顾及位置关系的网络POI地址信息标准化处理方法
2016-09-06刘纪平郭庆胜
王 勇,刘纪平,郭庆胜,罗 安
1. 武汉大学资源与环境科学学院,湖北 武汉 430079; 2. 中国测绘科学研究院,北京 100830
顾及位置关系的网络POI地址信息标准化处理方法
王勇1,2,刘纪平2,郭庆胜1,罗安2
1. 武汉大学资源与环境科学学院,湖北 武汉 430079; 2. 中国测绘科学研究院,北京 100830
Foundation support: The National High-tech Research and Development Program of China (863 Program) (Nos.2012AA12A402;2013AA12A403) ; The National Natural Science Foundation of China (No.41471384); Research Projects of Public Welfare for Surveying and Mapping Industry(Nos. 201512021;201512032 )
针对互联网POI(兴趣点)地址信息中广泛存在的地址要素不完整、文字表达不一致等不规范现象,提出一种顾及位置关系的网络POI地址信息标准化处理方法,首先对POI信息进行切分提取并逐层匹配地址树模型;然后基于4种位置关系从标准POI库中选出相应集合,作为丰富和修正非标准POI地址要素的候选;最后通过最小粒度地址要素的回溯,实现POI地址信息的快速标准化处理。试验表明该方法可以获得较高的准确率,尤其适用于在互联网数据环境中的POI地址信息标准化。
网络POI;地址树;位置关系;地址标准化
近年来,随着互联网地理信息服务的蓬勃发展,网络POI已经成为大数据时代一种重要的空间信息资源。在我国,网络POI主要来源于地图服务商和用户标注,不同地图数据提供者对于同一个地址的文字表达不尽相同,而用户标注中的地址信息也经常以口述和简化表达的方式来描述,使得同一个地址可能出现多种不同的文字表达,导致来源不同的POI数据融合困难,难以发挥多源信息的聚合作用。
地址标准化处理是网络POI数据清洗、融合与分析的重要内容,是实现地址编码(geocoding)等网络服务的重要基础[1-8],其核心是将不规范、不完整的“非标准”地址信息以符合常见地址表达模型的方式进行“规范化”处理和表达。现有的商业化地址标准化处理工具如ArcGIS的Address Geocoding、MapInfo的MapMarker、Oracle的Spatial Geocoder等,均基于内嵌判别规则来实现地址标准化[9-10];文献[11]通过构建专家系统实现中文地址的标准化;文献[12—13]通过构建多层地址规则实现地名地址向标准化表达模型的转化;文献[14]采用决策树模型实现地址模式匹配。以上方法均需要构建大量领域规则或基于规则形成专家系统,这些方法能较好地满足英文地址信息的标准化与位置匹配要求,但对于中文地址信息处理效果较差,且规则构建过程需要大量人工参与。相比而言,机器学习方法可以基于大量标准化地址样本自动构建出地址要素间的组合规则,从而支持非标准化地址信息的标准化处理[15-22],因而可移植性更强。文献[17]利用机器训练后获得的地址语料库及相关规则,通过局部模糊匹配实现地名地址解析与标准化;文献[20]利用半监督机器学习方法,基于HMM训练模型实现地名地址标准化;文献[21]通过总结中文地址模型的内部规则与空间约束关系,提出基于可扩展地址树的标准地址提取方法。然而,由于汉语言文字固有的地址描述信息不带分隔符等特点,使得基于机器学习的方法也存在样本需求较大、训练周期较长、标准化准确率较低等弊端。
以上基于规则和基于机器学习的地址标准化方法,侧重从纯文本(地址文本)分析角度挖掘地址信息的组合规则,而对POI的位置属性却未充分加以利用。本文试图提出一种顾及空间位置关系的网络POI地址信息标准化处理方法,以可扩展中文地址树模型为指导,首先基于特征词对待处理POI的地址信息进行地址要素切分、识别并与地址树模型逐层匹配,其次将待处理POI的地理坐标与标准参考库进行位置关系计算并形成参考对象库,最后根据最佳匹配结果完成待处理POI地址信息的标准化处理。
