基于隐含狄列克雷分配分类特征扩展的微博广告过滤方法
2016-09-29邢金彪崔超远孙丙宇宋良图
邢金彪 崔超远 孙丙宇 宋良图


摘要:传统的微博广告过滤方法忽略了微博广告文本的数据稀疏性、语义信息和广告背景领域特征等因素的影响。针对这些问题,提出一种基于隐含狄列克雷分配(LDA)分类特征扩展的广告过滤方法。首先,将微博分为正常微博和广告型微博,并分别构建LDA主题模型预测短文本对应的主题分布,将主题中的词作为特征扩展的基础;其次,在特征扩展时结合文本类别信息提取背景领域特征,以降低其对文本分类的影响;最后,将扩展后的特征向量作为分类器的输入,根据支持向量机(SVM)的分类结果过滤广告。实验结果表明,与现有的仅基于短文本分类的过滤方法相比,其准确率平均提升4个百分点。因此,该方法能有效扩展文本特征,并降低背景领域特征的影响,更适用于数据量较大的微博广告过滤。
关键词:广告过滤;隐含狄列克雷分配;短文本分类;支持向量机;特征扩展
中图分类号:TP181
文献标志码:A
0引言
当前,微博作为一种新的传播载体,允许任何人用电脑、手机等方式在任何时间发布任何言论,且这些言论能迅速传播给互联网所能触及的任何人[1]。微博这种实时且传播迅速的特点,使其蕴含了巨大的商业价值,越来越多的微博用户通过自己的账户发布商品等广告信息。逐渐增多的微博广告不仅影响用户体验,还对微博平台上的舆情分析等研究产生不利影响。该现象依靠现有的微博平台提供的举报和屏蔽功能很难进行监管。因此,如何有效过滤广告,成为了一个亟待解决的问题。
微博广告过滤是信息过滤的一种[2],主要指从大量的微博中把广告删除,保留非广告内容。因此微博广告过滤可归结为短文本分类问题,将微博分为正常微博和广告型微博。而微博文本作为短文本,其关键特征非常稀疏且上下文依赖性强,目前的微博广告过滤方法不能解决短文本特征稀疏问题;且中文词汇中存在大量同义词,采用一般的特征提取方法,同义词会被看作不同的特征,影响分类性能[3]。因此本文结合隐含狄列克雷分配(Latent Dirichlet Allocation, LDA)主题模型[4]实现特征扩展,解决特征稀疏及同义词影响分类性能的问题。进一步分析发现,由于广告涉及领域多,在特征扩展时可能会引入背景领域特征等噪声数据,影响分类效果,因此,本文在特征扩展时引入文本类别信息,来降低其对分类效果的影响。最后将特征扩展后形成的有效特征向量作为分类器的输入,使用支持向量机(Support Vector Machine, SVM)分类器进行分类,实现广告过滤功能。
1相关工作
目前的微博广告过滤方法主要有基于统计分析的方法和基于短文本分类的方法。王琳等[5]基于统计数据分析了噪声微博和相似微博的特点,提出了一种面向微博文本流的噪声判别和内容相似性双重检测的过滤方法: 通过统一资源定位符(Uniform Resource Locator, URL)链接、字符率、高频词等特征判别,过滤噪声微博;然而,URL已不能作为微博是否为广告的依据。因此,高俊波等[6]从微博文本内容分析,基于短文本分类方法实现广告过滤;但该方法缺乏对文本语义的考虑。研究表明,文本的语义主题信息对文本的分类有很大的影响。如方东昊[7]将词向量特征空间扩展为语义向量特征空间,并对文本进行分类,提升了分类性能;刁宇峰等[8]利用LDA主题模型对博客中的博文进行主题提取, 并结合主题信息进行判断,识别Blog空间的垃圾评论。
基于短文本分类的方法则面临微博短文本特征稀疏的问题。许多学者从特征扩展的角度进行了研究,如Xu等[9]以Wikipedia为数据源,通过对能够表征微博主题的特征项进行语义拓展来提高主题聚类学习模型的性能;该方法虽然能降低特征的稀疏性,但也同时存在引入噪声数据的风险。吕超镇等[10]通过构建LDA模型,选择较高概率的主题的主题词对短文本进行特征扩充,形成较为有效的短文本的特征向量,并以此进行分类。
如果将微博分为正常微博和广告型微博,每一类都涉及众多领域(包括电商广告、招聘广告等),包含丰富的背景领域特征(词汇),涉及较多的主题。所谓背景领域特征是指微博短文本中描述广告所宣传的领域的特征、词汇等,具有较为明显的领域主题特征,这些特征具有较好的类别区分能力。因此,在解决现有的微博广告过滤方法所面临的特征稀疏问题时,若直接通过LDA预测微博文档主题,并盲目地利用相应的高概率主题词进行特征扩展,会促使微博主题偏离目标类别(广告或非广告),影响最终的广告过滤效果。如对于如下一条广告博文:
