内河船舶安全缺陷的要素关联性
2016-10-12郝勇,黄强
郝 勇, 黄 强
(1.武汉理工大学,航运学院, 武汉 430063; 2.国家水运安全工程技术研究中心, 武汉 430063;3.湖北省内河航运技术重点实验室, 武汉 430063)
内河船舶安全缺陷的要素关联性
郝 勇1,2,3, 黄 强1,3
(1.武汉理工大学,航运学院, 武汉 430063; 2.国家水运安全工程技术研究中心, 武汉 430063;3.湖北省内河航运技术重点实验室, 武汉 430063)
对内河船舶安全缺陷之间隐含的关联规则进行研究,有助于准确定位船舶缺陷,提高内河船舶安全检查水平及船公司安全自查质量,保障水上交通安全。对此,基于长江海事局船舶安检数据进行数据处理,并将其存入到数据库中;采用Apriori算法开发关联规则挖掘软件进行数据挖掘,并结合置信度对关联规则进行可靠性分析。结果表明,采用该方法可得到可靠的内河船舶安全缺陷的关联规则。
水路运输;内河船舶;安全检查;缺陷;关联规则;数据挖掘;Apriori算法
Abstract: To discover the implicit association rules relating to the different safety defects of inland ship is useful to find the defects, therefore, to improve the safety inspection. A database based on the data of Inland Ship’s safety inspection from Changjiang Maritime Safety Administration and develops a software to mining safety defects association rules is developed with Apriori algorithm. The credibility of the association rules is examined with confidence degree check.
Keywords: waterway transportation; inland ship; safety inspection; defect; association rule; data mining; Apriori algorithm