1 中文地址模型
1.1中文地址的层次模型
中文地址模型是一种基于层次关系的排列模型,可分为政区级地址要素、街区级地址要素、门牌级地址要素3个层级,其中:政区级要素可细分为国家名、省名、市名、区县名、乡镇名等;街区级要素一般表现为道路、街巷、住宅区等基础限定物;门牌级要素一般表现为楼牌号、单位名称、标志物等局部点位置描述。针对中文地址的结构特征,以及目前我国地址模型存在多套标准的现状,本文设计了一种包含行政区划、基础地址限定物、局部点位置描述的3层地址树模型,如图1所示。
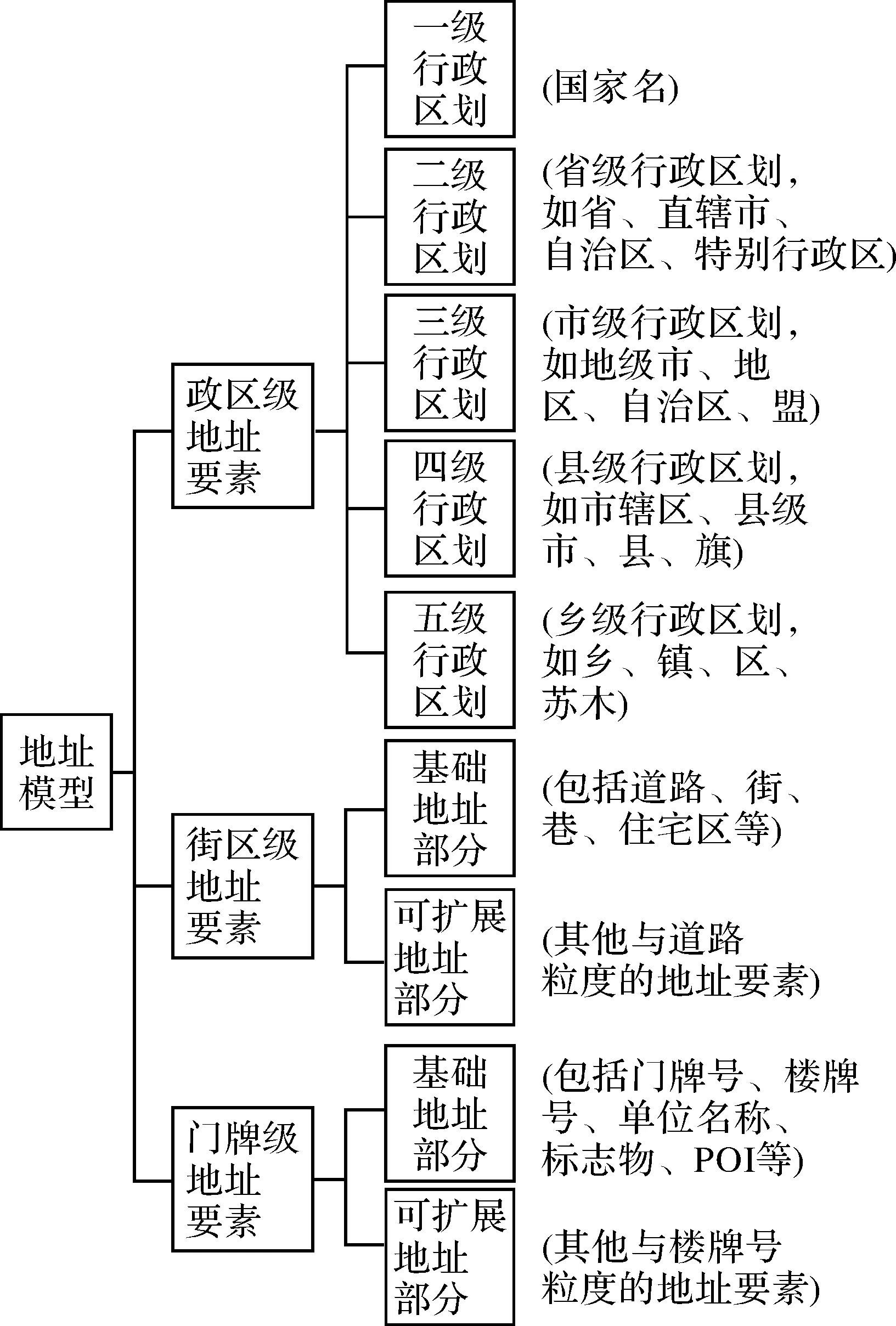
图1 地址树模型的构成Fig.1 Composition of the address model
1.2地址要素组合的限定关系
一个完整的中文地址由政区级、街区街、门牌级等3层要素构成,各层要素还可细分为不同的级别。对于某个具体的地址实例而言,上下级地址要素实例需要遵循一定的限定关系(通常为行政或管理意义上的隶属关系),如图2所示。这种要素实例的限定/映射关系普遍存在,是实现地址标准化尤其是缺失地址要素补全的重要依据。
2 POI地址信息标准化处理
本文提出的POI地址信息标准化处理流程为:首先基于特征词典实现要素识别与切分,将输入的地址信息分割为多个地址要素;其次,通过匹配地址要素,构建各级要素的层次关系,形成地址树;再次,通过位置关系计算筛选出与待标准化POI紧密相关的参考样本;最后利用最小粒度回溯法,基于参考POI实现地址信息中缺失要素自动填充与标准化。
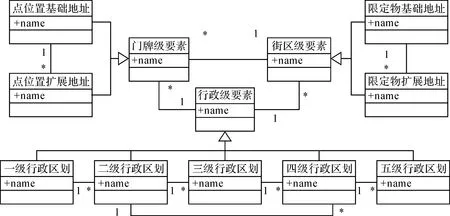
图2 地址要素组合关系图Fig.2 Relations of elements in the address tree
2.1地址要素识别与切分
中文地址要素通常采用“专名+通名”的组合方式进行描述,如“北京市”、“海淀区”、“中关村创业大厦”。其中,通名是表征地址要素级别或类型的特征词,如“市”、“区”、“大厦”;一个地址要素中除掉通名部分如“北京”、“海淀”、“中关村创业”即为专名,专名通常与通名相配合来完整表达一个地址要素。利用通名特征词可以很好地实现地址要素的切分和识别,本文使用的特征词库如表1所示。

表1 地址要素类别与通名(特征词)列表
2.2地址要素逐层匹配
在对地址信息进行要素切分后,需要根据地址树模型匹配处理,具体匹配方法是:读取一个待处理的地址信息后,首先按照2.1节所述的要素组成规则及特征词,将其切分为若干最小粒度的地址要素,然后顺次将各个地址要素与地址树模型的各个层次进行匹配。一旦某要素与地址树模型中的某一级别匹配成功,就将待处理的下一个地址要素与当前匹配级别的下级节点进行逐层比较直至成功匹配;若匹配失败,则将其作为成功匹配出的上级要素的下级节点。如此循环,直到所有地址要素都匹配成功或都已经加入到地址树中。
地址要素匹配主要有3种情况:完全匹配、粗粒度匹配、细粒度匹配。
完全匹配:当能够从地址树中完全匹配到从地址信息中切分出的地址要素时,该地址树无须进行扩展,具体情况见匹配路径(图3(a)),这属于完全匹配情况。
粗粒度匹配:根据切分出的地址要素的上下层次关系,上层较粗粒度的地址要素匹配成功,但下层细粒度的地址要素无法匹配成功。此时,可自动将细粒度地址要素添加到地址树中,匹配过程见图3(b)、(c)、(d)3条路径,其中虚线为扩展。
细粒度匹配:在匹配过程中,地址树中间某层的地址要素无法匹配成功,该情况下可将未匹配成功的地址要素,插入到地址树中,并建立地址树的父子语义关系,匹配过程见图3(e)的匹配路径。
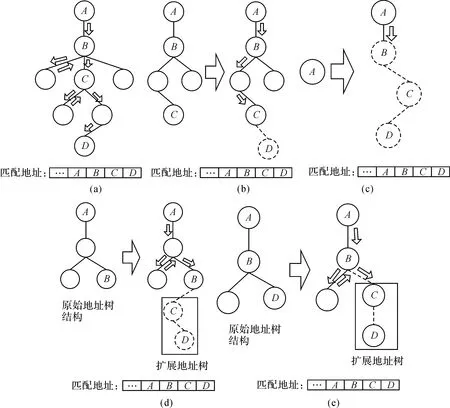
图3 地址树中地址要素的匹配示意图Fig.3 Matching of address elements in address tree
