP问题,可以使用SQP算法对NLP问题进行有效的求解。如此一来,可以设计出一个主子结构,主结构使用BB算法作为框架,子结构使用SQP算法求解每个结点中的NLP子问题,随着BB算法的进行,分支、定界、剪枝的程度愈加深入,不断增加的约束条件使NLP问题逐渐满足原MINLP问题的约束,在遍历了所有的活结点后,最终可求得原MINLP问题的最优解。
2 串行和并行BB/SQP混合算法设计
2.1 串行BB/SQP混合算法的设计
本文所需解决问题的目标是最小化换热网络的年度费用,采取优先队列式分支定界法。将各结点按照优先级进行排序,目标函数值越小的结点优先级越高。因此,本文以最小堆的形式组织活结点表,将活结点按照各自的目标函数值排序。如此可以保证每次取出的表首结点都是活结点表中目标函数值最小的结点,结点一旦被取出后则从活结点表中删除。
按照优先队列式分支定界法的原则,混合算法的流程如图1所示。

图1 串行BB/SQP混合算法流程
由图1可以看出,串行BB/SQP混合算法的基本流程如下。
(1)构造换热网络优化MINLP问题的松弛问题,记为NLP0。
(2)调用SQP算法模块求解NLP0,结果分为3种情况:若NLP0无解,则原MINLP问题无解,计算结束;若NLP0有解且解满足原MINLP问题的所有约束,则得到原问题的最优解,其目标函数值即为最优目标函数值,计算结束;若NLP0有解但解不满足原问题的约束条件,则转步骤(3)。
(3)将该结点加入活结点表。
(4)若活结点表不为空,取出活结点表中的优先级最高的结点,将其分支产生两个子问题NLP1和NLP2,之后将该结点从活结点表中删除,调用SQP求解模块对子问题分别求解。
(5)对NLP1和NLP2的求解结果分别进行检查,若其目标函数值大于当前的上界,将该结点舍弃;否则,转步骤(6)。
(6)进一步判断子问题的解是否满足原问题的约束,若不满足,转步骤(3);若满足,则得到原问题的一组可行解,将其记录下来,同时得到一个更优的上界,将上界更新为该结点的目标函数值,转步骤(4)。
(7)重复步骤(3)~步骤(6),直到活结点表为空时,计算终止。
在分支步骤中,新产生的子结点复制其父结点的最优解作为子结点中SQP算法的迭代初值。相比一般的初值,从父结点继承的最优解通常情况下能够更接近子结点的最优解,为SQP算法提供更好的初值,加速问题的求解。
2.2 并行BB/SQP混合算法的设计
由于并行化程序的要求,需要将算法设计为若干适于并行独立求解的部分,因此如何将任务进行合理分解是本算法的重点。
分支定界算法的搜索起始于一个根结点,这一根结点是将原混合整数规划中整数约束的部分去掉,将整数变量松弛为连续型变量进行求解的,其解空间会相应增大。通常情况下,根结点的解难以满足原问题的约束,但是其目标函数值可作为该优化问题最优解的一个下界,可先通过并行SQP算法对根结点求解,如果根结点的解不是原问题的解,则将原问题分解为若干子问题,再利用并行混合算法进行求解。
在换热网络合成问题的MINLP模型中,其中的二元变量数目为已知,假设为,则个二元变量的所有组合形式即为完整的换热网络结构序列,可通过穷举得到,其总数为2,或者可以看做是深度为1的满二叉树的所有叶子结点所构成的集合,如图2所示。
