基于信息融合的中文微博可信度评估方法
2016-09-29高明霞陈福荣
高明霞 陈福荣


摘要:针对中文微博信息的特点及这些特点的可测量性和实际任务,系统地梳理了中文微博信息可信度测量指标,并将其进行了谱系化分析,提出一个基于信息融合的中文微博可信度评估框架CCM-IF。首先,为本质不同的三个异构特征:文本内容、信息作者与信息传播使用了不同的度量方式;其次,基于决策层可信度的模糊认知特点,采用了多维证据理论进行特征融合;最后,收集了新浪微博两个真实数据集进行了一系列实验。实验结果表明,与传统信息检索排序方法平滑语言模型(LMJM)相比,CCM-IF符合用户需求的信息占比提高了10%~20%。因此,作为一个静态质量评估指标,CCM-IF可直接用于微博检索排序、垃圾微博过滤等实际任务。
关键词:中文微博;可信度;信息融合;四象限法则; 证据理论
中图分类号:TP391
文献标志码:A
0引言
最近几年,社会媒体得到迅猛发展,特别是微博、微信等社交软件,已发展成为互联网上的巨擘。中国互联网络信息中心(China Internet Network Information Center, CNNIC)于2014年7月发布的《第34次中国互联网络发展状况统计报告》显示,截至2014年6月,我国微博用户规模为2.75亿,网民使用率为43.6%,微博已进入平稳成熟期。但是微博固有的草根特性带来的问题依然存在,也即用户对微博内容的真实性和价值依然难以判断。因此,针对微博在信息书写、信息传播、社会网络分析等方面的固有特点,分析、评估微博内容、用户,并将其应用于微博信息综合或垂直搜索、垃圾微博过滤等领域的研究,已经成为微博研究领域的重要内容之一[1]。
由于时间因素,目前对微博质量研究的实例大多集中于Twitter分析,例如文献[2-4]。这些研究可以分为两类,一类是利用传统分类技术的定性分析,这类研究需要大量样本,获取的是二值或多值的逻辑值;另一类是针对不同性能指标的定量算法,这些质量评估算法多数只关注信息本身或某一侧面,缺少系统、全面的分析和评估,更没有从模糊认知的角度进行度量。目前针对中文微博质量分析的研究多数集中于内容分析以及特定用户或主题提取,缺少专门针对质量进行定量评估的系统方法,例如高承实等[5]构建的三维空间就是针对微博舆情评估的指标。
本文从中文微博信息的特点入手,兼顾了这些特点的可测量性和实际任务,系统地梳理了中文微博信息可信度测量指标,并将其进行了谱系化分析,最终抽取出文本信息、信息作者与信息传播三个高层异构特征。考虑到可信度的模糊性本质,提出一个基于信息融合的中文微博可信度评估框架(Credibility of Chinese Microblog based on Information Fusion,CCM-IF),并依据中文微博特点以及信息融合技术实现了用于计算并融合三个高层异构特征的具体方法。最后,收集了新浪微博两个真实数据集进行了一系列实验。实验结果表明,本文提出的微博可信度评估方式作为一个静态质量评估指标可直接用于微博检索排序、垃圾微博过滤等实际任务;而且和传统信息检索排序方法平滑语言模型相比,该框架和计算方式在准确性方面有明显优势。
1相关工作
从社会媒体角度看,“可信度是主观认知的可信度,是指传播过程中,信息受播人对传播媒体的信赖度的主观评量”。微博是一种典型的社会媒体,对其可信度的研究属于质量评测的一种。下面从微博质量评估角度来讨论现有工作。
