国外名称规范项目及发展趋势研究
2016-09-28郝嘉树
郝嘉树
摘要:文章梳理了国外近些年开展的名称规范项目,对各项目和相关研究进行介绍和评价:认为项目中使用的方法有传统的人工维护、基于著者交互的自规范和自动名称消歧等3种维护模式,各模式各有优劣;同时,认为规范数据的语义化、开放化和关联化、多种维护模式相结合的大资源规范控制、越来越方便用户使用和从标目向唯一标识符方向发展,是未来名称规范发展走向和趋势。
关键词:名称规范项目;名称规范维护模式;开放关联数据;大资源规范控制;用户便利性;唯一标识符
中图分类号:G254 文献标识码:A DOI:10.11968/tsyqb.1003-6938.2016042
1.引言
我国名称规范控制工作存在一些突出的问题,如依赖于自上而下、由领域内少数权威机构维护的模式使得名称规范控制能力跟不上资源增长的速度,面对海量数据完全由编目员承担的方式耗费人力财力而又效率偏低,MARC格式和交换协议使我国名称规范封闭在图书馆环境内,限制了数据的开放、交换和使用,等等。与此同时,近几年计算机技术和互联网的发展使规范控制的环境和对象悄然发生着变化,展现出一些新的走向,如面对越来越以人为中心组织资源的趋势,名称规范急需寻找摆脱困境的出口。
了解国外开展的项目与借鉴他国名称规范控制工作的模式与经验,并掌握和跟随最新的发展趋势,从而引领我国名称规范控制工作走出困境是解决问题的一大出路。但目前我国对他国名称规范相关项目尚无系统的介绍,相关研究也只是散落于个别文献中。针对该情况,本文对国外近些年开展的名称规范项目进行了梳理和评价:对项目中使用的方法进行了总结,归纳出名称规范维护模式的类型,并分析各类型的优劣,给出使用建议:在此基础上,对名称规范发展趋势进行归纳和分析。
2.国外名称规范项目
2.1NACo与VIAF
NAC0(Name Authority Cooperative Program,名称规范合作项目)和VIAF(virtual International Autllority File,虚拟国际规范文档)分别由LC PCC(Library of Congress Program for Cooperative Cataloging,美国国会图书馆编目合作项目)和OCLC(OnlineComputer Library Center,联机图书馆中心)牵头于1976年和2003年开始实行。两个项目都联合了若干国家、地区图书馆和相关机构参与合作,目的同为构建大规模的名称规范档并可用于共建共享,但在成员管理、数据制作与提交和服务理念方面NACO和VIAF存在以下差异。
(1)在成员管理方面,NACO会给成员提供完整的培训课程,并且授权后才能开始工作以保证数据质量,VIAF则不提供培训,主要让成员配合解决数据分歧和冲突方面的问题;NACO成员主要参加业务交流和名称规范相关政策及标准的制定等,VIAF除让成员制定VIAF政策外,还需提供运营方面的建议并帮组推广VIAF的使用。
(2)在数据制作与提交方面,NACO对成员提交的数据质量要求较高,需按照一系列的标准和规则建立和维护规范记录,对有维护能力的机构规定每年提交的数量,其他的则参与NACO的数据质量监控;OCLC也规定成员数据要符合VIAF政策和范例,并且要求成员能提供大量的能明显提升VIAF数量的规范文档,同时还得提交书目数据。
(3)在提供服务方面,NACO专注于成员数据之间的共编和共享,而VIAF更加强调服务理念,提供世界上主要名称规范文档的便捷获取服务,并于2012年由项目转变成为OCLC服务,将各国名称规范档进行映射,可提供名称的多种形式和变体,并附有著者的著述、合著者等内容信息,另外与Wikipedia(维基百科)、ISNI(Imernntional StandardName Identifier,国际标准名称标识符)等合作将应用范围拓展到图书馆以外的领域。
