基于MPI的卷积计算并行实现
2016-09-07鲁金,马可,高剑
鲁 金,马 可,高 剑
(西安电子工程研究所,西安 710100)
基于MPI的卷积计算并行实现
鲁金,马可,高剑
(西安电子工程研究所,西安710100)
针对传统的卷积并行计算模型中,存在着大量的消息传递,负载不均衡等问题;提出一种新的基于MPI同步模型的并行卷积算法;该模型采用消息传递的方式进行进程间的通信,同时有效平衡负载,避免大量的消息传递;通过分析该模型的加速比和效率,实验结果表明,此方法显著提高了并行效率和长序列的运算速度,充分发挥了节点间分布式存储和多核并行处理的优势,是一种有效可行的并行策略。
卷积计算;并行;消息传递接口;负载平衡
0 引言
近年来,受到程工艺的限制,单核处理器的性能已接近极限,通过提高单处理器的时钟频率来提高计算机性能的方法越来越难以达到良好的效果。因此,多核技术成为CPU制造商显著提高处理器的性能的共同解决方案[1-2]。多核设备为应用程序提供了并行计算的硬件平台,使计算机的计算速度得到了巨大提高。而另一方面,在数字信号处理领域中,要处理的数据量越来越庞大,实时性的要求也越来越高,,将并行处理的思想运用在信号处理中,构建一个具有并行性的系统,必将是一个未来发展的趋势。
卷积计算作为信号与系统时域分析的一种重要方法。在科学计算领域中起着重要的作用[3],广泛应用于通信,航空航天,生物医学工程,雷达信号处理等工程领域。因此,将并行化的思想应用在卷积计算中,从而大大加快卷积计算的速度,提高卷积计算的效率,具有重要的研究意义。
1 MPI并行