“把你的名字做成项链,戴在胸前,心跳多久,爱你多久,良心推荐,首饰纯手工,用名字定制项链,成就属于你的极致浪漫,@***,快来定制你的专属项链吧。”
该博文为涉及情感领域的广告文本,包含较多的情感背景特征,若直接对其进行特征扩展,会引入更多的情感特征,在预测主题时,则会更倾向于正常微博的情感主题类别,偏离了其目标类别——广告型微博。
2基于LDA分类特征扩展的微博广告过滤方法
如上所述, 将广告过滤问题归为微博短文本分类问题,现有的广告过滤方法仍不能解决短文本特征稀疏和微博广告所在领域背景特征影响分类性能的问题。因此本文结合文献[10]中特征扩展的方法,提出基于LDA分类特征扩展的微博广告过滤方法以解决这些问题。
2.1隐含狄列克雷分配
隐含狄列克雷分配(Latent Dirichlet Allocation, LDA)是一种文档主题生成模型[4],它包含三层结构:单词、主题和文档。LDA是一种非监督机器学习技术,可以用来识别大规模文档集或语料库中潜藏的主题信息,采用词袋(Bag of Words, BoW)方法,将每一篇文档视为一个词频向量,词与词之间没有先后顺序,从而将文本信息转化为易于建模的数字信息。
对于语料库中的每篇文档,LDA定义了如下生成过程:
1) 对每一篇文档,从主题分布中抽取一个主题;
2) 从被抽到的主题对应的单词分布中抽取一个单词;
3) 重复上述过程直至遍历文档中的每一个单词。
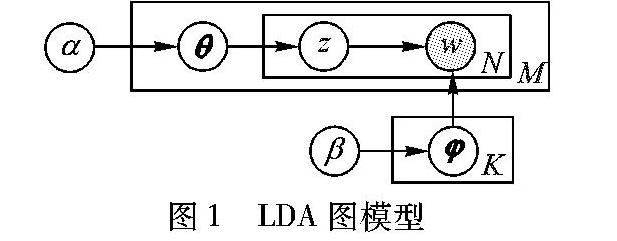
LDA图模型如图1所示,其中:θ表示文本主题概率分布,φ表示主题词概率分布,α、 β分别是θ、 φ的超参数;w表示可观测的单词;z表示主题;K表示主题数;M为文档数;N为文档中的词数。
图1模型中:阴影圆圈表示可观测变量,非阴影圆圈表示潜在变量;箭头表示两变量间的条件依赖性;方框表示重复抽样,重复次数在方框的右下角。主题z在文档d上以及单词w在主题上分别服从参数为θ和φ的多项分布,而这两个参数又分别服从超参数为α和β的Dirichlet分布(因为Dirichlet分布是多项分布的共轭分布),所以LDA主题模型是一种概率生成模型。其中:超参数α和β需指定;w是可见的(标记为深色);z需要学习;θ和φ需要推断,通常情况下可以用吉布斯采样(Gibbs sampling)[11]来实现。
2.2基于LDA的分类特征扩展及背景特征影响消除
分类特征扩展是指在进行特征扩展时,按照文本所属类别从中选取合适的特征进行扩展,以便降低背景领域特征对分类效果的影响。李文波等[12]研究发现使用LDA模型进行文本分类时,附加类别标签能够提升分类效果,所以在特征扩展时按分类进行是切实有效的。
图2所描述的是本文模型的文档集合结构,文档集合(C)中的所有文档被划分为正常微博(C1)和广告微博(C2),每一类又包含若干个隐含主题(底部小圆)。该模型多了一层文档类别层,即将类别信息嵌入到模型中。针对每一类别的文档集合分别构建LDA模型,并得到对应的“文档主题”分布,作为下一步文档特征扩展的基础。
根据以上分析及文本集合结构,本文建立的微博广告过滤模型如图3所示。
如图3所示,训练集和测试集经过相同的预处理及特征提取操作,训练集用于分类构建LDA模型和训练分类器,并将生成的LDA模型用于文档的特征扩展,两处特征扩展的区别在于测试集在特征扩展时需要考虑消除背景领域特征的影响,而训练集由于文档类别已知则不需要。本文主要工作集中在分类构建LDA模型、特征扩展以及消除背景领域特征的影响。
2.2.1特征提取及加权
在构建本文方法前需要对原始数据进行预处理、特征提取等操作,并选择合适的文本表示形式,便于分类器处理。首先,预处理主要包括去除噪声数据(HTML标签、特殊符号等)、分词、去除停用词。其中,分词的好坏直接影响到最终的实验效果。由于传统的中文文本语料词典难以涵盖微博中出现的网络新词,直接使用NLPIR(Natural Language Processing and Information Retrieval sharing platform)中文分词工具[13]进行分词,其效果很不理想,本文也在实验中验证了这一点。因此本文将实验时收集的网络最新热点事件、网络用语等,用于分词时加载,改善分词效果。