(4)LC与OCLC都较早开始对开放关联数据进行研究及应用。LC主要采用MODS对LCNAF(Li brary of Congress Name Authority File,国会图书馆名称规范档)进行语义化描述,并开发了基于关联数据技术的BIBFRAME(书目框架),规范数据是其中四种数据类型之一。OCLC主要采用Schema.org和SKOS对VIAF进行语义化描述,并研发了VIAF的关联数据服务。
2.2NameProject
由于机构知识库在英国大量增长导致文献的著者名称需要规范控制,JISC(Joint Inform~ion SystemCommittee,联合信息系统委员会1于2008年联合87家机构仓库开展了Names Proiect项目,以寻找唯一辨识英国科研产出者的方法。为进一步推进项目发展,JISC要求各机构提交执行规范控制的调查文档,并于2009年发布最终报告,报告内容包括名称规范控制现状、界定用于名称规范服务所需要的数据元素集和试验性系统的需求分析。并最终于2013年从Zetoc、EthOS、Je-S等机构知识库抽取数据构建了试验原型系统,该系统包含5万个人和机构数据,提供简单查询功能,可返回作者的文献列表。
Name Project为解决文献类资源的名称规范控制提供了可行方案,其从已有数据源中搜集名称方面数据的做法可用来自动产生相当规模的名称规范数据用于更广范围的共享。该项目的特点是没有为著者建立规范标目,而是为每个作者分配ID,可连接作者名称的不同形式,并通过ID聚合发布文献。该做法更像是检索控制而不是规范控制,由于资源类型的差异,该项目建立的规范数据与LCNAF重复率很低。
2.3ULAN
Getty公司构建的ULAN(Union List of Artist Names,艺术家名称联合列表)于1984年开始筹建,起初为自身项目提供受控的艺术家名称,后将服务对象扩展到博物馆、图书馆、档案馆和艺术类书目项目,为搜索艺术家提供检索点、编目提供标准名称和作为研究工具。ULAN于90年代改变列表形式采用叙词表结构表示数据,出版形式为印刷本,目前因数据量大改为网络版,并提供数据下载。
ULAN的数据维护方法与图书馆传统方式一样由专职人员负责,无法满足大量新增资源规范控制的需要。ULAN秉承Gettv制作叙词表的做法和经验,目前完全根据用户的需要和反馈新建规范记录,并且采用叙词表结构表示数据,揭示的内容增加了等级结构和扩展了相关关系种类,并描述了名称类型、语种、新旧程度和是否与LC重复等。
2.4Stylometry
S州ometry(文体学)起初用于经典文学作品中匿名作品的身份识别,后来随机器学习技术的发展,有学者将其用于当代著述中同名著者的区分。著者无意识和根深蒂固的写作风格会在著述中通过各种特征表现出来,因此可以通过计算机统计特征来分析著者写作风格,帮助区分同名著者作品。利用Stylometry开展同名著者作品的区分要根据文献类型提取能体现文体风格的识别特征指标,设计各识别指标的统计方法和公式,并采用N-gram、支持向量机等计算同名著者作品的相似程度。
2.5IDs
文献数据库文章数量巨大,重名、别称、翻译问题、名字变动和西方名字缩写现象严重,导致系统无法辨析著者的唯一性。从2005年开始资源出版商和服务商相继推出Research ID、Scopus Author ID、Pubmed author ID和arXiv Author ID等,即为文章著者分配能唯一标识其学术身份的标识符,旨在消除姓名混淆和重名问题。这些著者唯一标识解决方案有各自的目标和应用边界,削弱了著者标识符的辨识度,阻碍了与外界的共享。