并行计算是指在并行系统上,将一个大的任务分解为多个小的子任务,分配给不同计算单元上,各个计算单元之间相互协同,并行地执行各个子任务,最后汇合同步,从而达到加速求解任务的目的。
消息传递接口MPI[4](message passing interface,MPI)是目前最流行的并行编程模型。它并不是一种新的编程语言,而是一个可以被C、C++和Fortran等程序调用的函数库。不仅具有易移植、高效率等多种优点,而且可以广泛应用于分布式系统中。在MPI程序中,运行在一个核上的程序称为一个进程。两个进程可以通过调用函数来进行通信:一个进程调用发送函数,另一个调用接收函数。将消息传递的实现称为消息传递接口,即MPI。
MPI有多种免费的、高效的实现版本,包括MPICH,LAM和MPI/Pro等,其中MPICH是目前最主流的一种版本,大多并行计算机厂商都提供对它的支持。
2 卷积计算的并行模型
假设x(n)是长度为N1的序列,h(n)是长度为N2的序列,则由x(n)和h(n)卷积所得的结果y(n)可表示为:

(1)
为了能更直观地理解卷积公式,如图1所示,固定h(n)序列不动,将x(n)序列以x(0)作对折,y(0)等于h(0)和x(0)的乘积,然后将x(n)序列往右平移一位,再作乘积相加,对应y(1),并以此类推,求的y(2),y(3),y(4)… 。
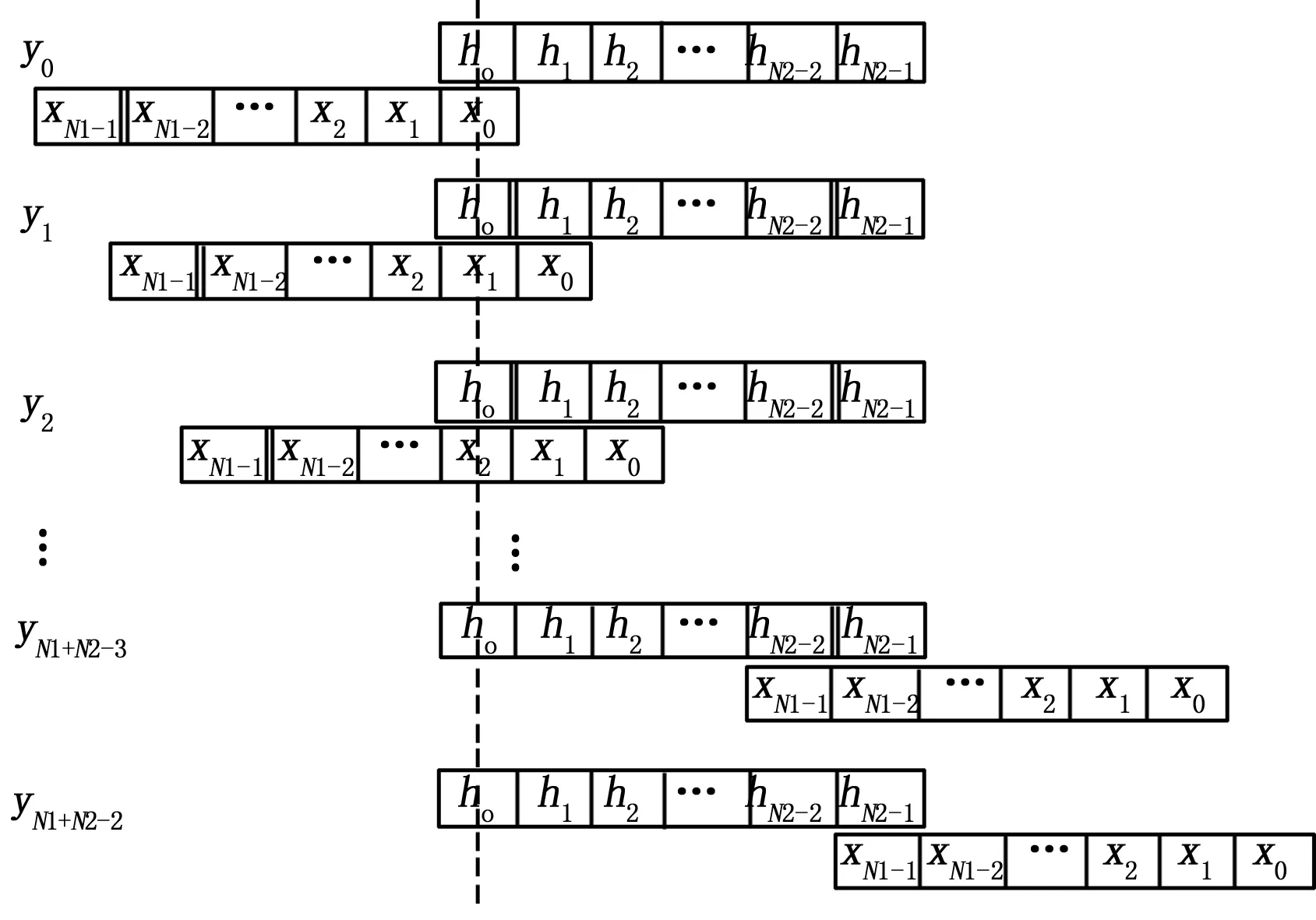
图1 卷积计算
2.1传统基于y(n)分配的MPI模型
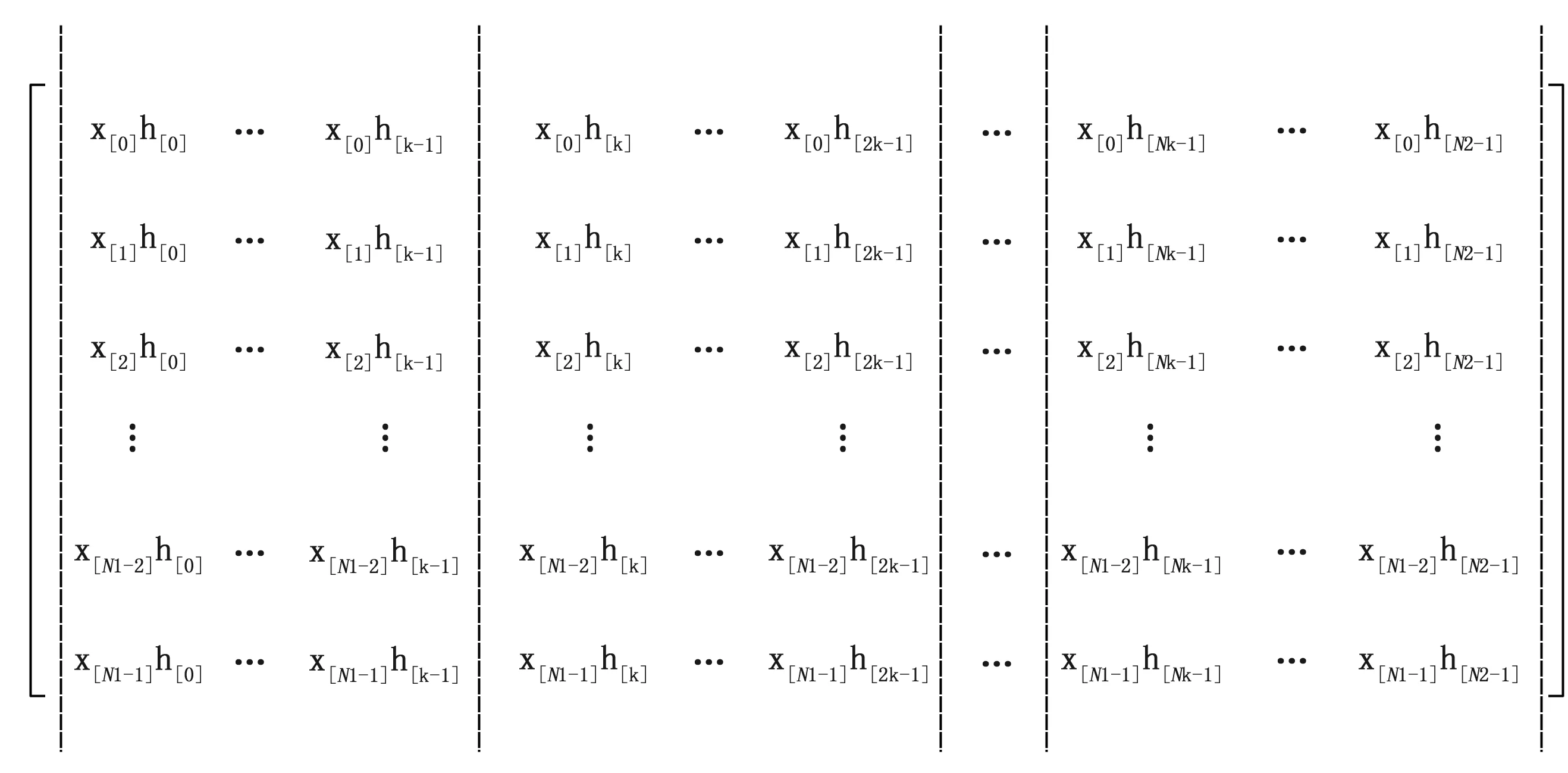
图4 矩阵分割