2.3顾及位置关系的参考样本选取
POI的地理位置与其地址描述具有强烈的关联关系,因此,待处理POI与标准化POI之间的位置关系对提升地址标准化效果具有重要参考价值。根据对地址标准化的影响程度,本文重点考虑欧氏距离、从属同一区域、从属同一线状要素和从属同一点状要素等4类位置关系。假定P1为待处理的POI,P2为地址信息已经标准化的POI,Pixq、Piy分别代表Pi点的地理坐标,则4种位置关系(图4)的定义及计算方法如下:
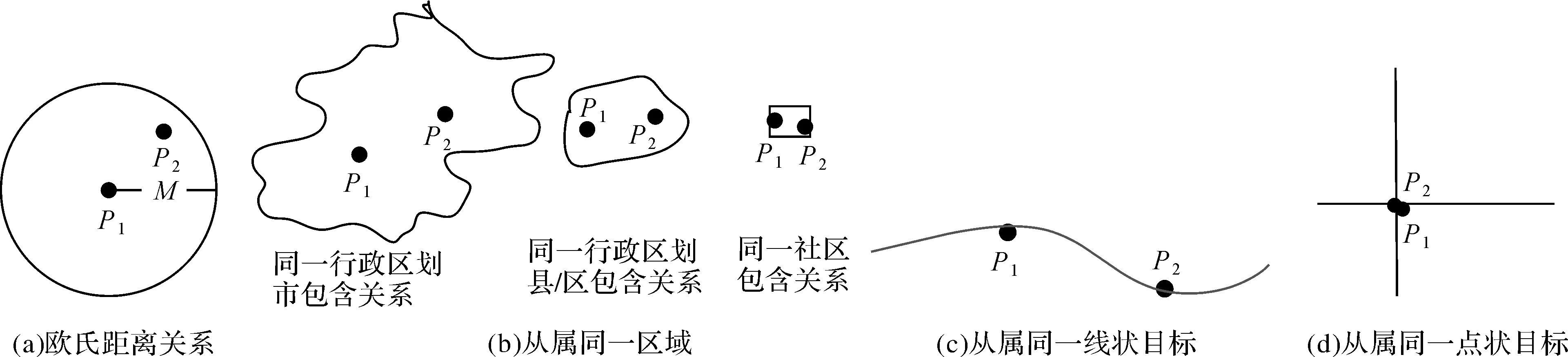
图4 4种位置关系示意图Fig.4 Four types of positional relations
欧氏距离:以POI之间的直线距离来表示,其计算公式为
(1)
欧氏距离一般只用于POI点比较稀少且路网、居民地较为稀少的农村或边远地区,主要作为一种弱空间相关的参考POI样本选取据。在地址标准化参考样本选取时,可以设定一个距离阈值N,当标准化POI与待处理POI的距离大于阈值N时,将不作为地址标准化处理的样本。对我国县级行政区的面积进行统计发现最小面积为56 km2,本文以面积相当的圆反算对应半径,因此将距离阈值设置为N=4.2 km。
从属同一区域:表示两个POI点处于同一个面状地理对象范围内,即被同一个面状地理对象包含,如同一行政区划市包含关系、同一行政区划区包含关系、同一社区包含关系等。
Area(Ai,Pm,Pn)=PtInArea(Pm,Ai)&
PtInArea(Pn,Ai)
(2)
式中,Area(Ai,Pm,Pn)表示点Pm、Pn同时被面对象Ai包含范围;PtInArea用于判断某点P是否被面对象A包含,计算公式如下
PtInArea(P,Area)={∀Area[i],Area[j]|(Px-Area[i]x)*(Area[j]y-Area[i]y)-
(Area[j]x-Area[i]x)*(Py-Area[i]y)<0}
(3)
式(3)通过计算P与Area中任意两点Area[i]、Area[i]的向量叉积是否小于0,判断点P是否被面对象Area包含。
从属同一线状要素:表示两个POI点同处于某一个线性地理对象上,如相同道路附属关系、相同街道附属关系等
Line(Li,Pm,Pn)=PtOnLine(Pm,Li)&
PtOnLine(Pn,Li)
(4)
式中,Line(Li,Pm,Pn)表示点P、P2同属于线对象Li。PtOneLine用于判断是否位于某个线对象上,计算公式如下
PtOnLine(P,Line)={∃Line[i]|Dist
(P,Line[i])=0}
(5)
式中,Line[i]为构成Line的任一线段;Dist(P,Line[i])表示点与和线段的欧氏距离。
从属同一点状要素:表示两个POI点处于同一点状对象或同一地理位置,如属于同一座大厦、位于同一个单元号、或位于同一个地理坐标
Dist(P1,P2)=0‖Dist(P1,P2) (6) 式中,Dist(P1,P2)表示点P1、P2的欧氏距离;M为实际计算中判断为共点关系的阈值。在地址标准化处理中,可作为参考POI的一般为相对固定的点状交通管线要素(如公交站、电线杆)和地标物(如大厦、广场等)。因此本文在重点参考城市道路、建筑设计等相关规范(详见表2)的基础上,设定阈值M=3.5m。 表2 共点距离阈值M设置的主要参考依据 2.4地址要素填充与标准化处理 根据位置关系对地址标准化的影响程度,给出如下强弱关系排序为:共点关系>共线关系>从属同一区域关系>欧氏距离关系。在给定一个具有标准化地址信息的POI数据集后,可以为某个待处理的POI计算出对应于4种位置关系的参考POI集合,分别为Mpt(满足共点关系的集合)、Mln(满足共线关系的集合)、Mar(从属同一区域关系的集合)、Md(符合欧氏距离阈值条件的集合)。依次从4个数据集中选取标准地址作为参考,对待处理POI地址信息中的“缺位”的地址要素进行自动填充,并使地址信息标准化尽可能达到地址要素的最小粒度。具体分为3种情况: (1) 基于共点匹配的地址标准化:当Npt>0时,可以根据参考POI的地址信息实现门牌级地址要素标准化。