中文微博发展时间短,目前对微博质量研究的实例大多集中于Twitter分析。Castillo等[2]利用典型的分类算法对Twitter上的新闻类信息和其他类信息进行了可信和不可信的自动分类学习,其中对Twitter信息的特征从四个侧面(msg.,user,topic,prop.)进行了归类。自动分类方法需要大量人工标注的样本,并且得到的是一个二值逻辑结果。Ravikumar等[3]将微博看作一个包含用户、文本内容和网页的三层图结构,并建立了图中存在的各种链接,据此达到通过信任和传播为Twitter中文本内容排队的目的。Nagmoti等[4]描述了一个微博实时搜索中排序的新策略。该策略除微博属性外,还考虑了微博作者的社会网络属性并将其用于Twitter实时搜索的二次排序中,得到了较好的结果;但该方法涉及到的微博和作者属性太少,计算方式也相对简单。
目前针对中文微博质量分析的研究多数集中于内容分析和特定用户比较方面。高承实等[5]在研究了微博信息传播机制的基础上,结合信息空间模型构建了微博舆情的三维空间,并运用层次分析法建立了微博舆情监测指标体系。该体系中重要的监测和影响因素就是微博质量评估分析。焦德武等[6]探讨了微博在舆情生产中具有的作用与特征,并从微博内容维度和传播时间维度两个方面对微博舆情价值进行判断。郭秋艳等[7]基于新浪微博中用户数据,对名人效应进行了定量研究。Wang等[8] 通过比较新浪微博中认证和非认证用户的统计信息,提出了认证用户中只有很少部分有较大影响,是一些团体的核心成员。
从以上的分析可见,目前对微博质量研究的实例大多集中于Twitter分析,现有的针对中文微博质量的研究只关注信息本身或某一侧面,缺少系统、全面的分析和量化评估,更没有从“可信度”这一模糊认知角度进行定量分析。这正是本文要解决的问题。
2基于信息融合的可信度评估框架
微博,即微博客(Microblog)的简称,是一个基于用户关系的信息分享、传播以及获取平台,用户可通过Web、即时通信、电子邮件和手机等方式,以140字左右的文字更新信息并实现即时分享。从这个角度说,微博是一种典型的社会媒体,其可信度定义完全符合社会媒体可信度概念。
社会媒体可信度(social media credibility)这个词最早出现于19世纪中期,由Hovland等[9]提出。其确切定义经历了从信息客观属性到受众主观认知的本质转变。目前,OKeffe[10]的定义“可信度是主观认知的可信度,是指传播过程中,信息受播人对传播媒体的信赖度的主观评量”已被大多数人所接受。既然可信度是受众对媒体信息的主观认知和评估,那从受众角度出发、以多维视角和方法来定义和测量信息可信度,已成为此领域学术研究的基本准则。
为了对多个来源的观测信息进行统一分析、综合评估,信息融合技术逐渐兴起。本文的基本思想就是将微博可信度评估看作是一个信息融合问题进行具体分析。首先,参考文献[2,11]中涉及到的两种社会媒体信息可信度评估指标,并结合中文微博的特点,基于分层断代思想对微博信息可量化指标以及高层特征维度进行系统梳理与归属划分,获得了如图1所示的中文微博可信度影响因子谱系;然后参考信息融合Dasarathy模型及各层的融合技术,形式化数据层和特征层的具体评估方法,提出了基于信息融合的中文微博可信度评估框架(CCM-IF),并在该框架下实现了三个异构特征的评估方式以及最终的融合方法。文本信息影响因素多,各因素的激励作用不同,采用了相对简单的统计和度量;信息来源即用户可信度影响因素少,而且带有明显的模糊本质,参考著名的四象限法则提出了媒体用户四象限划分度量;考虑到媒体信息传播的共性,传播度量借鉴了文献[11]中博客的传播计算形式;考虑到可信度的模糊认知,最终的异构特征融合采用了具有模糊属性的多维证据理论。
3基于信息融合的可信度评估方法
3.1文本信息可信度测量