针对以上情况,近几年出现了ORCID(Open Researcher and Contributor Identifier,开放研究者和贡献者标识符),目的是解决各系统间著者姓名混淆和识别问题。ORCID在兼容性方面建立与各系统著者标识符的关联,并将著者相关信息和科研情况聚合起来;在共享性方面不限语言、机构和地理限制,免费向全球学术界开放并提供服务,这种扩大数据和服务范围的做法才能真正起到不同著者唯一身份辨识的作用。有学者对用户参与维护自身信息的积极性提出质疑,但有研究表明从事学术研究的人员希望自己的文献和相关信息被传播和得到认同,并有动力参与此类活动。
2.6AND
AND(Automatic Name Disambiguation,自动名称消歧)是利用机器学习方法对著者文献信息特征进行自动分类及聚类,从而将同一人的作品聚合在一起,而将不同人的作品分开的过程。国内外有较多开展AND技术的研究,主要分为基于监督和非监督两类方法,其中以Han H等人的最具代表性,两类方法都实现了人名自动消歧。基于监督的方法中,Han H等人在标注训练集的基础上利用文献信息的题目、出版物名称和合著者,分别采用Naive Bayesian(朴素贝叶斯)和SVM(支持向量机)对文献作者进行排歧,同时解决了同名和名称变体两个问题:后来为弥补监督学习方法的不足,Han H等人提出Kway聚类算法,该算法将每个文献看作一个特征向量,仍采用题目、出版物名称和合著者作为特征,并用TF-IDF(逆文档频率)和NTF(标准词项频率)计算权重,文献之间采用余弦函数形成相似度矩阵,最终将同一人的作品聚合在一起。两种方法对来自网络资源的消歧准确率分别为90%以上和58%。
2.7FOAF
FOAF(Friend-of-a-Friend,朋友的朋友)是用定义好的RDF词汇表形式化描述个人信息和其相关的社会网络,其本质为描述个人的简单本体。它由Dan Brickley和Libby Miller于2000年创建,遵循W3C体系,最初只描述个人,后扩展到各类群体,如机构、公司和地点,FOAF描述词汇历经10次更新于2014最终确定下来不再更改。
FOAF在名称与主题规范数据中得到广泛应用。名称规范档中的VIAF和LCNAF、主题词表LCSH、Agrovoc和AAT等都用FOAF进行语义化描述。FOAF包含姓名、出生日期、兴趣、职业、项目、发表的著作以及和其他人之间的关系等内容,可用来完善名称规范数据附加成分和单纯参照,提高名称规范数据质量,另外FOAF可通过URI(Uniform Resource Identifier,统一资源标识符)和词汇集的关联自动发现和整合开放数据集合中特定人的相关信息,用于名称规范数据的资源发现和共享。
2.8ISNI
ISNI作为ISO标准始于2007年,目的是为创作和发布内容产品的责任人(包括研究人员、出版机构、发明家、程序员和表演者等)分配一个永久的唯一标识符,同时让ISNI在全球范围的知识库使用从而使作品可以无歧义的归属其作者。ISNI数据库目前由30家机构和数据库、40家国家和研究类型的图书馆组成,有近9百万ISNI标识符,提供检索工具用于查询ISNI号,并可作为关联数据重要部分应用于语义网。
ISNI机制将对图书馆名称规范产生重大影响。ISNI对于唯一标示符的分配把控严格,多样查重后才赋予新ISNI号以保障著者名称标识的权威性和全球唯一性:还开发映射算法与其他机构数据库匹配用于搜集、补充和完善著者信息,并与来源数据库保持同步实现ISNI的实时更新。以上机制保证ISNI在全球范围的通用性和唯一性,如同ISBN的实施措施,随着ISNI的普及图书馆OPAC、机构知识库、文献数据库和网络资源等的人名识别将迎刃而解,不再需要大量人员维护规范数据和挂接文献,工作重点也转移到用户注册、查重与质量认证。