传统的基于MPI卷积计算的并行方法是根据y(n)来分配任务,如图2所示,基本思想如下:
1)把x(n), h(n)分别广播给N个进程,主进程申请N1+N2-1个存储空间,用以存放计算结果y(n);
2)为每个进程申请ceil((N1+N2-1)/N)个存储空间temp(ceil为向上取整);
3)以循环分配的方式划分每个进程的任务y(k)如图1所示,第k个处理器只计算y(k),y(k+N),y(k+2N),y(k+3N)…,并通过如上计算公式将计算结果按顺序放在该进程申请的存储空间temp中;
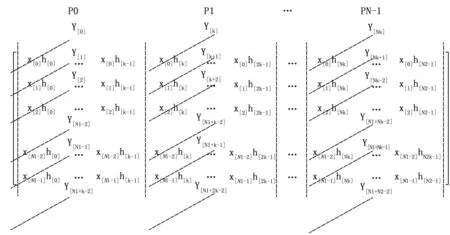
图5 矩阵分割
4)通过MPI_Barrier同步;
5)通过循环(N1+N2-1)/N次,利用MPI_Gather[5-6]依次把temp中的数据搬移到主进程y中。
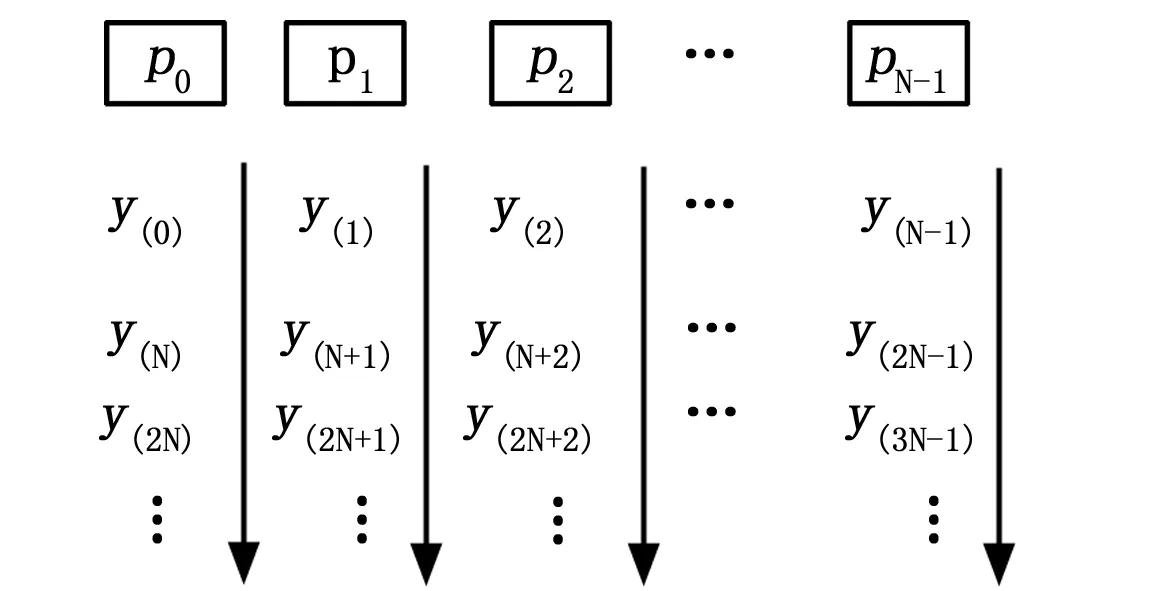
图2 每个进程的任务分配
虽然传统的卷积并行计算相对于普通的串行计算在一定情况下的速度有一定提升,但也存在一些不足:1.负载不均衡,每个y(n)的计算量不同,如y(0)只需一次乘法计算,y(1)需要两次乘法和一次加法计算,而y(3)需要3次乘法和两次加法计算,这会增加单个进程的空闲时间;2.进程间通信量大,进程间的通信严重影响执行的效率[7]。整个计算过程中,除了初始化时的广播外,还有(N1+N2-1)/N次的聚集(gather)操作,花费了大量的额外开销。
2.2基于矩阵分割的MPI模型