船舶安全对保障水上人命和财产安全,防止船舶造成水域污染有着重要的意义。内河船舶安全检查作为保障船舶安全的重要手段越来越受重视,但目前内河船舶安检员工作繁重、业务能力参次不齐,安全检查以抽查为主,难以准确发现安全缺陷,亟需科学的方法提升安检效率。目前海事管理机构有大量船舶安全检查缺陷数据,若缺陷之间存在隐含的关联性,则可通过该性质快速找到更多的安全缺陷,进而提高船舶安检效率,监督船舶的适航性;船公司也可利用该性质提高安全自查的质量。
在船舶安全检查中,若发现某项缺陷时另一项缺陷在高于一定概率的情况下同时被发现,则称两缺陷间的这种关联性关系为船舶安全缺陷的关联规则。目前已有大量针对港口国监督(Port State Control,PSC)的船舶缺陷关联规则的研究,HNNINEN等[1]使用贝叶斯网络模型对芬兰PSC检查数据和事故进行关联规则研究,分析导致事故发生的缺陷指标。然而,要得到一个好的贝叶斯网络模型需比较复杂的训练,数据挖掘以其能从海量数据中高效地发现潜在信息而得到越来越广泛的应用。[2-3]中国港口国监督数据管理中心[4]对PSC检查缺陷及滞留缺陷等数据进行详细的统计分析,但不能发现缺陷间深层的隐含关系。戴耀存等[5]采用频繁项集和关联规则数据挖掘的方式对港口国监督滞留缺陷进行关联规则研究,通过统计缺陷关联规则数量得到导致船舶滞留的重要缺陷。
上述研究未涉及内河船舶安全缺陷,且多侧重于安全缺陷本身,未能就缺陷间的关系进行关联性研究。对此,基于长江海事局辖区内河船舶安全检查数据,研究发现适用于内河船舶安全缺陷的数据挖掘方法。该方法以内河船舶安全检查数据的挖掘过程为落脚点,在此过程中解析数据内涵,确定安全缺陷挖掘对象和数据形式;采用Apriori算法设计内河船舶安全缺陷关联规则挖掘软件,进行数据挖掘;对挖掘结果进行定量评估,验证内河船舶安全缺陷之间的关联性,并加以探讨和应用。
1 内河船舶安全缺陷关联规则挖掘算法
采用数据挖掘中的量化型关联规则挖掘形式,运用Apriori算法[6]对经过处理的船舶安全缺陷数据进行挖掘。Apriori算法按目标项集从小到大的顺序寻找频繁项集。
假设样本数据集D为内河船舶安全缺陷项代码记录,每个项集表示一次安全检查的缺陷代码项集,其示例见表1。