本文采用向量空间模型(Vector Space Model,VSM)[14]对文本数据进行描述,文本空间被视为一组特征向量组成的向量空间。因此,对于给定的文档集D={d1,d2,…,dM}(M为文档总数),其中包含词为V={v1,v2,…,vN}(N为词的总数),可以表示成一个M*N的矩阵空间;权值wij表示词j在文档i中的权重,采用TF-IDF算法[15]、词频(Term Frequency, TF)、逆文档频率(Inverse Document Frequency, IDF)计算,计算公式如式(1)。
2.2.2特征扩展及消除背景特征影响
文档特征提取后,利用分类构建的LDA模型预测文档的主题分布,并选取概率最大的主题作为文档特征扩展的基础,对于类别未知的文档在特征扩展时需处理背景特征的影响。将处理后的文档作为分类器的输入,根据分类结果区分广告和正常微博。因此本文方法主要包含两个阶段:生成候选特征扩展词集及消除背景领域特征影响。
1)候选特征扩展词集生成。
对比传统的特征扩展方法(如文献[10]所述),本文在特征扩展时分类进行。给定如图2所示的文档集合结构Document={DNormal,DAd},其中DNormal表示正常微博文档集,DAd表示广告型微博文档集,为两类文档集分别构建LDA模型,得到ModelLDA(θc,φc)(c∈{Normal,Ad})。利用已建立的LDA模型来预测待测文档x的主题分布,并选取概率最大的主题Topicmax。
定义1候选特征扩展词集Candidate。 Candidate={(wi,pi)|i∈N},其中(wi,pi)表示Topicmax的前Top-N个主题词及其对应的概率值。Candidate用于存储文档x的候选特征扩展词。
2)背景特征影响消除。
若待测文档x的类别已知(如训练集),则在特征扩展时不会使背景领域特征过分放大而影响文本分类。
若待测文档x的类别未知(如测试集),盲目地对其特征项进行扩展,可能会放大背景领域特征的影响,使文档在预测分类时偏离其原应正确归属的类别(广告、正常)。因此首先分别利用ModelLDA(θc,φc)对待测文档x进行预测,产生候选特征扩展集Candidatec(c∈{Normal,Ad});并将LDA用作类条件概率,根据式(2)计算类条件概率,判断待测文档x可能所属的类别。
步骤5计算背景特征词在候选特征扩展集中的比例η,当η大于等于阈值γ时,对于Comm集中的每一个特征item,修改其权重为:pitem=|pNormal-pAd|,并将Candidate中对应的权值更新;若η小于γ,则表明背景领域特征影响较小,无需修改Candidate中相应特征。最终的特征扩展候选词集Candidate=Candidate。
步骤6将Candidate中的特征词项扩展至文档x的特征向量中,对于x中已存在的特征项,替换其权值,生成最终表示文档x的有效特征向量,作为分类器的输入。
3实验流程及结果分析
3.1实验数据
实验数据源自新浪微博2015年06月—2015年07月的微博信息,人工标注后获得有效广告微博3315条,非广告微博4813条,构成一个微博语料集。
3.2实验设置
1)主题数。采用LDA模型对文本集进行主题建模时,主题数K对模型拟合文本集的性能以及最终的分类性能影响很大,对于K的取值本文采用统计语言模型中常用的困惑度(Perlexity)来进行选取[16]。困惑度是衡量一个模型好与坏的评价指标,困惑度越小,代表模型的泛化能力越强。困惑度公式[4]为:
准确率:即正常微博“保留率”,体现了过滤方法辨别广告的准确度。
召回率:即被保留下来的正常微博数量占所有正常微博数量的比例,体现了广告过滤模型过滤广告的完备性。
F1值:实际上是召回率和正确率的调和平均, 当F1较高时则能说明实验方法比较有效。
4)实验分组。
文献[6]中已证明基于文本内容分析的微博广告过滤模型优于文献[5]中基于统计分析的方法。因此本文基于文献[6]方法设计对比实验,每次实验采用相同数据集。具体如下:
方法1:文献[6]所述基于文本内容分析的方法;
方法2:在方法1基础上增加短文本特征扩展处理;
本文方法:利用本文所描述的增加特征扩展及消除背景特征影响方法设计实验,并根据分类后的结果设计过滤器。
3.3实验结果及对比
1)主题数。实验将LDA 模型的主题数设置为20~100 (间隔5),两种类别的训练集困惑度随主题数变化情况如图4所示,随着主题数不断增加,两种类别训练集的困惑度均逐渐下降,当达到55时,下降趋势趋于平稳。而主题数越多,LDA模型估计的参数越多,计算代价越大,因此取主题数K=55。
根据实验结果分析可知,Topic A主要表示股市相关的主题,Topic B表示娱乐相关的信息,Topic C表示服饰、百货等相关的广告主题,Topic D表示化妆品相关的广告主题。此处生成的主题特征作为候选特征扩展集的基础。
3)阈值γ对算法性能的影响。背景特征词在候选特征集中比例的阈值γ大小的选择对实验结果有较大的影响。本文利用已经标注的5000条微博训练集,以F1值作为评判标准,对该参数进行了多组实验,实验结果如图5所示。
当γ取值范围在0.1~0.3时,F1值增长较快;当γ大于0.3时,F1开始下降并趋于平稳。由于γ影响最终的实验效果,若γ设定较小,则背景特征较少不足以对分类效果产生影响时增加了不必要的计算,且可能过滤掉重要的特征词,影响分类性能;若γ较大,则遗漏较多的背景特征,使得实验效果趋于仅进行特征扩展的方法2,影响对算法性能的判断。因此通过实验分析将阈值γ取值0.3。
4)对比实验。
由于数据集越大LDA模型构建得越好,则特征扩展的效果越明显,因此本文实验通过改变数据集的大小,对比分析特征扩展及背景领域特征两因素对实验效果的影响。表3显示的是三种方法的实验结果对比。
从表3的对比结果中可以看出,当数据集较小时,三种方法的过滤效果均较差,且方法2和本文方法实验效果相近,这是因为LDA模型未得到充分训练,特征扩展效果不佳且分类器未训练到较好的水平。随着数据集的增大,分类器分类效果明显提升,后两种方法中的文本特征得到扩展,其准确率明显高于方法1。然而当数据集增大到一定程度时,三种方法准确率增长趋于平缓,本文方法在准确率上仍有提升,主要原因是随着实验数据集的充分增大,分类构建的LDA模型能为特征扩展提供更好的候选特征扩展集,但方法2在特征扩展时也引入了较多的背景领域特征对实验效果产生了不利影响。本文方法增加了消除背景领域特征影响的操作,使得准确率较方法2有了进一步的提升。
为验证本文设计的广告过滤方法的实际性能,利用已训练好的三种方法,将新浪微博平台2015年07月17日—2015年07月23日,每天下载的500条微博信息用于实验,实验结果对比如图6所示。
图6中,横轴表示日期07月17日—07月23日,纵轴表示F1值。实验结果表明本文方法明显优于文献[6]中仅从文本内容分析的方法(即方法1)。这主要是因为文献[6]没有考虑微博文本的语义信息和特征稀疏的问题,然而本文方法增加了特征扩展处理,又消除广告背景领域特征对分类性能的影响,从而使过滤效果得到进一步的提升,实验结果较现有过滤方法的F1值平均提升4个百分点。
4结语
本文提出了一种基于LDA分类特征扩展的广告过滤方法,弥补了现有的仅基于短文本分类的微博广告过滤方法在广告文本语义信息、文本数据稀疏、广告背景领域特征影响等方面的不足。该方法能有效地实现特征扩展,降低广告背景领域特征的影响,且本文方法对处理数据量较大的微博数据效果更好。实验证明本文方法优于文献[6]中基于文本内容分析的方法,是一种有效的微博广告过滤方法。
然而本文只针对微博文本特征进行研究,后续研究可以通过检测用户的所有微博信息判断广告用户,实现对特殊用户的特殊关注,以从源头控制微博广告的传播。
参考文献:
[1]张剑峰,夏云庆,姚建民.微博文本处理研究综述[J].中文信息学报,2012,26(4):21-27. (ZHANG J F, XIA Y Q, YAO J M. A review towards microtext processing [J]. Journal of Chinese Information Processing, 2012, 26(4): 21-27.)