为了解决上述传统卷积并行计算存在的一些不足,本文提出一种基于矩阵分割的MPI模型。为了便于分析,我们建立一个由N1个x(n)序列和N2个h(n)序列组成的N1*N2矩阵模型,如图3:可以直观的看出,卷积结果y(k)正好等于第k条斜对角线的所有元素相加。这样,就把求卷积的过程转化为求斜对角线上的元素,并相加。
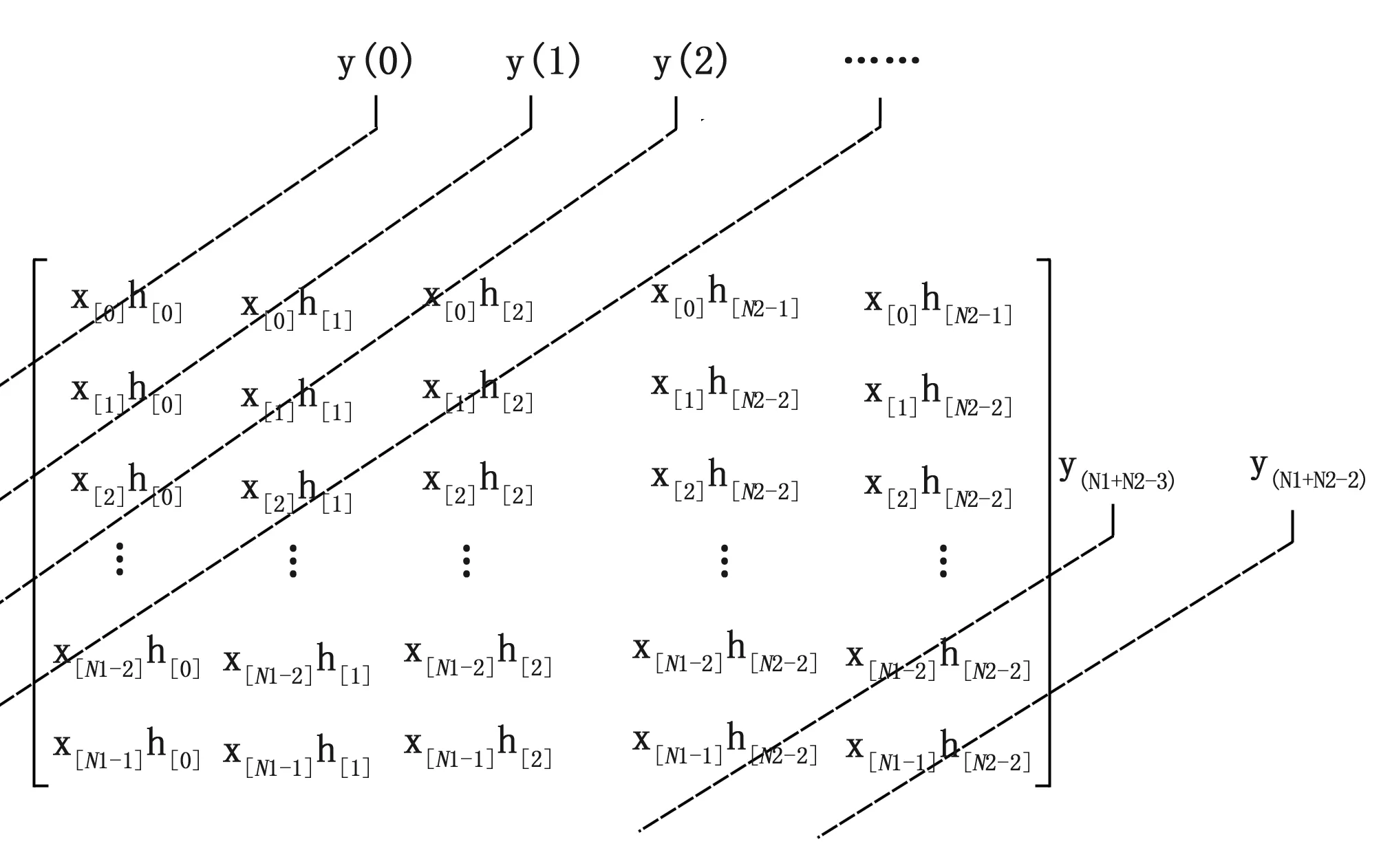
图3 矩阵分割
以并行方式在求矩阵斜对角线元素的和时,本文按图4方式划分并行任务,即按列将整个N1*N2矩阵等分成N个子块(N为进程的个数),不能等分的向上取整(如:列数N2=100,进程数N=8,则前7个子块每块连续分配13列,第8块分配最后9列)。然后将每一块分配给N个进程,每个进程求解对应子块的斜对角线元素的和,如图5所示。最后通过集合通信的方式将每个子块已经求的结果作归约[8]计算。从而就求出了整个矩阵斜对角线元素的和,即卷积的最终结果。整个计算流程如图6所示,具体步骤如下:
1)将x(n)广播给N个进程;
2)将h(n)按块等分成N块(不能等分的向上取整),再将每一块依次广播给N个进程;
3)为每个进程申请N1+N2-1个存储空间y,并初始化为0;
4)每个进程计算对应的子块中斜对角线元素的和,并赋值给对应的y(n),如图3所示。
5)通过MPI_Reduce将每个进程的y(n)相加,最后的结果就是x(n)和h(n)的卷积和y(n)。
可以看到,在整个计算过程中,每个进程的独立性较强,仅在最后作数据归约计算的时候又一次集合通信,大大降低了进程间的通信量。另外,当N2能被N整除时,每个进程的任务负载完全相同。这也大大减少了进程为了同步而等待所消耗的开销。

图6 并行卷积计算流程图