2.9FRAD和BIBFRAME Authority
FRAD(Functional Reqmrements for Authority Data,名称规范数据的功能需求)是IFLA FRBR家族中的一部分,于2009年被IFLA编目组和分类标引组常务委员会批准,它扩充了FRBR第二组实体(相关责任者)的概念模型,为名称规范提供了一个明确定义的结构化参考框架。该框架中,用更接近真实情况的E-R模型(实体关系模型)描述责任者及其属性,还有与其他实体的关系,改变了MARC格式扁平、线性和单一的表示形式。
FRAD模型除包含名称规范数据中承载的信息外,为迎合用户需求具体定义了16个实体和各实体包含的属性以及四大类关系,并提供明确的定义及结构。FRAD用实体(Entity)描述责任者,用属性揭示责任者特征帮助用户进行查找和辨识,用关系反映责任者之间的立体、网状关系,以便用户在书目世界“航行”。
BIBFRAME作为表达书目数据的新方法用于取代世界各国沿用至今的MARC,使得书目数据在整个互联网能得到便捷的交换、发现和共享,其中的BIBFRAME Authority(比图书馆传统的Authority含义更加广泛,囊括主题规范等方面的内容)既实现了传统的规范控制功能,又有网络资源规范控制的特点,如对数据的结构化描述以及与外部RDF数据的关联。
BIBFRAME Authority中发布的与名称规范相关的类为代理,包含人、机构和会议等5个子类,包括的词汇有name、alternative name、authority link、data、control code和description等。BIBFRAME Authority与其它规范控制方法并非竞争关系,而是作为一个轻量级的抽象层定义规范数据如何与作品和实例关联,以及如何指向已有的规范数据,使得规范控制在互联网环境下更加有效的发挥作用。
2.10UTL
UTL(University of Tennessee Library,田纳西大学图书馆)针对小型图书馆没有充足的人力、时间等资源构建名称规范档制定了相应的策略。UTL首先将图书馆书目中所有著者罗列为一张表,并记录著者频次及出处,再根据制定的标准筛选出需要规范的著者,该标准规定著者频率大于3或者是有名的人物才建立名称规范记录:其次到LCNAF和VIAF中寻找该著者的名称规范形式,在没有匹配情况下才新建记录:最后通过列表中出处到书目库搜集著者相关信息。并通过网络、各种工具书和数据库进行完善。
该策略对少产或无名著者不建立规范记录,将精力集中于真正需要消除歧义的著者名称上,并利用已有的规范档减少工作量,节省了人力和时间,适合资源有限的图书馆,也是快速构建本地名称规范档从无到有的有效模式。
2.11BibApp
BiBApp是由伊利诺伊大学香槟分校和威斯康星大学麦迪逊分校图书馆联合开发的用于搜索校园专家的一款软件,最新版本为2011年发布的BibAppl.1。该软件可方便的管理研究人员的科研成果、浏览他人相关信息及成果,并能轻松的找到项目合作人。图书馆对名称规范的维护和应用可借鉴BibApp软件,通过用户参与帮助消除同名作者歧义,并开发相关功能供用户使用,同时又注重友好性体验。另外图书馆可以从BibApp这类的应用中收割信息帮助识别和完善名称规范数据。
3.名称规范维护的模式及分析
从国外开展的名称规范项目和研究之中可以得出当前名称规范维护模式主要有三种类型,本文对它们的优势和劣势进行分析并提供使用建议,以帮助相关机构选择开展名称规范维护的方法和模式。
3.1三种维护模式
(1)传统的人工维护模式。传统的人工维护模式采用自上而下、由领域内少数权威机构的专业编目人员维护名称规范以及挂接书目数据,各国家图书馆名称规范档、ULAN和UTL都采用该种维护模式;另外也有像网络社区、社交软件等自发、小规模的通过人工维护进行身份辨识和消除重名问题的应用。
