一种提高错误定位效率的测试用例选择方法
2016-09-18付文豪虞慧群范贵生
付文豪, 虞慧群, 范贵生
(华东理工大学计算机科学与工程系,上海 200237)
一种提高错误定位效率的测试用例选择方法
付文豪,虞慧群,范贵生
(华东理工大学计算机科学与工程系,上海 200237)
为提高错误定位的效率,提出了多种测试用例约简与选择的方法,然而,过度的约简与不适的选择造成了部分测试信息丢失,引起了错误定位有效性的损失。本文提出了一种相似测试用例选择方法,用以约简测试集。该方法能消除偶然测试用例对错误定位准确性造成的偏差,通过为每个失败测试用例选择执行轨迹与其相似的成功测试用例的方式,最大限度地保留测试的全部信息;基于选择出的测试用例信息,利用已有的错误定位方法输出程序语句的可疑值列表。以Siemens程序集作为实验对象,证明了本文测试用例选择方法能显著提高错误定位的有效性。
调试; 错误定位; 测试用例选择; 相似测试用例
为了节省软件调试的开销,研究人员提出了许多软件错误自动定位的方法。这些方法利用软件测试过程的测试用例产生的结果和执行信息,分析程序的异常并提供一组程序的可疑代码供开发人员进一步检测,以便快速发现软件的缺陷。然而定位中所使用的测试用例及其执行信息直接影响了此类方法的有效性,因此如何选择合适的测试用例集合成为错误定位的一个关键问题。为了减少错误定位的开销并达到更好的错误定位效率,研究人员提出了多种测试用例约简的方法,并进一步研究了测试用例约简与错误定位有效性之间的关系。
Abreu等[1]研究了错误定位的效率与选择的测试用例数量之间的关系。Baudry等[2]验证了测试用例集的改变可以提高错误定位的准确性。Graves等[3]对多种测试用例选择方法进行了实验研究,并分析了它们的开销与提高的效率。Harrold等[4]提出了一个减少测试用例规模的启发式的算法HGS。Chen等[5]进一步规范了测试用例的约简问题并提出了两个启发式的约简算法。Hao等[6]假设相似的或冗余的测试用例会降低错误定位的有效性,并基于已有的错误定位方法,提出了3种测试用例约简的策略。Hsu等[7]提出了一个测试集最小化框架,这个框架允许测试人员处理涉及多种测试准则的问题,并基于线性规划计算出一个最优的解决方案。而Yu等[9]基于4种覆盖分析方法,通过一系列的实验,进一步研究了测试用例约简方法对错误定位有效性的影响。
不同于已有的测试用例选择或约简的方法,本文单独考虑失败测试用例集中的每种可能的执行轨迹,从成功测试用例集中选取执行轨迹与失败测试用例相似的测试用例,约简那些执行轨迹与相应的失败测试用例执行轨迹具有较大差异的测试用例,利用选择出的测试用例集和现有的错误定位的方法,计算程序中代码的可疑度值,并产生一个供开发人员检测的代码序列。以西门子程序集为实验对象进行了研究,结果表明,该方法能显著地提高错误定位的有效性,同时发现,错误定位的有效性会随着相似比例的变化呈现规律性地变化。