图2中,结点内的序列表示已确定的二元变量组合即部分网络结构。可以看出,深度不同,结点数目不同,结点的深度与其已确定的不完整的结构序列位数一一对应,且左子结点是在其父结点结构序列的基础上增加一位,以“0”占位;右子结点是在其父结点结构序列的基础上增加一位,以“1”占位,即下层的结点均是由上层的结点分支得到,且不会有遗漏。这与需要获得某一位的组合序列的思路是一致的。为了利用GPU并行计算的特性,可根据问题的规模,选取分支树的某一深度,列举出深度为时的所有结点的组合序列共2-1种,它们是最终网络结构的前-1位的所有组合形式。将这些结点加入初始活结点表中,之后分别初始化于每个block中作为并行深度优先分支定界法搜索的根结点,深度的选取需要同时考虑所要求解问题的整型变量数目以及硬件自身的能力。

图2 分支树的深度与产生组合数目的关系
经并行初始化之后,每个block拥有各自预先确定的部分网络结构。因此,每个block都可看作是一个深度优先分支定界法的根结点,可通过核函数(kernel)执行并行的深度优先搜索(DFS)[18],如图3所示。
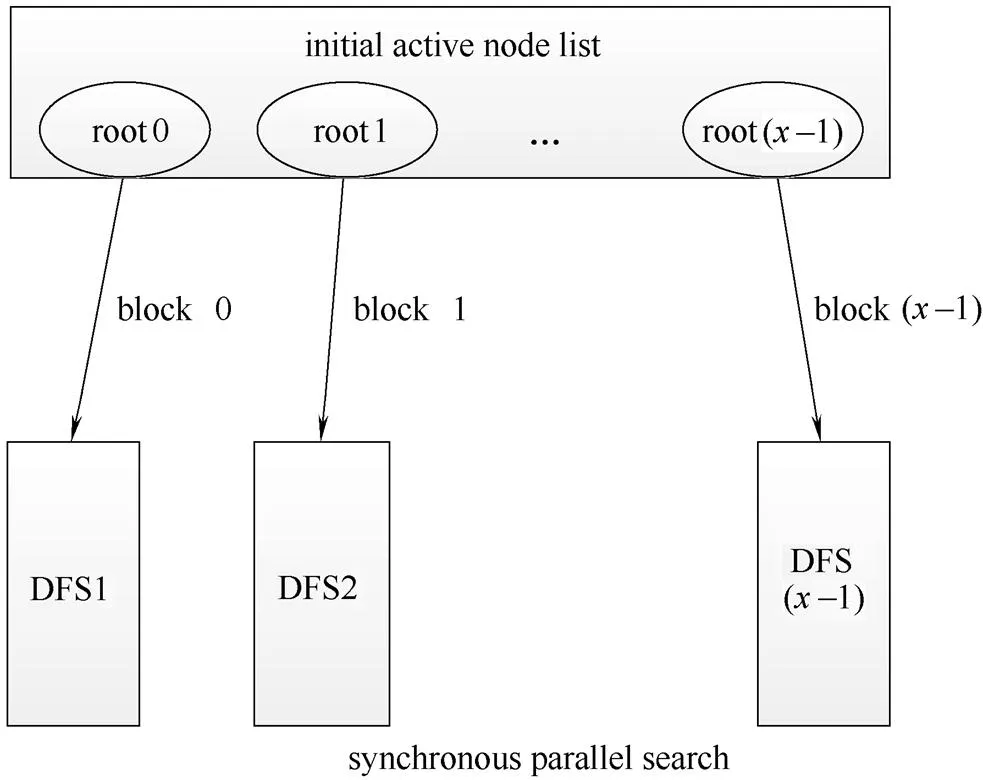
图3 根结点与block的关系
图3中,初始活结点表中的每个结点均作为深度优先搜索的根结点,同时分布于各个block中,之后以其为根结点的深度优先搜索DFS在每个block中执行,除了搜索方式不同,其他执行过程与串行混合算法相似,如此每一个子空间都可以同时进行求解,且每个block中的解均为原问题解空间中的子集。这里所执行的深度优先搜索是一个回溯的过程,其本质是先序遍历一棵状态树,同时将状态树的建立隐含在遍历过程中,使用它可以避免穷举式搜索,这种方式适用于求解一些组合数相当大的问题[19]。本文所设计的结合并行SQP算法的深度优先BB/SQP搜索流程如图4所示。
从图4可以看出,在执行分支时每次只产生一个子结点,子结点的迭代初值可设置为其父结点的最优解,如果该子结点经过比较之后被剪枝,则将搜索返回其父结点,分支产生另一子结点。

图4 深度优先搜索算法流程
下面给出本文所采用的深度优先BB/SQP搜索的基本步骤:
(1)设置各根结点的初始信息,包括对初始结构序列和变量赋初值,读入已知数据等;
(2)选取其中某一分支进行试探,即在缺省的网络结构序列中添加一位“0”或“1”;
(3)使用并行SQP算法对该结点进行求解,之后判断此分支是否可行,若不可行则转步骤(6);
(4)若分支可行则前进一步继续试探;
(5)找到一组可行解则进行记录,若未找到则转步骤(2);
(6)选取另一分支进行搜索,转步骤(3),若该结点的分支全部试探完则转步骤(7);
(7)退回一步返回父结点,若未退到头则转步骤(6);
(8)已退到头则结束或输出无解。
当所有block完成搜索之后,会产生大量的解,此时需要执行同步步骤来确保所有block均已计算完毕,并且将所有block的解汇总比较,进行最优解的筛选。