传统人工维护模式主要依据相关标准和管理系统进行名称规范控制。目前国际上主要有两套名称规范格式和著录体系,分别为IFLA的《UNIMARC/规范格式》、《规范和参照款目指南》和LC的《MARC21规范数据格式》,各机构基于此开展名称规范数据的维护:另外利用带有相关功能的系统管理规范数据,进行存取、增删改操作和实施规范控制。
由于传统维护模式效率低下催生了联合规范项目,由图书馆及相关机构联合起来参与名称规范的共建共享,扩大名称规范控制的范围,如VIAF和NACO。但该方式仍无法弥补传统模式的缺陷,规范控制能力跟不上资源增长的速度。
(2)基于著者交互的自规范模式。自规范模式发起于机构知识库和文献数据库,典型项目有NameProiect和各IDs,这些系统大都由著者填写自身及相关学术信息或是进行身份识别认证,系统会为著者分配一个唯一标识符以解决姓名混淆和重名问题。多次注册、多入口操作和多个标识符问题又促使了ISNI和ORCID的发展,使得唯一标识符扩大到世界范围并且扩展为标准。
基于著者交互的自规范是一种自下而上、去中心化的由著者主导的联合共建模式,著者了解自身相关信息和著述,通过UGC(User Generated Content,用户创造内容)形式整合存在头脑里有关人、机构等的事实信息,并通过系统自发、协同的实现名称规范信息的生成、完善以及不同实体的辨识,可作为名称规范数据维护的另一方法和模式。
基于著者交互的自规范需要以交互网络平台为渠道,通过著者的参与在平台中新增或修改信息项从而实现规范数据的维护。在搭建交互平台中,要规避专业的MARC格式,通过技术手段和友好性设计降低用户参与的复杂度:另外只维护数据难以提高著者的参与度,要设计能帮助个人管理、统计、方便生成科研成果的相关功能来增强著者参与的积极性。
(3)自动名称消歧模式。自动名称消歧模式主要应用在文献数据库和学术机构库中的数字(化)文献,Stylometrv和AND都属于该模式。stvlometrv是从著作内容的角度区分同名著者作品,AND则是通过著作外部特征来帮助区分同名著者作品。该类数据数量巨大且重名现象严重,将易于抽取的著者文献信息项,如主题、合著者、研究方向、出版物名称及类型、引文和分类号等作为辨识特征,利用自然语言学和机器学习技术自动区分重名著者和聚合别名著者的作品,从而实现名称规范控制,可作为名称规范维护的又一重要途径和模式。
Stvlometry中,可有效区分著者文体的识别指标有四方面:词汇特征方面包括基于字和词的特征,句法特征方面有功能词、词性和标点符号,结构特征分为文本总行数、总句数、总段落数、平均每段句数、词数和字数等,内容特征方面是抽取文献表达的主题。stvlometry方法比较适合单一作者的文献,不适用于有多个作者的情况。AND中,基于监督的分类方法有较高的准确度,但需人工构建训练集,面对海量数据进行人工标注工作量巨大,限制了该方法在著者消歧中的应用。基于非监督的聚类方法不需要训练数据,适用性较高,是当前人名消歧的主流方法,但判断数据分布、设定聚类个数等因素影响准确性,可使用EM算法和Gibbs抽样弥补一般聚类算法的不足。
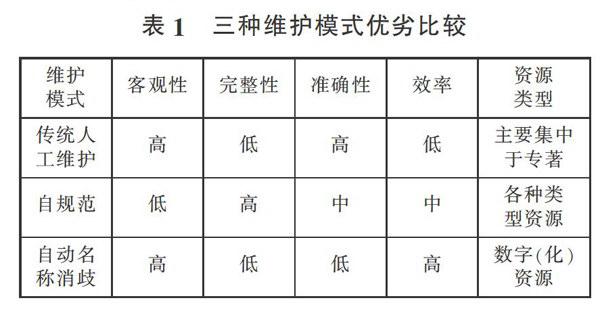
3.2各模式优劣分析
传统模式制作的规范数据质量高但维护效率低下。传统维护模式由专门的编目员根据著录格式和规则对数据进行辨识、新建和完善,客观性和准确性强,但受有效信息源获取的影响,存在不完整、甚至是白板数据。另外面对日益增长的书目和各类型资源,采用由领域内少数权威机构维护的模式使规范数据的规模和范围受到影响和限制,规范控制能力远跟不上资源增长的速度。