3 实验性能分析
为了测试这种编程模型的性能,将其对串行模型、传统的MPI并行模型进行模拟数值实验,实验环境是:CPU:intel i7@3.4 GHz;内存4.00 GB;操作系统:linux Fedora 17;MPI函数库:MPICH2。在固定处理器数目的条件下(P=8)选取不同的序列长度作等长卷积,对本文基于矩阵分割的MPI算法和传统基于y(n)分配的MPI算法、普通串行算法在执行时间方面进行了实验测试,运行时间如图7所示。
由图6的实验数据可知,随着卷积序列长度的增大,尤其当序列长度大于1 024点以后,基于矩阵分配的MPI算法有明显的效率提升,充分证明该模型具有很高的可行性。
4 结束语
通过对不同长度作卷积计算的测试,实验表明,本文提出的基于矩阵分割的MPI算法具有更高的执行效率,计算时间
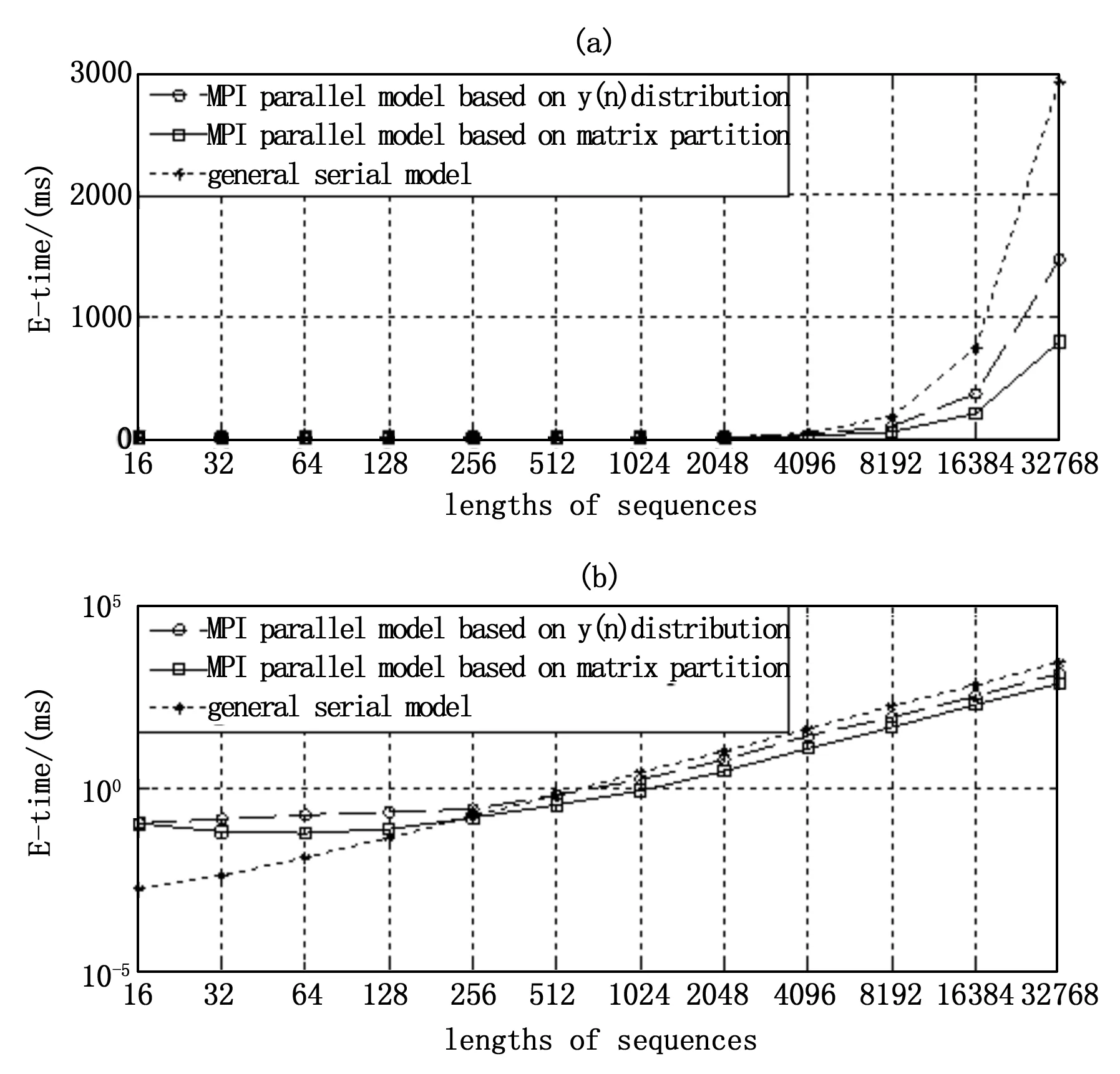
图7 卷积计算效率对比
大大缩短,更加充分发挥节点间分布式存储和多核并行计算的优势。在多核处理器环境下该模型可以有效提高并行计算性能,是一种高效可行的并行编程策略。但当序列长度大到一定的值时,在时域上作卷积并行计算效果并不明显,这时应该考虑转化到频域中再作并行FFT的计算。
[1]Michael J.Quin. Parallel Programming in C with MPI and OpenMP[M]. 北京:清华大学出版社, 2005.
[2]Calvin Lin, Lawrence Snyder. 并行程序设计原理[M]. 北京: 机械工业出版社, 2009.