首先通过文本相似度计算,筛选出与待处理地址具有最大文本相似度的POI作为候选;若候选POI个数大于1,则取距离最近的作为标准化依据。后续的地址标准化处理流程为:以待处理POI地址的最小粒度要素为起点,逐层追溯参考POI的上级地址要素直至最顶层,然后将各级要素的名称顺序串联起来。 (2) 基于共线/共面关系的地址标准化:当Npt=0&(Nln>0‖Nar>0)时,门牌级地址要素匹配失败,但可以根据共线或共面位置关系匹配到关联POI。在这两种情况下,可以回溯到门牌级地址要素的上一级,再根据上一级地址要素与地址树的匹配情况进行处理:①如果该要素的上一级地址要素匹配成功,则找出所有以该上一级地址要素为父节点的地址要素,并依次与当前地址要素进行相似度计算,选取相似度最高的地址要素作为地址标准化的参考节点,然后再从该参考地址要素为起点,逐层追溯其所有的上级地址要素,直至地址树的最顶层,从而实现中文地址的标准化处理;②如果该要素的上一级地址要素仍然匹配失败,则依次循环,继续回溯到更上一级的地址要素进行匹配,直到匹配成功,最终完成地址标准化处理。 (3) 基于欧氏距离的地址标准化:当Npt=0&Nln=0&Nar=0即不存在与该POI共点/共线/共面的参考POI资源时,可以通过欧氏距离计算来选择参考POI。根据Md中POI对象的地址信息,利用文本相似度进行匹配。如果匹配成功,则以该参考地址要素为起点进行地址标准化处理;如果失败,则不以该POI地址作为标准化参考。 3.1算法试验 本文以北京市为例,选取4家互联网地图商的POI数据进行试验,以其中2家互联网地图商的地址数据作为基础匹配资源库,另外2家地址数据作为待处理的测试数据。测试中,基础匹配库分别设置了3万和6万两个级别的数据量,待处理测试数据的数量分别为5000、8000、10 000、15 000、20 000、25 000,测试结果如图5所示。其中,a1、b1表示基础POI资源库有3万条地址数据时的匹配率曲线,a2、b2则表示基础POI资源库数量增加至6万条时的匹配率曲线。 从图5可看出:①不同来源的地址数据标准化的正确率不完全相同,其原因是由于不同来源的网络POI地址表达方式不尽相同,地址表达相对规范或与某一地址模型更为接近的数据源,其地址标准化正确率也相对高些;②随着基础POI资源库数量的增大,尤其是能基本覆盖整个试验地区后,地址标准化将获得更高的正确率,可达90%左右。 图5 中文地址标准化试验结果对比Fig.5 Comparison of experimental result for address standardization 3.2算法讨论 本文提出的地址标准化方法,其处理效果与参考POI数据的丰富程度密切相关,因为参考数据越多,为待标准化地址的各级要素匹配到对应参考对象的几率就越大,从而使缺失的地址要素得以补全、较粗粒度的地址信息也得以提升到更细粒度。在网络数据环境中,由于地图服务提供的POI数量庞大且地址信息较为规范,使得本文提出的基于位置关系POI地址标准化方法具有相当的可行性。 以北京市为例,当基础参考信息为行政区划数据即北京市所辖各区时,待标准化处理的POI数据如表3所示,其标准化匹配遍历及结果如图10。主要存在两种情况: (1) 成功标准化:POI4-POI8的地址标准化处理可以以POI1-POI3的地址要素为参考样本,同时也能自动修正与填充POI1-POI3中地址缺失的地址要素。 (2) 标准化失败:对于POI10地址为“北京西绒线胡33号”,由于地址要素“西城区”与“西绒线胡”在其他POI中从未出现,导致该条POI地址标准化失败。 3.3与传统方法比较 基于规则匹配和纯文本机器学习等传统中文地址信息标准化处理方法[11,20],都聚焦在对“地址文本”进行分析处理,而对因地理坐标派生的“位置关系”及其参考资源考虑较少。此外,基于规则匹配的方法由于需要人工构建地址信息的规则库和专家库,较为耗时耗力,通用性较差,地址标准化效果受规则库质量的影响较大;纯文本机器学习方法多采用半监督学习方法,具有较高的通用性,可以获得较高的准确率。 