著者交互的自规范可以缓解传统维护模式的突出问题,但目前还很难完成规范数据的快速扩张。著者能较容易的辨识规范库中同名数据,发现由更名、别名构建的重复记录;通过添加、修改相关信息项可完善名称规范数据,提高数据质量:除此之外,广泛的著者参与能消除传统维护的局限,扩大名称规范数据的规模和范围。但自规范也存在局限性,仍由人承担维护工作再加上著者参与驱动力的问题,目前还很难快速完成规模扩张,另外著者参与存在信息真实性问题,还需要进行申明和认证。
自动名称消歧效率高但准确性较差。自动名称消歧能根据文献内、外部特征对海量数据快速区分重名著者和聚合别名著者作品,从而实现名称规范维护及控制,但准确性受选取的特征项、特征项信息完整程度和算法影响大。
究竟采用何种方式维护名称规范数据,首先要了解各维护模式的优势和劣势(见表1)。三种维护模式中客观性和完整性之间、准确性和效率之间成反比关系,并且有各自适合的资源类型:其次要结合自身情况,如项目目的、人力和时间、规范对象的类型和规模等因素选择合适的开展方式。对于专业领域、小规模而且人力有限的情况可采用传统维护模式,对于多来源、大规模数字资源宜选用自动消歧方式;另外三种维护方式并不相互排斥,可结合起来使用,前期可选择自动名称消歧并对结果进行检验,区分效果差的资源类型再采用传统和自规范模式维护完成,在提高效率的同时保证准确性,同时也扩大了规范控制能力和范围。
4.名称规范的发展趋势
4.1规范数据的语义化、开放化和关联化
名称规范的MARC格式和交换协议使其封闭在图书馆内,限制了数据开放、交换和使用。随着技术的发展和信息环境的改变,读者利用图书馆资源的对象和方式发生巨大变化,MARC的种种局限,如揭示粒度粗、扁平化和可扩展性差等,在网络时代越来越成为绊脚石:另外只有Z39.50接口和IS02709用于互操作,MARC格式的数据被牢牢圈养在各个图书馆OPAC范围内。
发布开放关联数据可弥补图书馆规范数据的封闭性、无语义、粗粒度、关系揭示少和扩展性差的不足,打破规范数据维护与利用的困境,也为转变资源组织的模式提供了全新的思路,随着BIBFRAME、Schema.org等的推行,规范数据的开放关联必然成为一个重要趋势。事实上一些国家和机构已迈出了一步,大英图书馆和德国国家图书馆等一批国家图书馆已将自己的名称规范发布成了关联数据,OCLC还研发了VIAF的关联数据服务.LC也开发了符合关联数据规范的BIBFRAME书目数据格式,规范数据是其中的数据类型之一。新的数据规范一方面充分考虑与过去MARC的兼容,保证规范数据的语义内容能够迁移到新的系统中:另一方面也为未来的规范控制探索了可行的技术方案。将名称规范发布为开放关联数据,要经过语义化、开放化和关联化的过程:
(1)语义化就是将名称规范数据的MARC格式转换为RDF表达形式,即使用“主体一谓词一客体”三元组(Triple)对规范数据中各项内容进行结构化描述。RDF的三元组描述方式及URI技术可以容易的关联和发现资源而不需任何人工干预,RDF Schema实现理解从而可自动定向获取资源和相关信息。数据语义化后可以被机器理解和处理,为扩展本地名称规范数据种类、范围和规模提供技术保障。转化过程中,为保证共享和重用,要尽量利用已标准化和成熟的词汇集描述数据,避免自造新词汇。同时建立规范数据MARC格式字段及子字段对应的RDF词汇映射表,方便计算机自动批量实现名称规范数据的语义化描述。