信息本身的可信度可以从客观和主观两个方面入手考察。客观方面不涉及社会性,单纯考虑信息本身的可信度,也即通常所说的文本质量。通常情况下,我们会假定:质量好的文本比质量差的文本更可信,在某种程度上,这正是用户对微博信息第一印象的直观反映。另一方面是用户对文本的主观印象,目前可直接测量的主观因素有转贴数(Sreposts)和评论数(Scomments),这两个影响因素都是正向激励因子,因为其可取值差别很大,所以使用了lg()形式的计算方式,如表1所示。文本质量的考察包括句法、语法、语气和语义四个层面。前两个层面体现作者的写作模式与写作习惯。一个可信的文本至少应该做到句法和语法正确,例如:一个拼写错误百出的文本很难被认定为是可信的。句法和语法方面,本文主要考虑了正向激励文本长度(Slength)和负向激励拼写错误(Sspelling)两个指标,具体计算方式如表1所示。文本的语气通常体现个人情绪和感情倾向。一个可信的文本语气应该客观,也即尽量少地涉及到表达情绪的因素,做到感情上客观公正。中文微博信息中和个人情绪相关的因素包括图标(Semoticons)、重复标点(Spunc)以及正/负性词(Sposi/neg)三个指标,重复标点只统计和情绪相关的问号、感叹号和省略号,这些因素的具体计算方式如表1所示。语义是文本质量更高层次的要求,与具体任务和领域相关,对其评价时需要有对应的参考量,一个可信的文本应该是与参考量语义相关的。由于不同的任务参考量可能不同,例如查询任务中的查询需求或信息聚类中的主题集合等,因此语义因素是一个依赖主题的指标,用于在具体任务中发挥作用进行文本预处理或最后步骤的领域识别。文本信息影响因素多,各因素的激励作用不同,采用了相对简单的统计和度量,如式(1):
3.2信息来源可信度测量
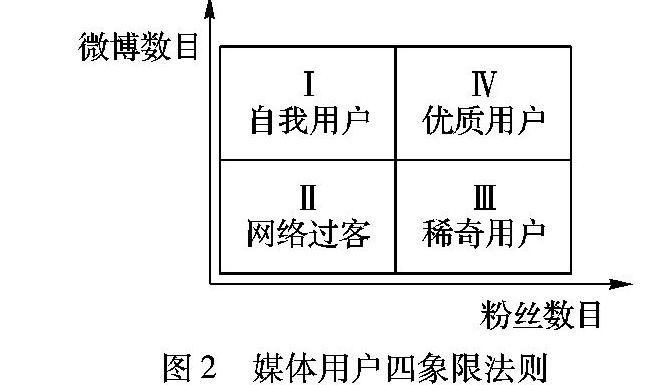
从本质上看,任何社会媒体信息最初都是由人产生的,因此信息来源(简称信源)可信度就是信息作者的可信度。社会媒体中的用户可信度通常又是由他的客观日常行为和主观外部评估累积形成。常见的可测量客观日常行为包括是否做过实名认证(Scertify)、发布的文本信息总数(Sposts);而常见的可测量外部评估通常包括粉丝数目(Sfellows)。这些指标中,影响较大的是实名认证。实名认证可看作是虚拟环境和现实世界的桥梁。因为做过认证的作者有为自己的言论负责的主观意愿,客观上也更容易被监督和审查,因此这个指标可以单独作为激励因子(>1)影响最终用户的可信度。粉丝数和信息总数这两个客观和主观因素配合可以粗略地区分不同类型的用户。借鉴著名的四象限法则,图2是一个主客观因素决定的媒体用户四象限分类图。
图2中,位于第四象限的用户是粉丝和发贴数目都高的优质用户,其可信度相对最高。位于第二象限的是两者都低的网络过客,这类用户对各种媒体信息的参与度最低,可信度也相对最低。位于第一和第三象限的用户一类是发贴多、粉丝少的自我用户或广告客户,这类用户的帖子关注度太低,价值也相对较低,接近网络过客;另一类是发贴少、粉丝多的稀奇用户,这类用户尽管发贴很少,但是粉丝众多,其帖子的关注度很高,因此可信度接近优质用户。通过上述分析用户的可信度大小关系符合:优质用户>稀奇用户自我用户>网络过客。区分用户的具体划分值和数据集分布密切相关,每类用户的实际取值和数据集性质以及实际任务相关。粉丝数和信息数这两个指标可取值范围差别太大,为了最终表现形式仍使用了lg()取值进行了缩减。考虑到认证的激励作用,用户的最终可信度值可以通过式(2)获取:
3.3信息传播可信度测量
和普通网页相比,社会媒体信息的传播能力更强。而影响媒体信息可信度传播的因素一般包括两项:一是时效,二是传播媒介。时效对新闻和热点事件是个不可忽视的影响因素,它的计算需要依赖于同一主题的媒体集合,可应用于具体任务,在此不讨论。传播媒介通常指信息从诞生到测量时经历的媒体用户,通常可以表达成如图3所示的树形结构,其中根A是原始作者,B、C、D则是从作者处进行了第一轮转发的社会媒体用户,同样E、F和G到I分别是从C、D处进行第二轮转发的用户。