表3 POI地址标准化匹配示例数据 与之相比,本文提出的顾及位置关系的地址信息标准化处理方法考虑了待处理POI与参考资源库的位置关系,充分利用网络POI数量庞大、样本丰富的优势,在有效克服地址要素缺失、标准化粒度较粗等问题的同时达到较高准确率(表4);无监督学习方式也使得该方法具有较高通用性,可以很好地解决我国大部分城市的POI地址标准化问题。但在偏远地区,由于受参考POI样本数量限制,标准化效果与纯文本机器学习方法相当。 表4 本文方法与传统地址标准化方法的比较 本文提出一种顾及空间位置关系的网络POI地址信息标准化处理方法,该方法基于可扩展中文地址树模型,首先在对POI地址信息进行要素切分和匹配,其次通过基于地理坐标衍生的4种位置关系从标准参考库中抽取出参考对象库,最后根据共点、共线、共面等不同情况完成待处理POI地址信息的细粒度要素匹配和缺失要素填充。与传统地址标准化方法相比,该方法充分利用了POI的坐标信息及其衍生位置关系,能够明显改善机器学习、规则匹配方法等传统方法训练和归纳成本较大、耗时耗力等问题,尤其在具有大量参考POI样本资源的互联网数据环境中具有更好的适用性和更高的准确率。目前本方法使用的位置关系较为简单,相关阈值设定也主要为经验取值,在后续工作中将考虑增加更多的位置关系(如通达性),并就相关阈值设置进行更多的讨论,以使筛选出的候选目标对POI地址标准化具有更好的参考价值。 [1]GOLDBERGDW,WILSONJP,KNOBLOCKCA.FromTexttoGeographicCoordinates:TheCurrentStateofGeocoding[J].URISAJournal, 2007,19(1): 33-46. [2]黄颂. 中文地址编码技术的研究[D]. 北京: 北京大学, 2005. HUANGSong.ResearchonChineseAddressCodingTechnology[D].Beijing:BeijingUniversity, 2005. [3]陈细谦, 迟忠先, 金妮. 城市地理编码系统应用与研究[J]. 计算机工程, 2004, 30(23): 50-52. CHENXiqian,CHIZhongxian,JINNi.ApplicationandStudyofCityGeocodingSystem[J].ComputerEngineering, 2004, 30(23): 50-52. [4]江洲, 李琦, 王凌云. 空间信息融合与地理编码数据库的开发[J]. 计算机工程, 2004, 30(5): 1-2, 153. JIANGZhou,LIQi,WANGLingyun.GeospatialInformationFusionandImplementationofGeocodingDatabase[J].ComputerEngineering, 2004, 30(5): 1-2, 153. [5]李琦, 罗志清, 郝力, 等. 基于不规则网格的城市管理网格体系与地理编码[J]. 武汉大学学报(信息科学版), 2005, 30(5): 408-411. LIQi,LUOZhiqing,HAOLi,etal.ResearchonUrbanGridSystemandGeocodes[J].GeomaticsandInformationScienceofWuhanUniversity, 2005, 30(5): 408-411. [6]程承旗, 关丽. 基于地图分幅拓展的全球剖分模型及其地址编码研究[J]. 测绘学报, 2010, 39(3): 295-302. CHENGChengqi,GUANLi.TheGlobalSubdivisionGridBasedonExtendedMappingDivisionandItsAddressCoding[J].ActaGeodaeticaetCartographicaSinica, 2010, 39(3): 295-302. [7]ZANDBERGENPA.AComparisonofAddressPoint,ParcelandStreetGeocodingTechniques[J].Computers,EnvironmentandUrbanSystems, 2008, 32(3): 214-232. [8]薛明, 肖学年. 