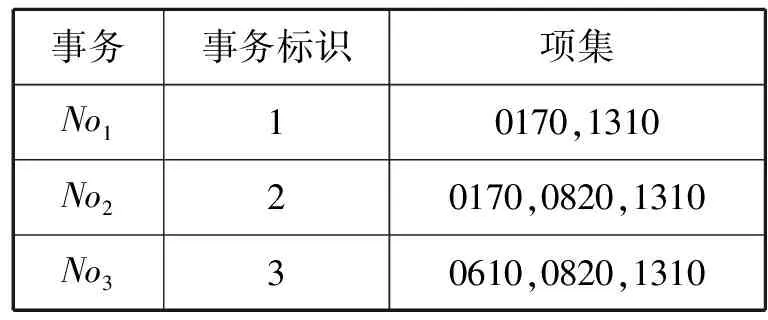
表1 样本数据集D示例
“事务”是指船舶安检过程中所有缺陷项目的集合,每个事务都有一个唯一标志编号,如表1中的每个事务为一个船舶安全缺陷代码集合;事务数据库D={No1,No2,…,Non}由一系列具有唯一标志的事务组成;“项”是指事务数据库的一个属性字段,在该数据集中是指某个船舶安全缺陷代码;“项集”是指包含若干个项的集合。
Apriori算法的第一次遍历找出所有项的候选频繁项集的集合C1,由最小支持度确定候选频繁项集的集合L1;然后遍历迭代,在第k次迭代中找到上次迭代的频繁项集的集合Lk-1和本次迭代的候选项集的集合Ck,为Ck的每个项目集分配初始值为零的计数器以保存其支持度。扫描数据集D中的事务,若Ck中的项目集在其中一个事务中出现,则该项目集计数器数值加1;在数据集D扫描结束后可得到Ck中各项集的支持度,根据最小支持度可确定其频繁项集,继续迭代,直到不能生成新的频繁项集为止。
Apriori算法具有算法简单和数据量少时性能好的优点,但在项集关系复杂且数量相对较多时将增加数据的空间复杂度,进而影响算法的效率。该研究的缺陷数据量相对较少且关系简单,适宜采用该算法。
2 内河船舶安全缺陷关联规则挖掘方法
在数据挖掘过程中,采用适当的方式进行数据处理和识别是数据挖掘的基础及关键,但由于原始数据的特征和挖掘目标不尽相同,需针对内河船舶缺陷数据采用合适的数据挖掘方法。对此,首先将具体的船舶安检缺陷项目数字化,然后进行数据去噪和分类得到有价值的信息,最后根据需求反馈调整数据集形式,以得到适宜挖掘的数据。[7]用关系数据库管理系统(Relational Database Management System,RDBMS)技术将数据集转换成数据库形式来存储,并借助专门软件挖掘关联规则。整个数据挖掘过程以知识发现模式进行。[8]
2.1数据准备
2.1.1目标数据集成和选择
从原始数据中提取有效的目标数据是进行关联规则数据挖掘的基础。首先从各分支海事局内河船舶安全检查数据中提取出原始船舶安全缺陷数据信息,进行统计,分析其宏观规律;随后以研究需求为驱动,从原始数据中提取出有用数据组,解决数据语义的模糊性问题,处理数据可能存在的缺失和噪声,从而缩小数据处理范围。[9]