传播媒介对文本信息可信度测量影响很大,这种影响方式主要通过两种情况递增媒体信息可信度。一种方式是传播媒介中包含可信度高的名人。例如:由于“李开复”在计算机领域的影响力,一个默默无闻的作者撰写的与计算机相关的信息被李开复转发后,其可信度将大幅提升,甚至等同于李开复自己的文本。另外一种方式是传播媒介中节点数目庞大。例如:一条媒体信息被1万人转发,尽管转发者可能都是一般用户,但是由于节点数目庞大,将导致这条信息的可信度大幅提升。另外一个需要注意的递增特点是,无论多少人转发,可信度都应该趋向于一个上限,因为当节点数大到一定程度后,再增加转发人数在可信度上已经没有明显贡献。例如1万人转发和1.1万人转发,在人类认知的模糊程度上,已经没有明显区别。考虑到上述可信度递增特点,本文借鉴了文献[11]中博客的传播影响定义了式(3)用于计算传播媒介对微博可信度的影响:
4实验与分析
微博可信度作为一种静态质量评估指标,可以应用于微博检索排名与垃圾微博过滤等多种实际任务,为了验证可信度评估效果,本文从数据堂(http://www.shujutang.com)收集了两个新浪微博真实数据集进行了微博检索排名实验。DS1数据集是主题相关的,选择了直接排序;为了避免查询主题偏好,分别选取4个不同查询主题对DS2进行了检索排名。
针对两个数据集中的数据,排名时分别使用了文本可信度值、文本+作者融合可信度值以及文本+作者+传播融合可信度值。微博检索依然属于信息检索范畴,信息检索中常用的传统检索排名方法平滑语言模型(Language Modeling with Jelinek-Mercer smoothing, LMJM)[14] 方法被用于和本文提出的可信评估进行了对比实验。
评估使用了不同情况下排名前20的信息中去重信息占比、相关信息占比以及有用信息占比。去重信息占比指去重信息数目与信息总数20之比;相关信息指信息中包括和查询主题一致的内容,相关信息占比指相关信息数目与去重信息数目之比;有用信息占比指符合用户需求的信息与相关信息之比。其中,对相关和有用信息的识别是通过人工标记获取的,为了消除个体差异,采用了多人标记结果取重叠部分的方式。
4.1数据及预处理
DS1数据集包括了从2014年3月14日到3月27关于“马航失联”的微博数据共2795条,涉及到用户1930个;DS2数据集没有固定主题,包括6万多条微博和1万多个用户。两个数据集的用户来源比较多,有个人也有权威机构,因此,用户可信度差别相对较大。图4和图5分别是DS1和DS2中用户的实际分布以及基于这一分布的四象限划分,其中DS2中仅包括随机抽取的2000个用户。
为了获取传播树需要实时遍历媒体网络,由于网络访问受限,实时获取每个用户相对困难。但是每条信息的转发数目很容易获取,而且基于四象限分类划分思想,媒体用户的可信度取值是一个8元素有限集,也即{认证优质客户,无认证优质客户,认证稀奇客户,无认证稀奇客户,认证自我用户,无认证自我用户,认证网络过客,无认证网络过客}。考虑到数据转发的常见情况和数据集特点,传播树可以采用有限集随机取样模拟产生。网络世界的转发情况通常可以归纳为三类:转发数目少、转发数目多以及转发数目适中。第一类转发数目少,转发者基本不包括优质客户或稀奇客户,因此随机取样的可选范围要去掉有限集中的前四个值;第二类转发数目多,转发者中必定包括优质客户或稀奇客户,随机取样的可选范围依然是8元素有限集,为了满足最终传播队列中必须包括有限集中的前四个值,需要附加一个检查替换步骤;第三类转发数目适中是中间状态,直接使用有限集随机取样即可。三种类型中第一种情况占比最多,通常情况下一个数据集中95%的信息都没有转发数,只有少数信息能引起用户关注,而转发数目多的信息更是寥寥无几。基于以上分析,结合具体数据集情况,确定三种转发情况的分类数据。