由于DFS的过程发生在device端,而GPU的流处理器相对简单,若在device端使用复杂的分支与定界程序会大大影响GPU的执行效率。因此,本文通过使用有序的分支策略和一个简单的定界函数来替代串行部分复杂的分支定界过程,以此缓解GPU的这一局限。线程间的同步和问题的规模是影响程序执行时间的两个重要因素,因此应该设置更紧的上界以剪掉更多的分支,创建更小的分支定界树,避免上界的多次更新同步。因此初始上界的设置就显得尤为重要,通常可通过启发式算法或多项式近似的方法来得到相对合适的初始上界。如果问题的规模很大,所需求解的并行的子问题过多时,可按子问题数目选择合适的block数目,通过多轮实现的形式,每轮计算一部分子问题,将问题分批次处理。图5给出了并行混合算法的计算流程。

图5 并行BB/SQP混合算法流程
3 算例分析
本文算例计算所用设备为一台安装了Nvidia Tesla K20c和Quadro K600的工作站,计算环境为:CPU为Pentium(R) Dual-Core CPU E5800,3.20 GHz。软件环境为:Windows 7操作系统,CUDA toolkit版本为6.0。
GPU为Nvidia Tesla K20c显卡一块,流处理器内核数量104,CUDA核心数量2496,计算能力3.5,单精度浮点性能3.52 Tflop·s-1,容量4 GB,时钟频率0.71 GHz;Quadro K600显卡一块,流处理器内核数量8,CUDA核心数量192,计算能力3.0,单精度浮点性能194.84 Gflop·s-1,显存容量1 GB,时钟频率0.88 GHz。
3.1 对小型换热网络模型的计算测试
本节采用一个规模较小的换热网络案例来进行测试,算例来源于文献[20]。该换热网络包括2股热流和2股冷流,基础数据如表1所示。
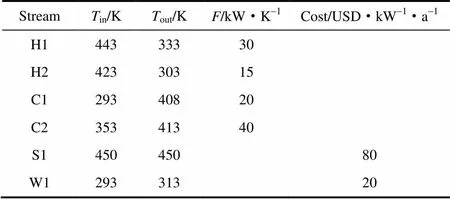
表1 算例1的流股数据
本例换热网络模型规模为2×2×3,无分流,最小传热温差为10 K,模型中共包含68个变量,其中有16个整型变量。采用本文算法得到的换热网络结构见图6。表2中列出了串行程序与并行程序计算结果的对比,并与文献中的结果进行比较。
由表可见,串行计算和并行计算均得到了比文献中更优的目标函数值,表明本文算法能够很好地求解小型换热网络优化问题,且并行程序相比串行程序执行时间大大缩短,达到了约39的加速比。

图6 算例1的换热网络结构
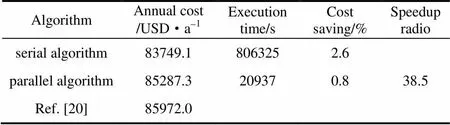
表2 算例1的计算结果对比
3.2 对中型换热网络模型的计算测试
本节将对一个规模较大换热网络的MINLP模型进行测试,该算例来源于文献[21],基础数据见表3。
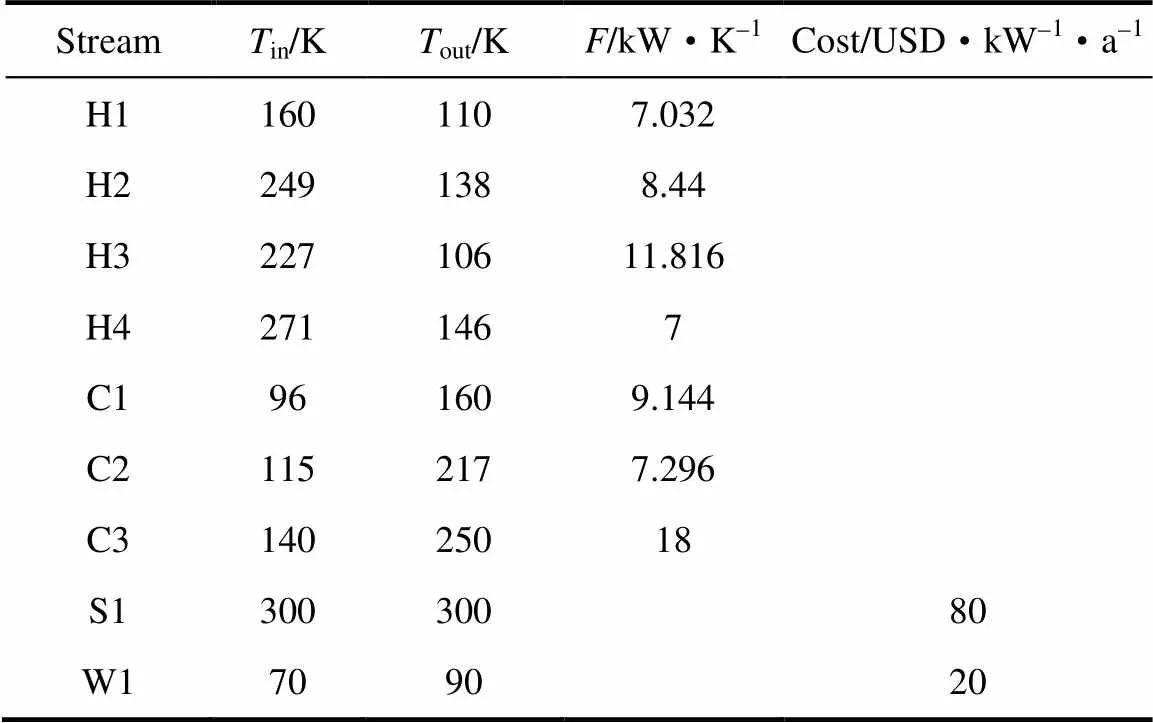
表3 算例2的流股数据
本算例的规模为4×3×2,有分流,最小传热温差为1 K,模型中共有整型变量31个,连续变量95个。由于串行程序的计算时间过长,本节仅给出采用并行计算进行测试的结果,所得到的换热网络结构如图7所示,结果对比如表4所示。