该研究的数据来自于2010年长江海事局各分支局检查的22艘船舶的安全检查记录。对其中的缺陷项进行分类统计,形成原始船舶安检数据集,绘制成频数分布图(见图1),其中横轴为船舶安检缺陷代码,其间每个数字标志表示一项缺陷大类代码,每条柱状图表示缺陷大类中一个缺陷的频数。
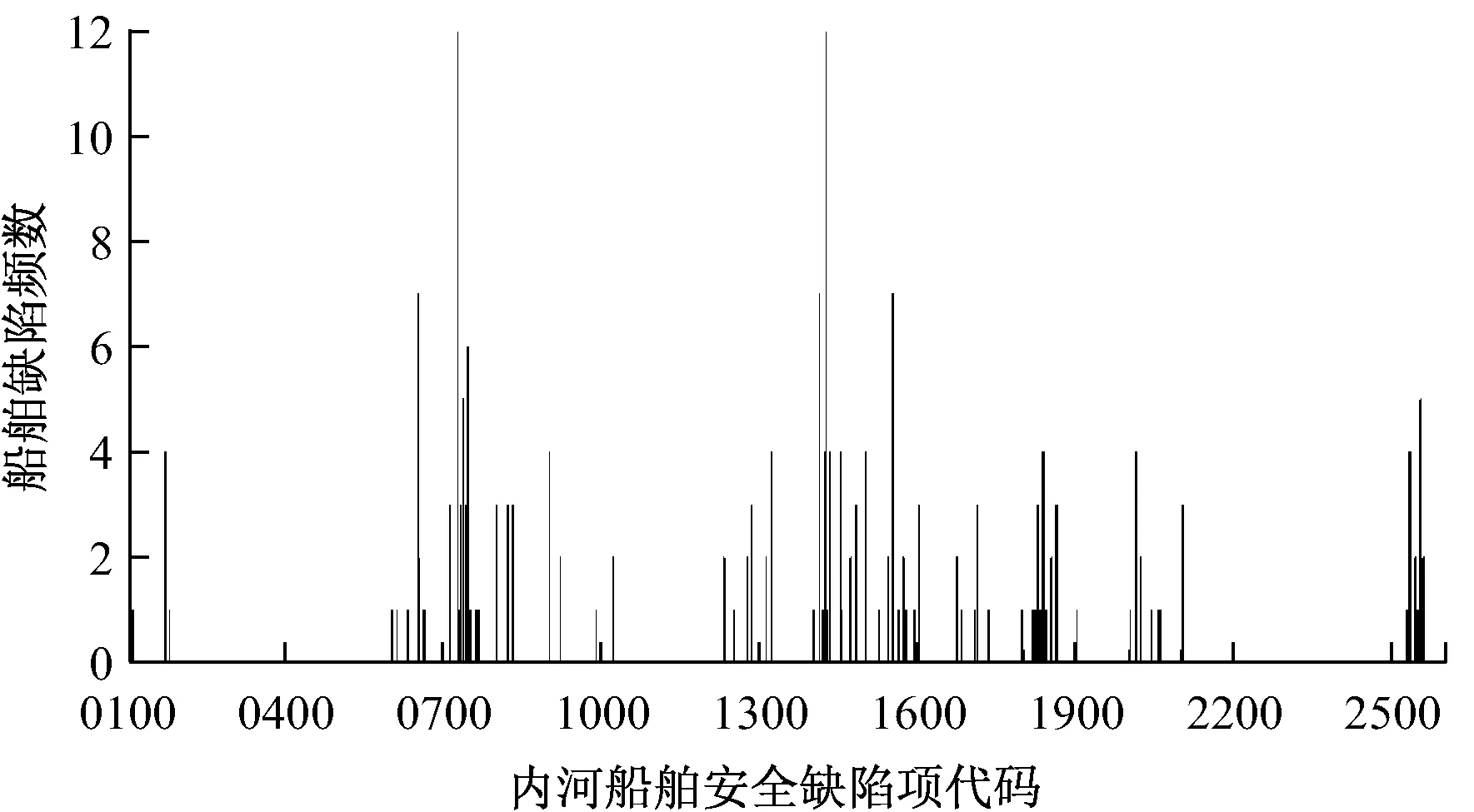
图1 船舶安全检查原始缺陷数据频数分布图
由图1可知,由于安全缺陷项种类较多,缺陷出现的频数都比较低,因此难以采用数据挖掘的方法寻找到高支持度的项集。对此,将船舶安检缺陷按大类来分类。[10]例如,缺陷0120符合证明(Document of Compliance,DOC)副本和缺陷0130最低安全配员证书统一归为0100船舶证书及有关文件大类中。内河船舶安全检查主要缺陷分类见表2。
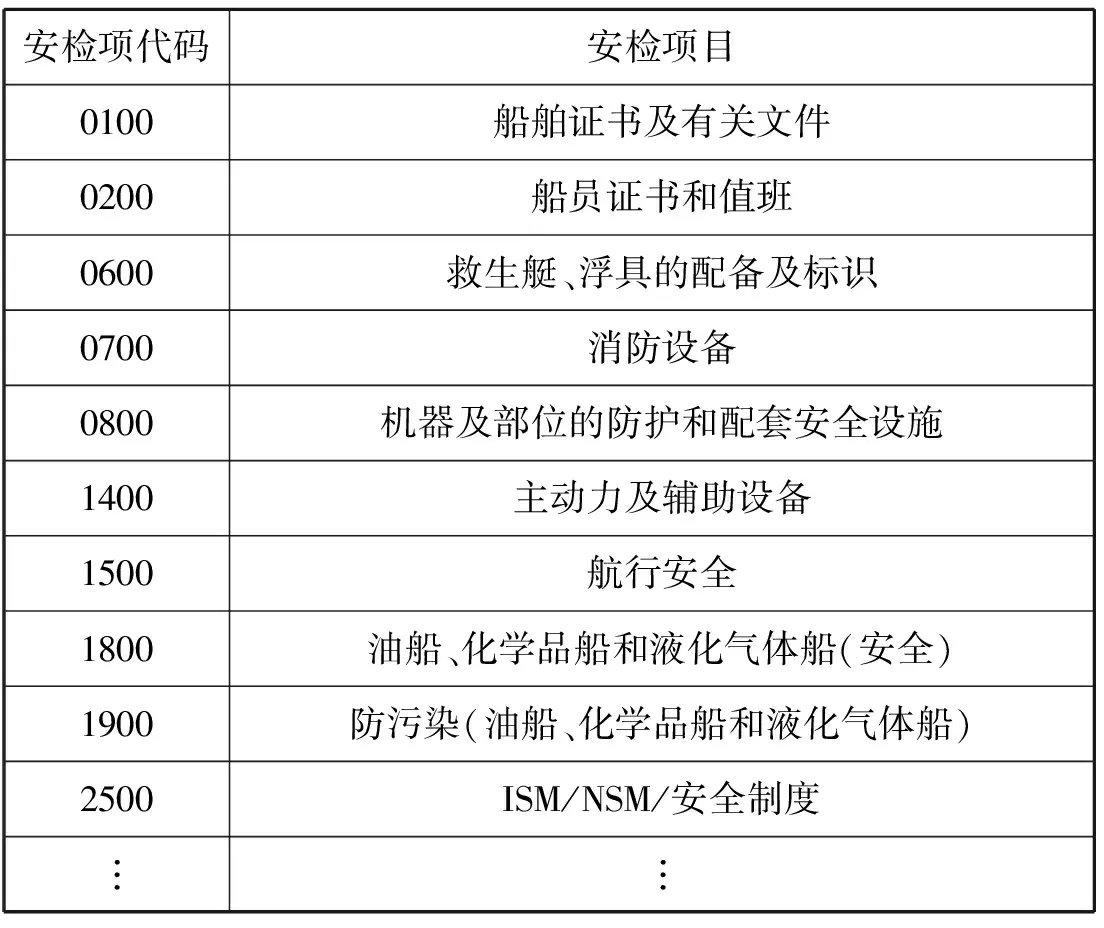
表2 内河船舶安全检查主要缺陷分类
根据船舶安检项目大类进行分类之后,得到处理后船舶安全检查缺陷数据频数分布图(见图2)。
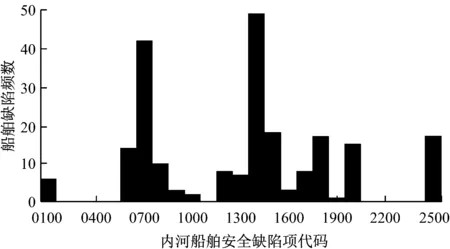
图2 处理后船舶安全检查缺陷数据频数分布图
由图2可知,采用大类统计后,缺陷频数都有提高,高频缺陷都集中在0700和1400附近。数据经过归类处理,复杂程度降低,规律更加明显,便于后期对数据进行关联规则挖掘。但是,基于频数统计得到的只是简单的规律,难以在大量数据中找到隐含规律。
2.1.2目标数据转换
经过上述分析,确定数据挖掘的目标数据,即缺陷大类。由于该研究的目标是寻找高频关联缺陷项集,因此低频项可当作数据噪声剔除。对长江海事局各分支海事局的船舶安检数据进行汇总,剔除低频数据之后按照频率排序,统计出10个高频缺陷大类候选项(见表3)。为保证数据挖掘能得到最有用的结果,避免产生过多无用的候选集而影响数据挖掘算法的效率[11],对每艘船舶的安检记录中属于这10个高频缺陷大类的缺陷集合进行统计,得到的缺陷信息集合即为数据挖掘的原始样本集。
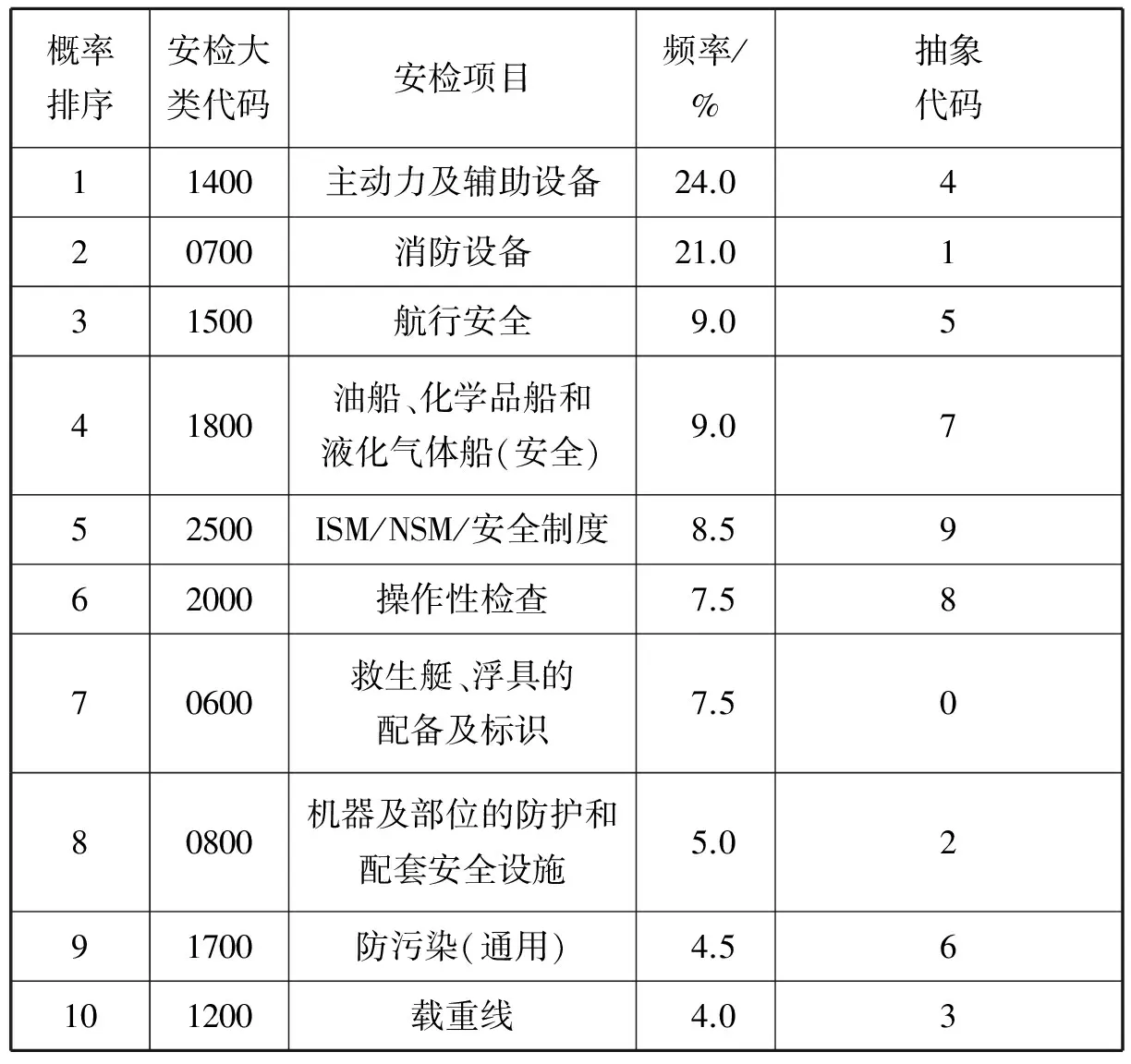
表3 主要缺陷信息列表