4.2结果分析
表2是DS1的排序结果,从表中可以看出,作者和传播两个上层特征对文本可信有显著影响,特别是用户特征将相关信息占比提高了20%多。对于“马航失联”这样的热点事件而言,一些权威新闻机构(例如路透社或CNN)的信息比一般用户更能获取公众认可,而这些权威新闻机构基本都属于认证优质客户范畴,因此相关信息占比大幅度提高。传播特征对相关信息的占比提高有限,这是因为DS1数据集中传播特征影响很小,只有10多条数据有传播信息,而且最大传播数只有7, 通过参数设定归属于适中(1 尽管LMJM方法的相关信息占比达到了100%,但是LMJM方法中有用信息的数目是0,而本文方法的有用信息占比达到了100%。表3中列出了针对DS1数据的LMJM和文本+作者+传播中排名前3的信息。从表3中可见,LMJM更注重“马航”在整个文本中出现的比率,因此这些无实际意义的短文本更易排名靠前;而本文方法更注重文本实际内容,因此有实际意义的长微博更易排名靠前。本文方法更符合用户对微博检索的实际需求,在很多检索情况下,少于5个字的短文本可以直接作为垃圾处理。 表4是DS2在四个不同主题上检索排序后得到的平均值。DS2 数据中没有转发数,传播特征没起作用。用户特征对文本可信有显著影响,特别是用户特征将相关信息占比提高了10%左右。尽管LMJM方法的相关信息占比和本文文本+作者融合相当,但是LMJM方法中有用信息占比明显偏低,而本文的有用信息占比达到了80%。通过详细分析,和DS1数据集类似,LMJM更注重主题在整个文本中出现的比率,因此一些无实际意义的短文本更易排名靠前;而本文提出方法更注重文本实际内容,因此有实际意义的长微博更易排名靠前。从这点来看,本文方法更符合用户对微博检索的实际需求。 5结语 从中文微博信息的特点入手,兼顾了这些特点的可测量性和实际任务,形成了中文微博可信度影响因子谱系。考虑到人类认知的模糊性本质,本文提出一个基于信息融合的中文微博可信度评估框架。该框架首先为本质不同的三个异构特征:文本内容、信息作者与信息传播分别使用了统计和、四象限法则与传播树排序的度量方式;其次,基于决策层可信度的模糊认知特点,采用了多维证据理论进行了最终的特征融合;最后,收集了新浪微博中两个真实数据集进行了一系列实验。实验结果表明: 与传统信息检索排序方法平滑语言模型(LMJM)相比,CCM-IF的符合用户需求的信息占比提高了10%~20%。因此,作为一个静态质量评估指标,CCM-IF可直接用于微博检索排序、垃圾微博过滤等实际任务。 尽管CCM-IF可以对可信度进行系统评估,但是从可信的定义可知,这是一个主观性比较强的概念。除了现有的文本内容、文本作者和信息传播三个高层特征以及文中讨论的体现这些特征的可测量指标外,其他很多指标比如:时效、作者文化层次、发帖频率等都可能对可信度有一定影响,而且不同指标可能的影响方式和程度也不同。因此,为现有指标和特征提供新的评估方式,增加新的影响指标与特征进一步完善可信度评估框架是未来要进行的研究工作。
参考文献:
[1]张剑峰,夏云庆,姚建民.微博文本处理研究综述[J].中文信息学报,2012,26(4):21-27. (ZHANG J F, XIA Y Q, YAO J M. A review towards micro text processing [J]. Journal of Chinese Information Processing, 2012, 26(4): 21-27.)