1 基于语句的相似测试用例选择方法
1.1基于语句的相似测试用例选择方法框架
相似测试用例选择的主要目标是为每个失败测试用例单独地挑选与其相似的成功用例,然后利用现有的错误定位方法计算每条语句的可疑度值。该方法基于两个思路:
(1) 对于单个错误的程序而言,每一个失败的测试用例均执行了错误语句;
(2) 与失败测试用例的执行轨迹相似的成功测试用例,其对错误的贡献最大。
这是因为相似的成功测试用例的执行轨迹仅在某些代码部分与失败测试用例存在差异,且若这些差异语句仅被包含在失败测试用例的执行轨迹中,那么这些语句出错的可能性更高。为每个失败的测试用例选择与其执行轨迹相似的成功测试用例,最终构成该失败测试用例的相似测试用例集,用这个相似测试集可以更准确地确定出错语句。
图1示出了测试用例选择方法的基本框架。该框架包括3个阶段:测试用例约简阶段、相似测试用例选择阶段和语句排序计算阶段。整个方法的输入包含一个单个错误的程序以及一组测试套件,使用程序的执行结果和执行过程中收集的语句覆盖信息,利用现有的错误定位的方法,输出程序中所有可执行语句的可疑度列表。在测试用例约简阶段,通过提取程序中的高可疑语句,排除了测试集中的偶然成功测试用例。在测试用例选择阶段,一个测试用例被选择,当且仅当其执行轨迹与对应的失败测试用例的轨迹相似度达到一定值时,每一个失败测试用例的相似测试用例集被选择并产生。在语句排序计算阶段,语句的最终可疑度值通过给定的错误定位方法与每一个相似测试用例集中的频谱信息计算得出。
1.2测试用例约简
测试用例约简阶段的主要目的是将一部分偶然成功测试用例从原有的成功测试集中删除,得到一个优化的新成功测试用例集。对于单个错误的程序而言,成功测试用例中也可能执行了错误语句,这类成功测试用例被归为偶然成功测试用例。偶然成功测试用例是指那些执行了错误语句但却得到正确结果的测试用例。由于本文方法利用失败测试用例与成功测试用例之间的轨迹差异来指导错误定位,若选择了偶然成功测试用例,那么它的执行轨迹将使得某些语句的频谱发生变化,最终必然会影响语句的可疑度值排序,直接影响错误定位的准确性,因此消除这类成功测试用例是该方法中一个重要的阶段。在包含单个错误的程序中,每个失败测试用例必然包含了错误语句,因此,被所有失败测试用例执行过的语句必然具有较高出错的可能性,定义为高可疑语句(HSS)。由于程序错误语句未知,偶然成功测试用例无法完全确定,但可以肯定的是,包含所有HSS的成功测试用例必然为偶然成功测试用例。
根据测试用例的执行结果,原有的测试套件可以分为失败测试集合FT={f1,f2,…,fx}和成功测试集合PT= {p1,p2,…,py},测试用例t的执行轨迹可以表示为et(t)={s1,s2,…,sn},其中n表示程序P中可执行语句的数目。