(2)开放化通过URI表示和HrITP URI访问实现数据的参引(Dereference),以确保图书馆高质量的规范数据和资源被外部检索使用,并能发挥对网络信息的规范控制作用。根据数据存储方式、数量大小、更新频率和访问方式的不同,一般可考虑采用以下几种方式开放数据:①发布静态的RDF文件,适用于数据量很小的情况:②将RDF文件存储在RDF数据库中,并采用Pubby等服务器作为关联数据服务的前端,适用于数据量大的情况;③在请求数据时根据原始数据在线生成RDF数据,适用于更新频率多的情况;④D2R方式,即从关系数据库到RDF数据转换,适用于关系数据库存储的数据发布成关联数据。
(3)关联化通过语义词汇将不同数据集合以各种关系形式连接起来,通过从一个数据集跳转到另一个数据集,从而能极大程度的发现资源,扩大本地名称规范数据规模,完善自身名称规范数据。OCLC已经开始将VIAF的URIs添加到LC规范数据和Wikipedia当中,从而使LC数据可以被VIAF服务发现,同时获取Wikipedia中的信息。关联其他数据源虽然可通过匹配算法实现,但仍需要人工修正,因此要根据一定的标准来选择关联的来源数据:一是该资源被广泛参考引用,二是该资源可用于丰富、完善本地数据。
4.2多种维护模式相结合实现大资源规范控制
名称规范维护工作一直局限于专著,网络资源、机构知识库和文献数据库等对规范控制的需要促进了大资源规范控制。网络上充斥的错误、冗余和虚假信息需要规范控制发挥作用,该需求促进了语义网技术的发展和各规范数据的发布:机构知识仓库和文献数据库重名、别名和翻译规则等现象严重,急需进行名称规范以提高检准率,IDs和ISNI都是该需求下的产物。各类型资源对规范控制的需要日趋显著促进了大资源规范控制观念的产生,即对各类型的海量资源开展全面的名称规范控制,伴随相关技术的成熟,实现大资源规范控制是名称规范的另一重要趋势。
未来的名称规范控制不应只局限于一种维护模式,而是要根据资源的类型和规模、自身情况和项目要求等采用多种模式相结合的方式进行名称规范维护,从而应对海量资源的快速增长,实现大资源规范控制。面对各类型海量资源规范控制的需要再采用传统的维护模式显然不现实,需借鉴Web2,0环境下的自规范和机器学习领域的自动名称消歧方法。自规范是一种自下而上、去中心化的维护模式,有作者自发、协同的实现个人信息生成、完善以及不同人辨识,能有效弥补著者信息难以获取的问题:自动名称消歧方法非常适用于不断扩大的网络和数字化环境的趋势,有快速区分海量资源中重名著者及其作品的能力,解决名称控制范围和能力低下等问题。
同时,也不必要求对各种类型的资源都规范的越严格越好(如文学作品),所有的规范数据都做到信息项和参照关系完备,如此一定是以牺牲效率为代价。不同的应用领域有不同的需求,如网络环境下的规范控制只能追求合适,无法追求完美。而评价是否合适主要以能否满足需求为标准,如IFLA在FRAD中总结的查找、辨识、提供情境、证明、选择和探索等。借鉴ULAN、UTL等的做法,可只对著名、出现频率高和用户需要的作者进行高质量的维护,而对于一般的人名规范更多的从人名区分和消歧的角度完成规范控制即可。
4.3越来越方便用户使用
《国际编目原则声明》中的最高原则为用户的便利性,对应到名称规范中即在抉择著录及检索用的名称规范数据时应该考虑到用户的需求。目前大部分图书馆名称规范标目(首选检索点)选取的原则为唯一性和一致性,如用生卒年保证标目的唯一性,但从用户的角度来讲,生卒年信息并不能帮助他们有效选择名称和区分相似、同名著者。具体表现在使用OPAC检索著者名称,返回内容或混乱或没有能容易辨识、区分著者名称的信息项,导致用户难以选择所需的名称规范数据。
