基于SVM的多特征手写体汉字识别技术
2016-09-19周庆曙陈劲杰纪鹏飞
周庆曙,陈劲杰,纪鹏飞
(上海理工大学 机械工程学院,上海 200093)
基于SVM的多特征手写体汉字识别技术
周庆曙,陈劲杰,纪鹏飞
(上海理工大学 机械工程学院,上海 200093)
针对传统的模板匹配法对汉字的识别率较低,文中提出一种基于SVM的多特征手写体汉字识别技术。在提取网格特征的基础上增加对汉字质心特征、笔划特征、特征点的提取,并采用SVM算法构造分类器,实现对手写体汉字的识别。实验结果表明,该方法的平均识别率为95.9%,高于传统的模板匹配法。
SVM;网格特征;质心特征;笔划特征;特征点
汉字作为中华民族文化的信息载体,与人们的日常学习和工作密不可分。在网络信息交流中,需要输入大量的中文信息[1],重复、单调的传统键盘手工输入方式效率低下,已逐渐不能满足迅速发展的信息化时代。而传统的模板匹配法对于汉字的识别率不高,作者提出一种基于SVM的多特征手写汉字识别技术,可大幅提高汉字的识别率以及录入效率。
1 系统流程
首先对汉字图像进行灰度化、二值化、形态学处理、倾斜校正、字符分割和归一化、细化等图像预处理操作,再对字符进行特征提取,最后采用SVM算法构造分类器。系统识别流程如图1所示。
2 SVM原理
SVM (Support Vector Machines)是建立在统计学习理论的VC维理论和结构风险最小原理基础上的,面对小样本问题,其能表现出良好的学习能力,并能做到与数据的维数无关[2]。

图1 汉字识别流程图
SVM方法是从线性可分情况下的最优分类超平面提出的,所谓最优分类超平面就是要求分类平面不但能将两类无错地分开,且要使分类平面两侧样本之间的间隔最大[4]。过两类样本中离最优分类超平面最近的点,且平行于最优分类超平面的分类超平面上的训练样本称为支持向量[3]。设样本集(xi,yi),xi∈Rd,yi∈{1,-1},i=1,…,n。在线性可分情况下,则可找到权向量w,使两类间隔最大,即‖w‖2最小,同时满足
yi[(w,xi)+b]-1≥0
(1)
其中,i=1,…,n,n表示分类样本的数目。
为求解上述优化问题,引入拉格朗日函数
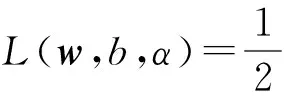
(2)
式中,α为拉格朗日乘子,αi≥0。
通过拉格朗日函数L分别对w,b求偏导,并令偏导数值为0,结果代入超平面方程得到最优分类函数
(3)
汉字识别的分类对象是非线性不可分的。对于不可分问题,可通过引入非负松弛变量ξi加以解决,则约束条件变为
yi[(w·xi)+b]≥1-ξi
(4)

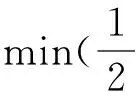
(5)
式中,C是惩罚因子,用来调节分类的准确率与泛化能力[5]。拉格朗日乘子α的取值范围变为0≤αi≤C。对于低维空间的非线性可分问题,可通过引入核函数解决。原始数据的核函数变换为(xi·xj)→K(xi·xj),则非线性情况下,使用核函数之后对应的分类函数为
(6)
3 关键技术
3.1质心特征的提取
质心特征是字符笔划分布的体现[6]。将二值图像转化成点阵形式,黑色像素点用“1”表示,白色像素点用“0”表示。设c(i,j)表示汉字点阵,质心计算如下:水平质心
(7)
垂直质心
(8)
式中,i表示该点阵的行;j表示该点阵的行。
3.2笔划特征的提取
汉字由横、竖、撇、捺4种基本笔划构成,笔划的构成体现了汉字的基本形态[7]。下面对4种基本笔划进行提取。
(1)横、竖笔划的提取。横笔划中所有的像素点具有同一纵坐标,而竖笔划中所有的像素点具有同一横坐标[8]。其特征明显,提取算法也基本相同。本文提出一种将细化后图像与原图像相结合的笔划提取方法,方法如下:1)对细化后图像进行自上而下、从左往右的水平扫描,若同一纵坐标上连续的黑点个数大于或等于2,则记下这些黑点的坐标;2)对原图像进行水平扫描,若这些黑点依然连续,则说明这些黑点构成一个横笔划,横笔划数量加1;3)重复第1、2步;4)当细化后图像水平扫描全部完成时,记下横笔划数。同理,对细化后图像进行自左向右而下、从上往下的竖直扫描,可得到竖笔划数;
(2)撇、捺笔划的提取。1)将细化后图像中的横、竖笔划删除,降低图像的复杂性;2)自上而下、从左往右的水平扫描细化后图像,如果第i行扫描到黑点,记下该黑点的纵坐标yi;3)跳出对第i行的扫描,依次扫描第i+1,i+2,i+3,…,20行,记下首次扫描到黑点的纵坐标y2,y3,y4,…,y21-i;4)比较y2,y3,y4,…,y21-i,若满足yj+1≤yj≤yj+1+1∪yj+2≤yj≤yj+2+2,j∈{1,2,3,…,20-i},则这些点构成一撇笔划,撇笔划数量+1,若满足yj≤yj+1≤yj+1∪yj≤yj+2≤yj+2,j∈{1,2,3,…,20-i},则这些点构成一捺笔划,捺笔划数量+1;5)删除已提取的撇、捺笔划,重复第2)~4)步;6)扫描结束后,记下撇、捺笔划数。
3.3特征点的提取
汉字笔划特征点主要有端点、折点、歧点、交点[9]。端点是笔划的起点或终点(不与其他笔划相接);折点是指笔划方向出现显著变化的点;歧点是三叉点,要求其中两个笔端的分支方向相同;交点是四叉点,且有两对等的对顶角。自左向右、自上而下的对二值图像进行扫描,统计各笔划特征点的个数。
3.4构造分类器
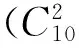
SVM方法的关键环节是选取参数(C,γ)[10]。本文通过网格化寻优和交叉验证的方法得到训练集500×10(10个汉字各有500个样本)的最优参数为(1.76,0.02)。500×10训练集的最优参数网格化寻优如表1所示。