由表可见,本文设计的并行混合算法可求得算例2的最优整型变量组合,其相应的目标函数值不仅优于文献中的最优目标函数值,且得到了切实可行的换热网络设计方案,证明了本文设计算法可以对换热网络的MINLP问题进行有效求解。
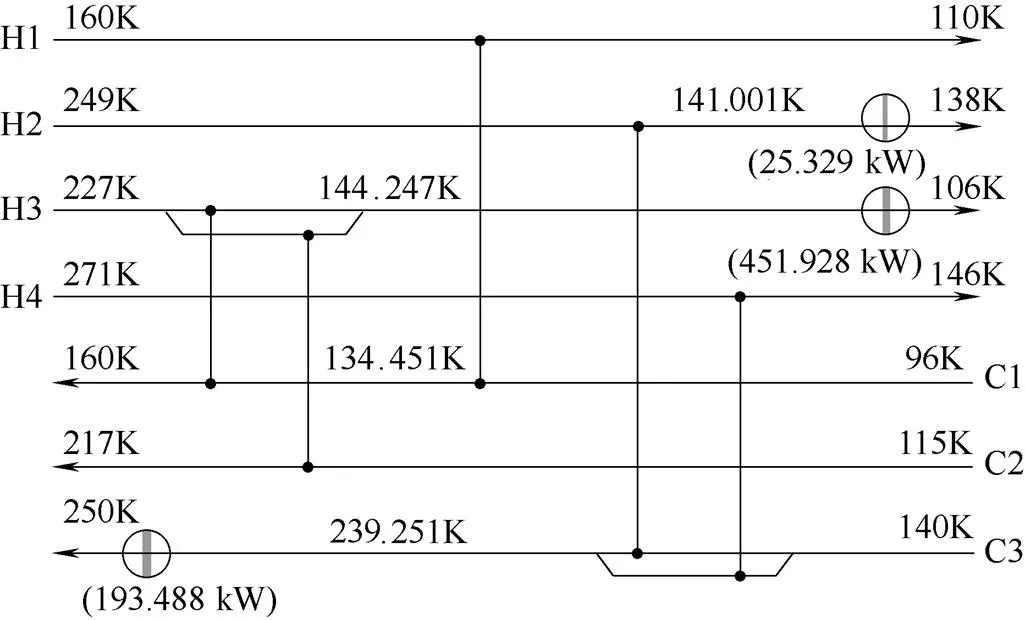
图7 算例2的换热网络结构
4 结 论
针对换热网络的合成问题,本文分析并设计了将分支定界算法与序贯二次规划算法相结合的混合算法,同时实现了混合算法的串行计算和基于GPU的并行计算。通过对两个规模不同的算例进行测试,验证了本文提出的BB/SQP并行混合算法对于求解换热网络优化问题的有效性。对比串行计算和并行计算,本文提出的并行混合算法具有显著的加速效果。
[1] BAKAR S H A, HAMID M K A, ALWI S R W. Selection of minimum temperature difference (Δmin) for heat exchanger network synthesis based on trade-off plot [J]. Applied Energy, 2016, 162 (15): 1259-1271.
[2] NOVAK P Z, KRAVANJA Z. A methodology for the synthesis of heat exchanger networks having large numbers of uncertain parameters [J]. Energy, 2015, 92 (3): 373-382.
[3] GROSSMANN I E, APAP R M, CALFA B A. Recent advances in mathematical programming techniques for the optimization of process systems under uncertainty [J]. Computers & Chemical Engineering, 2015, 37 (1): 1-4.
[4] LEE S, GROSSMANN I E. A global optimization algorithm for nonconvex generalized disjunctive programming and applications to process systems [J]. Computers & Chemical Engineering, 2001, 25 (11): 1675-1697.
[5] YEE T F, GROSSMANN I E, KRAVANJA Z. Simultaneous optimization models for heat integration (Ⅰ): Area and energy targeting and modeling of multi-stream exchangers [J]. Computers & Chemical Engineering, 1990, 14 (10): 1151-1164.