[3]章隆兵,吴少刚,蔡飞. PC机群上共享存储与消息传递的比较[J]. 软件学报,2004(6):842-849.
[4]Peter S.Pacheco. 并行程序设计导论[M]. 北京: 机械工业出版社, 2013.
[5]Fayez Gebali. Mahafza. 算法与并行计算[M]. 北京: 清华大学出版社, 2012.
[6]Snir M, Otto S, HussLederman S, Walker D, Songarra J, MPI: The Complete Reference,[M]. London: MIT Press, 1996.
[7]曹振南.高性能计算的性能评测与性能优化[D].北京:北京科技大学,2003.
[8]钟光清,郑灵翔. 一种基于循环并行模式的多核优化方法[J], 厦门大学学报(自然科学版), 2010(6):789-792.
Implementation of Parallel Convolution Based on MPI
Lu Jin, Ma Ke, Gao Jian
(Xi’an Electronic Engineering Research Institute, Xi’an710100,China)
Convolution computing plays an important role in scientific computing. There exist massive message passing, load-unbalancing in traditional MPI model. Concerning this question, a new parallel convolution based on MPI model was proposed in this paper. This model prevents massive message passing, and keeps load-balancing. By analyzing the speedup ratio and efficiency, the experimental result shows that the new MPI parallel programming obviously promotes parallel efficiency and large-scale sequence’s speed, which exerts the advantages of distributional memory between nodes and parallel computing. It is an effective and feasible parallel strategy.
convolution computing; parallel; MPI; load-balancing
2015-08-05;
2015-09-11。
武器装备预先研究资助项目(40405040301)。
鲁金(1988-),男,浙江杭州人,硕士,工程师,主要从事并行计算在现代雷达中的应用方向的研究。
1671-4598(2016)01-0292-03
10.16526/j.cnki.11-4762/tp.2016.01.081
TP311
A