关于地理编码几个问题的思考[J]. 北京测绘, 2007(2): 54-56.XUEMing,XIAOXuenian.ConsideringonSomeQuestionsofGeocoding[J].BeijingSurveyingandMapping, 2007(2): 54-56. [9]章意锋, 吴健平, 程怡, 等.ArcGIS中地理编码方法的改进[J]. 测绘与空间地理信息, 2007, 30(3): 116-119. ZHANGYifeng,WUJianping,CHENGYi,etal.TheImprovementofGeocodinginArcGIS[J].Geomatics&SpatialInformationTechnology, 2007, 30(3): 116-119. [10]朱前飞.MapInfo中的地理编码及应用[J]. 四川测绘, 2001, 24(3): 117-119. ZHUQianfei.GeocodeandItsApplicationinMapInfo[J].SurveyingandMappingofSichuan, 2001, 24(3): 117-119. [11]GUBin,JINYanfeng,ZHANGChang.StudyontheStandardizedMethodofChineseAddressesBasedonExpertSystem[C]∥ProceedingsoftheIEEE2ndInternationalConferenceonCloudComputingandIntelligentSystems(CCIS).Hangzhou:IEEE, 2012: 1254-1258. [12]KOTHARIG,FARUQUIETA,SUBRAMANIAMLV,etal.TransferofSupervisionforImprovedAddressStandardization[C]∥Proceedingsofthe20thInternationalConferenceonPatternRecognition(ICPR).Istanbul:IEEE, 2010: 2178-2181. [13]CHENLiyan,FANGYuan.TheDesignandResearchofStandardAddressDatabaseSystemBasedonWebGISinPanyu,Guangzhou[C]∥Proceedingsof2008InternationalSeminaronBusinessandInformationManagement.Wuhan:IEEE, 2008: 233-235. [14]AUTHORITYTV.AddressDataContentStandardPublicReviewDraft[S]. [S.l.]:SubcommitteeonCulturalandDemographicData,FederalGeographicDataCommittee,2003. [15]高红, 黄德根, 杨元生. 汉语自动分词中中文地名识别[J]. 大连理工大学学报, 2006, 46(4): 576-581. GAOHong,HUANGDegen,YANGYuansheng.ChinesePlaceNamesRecognitionforChineseAutomaticSegmentation[J].JournalofDalianUniversityofTechnology, 2006, 46(4): 576-581. [16]张春菊, 张雪英, 吉蕾静, 等. 地名通名与地理要素类型的关系映射[J]. 