[6] YEE T F, GROSSMANN I E. Simultaneous optimization models for heat integration (Ⅱ): Heat exchanger network synthesis [J]. Computers & Chemical Engineering, 1990, 14 (10): 1165-1184.
[7] ZHOU Y, TAN Y. GPU-based parallel multi-objective particle swarm optimization [J]. International Journal of Artificial Intelligence, 2011, 7 (11): 125-141.
[8] WANG J, WU Z. Opposition-based particle swarm optimization for solving large scale optimization problems on GPU [J]. Journal of Wuhan University(Natural Science), 2011, 57 (2): 148-154.
[9] MUSSI L, DAOLIO F, CAGNONI S. Evaluation of parallel particle swarm optimization algorithms within the CUDA architecture [J]. Information Sciences, 2011, 181 (20): 4642-4657.
[10] MUSSI L, NASHED Y S G, CAGNONI S. GPU-based asynchronous particle swarm optimization [C]//Proceedings of the 13th Annual Conference on Genetic and Evolutionary Computation. Dublin: ACM. 2011: 1555-1562.
[11] WONG M L. Parallel multi-objective evolutionary algorithms on graphics processing units [C]//Proceedings of the Conference on Genetic and Evolutionary Computation. Canada: Companion Material, 2009: 2515-2522.
[12] MUNAWAR A, WAHIB M, MUNETOMO M. Advanced genetic algorithm to solve MINLP problems over GPU [C]//Congress of Evolutionary Computation. LA: IEEE, 2011: 318-325.