若将大量船舶安全缺陷信息直接存储到数据库中进行分析,则不仅在查询设计上语句复杂、时间复杂度高,而且对计算性能有很高的要求。因此,需对缺陷信息进行抽象转换。数据转换的目的是对数据进行降维处理,找到真正有用的特征,减少数据挖掘时的变量个数。[12]基于该思想,定义船舶安检过程中所有高频缺陷大类的集合为事务,将现实的船舶安检缺陷事务抽象为数字形式的代码集合,去除船名、船型等信息,以减少数据挖掘时要考虑的因素,并克服数据挖掘工具的局限性。[13]由此,将原始样本集的船舶安检缺陷信息进一步抽象为0~9这10个数字的代码集合,每个抽象代码对应一个船舶安检大类代码;在各个事务中消除重复的项形成缺陷项集,并赋予唯一的事务标志数字,格式为{事务标志(No);项集(ITEM)}(如{1;1,2,7,8,9}),将这样的信息存至数据库中。至此,将数据转化为数据挖掘所需的格式,完成数据挖掘前的数据准备工作。
2.2数据挖掘
2.2.1内河船舶安全缺陷关联规则挖掘软件
为更好地进行数据存储,数据库采用RDBMS技术,使用SQL Server进行内河船舶缺陷数据库开发。由于SQL语言[14]难以实现灵活深入的数据分析表达,因此开发内河船舶安全缺陷关联规则挖掘软件,采用C#语言连接数据库接口调用数据,通过可视化界面简化数据挖掘操作,并提供直观的结果展示界面。程序运行和结果演示见图3。

图3 数据挖掘程序运行和结果演示
内河船舶安全缺陷关联规则挖掘软件首先通过连接内河船舶缺陷数据库调用船舶缺陷数据,利用Apriori算法找到数据中的所有缺陷项并将其形成候选缺陷项集合Ck;然后根据这些缺陷项在每艘船舶中出现的次数,在计数器COUNT中进行初次赋值,删除集合中低于支持度的项,形成频繁项集Lk;最后通过迭代,找到在所有船舶中出现频率高于支持度的缺陷项集,并在软件界面中以频繁项集展示。
2.2.2挖掘结果
由于该研究旨在对船舶缺陷项进行关联分析,以获取其中隐含的关联规则,因此需选择项集的支持度最小值,以确定频繁项集。支持度的定义如下。
假定X是一个项集,D是一个事务集合或事务数据库,称D中包含X的缺陷个数与D中总的缺陷个数之比为X在D中的支持度,记作Support(X)[7],即

(1)
取0.2~0.5内的支持度进行数据挖掘测试,得到支持度与频繁项集统计图(见图4)。
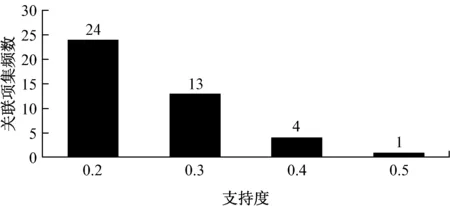
图4 支持度与频繁项集统计图
由图4可知:在取支持度为0.3时,频繁项集个数为13,数量较多且支持度不高;在取支持度为0.5时,只有一个频繁项集,难以进行分析比较;在取支持度为0.4时,支持度较高且有多样的关联规则。因此,取支持度为0.4进行数据挖掘。[15]统计支持度在0.4时挖掘到的结果(见表4)。