(1)
如前所述,由于错误语句是未知的,所以我们定义包含所有高可疑语句(HSS)的成功测试用例为偶然成功测试用例。因此需要从所有失败测试用例中提取出HHS。如果语句被所有失败测试用例覆盖,即在所有失败测试用例的执行轨迹et中,si=1或si=0 (1≤i≤n)分别表示语句为高可疑语句或普通语句,那么高可疑语句可以表示为

图1 基于语句的测试用例选择方法Fig.1 Statement-based test suite selection approach
(2)
在确定高可疑语句之后,需逐一检测PT中的偶然成功测试用例。依据之前的定义,若HSS ⊆et(pj) (1 ≤j≤y),即意味着测试用例pj的执行轨迹中包含了所有的高可疑语句,那么测试用例pj被认为是偶然成功测试用例,需从原PT中将其删除。遍历PT中的所有测试用例,直到将所有此类偶然成功测试用例删除,得到新的成功测试集NPT。
1.3测试用例选择
测试用例选择阶段的主要目标是为每个失败测试用例选择与其执行轨迹最为相近的成功测试用例,得到仅包含该失败测试用例和若干成功测试用例的相似用例集。定义一个相似比例(Similar Proportion,SP)作为选择的标准。相似比例表示了两个测试用例共同执行的语句占待检测语句的比例。给定两个测试用例f和p,其执行轨迹分别为et(f)= {a1,a2,…,an} 和et(p) = {b1,b2,…,bm},定义E={e1,e2,…,en}为一个一维数组,对于ek∈E,
(3)

(4)
在测试用例选择阶段,给定一个失败用例,当且仅当成功测试用例与其相似比例满足SP(pj|fi) ≥θ(1≤j≤y,1≤l≤x)时,该成功测试用例才能被选择。θ为给定阈值,表示了选择标准需达到的最小值,θ在0与1之间。根据式(4)的要求,最终得到每个失败测试用例的相似测试用例集。在相似测试用例集中仅包含一个失败测试用例和若干个与该失败测试用例执行轨迹相似的成功测试用例。
1.4语句排序
语句排序阶段的主要目标是利用现有的错误定位技术(如Tarantula[10]方法等)与选择产生的相似测试集,计算得出每条语句的最终可疑值,并按照从高到底的顺序输出。该阶段主要分为两个部分:可疑值分组计算和组合调整。在计算语句可疑值时,应利用每个相似测试集中的语句频谱信息,计算出语句的可疑值,最终,对所有组计算的结果进行调整,得到语句最终的可疑值。
以Tarantula 方法为例,各组中语句的可疑值计算见式(5)。
(5)
其中:suspi(s)表示语句s由测试用例fi与其相似测试集计算得出的可疑度值;tp(s)表示相似测试集中覆盖了语句s的成功测试用例数量;tp表示该相似测试集中的成功测试用例总数量。
根据式(5)计算出程序语句在每个相似测试集中的可疑度值,对各组中的语句可疑度值进行统计分析,得到语句的最终可疑度值,见式(6)。