[2]徐小琳,阙喜戎,程时端.信息过滤技术和个性化信息服务[J].计算机工程与应用,2003,39(9):182-184. (XU X L, QUE X R, CHENG S D. Information filtering and user modeling [J]. Computer Engineering and Applications, 2003,39(9):182-184.)
[3]贺涛,曹先彬,谭辉.基于免疫的中文网络短文本聚类算法[J].自动化学报,2009,35(7):896-902. (HE T, CAO X B, TAN H. An immune based algorithm for Chinese network short text clustering [J]. Acta Automatica Sinica, 2009, 35(7): 896-902.)
[4]BLEI D M, NG A Y, JORDAN M I. Latent Dirichlet allocation [J]. Journal of Machine Learning Research, 2003, 3: 993-1022.
[5]王琳,冯时,徐伟丽,等.一种面向微博客文本流的噪音判别与内容相似性双重检测的过滤方法[J].计算机应用与软件,2012,29(8):25-29. (WANG L, FENG S, XU W L, et al. A filtering approach for spam discrimination and content similarity double detection for microblog text stream [J]. Computer Applications and Software, 2012, 29(8):25-29.)
[6]高俊波,梅波.基于文本内容分析的微博广告过滤模型研究[J].计算机工程,2014,40(5):17-20. (GAO J B, MEI B. Research on microblog advertisement filtering model based on text content analysis [J]. Computer Engineering, 2014, 40(5): 17-20.)
[7]方东昊.基于LDA的微博短文本分类技术的研究与实现[D].沈阳:东北大学, 2011:23-28. (FANG D H. Study and implementation for microblogs short text classification based on LDA [D]. Shenyang: Northeastern University, 2011: 23-28.)
[8]刁宇峰,杨亮,林鸿飞.基于LDA模型的博客垃圾评论发现[J].中文信息学报,2011,25(1):41-47. (DIAO Y F, YANG L, LIN H F. LDA-based opinion spam discovering [J]. Journal of Chinese Information Processing, 2011, 25(1): 41-47.)
[9]XU T, OARD D W. Wikipedia-based topic clustering for microblogs[J]. Proceedings of the American Society for Information Science and Technology, 2011, 48(1): 1-10.
http://xueshu.baidu.com/s?wd=paperuri%3A%28c10c0fa9062177526c1e6ca5fc35b6c6%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Fonlinelibrary.wiley.com%2Fdoi%2F10.1002%2Fmeet.2011.14504801186%2Fpdf&ie=utf-8&sc_us=3265163405836292075
[10]吕超镇,姬东鸿,吴飞飞.基于LDA特征扩展的短文本分类[J].计算机工程与应用,2015,51(4):123-127. (LYU C Z, JI D H, WU F F. Short text classification based on expanding feature of LDA [J]. Computer Engineering and Applications, 2015, 51(4): 123-127.).
[11]GRIFFITHS T L, STEYVERS M. Finding scientific topics [J]. Proceedings of the National Academy of Sciences of the United States of America, 2004,101(S1): 5228-5235.
[12]李文波,孙乐,张大鲲.基于Labeled-LDA模型的文本分类新算法[J].计算机学报,2008,31(4):620-627. (LI W B, SUN L, ZHANG D K. Text classification based on labeled-LDA model [J]. Chinese Journal of Computers, 2008, 31(4): 620-627.)
[13]张华平.NLPIR汉语分词系统[CP/OL]. [2015-07-17]. http://ictclas.nlpir.org/. (ZHANG H P. Chinese lexical analysis system [CP/OL]. [2015-07-17]. http://ictclas.nlpir.org/.)
[14]SALTON G, WONG A, YANG C S. A vector space model for automatic indexing [J]. Communications of the ACM, 1975, 18(11): 613-620.
[15]SALTON G, YANG C S. On the specification of term values in automatic indexing [J]. Journal of Documentation, 1973, 29(4): 351-372.
[16]CAO J, XIA T, et al. A density-based method for adaptive LDA model selection [J]. Neurocomputing, 2009, 72(7/8/9): 1775-1781.
[17]CHANG C-C, LIN C-J. LIBSVM: a library for support vector machines [J]. ACM Transactions on Intelligent Systems and Technology, 2011, 2(3): Article No. 27.