[2]
CASTILLO C, MENDOZA M, POBLETE B. Information credibility on twitter [C]// WWW 11: Proceedings of the 20th International Conference on World Wide Web. New York: ACM, 2011: 675-684.
[3]RAVIKUMAR S, BALAKRISHNAN R, KAMBHAMPATI S. Ranking tweets considering trust and relevance [C]// IIWeb 12: Proceedings of the 9th International Workshop on Information Integration on the Web. New York: ACM, 2012: Article No. 4.
[4]NAGMOTI R, TEREDESAI A, COCK M D. Ranking approaches for microblog search [C]// WI-IAT 10: Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology. Washington, DC: IEEE Computer Society, 2010, 1: 153-157.
[5]高承实,荣星,陈越.微博舆情监测指标体系研究[J].情报杂志,2011,30(9):66-70. (GAO C S, RONG X, CHEN Y. Research on public opinion monitoring index-system in micro-blogging [J]. Journal of Intelligence, 2011, 30(9): 66-70.)
[6]焦德武,常松.微博舆情:生产、研判与处置研究[J].安徽师范大学学报(人文社会科学版),2013,41(1):65-71. (JIAO D W, CHANG S. Study of micro-blog public opinions: production, judgments and treatment [J]. Journal of Anhui Normal University (Humanities and Social Sciences), 2013, 41(1):65-71.)
[7]郭秋艳,何跃.新浪微博名人用户特征挖掘及效应研究[J].情报杂志,2013,32(2):112-116. (GUO Q Y, HE Y. Study on the celebrity users characteristics mining and the effects of Sina micro-blog [J]. Journal of Intelligence. 2013, 32(2):112-116.)
[8]WANG N, SHE J, CHEN J. How “Big Vs” dominate Chinese microblog: a comparison of verified and unverified users on Sina Weibo [C]// WebSci 14: Proceedings of the 2014 ACM Conference on Web Science. New York: ACM, 2014:182-186.
[9]HOVLAND C I. Changes in attitude through communication [J]. Journal of Abnormal Psychology, 1951, 46(3): 424-437.
[10]OKEFFE D J. Persuasion: Theory and Research [M]. Newbury Park: SAGE Publications, 1992: 131-132.
[11]WEERKAMP W, DE RIJKE M. Credibility-inspired ranking for blog post retrieval [J]. Information Retrieval, 2012, 15(3/4): 243-277.http://xueshu.baidu.com/s?wd=paperuri%3A%28ded32bd6967fc22636ecedc1f4833af8%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Flink.springer.com%2F10.1007%2Fs10791-011-9182-8&ie=utf-8&sc_us=15617408281526462347
[12]DEMPSTER A P. Upper and lower probabilities induced by a multivalued mapping [M]// Classic Works of the Dempster-Shafer Theory of Belief Functions, Volume 219 of the series Studies in Fuzziness and Soft Computing. Berlin: Springer-Verlag, 2008: 57-72.
原稿Annals of Mathematical Statistics, 1967, 38: 325-339.
http://xueshu.baidu.com/s?wd=paperuri%3A%280fd693ec38ad9bd0717c38946617c2b2%29&filter=sc_long_sign&tn=SE_xueshusource_2kduw22v&sc_vurl=http%3A%2F%2Frd.springer.com%2Fchapter%2F10.1007%2F978-3-540-44792-4_3&ie=utf-8&sc_us=5445830529683542081
[13]李弼程,王波,魏俊,等.一种有效的证据理论合成公式[J].数据采集与处理,2002,17(1):34-36. (LI B C, WANG B, WEI J, et al. An efficient combination rule of evidence theory [J]. Journal of Data Acquisition & Processing, 2002, 17(1):34-36.)
[14]BTTCHER S, CLARKE C, CORMACK G V. Information Re-trieval: Implementing and Evaluating Search Engines [M]. Cambridge, MA: MIT Press, 2010: 198-200.