(6)
其中:score(s)表示语句s最终的可疑度值;x表示失败测试用例的数量,即相似测试集的数量。基于所有语句的最终可疑度值,本文方法最终提供了程序语句的可疑度值的排序列表。
2 实验研究与分析
2.1评测标准
错误定位的有效性可以定义为当检测到错误语句时,已检测的语句(或未被检测的语句)占待检测的总语句的百分比,这个标准被定义为Expense。但为了进一步验证测试用例选择方法对错误定位有效性的影响,本文定义了一个评价标准ExpenseDecrease。
ExpenseDecrease=
(7)
ExpenseDecrease表示错误定位方法在应用原有测试用例与选择出的测试用例上的效率的差值,若ExpenseDecrease的值为正,表明测试用例选择的方法提高了错误定位的效率; 若为负值,则表明该方法使得错误定位的效率降低。使用ExpenseDecrease衡量测试用例选择方法对错误定位有效性的影响,可以规范不同规模程序的错误定位有效性的判定。
2.2实验结果与分析
为了评估测试用例选择方法对错误定位有效性的影响,本文设计并实施了一系列实验来解决以下两个问题:
(1) 相似测试用例选择的方法是否能提高错误定位的有效性?
(2) 在实验中,测试用例选择的标准θ值的改变,会对错误定位的有效性产生怎么样的影响?
本文选择Siemens程序集作为实验对象。Siemens程序包含7组实现不同功能的C程序,每组程序通过人工注入的方式创建了132个不同的错误版本,每个版本中包含1个错误。Siemens程序集被广泛地应用于错误定位方法的研究中,排除不可用版本,实验中仅用了123个版本。在用测试用例选择方法之前,需要完成一些基本实验来获取测试用例的执行结果及轨迹信息。依据测试用例的执行结果,将测试用例划分为成功测试集和失败测试集。为了使实验结果更具有说服性,选取了3种被普遍研究的错误定位技术:Tarantula、Ochiai[11]、Naish[12]。
图2 (a)示出了采用Tarantula方法,错误定位的效率在原有测试集和本文方法(θ为0.50,0.60,0.70,0.80)上的比较结果。图中横坐标表示当定位出错误时已检测的语句占程序总语句的比例,纵坐标表示已检测出的程序版本占错误总版本数的比例。被检测的语句所占的比例越低,表示错误定位的效率越高。将本文方法中的θ取不同值时,相应的相似选择方法定义为S(θ) (θ=0.50,0.60,0.70,0.80)。从图2(a)中可以看出,利用测试用例选择的方法进行错误定位的效率比使用原有测试用例集的效率要好。在同一程序中,当检测相同比例的程序语句时,使用测试用例选择方法能定位出更多的错误版本。例如,当少于10%的语句被检测时,能确定错误语句的错误版本所占的比例依次为53.28%、 54.1%、 63.12% 、66.39%,高于使用原测试集时的效率(40.98%)。