[13] 康丽霞, 姜楠, 夏明星, 等. 基于OpenMP的并行GA加速求解换热网络设计 [J]. 高校化学工程学报, 2016, 30 (2): 423-438. KANG L X , JIANG N, XIA M X,Paralleled genetic algorithm for design of HEN based on OpenMP system [J]. Journal of Chemical Engineering of Chinese Universities, 2016, 30 (2): 423-438.
[14] WAH B W, CHEN Y X. Constraint partitioning in penalty formulations for solving temporal planning problems [J]. Artificial Intelligence, 2006, 170 (3): 187-231.
[15] BOGATAJ M, KRAVANJA Z. An alternative strategy for global optimization of heat exchanger networks [J]. Applied Thermal Engineering, 2012, 43 (43): 75-90.
[16] BJORKQVIST J, WESTERLUND T. Parallel solution of disjunctive MINLP problems [J]. Chemical Engineering Communications, 2002, 185 (1): 115-124.
[17] 康丽霞, 张燕蓉, 唐亚哲, 等.基于GPU加速求解MINLP问题的SQP并行算法 [J]. 化工学报, 2012, 63 (11): 3597-3601. KANG L X, ZHANG Y R, TANG Y Z,. Paralleled SQP algorithm for solution of MINLP problems based on GPU acceleration [J].CIESC Journal, 2012, 63 (11): 3597-3601.
[18] CHAKROUN I, MELAB N. Operator-level GPU-accelerated branch and bound algorithms [J]. Procedia Computer Science, 2013, 18 (1): 280-289.
[19] CARNEIRO T, MURITIBA A E, NEGREIROS M. A new parallel schema for branch-and-bound algorithms using GPGPU [C]//Computer Architecture and High Performance Computing. Espirito Santo: IEEE, 2011: 41-47.
[20] ZAMORA J M, GROSSMANN I E. A global MINLP optimization algorithm for the synthesis of heat exchanger networks with no stream splits [J]. Computers & Chemical Engineering, 1998, 22 (3): 367-384.
[21] VIDYASHANKAR K, NARASIMHAN S. Comparison of heat exchanger network synthesis using Floudas and Yee superstructures [J]. Indian Chemical Engineer, 2010, 52 (1): 1-22.
Parallel algorithm of hybrid BB/SQP for heat exchanger network synthesis
JIANG Nan1, LIU Yongzhong1,2, ZHU Tianhong1
(1School of Chemical Engineering and Technology, Xi’an Jiaotong University, Xi’an 710049, Shaanxi, China; 2Key Laboratory of Thermo-Fluid Science and Engineering, Ministry of Education, Xi’an 710049, Shaanxi, China)
Heat exchanger network synthesis can be described by a mixed integer non-linear programming (MINLP) model, which features non-convex, non-linear and non-differentiable optimization. The parallel computing technology based on GPU provides an efficient support for solving large scale models. In this work, a hybrid algorithm combined branch and bound method (BB) with sequential quadratic programming (SQP) is proposed to overcome difficulties in the existing parallel SQP algorithm, such as too many combinations of integer variables, dependency of initial values and. The BB method is adopted in the hybrid algorithm instead of the exhaustive method. It can not only reduce the combinations of integer variables, but also select feasible initial values for the SQP algorithm. The solution quality is improved. The results of the examples show that the proposed parallel hybrid algorithm can solve the heat exchanger network synthesis problems efficiently. Compared to the serial algorithm, the proposed parallel algorithm has much higher executive speed with the speedup ratio of 39.
heat exchanger network synthesis; mixed integer non-linear programming; GPU; hybrid algorithm
date: 2016-09-13.
Prof. LIU Yongzhong, yzliu@mail.xjtu.edu.cn
10.11949/j.issn.0438-1157.20161287
TQ 021.8
A
0438—1157(2016)12—5169—07
国家自然科学基金项目(21376188,21676211)。
supported by the National Natural Science Foundation of China (21376188, 21676211).
2016-09-13收到初稿,2016-09-22收到修改稿。
联系人:刘永忠。第一作者:姜楠(1990—),男,硕士研究生。