表1 500×10训练集的最优参数网格化寻优
4 实验与分析
实验使用的计算机平台为三星R467笔记本,2.13 GHz CPU,4 GB RAM,Win7 32位操作系统,软件平台为Visual Studio 2010。实验图片来自于HCL2000脱机手写汉字库,使用开源的LIBSVM软件包作为SVM的开发工具。
作者选取训练集500×10、测试集200×10的样本进行3组实验,第一组采用多特征模板匹配法,第二组采用网格特征SVM法,第三组采用多特征SVM法。3组实验的结果如表2~表4所示。由实验结果可知,多特征模板匹配法的平均识别率为81.1%,网格特征SVM法的平均识别率为89.1%,多特征SVM法的平均识别率为95.1%,相比于传统的模板匹配法,多特征SVM法的识别率得到显著提高,从而验证了该方法的有效性。

图2 用于实验的10个汉字

真实值识别值千山鸟飞绝万径人踪灭识别率/%平均识别率/%千16623415510138381.1山81573337392578.5鸟53160655364380飞106315407390877绝007117216011286万873120153180876.5径117311016805484人103580711610580.5踪10509041175587.5灭837315611015678

表3 网格特征SVM法

表4 多特征SVM法
5 结束语
文中提出的基于SVM的多特征手写体汉字识别技术,为提高汉字的识别率,提取了较为全面的字符特征,但提取更多的字符特征意味着算法更为复杂,这样将影响程序的执行效率,降低了识别速度。因此在今后的研究中,还需继续努力改进方法,进一步提高系统的识别速度,使其兼备较高的识别率和较快的识别速度,这样才能更好地替代人工录入。
[1]姜宇,张子潮,周富强.基于OpenCV的车牌识别系统研究[J].辽宁师范大学学报:自然科学版,2011,34(2):170-174.
[2]Gary Bradski,Adrian Kaehler.学习OpenCV:中文版 [M].于仕琪,刘瑞祯,译.北京:清华大学出版社,2009.
[3]汪芳,康慕宁,李先国.印刷体汉字识别技术[J].情报杂志,2004(2):32-33.
[4]王建平,钱自拓,王金玲,等.基于数学形态学的图像汉字笔划细化和提取[J].合肥工业大学学报:自然科学版,2005,28(11):1431-1435.
[5]陈胜勇,刘盛.基于OpenCV的计算机视觉技术实现[M].北京:科学出版社,2008.
[6]刘聚宁.印刷体汉字识别系统研究与实现[D].大连:大连理工大学,2011.
[7]王晓雪.基于字型特征的脱机手写体汉字多分类识别的研究[D].合肥:合肥工业大学,2008.
[8]蔺菲.手写体汉字识别的研究[D].合肥:合肥工业大学,2006.
[9]高彦宇,杨扬.脱机手写体汉字识别研究综述[J].计算机工程与应用,2004(7):74-77.
[10] 尹芳,王卫兵,陈德运.印刷体英文文档识别系统的设计与实现[J].哈尔滨理工大学学报,2009,13(6):9-12.
The Technology of Multiple Features Handwritten Chinese Character Recognition Based on SVM
ZHOU Qingshu,CHEN Jinjie,JI Pengfei
(School of Mechanical Engineering, University of Shanghai for Science and Technology, Shanghai 200093, China)
To solve the recognition rate of traditional template matching method is not high for Chinese character, a new method of multiple featureshandwritten Chinese character recognition based on SVM is proposed. In addition to the extraction grid features, also extract the centroid feature, stroke feature, feature point, and use SVM algorithmconstructclassifierto achieve the recognition of handwritten Chinese characters. Experimental results show that the average recognition rate of the proposed method is 95.9% higher than that of the traditional template matching method.
SVM; grid feature; centroid feature; stroke feature; feature point
10.16180/j.cnki.issn1007-7820.2016.08.040
2015-11-20
周庆曙(1992-),男,硕士研究生。研究方向:机器学习。
TP391
A
1007-7820(2016)08-136-04