当检测更多比例的错误语句时,这一趋势保持不变。得出这样一个简单的结论:在相似测试用例选择的方法中,随着相似比例的增大,错误定位的有效性也不断提高。此外,当θ≥0.85时,某些程序错误版本无法为失败的测试用例选择出达到条件的相似成功测试用例。对于进行选择操作的其他错误程序,错误定位的效率仍然得到了大幅的提高,如图2(b)所示。
Yu等[9]研究了使用了10种基于语句的测试用例约简方法(SA)时Tarantula方法的效率,Gong等[8]也使用Tarantula方法对他们提出的测试用例约简方法(CRV+PRV)进行了研究。为了进一步比较方法的有效性,对实验数据进行了对比,见表1。在表1中,我们发现,SA方法的ExpenseDecrease值均为负,由此表明,SA约简策略降低了错误定位方法的效率;CRV+PRV方法的ExpenseDecrease均为正值,但普遍偏小,说明错误定位的效率提高不明显; 而使用本文方法,不管θ取何值,计算得出的ExpenseDecrease值均为正,且数值偏大,错误定位的效率提高明显。ExpenseDecrease值的变化趋势也证明了θ值影响错误定位效率的结论。
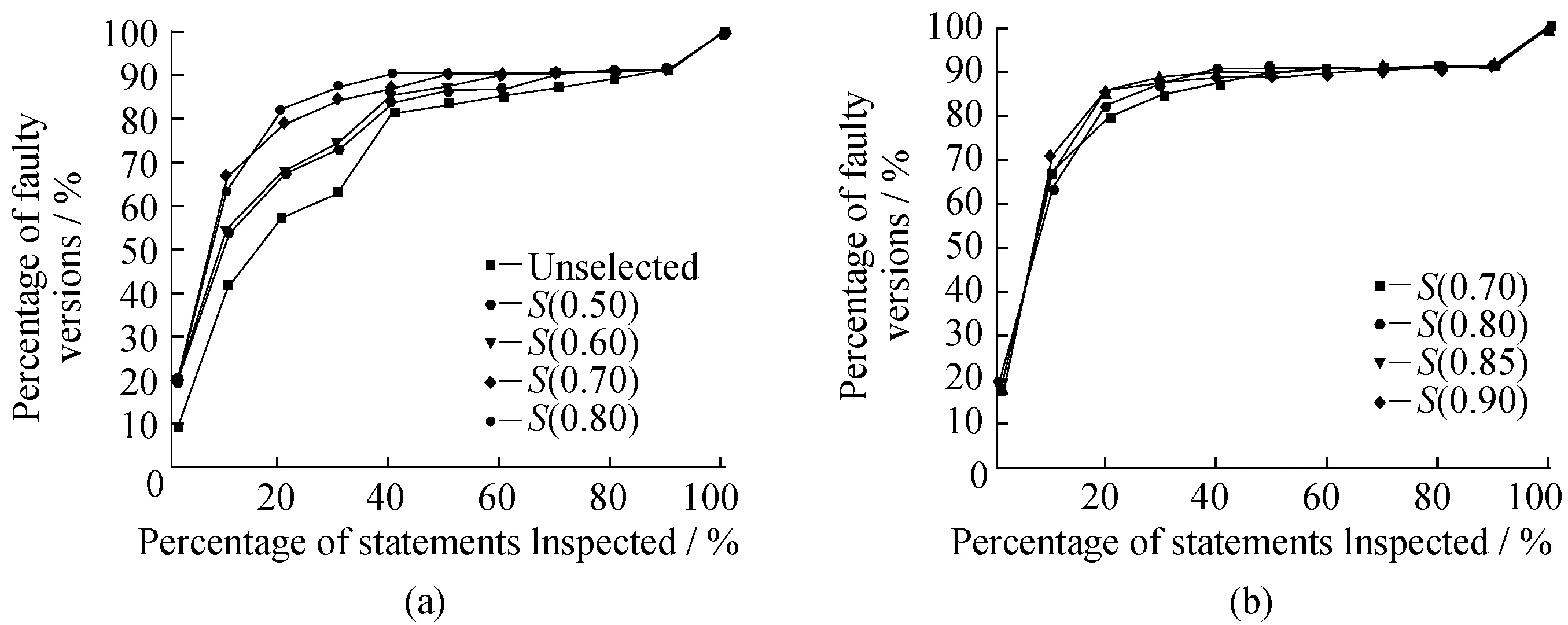
图2 使用被选择的测试用例与原测试集时Tarantula方法的错误定位效率Fig.2 Comparison of Tarantula between selected test suite and unselected test suite 表1 利用Tarantula方法,各测试用例约简方法的平均ExpenseDecrease值 Table 1 Mean ExpenseDecrease using Tarantula on test suite selection
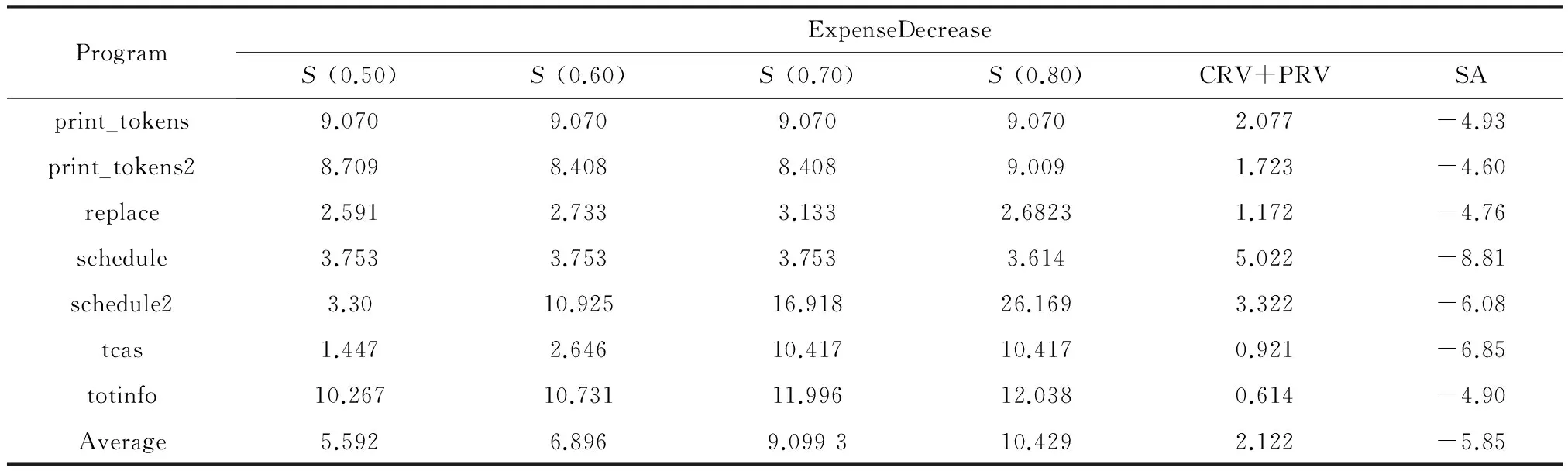
ProgramExpenseDecreaseS(0.50)S(0.60)S(0.70)S(0.80)CRV+PRVSAprint_tokens9.0709.0709.0709.0702.077-4.93print_tokens28.7098.4088.4089.0091.723-4.60replace2.5912.7333.1332.68231.172-4.76schedule3.7533.7533.7533.6145.022-8.81schedule23.3010.92516.91826.1693.322-6.08tcas1.4472.64610.41710.4170.921-6.85totinfo10.26710.73111.99612.0380.614-4.90Average5.5926.8969.099310.4292.122-5.85