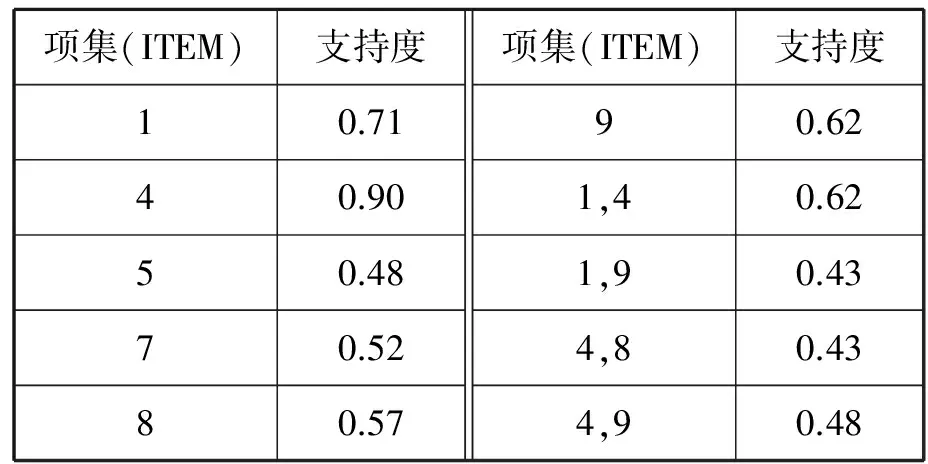
表4 频繁项集
2.3结果分析
对于一个项集X,若其支持度不小于最小支持度,则称X为频繁项集,在得到船舶安检缺陷的频繁项集后,需将抽象的数据还原为客观的船舶安全缺陷进行解释和评价。
表4中,只含有1项的项集为高频缺陷项;含有2个及2个以上项的项集为频繁项集,为该研究的重点。项集{1,4}即消防设备和主动力及辅助设备,这2项缺陷的关联规则的支持度最高,为0.62,表明其在一艘船舶的安检过程中同时出现的概率高达62%。可据此规划下一步检查目标,或作为判定船舶不符合初步检查要求的依据等。
为进一步研究这2项缺陷的规律,引入置信度进行分析。置信度定义为:对形如X→Y的关联规则,X和Y分别称为关联规则的先导及后继,其中X和Y都是项集,规则的置信度为事务集合D中既包含X也包含Y的事务个数与D中包含X的个数之比,记作Confidence(X→Y)[7],即

(2)
以项集{1,4}为例,根据置信度定义得:Confidence(1→4)=86.7%;Confidence(4→1)=68.4%。
由于关联规则(1→4)有更高的置信度,因此可认为规则(1→4)为项集{1,4}唯一的关联规则,即在船舶安检中若出现缺陷项1,则当0700消防设备有缺陷时,检测1400主动力及辅助设备有缺陷的概率高达86.67%。由此,通过关联规则数据挖掘可得出结论:当消防设备出现缺陷时,主动力及辅助设备也很可能出现缺陷。
统计支持度为0.4时各频繁项集的置信度,结果见表5。
为保证关联规则的有效性,取支持度为0.4,最小置信度为60%的数据进行统计,将数据制作成关联规则路径图(见图5)。

表5 关联规则置信度

图5 关联规则路径图
图5中,置信度大于80%的关联规则为(1→4),(9→4)和(8→4),即出现消防设备缺陷及ISM/NSM/安全制度或操作性检查缺陷时,都会有>80%的概率出现主动力及辅助设备缺陷。
当置信度>60%时,根据最大置信度进行路径选择可得关联规则(9→4→1)和(8→4→1),即在内河船舶安全检查时,当出现ISM/NSM/安全制度缺陷或操作性检查缺陷时,继续检查主动力和辅助设备,其会有83.3%的概率出现缺陷;再继续检查消防设备缺陷,其产生缺陷的概率达68.4%。