近些年名称规范逐渐从用户的角度考虑格式和规则的制定,方便用户使用在今后的名称规范制作中会越来越得到重视和体现。1961年的“巴黎原则”只描述了选择单一形式的名称作为规范标目,却没有考虑、解决如何区分相似名称;1984年在IFLAUBC(Universal BibliograDhic Control,世界书目控制)国际会议中,允许以非编目形式记录能区分著者的信息,即以注释的形式将帮助区分著者的信息和来源放在690字段,但只提供给编目员使用,而不包括用户:1999年成立的FRANAR(Functional Requirements and Numbering of Authority Records,规范记录的功能需求与编号工作组)意识到只通过名称不足以判定其代表的实体,在规定用户任务时有两条都与相似著者的名称识别相关,但并没有说明提供给编目员还是用户使用;2009年发布的FRAD增加了描述用户任务的信息,但没有解决以何种形式和用哪些信息为用户提供区分不同著者的服务:随后一年发布的RDA(Resource Descrmdon&Access;,资源描述与检索)中规定了对于无法区分的名称规范使用描述性短语进行识别:西华盛顿大学经过研究认为从事的领域容易区分著者,并建议在FRAD中增加该方面的属性。
另外在名称规范的应用方面将越来越注重用户的友好性体验。随着数字资源越来越以人为中心进行组织,名称规范的应用价值将得到进一步彰显,相应的要设立友好性体验才能充分发挥名称规范控制作用。目前已有一些机构在有意识地增强名称规范区分度以提高用户体验,如香港中文大学图书馆利用DSpace开发的机构知识库对作者加入部门、中文名等属性帮助用户选择正确的著者:Eprints作为世界上第一个数字知识仓库软件开发了自动填词功能,用户输入著者检索词时,系统会自动列出相似词条,供用户区分和选取特定的责任者名称。
随着RDA、BIBFRAME等的提出和推行,其规范数据要充分考虑用户的需求,在属性中扩展消歧短语帮助辨识、区分和选择名称规范,并制定生成消歧短语的相关规则等。在开发基于名称规范的应用时,还需要挖掘方便用户使用的界面和功能,如为用户提供容易识别著者的信息项,制定合适长度的消歧短语在充分揭示信息的同时又不引起噪音,对相似著者的辨识使用浏览、鼠标悬浮和机器提问等显示形式方便用户选择等,从而满足未来普遍存在的以作者为中心的资源组织方式。
4.4从标目向唯一标识符方向发展
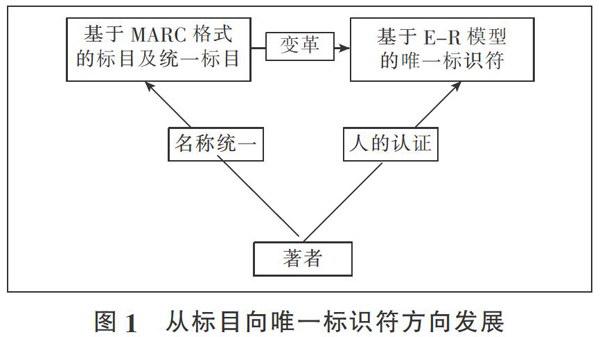
基于MARC格式的标目及统一标目形式实际是一种较浅层次的名称规范。名称规范为实现区分和聚集功能,采用MARC格式承载标目和统一标目的方法实现对著者的唯一标识,其实质是对著者的名称形式进行统一,而不是对人的唯一标识,因此会遇到名称变更、重名和翻译等诸多问题。另外不同机构之间对首选标目原则、姓名著录次序、缩写方式等存在不同的规则和标准,人为造成再次的不统一。
基于E-R模型的唯一标识符其实质是对人的唯一认证,可解决标目的诸多问题。FRBR家族的出现促进了名称规范的发展,采用E-R模型对名称规范的揭示更加细粒度、立体化和满足用户需要,也更接近现实中的真实情况,其实质是对人的唯一认证。其中的唯一标识符对著者的揭示是一种独立于名称形式的表达模型,它唯一标示著者、标识符公开和有明确的界定,并且不会随着名称的变更发生改变,能使统一标目的问题得到有效解决,即不需要选择任何一种优先形式作为标目,从而绕开标目由名称及其变动带来的重名、别称、翻译问题、名字变动和西方名字缩写等诸多问题。随着关联数据的普及和大批量数据的发布,会更加促使名称规范向著者唯一标识符方向发展,最终取代标目的形式,完成从名称到人的本质性认证(见图1)。
5.结语
当前我国名称规范的诸多问题要求改革现有的维护方法,采用多种模式相结合的方式进行名称规范维护,同时要紧随国际上的发展动向,帮助我国名称规范控制工作走出困境。其实,传统的图书馆名称规范控制和整序工作,在新趋势下并没有失去其价值,图书馆数百年积累起来的规范控制经验,如果能积极的迎合时代和环境的发展趋势,不仅能实现过去没有实现的理想,而且能在更大范围内发扬光大。
