关联改进算法在煤矿隐患挖掘中的应用
2016-09-28贵州六盘水师范学院计算机科学与信息技术系胡广勤孙国营
贵州六盘水师范学院计算机科学与信息技术系 胡广勤 孙国营
关联改进算法在煤矿隐患挖掘中的应用
贵州六盘水师范学院计算机科学与信息技术系胡广勤孙国营
我国煤矿事故频发,煤矿安全生产形势严峻,为了能够根据煤矿隐患参数数据挖掘有效信息,指导煤矿安全生产,根据关联算法中常用的Apriori算法在时间效率上的不足,提出改进算法,并通过实验验证了改进算法的合理性,然后通过改进算法挖掘煤矿安全隐患数据,得到强关联规则,对煤矿安全生产起到较好的促进作用。
煤矿事故;隐患参数;关联算法;Apriori算法;改进算法;强关联规则
1 我国煤炭安全生产综述
煤炭行业关系国计民生,是影响我国经济运行的基础产业[1]。然而,我国煤矿安全事故频发,每年因为煤矿事故死亡的人数排在世界前列[2]。煤矿安全生产事故中最常见的是瓦斯问题导致的瓦斯爆炸等事故,而矿井内的瓦斯浓度、瓦斯压力、通风量以及温度等因素都有可能导致瓦斯事故的发生,煤矿安全监测系统能够实时地监测这些参数信息,而这些参数信息之间也是会相互影响的,通过关联算法挖掘瓦斯浓度、瓦斯压力、通风量以及温度之间隐含的关联知识,可以对煤矿安全生产起到较好的指导性作用[3]。
2 关联算法综述
2.1关联规则概念
设I={i1,i2,i3,i4,…,ip}是由p个不同项目组成的集合,对于一个给定的事务数据库DB,假设事物集合O由很多具有唯一标示的事务Oid组合而成,每一条包含于事物集合O的事务Oid所处理的项目集都和I上的一个子集相互对应,就被称为项集Io,也叫作模式Io。如果同时满足事务o∈O以及模式XI的条件,那么就称X包含于事务O。
对于模式X,若X中包含q个项目,记为|X|=q(1≤q≤p),那么,我们就称X为q-模式,也称X的长度为q。例如下面的项集X={i1,i2,i3,i4,i5,i6}就是一个6-项集。
包含X的事务在事务数据库DB中占的百分比数被称为模式X在事务数据库中的支持数,记为X.s;事务数据库DB中含有模式X事务Oid的数目被称为模式X在事务数据库中的支持数,记为X.c。

通过用户提前设定支持度阈值以及置信度阈值的值能够达到更好地实现关联规则挖掘的目的,如果关联规则能够达到支持度和置信度均大于预习设定的阈值的要求,那么就把称为强关联规则。满足这一条件的支持度阈值叫作最小支持度,记为minsup,满足这一条件的置信度阈值叫作最小置信度,记为minconf。
2.2关联规则挖掘算法
作为商业和学术应用范围最广的关联知识发现方法,关联规则挖掘算法已经被开发出多种比较成熟的算法,在这些算法中,被应用最广的是由Agrawal等研究人员提出的Apriori以及随后其他研究人员提出的Apriori改进算法[4]。成功运用这一算法需要注意两点问题,也就是两个阈值的设定:最小支持度(minimumsupport)以及最小可信度(minimumconfidence)。算法挖掘出的最终结果都是要满足最先设定的阈值的大小范围,尤其是一定要小于最小支持度阈值。这个值反应了关联算法中的最低可靠度,基于这一层含义,数据挖掘系统也可以看成是从设定好的数据库中,运用挖掘算法获取满足设定的两个支持度阈值要求的关联规则[5]。
3 Apriori算法存在的缺陷及改进措施
3.1算法缺陷
对数据进行关联规则挖掘非常有效的手段是采用Apriori算法的频繁项集方法,但是在实际生产和应用中,这一算法还存在一些不足之处:
应用Apriori算法处理大量候选项集时会产生巨大的开销,如果算法产生大量的频繁1-项集,那么在由频繁1-项集产生频繁2-项集时就会产生大量的2-项候选集,由于生成的2-项候选集没有剪枝,因此要对每一个2-项候选集进行检验,另外,频繁模式的尺寸过大也会导致大量需要检验的候选项集的产生。由于根据候选项集方法所决定的开销和采用的实现技术无关,因此,在算法会产生大量候选集的情况下,Apriori类的算法运行起来会非常吃力。例如,假设算法得到104个1-频繁集,根据Apriori算法,生成的2-频繁集会超过107个,所有生成的2-频繁集都需要进行检验,这样就会消耗大量的内存,严重增加时间消耗量。
3.2算法改进
3.2.1改进思想
在生成候选项集Ck+1之前,判断Lk中所有项集的数目m以及总的事务属性项数n,如果m>n,再判断Lk中所有项出现的次数是否相同,如果Lk中所有项出现的次数并不完全相同,获取Lk中所有项中次数最小的项的次数值j,裁剪掉Lk中次数值为j的项得到Lk’,然后通过Lk’连接Lk’的操作得到Ck+1。改进后的算法的伪代码为:
(1) L1={large 1-itemsets};
(2)FOR(k=1;Lk≠Φ;k++)DOBEGIN
(3)CutOut(Lk);//对Lk进行裁剪
(4)Ck+1=apriori-gen(Lk);//Ck+1是k个元素的候选集
(5)FOR all transactions t∈DDOBEGIN
(6)Ct=subset(Ck+1,t);//Ct是所有t包含的候选集元素
(7)FOR all candidates c∈CtDO
(8)c.count++;
(9)END
(10)Lk+1={c∈Ck+1|c.count≥minsup_count}
(11)END
(12)Answer=∪kLk;
上述算法调用了CutOut(Lk),是为了对Lk进行裁剪。下面是CutOut(Lk)的伪代码:
(1)if(k>2)Then
(2) for all itemset li∈Lk;
(3)m=count(li);
(4)if(m>n)//n是总的事务属性项数
(5){
(6)min=count(l1);
(7)ifexist(count(li)<min)then
(8)min=count(li);//得到最小次数值
(9)}
(10)delete all ljfromLk(count(lj)=min);
(11)return Lk’
3.2.2算法评价
通过对改进算法的理论分析和实例介绍,我们能够看出改进以后的算法在思路上和Apriori算法仍然是一致的,也就是通过循环扫描数据库获得支持度不小于给定的最小支持度的频繁项集,但是,改进算法在生成Ck+1之前,如果Lk中所有项集的数目大于总的事务属性项数,并且Lk中所有项出现的次数并不完全相同,那么就会对Lk进行一次裁剪,这样就可以减少候选项集Ck+1中候选项的数量,大大降低算法的时间消耗量。但是,这一改进算法也有不足之处,那就是在对Lk进行裁剪的过程中是需要消耗一定的时间的,但是就大型数据库来说,这些时间是可以忽略不计的,使用改进的Apriori算法进行关联规则挖掘的效率也是明显提高的。
4 基于Apriori改进算法的煤矿隐患数据挖掘
4.1数据获取
本文根据某矿2012年1月至2015年1月的煤矿隐患监测系统中持续监测的数据作为研究对象,选取瓦斯浓度、瓦斯压力、通风量以及温度为研究目标,得到的结果如表1所示。
4.2数据预处理
设定瓦斯浓度、瓦斯压力、通风量以及温度的属性分别为C、P、V、T。根据瓦斯浓度的值的情况可以将其分为(0-0.16),(0.16-0.32),(0.32-)三组,对应的标志分别为:C1,C2,C3;根据瓦斯压力的值的情况可以将其分为(0-8),(8-19),(19-)三组,对应的标志分别为:P1,P2,P3;根据通风量的值的情况可以将其分为(0-1100),(1100-1300),(1300-)三组,对应的标志分别为:V1,V2,V3;根据温度的值的情况可以将其分为 (-12),(12-16),(16-)三组,对应的标志分别为:T1,T2,T3。表2为表1中的数据经过预处理以后的数据:

表1 煤矿隐患参数数据

表2 预处理后的数据
4.3关联规则挖掘
4.3.1实验环境
进行煤矿隐患数据挖掘的软硬件环境如下:
硬件环境:处理器为AMDA-10,内存为3G,硬盘为250G。
软件环境:数据库为SQLServer2008。
采用的编程语言是C#,开发环境为Visual Studio2010。
4.3.2挖掘结果
设置最小支持度为0.4,最小置信度为0.6,同时,运用改进后的算法,求得挖掘结果如表3所示。
4.3.3挖掘结果分析
从表3中可以看出,运用改进后的挖掘算法对数据仓库中的数据进行挖掘,一共挖掘出了六条强关联规则,总结如下:
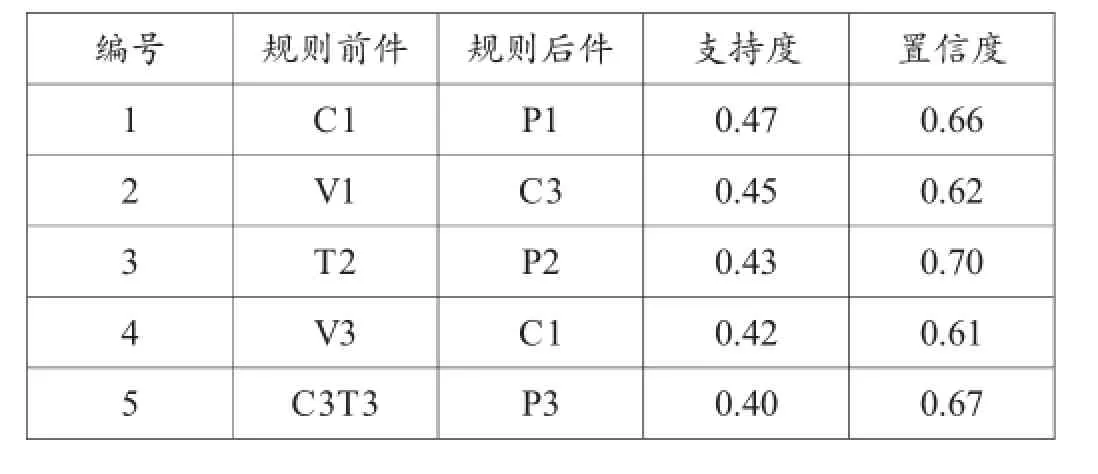
表3 挖掘结果

将这些强关联规则转化为瓦斯浓度、瓦斯压力、通风量以及温度得到的实际意义如下:


通过参考矿井内隐患参数数据的实际情况可以看出,利用改进后的算法得到的强关联规则均是符合客观事实的,利用挖掘出来的有效信息,可以对矿井安全生产起到较好的指导性作用。
[1]刘双跃,彭丽.基于Apriori改进算法的煤矿隐患关联性分析[J].内蒙古煤炭经济,2013,10(11):92-97.
[2]朱翼.基于数组的Apriori算法的改进研究[D].哈尔滨:哈尔滨师范大学,2014.
[3]杨国英.泛在网下基于Apriori算法的移动群组的位置预测[D].南京:南京邮电大学,2013.
[4]邵天会.基于改进的Apriori算法的Web日志研究[D].昆明:昆明理工大学,2013.
[5]冯舸.基于云计算的数据挖掘关联算法研究与实现[D].成都:成都理工大学,2013.