至此,通过关联规则挖掘的方法找到可靠性较高的内河船舶安全缺陷关联规则,证明内河船舶安全缺陷之间存在关联性,可用于指导船舶安全检查。
3 结束语
基于数据挖掘理论、内河船舶安全检查的实际情况和长江海事局的船舶安检数据,研究得到适用的内河船舶关联规则数据挖掘方法。对该方法进行数据挖掘和分析,得到以下结论。
1) 内河船舶的安全缺陷之间存在关联性。例如,当产生消防设备缺陷时,主动力及辅助设备有较高的概率也同时产生缺陷。
2) 存在支持度较高的关联规则,即该类规则下缺陷同时产生的概率较高,可重点检查该类缺陷,避免随机抽查安检效率不高的问题。
3) 某些缺陷形成的关联规则存在较高的置信度,在安检过程中发现该类缺陷时可通过高置信度的关联规则迅速找到其他缺陷。
由于目前内河船舶安检数据有限,因此该研究对船舶安检大类进行数据挖掘并建立关联规则旨在研究适用于内河船舶安全检查的数据挖掘方法及验证船舶缺陷间是否存在关联性。随着数据逐渐丰富,可对细分的缺陷项进行关联规则挖掘,或引入滞留、事故参数,为船舶安全检查工作提供更好的技术决策支持。
[2] 刘晓葳,朱建平.大数据内涵的挖掘角度辨析[J].中国统计,2013(4):59-61.
[3] 滕广青,毛英爽.国外数据挖掘应用研究与发展分析[J]. 统计研究,2005(12):68-70.
[4] 中国港口国监督数据管理中心. 2012年中国港口国监督数据分析年报[EB/OL]. [2013-05-10](2013-12-07).http://www.moc.gov.cn/zizhan/zhishuJG/haishiju/chuanbojiandu/201305/P020130523308494046 599.pdf.
[5] 戴耀存,陈兴伟,陈雪峰.船舶港口国检查的滞留原因分析[J].中国航海,2010,33(3):64-68.
[6] 梁静国.决策支持系统与决策知识发现[M].哈尔滨:哈尔滨工程大学出版社,2007:207-215.
[7] 胡可云,田凤占,黄厚宽. 数据挖掘理论与应用[M].北京:北京交通大学出版社, 2008:4-12,103-106.
[8] FAYYAD U.From Data Mining to Knowledge Discovery in Databases[J]. AI Magazine, 1996,17(3):37-54.