武汉大学学报(信息科学版), 2011, 36(7): 857-861.ZHANGChunju,ZHANGXueying,JILeijing,etal.RelationMappingbetweenGenericTermsofPlaceNamesandGeographicalFeatureTypes[J].GeomaticsandInformationScienceofWuhanUniversity, 2011, 36(7): 857-861. [17]唐旭日, 陈小荷, 张雪英. 中文文本的地名解析方法研究[J]. 武汉大学学报(信息科学版), 2010, 35(8): 930-935, 982. TANGXuri,CHENXiaohe,ZHANGXueying.ResearchonToponymResolutioninChineseText[J].GeomaticsandInformationScienceofWuhanUniversity, 2010, 35(8): 930-935, 982. [18]BOURLANDFJ,WALDENSC,BAKERCA.RichBrowser-basedInterfaceforAddressStandardizationandGeocoding:US, 20080065605[P]. 2008-03-13. [19]MASREKMN,RAZAKZA.MalaysianAddressSemantic:TheProcessofStandardization[C]∥Proceedingsofthe2ndInternationalConferenceonComputerResearchandDevelopment.KualaLumpur:IEEE, 2010: 77-80. [20]KALEEMA,GHORIKM,KHANZADAZ,etal.AddressStandardizationUsingSupervisedMachineLearning[C]Proceedingsof2011InternationalConferenceonComputerCommunicationandManagement.Singapore:IACSITPress, 2011, 5: 441-445. [21]亢孟军, 杜清运, 王明军. 地址树模型的中文地址提取方法[J]. 测绘学报, 2015, 44(1): 99-107.DOI: 10.11947/j.AGCS.2015.20130205. KANGMengjun,DUQingyun,WANGMingjun.ANewMethodofChineseAddressExtractionBasedonAddressTreeModel[J].ActaGeodaeticaetCartographicaSinica, 2015, 44(1): 99-107.DOI: 10.11947/j.AGCS.2015.20130205. [22]GUOHonglei,ZHUHuijia,GUOZhili,etal.AddressStandardizationwithLatentSemanticAssociation[C]∥Proceedingsofthe15thACMSIGKDDInternationalConferenceonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2009: 1155-1164. (责任编辑:宋启凡) WANGYong(1976—),male,associateprofessor,majorsinretrievingandminingofWebgeospatialinformation. The Standardization Method of Address Information for POIs from Internet Based on Positional Relation WANG Yong1,2, LIU Jiping2, GUO Qingsheng1, LUO An2 1. School of Resource and Environmental