本文还使用Ochiai和Naish方法对测试用例选择方法进行了实验研究。图3 示出了语句检测率与错误版本定位率之间的关系图。结果表明,使用测试用例选择方法,Ochiai和Naish方法得出的错误定位的有效性得以提高,并且当θ达到可取的最大值时,错误定位的效率也是最高的。这一结果与Tarantula方法计算出的结果保持一致。表2和表3分别给出了利用Ochiai和Naish方法,结合测试用例约简方法计算出的错误定位有效性的变化值。表中的数据表明了本文提出的相似测试用例选择方法提高了错误定位的有效性。在表中,“replace”程序的错误定位效率有少许降低,但从程序总体看,错误定位的有效性得到了明显的提高。

图3 使用测试用例选择方法与原测试集时,Ochiai和Naish的错误定位效率Fig.3 Comparison of Ochiai and Naish between selected test suite and unselected test suite
3 结束语
本文提出了一种相似测试用例选择的方法用以提高错误定位的有效性。该方法的主要思想是为每一个失败测试用例选择与其执行轨迹最为相似的成功测试用例,利用选择出的相似测试用例及其执行轨迹信息,用现有的错误定位方法计算出语句的最终可疑度值,输出最终的语句可疑值列表。对待选择的成功测试集中的偶然成功测试用例进行了排除操作,提高了本文方法在错误定位上的准确性。最终,Siemens程序集上的实验研究证明了相似测试用例选择的方法能提高错误定位的有效性,并且,随着相似比例的提高,错误定位的有效性提高更为明显。
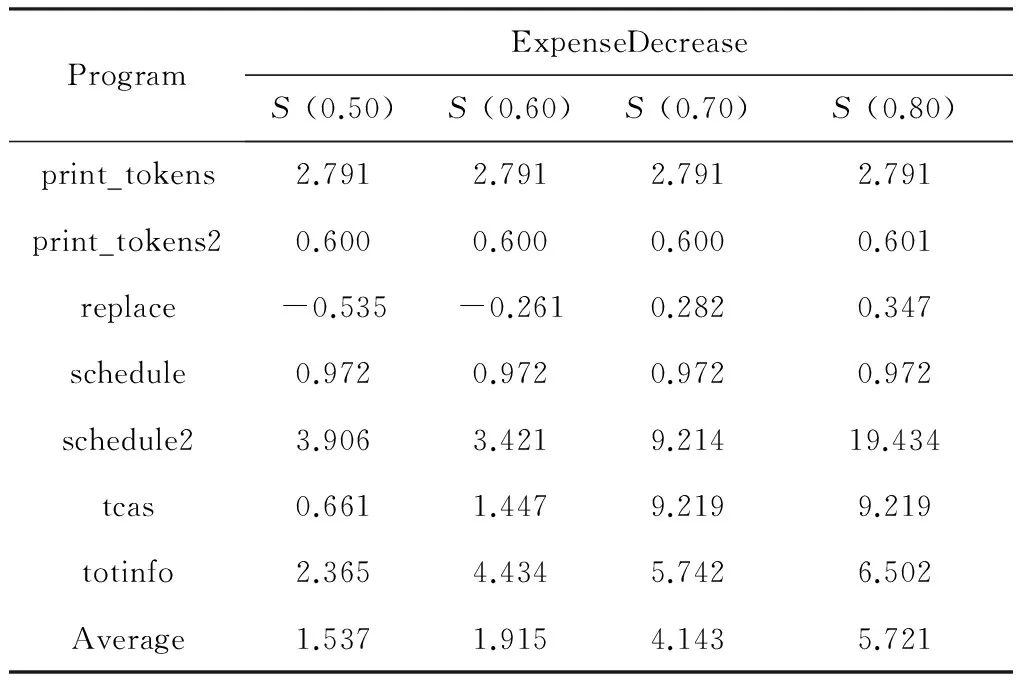
表2 Ochiai方法的平均

表3 Naish方法的平均
本文突出考虑每一种失败执行轨迹,对于单个错误的程序而言,每一个失败测试用例必然执行了错误语句,因此,失败测试用例对错误定位的贡献最大,通过分析比较与失败测试用例的执行信息相似的成功测试用例,将差异语句突显出来,成为了提高错误定位有效性的关键。在未来的工作中,我们将进一步研究基于其他粒度(分支,方法等)的测试用例的约简策略。本文的研究重点关注在小规模单错误的程序上,未来将考虑大规模多错误的程序中测试用例选择方法的研究。
[1]ABREU R,ZOETEWEIJ P,VAN GEMUND A J C.On the accuracy of spectrum-based fault localization[C]//Testing:Academic and Industrial Conference Practice and Research Techniques,MUTATION 2007.Windsor:IEEE,2007:89-98.