[9] 熊平.基于杂度削减的连续属性离散化方法[J].统计与决策,2012(5):35-37.
[10] 陈晶,金永兴,袁建中,等. PSC数据中船龄与缺陷相关性的可视化挖掘[J]. 船舶工程,2013,35(5):109-111.
[11] SZCZUKA M, SOSNOWSKI L, KRASUSKI A, et al. Using Domain Knowledge in Initial Stages of KDD: Optimization of Compound Object Processing[J]. Fundamenta Informaticae,2014,129(4): 341-364.
[12] 史忠植.知识发现[M].2版.北京:清华大学出版社,2011:2-5.
[13] 黄常海,高德毅,胡甚平,等.基于Apriori算法的船舶交通事故关联规则分析[J]. 上海海事大学学报,2014,35(3):18-22.
[14] 覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce的竞争与共生[J].软件学报,2012,23(1):32-45.
[15] 刘正江,吴兆麟.基于船舶碰撞事故调查报告的人的因素数据挖掘[J].中国航海,2004(2):1-6.
AssociationAmongSafetyDefectsforInlandShip
HAOYong1,2,3,HUANGQiang1,3
(1. School of Navigation, Wuhan University of Technology, Wuhan 430063, China;2. National Engineering Research Center for Water Transport Safety, Wuhan 430063, China;3. Hubei Key Laboratory of Inland Shipping Technology, Wuhan 430063, China)
U691+.6;U698
A
2016-04-15
郝 勇(1966—),男,湖北潜江人,副教授,博士,主要从事海事管理和水上交通工程教学与研究。E-mail:marinehao@126.com
1000-4653(2016)03-0077-05