Sciences, Wuhan University, Wuhan 430079, China; 2. Chinese Academy of Surveying and Mapping, Beijing 100830, China As points of interest (POI)on the internet, exists widely incomplete addresses and inconsistent literal expressions, a fast standardization processing method of network POIs address information based on spatial constraints was proposed. Based on the model of the extensible address expression, first of all, address information of POI was segmented and extracted. Address elements are updated by means of matching with the address tree layer by layer. Then, by defining four types of positional relations, corresponding set are selected from standard POI library as candidate for enrichment and amendment of non-standard address. At last, the fast standardized processing of POI address information was achieved with the help of backtracking address elements with minimum granularity. Experiments in this paper proved that the standardization processing of an address can be realized by means of this method with higher accuracy in order to build the address database. POIs from internet;addresses tree; positional relation;standalization of address 2015-12-08 2016-03-22 王勇(1976—),男,副研究员,研究方向为网络地理信息获取与挖掘。 E-mail:wangyong@casm.ac.cn 10.11947/j.AGCS.2016.20150618. WANG Yong, LIU JiPing, GUO QingSheng, et al.The Standardization Method of Address Information for POIs from Internet Based on Positional Relation[J]. Acta Geodaetica et Cartographica Sinica,2016,45(5):623-630. DOI:10.11947/j.AGCS.2016.20150618. P208 A 1001-1595(2016)05-0623-08 国家863计划(2012AA12A402;2013AA12A403);国家自然科学基金 (41471384);国家测绘地理信息局公益科研专项(201512021;201512032) 引文格式:王勇,刘纪平,郭庆胜,等.顾及位置关系的网络POI地址信息标准化处理方法[J].测绘学报,2016,45(5):623-630.
3 试验与分析



4 结 论