[2]BAUDRY B,FLEUREY F,TRAONY LE.Improving test suites for efficient fault localization[C]//Proceedings of the 28th International Conference on Software Engineering.Shanghai:ACM,2006:82-91.
[3]GRAVES T L,HARROLD M J,KIM J M,etal.An empirical study of regression test selection techniques[J].ACM Transactions on Software Engineering and Methodology (TOSEM),2001,10(2):184-208.
[4]HARROLD M J,GUPTA R,SOFFA M L.A methodology for controlling the size of a test suite[J].ACM Transactions on Software Engineering and Methodology (TOSEM),1993,2(3):270-285.
[5]CHEN T Y,LAU M F.A new heuristic for test suite reduction[J].Information and Software Technology,1998,40(5):347-354.
[6]HAO Dan,XIE Tao,ZHANG Lu,etal.Test input reduction for result inspection to facilitate fault localization[J].Automated Software Engineering,2010,17(1):5-31.
[7]HSU H Y,ORSO A.MINTS:A general framework and tool for supporting test-suite minimization[C]//IEEE 31st International Conference on Software Engineering.USA:IEEE,2009:419-429.
[8]DANDAN G,TIANTIAN W,XIAOHONGS,etal.A test-suite reduction approach to improving fault-localization effectiveness[J].Computer Languages,Systems & Structures,2013,39(3):95-108.
[9]YU YANBIN,JONES J A,HARROLD M J.An empirical study of the effects of test-suite reduction on fault localization[C]//Proceedings of the 30th International Conference on Software Engineering.Leipzig,Germany:ACM,2008:201-210.
[10]JONES J A,HARROLD M J,STASKO J.Visualization of test information to assist fault localization[C]//Proceedings of the 24th International Conference on Software Engineering.New York:ACM,2002:467-477.
[11]CAMPOS J,ABREU R.Leveraging a constraint solver for minimizing test suites[C]//2013 13th International Conference on Quality Software (QSIC).Nanjing:IEEE,2013:253-259.
[12]LEE NAISH,LEE H J,RAMAMOHANARAO K.A model for spectra-based software diagnosis[J].ACM Transactions on Software Engineering and Methodology (TOSEM),2011,20(3):11.
A Test Suite Selection Approach to Improving the Effectiveness of Fault Localization
FU Wen-hao,YU Hui-qun,FAN Gui-sheng
(Department of Computer Science and Engineering,East China University of Science and Technology,Shanghai 200237,China)
In order to improve the effectiveness of fault localization,various test suite reduction and selection methods have been proposed in recent years.However,excessive reduction or improper selection on test cases may result in the loss of some testing information and affect the fault localization.In this paper,a new test suite selection approach is proposed to improve spectrum-based fault localization (SFL).The proposed approach can eliminate the deviation in the accuracy of fault localization caused by coincidental passed test cases.By selecting similar test cases for each failed test case from the past test set,testing information is retained as more as possible.Besides,a ranking list is constructed by using an SFL technique with the new spectra.Finally,it is shown via experimental results on Siemens programs that the proposed approach can improve fault-localization effectiveness significantly.
debugging; fault localization; test suite selection; similar test case
1006-3080(2016)04-0557-06
10.14135/j.cnki.1006-3080.2016.04.018
2015-11-06
付文豪(1990-),女,博士生,主要研究方向为软件调试、错误定位等。E-mail:whfu2012@163.com
通信联系人:虞慧群,E-mail:yhq@ecust.edu.cn
TP312
A
